Lassen Sie uns einen Prototyp des Verstärkungslernagenten (RL) erstellen, der die Handelsfähigkeiten beherrscht.
Da die Implementierung des Prototyps in der R-Sprache funktioniert, ermutige ich R-Benutzer und Programmierer, sich den in diesem Artikel vorgestellten Ideen anzunähern.
Dies ist eine Übersetzung meines englischen Artikels:
Kann Reinforcement Learning Trade Stock? Implementierung in R.Ich möchte die Codejäger warnen, dass es in dieser Notiz nur einen Code für ein neuronales Netzwerk gibt, das für R angepasst ist.Wenn ich mich nicht in gutem Russisch auszeichnete, weisen Sie auf die Fehler hin (der Text wurde mit Hilfe eines automatischen Übersetzers erstellt).
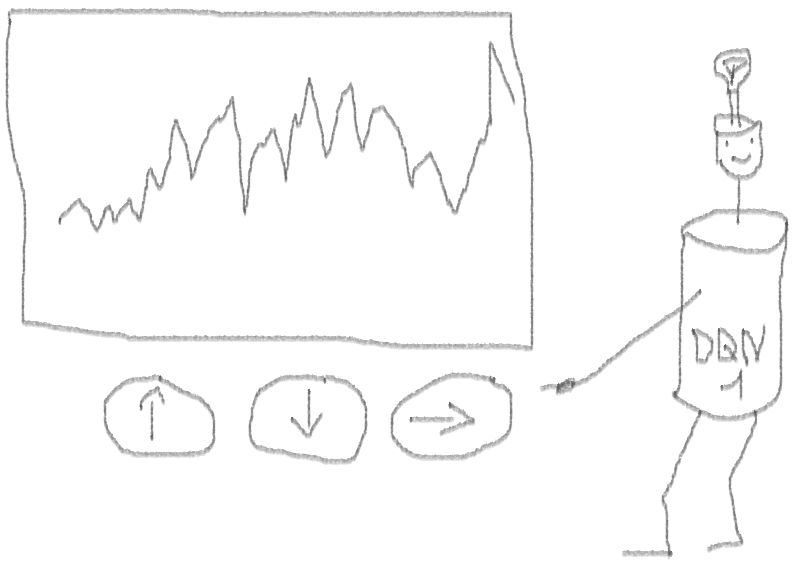
Einführung in das Problem
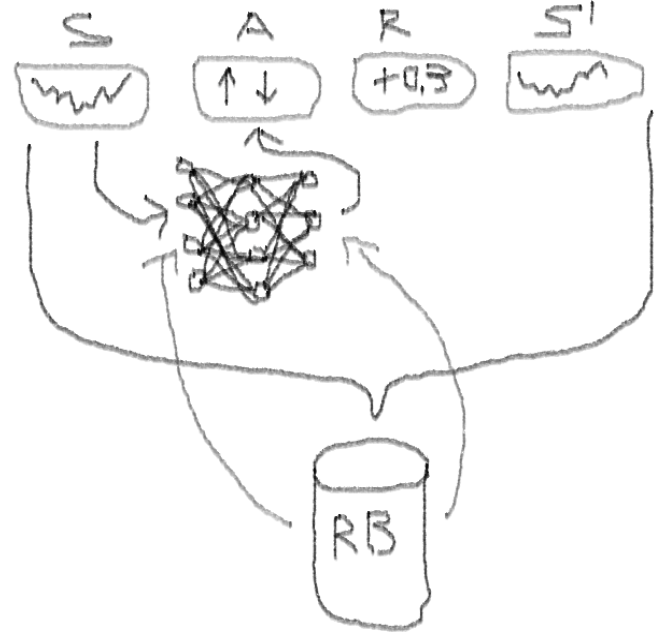
Ich rate Ihnen, mit diesem Artikel in das Thema
einzutauchen :
DeepMindEs führt Sie in die Idee ein, das Deep Q-Network (DQN) zu verwenden, um eine Wertefunktion zu approximieren, die für Markov-Entscheidungsprozesse von entscheidender Bedeutung ist.
Ich empfehle auch, mit dem Vorabdruck dieses Buches von Richard S. Sutton und Andrew J. Barto:
Reinforcement Learning tiefer in die Mathematik
einzusteigenIm Folgenden werde ich eine erweiterte Version des ursprünglichen DQN vorstellen, die weitere Ideen enthält, die dem Algorithmus helfen, schnell und effizient zu konvergieren, nämlich:
Deep Double Dueling Noisy NN mit Prioritätsauswahl aus dem Erfahrungswiedergabepuffer.
Was macht diesen Ansatz besser als klassisches DQN?
- Double: Es gibt zwei Netzwerke, von denen eines trainiert ist und das andere die folgenden Werte von Q auswertet
- Duell: Es gibt Neuronen, die eindeutig Wert legen und davon profitieren
- Rauschen: Auf die Gewichte der Zwischenschichten werden Rauschmatrizen angewendet, bei denen der Mittelwert und die Standardabweichung trainierte Gewichte sind
- Priorität der Probenahme: Beobachtungsstapel aus dem Wiedergabepuffer enthalten Beispiele, aufgrund derer das vorherige Training der Funktionen zu großen Rückständen führte, die im Hilfsarray gespeichert werden können.
Was ist mit dem Handel des DQN-Agenten? Dies ist ein interessantes Thema als solches.
Es gibt Gründe, warum dies interessant ist:
- Absolute Wahlfreiheit bei der Darstellung von Status, Aktionen, Auszeichnungen und Architektur von NN. Sie können den Einstiegsbereich mit allem bereichern, was Sie für einen Versuch wert halten, von Nachrichten bis zu anderen Aktien und Indizes.
- Die Entsprechung der Handelslogik mit der Verstärkungslernlogik besteht darin, dass: der Agent diskrete (oder kontinuierliche) Aktionen ausführt, selten belohnt wird (nachdem die Transaktion abgeschlossen wurde oder der Zeitraum abläuft), die Umgebung teilweise beobachtbar ist und Informationen über die nächsten Schritte enthalten kann. Der Handel ist ein episodisches Spiel.
- Sie können DQN-Ergebnisse mit verschiedenen Benchmarks vergleichen, z. B. mit Indizes und technischen Handelssystemen.
- Der Agent kann ständig neue Informationen lernen und sich so an die sich ändernden Spielregeln anpassen.
Um das Material nicht zu dehnen, schauen Sie sich den Code dieses NN an, den ich teilen möchte, da dies einer der mysteriösen Teile des gesamten Projekts ist.
R-Code für ein neuronales Wertnetzwerk, das Keras zum Erstellen unseres RL-Agenten verwendet
Ich habe diese Quelle verwendet, um Python-Code für den Rauschteil des Netzwerks
anzupassen :
Github RepoDieses neuronale Netzwerk sieht folgendermaßen aus:
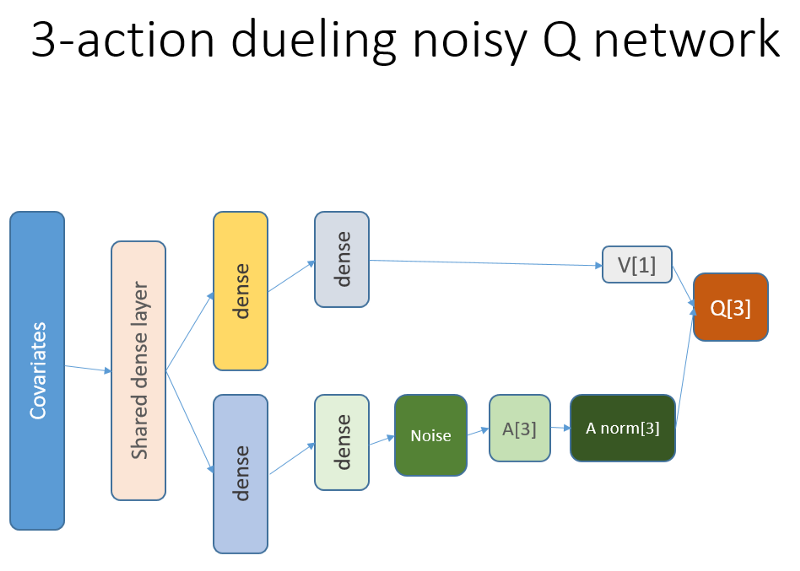
Denken Sie daran, dass wir in der Duellarchitektur Gleichheit verwenden (Gleichung 1):
Q = A '+ V, wobei
A '= A - Durchschnitt (A);
Q = Wert der Zustandsaktion;
V = Zustandswert;
A = Vorteil.
