Es scheint, dass wir so tief in den Dschungel der Hochlastentwicklung eingetaucht sind, dass wir einfach nicht über die Grundprobleme nachdenken. Nehmen Sie zum Beispiel Scherben. Was ist zu verstehen, wenn es möglich ist, bedingte Shards = n in die Datenbankeinstellungen zu schreiben und alles von selbst erledigt wird? Das ist richtig, das ist er, aber wenn eher, wenn etwas schief geht, die Ressourcen wirklich knapp werden, würde ich gerne verstehen, was der Grund ist und wie man es behebt.
Kurz gesagt, wenn Sie Ihre alternative Hash-Implementierung in Cassandra beigesteuert haben, gibt es kaum Enthüllungen für Sie. Wenn Ihre Dienste jedoch bereits ausgelastet sind und die Systemkenntnisse nicht mithalten können, sind Sie herzlich willkommen. Der große und schreckliche
Andrei Aksyonov (
Shodan ) wird auf seine übliche Weise sagen, dass
Scherben schlecht sind, nicht Scherben auch schlecht , und wie es im Inneren angeordnet ist. Und ganz zufällig geht es in einem Teil der Geschichte über das Scherben überhaupt nicht um Scherben, aber der Teufel weiß, was - wie man Objekte Scherben zuordnet.

Das Foto der Robben (obwohl sie sich versehentlich als Welpen herausstellten) scheint bereits die Frage zu beantworten, warum dies alles ist, aber beginnen wir nacheinander.
Was ist Scherben?
Wenn Sie beharrlich googeln, stellt sich heraus, dass zwischen der sogenannten Partitionierung und dem sogenannten Sharding eine ziemlich unscharfe Grenze besteht. Jeder nennt alles, was er will, als er will. Einige Leute unterscheiden zwischen horizontaler Aufteilung und Scherbenbildung. Andere sagen, dass Sharding eine bestimmte Art der horizontalen Partitionierung ist.
Ich habe keinen einzigen terminologischen Standard gefunden, der von den Gründervätern genehmigt und nach ISO zertifiziert wäre. Ein persönlicher innerer Glaube ist ungefähr so:
Partitionierung bedeutet im Durchschnitt, die Basis auf willkürliche Weise in Stücke zu schneiden.
- Vertikale Partitionierung Zum Beispiel gibt es eine riesige Tabelle mit ein paar Milliarden Einträgen in 60 Spalten. Anstatt eine solche gigantische Tabelle zu führen, führen wir 60 nicht weniger gigantische Tabellen mit jeweils 2 Milliarden Datensätzen - und dies ist keine Teilzeitdatenbank, sondern eine vertikale Partitionierung (als Beispiel für Terminologie).
- Horizontale Partitionierung - Wir schneiden Zeile für Zeile, möglicherweise innerhalb des Servers.
Der unangenehme Moment hier ist der subtile Unterschied zwischen horizontaler Aufteilung und Scherbenbildung. Sie können mich in Stücke schneiden, aber ich werde Ihnen nicht mit Sicherheit sagen, woraus es besteht. Es besteht das Gefühl, dass Sharding und horizontale Partitionierung ungefähr dasselbe sind.
Sharding ist im Allgemeinen, wenn eine große Tabelle in Bezug auf Datenbanken oder eine Sammlung von Dokumenten, Objekten, wenn Sie keine Datenbank, sondern einen Dokumentenspeicher haben, speziell für Objekte geschnitten wird. Das heißt, Stücke aus 2 Milliarden Objekten werden ausgewählt, egal welcher Größe. Objekte für sich in jedem Objekt werden nicht in Stücke geschnitten, wir zerlegen nicht in separate Spalten, sondern legen Bündel an verschiedenen Stellen aus.
Der Vollständigkeit halber auf die Präsentation verlinken.Subtile terminologische Unterschiede sind bereits aufgetreten. Relativ gesehen können Postgres-Entwickler beispielsweise sagen, dass die horizontale Partitionierung erfolgt, wenn alle Tabellen, in die die Haupttabelle unterteilt ist, im selben Schema liegen und wenn sie auf verschiedenen Computern shardet.
Im Allgemeinen besteht, ohne an die Terminologie einer bestimmten Datenbank und eines bestimmten Datenverwaltungssystems gebunden zu sein, das Gefühl, dass das Sharding nur zeilenweise und so weiter erfolgt - und das ist alles:
Sharding (~ =, \ in ...) Horizontale Partitionierung == ist typisch.
Ich betone normalerweise. In dem Sinne, dass wir all dies nicht nur tun, um 2 Milliarden Dokumente in 20 Tabellen zu schneiden, von denen jede besser zu verwalten wäre, sondern um sie auf viele Kerne, viele Festplatten oder viele verschiedene physische oder virtuelle Server zu verteilen .
Es versteht sich, dass wir dies tun, damit jeder Shard - jeder Daten-Shatka - viele Male repliziert wird. Aber eigentlich nein.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
Wenn Sie eine solche Datenaufteilung vornehmen und aus einer riesigen SQL-Tabelle in MySQL 16 kleine Tabellen auf Ihrem tapferen Laptop generieren, ohne über einen einzigen Laptop, kein einziges Schema, keine einzige Datenbank usw. hinauszugehen. usw. - Alles, du hast schon Scherben.
Wenn man sich an die Abbildung mit Welpen erinnert, führt dies zu Folgendem:
- Die Bandbreite nimmt zu.
