Hallo Habr! Ich heiße Pavel Lipsky. Ich bin Ingenieur und arbeite für Sberbank-Technology. Meine Spezialisierung ist das Testen der Fehlertoleranz und Leistung der Backends großer verteilter Systeme. Einfach gesagt, ich breche die Programme anderer Leute. In diesem Beitrag werde ich über die Fehlerinjektion sprechen - eine Testmethode, mit der Sie Probleme im System finden können, indem Sie künstliche Fehler verursachen. Ich beginne damit, wie ich zu dieser Methode gekommen bin, dann werden wir über die Methode selbst sprechen und wie wir sie verwenden.
Der Artikel enthält Java-Beispiele. Wenn Sie nicht in Java programmieren - es ist in Ordnung, verstehen Sie einfach den Ansatz selbst und die Grundprinzipien. Apache Ignite wird als Datenbank verwendet, aber die gleichen Ansätze gelten für jedes andere DBMS. Alle Beispiele können von meinem
GitHub heruntergeladen werden.
Warum brauchen wir das alles?
Ich werde mit der Geschichte beginnen. 2005 habe ich für Rambler gearbeitet. Zu diesem Zeitpunkt wuchs die Anzahl der Rambler-Benutzer rapide und unsere zweistufige Architektur "Server - Datenbank - Server - Anwendungen" wurde nicht mehr bewältigt. Wir haben darüber nachgedacht, wie Leistungsprobleme gelöst werden können, und auf die zwischengespeicherte Technologie aufmerksam gemacht.
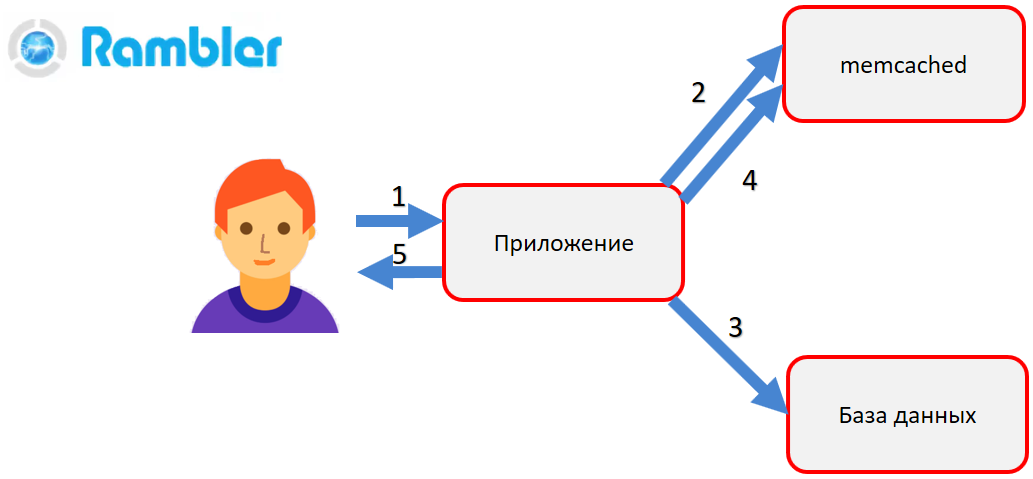
Was ist zwischengespeichert? Memcached - Eine Hash-Tabelle im Direktzugriffsspeicher mit Zugriff auf gespeicherte Objekte per Schlüssel. Zum Beispiel müssen Sie ein Benutzerprofil erhalten. Die Anwendung greift auf memcached (2) zu. Befindet sich ein Objekt darin, wird es sofort an den Benutzer zurückgegeben. Wenn es kein Objekt gibt, wird ein Rechtsbehelf bei der Datenbank eingelegt (3), das Objekt wird gebildet und in den Speicher gestellt (4). Dann müssen wir beim nächsten Aufruf keinen ressourcenintensiven Aufruf mehr an die Datenbank vornehmen - wir erhalten das fertige Objekt aus dem Hauptspeicher - zwischengespeichert.
