Vor kurzem wurde die Webentwicklung geteilt. Jetzt sind wir nicht alle Full-Stack-Programmierer - wir sind Front-End und Back-End. Und das Schwierigste daran ist, wie auch anderswo, das Problem der Interaktion und Integration.
Das Frontend mit dem Backend interagieren über die API. Das gesamte Entwicklungsergebnis hängt davon ab, um welche API es sich handelt, wie gut oder schlecht sich Backend und Frontend einig sind. Wenn wir alle gemeinsam darüber diskutieren, wie das Upgrade durchgeführt werden soll, und den ganzen Tag damit verbringen, es zu überarbeiten, kommen wir möglicherweise nicht zu den Geschäftsaufgaben.
Um keine Holivars über die Namen von Variablen zu schleudern und zu züchten, benötigen Sie eine gute Spezifikation. Sprechen wir darüber, wie es sein sollte, allen das Leben zu erleichtern. Gleichzeitig werden wir Experten für Fahrradschuppen.

Beginnen wir von weitem - mit dem Problem, das wir lösen.
Vor langer Zeit, im Jahr 1959, hat
Cyril Parkinson (nicht zu verwechseln mit der Krankheit, er ist Schriftsteller und eine Wirtschaftsfigur) mehrere interessante Gesetze ausgearbeitet. Zum Beispiel wachsen diese Ausgaben mit dem Einkommen usw. Eines davon heißt Gesetz der Trivialität:
Die Zeit, die für die Erörterung des Artikels aufgewendet wird, ist umgekehrt proportional zum betrachteten Betrag.
Parkinson war ein Ökonom, also erklärte er seine Gesetze in wirtschaftlicher Hinsicht, so ähnlich. Wenn Sie in den Verwaltungsrat kommen und sagen, dass Sie 10 Millionen US-Dollar für den Bau eines Kernkraftwerks benötigen, wird dieses Problem höchstwahrscheinlich viel weniger diskutiert als die Zuweisung von 100 Pfund für einen Fahrradschuppen für Mitarbeiter. Weil jeder weiß, wie man einen Fahrradschuppen baut, jeder seine eigene Meinung hat, jeder sich wichtig fühlt und teilnehmen möchte und das Kernkraftwerk etwas Abstraktes und Fernes ist, 10 Millionen wurden auch nie gesehen - es gibt weniger Fragen.
1999 erschien das Parkinsonsche Trivialitätsgesetz in der Programmierung, die dann aktiv weiterentwickelt wurde. In der Programmierung wurde dieses Gesetz hauptsächlich in der englischsprachigen Literatur gefunden und klang wie eine Metapher. Es wurde
der Bikeshed-Effekt genannt (der Effekt eines Fahrradschuppens), aber das Wesentliche ist dasselbe - wir sind bereit für einen Fahrradschuppen und möchten viel länger als den Bau eines Kraftwerks diskutieren.
Dieser Begriff wurde vom dänischen Entwickler Poul-Henning Kamp geprägt, der an der Erstellung von FreeBSD beteiligt war. Während des Designprozesses diskutierte das Team sehr lange darüber, wie die Schlaffunktion funktionieren sollte. Dies ist ein Zitat aus einem
Brief von Poul-Henning Kamp (Entwicklung wurde dann in E-Mail-Korrespondenz durchgeführt):
Es war ein Vorschlag, Schlaf zu machen (1) DTRT Wenn ein nicht ganzzahliges Argument gegeben wird, das dieses bestimmte Grasfeuer auslöst, werde ich nicht mehr darüber sagen, da es ein viel kleineres Element ist als eines Erwarten Sie von der Länge des Threads, und es hat bereits weit mehr Aufmerksamkeit erhalten als einige der * Probleme *, die wir hier haben.
In diesem Brief sagt er, dass es viele viel wichtigere ungelöste Probleme gibt: "Lasst uns nicht mit dem Fahrradschuppen umgehen, wir werden etwas dagegen tun und weitermachen!"
So führte Poul-Henning Kamp 1999 den Begriff Bikeshed-Effekt in die englischsprachige Literatur ein, der wie folgt umformuliert werden kann:
Die Menge an Rauschen, die durch die Änderung des Codes erzeugt wird, ist umgekehrt proportional zur Komplexität der Änderung.
Je einfacher die Hinzufügung oder Änderung ist, desto mehr Meinungen müssen wir darüber hören. Ich denke, viele haben das getroffen. Wenn wir eine einfache Frage lösen, zum Beispiel, wie man Variablen benennt, spielt es für eine Maschine keine Rolle - diese Frage verursacht eine große Anzahl von Holivars. Aber ernsthafte, wirklich wichtige für geschäftliche Probleme werden nicht diskutiert und treten in den Hintergrund.
Was ist Ihrer Meinung nach wichtiger: Wie kommunizieren wir zwischen dem Backend und dem Frontend oder den Geschäftsaufgaben, die wir erledigen? Jeder denkt anders, aber jeder Kunde, der erwartet, dass Sie ihm Geld bringen, wird sagen: "Machen Sie mir schon unsere Geschäftsaufgaben!" Es ist ihm absolut egal, wie Sie Daten zwischen dem Backend und dem Frontend übertragen. Vielleicht weiß er nicht einmal, was ein Backend und ein Frontend sind.
Um die Einführung zusammenzufassen, möchte ich sagen:
API ist ein Fahrradschuppen.PräsentationslinkÜber den Sprecher: Alexey Avdeev (
Avdeev ) arbeitet für die Firma Neuron.Digital, die sich mit Neuronen befasst und ein cooles Frontend für sie macht. Alex achtet auch auf OpenSource und berät alle. Er war lange Zeit in der Entwicklung tätig - seit 2002 fand er das alte Internet, als Computer groß waren, das Internet klein war und der Mangel an JS niemanden störte und jeder Websites auf den Tischen erstellte.
Wie gehe ich mit Fahrradschuppen um?
Nachdem der angesehene Cyril Parkinson das Gesetz der Trivialität abgeleitet hatte, wurde er viel diskutiert. Es stellt sich heraus, dass die Wirkung eines Fahrradschuppens hier leicht vermieden werden kann:
- Hören Sie nicht auf Ratschläge. Ich denke, die Idee ist mittelmäßig. Wenn Sie sich die Tipps nicht anhören, können Sie so etwas tun, insbesondere beim Programmieren und insbesondere, wenn Sie ein unerfahrener Entwickler sind.
- Mach was du willst. "Ich bin ein Künstler, ich sehe so!" - Kein Bikeshed-Effekt, alles, was Sie brauchen, ist erledigt, aber auf dem Ausgang erscheinen sehr seltsame Dinge. Dies ist häufig in freiberuflichen Tätigkeiten zu finden. Sicherlich sind Sie auf Aufgaben gestoßen, die Sie für andere Entwickler erledigen mussten und deren Implementierung Sie verwirrt hat.
- Ist es wichtig, sich zu fragen? Wenn nicht, können Sie es einfach nicht diskutieren, aber es ist eine Frage des persönlichen Bewusstseins.
- Verwenden Sie objektive Kriterien. Ich werde im Bericht über diesen Punkt sprechen. Um die Auswirkungen eines Fahrradschuppens zu vermeiden, können Sie Kriterien verwenden, die objektiv angeben, welche besser sind. Sie existieren.
- Sprechen Sie nicht darüber, was Sie nicht hören möchten. In unserem Unternehmen sind Backend-Entwickler introvertiert. Es kommt also vor, dass sie etwas tun, von dem sie anderen nichts erzählen. Infolgedessen stoßen wir auf Überraschungen. Diese Methode funktioniert, ist aber bei der Programmierung nicht die beste Option.
- Wenn Sie sich nicht für das Problem interessieren, können Sie es einfach loslassen oder eine der vorgeschlagenen Optionen auswählen , die sich im Verlauf von holivarov ergeben haben.
Anti-Bikeshedding-Tool
Ich möchte über
objektive Werkzeuge sprechen, um das Problem eines Fahrradschuppens zu lösen. Um zu demonstrieren, was ein Anti-Bikeshedding-Tool ist, erzähle ich Ihnen eine kleine Geschichte.
Stellen Sie sich vor, wir haben einen unerfahrenen Backend-Entwickler. Er kam kürzlich in die Firma und wurde angewiesen, einen kleinen Dienst zu entwerfen, zum Beispiel einen Blog, für den Sie ein REST-Protokoll schreiben müssen.
 Roy Fielding, Autor von REST
Roy Fielding, Autor von RESTAuf dem Foto verteidigte Roy Fielding, der im Jahr 2000 seine These "Architekturstile und Design von Netzwerksoftware-Architekturen" verteidigte und damit den Begriff REST einführte. Darüber hinaus hat er HTTP erfunden und ist einer der Begründer des Internets.
REST ist eine Reihe von Architekturprinzipien, die festlegen, wie REST-Protokolle, REST-APIs und RESTful-Services entworfen werden. Dies sind ziemlich abstrakte und komplexe architektonische Prinzipien. Ich bin sicher, dass keiner von Ihnen jemals eine API gesehen hat, die vollständig nach allen RESTful-Prinzipien erstellt wurde.
Anforderungen an die REST-Architektur
Ich werde einige Anforderungen für
REST- Protokolle
angeben , auf die ich mich dann beziehen und auf die ich mich verlassen werde. Es gibt ziemlich viele von ihnen, Sie können mehr darüber auf Wikipedia lesen.
1.
Das Client-Server-Modell.Das wichtigste Prinzip von REST ist unsere Interaktion mit dem Backend. Laut REST ist das Backend ein Server, das Frontend ein Client und wir kommunizieren in einem Client-Server-Format. Mobile Geräte sind auch ein Client. Entwickler für Uhren, für Kühlschränke, andere Dienstleistungen - entwickeln auch den Client-Teil. Die RESTful-API ist der Server, auf den der Client zugreift.
2.
Mangel an Zustand.Auf dem Server darf kein Status vorhanden sein, dh alles, was für eine Antwort benötigt wird, ist in der Anfrage enthalten. Wenn eine Sitzung auf dem Server gespeichert ist und je nach Sitzung unterschiedliche Antworten eingehen, verstößt dies gegen das REST-Prinzip.
3.
Einheitlichkeit der Schnittstelle.Dies ist eines der wichtigsten Grundprinzipien, auf denen die REST-API aufbauen sollte. Es enthält Folgendes:
- Mit der Ressourcenidentifikation sollten wir eine URL erstellen. Bei REST wenden wir uns an den Server, um eine Ressource zu erhalten.
- Manipulation von Ressourcen durch Präsentation. Der Server gibt uns eine Ansicht zurück, die sich von der Ansicht in der Datenbank unterscheidet. Es spielt keine Rolle, ob Sie die Informationen in MySQL oder PostgreSQL speichern - wir haben eine Ansicht.
- Selbstbeschreibende Nachrichten - das heißt, die Nachricht enthält ID, Links, über die Sie diese Nachricht erneut erhalten können - alles, was erforderlich ist, um wieder mit dieser Ressource zu arbeiten.
- Hypermedia ist eine Verknüpfung zu den folgenden Aktionen mit einer Ressource. Es scheint mir, dass keine einzige REST-API dies tut, aber es wird von Roy Fielding beschrieben.
Es gibt drei weitere Prinzipien, die ich nicht zitiere, weil sie für meine Geschichte nicht wichtig sind.
RESTful Blog
Zurück zum Anfang Backend-Entwickler, der gebeten wurde, einen Service für den Blog auf RESTful zu erstellen. Unten sehen Sie ein Beispiel für einen Prototyp.
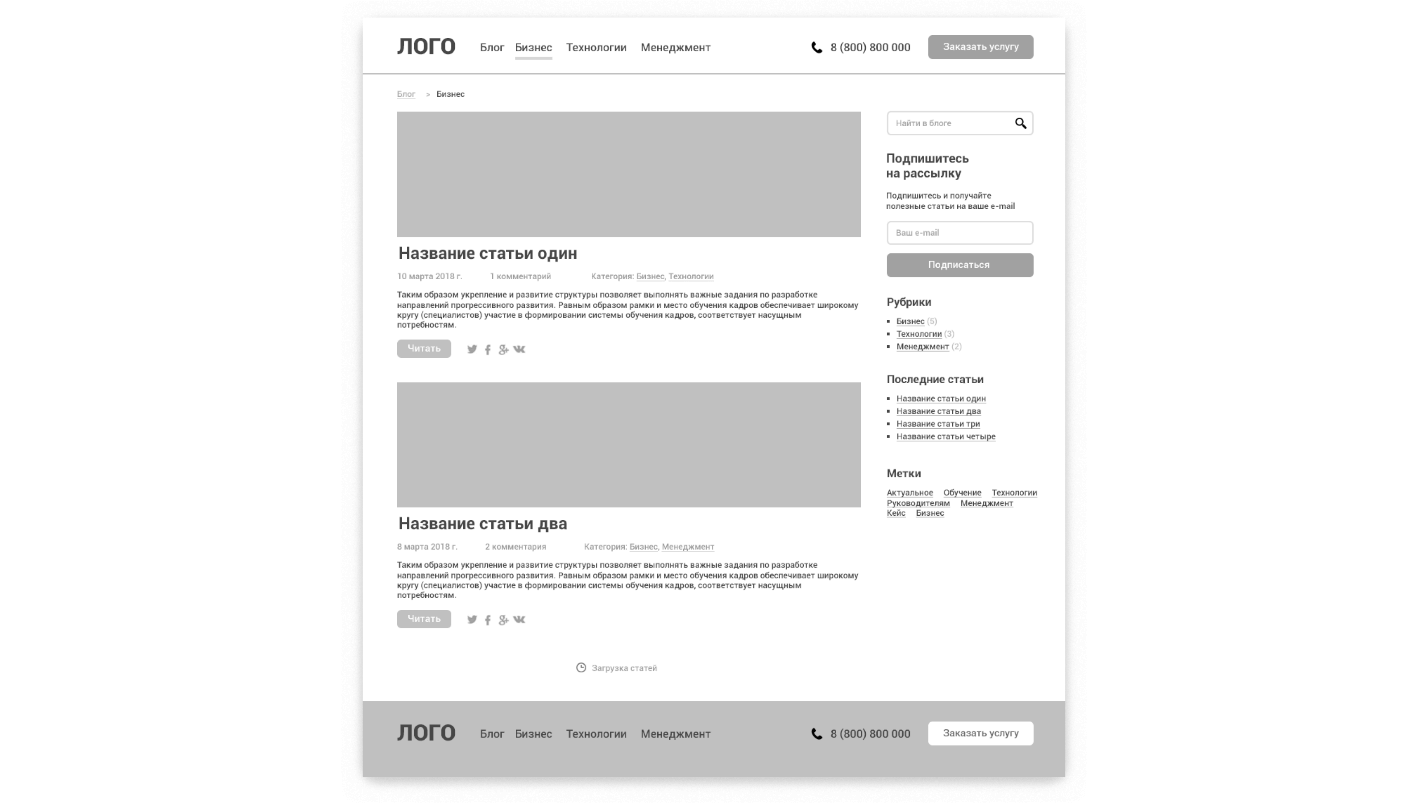
Dies ist eine Seite, auf der es Artikel gibt, die Sie kommentieren können. Der Artikel und die Kommentare haben einen Autor - eine Standardgeschichte. Unser unerfahrener Backend-Entwickler wird eine RESTful-API für diesen Blog erstellen.
Wir arbeiten mit allen Blogdaten auf Basis von
CRUD .
Es sollte möglich sein, Ressourcen zu erstellen, zu lesen, zu aktualisieren und zu löschen. Versuchen wir, unseren Backend-Entwickler zu bitten, einen RESTful-AP zu erstellen, der auf dem CRUD-Prinzip basiert. Schreiben Sie also Methoden, um Artikel zu erstellen, eine Liste von Artikeln oder einen einzelnen Artikel abzurufen, zu aktualisieren und zu löschen.
Mal sehen, wie er es schaffen konnte.
 In Bezug auf alle REST-Prinzipien ist hier alles falsch
In Bezug auf alle REST-Prinzipien ist hier alles falsch . Das Interessanteste ist, dass es funktioniert. Ich habe tatsächlich APIs, die ungefähr so aussahen. Für den Kunden ist es ein Fahrradschuppen, für Entwickler eine Gelegenheit zum Entspannen und Streiten, und für einen unerfahrenen Entwickler ist es nur eine riesige, schöne neue Welt, über die er jedes Mal stolpert, fällt und sich den Kopf zerschmettert. Er muss es immer und immer wieder wiederholen.

Dies ist eine REST-Option. Basierend auf den Prinzipien der Identifizierung von Ressourcen arbeiten wir mit Ressourcen - mit Artikeln und verwenden die von Roy Fielding vorgeschlagenen HTTP-Methoden. Er konnte nicht anders, als seine vorherige Arbeit in seiner nächsten Arbeit zu verwenden.
Um Artikel zu aktualisieren, verwenden viele die PUT-Methode, die eine etwas andere Semantik aufweist. Die PATCH-Methode aktualisiert die übergebenen Felder, und der PUT ersetzt einfach einen Artikel durch einen anderen. Durch die Semantik wird PATCH zusammengeführt und PUT ersetzt.
Unser unerfahrener Backend-Entwickler fiel, sie nahmen es auf und sagten: "Alles ist in Ordnung, mach es so", und er überarbeitete es ehrlich. Aber dann wird er einen großen langen Weg durch die Dornen finden.
Warum ist es so richtig?- weil Roy Fielding es sagte;
- weil es REST ist;
- denn das sind die architektonischen Prinzipien, auf denen unser Beruf jetzt basiert.
Dies ist jedoch ein "Fahrradschuppen", und die vorherige Methode wird funktionieren. Computer kommunizierten vor REST und alles funktionierte. Aber jetzt ist ein Standard in der Branche erschienen.
Artikel löschen
Betrachten Sie das Beispiel zum Löschen eines Artikels. Angenommen, es gibt eine normale Ressourcenmethode DELETE / articles, mit der der Artikel anhand der ID entfernt wird. HTTP enthält Header. Der Accept-Header akzeptiert den Datentyp, den der Client als Antwort erhalten möchte. Unser Junior hat einen Server geschrieben, der 200 OK, Inhaltstyp: application / json, zurückgibt und einen leeren Text übergibt:
01. DELETE /articles/ 1 /1.1
02. Accept: application/json01. HTTP/1.1 200 OK
02. Content-Type: application/json
03. null
Hier wurde ein sehr
häufiger Fehler gemacht - ein leerer Körper . Alles scheint logisch zu sein - der Artikel wurde gelöscht, 200 OK, der Anwendungs- / JSON-Header ist vorhanden, aber der Client wird höchstwahrscheinlich fallen. Es wird ein Fehler ausgegeben, da ein leerer Körper nicht gültig ist. Wenn Sie jemals versucht haben, eine leere Zeichenfolge zu analysieren, sind Sie mit der Tatsache konfrontiert, dass jeder JSON-Parser darüber stolpert und abstürzt.
Wie kann diese Situation behoben werden? Wahrscheinlich ist die beste Option, json zu übergeben. Wenn wir sagten: "Akzeptiere, gib uns json", sagt der Server: "Inhaltstyp, ich gebe dir json", gib json. Ein leeres Objekt, ein leeres Array - legen Sie etwas dort ab - dies wird die Lösung sein und es wird funktionieren.
Es gibt noch eine Lösung. Zusätzlich zu 200 OK gibt es einen Antwortcode 204 - kein Inhalt. Damit kann man den Körper nicht übertragen. Nicht jeder weiß davon.
Also habe ich zu den Medientypen geführt.
Pantomimenarten
Medientypen sind wie eine Dateierweiterung, nur im Web. Wenn wir Daten übertragen, müssen wir informieren oder anfordern, welchen Typ wir als Antwort erhalten möchten.
- Standardmäßig ist dies Text / Nur-Text.
- Wenn nichts angegeben ist, bedeutet der Browser höchstwahrscheinlich Anwendung / Oktett-Stream - nur ein Bit-Stream.
Sie können nur einen bestimmten Typ angeben:
- Anwendung / pdf;
- image / png;
- Anwendung / json;
- application / xml;
- application / vnd.ms-excel.