- Die Latenz ändert sich nicht, das heißt, jeder, sozusagen Arbeiter oder Verbraucher, bekommt in diesem Fall seine eigene. Es ist nicht bekannt, was Welpen auf dem Bild sehen, aber Anfragen werden ungefähr zur gleichen Zeit bearbeitet, als ob der Welpe alleine wäre.
- Oder beides und noch eine und immer noch hohe Verfügbarkeit (Replikation).
Warum Bandbreite? Manchmal haben wir solche Datenmengen, die nicht passen - es ist nicht klar, wo, aber sie passen nicht - um 1 {core | Laufwerk | Server | ...}. Es gibt einfach nicht genug Ressourcen und das wars. Um mit diesem großen Datensatz arbeiten zu können, müssen Sie ihn ausschneiden.
Warum Latenz? Auf einem Kern ist das Scannen einer Tabelle mit 2 Milliarden Zeilen 20-mal langsamer als das Scannen von 20 Tabellen auf 20 Kerneln, und dies parallel. Daten werden auf einer Ressource zu langsam verarbeitet.
Warum hohe Verfügbarkeit? Oder wir schneiden die Daten, um das eine und das andere gleichzeitig zu tun, und gleichzeitig bieten mehrere Kopien jeder Shard-Replikation eine hohe Verfügbarkeit.
Ein einfaches Beispiel für "wie man es mit den Händen macht"
Das bedingte Sharding kann mithilfe der Testtabelle test.documents für 32 Dokumente und durch Generieren von 16 Testtabellen für jeweils ca. 2 Dokumente test.docs00, 01, 02, ..., 15 aus dieser Tabelle ausgeschnitten werden.
INSERT INTO docs00 SELECT * FROM documents WHERE (id%16)=0 ... INSERT INTO docs15 SELECT * FROM documents WHERE (id%16)=15
Warum etwa? Da wir a priori nicht wissen, wie die ID verteilt wird, wenn von 1 bis einschließlich 32, dann gibt es jeweils genau 2 Dokumente, andernfalls nicht.
Wir machen das für was. Nachdem wir 16 Tische erstellt haben, können wir 16 von dem, was wir brauchen, „fangen“. Unabhängig davon, worauf wir uns ausgeruht haben, können wir diese Ressourcen parallelisieren. Wenn beispielsweise nicht genügend Speicherplatz vorhanden ist, ist es sinnvoll, diese Tabellen in separate Datenträger zu zerlegen.
All dies ist leider nicht kostenlos. Ich vermute, dass es im Fall des kanonischen SQL-Standards (ich habe den SQL-Standard lange nicht mehr gelesen, vielleicht wurde er lange nicht mehr aktualisiert) keine offizielle standardisierte Syntax gibt, um einem SQL-Server zu sagen: „Lieber SQL-Server, machen Sie mich zu 32 Shards und lege sie auf 4 Scheiben. " In einzelnen Implementierungen gibt es jedoch häufig eine bestimmte Syntax, um dies im Prinzip zu tun. PostgreSQL hat Mechanismen für die Partitionierung, MySQL MariaDB hat es, Oracle hat dies wahrscheinlich schon vor langer Zeit getan.
Wenn wir dies jedoch von Hand tun, ohne Datenbankunterstützung und im Rahmen des Standards,
zahlen wir
bedingt die Komplexität des Zugriffs auf Daten . Wo es ein einfaches SELECT * FROM-Dokument gab WHERE id = 123, jetzt 16 x SELECT * FROM docsXX. Und nun, wenn wir versuchen würden, die Aufzeichnung per Schlüssel zu erhalten. Deutlich interessanter, wenn wir versuchen, eine frühe Reihe von Aufzeichnungen zu erhalten. Nun (wenn ich betone, wie Narren, und innerhalb des Standards bleiben) müssen die Ergebnisse dieser 16 SELECT * FROM in der Anwendung kombiniert werden.
Welche Leistungsänderung ist zu erwarten?- Intuitiv linear.
- Theoretisch - sublinear, weil Amdahl-Gesetz .
- In der Praxis - vielleicht fast linear, vielleicht nicht.
In der Tat ist die richtige Antwort unbekannt. Durch geschickte Anwendung der Sharding-Technik können Sie eine signifikante superlineare Verschlechterung im Betrieb Ihrer Anwendung erzielen, und sogar der DBA wird mit einem glühenden Poker ausgeliefert.
Mal sehen, wie dies erreicht werden kann. Es ist klar, dass nur die Einstellung auf PostgreSQL-Shards = 16 gesetzt wurde und sich dann von selbst abhebt - das ist nicht interessant. Lassen Sie uns darüber nachdenken, wie wir erreichen können, dass
wir durch das Splittern auf das 32-fache verlangsamen , was unter dem Gesichtspunkt interessant ist, wie man dies nicht tut.
Unsere Versuche, zu beschleunigen oder zu verlangsamen, werden immer gegen die Klassiker gerichtet sein - das gute alte Amdahl-Gesetz, das besagt, dass es keine perfekte Parallelisierung einer Anfrage gibt, es gibt immer einen konsistenten Teil.
Amdahl-Gesetz
Es gibt immer einen serialisierten Teil.
Es gibt immer einen Teil der Ausführung der Anforderung, der parallel ist, und es gibt immer einen Teil, der nicht parallel ist. Selbst wenn es Ihnen so scheint, als ob eine perfekt parallele Abfrage, die zumindest eine Zeile des Ergebnisses sammelt, das Sie an den Client senden möchten, aus den von jedem Shard empfangenen Zeilen immer und immer konsistent ist.
Es gibt immer eine Art sequentiellen Teil. Es kann winzig sein, vor dem allgemeinen Hintergrund absolut unsichtbar, es kann gigantisch sein und dementsprechend die Parallelisierung stark beeinflussen, aber es ist immer da.
Darüber hinaus
ändert sich sein Einfluss und kann erheblich zunehmen. Wenn wir beispielsweise unsere Tabelle von 64 Datensätzen auf 16 Tabellen mit 4 Datensätzen kürzen - erhöhen wir die Raten -, ändert sich dieser Teil. Angesichts dieser gigantischen Datenmengen arbeiten wir natürlich mit einem Mobiltelefon und einem 86-MHz-Prozessor. Wir haben nicht genügend Dateien, die gleichzeitig geöffnet bleiben können. Anscheinend öffnen wir mit solchen Eingaben jeweils eine Datei.
- Es war Total = Serial + Parallel . Wobei beispielsweise die gesamte Arbeit in der Datenbank parallel ist und seriell das Ergebnis an den Client sendet.
- Es wurde Total2 = Seriell + Parallel / N + Xserial. Zum Beispiel, wenn die allgemeine ORDER BY, Xserial> 0.
Mit diesem einfachen Beispiel versuche ich zu zeigen, dass Xserial angezeigt wird. Zusätzlich zu der Tatsache, dass es immer ein serialisiertes Teil gibt und dass wir versuchen, parallel mit Daten zu arbeiten, scheint ein zusätzliches Teil dieses Daten-Slicing sicherzustellen. Grob gesagt brauchen wir vielleicht:
- Finden Sie diese 16 Tabellen im internen Datenbankwörterbuch.
- Dateien öffnen;
- Speicher zuweisen;
- Speicher verschieben;
- färben Sie die Ergebnisse;
- zwischen Kernen synchronisieren;
Nicht synchronisierte Effekte werden immer angezeigt. Sie können unbedeutend sein und ein Milliardstel der Gesamtzeit einnehmen, aber sie sind immer ungleich Null und existieren immer. Mit ihrer Hilfe können wir nach dem Splittern die Produktivität drastisch verlieren.
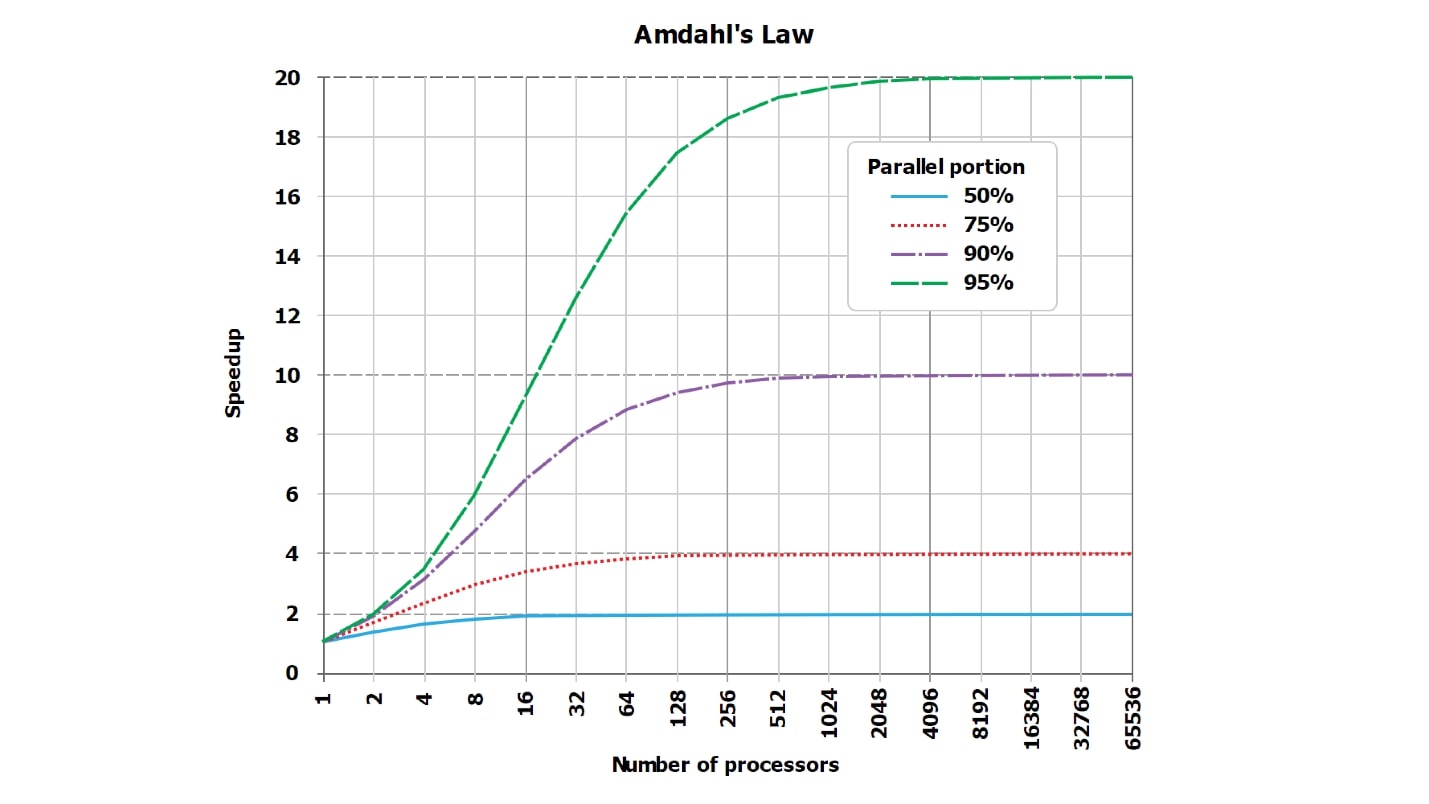
Dies ist ein Standardbild über Amdahls Gesetz. Es ist nicht sehr gut lesbar, aber es ist wichtig, dass die Linien, die idealerweise gerade sind und linear wachsen, an der Asymptote anliegen. Da die Grafik aus dem Internet jedoch nicht lesbar ist, habe ich meiner Meinung nach mehr visuelle Tabellen mit Zahlen erstellt.