Aufgrund von Memcached haben wir die Datenbank merklich entladen und unsere Anwendungen begannen viel schneller zu arbeiten. Aber wie sich herausstellte, war es zu früh, um sich zu freuen. Zusammen mit der Steigerung der Produktivität haben wir neue Herausforderungen erhalten.
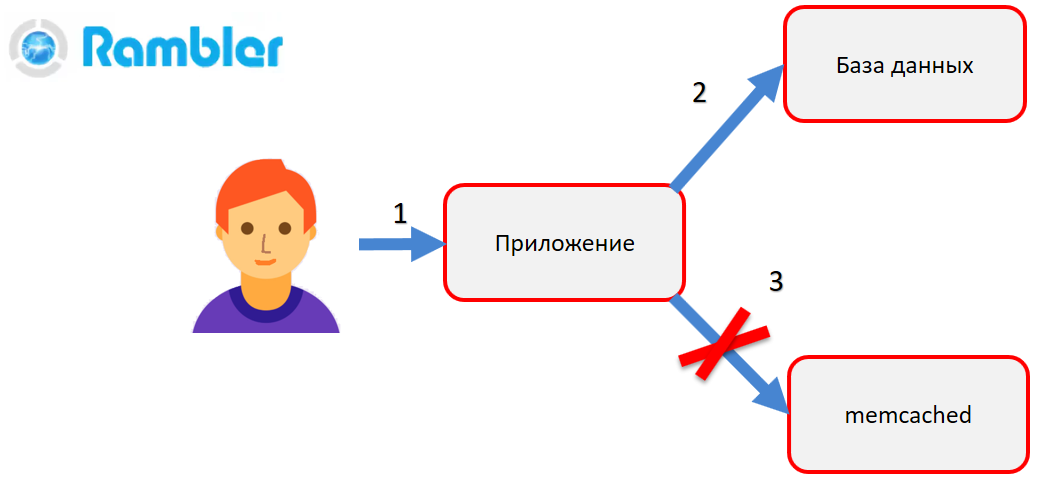
Wenn Sie die Daten ändern müssen, korrigiert die Anwendung zuerst die Datenbank (2), erstellt ein neues Objekt und versucht dann, es in memcached (3) abzulegen. Das heißt, das alte Objekt muss durch ein neues ersetzt werden. Stellen Sie sich vor, dass in diesem Moment etwas Schreckliches passiert - die Verbindung zwischen der Anwendung und memcached ist unterbrochen, der memcached Server oder sogar die Anwendung selbst stürzt ab. Daher konnte die Anwendung die Daten in memcached nicht aktualisieren. Infolgedessen geht der Benutzer zur Seite der Site (z. B. seinem Profil), zeigt die alten Daten an und versteht nicht, warum dies passiert ist.
Könnte dieser Fehler beim Funktionstest oder Leistungstest erkannt werden? Ich denke, dass wir ihn höchstwahrscheinlich nicht finden würden. Um nach solchen Fehlern zu suchen, gibt es eine spezielle Art der Prüfung - die Fehlerinjektion.
Normalerweise gibt es beim Testen der Fehlerinjektion Fehler, die im Volksmund als
schwebend bezeichnet werden . Sie treten unter Last auf, wenn mehr als ein Benutzer im System arbeitet, wenn abnormale Situationen auftreten - Gerätestörungen, Stromausfall, Netzwerkstörung usw.
