Bei der Entwicklung eines Produkts wird selten auf die Leistung bei einer hohen Intensität eingehender Anfragen geachtet. Wenig oder gar nichts tun - es gibt nicht genug Zeit, Spezialisten, oder sie rechtfertigen sich mit dem typischen Satz: "Bei uns funktioniert alles schnell, also warum etwas anderes überprüfen?" In solchen Fällen kann es vorkommen, dass eine gut funktionierende Produktion aufgrund des wachsenden Besucherstroms, beispielsweise unter dem Habraeffekt, plötzlich ausfällt. Dann wird klar, dass Produktivitätsforschung wirklich notwendig ist.
Diese Aufgabe verwirrt viele, weil es einen Bedarf gibt, aber es gibt kein klares Verständnis dafür, was und wie zu messen und wie das Ergebnis zu interpretieren ist. Manchmal gibt es keine gebildeten nicht funktionalen Anforderungen. Als Nächstes werde ich darüber sprechen, wo Sie anfangen sollen, wenn Sie sich für diesen Weg entscheiden, und erläutern, welche Metriken für die Leistungsforschung wichtig sind und wie sie verwendet werden.
Ein bisschen Theorie
Stellen Sie sich vor, wir haben eine sphärische Anwendung im luftleeren Raum - sie empfängt Anfragen und gibt Antworten darauf. Der Einfachheit halber kann es sich um einen Mikrodienst mit einer Methode handeln, die nirgendwohin führt und nicht von anderen Komponenten oder Anwendungen abhängt. In diesem Fall interessiert uns nicht viel, worauf es geschrieben steht, wie es funktioniert und in welcher Umgebung es gestartet wird.
Was wollen wir über die Leistung im Allgemeinen wissen? Es ist wahrscheinlich gut, den maximalen Datenstrom eingehender Anforderungen zu kennen, bei dem der Dienst stabil ist, seine Leistung mit diesem Datenstrom und die Zeit, die zum Abschließen einer Anforderung benötigt wird. Es ist sehr gut, wenn Sie die Gründe ermitteln können, die das weitere Produktivitätswachstum einschränken.
Natürlich müssen Sie die Antwortzeit auf die Anforderung anhand des Flusses eingehender Anforderungen oder der Intensität messen. Wir meinen die Anzahl der Anforderungen pro Zeiteinheit, normalerweise pro Sekunde, und die Leistung - die Anzahl der Antworten auf dieselbe Zeiteinheit. Die Reaktionszeiten können über einen weiten Bereich verteilt sein. Daher ist es zunächst sinnvoll, sie als Durchschnitt pro Sekunde darzustellen.
Darüber hinaus können Probleme auf verschiedenen Ebenen auftreten: beginnend mit der Tatsache, dass der Dienst mit einem Fehler antwortet (und es ist gut, wenn es fünfhundert sind, und nicht "200 OK {" status ":" error "}", und endend mit der Tatsache, dass dies der Fall ist reagiert überhaupt nicht mehr oder Antworten gehen auf Netzwerkebene verloren. Nicht erfolgreiche Anfragen müssen abfangen können, und es ist zweckmäßig, sie als Prozentsatz der Gesamtzahl anzuzeigen. Das Diagramm von Leistung, Reaktionszeit und Fehlerrate in Abhängigkeit von der Intensität sieht ungefähr so aus:
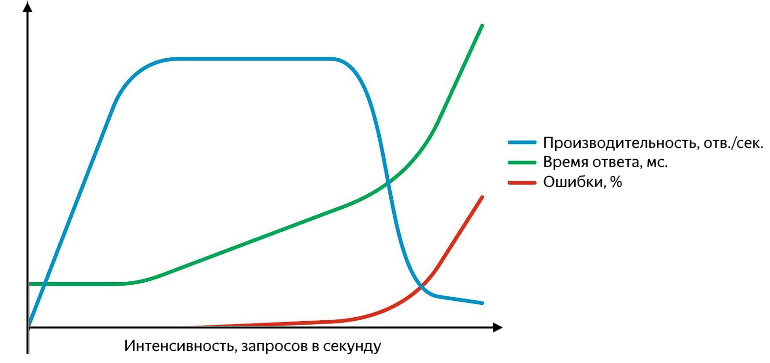
Mit zunehmender Abfrageintensität nehmen Antwortzeit und Fehlerrate zu
Während die Produktivität linear mit der Intensität wächst, geht es dem Service gut. Es verarbeitet erfolgreich den gesamten eingehenden Anforderungsstrom, die Antwortzeit ändert sich nicht, es gibt keine Fehler. Wenn wir die Intensität weiter erhöhen, verlangsamen wir das Produktivitätswachstum bis zur Sättigung, wobei die Produktivität ihr Maximum erreicht und die Reaktionszeit zu wachsen beginnt. Eine nachfolgende Erhöhung der Intensität führt zu Verwirrung - eine signifikante Erhöhung der Reaktionszeit und ein Rückgang der Produktivität, ein aktives Wachstum von Fehlern wird beginnen. In der Phase des Wachstums und der Sättigung gibt es zwei wichtige Punkte - normale und maximale Leistung.