Angenommen, wir haben einen serialisierten Teil der Anforderungsverarbeitung, der nur 5% dauert:
serial = 0.05 = 1/20.Intuitiv scheint es, dass mit dem serialisierten Teil, der nur 1/20 der Anforderungsverarbeitung benötigt, wenn wir die Verarbeitung der Anforderung um 20 Kerne parallelisieren, diese im schlimmsten Fall 18-mal schneller wird.
In der Tat ist
Mathematik eine herzlose Sache :
wall = 0.05 + 0.95/num_cores, speedup = 1 / (0.05 + 0.95/num_cores)Es stellt sich heraus, dass bei sorgfältiger Berechnung mit einem serialisierten Teil von 5% die Beschleunigung das 10-fache (10,3) beträgt, und dies sind 51% im Vergleich zum theoretischen Ideal.
| 8 Kerne | = 5,9 | = 74% |
| 10 Kerne | = 6,9 | = 69% |
| 20 Kerne | = 10,3 | = 51% |
| 40 Kerne | = 13,6 | = 34% |
| 128 Kerne | = 17,4 | = 14% |
Wenn Sie 20 Kerne (20 Festplatten, wenn Sie möchten) für die Aufgabe verwenden, an der Sie zuvor gearbeitet haben, werden wir theoretisch nie mehr als 20 Mal beschleunigt, aber praktisch viel weniger. Darüber hinaus nimmt die Ineffizienz mit zunehmender Anzahl von Parallelen rapide zu.
Wenn nur noch 1% der serialisierten Arbeit übrig bleibt und 99% parallelisiert sind, werden die Beschleunigungswerte etwas verbessert:
| 8 Kerne | = 7,5 | = 93% |
| 16 Kerne | = 13,9 | = 87% |
| 32 Kerne | = 24,4 | = 76% |
| 64 Kerne | = 39,3 | = 61% |
Bei einer vollständig thermonuklearen Abfrage, die natürlich stundenlang ausgeführt wird, und bei der Vorbereitung und Zusammenstellung des Ergebnisses ist nur sehr wenig Zeit erforderlich (Seriennummer = 0,001). Wir werden bereits eine gute Effizienz feststellen:
| 8 Kerne | = 7,94 | = 99% |
| 16 Kerne | = 15,76 | = 99% |
| 32 Kerne | = 31.04 | = 97% |
| 64 Kerne | = 60,20 | = 94% |
Bitte beachten Sie, dass
wir niemals 100% sehen werden . In besonders guten Fällen sehen Sie beispielsweise 99,999%, aber nicht genau 100%.
Wie man N-mal mischt und einbricht?
Sie können genau N-mal mischen und einbrechen:
- Senden Sie docs00 ... docs15-Anfragen nacheinander , nicht parallel.
- Wählen Sie in einfachen Abfragen nicht nach Schlüssel aus , WO etwas = 234.
In diesem Fall belegt der serialisierte Teil (seriell) nicht 1% und nicht 5%, sondern etwa 20% in modernen Datenbanken. Sie können 50% des serialisierten Teils erhalten, wenn Sie mit einem äußerst effizienten Binärprotokoll auf die Datenbank zugreifen oder sie als dynamische Bibliothek mit einem Python-Skript verknüpfen.
Der Rest der Verarbeitungszeit für eine einfache Anforderung wird durch nicht parallelisierte Vorgänge zum Parsen der Anforderung, Erstellen des Plans usw. belegt. Das heißt, es wird langsamer, wenn die Aufzeichnung nicht gelesen wird.
Wenn wir die Daten in 16 Tabellen aufteilen und nacheinander ausführen, wie es beispielsweise in der PHP-Programmiersprache üblich ist (es weiß nicht, wie asynchrone Prozesse sehr gut ausgeführt werden sollen), wird nur eine 16-fache Verlangsamung angezeigt. Und vielleicht sogar noch mehr, weil auch Netzwerk-Roundtrips hinzugefügt werden.
Beim Sharding ist plötzlich die Wahl einer Programmiersprache wichtig.
Wir erinnern uns an die Wahl einer Programmiersprache, denn wenn Sie nacheinander Anfragen an die Datenbank (oder den Suchserver) senden, woher kommt dann die Beschleunigung? Vielmehr wird eine Verlangsamung auftreten.
Fahrrad aus dem Leben
Wenn Sie sich für C ++ entscheiden,
schreiben Sie in POSIX-Threads und nicht in Boost I / O. Ich habe eine ausgezeichnete Bibliothek von erfahrenen Entwicklern von Oracle und MySQL selbst gesehen, die die Kommunikation mit dem MySQL-Server auf Boost geschrieben haben. Anscheinend waren sie gezwungen, bei der Arbeit in reinem C zu schreiben, aber dann gelang es ihnen, sich umzudrehen, Boost mit asynchroner E / A zu verwenden usw. Ein Problem - diese asynchrone E / A, die theoretisch 10 Anforderungen parallel hätte steuern sollen, hatte aus irgendeinem Grund einen unsichtbaren Synchronisationspunkt im Inneren. Wenn 10 Anforderungen parallel gestartet wurden, wurden sie genau 20 Mal langsamer als eine ausgeführt, da 10 Mal zu den Anforderungen selbst und einmal zum Synchronisationspunkt.
Fazit: Schreiben Sie in Sprachen, die paralleles Ausführen implementieren und gut auf unterschiedliche Anforderungen warten. Ich weiß ehrlich gesagt nicht, was genau neben Go zu raten ist. Nicht nur, weil ich Go wirklich liebe, sondern weil ich nichts passenderes weiß.
Schreiben Sie nicht in ungeeigneten Sprachen, in denen Sie nicht 20 parallele Abfragen an die Datenbank ausführen können. Oder machen Sie bei jeder Gelegenheit nicht alles mit Ihren Händen - verstehen Sie, wie es funktioniert, aber machen Sie es nicht manuell.
A / B Testrad
Manchmal können Sie langsamer fahren, weil Sie daran gewöhnt sind, dass alles funktioniert, und Sie haben nicht bemerkt, dass der serialisierte Teil erstens ein großer ist.
- Sofort ~ 60 Suchindex-Shards, Kategorien
- Dies sind korrekte und korrekte Shards unter einem Themenbereich.
- Es gab bis zu 1000 Dokumente und es gab 50.000 Dokumente.
Dies ist ein Serienrad, bei dem die Suchanfragen leicht geändert wurden und viel mehr Dokumente aus 60 Shards des Suchindex ausgewählt wurden. Alles funktionierte schnell und nach dem Prinzip: „Es funktioniert - fass es nicht an“, alle haben es vergessen, das sich tatsächlich in 60 Scherben befindet. Wir haben die Stichprobengrenze für jeden Shard von tausend auf 50.000 Dokumente erhöht. Plötzlich wurde es langsamer und die Parallelität hörte auf. Die Anfragen selbst, die nach Scherben ausgeführt wurden, flogen recht gut, und die Bühne wurde verlangsamt, als 50.000 Dokumente aus 60 Scherben gesammelt wurden. Diese 3 Millionen endgültigen Dokumente auf einem Kern wurden zusammengeführt, sortiert, die Spitze von 3 Millionen wurde ausgewählt und dem Kunden übergeben. Der gleiche serielle Teil verlangsamte sich, das gleiche rücksichtslose Gesetz von Amdal wirkte.
Vielleicht solltest du nicht mit deinen Händen scherben, sondern nur menschlich
Sagen Sie der Datenbank: "Mach es!"
Haftungsausschluss: Ich weiß nicht wirklich, wie ich etwas richtig machen soll. Ich bin wie aus dem falschen Stock !!!
Ich habe während meines gesamten bewussten Lebens eine Religion namens „algorithmischer Fundamentalismus“ gefördert. Es wird kurz ganz einfach formuliert:
Sie möchten eigentlich nichts mit Ihren Händen tun, aber es ist äußerst nützlich zu wissen, wie es im Inneren angeordnet ist. Damit Sie in dem Moment, in dem in der Datenbank etwas schief geht, zumindest verstehen, was dort schief gelaufen ist, wie es im Inneren angeordnet ist und wie es ungefähr repariert werden kann.
Schauen wir uns die Optionen an:
- "Hände . " Zuvor haben wir die Daten manuell in 16 virtuelle Tabellen fragmentiert und alle Abfragen mit unseren Händen neu geschrieben - dies ist äußerst unangenehm. Wenn die Möglichkeit besteht, die Hände nicht zu mischen, mischen Sie nicht die Hände! Aber manchmal ist dies nicht möglich, zum Beispiel haben Sie MySQL 3.23 und müssen es dann.
- "Automatisch". Es kommt vor, dass Sie automatisch oder fast automatisch mischen können. Wenn die Datenbank die Daten selbst verteilen kann, müssen Sie nur irgendwo eine bestimmte Einstellung grob schreiben. Es gibt viele Basen und sie haben viele verschiedene Einstellungen. Ich bin sicher, dass in jeder Datenbank, in der es möglich ist, Shards = 16 zu schreiben (unabhängig von der Syntax), viele andere Einstellungen von der Engine auf diesen Fall geklebt werden.
- "Halbautomatisch" - meiner Meinung nach ein völlig kosmischer und brutaler Modus. Das heißt, die Basis selbst scheint nicht dazu in der Lage zu sein, aber es gibt externe zusätzliche Patches.
Es ist schwierig, etwas über die Maschine zu erzählen, außer es an die Dokumentation in der entsprechenden Datenbank zu senden (MongoDB, Elastic, Cassandra, ... im Allgemeinen das sogenannte NoSQL). Wenn Sie Glück haben, ziehen Sie einfach den Schalter „Mach mich zu 16 Scherben“ und alles wird funktionieren. In diesem Moment, wenn es nicht funktioniert, kann der Rest des Artikels notwendig sein.