Neues Sberbank IT-System
Vor einigen Jahren begann die Sberbank mit dem Aufbau eines neuen IT-Systems. Warum? Hier sind die Statistiken von der Website der Zentralbank:
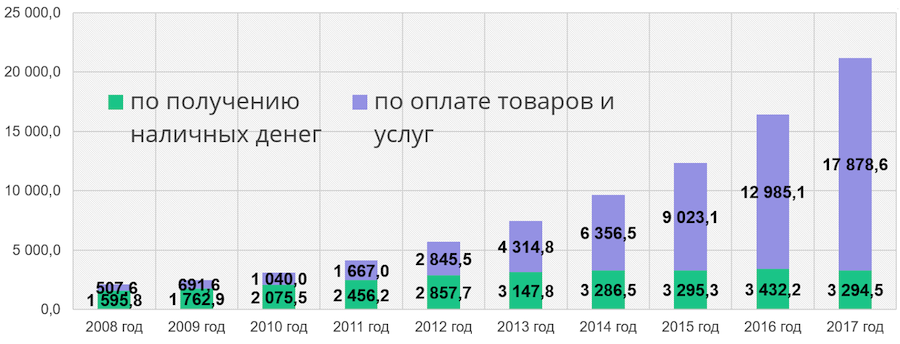
Der grüne Teil der Spalte gibt die Anzahl der Bargeldabhebungen an Geldautomaten an, der blaue Teil die Anzahl der Vorgänge, bei denen Waren und Dienstleistungen bezahlt werden müssen. Wir sehen, dass die Zahl der bargeldlosen Transaktionen von Jahr zu Jahr zunimmt. In einigen Jahren müssen wir in der Lage sein, die wachsende Arbeitsbelastung zu bewältigen und unseren Kunden weiterhin neue Dienstleistungen anzubieten. Dies ist einer der Gründe für die Schaffung eines neuen Sberbank-IT-Systems. Darüber hinaus möchten wir unsere Abhängigkeit von westlichen Technologien und teuren Mainframes, die Millionen von Dollar kosten, verringern und auf Open Source-Technologien und Low-End-Server umsteigen.
Zunächst haben wir den Grundstein für die Apache Ignite-Technologie im Zentrum der neuen Sberbank-Architektur gelegt. Genauer gesagt verwenden wir das kostenpflichtige Gridgain-Plugin. Die Technologie verfügt über eine ziemlich umfangreiche Funktionalität: Sie kombiniert die Eigenschaften einer relationalen Datenbank (SQL-Abfragen werden unterstützt), NoSQL, verteilte Verarbeitung und Speicherung von Daten im RAM. Darüber hinaus gehen beim Neustart keine Daten verloren, die sich im RAM befanden. Ab Version 2.1 hat Apache Ignite den persistenten Datenspeicher von Apache Ignite mit SQL-Unterstützung verteilt.
Ich werde einige Funktionen dieser Technologie auflisten:
- Speicherung und Datenverarbeitung im RAM
- Festplattenspeicher
- SQL-Unterstützung
- Verteilte Aufgabenausführung
- Horizontale Skalierung
Die Technologie ist relativ neu und erfordert daher besondere Aufmerksamkeit.
Das neue IT-System der Sberbank besteht physisch aus vielen relativ kleinen Servern, die in einem einzigen Cloud-Cluster zusammengefasst sind. Alle Knoten sind in ihrer Struktur identisch, Peer-to-Peer, und erfüllen die Funktion zum Speichern und Verarbeiten von Daten.
Innerhalb des Clusters ist in die sogenannten Zellen unterteilt. Eine Zelle besteht aus 8 Knoten. Jedes Rechenzentrum hat 4 Knoten.
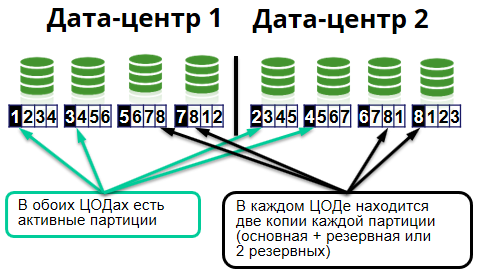
Da wir das speicherinterne Datenraster Apache Ignite verwenden, wird dies alles dementsprechend in serververteilten Caches gespeichert. Darüber hinaus sind Caches wiederum in identische Teile unterteilt - Partitionen. Auf Servern werden sie als Dateien dargestellt. Partitionen desselben Caches können auf verschiedenen Servern gespeichert werden. Für jede Partition im Cluster gibt es Primärknoten und Sicherungsknoten.
