Hallo nochmal!
Im Dezember werden wir mit dem Training für die nächste
Data Scientist-Gruppe beginnen , daher gibt es immer mehr offene Lektionen und andere Aktivitäten. Neulich fand beispielsweise ein Webinar unter dem langen Namen „Feature Engineering am Beispiel des klassischen Titanic-Datensatzes“ statt. Es wurde von
Alexander Sizov , einem erfahrenen Entwickler, Ph.D., einem Experten für maschinelles / tiefes Lernen und Teilnehmer an verschiedenen kommerziellen internationalen Projekten im Zusammenhang mit künstlicher Intelligenz und Datenanalyse, durchgeführt.
Eine offene Lektion dauerte ungefähr anderthalb Stunden. Während des Webinars sprach der Lehrer über die Auswahl von Funktionen, die Transformation von Quelldaten (Codierung, Skalierung), das Einstellen von Parametern, das Trainieren des Modells und vieles mehr. Während des Unterrichts wurde den Teilnehmern ein Jupyter-Notizbuch gezeigt. Für die Arbeit verwendeten wir offene Daten von der
Kaggle- Plattform (ein klassischer Datensatz über die Titanic, von dem viele beginnen, sich mit Data Science vertraut zu machen). Im Folgenden bieten wir ein Video und eine Abschrift des vergangenen Ereignisses an.
Hier können Sie die Präsentation und die Codes in einem Jupiter-Laptop abrufen.
Funktionsauswahl
Das Thema wurde gewählt, obwohl klassisch, aber immer noch ein wenig düster. Insbesondere war es notwendig, das Problem der binären Klassifizierung zu lösen und anhand der verfügbaren Daten vorherzusagen, ob der Passagier überleben wird oder nicht. Die Daten selbst wurden in zwei Stichproben Training und Test aufgeteilt. Die Schlüsselvariable ist Überleben (überlebt / nicht überlebt; 0 = Nein, 1 = Ja).
Trainingsdaten eingeben:
- Ticketklasse
- Alter und Geschlecht des Passagiers;
- Familienstand (ob Verwandte an Bord sind);
- Ticketpreis;
- Kabinennummer;
- Einschiffungshafen.
Wie Sie sehen können, sind die Variablentypen unterschiedlich: numerisch, Text. Aus diesem Kaleidoskop musste ein Datensatz für das bevorstehende Modelltraining erstellt werden.
Wir fassen zusammen:
- train.csv - Trainingssatz - Trainingsdatensatz. Die Antwort ist in ihnen bekannt - Überleben - ein Binärzeichen 0 (nicht überlebt) / 1 (überlebt);
- test.csv - Testsatz - Testdatensatz. Die Antwort ist unbekannt. Dies ist ein Beispiel, das an die Kaggle-Plattform gesendet werden muss, um die Modellqualitätsmetrik zu berechnen.
- gender_submission.csv ist ein Beispiel für das Format der Daten, die an kaggle gesendet werden sollen.
Arbeitsalgorithmus
- Die Arbeit erfolgte schrittweise:
- Analyse von Daten aus train.csv.
- Umgang mit fehlenden Werten.
- Skalieren.
- Codierung kategorialer Merkmale.
- Erstellen eines Modells und Auswählen von Parametern, Auswählen des besten Modells für die konvertierten Daten aus train.csv.
- Fixierung und Modell der Transformationsmethode.
- Anwenden der gleichen Konvertierungen auf test.csv mithilfe der Pipeline.
- Anwendung des Modells auf test.csv.
- Speichern der Anwendungsergebnisdatei im selben Format wie in gender_submission.csv.
- Senden von Ergebnissen an die Kaggle-Plattform.