Content-Type- und Accept-Header sind und sind wichtig.
Die API und der Client müssen die Header Content-Type und Accept übergeben.
Wenn Ihre API auf JSON basiert, übergeben Sie immer Accept: application / json und Content-Type application / json.
Beispieldateitypen.

Medientypen ähneln diesen Dateitypen nur im Internet.
Antwortcodes
Das nächste Beispiel für die Abenteuer unseres Nachwuchsentwicklers sind die Antwortcodes.

Die lustigste Antwortrate ist 200 OK. Jeder liebt ihn - es bedeutet, dass alles richtig gelaufen ist. Ich hatte sogar einen Fall - ich habe
Fehler 200 OK erhalten . Es ist tatsächlich etwas auf den Server gefallen. Als Antwort auf die Antwort kommt eine HTML-Seite, auf der ein HTML-Fehler kompiliert wurde. Ich habe eine Anwendung json mit dem Code 200 OK angefordert und mir überlegt, wie ich damit arbeiten soll. Sie gehen nach Antwort, suchen nach dem Wort "Fehler", Sie denken, dass dies ein Fehler ist.
Dies funktioniert jedoch in HTTP. Es gibt viele andere Codes, die Sie verwenden können, und REST empfiehlt, dass Sie sie in REST verwenden. Zum Beispiel kann die Erstellung einer Entität (eines Artikels) beantwortet werden:
- 201 Erstellt ist ein erfolgreicher Code. Der Artikel wird erstellt. Als Antwort müssen Sie den erstellten Artikel zurückgeben.
- 202 Akzeptiert bedeutet, dass die Anforderung akzeptiert wurde, das Ergebnis jedoch später angezeigt wird. Dies sind lang laufende Operationen. Bei Akzeptiert kann kein Körper zurückgegeben werden. Das heißt, wenn Sie in der Antwort nicht den Inhaltstyp angeben, ist dies möglicherweise auch nicht der Fall. Oder Inhaltstyp Text / Ebene - das ist alles, keine Fragen. Eine leere Zeichenfolge ist ein gültiger Text / eine gültige Ebene.
- 204 Kein Inhalt - der Körper kann vollständig fehlen.
- 403 Verboten - Sie dürfen diesen Artikel nicht erstellen.
- 404 Nicht gefunden - Sie sind irgendwo falsch geklettert, es gibt zum Beispiel keinen solchen Weg.
- 409 Konflikt ist ein Extremfall, den nur wenige Menschen verwenden. Es ist manchmal erforderlich, wenn Sie eine ID auf dem Client und nicht im Backend generieren und zu diesem Zeitpunkt bereits jemand diesen Artikel erstellt hat. Konflikt ist in diesem Fall die richtige Antwort.
Entitätserstellung
Das folgende Beispiel: Wir erstellen eine Entität, z. B. Inhaltstyp: application / json, und übergeben diese Anwendung / json. Das macht den Kunden zu unserem Frontend. Lassen Sie uns genau diesen Artikel erstellen:
01. POST /articles /1.1
02. Content-Type: application/json
03. { "id": 1, "title": " JSON API"}Der Code kann als Antwort kommen:
- 422 Nicht verarbeitbare Entität - Eine nicht verarbeitete Entität. Alles scheint großartig zu sein - Semantik, es gibt Code;
- 403 Verboten
- 500 Interner Serverfehler.
Aber es ist absolut unverständlich, was genau passiert ist: Welche Art von Entität wird nicht verarbeitet, warum sollte ich nicht dorthin gehen und was ist schließlich mit dem Server passiert?
Fehler zurückgeben
Stellen Sie sicher, dass (und die Junioren wissen nichts davon) als Antwort Fehler zurückgeben. Das ist semantisch und richtig. Fielding hat übrigens nicht darüber geschrieben, das heißt, es wurde später erfunden und auf REST aufgebaut.
Das Backend kann ein Array mit Fehlern in der Antwort zurückgeben, es kann mehrere geben.
01. HTTP/1.1 422 Unprocessable Entity
02. Content-Type: application/json
03.
04. { "errors": [{
05. "status": "422",
06. "title": "Title already exist",
07. }]}Jeder Fehler kann einen eigenen Status und Titel haben. Das ist großartig, aber es geht bereits auf Konventionsebene über REST. Dies könnte unser Anti-Bikeshedding-Tool sein, um das Streiten zu beenden und sofort eine gute, richtige API zu erstellen.
Paginierung hinzufügen
Das folgende Beispiel: Designer kommen zu unserem ersten Backend-Entwickler und sagen: „Wir haben viele Artikel, wir brauchen Paginierung. Wir haben diesen gezeichnet. “

Betrachten wir es genauer. Zunächst fallen 336 Seiten auf. Als ich das sah, dachte ich darüber nach, wie ich diese Figur bekommen könnte. Wo bekomme ich 336, denn wenn ich eine Liste von Artikeln anfordere, bekomme ich eine Liste von Artikeln. Zum Beispiel gibt es 10 Tausend davon, das heißt, ich muss alle Artikel herunterladen, durch die Anzahl der Seiten dividieren und diese Anzahl herausfinden. Für eine sehr lange Zeit werde ich diese Artikel laden, ich brauche eine Möglichkeit, um die Anzahl der Einträge schnell zu erhalten. Wenn unsere API jedoch eine Liste zurückgibt, wo diese Anzahl von Datensätzen im Allgemeinen abgelegt werden soll, da eine Reihe von Artikeln als Antwort kommt. Es stellt sich heraus, dass die Anzahl der Datensätze, da sie nirgendwo platziert wird, zu jedem Artikel hinzugefügt werden muss, damit in jedem Artikel steht: „Und es gibt so viele von uns allen!“
Über der REST-API gibt es jedoch eine Konvention, die dieses Problem löst.
Listenanfrage
Um die API erweiterbar zu machen, können Sie sofort die GET-Parameter für die Paginierung verwenden: die Größe der aktuellen Seite und ihre Nummer, sodass genau der von uns angeforderte Teil der Seite an uns zurückgegeben wird. Das ist bequem. Als Antwort können Sie nicht sofort ein Array angeben, sondern zusätzliche Verschachtelungen hinzufügen. Beispielsweise enthält der Datenschlüssel ein Array, die von uns angeforderten Daten und der Metaschlüssel, der zuvor nicht vorhanden war, die Gesamtsumme.
01. GET /articles? page[size]=30&page[number]=2
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Auf diese Weise kann die API zusätzliche Informationen zurückgeben. Zusätzlich zum Zählen kann es einige andere Informationen geben - es ist erweiterbar. Wenn der Junior es nicht sofort tat und erst nachdem er gebeten wurde, die Pyjinisierung durchzuführen, nahm er
die rückwärts inkompatible Änderung vor , brach die API und alle Clients mussten sie wiederholen - normalerweise tut es sehr weh.