Die Hauptknoten speichern die Hauptpartitionen und verarbeiten Anforderungen für sie. Replizieren Sie die Daten auf die Sicherungsknoten (Sicherungsknoten), auf denen die Sicherungspartitionen gespeichert sind.
Beim Entwurf der neuen Architektur der Sberbank kamen wir zu dem Schluss, dass Systemkomponenten ausfallen können und werden. Angenommen, Sie haben einen Cluster von 1000 Eisen-Low-End-Servern, dann treten von Zeit zu Zeit Hardwarefehler auf. RAM-Strips, Netzwerkkarten und Festplatten usw. fallen aus. Wir werden dieses Verhalten als völlig normales Systemverhalten betrachten. Solche Situationen sollten korrekt gehandhabt werden und unsere Kunden sollten sie nicht bemerken.
Es reicht jedoch nicht aus, die Fehlerresistenz des Systems zu bestimmen. Es ist unbedingt erforderlich, die Systeme während dieser Fehler zu testen. Caitie McCaffrey von Microsoft Research, eine bekannte Forscherin für verteilte Systeme, sagt: „Sie werden nie wissen, wie sich das System während eines Notfallfehlers verhält, bis Sie den Fehler reproduzieren.“
Verlorene Updates
Nehmen wir ein einfaches Beispiel, eine Bankanwendung, die Geldtransfers simuliert. Die Anwendung besteht aus zwei Teilen: Apache Ignite-Server und Apache Ignite-Client. Die Serverseite ist ein Data Warehouse.
Die Clientanwendung stellt eine Verbindung zum Apache Ignite-Server her. Erstellt einen Cache, in dem der Schlüssel die Konto-ID und der Wert das Kontoobjekt ist. Insgesamt werden zehn solcher Objekte im Cache gespeichert. In diesem Fall werden wir zunächst 100 USD auf jedes Konto einzahlen (damit etwas überwiesen werden kann). Dementsprechend beträgt der Gesamtbetrag auf allen Konten 1.000 USD.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) { for (int i = 1; i <= ENTRIES_COUNT; i++) cache.put(i, new Account(i, 100)); System.out.println("Accounts before transfers"); printAccounts(cache); printTotalBalance(cache); for (int i = 1; i <= 100; i++) { int pairOfAccounts[] = getPairOfRandomAccounts(); transferMoney(cache, pairOfAccounts[0], pairOfAccounts[1]); } } ... private static void transferMoney(IgniteCache<Integer, Account> cache, int fromAccountId, int toAccountId) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); }
Dann machen wir 100 zufällige Geldtransfers zwischen diesen 10 Konten. Beispielsweise werden 50 USD von Konto A auf ein anderes Konto B überwiesen. Schematisch kann dieser Prozess wie folgt dargestellt werden:

Das System ist geschlossen, Übertragungen erfolgen nur intern, d.h. Der Gesamtbetrag sollte 1000 US-Dollar betragen.
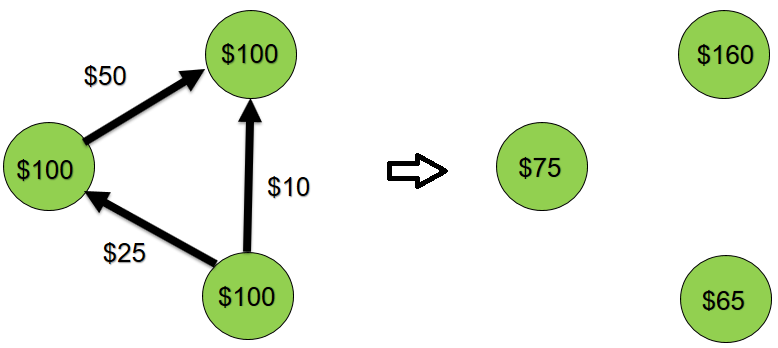
Starten Sie die Anwendung.
