Hinweis perev. : Dieser Artikel setzt die Reihe von Materialien über das Grundgerät von Netzwerken in Kubernetes fort, die in zugänglicher Form und mit veranschaulichenden Abbildungen beschrieben werden (in diesem Teil des Betons gab es jedoch praktisch keine Abbildungen). Bei der Übersetzung der beiden vorherigen Teile dieser Reihe haben wir sie zu einer Veröffentlichung zusammengefasst , in der das K8-Netzwerkmodell (Interaktion innerhalb von Knoten und zwischen Knoten) und Overlay-Netzwerke behandelt wurden. Ihre vorläufige Lektüre ist wünschenswert (vom Autor selbst empfohlen). Die Fortsetzung ist den Kubernetes-Diensten und der Verarbeitung des ausgehenden und eingehenden Datenverkehrs gewidmet.
NB : Der Einfachheit halber wird der Text des Autors durch Links ergänzt (hauptsächlich zur offiziellen Dokumentation von K8s).
Clusterdynamik
Aufgrund der sich ständig ändernden, dynamischen Natur von Kubernetes und der verteilten Systeme im Allgemeinen ändern sich auch die Pods (und infolgedessen ihre IP-Adressen) ständig. Die Gründe hierfür reichen von eingehenden Aktualisierungen, um den gewünschten Status und Ereignisse zu erreichen, die zur Skalierung führen, bis hin zu unvorhergesehenen Abstürzen des Pods oder Knotens. Daher können die IP-Adressen des Pods nicht direkt für die Kommunikation verwendet werden.
Der
Dienst in Kubernetes kommt ins Spiel - eine virtuelle IP mit einer Gruppe von Pod-IP-Adressen, die als Endpunkte verwendet und durch
Label-Selektoren identifiziert werden. Ein solcher Dienst arbeitet als virtueller Load Balancer, dessen IP-Adresse konstant bleibt, und gleichzeitig können sich die IP-Adressen des von ihm präsentierten Pods ständig ändern.
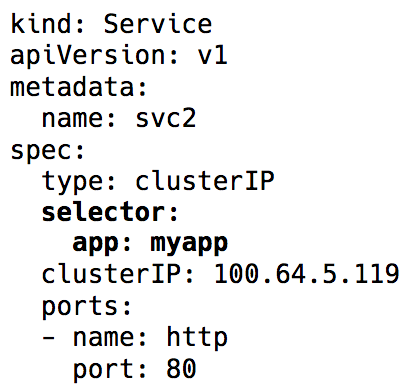 Beschriftungsauswahl im Serviceobjekt in Kubernetes
Beschriftungsauswahl im Serviceobjekt in KubernetesHinter der gesamten Implementierung dieser virtuellen IP stehen iptables-Regeln (die neuesten Versionen von Kubernetes können auch IPVS verwenden, dies ist jedoch ein Thema für eine weitere Diskussion), die von einer Kubernetes-Komponente namens
kube-proxy gesteuert werden. Ein solcher Name ist jedoch in der heutigen Realität irreführend. Kube-Proxy wurde in den Tagen vor der Veröffentlichung von Kubernetes v1.0 tatsächlich als Proxy verwendet. Dies führte jedoch aufgrund der ständigen Kopiervorgänge zwischen Kernel- und Benutzerbereich zu einem hohen Ressourcen- und Bremsenverbrauch. Jetzt ist es nur noch ein Controller - wie viele andere Controller in Kubernetes. Es überwacht den API-Server auf Änderungen an Endpunkten und aktualisiert die iptables-Regeln entsprechend.
Gemäß diesen iptables-Regeln wird DNAT (Destination Network Address Translation) durchgeführt, wenn das Paket für die IP-Adresse des Dienstes bestimmt ist: Dies bedeutet, dass sich seine IP-Adresse von der IP des Dienstes zu einem der Endpunkte ändert, d. H. eine der IP-Adressen des Pods, die iptables zufällig auswählt. Dies stellt sicher, dass die Last gleichmäßig auf die Pods verteilt wird.
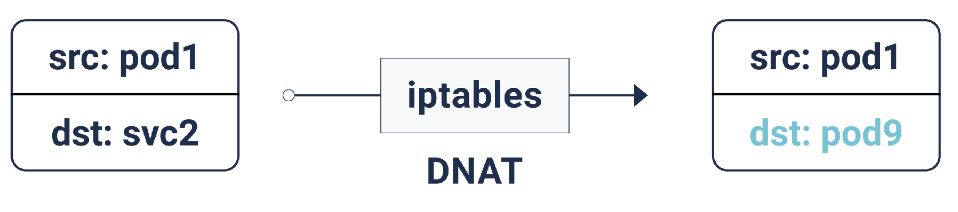 DNAT in iptables
DNAT in iptablesBei einem solchen DNAT werden die erforderlichen Informationen in
conntrack gespeichert - der Verbindungsabrechnungstabelle unter Linux (in der von iptables erstellte Fünf-Paar-Übersetzungen
srcIP sind:
protocol ,
srcIP ,
srcPort ,
dstIP ,
dstPort ). Alles ist so angeordnet, dass bei Rückgabe einer Antwort eine umgekehrte DNAT-Operation (Un-DNAT) auftreten kann, d. H. Ersetzen der IP-Quelle von Pod IP zu Service IP. Dank dieses Clients müssen Sie absolut nicht wissen, wie Sie mit Paketen hinter den Kulissen arbeiten.