Pajinisierung ist anders. Ich biete mehrere Life-Hacks an, die Sie verwenden können.
[Offset] ... [Limit]
01. GET /articles? page[offset]=30&page[limit]=30
02. Content-Type: application/json
01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }
Diejenigen, die mit Datenbanken arbeiten, haben möglicherweise bereits einen Subkortex [Offset] ... [Limit]. Die Verwendung anstelle von Seite [Größe] ... Seite [Nummer] wird einfacher. Dies ist ein etwas anderer Ansatz.
Cursorpositionierung
01. GET /articles? page[published_at]=1538332156
02. Content-Type: application/json01. HTTP/1.1 200 OK
02. {
03. "data": [{ "id": 1, "title": "JSONAPI"}, ...],
04. "meta": { "count": 10080 }
05. }Die Cursorposition verwendet einen Zeiger auf die Entität, mit der das Laden von Datensätzen gestartet werden soll. Dies ist beispielsweise sehr praktisch, wenn Sie die Paginierung oder das Laden in Listen verwenden, die sich häufig ändern. Nehmen wir an, in unserem Blog werden ständig neue Artikel geschrieben. Die dritte Seite ist jetzt nicht dieselbe dritte Seite, die in einer Minute erstellt wird. Wenn wir jedoch zur vierten Seite wechseln, erhalten wir einige Datensätze von der dritten Seite, da sich die gesamte Liste verschiebt.
Dieses Problem wird durch Cursor-Paginierung gelöst. Wir sagen: "Laden Sie die Artikel, die nach dem zu diesem Zeitpunkt veröffentlichten Artikel kommen" - rein technologisch kann es keine Verschiebung mehr geben, und das ist cool.
Problem N +1
Das nächste Problem, auf das unser Junior-Entwickler definitiv stoßen wird, ist das N + 1-Problem (Backender werden es verstehen). Angenommen, Sie möchten eine Liste mit 10 Artikeln auflisten. Wir laden eine Liste von Artikeln hoch, jeder Artikel hat einen Autor und für jeden müssen Sie einen Autor herunterladen. Wir versenden:
- 1 Anfrage für eine Liste von Artikeln;
- 10 Anfragen für die Autoren jedes Artikels.
Insgesamt: 11 Abfragen, um eine kleine Liste anzuzeigen.
Links hinzufügen
Im Backend ist dieses Problem in allen ORMs gelöst. Sie müssen nur daran denken, diese Verbindung hinzuzufügen. Diese Verbindungen können auch am Frontend verwendet werden. Dies geschieht wie folgt:
01. GET /articles? include =author
02. Content-Type: application/json
Sie können einen speziellen GET-Parameter verwenden, ihn include nennen (wie im Backend) und angeben, welche Links wir zusammen mit den Artikeln laden müssen. Angenommen, wir laden Artikel hoch und möchten den Autor sofort mit den Artikeln zusammenbringen. Die Antwort sieht so aus:
01. /1.1 200
02. { "data": [{
03. { attributes: { "id": 1, "title": "JSON API" },
04. { relationships: {
05. "author": { "id": 1, "name": "Avdeev" } }
06. }, ...
07. }]}Eigene Artikelattribute wurden auf Daten übertragen und die Schlüsselbeziehungen hinzugefügt. Wir setzen alle Verbindungen in diesen Schlüssel. Somit haben wir mit einer Anfrage alle Daten erhalten, die zuvor 11 Anfragen erhalten haben. Dies ist ein cooler Life-Hack, der das Problem mit N + 1 am Frontend gut löst.
Das Problem der Datenvervielfältigung
Angenommen, Sie möchten 10 Artikel anzeigen, die den Autor angeben. Alle Artikel haben einen Autor, aber das Objekt mit dem Autor ist sehr groß (z. B. ein sehr langer Nachname, der ein Megabyte benötigt). Ein Autor ist 10 Mal in der Antwort enthalten, und 10 Einschlüsse desselben Autors in die Antwort benötigen 10 MB.
Da alle Objekte gleich sind, wird das Problem, dass ein Autor 10 Mal (10 MB) enthalten ist, mithilfe der Normalisierung gelöst, die in Datenbanken verwendet wird. Am Frontend können Sie auch die Normalisierung bei der Arbeit mit der API verwenden - das ist sehr cool.
01. /1.1 200
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": "JSON API" },
05. "relationships": { ... }
06. "author": { "id": 1, "type": "people" } }
07. }, ... ]
08. }Wir markieren alle Entitäten mit einem Typ (dies ist ein Darstellungstyp, ein Ressourcentyp). Roy Fielding führte das Konzept einer Ressource ein, dh sie forderten Artikel an - erhielten einen „Artikel“. In Beziehungen setzen wir einen Link zu den Typ-Personen, dh wir haben die Personen-Ressource immer noch woanders. Und die Ressource selbst nehmen wir in einem separaten Schlüssel auf, der auf der gleichen Ebene wie Daten liegt.
01. /1.1 200
02. {
03. "data": [ ... ],
04. "included": [{
05. "id": 1, "type": "people",
06. "attributes": { "name": "Avdeev" }
07. }]
08. }Somit fallen alle verbundenen Entitäten in einer einzelnen Instanz in den enthaltenen Sonderschlüssel. Wir speichern nur Links und die Entitäten selbst werden in eingeschlossen gespeichert.
Anforderungsgröße verringert. Dies ist ein Life-Hack, von dem das anfängliche Back-End nichts weiß. Er wird später herausfinden, wann er die API brechen muss.
Es werden nicht alle Ressourcenfelder benötigt
Der folgende Life-Hack kann angewendet werden, wenn nicht alle Ressourcenfelder benötigt werden. Dies erfolgt mithilfe eines speziellen GET-Parameters, der die zurückzugebenden Attribute durch Kommas getrennt auflistet. Zum Beispiel ist der Artikel groß und das Inhaltsfeld kann Megabyte enthalten. Wir müssen nur die Liste der Header anzeigen. Der Inhalt in der Antwort wird nicht benötigt.
GET /articles ?fields[article]=title /1.101. /1.1 200 OK
02. { "data": [{
03. "id": "1″, "type": "article",
04. "attributes": { "title": " JSON API" },
05. }, ... ]
06. }Wenn Sie beispielsweise auch das Veröffentlichungsdatum benötigen, können Sie ein durch Kommas getrenntes „Veröffentlichungsdatum“ schreiben. Als Antwort werden zwei Felder in Attributen angezeigt. Dies ist eine Konvention, die als Anti-Bikeshedding-Tool verwendet werden kann.
