
Wir bemühen uns sicherzustellen, dass nach der Bestellung eines Taxis beim Benutzer ein sauberes, wartungsfähiges Auto der Marke, Farbe und Nummer, das in der Anwendung angegeben ist, zum Benutzer kommt. Und dafür verwenden wir die Fernqualitätskontrolle (DCC).
Heute werde ich den Lesern von Habr erklären, wie man maschinelles Lernen einsetzt, um die Kosten für die Qualitätskontrolle in einem schnell wachsenden Dienst mit Hunderttausenden von Maschinen zu senken und keine Maschine in Betrieb zu nehmen, die nicht den Regeln des Dienstes entspricht.
Wie wurde DCC vor dem maschinellen Lernen arrangiert?
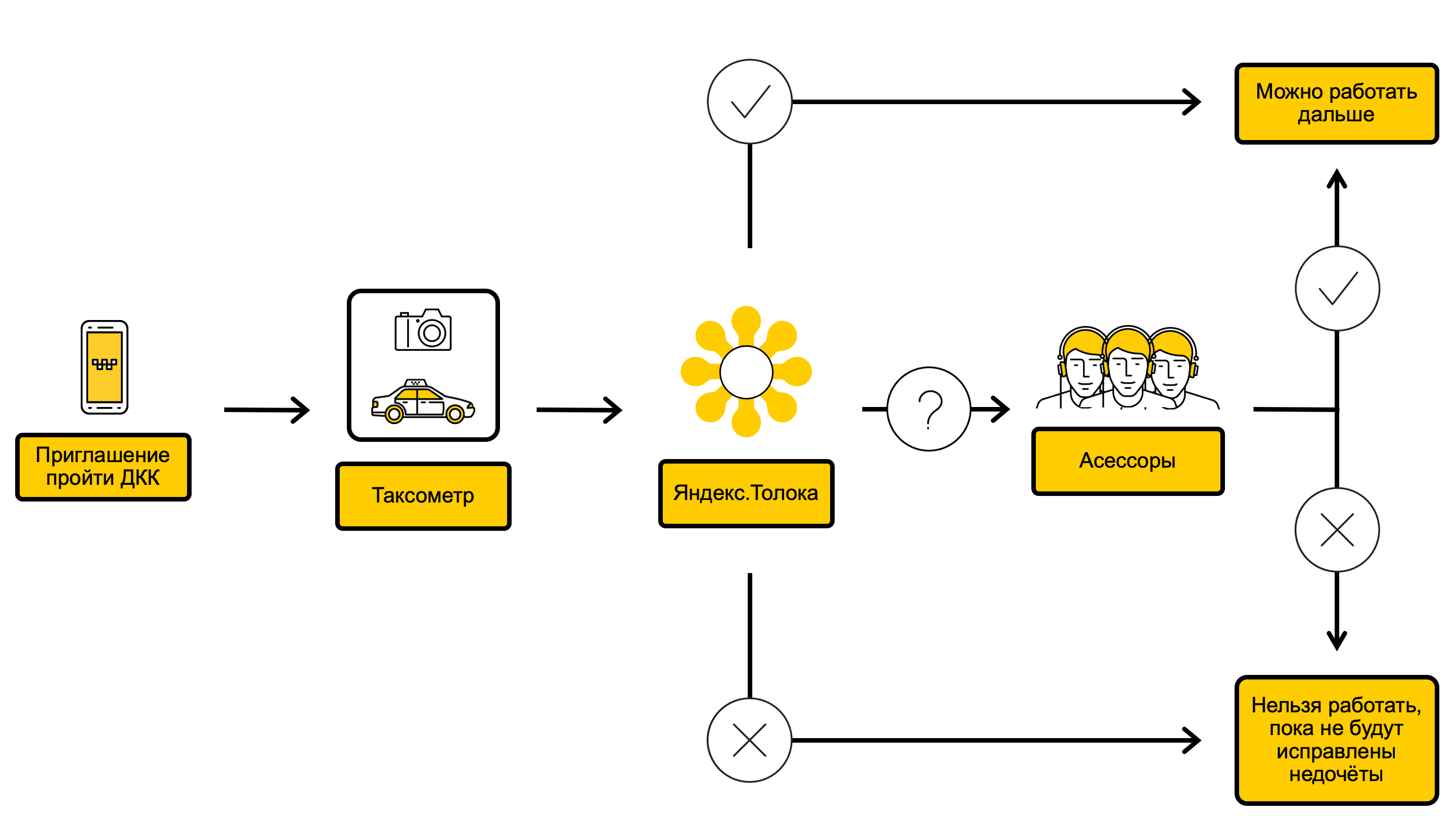
DCC-Prozessdiagramm
Im DCC-Prozess überprüfen wir die Fotos des Autos und entscheiden, ob es möglich ist, Aufträge für ein solches Auto zu erfüllen, oder ob es beispielsweise vorher gewaschen werden sollte. Alles beginnt damit, dass wir über die Treiberanwendung Taximeter den Fahrer auf dem DCC anrufen. Dies geschieht normalerweise alle 10 Tage, manchmal aber auch seltener oder öfter - je nachdem, wie erfolgreich der Fahrer die vorherigen Prüfungen bestanden hat. Unmittelbar nach einem Anruf beim DCC erhält der Fahrer eine Nachricht, in der er aufgefordert wird, sich einer Fotokontrolle zu unterziehen. Sobald der Fahrer die Einladung angenommen hat, fotografiert er im selben Antrag das Äußere und Innere des Autos aus verschiedenen Blickwinkeln und sendet Fotos an Yandex.Taxi. Der Fahrer kann Bestellungen entgegennehmen, während das DCC eingeschaltet ist.

DCC-Startbildschirm in der Taxameter-Anwendung

Bildschirm zum Fotografieren eines Autos in der Taximeter-Anwendung
Die resultierenden Fotos fallen in Yandex.Toloka - einen Dienst, mit dem Sie mithilfe von Crowdsourcing schnell einfache, aber umfangreiche Aufgaben ausführen können. Wie es funktioniert und warum Yandex.Tolok benötigt wird, haben wir in unserem Blog geschrieben .
In Yandex.Tolok beantworten im Rahmen einer Überprüfung mindestens drei Darsteller Fragen zum Zustand des Fahrzeugs. Wenn sich die Darsteller auf der Grundlage ihrer Antworten einig sind, wird entschieden, ob der Fahrer Bestellungen annehmen kann. Schecks in Yandex.Tolok haben zwei Ergebnisse:
- Wenn optisch alles in Ordnung mit dem Auto ist, nimmt der Fahrer weiterhin Bestellungen entgegen.
- Wenn das Auto verschmutzt, beschädigt ist oder Marke, Farbe oder Nummer nicht mit den Angaben auf der Fahrerkarte übereinstimmen, schränkt Yandex.Taxi vorübergehend die Fähigkeit des Fahrers ein, Bestellungen anzunehmen.
Wenn sich die Darsteller nicht einig sind, werden die Fotos an die Mitarbeiter von Yandex.Taxi gesendet - Gutachter, die das Auto gründlicher prüfen und dann die endgültige Entscheidung treffen. Die Prüfer absolvieren ein spezielles Schulungsprogramm und haben mehr Erfahrung.

So sieht der DCC-Testamentsvollstrecker Yandex.Tolki
Herausforderung
Mit dem Wachstum von Yandex.Taxi steigt auch die Anzahl der DCC-Inspektionen, was bedeutet, dass die Kosten für Tolker und Gutachter steigen. Außerdem sinkt die Geschwindigkeit, mit der das Auto überprüft wird. Während des DCC können Sie den Fahrern entweder erlauben, Bestellungen anzunehmen, oder nicht. Beide Optionen haben ihre Nachteile: Im ersten Fall hat ein skrupelloser Fahrer Zeit, mehrere Bestellungen für ein Auto anzunehmen, das nicht den Standards entspricht. Im zweiten Fall können alle Fahrer, die eine Fotokontrolle benötigen, erst nach Abschluss der Prüfung arbeiten. Daher ist es wichtig, Autos schnell zu überprüfen, damit sowohl Benutzer als auch Fahrer keine Unannehmlichkeiten haben.
Als wir beobachteten, wie die Diagramme der Kosten und der durchschnittlichen Inspektionszeit wachsen, haben wir erkannt, dass wir die Kosten für Toloka senken, Gutachter entladen und die durchschnittliche Inspektionszeit reduzieren möchten, mit anderen Worten, um einen Teil der Inspektionen zu automatisieren. Natürlich wollten wir nicht auf die Servicequalität verzichten und mehr Autos verpassen, die nicht den Qualitätsstandards für die Linie entsprachen, und wir wollten auch die Annahme von Bestellungen durch gutgläubige Fahrer nicht einschränken. Wir mussten das DCC automatisieren und gleichzeitig den Fehleranteil am gesamten Überprüfungsfluss nicht erhöhen.
Wie wir maschinelles Lernen bei DCC implementiert haben
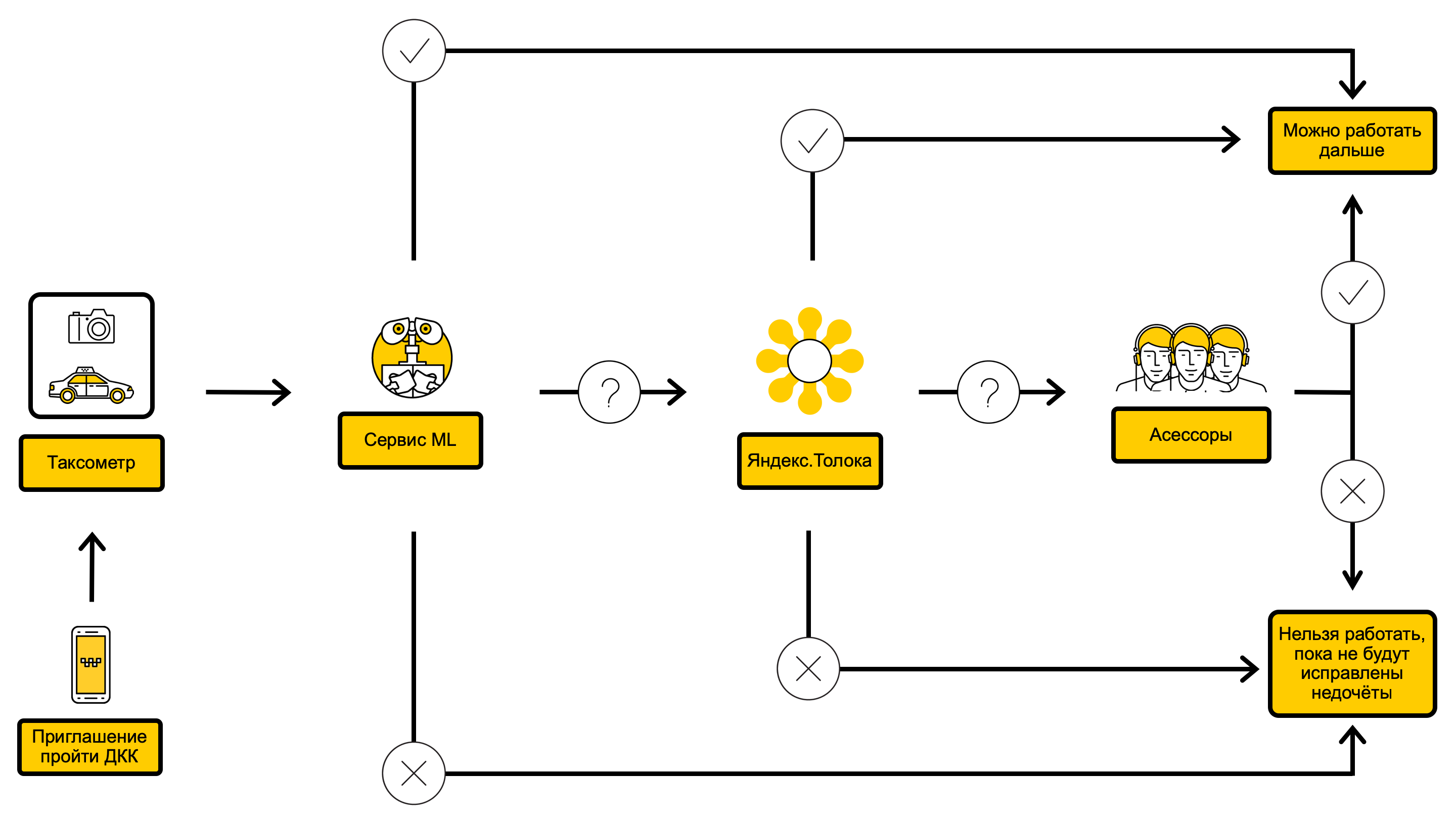
DCC-Prozessdiagramm mit ML im Inneren
Zunächst haben wir uns für die Problemstellung entschieden: So viele Überprüfungen wie möglich zu automatisieren, ohne die Fehlerrate im Gesamtfluss zu erhöhen.
Lassen Sie uns herausfinden, welche Fehler in unserer Aufgabe liegen. Sie kommen in zwei Formen vor: falsch positiv und falsch negativ . In unserer Terminologie ist negativ das Ergebnis einer Prüfung, mit der der Fahrer weiterarbeiten kann, und positiv ist das Ergebnis, das eine zeitliche Begrenzung für den Eingang von Bestellungen vorsieht. Dann ist falsch negativ ein Fall, in dem wir gezwungen waren, einem Fahrer mit einem schlechten Auto zu erlauben, Befehle entgegenzunehmen, und falsch positiv - im Gegenteil, als wir einem Fahrer nicht erlaubten, mit einem Auto zu arbeiten, das in Ordnung ist. Es stellt sich heraus, dass die False Negative Rate (FNR) der Anteil der Fahrer mit „schlechten“ Autos ist, mit denen wir Bestellungen annehmen durften, und die False Positive Rate (FPR) der Prozentsatz der Fahrer, mit denen wir nicht arbeiten durften, obwohl sie mit Autos in Ordnung sind. Seit der Einführung des maschinellen Lernens in das System wollten wir daher Folgendes: Automatisieren Sie so viele Überprüfungen wie möglich, ohne die FPR und FNR im Vergleich zu einem System ohne maschinelles Lernen zu erhöhen.
Darüber hinaus musste verstanden werden, an welchen Metriken bei der Auswahl von Modellen und Schwellenwerten für Entscheidungen auf der Grundlage ihrer Vorhersagen zu orientieren ist. Aus den Bedingungen des Problems geht hervor, dass wir an drei Größen interessiert sind:
- Der Bruchteil des Threads, den Modelle für maschinelles Lernen automatisch beantworten können.
- FNR-Systeme.
- FPR-Systeme.
Wir maximieren den ersten Wert und beachten dabei die Einschränkungen für den zweiten und dritten.
Dies kann die Frage aufwerfen: Warum nicht die Einsparung von Geld maximieren oder die durchschnittliche Scanzeit direkt minimieren und nicht durch den Anteil automatisierter Überprüfungen? Geldoptimierung ist eine sehr attraktive Idee, aber normalerweise schwer umzusetzen. In unserem Fall bestehen die Einsparungen aus zwei Faktoren: Der erste ist die Einsparung aus jedem automatisierten Scheck, da jeder Scheck bei Assessoren oder in Yandex.Tolok Geld kostet; Das zweite Problem ist die Reduzierung der Fehleranzahl, da jeder Fehler Yandex.Taxi-Geld kostet. Die objektive Berechnung der Kosten für Fehler ist eine sehr schwierige Aufgabe. Daher beschränken wir uns darauf, Einsparungen nur anhand des ersten Faktors zu berechnen. Dieser Wert erhöht sich monoton im Anteil der automatisierten Prüfungen, so dass dieser Anteil maximiert werden kann, anstatt zu sparen. Die gleiche Überlegung gilt für die durchschnittliche DCC-Zeit, sie nimmt auch entsprechend dem Anteil der automatisierten Überprüfungen monoton ab.
Modellauswahl
Wir können sagen, dass die DCC-Prüfung auf die Auswahl von Antwortoptionen für eine Reihe von Fragen zum Zustand des Autos auf den Fotos reduziert ist, und dies klingt nach einer Bildklassifizierungsaufgabe. Solche Aufgaben werden durch Computer Vision gelöst und in unserer Zeit - ein spezifisches Werkzeug, Faltungs-Neuronale Netze. Wir haben uns entschieden, sie für die DCC-Automatisierung zu verwenden.
Die erste Lösung oder "alles auf einmal" Ansatz
Nachdem wir verstanden haben, was zu optimieren ist und warum, ist es an der Zeit, Daten zu sammeln und Modelle darauf zu trainieren. Das Sammeln von Daten war einfach, da alle DCC-Prüfungen protokolliert und in einer praktischen Form gespeichert werden. In der ersten Version der Lösung wurden die Fotos von außen und innen des Fahrzeugs aus vier Winkeln, Marke, Modell und Farbe des Fahrzeugs sowie die Ergebnisse von 10 früheren DCC-Inspektionen als Zeichen verwendet. Als Zielvariablen haben wir die Antworten auf alle Überprüfungsfragen verwendet, zum Beispiel: "Ist das Auto beschädigt?" oder "Stimmt die Farbe des Autos mit der auf der Fahrerkarte überein?" Die Hauptzielvariable war die Antwort auf die Hauptfrage: "Ist es notwendig, die Fähigkeit des Fahrers, Bestellungen entgegenzunehmen, einzuschränken?" Wir haben einem großen Modell, das VGG mit SENet-Aufmerksamkeit sehr ähnlich ist, beigebracht, alle Fragen gleichzeitig zu beantworten, und als Ergebnis sind wir auf mehrere Probleme gestoßen.

All-in-One-Ansatz
Probleme des "Alles auf einmal" -Ansatzes:
- Wir konnten die Frage nach der Übereinstimmung der Fahrzeugnummer auf dem Foto auf der Fahrerkarte nicht beantworten. Ein großes Netzwerk zur Klassifizierung von Bildern konnte diese Aufgabe nicht bewältigen. Dazu benötigen wir ein spezielles OCR-Modell (Optical Character Recognition), das zur Erkennung von Nummernschildern geschärft wurde.
- Die Zielvariable war unvollständig und verrauscht. Als die Prüfer einen schwerwiegenden Fehler im Erscheinungsbild des Autos fanden, der ausreichte, um eine Entscheidung zu treffen, vergaßen sie oft, andere Fragen zu beantworten. Wenn also das Auto auf dem Foto sowohl schmutzig als auch kaputt war, haben wir mit hoher Wahrscheinlichkeit nur eine der Markierungen beobachtet: "schmutziges Auto" oder "Auto mit Beschädigung", während beide Modelle für unser Modell benötigt wurden.
- Es gab keine Interpretierbarkeit der Modelllösung. Das Modell könnte die Hauptüberprüfungsfrage mit einer Genauigkeit beantworten, die höher als zufällig ist, aber diese Antwort korrelierte schwach mit den Antworten auf andere Fragen. Mit anderen Worten, wenn die Antwort lautete: „Es ist notwendig, die Fähigkeit zur Annahme von Bestellungen einzuschränken“, haben wir den Grund für eine solche Entscheidung in den verbleibenden Antworten des Modells fast nie gesehen. Im Allgemeinen war die Genauigkeit der Antworten auf alle Fragen mit Ausnahme der Hauptfrage nahezu zufällig. Wir konnten dem Fahrer nicht erklären, was genau repariert werden musste, um Bestellungen wieder entgegenzunehmen, was bedeutet, dass wir die Fähigkeit des Fahrers, Bestellungen entgegenzunehmen, nicht einschränken konnten.
- Die Anzahl der falsch negativen Fehler in der Antwort auf die Frage: "Ist es notwendig, die Fähigkeit des Fahrers, Bestellungen entgegenzunehmen, einzuschränken?" - war zu groß, um Schecks automatisch zu genehmigen. Wir konnten nicht das gleiche FNR wie in einem System bereitstellen, das ohne maschinelles Lernen läuft, und dies war eine der Anforderungen in unserer Aufgabe.
Zusammen haben diese vier Gründe es uns nicht ermöglicht, die erste Lösung in die Praxis umzusetzen, aber wir haben nicht den Mut verloren und die zweite gefunden.
Die zweite Lösung oder der Ansatz „alles andere als allmählich“
Wir haben uns entschlossen, das Äußere des Autos zu überprüfen, da diese etwa 70% des Gesamtdurchflusses ausmachen. Darüber hinaus haben wir beschlossen, die allgemeine Aufgabe in Unteraufgaben zu unterteilen und zu lernen, wie alle DCC-Fragen separat beantwortet werden.

Nähere dich "alles, aber allmählich"
Es war einmal, dass unser Service bereits mit der DCC-Automatisierung befasst war und es gelang, ein Modell einzuführen, mit dem Sie dunkle und irrelevante Fotos filtern können. Wir haben dieses Modell weiter verwendet, um die Frage zu beantworten: „Sind die folgenden echten Fotos des Autos vorhanden: vorne, links, rechts, hinten?“.