Über halbautomatisches Gerät
An einigen Stellen inspirieren ausgefeilte Informationstechnologien den chthonischen Horror. Zum Beispiel hatte MySQL sofort keine Implementierung von Sharding für bestimmte Versionen, dennoch wächst die Größe der im Kampf betriebenen Basen auf unanständige Werte.
Das Leiden der Menschheit angesichts einzelner Datenbankadministratoren wird seit Jahren gequält und schreibt mehrere schlechte Sharding-Lösungen, die ohne Grund entwickelt wurden. Danach wird eine mehr oder weniger anständige Sharding-Lösung namens ProxySQL geschrieben (MariaDB / Spider, PG / pg_shard / Citus, ...). Dies ist ein bekanntes Beispiel für denselben Mantel.
ProxySQL als Ganzes ist natürlich eine Komplettlösung der Enterprise-Klasse für Open Source, Routing und mehr. Eine der zu lösenden Aufgaben ist jedoch das Sharding für eine Datenbank, die an sich nicht weiß, wie man menschlich shardet. Sie sehen, es gibt keinen "Shards = 16" -Schalter. Entweder müssen Sie jede Anforderung in der Anwendung neu schreiben, und es gibt viele davon, oder Sie legen eine Zwischenebene zwischen die Anwendung und die Datenbank, die so aussieht: "Hmm ... SELECT * FROM Documents?" Ja, es muss in 16 kleine SELECT * FROM server1.document1, SELECT * FROM server2.document2 zerrissen werden - zu diesem Server mit diesem Benutzernamen / Passwort, zu diesem mit einem anderen. Wenn man nicht antwortete, dann ... "usw.
Genau dies kann durch Zwischen-Patches erfolgen. Sie sind etwas geringer als bei allen Datenbanken. Für PostgreSQL gibt es meines Wissens gleichzeitig einige integrierte Lösungen (PostgresForeign Data Wrappers sind meiner Meinung nach in PostgreSQL selbst integriert), es gibt externe Patches.
Die Konfiguration jedes einzelnen Patches ist ein separates großes Thema, das nicht in einen Bericht passt. Daher werden nur grundlegende Konzepte erörtert.
Lassen Sie uns besser ein wenig über die Buzz-Theorie sprechen.
Absolut perfekte Automatisierung?
Die ganze Theorie des Summens beim Sharding in diesem Buchstaben F (), das Grundprinzip ist
immer das gleiche Rohöl:
shard_id = F(object).Beim Sharding geht es im Allgemeinen um was? Wir haben 2 Milliarden Datensätze (oder 64). Wir wollen sie in mehrere Teile teilen. Eine unerwartete Frage stellt sich - wie? Nach welchem Prinzip sollte ich meine 2 Milliarden Datensätze (oder 64) auf 16 Server verteilen, die mir zur Verfügung stehen?
Der latente Mathematiker in uns sollte vorschlagen, dass es am Ende immer eine bestimmte magische Funktion gibt, die für jedes Dokument (Objekt, Linie usw.) bestimmt, in welches Stück es eingefügt werden soll.
Wenn wir tiefer in die Mathematik einsteigen, hängt diese Funktion immer nicht nur vom Objekt selbst (der Linie selbst) ab, sondern auch von externen Einstellungen wie der Gesamtzahl der Shards. Die Funktion, die für jedes Objekt angeben muss, wo es abgelegt werden soll, kann keinen Wert mehr zurückgeben, als Server auf dem System vorhanden sind. Und die Funktionen sind etwas anders:
- shard_func = F1 (Objekt);
- shard_id = F2 (shard_func, ...);
- shard_id = F2 ( F1 (Objekt), current_num_shards, ...).
Aber weiter werden wir uns nicht mit diesen Dschungeln einzelner Funktionen befassen, sondern nur darüber sprechen, was magische Funktionen F () sind.
Was ist F ()?
Sie können mit vielen verschiedenen Implementierungsmechanismen aufwarten. Beispielzusammenfassung:
- F = rand ()% nums_shards
- F = somehash (object.id)% num_shards
- F = object.date% num_shards
- F = object.user_id% num_shards
- ...
- F = shard_table [somehash () | ... object.date | ...]
Eine interessante Tatsache - Sie können natürlich alle Daten zufällig verteilen - wir werfen den nächsten Datensatz auf einen beliebigen Server, auf einen beliebigen Kernel, in eine beliebige Tabelle. Es wird nicht viel Glück geben, aber es wird funktionieren.
Es gibt etwas intelligentere Methoden zum Betrügen nach reproduzierbaren oder sogar konsistenten Hash-Funktionen oder zum Betrügen nach bestimmten Attributen. Lassen Sie uns jede Methode durchgehen.
F = rand ()
Herumstreuen ist keine sehr korrekte Methode. Ein Problem: Wir haben unsere 2 Milliarden Datensätze pro tausend Server zufällig verteilt und wissen nicht, wo der Datensatz liegt. Wir müssen user_1 ziehen, wissen aber nicht, wo es ist. Wir gehen zu tausend Servern und sortieren alles - irgendwie ist es ineffizient.
F = somehash ()
Lassen Sie uns Benutzer auf erwachsene Weise verteilen: Lesen Sie die reproduzierte Hash-Funktion aus user_id, nehmen Sie den Rest der Division durch die Anzahl der Server und greifen Sie sofort auf den gewünschten Server zu.