Wir haben den erwarteten Wert des Gesamtbetrags erhalten - 1000 USD. Lassen Sie uns nun unsere Anwendung etwas komplizieren - machen wir sie multitasking. In der Realität können mehrere Clientanwendungen gleichzeitig mit demselben Konto arbeiten. Führen Sie zwei Aufgaben aus, mit denen gleichzeitig Geldtransfers zwischen zehn Konten durchgeführt werden.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.ATOMIC); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setIndexedTypes(Integer.class, Account.class); try (IgniteCache<Integer, Account> cache = ignite.getOrCreateCache(cfg)) {
Der Gesamtbetrag beträgt 1296 USD. Kunden freuen sich, die Bank erleidet Verluste. Warum ist das passiert?

Hier sehen wir, wie zwei Aufgaben gleichzeitig den Status von Konto A ändern. Die zweite Aufgabe kann jedoch ihre Änderungen früher als die erste aufzeichnen. Dann zeichnet die erste Aufgabe ihre Änderungen auf, und alle von der zweiten Aufgabe vorgenommenen Änderungen verschwinden sofort. Diese Anomalie wird als Problem verlorener Updates bezeichnet.
Damit die Anwendung ordnungsgemäß funktioniert, muss unsere Datenbank ACID-Transaktionen unterstützen, und unser Code sollte dies berücksichtigen.
Schauen wir uns die ACID-Eigenschaften für unsere Anwendung an, um zu verstehen, warum dies so wichtig ist.

- A - Atomizität, Atomizität. Entweder werden alle vorgeschlagenen Änderungen an der Datenbank vorgenommen, oder es wird nichts vorgenommen. Das heißt, wenn zwischen den Schritten 3 und 6 ein Fehler aufgetreten ist, sollten sich die Änderungen nicht in der Datenbank befinden
- C - Konsistenz, Integrität. Nach Abschluss der Transaktion muss die Datenbank in einem konsistenten Zustand bleiben. In unserem Beispiel bedeutet dies, dass die Summe von A und B immer gleich sein sollte, der Gesamtbetrag beträgt 1000 USD.
- I - Isolation, Isolation. Transaktionen sollten sich nicht gegenseitig beeinflussen. Wenn eine Transaktion eine Überweisung vornimmt und die andere nach Schritt 3 und bis zu Schritt 6 den Wert von Konto A und B erhält, glaubt sie, dass das System weniger Geld als nötig hat. Hier gibt es Nuancen, auf die ich mich später konzentrieren werde.
- D - Haltbarkeit Nachdem die Transaktion Änderungen an der Datenbank festgeschrieben hat, sollten diese Änderungen nicht aufgrund von Fehlern verloren gehen.
Bei der transferMoney-Methode führen wir also eine Geldüberweisung innerhalb der Transaktion durch.
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart()) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
Starten Sie die Anwendung.
Hm. Transaktionen haben nicht geholfen. Der Gesamtbetrag beträgt 6951 $! Was ist das Problem mit diesem Anwendungsverhalten?