Unsere Arbeit an der zweiten Lösung begann mit der Tatsache, dass wir das Yandex. Search Computer Vision-Servicemodell (von genau den Leuten, die DeepHD hergestellt haben ) verwendet haben, um Nummernschilder an Autos zu erkennen. So konnten wir die Frage beantworten: "Entsprechen Nummer und Code der Region des Autos vollständig den Angaben auf der Fahrerkarte?" Wenn wir genauer darüber sprechen, haben wir das Erkennungsergebnis mit der auf der Fahrerkarte angegebenen Nummer verglichen und je nach Levenshtein-Abstand zwischen ihnen eine der Antwortoptionen gewählt: "Die Nummer stimmt überein", "Die Nummer stimmt nicht überein" oder "Die Frage kann nicht genau beantwortet werden".
Als nächstes haben wir Fahrzeugklassifizierer geschult, um Marken und Modelle sowie Farben zu erkennen. Von diesem Moment an konnten wir die Frage beantworten: "Sind Marke, Modell und Farbe des Autos auf der Fahrerkarte angegeben?"
Zusammenfassend haben wir Klassifikatoren geschult, um beschädigte und schmutzige Autos zu finden. Dadurch konnten wir die Fragen schließen: „Gibt es Schäden oder Mängel an der Karosserie?“ und "Wie schmutzig ist die Karosserie?"
Der Ansatz „alles andere als allmählich“ ermöglichte es uns, das Problem der Überprüfung des Kennzeichens eines Autos zu lösen. Wir konnten auch die Unvollständigkeit und das Rauschen der Zielvariablen beseitigen, da wir nun eine Auswahl hatten, bei der negative Klassenobjekte vollständig erfolgreich überprüft wurden, und positive Klassenobjekte, bei denen der Prüfer oder alle drei Yandex.Tolki-Testamentsvollstrecker einen bestimmten Fehler fanden, beispielsweise eine Beschädigung des Falls . Nachdem wir die ersten beiden Probleme gelöst hatten, wurden unsere Modelle interpretierbar, und wir konnten dem Fahrer den Grund für die Einschränkung erklären, damit er beim nächsten Test die Fehler korrigieren konnte. Die Gesamtqualität der Antworten auf Fragen hat ebenfalls erheblich zugenommen, und FPR und FNR für einige Kombinationen von Modellvertrauensschwellen sind auf das Yandex.Tolki-Niveau gefallen, wodurch die Modelle in die Produktion eingeführt werden konnten.
Implementierung in der Produktion
Wir hatten die Wahl: einen regulären Prozess zu starten, der die Modelle auf die in der Warteschlange gesammelten Schecks anwendet, oder einen separaten Dienst zu erstellen, bei dem Sie über die API Modellantworten in Echtzeit erhalten können. Da es für uns wichtig ist, schnell „schlechte“ Autos zu finden, haben wir uns für die zweite Option entschieden. Sobald der Hauptteil des Dienstes geschrieben wurde und die erforderlichen Funktionen unterstützt werden konnten, haben wir begonnen, Modelle hinzuzufügen.
Um die Prüfung vollständig zu genehmigen, müssen Sie in der Lage sein, alle Fragen der Anweisung zu beantworten. Um jedoch den skrupellosen Zugriff der Fahrer auf den Dienst einzuschränken, reicht es in einigen Fällen aus, mindestens eine Frage beantworten zu können. Aus diesem Grund haben wir uns entschlossen, nicht zu warten, bis alle Modelle fertig sind, sondern sie hinzuzufügen, sobald sie verfügbar sind. Eine verallgemeinerte Pipeline zum Hinzufügen eines Modells sieht folgendermaßen aus:
- Sammeln Sie die Probe.
- Trainiere das Modell.
- Messen Sie die Qualität und wählen Sie die Schwellenwerte offline.
- Fügen Sie dem Service im Hintergrund ein Modell hinzu und messen Sie die Qualität online.
- Nehmen Sie das Modell in die Produktion auf und treffen Sie Entscheidungen auf der Grundlage seiner Vorhersagen.
Dieser Ansatz ermöglichte es uns, nicht nur sofort mehr und mehr „schlechte“ Autos zu finden, wenn neue Modelle eingeführt wurden, sondern auch die Qualität online ohne zusätzliche Zeitkosten zu messen, während die Modelle im Hintergrund arbeiteten.