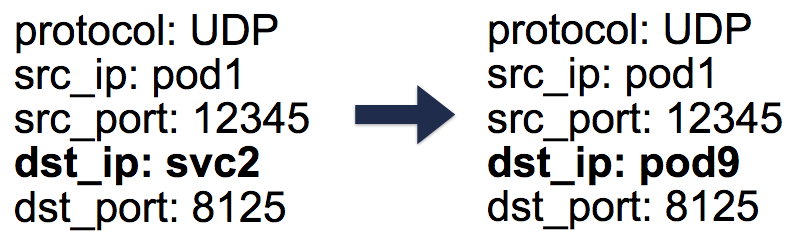 Fünf-Paar-Einträge (5-Tupel) in der Conntrack-Tabelle
Fünf-Paar-Einträge (5-Tupel) in der Conntrack-TabelleMit Kubernetes-Diensten können wir also ohne Konflikte mit denselben Ports arbeiten (da eine Neuzuweisung von Ports zu Endpunkten möglich ist). Dies macht die Serviceerkennung sehr einfach. Es reicht aus, das interne DNS zu verwenden und den Host der Dienste fest zu codieren. Sie können sogar die vorkonfigurierten Kubernetes-Variablen mit dem Host- und Service-Port verwenden.
Tipp : Wenn Sie den zweiten Pfad wählen, sparen Sie viele unnötige DNS-Anrufe!
Ausgehender Verkehr
Die oben beschriebenen Kubernetes-Dienste arbeiten in einem Cluster. In der Praxis benötigen Anwendungen normalerweise Zugriff auf einige externe APIs / Sites.
Im Allgemeinen können Hosts sowohl private als auch öffentliche IP-Adressen haben. Für den Zugriff auf das Internet wird für diese privaten und öffentlichen IP-Adressen ein Eins-zu-Eins-NAT bereitgestellt. Dies gilt insbesondere für Cloud-Umgebungen.
Bei normaler Interaktion des Hosts mit der externen IP-Adresse ändert sich die Quell-IP von der privaten Host-IP zur öffentlichen IP für ausgehende Pakete und für eingehende Pakete - in die entgegengesetzte Richtung. In Fällen, in denen die Verbindung zur externen IP vom Pod initiiert wird, ist die Quell-IP-Adresse die Pod-IP, über die der NAT-Mechanismus des Cloud-Anbieters nichts weiß. Daher werden einfach Pakete mit Quell-IP-Adressen verworfen, die sich von den Host-IP-Adressen unterscheiden.
Und hier, Sie haben es erraten, werden wir noch mehr Iptables brauchen! Dieses Mal werden die Regeln, die auch vom kube-proxy hinzugefügt werden, von SNAT (Source Network Address Translation), auch bekannt als
IP MASQUERADE (Masquerading), ausgeführt. Anstatt die Quell-IP-Adresse mitzuteilen, wird der Kernel angewiesen, die IP-Schnittstelle zu verwenden, von der das Paket ankommt. In conntrack wird auch ein Datensatz für die weitere Ausführung der Rückwärtsoperation (Un-SNAT) für die Antwort angezeigt.
Eingehender Verkehr
Bisher war alles in Ordnung. Pods können miteinander und mit dem Internet kommunizieren. Es fehlt uns jedoch immer noch die Hauptsache - die Bedienung des Benutzerverkehrs. Derzeit gibt es zwei Möglichkeiten, dies zu implementieren:
1. NodePort / Cloud Load Balancer (L4-Level: IP und Port)
Wenn Sie
NodePort als
NodePort wird der
NodePort Dienst im Bereich von 30.000 bis 33.000 zugewiesen. Dieser
nodePort auf jedem Knoten geöffnet, auch wenn auf dem Knoten kein Pod ausgeführt wird. Eingehender Datenverkehr auf diesem
NodePort an einen der Pods gesendet (der möglicherweise sogar auf einem anderen Knoten
NodePort !), Wieder unter Verwendung von iptables.
Die Art des Dienstes
LoadBalancer in Cloud-Umgebungen erstellt einen Cloud-Load-Balancer (z. B. ELB) vor allen Knoten, der mit demselben
NodePort .
2. Ingress (L7-Level: HTTP / TCP)
Viele andere Implementierungen führen auch eine HTTP-Host- / Pfadzuordnung mit entsprechenden Backends durch, z. B. Nginx, Traefik, HAProxy usw. Mit ihnen werden LoadBalancer und NodePort wieder zum Einstiegspunkt für den Datenverkehr. Hier besteht jedoch der Vorteil, dass wir anstelle zahlreicher NodePort / LoadBalancer nur einen Eingang benötigen, um den eingehenden Datenverkehr aller Dienste zu bedienen.
Netzwerkrichtlinien
Netzwerkrichtlinien können als Sicherheitsgruppen / ACLs für Pods betrachtet werden.
NetworkPolicy Regeln erlauben / verweigern den Verkehr zwischen Pods. Ihre genaue Implementierung hängt von der Netzwerkschicht / CNI ab, aber die meisten von ihnen verwenden einfach iptables.
...
Das ist alles. In den
vorherigen Abschnitten haben wir die Grundlagen des Netzwerks in Kubernetes und die Funktionsweise von Overlays kennengelernt. Jetzt wissen wir, wie die Dienstabstraktion in einem dynamischen Cluster hilft und die Ermittlung von Diensten wirklich einfach macht. Wir haben auch untersucht, wie ausgehender / eingehender Datenverkehr fließt und welche Netzwerkrichtlinien für die Sicherung eines Clusters hilfreich sein können.
PS vom Übersetzer
Lesen Sie auch in unserem Blog: