Mathe-Trolling ist das, worüber ich sprechen werde. Dies sind keine modischen Hacker-Tricks, sondern ein künstlerischer Ausdruck, eine lustige, intelligente Technologie, mit der die Leute Sie als Idioten betrachten. Jetzt werde ich prüfen, ob mein Bericht bereit ist, auf dem Bildschirm angezeigt zu werden. Alles scheint gut zu laufen, also kann ich mich vorstellen.

Mein Name ist Frank Tu, buchstabiert frank ^ 2 und @franksquared auf Twitter, weil Twitter auch eine Art Spammer namens "frank 2" hat. Ich habe versucht, Social Engineering auf sie anzuwenden, damit sie sein Konto löschen, da es sich technisch gesehen um Spam handelt und ich das Recht habe, es als meinen Klon loszuwerden. Aber anscheinend, wenn Sie sie ehrlich behandeln, erwidern sie nichts, denn trotz meiner Bitte, das Spammer-Konto zu löschen, haben sie nichts damit gemacht, also habe ich dieses verdammte Twitter zur Hölle geschickt.
Viele Leute erkennen mich an meiner Mütze. Ich arbeite in den regionalen Gruppen DefCon DC949 und DC310. Ich arbeite auch mit Rapid7, aber ich kann hier nicht darüber sprechen, ohne schlechte Sprache zu verwenden, und mein Manager möchte nicht, dass ich schwöre. Daher habe ich diese Präsentation für DefCon vorbereitet und werde die Frist von 15 Minuten einhalten, obwohl dies ein ziemlich kompliziertes Thema ist. Dies ist im Wesentlichen eine Standardpräsentation, die sich auf Reverse Engineering und verwandte lustige Dinge konzentriert.
Bei der Diskussion dieses Themas auf Twitter bildeten sich zwei Lager. Einer sagte: "Ich habe keine Ahnung, wovon dieser verdammte Frank ^ 2 spricht, aber es ist großartig!" Der zweite Reddit-Typ sah meine Folien und war verärgert über Links zu Dingen, die nicht mit dem Thema zu tun hatten. Ich wurde wütend, dass ein so ernstes Thema nicht vollständig behandelt wurde, und wünschte mir, meine Präsentation hätte „mehr Inhalt und weniger Müll“.

Deshalb möchte ich mich auf dieses Zitat konzentrieren. Nichts Persönliches, Alter von Reddit - ich sage das nicht nur für den Fall, dass er in diesem Raum anwesend ist, sondern auch, weil es faire Kritik war. Weil eine Konversation, die nicht genügend nützliche Inhalte enthält, eine leere Konversation ist.
Das Thema meines Gesprächs ist eine Standardroutine für Hacker, aber es scheint mir, dass die Redner normalerweise nicht versuchen, ihre Informationen auf unterhaltsame Weise zu präsentieren, selbst wenn dies möglich ist, und trockene, entmannte Schlussfolgerungen bevorzugen. "Hier ist IP, hier ist ESP, hier ist, wie Sie einen Exploit durchführen können, hier ist mein" Zero Day ", jetzt klatschen!" - und jeder klatscht in die Hände.
Danke für den Applaus, ich weiß das zu schätzen! Es scheint mir, dass mein Material viele interessante Punkte enthält, daher verdient es, auf unterhaltsame Weise erwähnt zu werden, was ich versuchen werde.
Sie werden eine außergewöhnlich oberflächliche Einstellung zur Informatik und einen völlig kindischen Humor sehen. Ich hoffe, Sie wissen zu schätzen, was ich hier zeigen werde. Es tut mir leid, wenn Sie hierher gekommen sind, um ein ernstes Gespräch zu suchen.
Auf der Folie sehen Sie eine wissenschaftliche Analyse meines letzten Berichts, in der der Anteil eines streng wissenschaftlichen Ansatzes und der Anteil eines „Arzneimittels“, das Computersicherheit bietet, verglichen werden.

Sie sehen, dass es viel mehr „Drogen“ gibt, aber Sie müssen sich keine Sorgen machen, jetzt hat der Anteil der Wissenschaft leicht zugenommen.

Vor einiger Zeit schrieb mein Freund Merlin, der hier an vorderster Front saß, einen erstaunlichen Bot, der auf dem IRC-Python-Skript basiert und nur eine Zeile belegt.
Dies ist eine wirklich großartige Übung zum Erlernen der funktionalen Programmierung, mit der es wirklich Spaß macht, sich zu beschäftigen. Sie können einfach eine Funktion nach der anderen hinzufügen und Kombinationen aller möglichen Funktionen erhalten. All dies wird als Regenbogenwelle auf dem Bildschirm angezeigt. Im Allgemeinen ist dies eines der dümmsten Dinge, die Sie tun können.