Der praktische Teil des WebinarsDas erste, was getan werden musste, war, den Datensatz zu lesen und unsere Daten auf dem Bildschirm anzuzeigen:
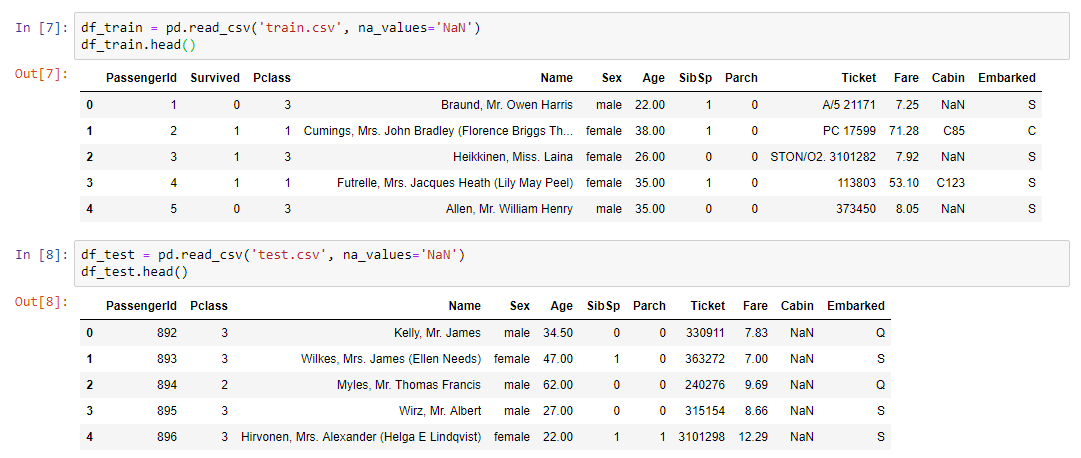
Für die Datenanalyse wurde eine wenig bekannte, aber recht nützliche Profilbibliothek verwendet:
pandas_profiling.ProfileReport(df_train)Mehr zur ProfilerstellungDiese Bibliothek erledigt alles, was a priori möglich ist, ohne die Details der Daten zu kennen. Zeigen Sie beispielsweise Statistiken zu Daten an (wie viele Variablen und welcher Typ sie sind, wie viele Zeilen, fehlende Werte usw.). Darüber hinaus werden separate Statistiken für jede Variable mit einem Minimum und einem Maximum, einem Verteilungsdiagramm und anderen Parametern angegeben.
Wie Sie wissen, müssen Sie sich mit dem Prozess, den wir simulieren möchten, befassen, um ein gutes Modell zu erstellen, und die wichtigsten Attribute verstehen. Darüber hinaus ist in unseren Daten nicht immer alles enthalten, was benötigt wird, und genauer gesagt, fast nie ist in ihnen alles Notwendige enthalten, was unseren Prozess vollständig bestimmt und bestimmt. In der Regel müssen wir immer etwas kombinieren und möglicherweise zusätzliche Funktionen hinzufügen, die nicht im Datensatz enthalten sind (z. B. die Wettervorhersage). Um den Prozess zu verstehen, benötigen wir eine Datenanalyse, die mithilfe der Profilbibliothek durchgeführt werden kann.
Fehlende WerteDer nächste Schritt besteht darin, das Problem fehlender Werte zu lösen, da die Daten in den meisten Fällen nicht vollständig gefüllt sind.
Für dieses Problem stehen folgende Lösungen zur Verfügung:
- Löschen Sie Zeilen mit fehlenden Werten (denken Sie daran, dass Sie einige wichtige Werte verlieren können).
- ein Zeichen löschen (relevant, wenn zu wenig Daten darauf sind);
- Ersetzen Sie fehlende Werte durch etwas anderes (Median, Durchschnitt ...).
Ein Beispiel für eine einfache Konvertierung mit der Fillna-Methode, bei der die Werte der Medianvariablen nur den nicht gefüllten Zellen zugewiesen werden:

Darüber hinaus zeigte der Lehrer Beispiele für die Verwendung von Imputer und Pipeline.
Feature-SkalierungDie Funktionsweise des Modells und die endgültige Entscheidung hängen von der Größe der Merkmale ab. Tatsache ist, dass es nicht so ist, dass ein Merkmal mit einem größeren Maßstab wichtiger ist als ein Merkmal mit einem kleineren Maßstab. Aus diesem Grund muss das Modell Features senden, die identisch skaliert sind, dh das gleiche Gewicht für das Modell haben.
Es gibt verschiedene Skalierungstechniken. Aufgrund des Formats der offenen Lektion konnten wir jedoch nur zwei davon genauer betrachten:
 Merkmalskombinationen
MerkmalskombinationenDurch die Kombination vorhandener Features mithilfe von arithmetischen Operationen (Summe, Multiplikation, Division) können Sie jedes Feature erhalten, das das Modell effizienter macht. Dies ist nicht immer erfolgreich, und wir wissen nicht, welche Kombination den gewünschten Effekt erzielt, aber die Praxis zeigt, dass es sinnvoll ist, es zu versuchen. Es ist praktisch, Feature-Transformationen mithilfe der Pipeline anzuwenden.