Zuerst wählten sie den ATOMIC-Cache-Typ, d.h. ohne ACID-Transaktionsunterstützung:
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TOMIC);
Zweitens verfügt die txStart-Methode über zwei wichtige Parameter des Aufzählungstyps, die angegeben werden sollten: die Sperrmethode (Parallelitätsmodus in Apache Ignite) und die Isolationsstufe. Abhängig von den Werten dieser Parameter kann eine Transaktion Daten auf unterschiedliche Weise lesen und schreiben. In Apache Ignite werden diese Parameter wie folgt festgelegt:
try (Transaction tx = ignite.transactions().txStart( , )) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); ... tx.commit(); }
Sie können PESSIMISTIC (pessimistische Sperre) oder OPTIMISTIC (optimistische Sperre) als Wert des Parameters LOCK METHOD verwenden. Sie unterscheiden sich im Moment der Blockierung. Bei Verwendung von PESSIMISTIC wird die Sperre beim ersten Lesen / Schreiben auferlegt und gehalten, bis die Transaktion festgeschrieben wird. Wenn beispielsweise eine Transaktion mit einer pessimistischen Sperre eine Übertragung von Konto A auf Konto B durchführt, können andere Transaktionen die Werte dieser Konten erst lesen oder schreiben, wenn die Transaktion, die die Übertragung vornimmt, festgeschrieben wurde. Es ist klar, dass andere Transaktionen, die auf die Konten A und B zugreifen möchten, gezwungen sind, auf den Abschluss der Transaktion zu warten, was sich negativ auf die Gesamtleistung der Anwendung auswirkt. Das optimistische Sperren schränkt den Zugriff auf Daten für andere Transaktionen nicht ein. Während der Vorbereitungsphase der Transaktion für das Festschreiben (Vorbereitungsphase, Apache Ignite verwendet das 2PC-Protokoll) wird jedoch eine Überprüfung durchgeführt. Haben sich die Daten bei anderen Transaktionen geändert? Und wenn Änderungen vorgenommen wurden, wird die Transaktion abgebrochen. In Bezug auf die Leistung läuft OPTIMISTIC schneller, eignet sich jedoch besser für Anwendungen, bei denen keine Konkurrenz zu Daten besteht.
Der Parameter INSULATION LEVEL bestimmt den Grad der Isolation von Transaktionen voneinander. Der SQL ANSI / ISO-Standard definiert vier Arten der Isolation. Für jede Isolationsstufe kann dasselbe Transaktionsszenario zu unterschiedlichen Ergebnissen führen.
- READ_UNCOMMITED ist die niedrigste Isolationsstufe. Transaktionen können "schmutzige" nicht festgeschriebene Daten anzeigen.
- READ_COMMITTED - Wenn eine Transaktion nur sensible Daten in sich sieht
- REPEATABLE_READ - bedeutet, dass dieser Lesevorgang wiederholbar sein muss, wenn innerhalb der Transaktion ein Lesevorgang durchgeführt wird.
- SERIALIZABLE - Diese Ebene setzt den maximalen Grad der Transaktionsisolation voraus - als ob sich keine anderen Benutzer im System befinden. Das Ergebnis paralleler Transaktionen ist so, als ob sie in der richtigen Reihenfolge ausgeführt würden. Zusammen mit einem hohen Maß an Isolation erhalten wir jedoch eine Leistungsminderung. Daher müssen Sie die Wahl dieser Isolationsstufe sorgfältig treffen.
Für viele moderne DBMS (Microsoft SQL Server, PostgreSQL und Oracle) lautet die Standardisolationsstufe READ_COMMITTED. In unserem Beispiel wäre dies fatal, da es uns nicht vor verlorenen Updates schützt. Das Ergebnis ist das gleiche, als hätten wir überhaupt keine Transaktionen verwendet.

In der
Apache Ignite-Transaktionsdokumentation können wir eine Kombination aus Sperrmethode und Isolationsstufe verwenden:
- PESSIMISTIC REPEATABLE_READ - Die Sperre wird beim ersten Lesen oder Schreiben von Daten auferlegt und bis zu ihrem Abschluss beibehalten .