Ich dachte, wenn Sie dieses Prinzip auf Binärdateien anwenden? Ich weiß nicht, woher diese Idee kam, aber sie hat sich als großartig herausgestellt! Ich möchte jedoch einige grundlegende Konzepte klarstellen.
Möglicherweise hat Ihr Mathematiklehrer diese Funktionen viel komplizierter dargestellt als sie wirklich sind.

Die Formel f (x) hat also eine sehr einfache Bedeutung und funktioniert wie gewöhnliche Funktionen. Sie haben X, Sie haben Eingaben und dann erhalten Sie X 7-mal, und das entspricht Ihrem Wert. In Python können Sie eine Funktion erstellen (Lambda x: x * 7). Wenn Sie mit Java arbeiten möchten - es tut mir leid, ich hoffe, Sie möchten dies nie tun -, können Sie Folgendes tun:
public static int multiplyBySevenAndReturn(Integer x) { return x * 7; }
Sie wissen, mathematische Funktionen können sogar viel komplizierter sein, aber das ist alles, was wir im Moment über sie wissen müssen.
Wenn Sie sich die Code-Assembly ansehen, werden Sie feststellen, dass die Anweisungen JMP und CALL nicht an bestimmte Werte gebunden sind, sondern mit einem Offset arbeiten. Wenn Sie einen Debugger verwenden, sehen Sie, dass der JMP00401000 eher einem Befehl zum Weiterleiten von Bytes als einem bestimmten Befehl zum Springen zu 5 oder 10 Bytes ähnelt. Gleiches gilt für die CALL-Funktion, mit der Ausnahme, dass eine ganze Reihe von Dingen auf Ihren Stapel geschoben werden. Die Ausnahme ist der Fall, wenn Sie die Adresse an das Register „kleben“, dh auf eine bestimmte Adresse zugreifen. Hier passiert alles ganz anders. Nachdem Sie die Adresse in das Register eingebunden und so etwas wie CALL EAX ausgeführt haben, greift die Funktion auf den spezifischen Wert in EAX zu. Das gleiche gilt für CALL [EAX] oder JMP [EAX] - es dereferenziert nur EAX und geht zu dieser Adresse. Wenn Sie einen Debugger verwenden, können Sie möglicherweise nicht feststellen, auf welche bestimmte Adresse CALL zugreift. Dies kann ein Problem sein, daher sollten Sie sich dessen bewusst sein.
Schauen wir uns die JMP SHORT-Kurzsprungfunktion an. Dies ist eine spezielle Anweisung in der x86-Architektur, mit der Sie einen Offset von 1 Byte anstelle eines Offsets von 4 Byte verwenden können, wodurch der verwendete Speicherplatz reduziert wird. Dies ist später für alle Manipulationen von Bedeutung, die mit einzelnen Anweisungen durchgeführt werden. Es ist wichtig zu beachten, dass JMP SHORT einen Bereich von 256 Bytes hat. Es gibt jedoch keinen CALL SHORT.

Betrachten wir nun die Hexerei der Informatik. Während der Erstellung dieser Folien wurde mir klar, dass Sie eine Baugruppe tatsächlich als Nullraum definieren können, dh technisch gesehen gibt es zwischen den einzelnen Anweisungen keinen Raum. Wenn Sie sich einzelne Anweisungen ansehen, werden Sie feststellen, dass jede Anweisung nacheinander ausgeführt wird. Technisch kann dies als bedingungsloser Sprung zum nächsten Befehl interpretiert werden. Dies gibt uns einen Abstand zwischen jeder Assemblierungsanweisung, während jede Anweisung entsprechend einem bedingungslosen Sprung zugeordnet ist.
Wenn Sie sich dieses Assembly-Beispiel ansehen, sind dies übrigens sehr einfache Dinge, die ich zum Dekodieren mit ASCII empfehle. Dies ist also nur ein Satz regulärer Anweisungen.
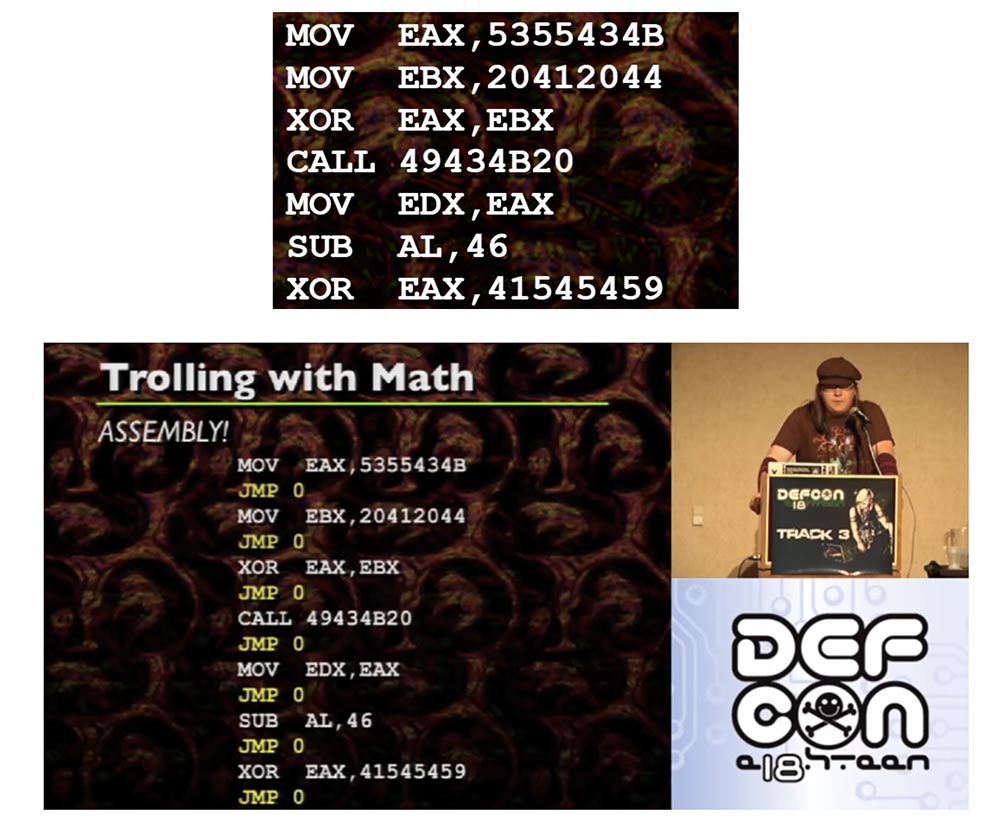
Die JMP-Nullen zwischen den einzelnen Befehlen sind bedingungslose Sprünge, die Sie normalerweise nicht sehen. Sie folgen einander nach jeder Anweisung. Daher ist es möglich, jeden einzelnen Baugruppenbefehl genau dann an einem beliebigen Speicherplatz zu platzieren, wenn jeder Einheitsbefehl von einem bedingungslosen Sprung zum nächsten Befehl begleitet wird. Denn wenn Sie die Assembly übertragen und denselben Code wie zuvor verwenden müssen, müssen Sie jeder Anweisung einen bedingungslosen Sprung hinzufügen.
Schauen wir weiter. Ein eindimensionales Array kann technisch als zweidimensionales Array interpretiert werden. Es erfordert nur ein bisschen Mathematik, Zeilen oder ähnliches, ich werde nicht sicher sagen, aber es ist nicht allzu schwierig. Dies gibt uns die Möglichkeit, den Ort im Gedächtnis in Form eines Gitters (x, y) zu interpretieren. In Kombination mit der Interpretation des leeren Raums zwischen Anweisungen als bedingungslose Sprünge, die miteinander in Beziehung gesetzt werden können, können wir Anweisungen buchstäblich zeichnen. Das ist großartig!
Um dies in die Praxis umzusetzen, müssen Sie folgende Schritte ausführen:
- Zerlegen Sie jede Anweisung, um herauszufinden, was der Code ist.
- Weisen Sie einen Speicherplatz zu, der viel größer als der Befehlssatz ist. Normalerweise reserviere ich 10 Mal mehr Speicher als die Codegröße.
- Bestimmen Sie für jede Anweisung f (x);
- Setzen Sie jeden Befehl auf die entsprechende (x, y) Stelle im Speicher.
- Fügen Sie der Anweisung einen bedingungslosen Sprung hinzu.
- Markieren Sie den Speicher als ausführbar und führen Sie den Code aus.
Leider stellen sich hier viele Fragen. Es ist wie mit der Schwerkraft, die nur in der Theorie funktioniert, aber in der Praxis sehen wir etwas ganz anderes. Weil in Wirklichkeit x86 Ihre JMP-Anweisungen, CALL-Anweisungen, zur Hölle sendet, verzerrt es Ihren selbstreferenziellen Code, selbstmodifizierenden Code, der Iteration verwendet.

Beginnen wir mit den JMP-Anweisungen. Da JMP-Anweisungen an einer beliebigen Stelle voreingenommen sind, zeigen sie nicht mehr auf die Stelle, an die sie Ihrer Meinung nach zeigen sollten. SHORT JMP befinden sich in einer ähnlichen Position. Durch Ihre Funktion (x, y) versehentlich platziert, zeigen sie nicht an, worauf Sie zählen. Im Gegensatz zu langen JMPs lassen sich kurze JMPs jedoch leichter reparieren, insbesondere wenn Sie mit einem eindimensionalen Array arbeiten. SHORT JMP lässt sich leicht in reguläres JMP konvertieren, aber dann müssen Sie herausfinden, wie der neue Offset geworden ist.
Die Arbeit mit registergestützten JMPs bereitet immer noch Kopfschmerzen. Da sie enge Offsets erfordern und zur Laufzeit berechnet werden können, gibt es keine einfache Möglichkeit, herauszufinden, wohin sie führen. Um jedes Register automatisch zu erkennen, müssen Sie eine Reihe von Kenntnissen aus der Kompilierungstheorie verwenden. Zur Laufzeit können Funktionszeiger, Klassenzeiger und dergleichen vorhanden sein. Richtig, wenn Sie keine zusätzliche Arbeit leisten möchten, um all dies zu tun, können Sie dies nicht tun. Die f (x) -Funktionen arbeiten in echtem Code nicht so elegant wie auf Papier. Wenn Sie es richtig machen wollen, müssen Sie viel arbeiten.
Um Klassenzeiger und ähnliches zu definieren, müssen Sie mit C und C ++ zaubern. Konvertieren Sie vor dem Speichern und während der Demontage Ihr KURZES JMP in normales JMP, da Sie sich mit Voreingenommenheit auseinandersetzen müssen. Dies ist ganz einfach.
Der Versuch, die tatsächlichen Verschiebungen zu berechnen, bereitet große Kopfschmerzen. Alle Anweisungen, die Sie finden, haben Offsets, die sich verschieben, wenn sich der Code bewegt, und sollten neu berechnet werden. Dies bedeutet, dass Sie den Anweisungen folgen müssen und wissen müssen, wohin sie sich als Ziele bewegen. Es fällt mir schwer, es Ihnen auf den Folien zu erklären, aber ein Beispiel dafür, wie dies erreicht werden kann, finden Sie auf der CD mit den Materialien dieser Konferenz.
Nachdem Sie alle Anweisungen platziert haben, ersetzen Sie die alten Offsets durch die neuen Offsets. Wenn Sie die Verschiebung nicht beschädigt haben, funktioniert alles. Nachdem Sie sich vorbereitet haben, gibt es eine echte Gelegenheit, die Idee auf höchstem Niveau umzusetzen. Dazu benötigen Sie:
- Anweisungen zerlegen;
- einen Speicherpuffer vorbereiten;
- initialisiere die verfügbaren Konstanten f (x);
- iteriere über f (x) und bestimmte Datenzeiger, nach denen dein Code geschrieben wird, während du verdammte Anweisungen verfolgst;
- Weisen Sie den entsprechenden erstellten Indizes Anweisungen zu.
- Beheben Sie alle bedingten Sprünge.
- Markieren Sie die neue Speicherpartition als ausführbar.
- Code ausführen.
Wenn Sie die Dinge an ihren Platz bringen, bekommen wir seltsame Dinge - alles wird durcheinander gebracht, Anweisungen springen in dunkle Orte der Erinnerung und all dies sieht einfach bezaubernd aus.

Hat das alles eine praktische Bedeutung oder ist es nur eine Zirkusvorstellung? Der angewendete Wert solcher Transformationen ist wie folgt. Durch Isolieren der Montageanweisungen und einiger Schritte zur Berechnung von f (x) können wir diese Montageanweisungen ohne Benutzerinteraktion an einer beliebigen Stelle im Puffer platzieren. Um die Codeausführungspfade zu verwirren, müssen Sie lediglich die Funktion und die Zeiger in einem Assembler mathematisch schreiben und sie zufällig auswählen.
Dies vereinfacht polymorphe Codierungstechniken erheblich. Anstatt jedes Mal Code zu schreiben, der Ihren Code auf eine bestimmte Weise manipuliert, können Sie eine Reihe von Funktionen schreiben, die die Position Ihres Codes zufällig bestimmen, und diese Funktionen dann als zufällig auswählen usw.
Anti-Reverse ist nicht so cool und frisch wie die Anti-Debugging-Technik.
Bei Anti-Version geht es nicht darum, wie viel Spaß es macht, die Verwendung des IDA unmöglich zu machen, und nicht darum, wie viel Sie den Computer Ihres Revers mit GNAA Last Measure-Bildern zerreißen, obwohl es verdammt viel Spaß macht. Anti-Reversal bedeutet einfach, ein Arschloch zu sein, denn wenn Sie wie das letzte Arschloch einen Reverser bekommen, einen Typen, der den Schutz verschiedener Systeme verletzt, wird er nur wütend, schickt dieses bösartige Programm in die Hölle und geht.