Warum machen wir das? Und dann, dass wir eine hohe Last haben und nichts auf einen Server bekommen. Wenn man sich einmischt, wäre das Leben so einfach.Nun, die Situation hat sich bereits verbessert. Um einen Datensatz zu erhalten, gehen wir zu einem bekannten Server. Wenn wir jedoch einen Schlüsselbereich haben, müssen wir in diesem Bereich alle Schlüsselwerte sortieren und im Limit entweder zu so vielen Shards gehen, wie wir Schlüssel im Bereich haben, oder zu jedem Server im Allgemeinen. Die Situation hat sich natürlich verbessert, aber nicht für alle Anfragen. Einige Anfragen sind betroffen.
Natürliches Sharding (F = object.date% num_shards)
Manchmal, das heißt oft, sind 95% des Datenverkehrs und 95% der Last Anforderungen, die eine Art natürliches Sharding aufweisen. , 95% - 1 , 3 , 7 , 5% . 95% , , , .
, , , - .
— , . , , , , . 5 % .
, :
- , 95% .
- 95% , , . , . , .
, — , - .
, , , , . « - ».
«». , .
1. :
, , .
, / , , , PM ( , PM ), . .
, . , , 100 . .
, , , , - .
2. «» : , join
, ?
- «» … WHERE randcol BETWEEN aaa AND bbb?
- «» … users_32shards JOIN posts_1024 shards?
: , !
, , , . . (, , document store ), , .
—
- . . , . , , , . - , , , , — .
, .
3. / :
: , .
, .
, , , . , , , 10 , - 30, 100 . . — , - — , - .
, : 16 -, 32. , 17, 23 — . , , - ?
: , , .
, «», « ».
#1.
- NewF(object), .
- NewF()=OldF() .
- .
- Autsch.
, 2 , , . : 17 , 6 , 2 , 17 23 . 10 , , . .
#2.
— — 17 23, 16 32 ! , .
- NewF(object), .
- 2^N, 2^(N+1) .
- NewF()=OldF() 0,5.
- 50% .
- , .
, , . , , .
, . , 16 16, — .
, — .
#3. Consistent hashing
, consistent hashing
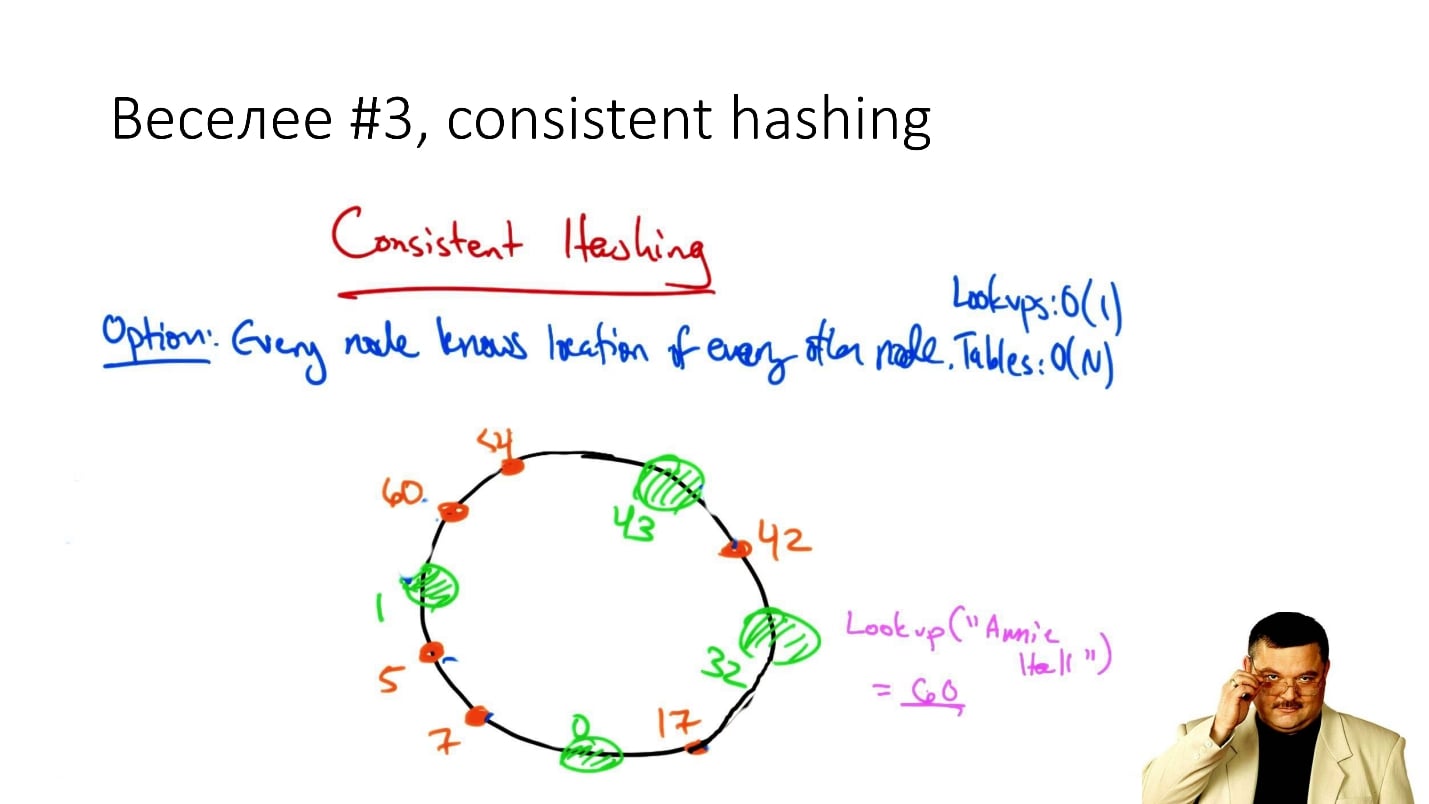
«consistent hashing», , .