Andere Variablen im Code sprechen für sich. Darüber hinaus eignet sich diese Architektur nur für eine bestimmte Aufgabe. Nehmen Sie sie daher nicht als selbstverständlich an.
Der Rest des Codes wird höchstwahrscheinlich allgemein genug für die Veröffentlichung sein, und es wird für den Programmierer interessant sein, ihn selbst zu schreiben.
Und jetzt - die Experimente. Das Testen der Arbeit des Agenten wurde in einem Sandkasten mit einem echten Makler durchgeführt, weit entfernt von den Realitäten des Handels auf einem Live-Markt.
Phase I.
Wir führen unseren Agenten gegen einen synthetischen Datensatz aus. Unsere Transaktionskosten betragen 0,5:
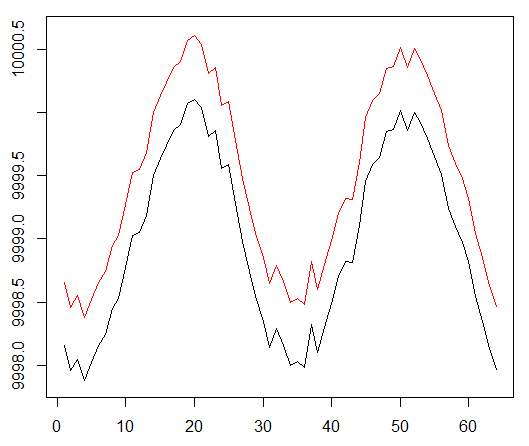
Das Ergebnis ist ausgezeichnet. Die maximale durchschnittliche episodische Belohnung in diesem Experiment
sollte 1,5 sein.
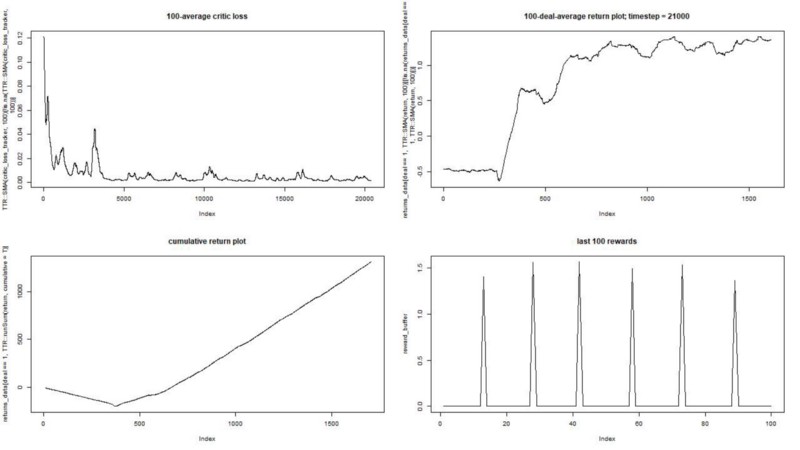
Wir sehen: Verlust der Kritik (das sogenannte Wertnetzwerk im Schauspieler-Kritiker-Ansatz), durchschnittliche Belohnung für eine Episode, akkumulierte Belohnung, Stichprobe der jüngsten Belohnungen.
Phase II
Wir bringen unserem Agenten ein willkürlich ausgewähltes Aktiensymbol bei, das ein interessantes Verhalten zeigt: einen flachen Start, ein schnelles Wachstum in der Mitte und ein trostloses Ende. In unserem Trainingskit ca. 4300 Tage. Die Transaktionskosten betragen 0,1 US-Dollar (absichtlich niedrig). Die Belohnung ist USD Gewinn / Verlust nach Abschluss eines Geschäfts zum Kauf / Verkauf von 1,0 Aktien.
Quelle:
Finance.yahoo.com/quote/algn?ltr=1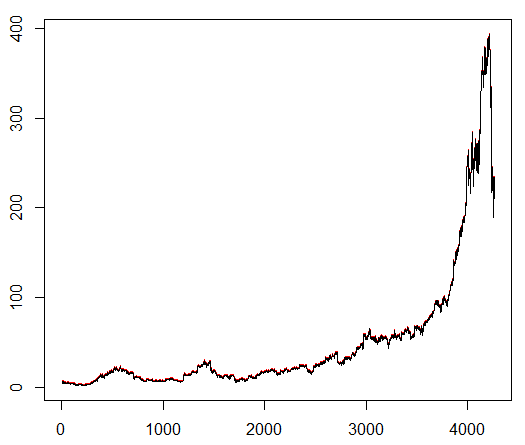 NASDAQ: ALGN
NASDAQ: ALGNNachdem wir einige Parameter eingestellt hatten (wobei die NN-Architektur unverändert blieb), kamen wir zu folgendem Ergebnis:

Es stellte sich als nicht schlecht heraus, da der Agent am Ende lernte, durch Drücken von drei Tasten auf seiner Konsole Gewinn zu machen.
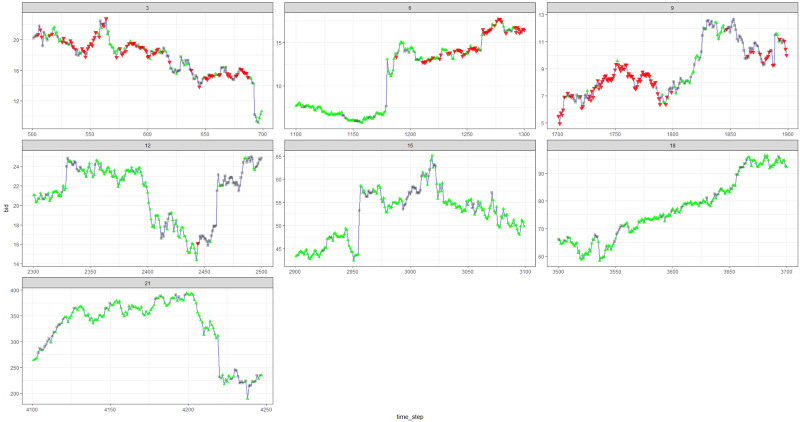 roter Marker = verkaufen, grüner Marker = kaufen, grauer Marker = nichts tun.
roter Marker = verkaufen, grüner Marker = kaufen, grauer Marker = nichts tun.Bitte beachten Sie, dass die durchschnittliche Belohnung pro Episode auf ihrem Höhepunkt den realistischen Transaktionswert überstieg, der im realen Handel auftreten kann.
Es ist schade, dass Aktien aufgrund schlechter Nachrichten wie verrückt fallen ...
Schlussbemerkungen
Der Handel mit RL ist nicht nur schwierig, sondern auch nützlich. Wenn Ihr Roboter es besser macht als Sie, ist es Zeit, Ihre persönliche Zeit zu verbringen, um Bildung und Gesundheit zu erlangen.
Ich hoffe das war eine interessante Reise für dich. Wenn Ihnen diese Geschichte gefallen hat, winken Sie mit der Hand. Wenn großes Interesse besteht, kann ich fortfahren und Ihnen zeigen, wie die Richtlinienverlaufsmethoden unter Verwendung der R-Sprache und der Keras-API funktionieren.
Ich möchte auch meinen Freunden, die sich für neuronale Netze interessieren, für ihren Rat danken.
Wenn Sie noch Fragen haben, bin ich immer hier.