CodierungWir haben also Daten verschiedener Typen: numerisch und Text. Derzeit können die meisten Modelle auf dem Markt nicht mit Textdaten arbeiten. Infolgedessen müssen alle kategorialen Zeichen (Textzeichen) in eine numerische Darstellung konvertiert werden, für die die Codierung verwendet wird.
Etikettencodierung . Dies ist ein Mechanismus, der im Rahmen vieler Bibliotheken implementiert ist und aufgerufen und angewendet werden kann:

Die Etikettencodierung weist jedem eindeutigen Wert eine eindeutige Kennung zu. Minus - wir führen die Reihenfolge in eine bestimmte Variable ein, die nicht geordnet wurde, was nicht gut ist.
OneHotEncoder. Die eindeutigen Werte der Textvariablen werden in Form von Spalten erweitert, die zu den Quelldaten hinzugefügt werden, wobei jede Spalte eine binäre Variable in Form von 0 und 1 ist. Dieser Ansatz ist frei von Fehlern bei der Etikettencodierung, hat jedoch das Minus: Wenn viele eindeutige Werte vorhanden sind, fügen wir zu viele Spalten hinzu und in einigen Fällen ist die Methode einfach nicht anwendbar (der Datensatz wächst zu stark).
ModelltrainingNach dem Ausführen der obigen Schritte wird eine endgültige Pipeline mit einer Reihe aller erforderlichen Operationen kompiliert. Jetzt reicht es aus, den Quelldatensatz zu nehmen und die resultierende Pipeline mithilfe der Operation fit_transform auf diese Daten anzuwenden:
x_train = vec.fit_transform(df_train)Als Ergebnis erhalten wir den x_train-Datensatz, der für die Verwendung im Modell bereit ist. Das einzige, was Sie tun müssen, ist, den Wert unserer Zielvariablen zu trennen, damit wir das Training durchführen können.
Wählen Sie als nächstes das Modell aus. Im Rahmen des Webinars schlug der Lehrer eine einfache logistische Regression vor. Das Modell wurde unter Verwendung der Anpassungsoperation trainiert, was zu einem Modell in Form einer logistischen Regression mit bestimmten Parametern führte:
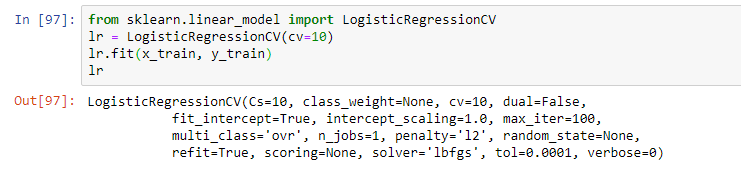
In der Praxis werden jedoch normalerweise mehrere Modelle verwendet, die am effektivsten zu sein scheinen. Die endgültige Lösung ist häufig eine Kombination dieser Modelle unter Verwendung von Stapeltechniken und anderen Ansätzen für Ensemble-Modelle (unter Verwendung mehrerer Modelle innerhalb desselben Hybridmodells).
Nach dem Training kann das Modell auf Testdaten angewendet werden, wobei die Qualität im Rahmen einer bestimmten Metrik bewertet wird. In unserem Fall betrug die Qualität innerhalb des Genauigkeitscores 0,8:

Dies bedeutet, dass anhand der erhaltenen Daten die Variable in 80% der Fälle korrekt vorhergesagt wird. Nachdem wir die Trainingsergebnisse erhalten haben, können wir entweder das Modell verbessern (wenn die Genauigkeit nicht zufriedenstellend ist) oder direkt mit der Prognose fortfahren.
Dies war das Hauptthema des Unterrichts, aber der Lehrer sprach in verschiedenen Aufgaben ausführlicher über die Merkmale des Modells und beantwortete Fragen des Publikums. Wenn Sie also nichts verpassen möchten, sehen Sie sich das vollständige Webinar an, wenn Sie an diesem Thema interessiert sind.
Wie immer warten wir auf Ihre Kommentare und Fragen, die Sie hier hinterlassen oder
Alexander stellen können, indem Sie an einem
Tag der offenen Tür zu ihm gehen
.