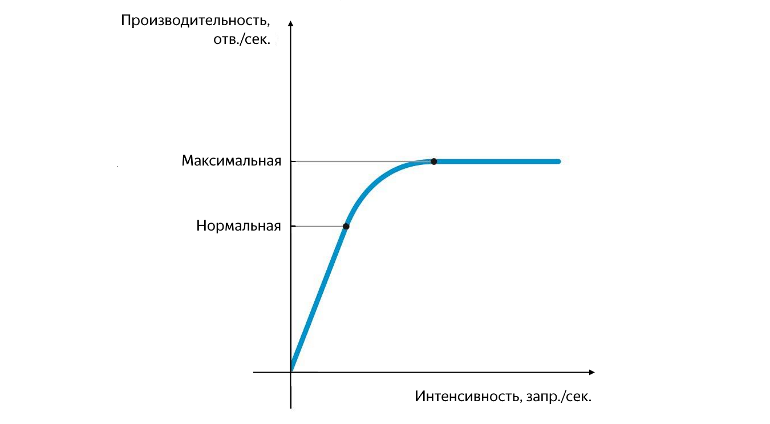
Normale und maximale Leistungsposition
Die normale Produktivität wird in dem Moment erreicht, in dem die Wachstumsrate zu sinken beginnt, und maximal - in dem Moment, in dem die Wachstumsrate Null wird. Die Trennung der Leistung zwischen normal und maximal ist sehr wichtig. Bei einer Intensität, die der normalen Leistung entspricht, sollte die Anwendung stabil arbeiten, und der Wert der normalen Leistung kennzeichnet den Schwellenwert, ab dem der Engpass des Dienstes auftritt, der sich negativ auf seinen Betrieb auswirkt. Wenn die maximale Leistung erreicht ist, beginnt der Engpass das weitere Wachstum vollständig einzuschränken, der Service ist instabil und in der Regel tritt in diesem Moment ein kleiner, aber stabiler Hintergrund mit Fehlern auf.
Das Problem kann aus verschiedenen Gründen verursacht werden: Warteschlangen sind blockiert, es sind nicht genügend Threads vorhanden, der Pool ist erschöpft, die CPU oder der RAM wurden vollständig ausgelastet, die Lese- / Schreibgeschwindigkeit von der Festplatte ist unzureichend und dergleichen. Es ist wichtig zu verstehen, dass die Korrektur eines Engpasses dazu führt, dass die Leistung durch den nächsten eingeschränkt wird und so weiter. Es ist unmöglich, einen Engpass vollständig zu beseitigen, er kann nur verschoben werden.
Die Experimente
Zunächst muss die Größe der Intensität, mit der der Dienst die normale und maximale Leistung erreicht, und die entsprechende durchschnittliche Antwortzeit bestimmt werden. Zu diesem Zweck reicht es in einem Experiment aus, den Fluss eingehender Anforderungen einfach zu erhöhen. Es ist schwieriger, den Wert der maximalen Intensität und die Zeit des Experiments zu bestimmen.
Sie können von dem ausgehen, was in nicht funktionalen Anforderungen (falls vorhanden) geschrieben ist, von der maximalen Benutzerlast aus dem Verkauf oder einfach von der Obergrenze. Wenn die Intensität des eingehenden Streams nicht ausreicht, hat der Dienst keine Zeit, um die Sättigung zu erreichen, und das Experiment muss wiederholt werden. Wenn die Intensität zu hoch ist, erreicht der Dienst sehr schnell die Sättigung und führt dann das Debuggen durch. In einem solchen Fall ist eine Überwachung zweckmäßig, damit Sie bei einer signifikanten Zunahme der Fehleranzahl nicht umsonst Zeit verschwenden und das Experiment beenden.