: () , . , , , ( , ), .
, . , , , : , .
. , . , .., . , - , , .
, , , Cassandra . , , , , , .
, — / , , .
, : ? ? — , !
#4. Rendezvous/HRW
( , ):
shard_id = arg max hash(object_id, shard_id).Rendezvous hashing, , , Highest Random Weight. :
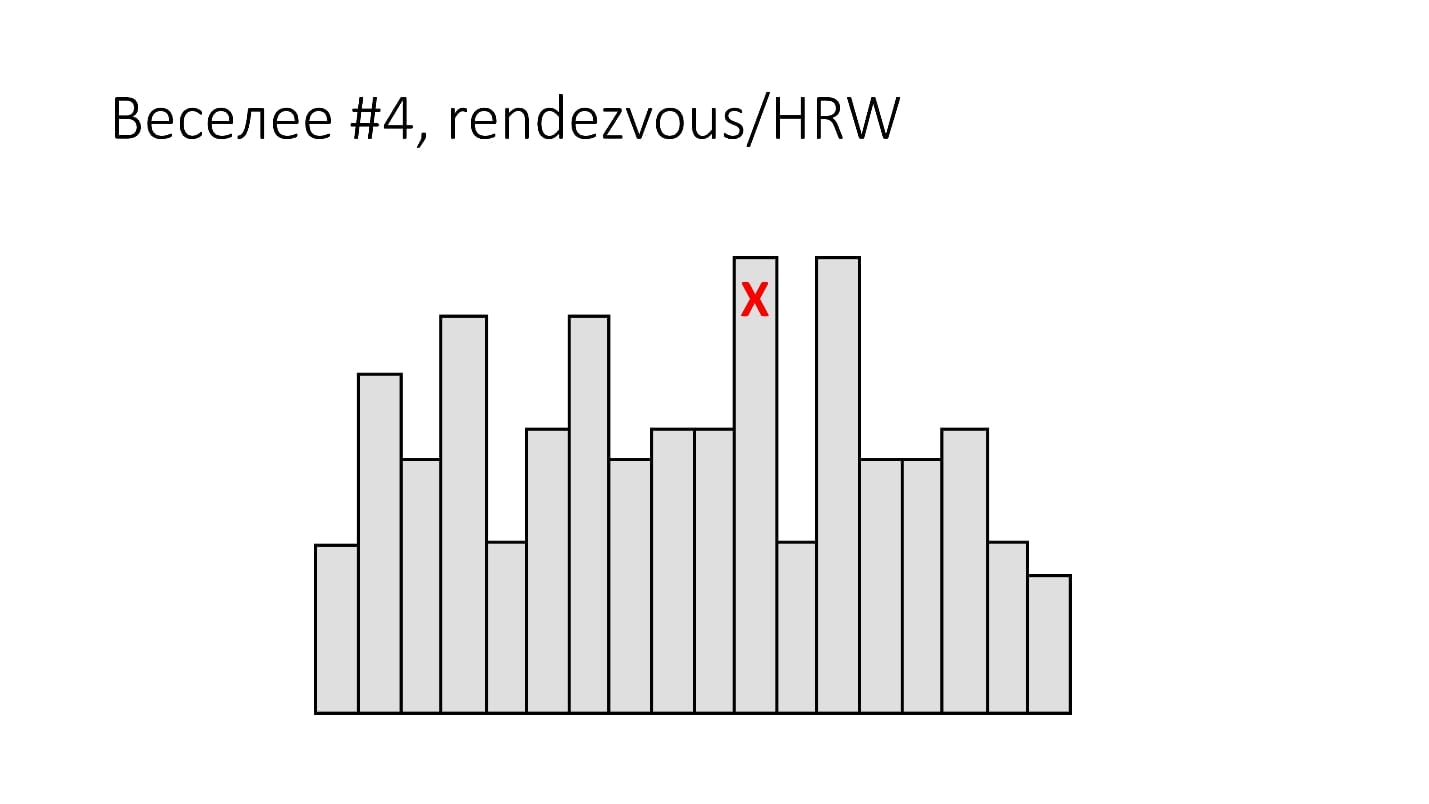
, , 16 . (), - , 16 , . -, .
HRW-hashing, Rendezvous hashing. , -, , .
, . , - - . .
, .
#5.
, Google - :
- Jump Hash — Google '2014.
- Multi Probe —Google '2015.
- Maglev — Google '2016.
, . , , , -, . .
#6.
— . ? , 2 , object_id 2 , .
, ? ?
. , - , , . , , , , .
:
- 1 .
- / / / : min/max_id => shard_id.
- 8 4 (4 !) — 20 .
- - , 20 — .
- 20 — .
2 - 16 — 100 - . : , , — 1 . , , .
, , , - , .
Schlussfolgerungen
: « , !». , 20 .
, , . ,
— . 100$ , . -, . — .
, , «» (, DFS, ...) . , , highload - . , , - . —
, .
F() , , , .. , , 2
.
, , .
HighLoad++ , , —Sphinx—highload , .
Highload User Group. , .
, ,
HighLoad++ . , , . , , .
highload-, .
, , , . , , , .
24 - «», « ». , . ,
.
, , 8 9 - HighLoad++ early bird .