Suche nach Artikeln
Oft brauchen wir Suchen und Filter. Hierfür gibt es Konventionen - spezielle Filter GET-Parameter:
●
GET /articles ?filters[search]=api HTTP/1.1 - Suche;
●
GET /articles ?fiIters[from_date]=1538332156 HTTP/1.1 - Artikel von einem bestimmten Datum herunterladen;
●
GET /articles ?filters[is_published]=true HTTP/1.1 - Laden Sie Artikel herunter, die gerade veröffentlicht wurden.
●
GET /articles ?fiIters[author]=1 HTTP/1.1 - Artikel mit dem Erstautor herunterladen.
Artikel sortieren
●
GET /articles ?sort=title /1.1 - nach Titel;
●
GET /articles ?sort=published_at HTTP/1.1 - nach Veröffentlichungsdatum;
●
GET /articles ?sort=-published_at HTTP/1.1 - nach Veröffentlichungsdatum in die entgegengesetzte Richtung;
●
GET /articles ?sort=author,-publisbed_at HTTP/1.1 - zuerst nach Autor, dann nach Veröffentlichungsdatum in die entgegengesetzte Richtung, wenn die Artikel vom selben Autor stammen.
URLs müssen geändert werden
Lösung: Hypermedia, die ich bereits erwähnt habe, kann wie folgt durchgeführt werden. Wenn das Objekt (die Ressource) sich selbst beschreiben soll, kann der Client durch Hypermedia verstehen, was damit gemacht werden kann, und der Server kann sich unabhängig vom Client entwickeln. Anschließend können wir mithilfe spezieller Linkschlüssel Links zur Artikelliste zum Artikel selbst hinzufügen ::
01. GET /articles /1.1
02. {
03. "data": [{
04. ...
05. "links": { "self": "http://localhost/articles/1" },
06. "relationships": { ... }
07. }],
08. "links": { "self": " http://localhost/articles " }
09. }
Oder verwandt, wenn wir dem Kunden mitteilen möchten, wie er einen Kommentar zu diesem Artikel hochladen soll:
01. ...
02. "relationships": {
03. "comments": {
04. "links": {
05. "self": "http://localhost/articles/l/relationships/comments ",
06. "related": " http://localhost/articles/l/comments "
07. }
08. }
09. }Der Client sieht, dass es einen Link gibt, folgt ihm und lädt einen Kommentar. Wenn es keinen Link gibt, gibt es keine Kommentare. Das ist praktisch, aber so wenige tun es. Fielding hat die Prinzipien von REST entwickelt, aber nicht alle sind in unsere Branche eingetreten. Wir verwenden hauptsächlich zwei oder drei.
Im Jahr 2013 wurden alle Life-Hacks, von denen ich Ihnen erzählt habe, von Steve Klabnik in die JSON-API-Spezifikation integriert und zusätzlich zu JSON als
neuer Medientyp registriert. So kam unser Junior-Backend-Entwickler, der sich allmählich weiterentwickelte, zur JSON-API.
JSON-API
Alles wird ausführlich auf der Website
http://jsonapi.org/implementations/ beschrieben : Es gibt sogar eine Liste von 170 verschiedenen Implementierungen von Spezifikationen für 32 Programmiersprachen - und diese werden nur dem Katalog hinzugefügt. Bibliotheken, Parser, Serialisierer usw. wurden bereits geschrieben.
Da diese Spezifikation Open Source ist, investieren alle in sie. Ich habe unter anderem selbst etwas geschrieben. Ich bin sicher, dass es viele solcher Leute gibt. Sie können diesem Projekt selbst beitreten.
JSON API-Vorteile
Die JSON-API-Spezifikation löst eine Reihe von Problemen - eine
gemeinsame Vereinbarung für alle . Da es eine allgemeine Vereinbarung gibt,
streiten wir
uns nicht im Team - der Fahrradschuppen ist dokumentiert. Wir haben eine Vereinbarung darüber getroffen, aus welchen Materialien ein Fahrradschuppen hergestellt und wie er lackiert werden soll.
Wenn der Entwickler etwas falsch macht und ich es sehe, beginne ich nicht mit der Diskussion, sondern sage: "Nicht über die JSON-API!" und in der Spezifikation an Ort und Stelle zeigen. Sie hassen mich in der Firma, gewöhnen sich aber allmählich daran und alle mochten die JSON-API. Wir stellen neue Standarddienste gemäß dieser Spezifikation her. Wir haben einen Datumsschlüssel, wir sind bereit, Meta hinzuzufügen, Schlüssel einzuschließen. Es gibt einen reservierten GET-Parameterfilter für Filter. Wir streiten uns nicht darüber, wie man einen Filter nennt - wir verwenden diese Spezifikation. Es wird beschrieben, wie Sie eine URL erstellen.
Da wir nicht streiten, sondern Geschäftsaufgaben erledigen, ist die
Entwicklungsproduktivität höher . Wir haben die beschriebenen Spezifikationen, der Entwickler hat das Backend gelesen, die API erstellt, wir haben sie angeschraubt - der Kunde ist zufrieden.
Beliebte Probleme wurden beispielsweise mit der Paginierung
bereits gelöst . Es gibt viele Hinweise in der Spezifikation.
Da dies JSON ist (danke an Douglas Crockford für dieses Format), ist es prägnanter als XML und
leicht zu lesen und zu verstehen .
Die Tatsache, dass dies
Open Source ist, kann sowohl ein Plus als auch ein Minus sein, aber ich liebe Open Source.
Nachteile JSON API
Das Objekt ist gewachsen (Datum, Attribute, eingeschlossen usw.) - das
Frontend muss die Antworten analysieren: Sie können über Arrays iterieren, um das Objekt herumgehen und wissen, wie Reduzieren funktioniert. Nicht alle unerfahrenen Entwickler kennen diese komplexen Dinge. Es gibt Bibliotheken von Serializern / Deserialisierern, die Sie verwenden können. Im Allgemeinen funktioniert dies nur mit Daten, aber die Objekte sind groß.
Und das
Backend hat Schmerzen:
- Nesting Control - Include kann sehr weit geklettert werden;
- Die Komplexität von Datenbankabfragen - sie werden manchmal automatisch erstellt und erweisen sich als sehr schwierig.
- Sicherheit - Sie können in den Dschungel klettern, besonders wenn Sie eine Art Bibliothek verbinden.
- Die Spezifikation ist schwer zu lesen. Sie ist auf Englisch, und es erschreckte einige, aber allmählich gewöhnten sich alle daran;
- Nicht alle Bibliotheken implementieren die Spezifikation gut - dies ist ein Open Source-Problem.
Fallstricke JSON API
Ein bisschen Hardcore.
Die Anzahl der Beziehungen in der Ausgabe ist nicht begrenzt. Wenn wir Artikel einschließen, anfordern und Kommentare hinzufügen, erhalten wir als Antwort alle Kommentare zu diesem Artikel. Es gibt 10.000 Kommentare - alle 10.000 Kommentare erhalten:
GET /articles/1?include=comments /1.101. ...
02. "relationships": {
03. "comments": {
04. "data": [0 ... ∞]
05. }
06. }Somit kamen tatsächlich 5 MB zu unserer Anfrage als Antwort: „Es ist in der Spezifikation geschrieben - es ist notwendig, die Anfrage korrekt neu zu formulieren:
GET /comments? filters[article]=1& page[size]=30 HTTP/1.101. {
02. "data": [0 ... 29]
03. }Wir bitten um Kommentare mit einem Filter nach Artikel, sagen: "30 Stück, bitte" und erhalten 30 Kommentare. Das ist Mehrdeutigkeit.
Die gleichen Dinge können mehrdeutig formuliert werden :
●
GET /articles/1 ?include=comments HTTP/1.1 - Artikel mit Kommentaren anfordern;
●
GET /articles/1/comments HTTP/1.1 - Kommentare zum Artikel anfordern;
●
GET /comments ?filters[article]=1 HTTP/1.1 - Fordern Sie Kommentare mit einem Filter nach Artikel an.
Dies ist ein und dasselbe - die gleichen Daten, die auf unterschiedliche Weise erhalten werden, es gibt einige Unklarheiten. Diese Falle ist nicht sofort sichtbar.
Eins-zu-viele polymorphe Beziehungen schleichen sich sehr schnell in REST ein.
01. GET /comments?include=commentable /1.1
02.
03. ...
04. "relationships": {
05. "commentable" : {
06. "data": { "type": "article", "id": "1″ }
07. }
08. }Es gibt eine kommentierbare polymorphe Verbindung im Backend - sie kriecht in REST. So sollte es passieren, aber es kann getarnt werden. Sie können es nicht in der JSON-API verschleiern - es wird herauskommen.
Komplexe Viele-zu-Viele-Beziehungen mit erweiterten Optionen . Außerdem kommen alle Verbindungstische heraus:
01. GET /users?include =users_comments /1.1
02.
03. ...
04. "relationships": {
05. "users_comments": {
06. "data": [{ "type": "users_comments", "id": "1″ }, ...]
07. },
08. }Prahlerei
Swagger ist ein Online-Tool zum Schreiben von Dokumentationen.
Angenommen, unser Backend-Entwickler wurde gebeten, eine Dokumentation für seine API zu schreiben, und er hat sie geschrieben. Dies ist einfach, wenn die API einfach ist. Wenn dies eine JSON-API ist, kann Swagger nicht so einfach geschrieben werden.
Beispiel: Swagger Tierhandlung. Jede Methode kann geöffnet werden, siehe Antwort und Beispiele.
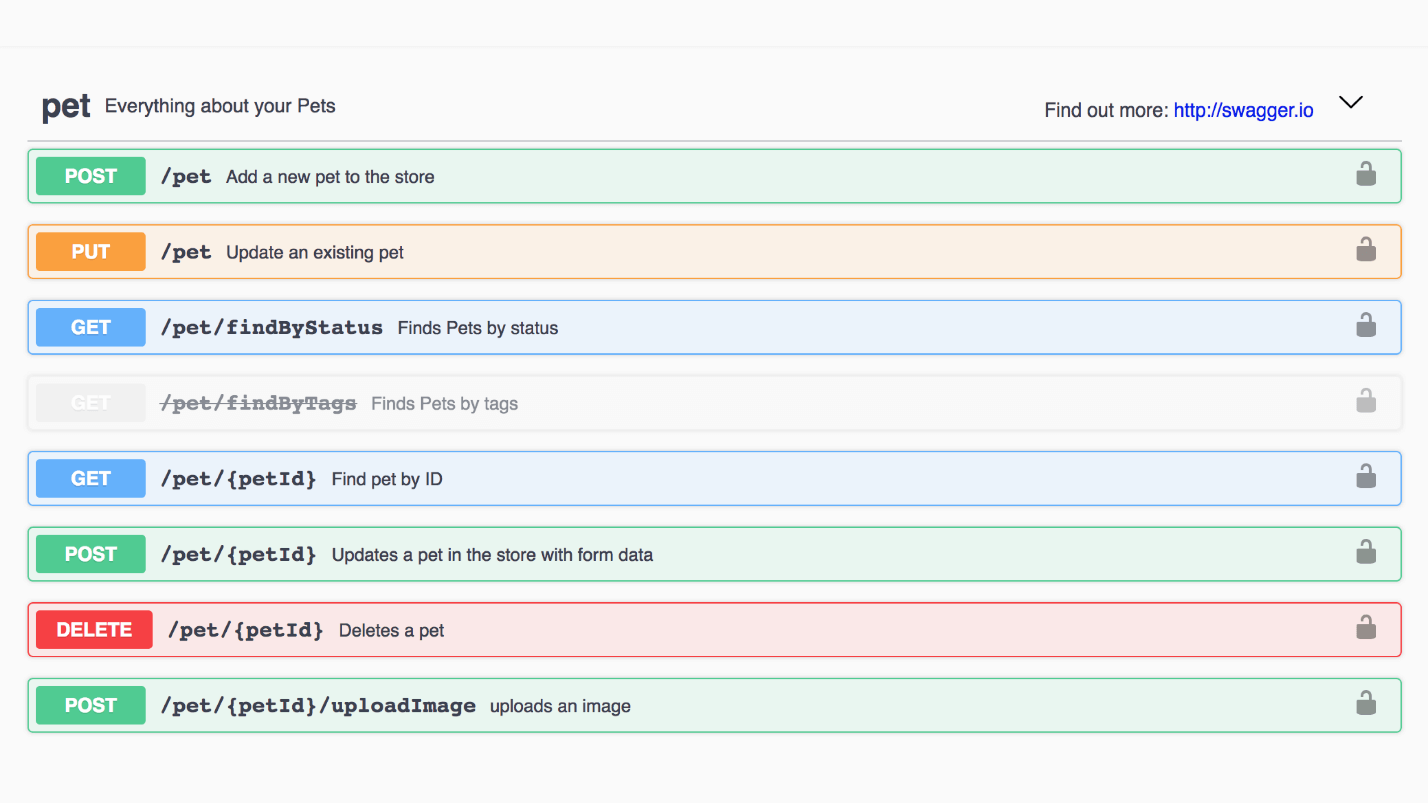
Dies ist ein Beispiel für ein Haustiermodell. Hier ist eine coole Oberfläche, alles ist leicht zu lesen.
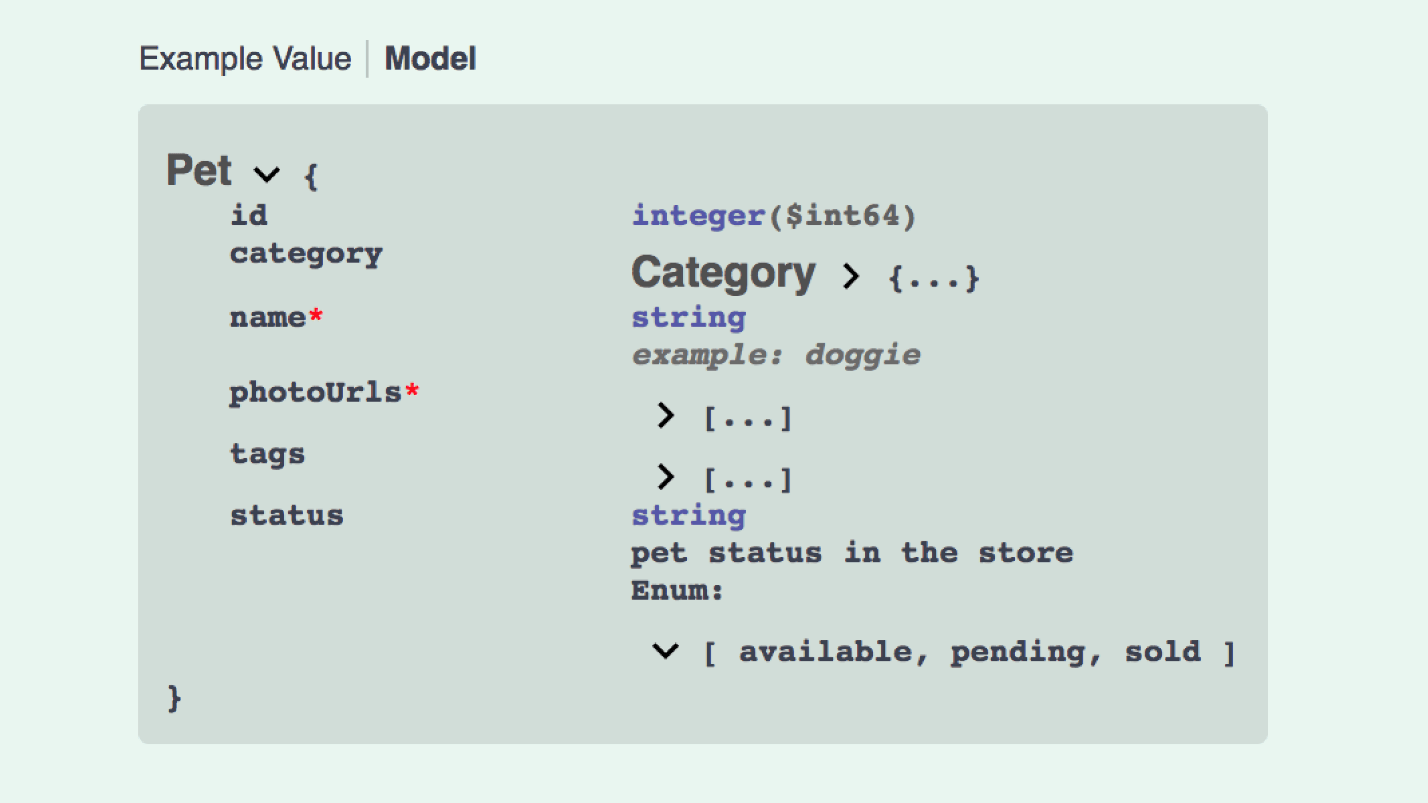
Und so sieht die Erstellung des JSON-API-Modells aus:

Das ist nicht so toll. Wir brauchen Daten, in Daten etwas mit Beziehungen, enthalten enthält 5 Arten von Modellen, etc. Sie können Swagger schreiben, die Open API ist eine mächtige Sache, aber kompliziert.
Alternative
Es gibt eine OData-Spezifikation, die etwas später erschien - im Jahr 2015. Dies ist „der beste Weg zum RESTEN“, wie die offizielle Website versichert. Es sieht so aus:
01. GET http://services.odata.org/v4/TripRW/People HTTP/1.1 - GET-Anforderung;
02. OData-Version: 4.0 - spezieller Header mit Version;
03. OData-MaxVersion: 4.0 - Zweiter spezieller Versionsheader
Die Antwort sieht so aus:
01. HTTP/1.1 200 OK
02. Content-Type: application/json; odata.metadata=minimal
03. OData-Version: 4.0
04. {
05. '@odata.context': 'http://services.odata.org/V4/
06. '@odata.nextLink' : 'http://services.odata.org/V4/
07. 'value': [{
08. '@odata.etag': 1W/108D1D5BD423E51581′,
09. 'UserName': 'russellwhyte',
10. ...
Hier ist die erweiterte Anwendung / json und das Objekt.
Erstens haben wir OData nicht verwendet, da es mit der JSON-API identisch ist, aber nicht präzise. Es gibt riesige Objekte und es scheint mir, dass alles viel schlechter gelesen ist. OData wurde auch in Open Source veröffentlicht, ist aber komplizierter.
Was ist mit GraphQL?
Als wir nach einem neuen API-Format suchten, stießen wir natürlich auf diesen Hype.
●
Hohe Eintrittsschwelle.Aus Sicht des Frontends sieht alles cool aus, aber Sie können den neuen Entwickler nicht dazu bringen, GraphQL zu schreiben, da Sie es zuerst studieren müssen. Es ist wie bei SQL - Sie können SQL nicht sofort schreiben, Sie müssen zumindest lesen, was es ist, die Tutorials durchgehen, dh der Einstiegsschwellenwert erhöht sich.
●
Die Wirkung des Urknalls.Wenn das Projekt keine API enthielt und wir anfingen, GraphQL zu verwenden, stellten wir nach einem Monat fest, dass es nicht zu uns passt, es wird zu spät sein. Ich muss Krücken schreiben. Sie können sich mit der JSON-API oder OData weiterentwickeln - das einfachste RESTful, das sich schrittweise verbessert, wird zu einer JSON-API.
●
Hölle im Backend.GraphQL ruft im Backend die Hölle auf - eins zu eins, genau wie die vollständig implementierte JSON-API, da GraphQL die volle Kontrolle über Abfragen erhält und dies eine Bibliothek ist und Sie viele Probleme lösen müssen:
- Verschachtelungskontrolle;
- Rekursion
- Frequenzbegrenzung;
- Zugangskontrolle.
Anstelle von Schlussfolgerungen
Ich empfehle, nicht mehr über den Fahrradschuppen zu streiten, sondern das Anti-Bikeshedding-Tool als Spezifikation zu verwenden und einfach eine API mit einer guten Spezifikation zu erstellen.
Unter den folgenden Links finden Sie Ihren Standard zur Lösung des Problems eines Fahrradschuppens:
●
http://jsonapi.org●
http://www.odata.org●
https://graphgl.org●
http://xmlrpc.scripting.com●
https://www.jsonrpc.org: alexey-avdeev.com github .
, Frontend Conf , 27 28 ++ . , .
? ? ? , ? !
, , , , .