Am Ende kam der Moment, als wir den Service erweiterten und das neueste Modell testeten. Jetzt konnten wir alle Fragen der Inspektionen beantworten, was bedeutet, dass sie automatisch genehmigt werden. Da es in Yandex.Taxi viel mehr „gute“ Autos als „schlechte“ gibt, hat die automatische Genehmigung von Inspektionen zu einem starken Anstieg unserer Hauptmetrik geführt - einem Teil des Stroms automatisierter Inspektionen. Wir konnten nur die richtigen Schwellenwerte auswählen, die den Anteil automatisierter Überprüfungen maximieren und gleichzeitig den Gesamt-FPR und den FNR des gesamten Systems auf demselben Niveau halten. Zur Auswahl der Schwellenwerte haben wir eine Stichprobe verwendet, die unabhängig von Yandex.Tolki-Testamentsvollstreckern, Assessoren und einem Yandex.Taxi-Mitarbeiter markiert wurde, der Assessoren für die Überprüfung von Autos geschult hat. Wir haben das Markup als die wahren Werte der Zielvariablen verwendet.
Ergebnisse
Sobald wir Modelle in die Produktion aufgenommen hatten, war es notwendig, die Online-Qualität der getroffenen Entscheidungen anhand ihrer Antworten zu messen. Und hier sind die Zahlen, die wir gesehen haben:
- 30% der Fahrzeugaußenkontrollen erhielten jetzt eine automatische Antwort.
- FNR blieb auf dem gleichen Niveau, während FPR fiel, und wir begannen, den Zugang zu dem Dienst weniger häufig auf diejenigen zu beschränken, die ihn nicht verdienten.
- Die Belastung der Prüfer verringerte sich um 14%, und sie konnten mehr Zeit für komplexe Tests aufwenden, die der maschinelle Lerndienst nicht übernehmen konnte.
- Die Erkennungszeit für Fahrzeuge mit schwerwiegenden Fehlern während der Inspektion wurde von einigen Stunden auf einige Sekunden reduziert.
Die Einführung des maschinellen Lernens half nicht nur, Geld zu sparen, sondern machte den Dienst auch sicherer und komfortabler für die Benutzer. Dies ist jedoch noch lange nicht das Ende der Geschichte. Unser schnell wachsendes Team wird weiterhin aktiv daran arbeiten, noch mehr Überprüfungen zu automatisieren und Yandex.Taxi noch komfortabler, komfortabler und sicherer zu machen.
Moral der Geschichte
Bei der Arbeit an der DCC-Automatisierung in Yandex.Taxi sind wir auf viele Probleme gestoßen, haben mehrere erfolgreiche Lösungen gefunden und sechs wichtige Schlussfolgerungen gezogen:
- Es ist nicht immer möglich, das Problem direkt zu lösen (selbst wenn Sie Deep Learning haben).
- Das Modell ist so gut wie die Daten, auf denen es trainiert wurde (klingt kitschig, ist es aber).
- Bei der Lösung eines Problems ist es wichtig, auf den tatsächlichen Anforderungen des Unternehmens aufzubauen und nicht auf der Minimierung der Cross-Entropie.
- Bei der Lösung einiger Probleme sind die Menschen trotz der Einführung des maschinellen Lernens immer noch wichtig (Hallo, Yandex.Toloka!).
- Entscheidungen, die auf Vorhersagen von Modellen für maschinelles Lernen basieren, können möglicherweise nicht in allen Fällen getroffen werden, sondern nur in dem Teil, in dem die Modelle sehr sicher in ihren Antworten sind. In anderen Fällen lohnt es sich wahrscheinlich, Entscheidungen auf die alte Art und Weise zu treffen - mit Hilfe von Menschen.
- Neben der Wahl der Architektur und der Modellschulung gibt es viele weitere Phasen des Projekts, die einen großen Einfluss darauf haben können, wie gut ein Geschäftsproblem gelöst wird. Diese Phasen sind: Datenerfassung, Auswahl von Qualitätsmetriken, Modellimplementierungsoptionen, Produktentscheidungslogik basierend auf Modellvorhersagen und vieles mehr.
Mehr von interessant über Technologie Taxi
Dynamische Preisgestaltung oder wie Yandex.Taxi eine hohe Nachfrage vorhersagt .
Wie Yandex.Taxi die Lieferzeiten von Autos mithilfe von maschinellem Lernen vorhersagt .