- PESSIMISTIC SERIALIZABLE - funktioniert ähnlich wie PESSIMISTIC REPEATABLE_READ
- OPTIMISTIC SERIALIZABLE - Die Version der Daten, die nach dem ersten Lesen erhalten wurden, wird gespeichert. Wenn sich diese Version während der Vorbereitungsphase für das Commit unterscheidet (die Daten wurden durch eine andere Transaktion geändert), wird die Transaktion abgebrochen. Versuchen wir diese Option.
private void transferMoney(int fromAccountId, int toAccountId) { try (Transaction tx = ignite.transactions().txStart(OPTIMISTIC, SERIALIZABLE)) { Account fromAccount = cache.get(fromAccountId); Account toAccount = cache.get(toAccountId); int amount = getRandomAmount(fromAccount.balance); if (amount < 1) { return; } int fromAccountBalanceBeforeTransfer = fromAccount.balance; int toAccountBalanceBeforeTransfer = toAccount.balance; fromAccount.withdraw(amount); toAccount.deposit(amount); cache.put(fromAccountId, fromAccount); cache.put(toAccountId, toAccount); tx.commit(); } catch (Exception e){ e.printStackTrace(); } }
Hurra, bekam wie erwartet 1.000 Dollar. Beim dritten Versuch.
Testen unter Last
Jetzt werden wir unseren Test realistischer machen - wir werden unter Last testen. Und fügen Sie einen zusätzlichen Serverknoten hinzu. Es gibt viele Tools für die Durchführung von Stresstests. Bei Sberbank verwenden wir das HP Performance Center. Dies ist ein ziemlich leistungsfähiges Tool, das mehr als 50 Protokolle unterstützt, für große Teams entwickelt wurde und viel Geld kostet. Ich habe mein Beispiel auf JMeter geschrieben - es ist kostenlos und löst unser Problem zu 100%. Ich möchte den Code nicht in Java umschreiben, daher werde ich den JSR223-Sampler verwenden.
Wir erstellen ein JAR-Archiv aus den Klassen unserer Anwendung und laden es in den Testplan. Führen Sie die CreateCache-Klasse aus, um den Cache zu erstellen und zu füllen. Nach dem Initialisieren des Caches können Sie das JMeter-Skript ausführen.
Alles ist cool, hat 1.000 Dollar.
Notfall-Herunterfahren des Clusterknotens
Jetzt werden wir destruktiver: Während des Clusterbetriebs stürzen wir einen der beiden Serverknoten ab. Über das Visor-Dienstprogramm, das im Gridgain-Paket enthalten ist, können wir den Apache Ignite-Cluster überwachen und verschiedene Datenbeispiele erstellen. Führen Sie auf der Registerkarte SQL Viewer eine SQL-Abfrage aus, um den Gesamtsaldo für alle Konten abzurufen.
Was ist das 553 Dollar. Kunden haben Angst, die Bank erleidet Reputationsverluste. Was haben wir diesmal falsch gemacht?
Es stellt sich heraus, dass es in Apache Ignite Cache-Typen gibt:
- partitioniert - Eine oder mehrere Sicherungskopien werden im Cluster gespeichert
- Replizierte Caches - Alle Partitionen (alle Teile des Caches) werden auf einem Server gespeichert. Solche Caches eignen sich hauptsächlich für Nachschlagewerke - etwas, das sich selten ändert und oft gelesen wird.
- lokal - alles auf einem Knoten

Wir werden unsere Daten häufig ändern, daher wählen wir einen partitionierten Cache aus und fügen ihm eine zusätzliche Sicherung hinzu. Das heißt, wir haben zwei Kopien der Daten - die primäre und die Sicherung.
CacheConfiguration<Integer, Account> cfg = new CacheConfiguration<>(CACHE_NAME); cfg.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL); cfg.setCacheMode(CacheMode.PARTITIONED); cfg.setBackups(1);
Wir starten die Anwendung. Ich erinnere Sie daran, dass wir vor Überweisungen 1000 Dollar haben. Wir starten und „löschen“ während des Betriebs einen der Knoten
Im Visor-Dienstprogramm führen wir eine SQL-Abfrage durch, um einen Gesamtbetrag von 1000 US-Dollar zu erhalten. Alles hat super geklappt!