In unseren Experimenten erhöhen wir die Intensität für 10 Minuten schrittweise von 0 auf 1000 Anfragen pro Sekunde. Dies reicht aus, damit der Dienst die Sättigung erreicht, und dann passen wir bei Bedarf die Zeit und Intensität im nächsten Experiment an, um ein genaueres Ergebnis zu erhalten. In den obigen Grafiken war alles glatt und schön, aber in der realen Welt kann es auf den ersten Blick schwierig sein, den Wert der normalen Leistung zu bestimmen.
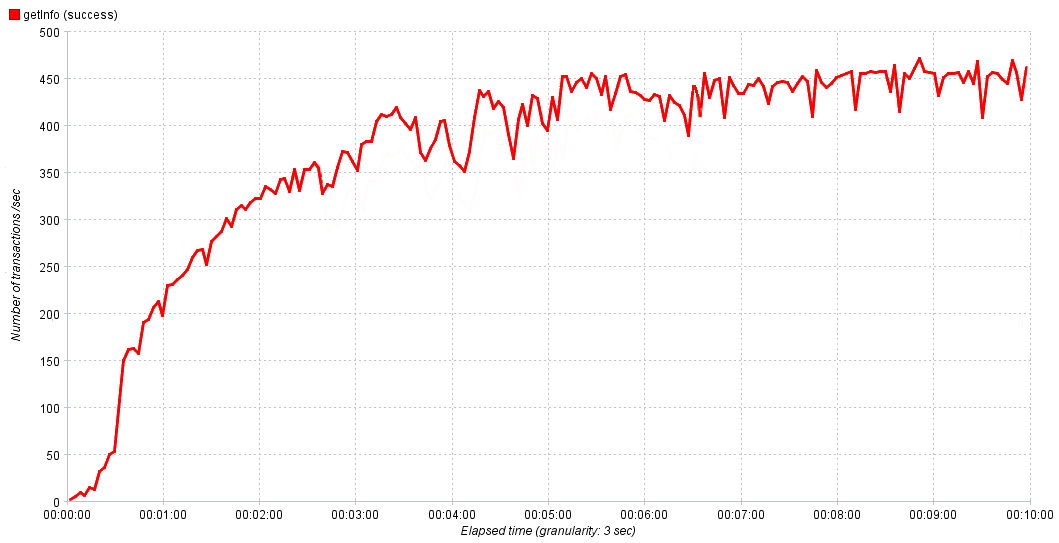
Die tatsächliche Abhängigkeit der Serviceleistung von der Zeit
In diesem Fall nehmen wir 80-90% des Maximums für die normale Leistung. Wenn wir nach Erreichen der Sättigung ein aktives Wachstum von Fehlern beobachten, ist es sinnvoll, diese zu untersuchen, da sie das Ergebnis eines Engpasses sind. Wenn Sie sie untersuchen, können Sie sie lokalisieren und zur Korrektur weitergeben.
So werden die ersten Ergebnisse erhalten. Jetzt kennen wir die normale und maximale Anwendungsleistung sowie die entsprechenden Antwortzeiten. Ist das alles Natürlich nicht! Bei normaler Leistung sollte der Dienst stabil funktionieren, was bedeutet, dass Sie den Betrieb für eine Weile unter normaler Last überprüfen müssen. Welches? Sie können sich erneut die nicht funktionalen Anforderungen ansehen, Analysten fragen oder die Dauer der Perioden maximaler Aktivität auf dem Produkt überwachen. In unseren Experimenten erhöhen wir die Last linear von 0 auf normal und stehen 10-15 Minuten darauf. Dies ist ausreichend, wenn die maximale Benutzerlast erheblich geringer als normal ist. Wenn sie jedoch vergleichbar sind, sollte die Versuchszeit verlängert werden.
Um das Ergebnis eines Experiments schnell auszuwerten, ist es zweckmäßig, die erhaltenen Daten in Form der folgenden Metriken zu aggregieren:
- durchschnittliche Antwortzeit
- Median
- 90% Perzentil
- % Fehler
- Leistung.
Die durchschnittliche Antwortzeit ist verständlich, aber der Durchschnitt ist nur bei einer Normalverteilung der Stichprobe ein angemessenes Maß, da er zu empfindlich gegenüber „Ausreißern“ ist - zu großen oder zu kleinen Werten, die stark vom allgemeinen Trend abweichen. Der Median ist die Mitte der gesamten Stichprobe der Antwortzeiten, die Hälfte der Werte ist kleiner als der Rest, der Rest ist größer. Warum wird es benötigt?
Erstens ist es aufgrund seiner Definition weniger empfindlich gegenüber Ausreißern, dh es ist eine adäquatere Metrik, und zweitens kann man durch Vergleich mit dem Durchschnitt die Merkmale der Antwortverteilung schnell beurteilen. Im Idealfall sind sie gleich - die Verteilung der Antwortzeiten ist normal und der Service ist in Ordnung!
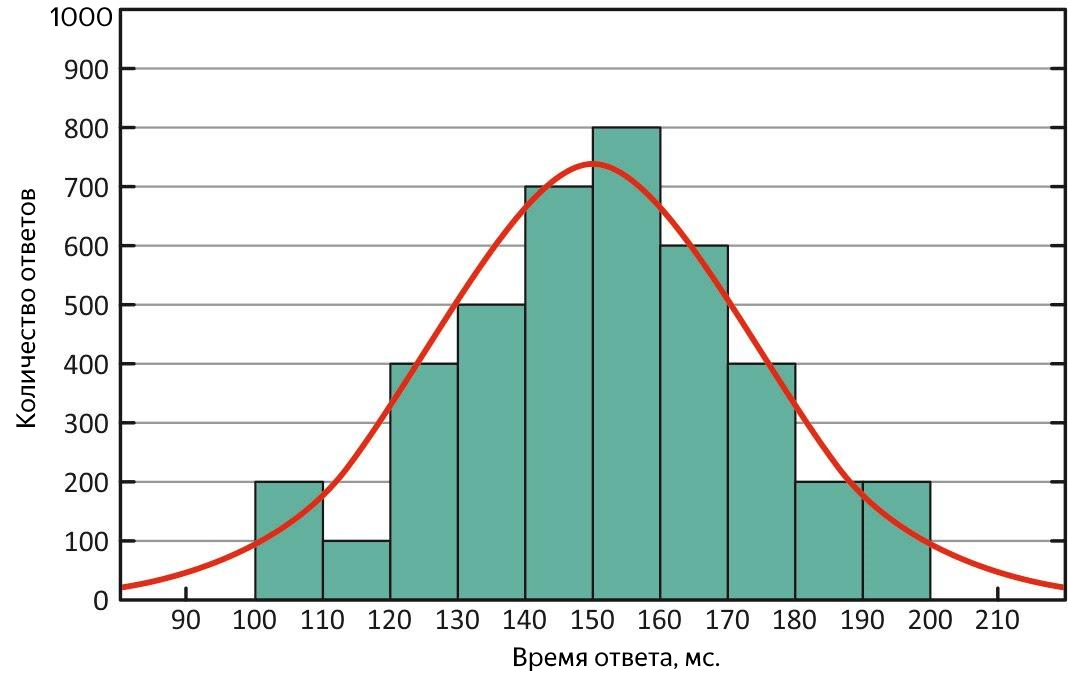
Normalverteilung der Antwortzeiten. Bei dieser Verteilung sind Mittelwert und Median gleichwertig
Wenn der Durchschnitt stark vom Median abweicht, ist die Verteilung verzerrt und es können während des Experiments „Ausreißer“ vorhanden sein. Wenn der Durchschnitt höher ist - es gab Zeiträume, in denen der Dienst sehr langsam reagierte, mit anderen Worten, er verlangsamte sich.
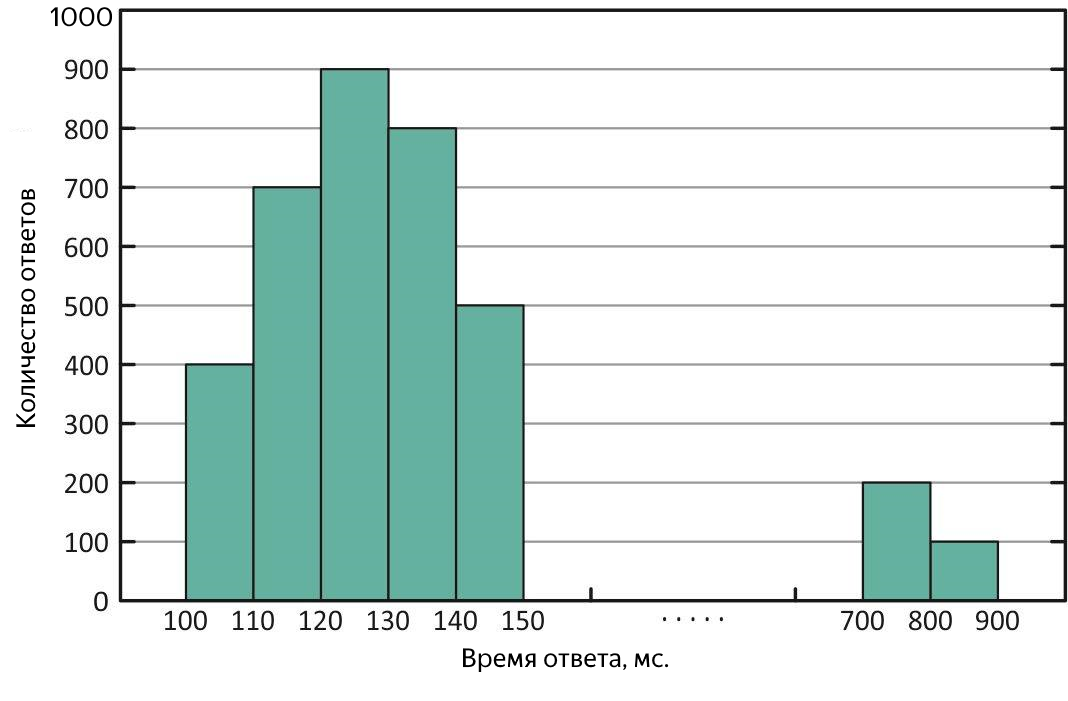
Verteilung der Antwortzeiten mit "Ausreißern" langer Antworten. Bei dieser Verteilung ist der Durchschnitt größer als der Median.
Solche Fälle erfordern eine zusätzliche Analyse. Um das Ausmaß der „Emissionen“ abzuschätzen, helfen Quantile oder Perzentile.
Ein Quantil ist im Kontext der erhaltenen Stichprobe der Wert der Antwortzeit, zu der der entsprechende Teil aller Anforderungen passt. Wenn Sie% der Abfragen verwenden, ist dies das Perzentil (der Median ist übrigens 50% Perzentil). Es ist zweckmäßig, ein 90% -Perzentil zur Abschätzung der Emissionen zu verwenden. Als Ergebnis des Experiments wurde beispielsweise ein Median von 100 ms erhalten, und der Durchschnitt von 250 ms übersteigt den Median um das 2,5-fache! Offensichtlich ist dies nicht ganz gut, wir betrachten ein 90% -Quantil und dort 1000 ms - bis zu 10% aller erfolgreichen Anfragen wurden länger als eine Sekunde abgeschlossen, ein Durcheinander, Sie müssen es herausfinden. Um nach langen Abfragen zu suchen, können Sie in die Datei mit den Versuchsergebnissen oder sofort in die Serviceprotokolle beißen. Es ist jedoch noch besser, die durchschnittliche Antwortzeit in Form eines Diagramms gegenüber der Zeit darzustellen. Sie zeigt sofort sowohl die Zeit als auch die Art der verfügbaren "Ausreißer" an.
Zusammenfassung
Sie haben die Experimente also erfolgreich durchgeführt und die Ergebnisse erhalten. Ob es gut oder schlecht ist, hängt von den Anforderungen für den Service ab, aber nicht die erhaltenen Zahlen sind wichtiger, sondern warum diese Zahlen sind und zu verstehen, durch was weiteres Wachstum begrenzt ist. Wenn es Ihnen gelingt, einen Engpass zu finden - sehr gut, wenn nicht, kann der Bedarf an Produktivität früher oder später steigen, und Sie müssen immer noch danach suchen, sodass es manchmal einfacher ist, der Situation zuvorzukommen.
In dieser Notiz gab ich einen grundlegenden Ansatz zur Leistungsforschung, indem ich Fragen beantwortete, die ich zu Beginn hatte. Haben Sie keine Angst, die Leistung zu recherchieren, es ist notwendig!
PS
Besuchen Sie unseren gemütlichen Telegramm-Chatraum, in dem Sie Fragen stellen, Ratschläge geben und einfach über Leistungsforschung sprechen können.