In der Zwischenzeit können Sie alle Ihre Bots an russische Unternehmensnetzwerke verkaufen, da Sie mit Ihrer Software alle am Reverse Engineering Beteiligten „senken“. Jeder weiß, wie man bei Google Anti-Debugging-Techniken findet, findet dort jedoch keine Lösung für Probleme, die sich aus kreativen Dingen ergeben. Die kreativsten Anti-Revolver lassen Reverter ihre Finger von der Tastatur brechen und faustgroße Löcher in den Wänden hinterlassen. Umkehrer werden vor Wut kochen, sie werden nicht verstehen, was zum Teufel Sie getan haben, weil Ihr Code alles durcheinander gebracht hat.
Dies ist eine Art Nervenspiel, eine psychologische Sache. Wenn Sie in dieser Angelegenheit kreativ sind und ein wirklich atemberaubendes Anti-Reverse erstellen, können Sie stolz darauf sein. Aber Sie wissen, dass Sie tatsächlich nur versuchen, sie von Ihrem Code wegzuschieben.
Also, was soll ich tun? Ich werde die Verschleierungsfunktionen übernehmen und sie verwirren. Dann werde ich die zweite Version der Verschleierung verschränkter Funktionen verwenden und die Verschleierung erneut anwenden. Ziehen wir also den Code. Dies ist ein Beispiel für mathematisches Trolling, das ich als Beispiel genommen habe.
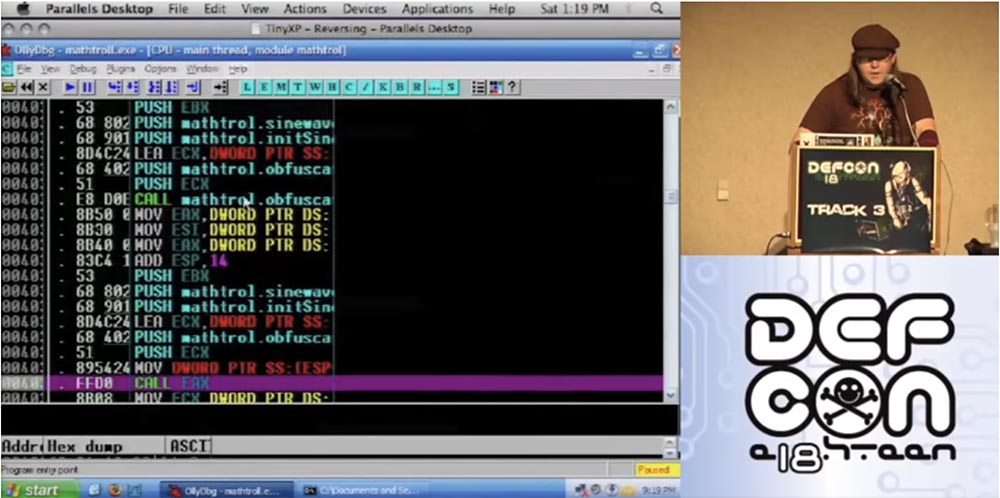
Also gebe ich den Befehl "Durch Formel verwirren" in das sich öffnende Fenster ein.
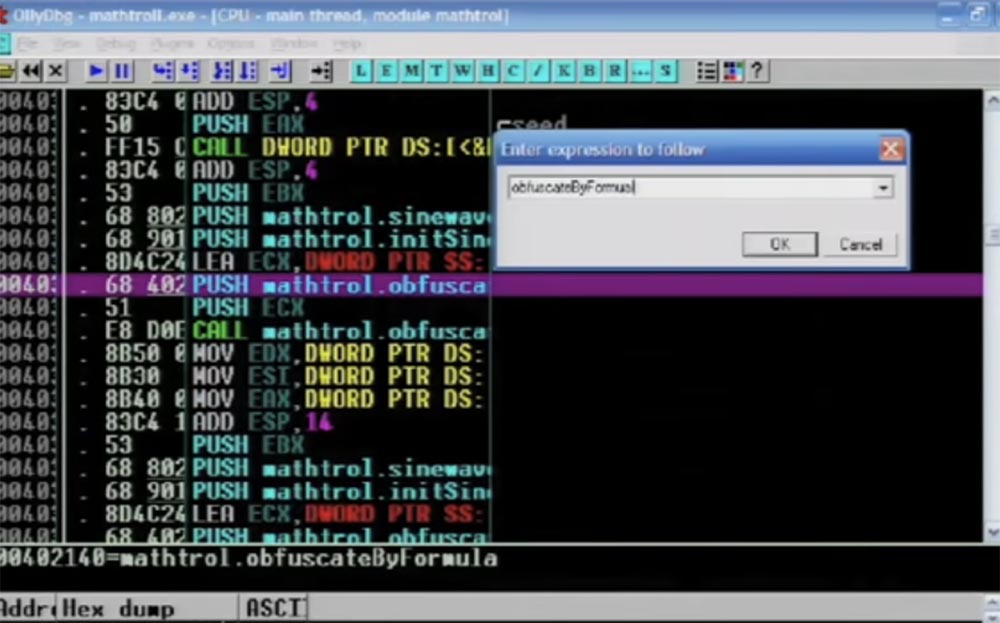
Als nächstes sehen Sie Montageanleitungen, die ihre Arbeit erledigen. Beachten Sie, dass ich hier C ++ verwende, obwohl ich bei der geringsten Gelegenheit versuche, dies zu vermeiden.
Hier wird die aktive Funktion CALL EAX hervorgehoben, dann folgt die anzuwendende Sprunganweisung, Sie sehen eine Reihe verschiedener Dinge im Puffer, und all dies wird mit jeder einzelnen Anweisung durchgeführt.

Jetzt spule ich das Programm bis zum Ende zurück und Sie werden das Ergebnis sehen. Der Code sieht also immer noch gut aus, eine Reihe von JMP-Anweisungen werden hier kompiliert, er sieht verwirrend aus und ist tatsächlich verwirrend.
Die nächste Folie zeigt eine grafische Darstellung des Stapels.

Jedes Mal, wenn dies passiert, generiere ich eine zufällige Sinuswellenformel, die eine beliebige Form hat. Sie sehen hier eine Reihe verschiedener Formen, und das ist cool. Ich denke, der Code beginnt irgendwo oben links, aber ich erinnere mich nicht genau. Also dreht er alles, man kann nicht nur Sinuskurven machen, sondern auch die Spiralen drehen.
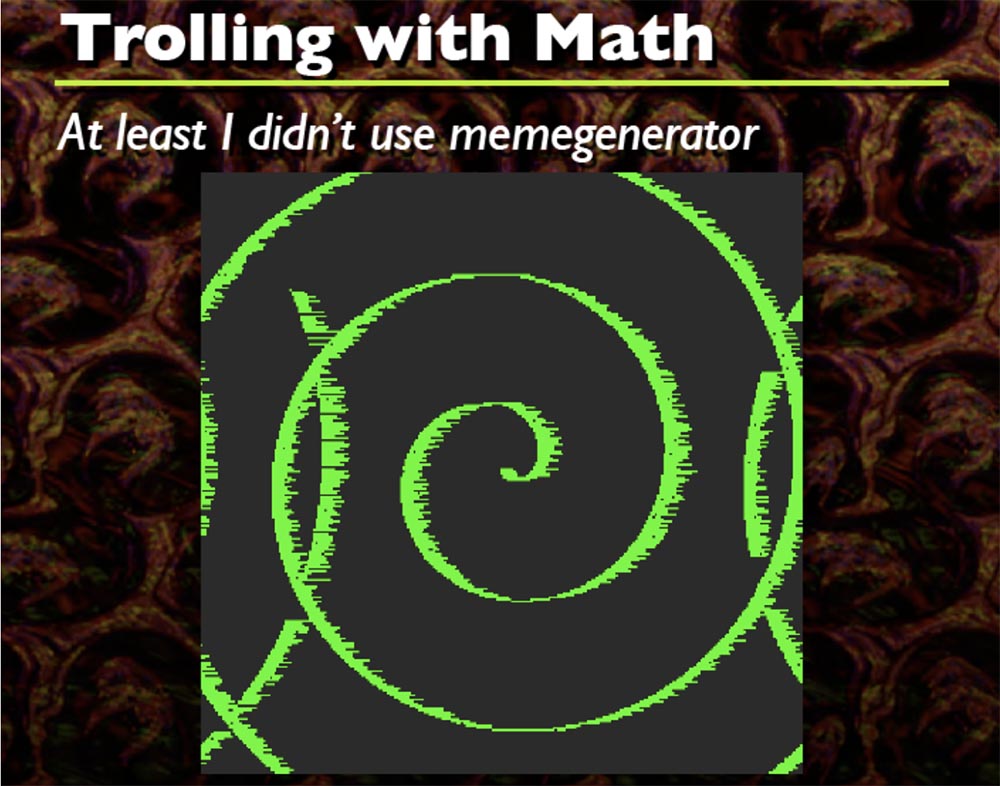
Hier funktionieren nur zwei Formeln, die ich in den Quellcode aufgenommen habe. Auf dieser Grundlage können Sie so viele kreative Dinge tun, wie Sie möchten. Im Wesentlichen ist es nur DIFF vom Startpuffer zum Endpuffer.
Das Problem ist, dass dieses Codebeispiel bedingungslose Sprünge verwendet, was eigentlich schlecht ist, da der Code genau derselbe sein sollte wie zuvor, dh bedingungslose Sprünge folgen nur einer Richtung. Daher müssen Sie auf die gleiche Weise vom Einstiegspunkt zum Ende gehen, die Sprunganweisungen entfernen und fertig - Sie haben Ihren Code! Was tun? Es ist notwendig, bedingungslose Sprünge in bedingte zu verwandeln. Bedingte Sprünge werden in zwei Richtungen gemacht, es ist viel besser, wir können sagen, dass es 50% besser ist.
Hier haben wir ein interessantes Dilemma: Wenn wir bedingte Sprünge brauchen, müssen wir immer noch bedingungslose Sprünge verwenden ... was zur Hölle? Was machen wir also? Undurchsichtige Prädikate werden uns retten! Für diejenigen, die es nicht wissen, ist ein undurchsichtiges Prädikat im Wesentlichen eine boolesche Anweisung, die unabhängig von irgendetwas immer für eine bestimmte Version ausgeführt wird.
Schauen wir uns also die Erweiterung des Nullraums an, die ich zuvor erwähnt habe. Wenn Sie über eine Reihe von Anweisungen verfügen und diese bedingungslose Sprünge und Übergänge zwischen den einzelnen Anweisungen aufweisen, kann eine Reihe von Montageanweisungen, die sich nicht direkt auf die von uns benötigten Anweisungen auswirken, einer einzelnen Anweisung vorangehen oder folgen.
Wenn Sie beispielsweise sehr spezifische Anweisungen geschrieben haben, die die Hauptbaugruppe dessen, was Sie verwirren möchten, nicht ändern, versuchen Sie, sich nicht auf die Register einzulassen, solange Sie den Status jeder Baugruppenanweisung beibehalten. Und das ist noch erstaunlicher.
Sie können jede Assembly-Anweisung berücksichtigen, die wie die Präambel, die Assembly-Daten und das Postscript verwechselt werden kann. Die Präambel ist diejenige, die der Montageanweisung vorausgeht, und das Nachskript ist diejenige, die darauf folgt. Die Präambel wird normalerweise verwendet oder kann für zwei Dinge verwendet werden:
- Korrektur der Folgen des undurchsichtigen Prädikats der vorherigen Präambel;
- Anti-Debugging von Codefragmenten.
Die Präambel ist jedoch im Wesentlichen begrenzt, da Sie nicht zu viel tun können.
Postscript ist eine lustigere Sache. Es kann verwendet werden für:
- undurchsichtige Prädikate und komplizierte Sprünge zu den folgenden Codeabschnitten;
- Anti-Debugging und Verschleierung der gesamten Codeausführung;
- Ver- und Entschlüsselung verschiedener Codefragmente im Programm selbst.
Im Moment arbeite ich an der Möglichkeit, jeden einzelnen Befehl so zu verschlüsseln und zu entschlüsseln, dass er bei Ausführung jedes Befehls den nächsten Abschnitt, den nächsten Abschnitt, den nächsten usw. entschlüsselt. Die folgende Folie zeigt ein Beispiel dafür.

Die Präambelzeilen und der Debugger-Aufruf sind grün hervorgehoben. Alles, was dieser Aufruf macht, ist zu überprüfen, ob wir einen Debugger haben, wonach wir zu einem beliebigen Abschnitt des Codes gehen.
Unten haben wir ein sehr einfaches undurchsichtiges Prädikat. Wenn Sie den Eax-Wert im Postskriptum der oberen Anweisung beibehalten, folgen Sie dem XOR-Operator, sodass Ihre JZ denkt: „OK, ich kann natürlich nach links oder rechts gehen, ich denke, es ist besser, ich gehe nach rechts, weil es 0 gibt.“ Dann wird POP EAX ausgeführt, Ihr EAX geht zurück, woraufhin der nächste Befehl verarbeitet wird und so weiter.
Dies führt offensichtlich zu viel größeren Problemen als unsere Grundstrategie, wie z. B. Resteffekte und die Komplikation der Generierung verschiedener Befehlssätze. Daher ist es sehr schwierig zu bestimmen, wie sich eine Anweisung auf eine andere Anweisung auswirkt. Sie können Hausschuhe auf mich werfen, weil ich dieses erstaunliche Programm noch nicht beendet habe, aber Sie können den Entwicklungsfortschritt in meinem Blog verfolgen.

Ich stelle fest, dass unsere Formeln f (x) nicht iterativ berechnet werden müssen, zum Beispiel f (1), f (2), ... f (n). Nichts hindert sie daran, zufällig berechnet zu werden. Wenn Sie klug sind, können Sie bestimmen, wie viele Anweisungen Sie benötigen, und dann beispielsweise f (27), f (54), f (9) zuweisen. Dies ist der Ort, an dem Ihre Anweisung zufällig platziert wird. Wenn Sie dies tun, können Sie den Code abhängig davon, wie Sie ihn geschrieben haben, im Voraus stoppen, und der Code bindet Ihre Anweisungen weiterhin nach dem Zufallsprinzip.
Wenn Ihr Code auf der Grundlage einer vorhersehbaren Formel generiert wird, ist der Einstiegspunkt auch vorhersehbar. Sie können also eine Ebene weiter gehen, bevor Sie den Code erhalten, und den Einstiegspunkt auf die eine oder andere Weise erheblich verwirren. Nehmen Sie zum Beispiel 300 Montageanweisungen von einem einzelnen Einstiegspunkt.
Lassen Sie uns nun über die Mängel sprechen.

Diese Methode erfordert eine sorgfältige Kompilierung des Codes, hauptsächlich mit GCC oder, Gott bewahre, mit C ++. C ++ ist aus mehreren Gründen eine ziemlich coole Sprache, aber Sie wissen, dass alle Compiler scheiße sind. Die Hauptsache in dieser Angelegenheit ist also eine kompetente handgemachte Zusammenstellung, denn wenn Ihr Versuch, Ihre eigene Versammlung zu verwirren, die Zustimmung der Bande hervorruft, die den Conficker-Wurm erfunden hat, haben Sie es vermasselt.
Sie benötigen viel Speicher. Denken Sie an das Bild mit Sinuswellen. Rot ist der Code und Blau ist der Speicher, der erforderlich ist, damit er funktioniert, und es sollte ausreichen, damit alles so funktioniert, wie es sollte.
Sie werden wahrscheinlich mit einem riesigen Datensatz zu tun haben, nachdem Sie den Code vervollständigt haben. Und es wird erheblich zunehmen, wenn Sie mehr als eine Funktion verwechseln möchten.
Funktionszeiger verhalten sich unvorhersehbar - manchmal richtig, manchmal nicht. Dies hängt davon ab, was Sie tun, und es wird definitiv ein Problem geben, da Sie nicht vorhersagen können, wo und wann der Funktionszeiger in Ihrer Assembly ausgelöst wird.
Je schwieriger Sie eine Verschleierung erzeugen und die Assembly in der Präambel und im Postscript bearbeiten, desto schwieriger ist es, sie zu reparieren und zu debuggen. Das Schreiben eines solchen Codes ist also wie ein Gleichgewicht zwischen "Okay, ich füge hier sorgfältig ein oder zwei JMPs ein" und "Wie zum Teufel kann ich das alles in kurzer Zeit herausfinden"? Sie müssen also nur Anweisungen einfügen und dann einige Monate lang herausfinden, was Sie getan haben.
Ich hoffe, Sie haben heute etwas Nützliches gelernt. Meiner Meinung nach habe ich mich wirklich betrunken und verstehe daher nicht wirklich, was jetzt passiert ist. Die nächste Folie zeigt meine Twitter-Kontakte, meinen Blog und meine Website. Besuchen Sie mich oder schreiben Sie.

Das ist alles, danke fürs Kommen!
Vielen Dank für Ihren Aufenthalt bei uns. Gefällt dir unser Artikel? Möchten Sie weitere interessante Materialien sehen? Unterstützen Sie uns, indem Sie eine Bestellung
aufgeben oder Ihren Freunden empfehlen, einen
Rabatt von 30% für Habr-Benutzer auf ein einzigartiges Analogon von Einstiegsservern, das wir für Sie erfunden haben: Die ganze Wahrheit über VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s von $ 20 oder wie teilt man den Server? (Optionen sind mit RAID1 und RAID10, bis zu 24 Kernen und bis zu 40 GB DDR4 verfügbar).
VPS (KVM) E5-2650 v4 (6 Kerne) 10 GB DDR4 240 GB SSD 1 Gbit / s bis Januar kostenlos, wenn Sie für einen Zeitraum von sechs Monaten bezahlen, können Sie
hier bestellen.
Dell R730xd 2 mal günstiger? Nur wir haben
2 x Intel Dodeca-Core Xeon E5-2650v4 128 GB DDR4 6 x 480 GB SSD 1 Gbit / s 100 TV von 249 US-Dollar in den Niederlanden und den USA! Lesen Sie mehr über
den Aufbau eines Infrastrukturgebäudes. Klasse mit Dell R730xd E5-2650 v4 Servern für 9.000 Euro für einen Cent?