Zuverlässigkeitsfälle
Vor zwei Jahren haben wir gerade damit begonnen, das neue Sberbank-IT-System zu testen. Irgendwie gingen wir zu unseren Escort-Ingenieuren und fragten: Was könnte überhaupt kaputt gehen? Sie antworteten uns: Alles kann kaputt gehen, alles testen! Diese Antwort passte natürlich nicht zu uns. Wir setzten uns zusammen, analysierten die Fehlerstatistik und stellten fest, dass der wahrscheinlichste Fall ein Knotenfehler ist.
Darüber hinaus kann dies aus ganz anderen Gründen geschehen. Beispielsweise kann eine Anwendung abstürzen, ein JVM-Absturz, ein Betriebssystemabsturz oder ein Hardwarefehler.
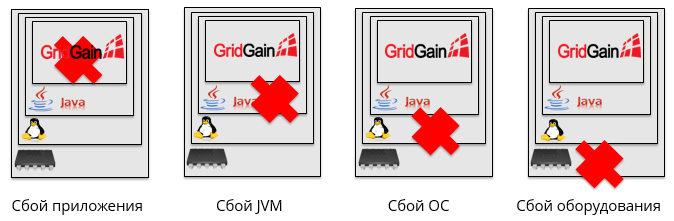
Wir haben alle möglichen Fehlerfälle in 4 Gruppen unterteilt:
- Ausrüstung
- Netzwerk
- Software
- Andere
Sie entwickelten Tests für sie und nannten sie Fälle von Zuverlässigkeit. Ein typischer Zuverlässigkeitsfall besteht aus einer Beschreibung des Systemzustands vor den Tests, Schritten zur Reproduktion des Fehlers und einer Beschreibung des erwarteten Verhaltens während des Fehlers.
Zuverlässigkeitsfälle: Ausrüstung
Diese Gruppe umfasst Fälle wie:
- Stromausfall
- Vollständiger Verlust des Zugriffs auf die Festplatte
- Ausfall eines Festplattenzugriffspfads
- CPU, RAM, Festplatte, Netzwerklast
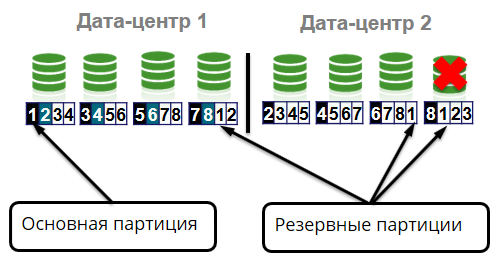
Der Cluster speichert 4 identische Kopien jeder Partition: eine primäre Partition und drei Sicherungspartitionen. Angenommen, ein Knoten verlässt einen Cluster aufgrund eines Geräteausfalls. In diesem Fall sollten die Hauptpartitionen zu anderen überlebenden Knoten verschoben werden.
Was könnte sonst noch passieren? Verlust des Gestells in der Zelle.
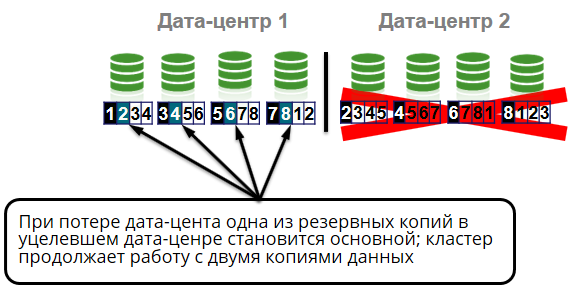
Alle Knoten der Zelle befinden sich in unterschiedlichen Racks. Das heißt, Die Rack-Ausgabe führt nicht zu Clusterfehlern oder Datenverlust. Wir werden drei Exemplare von vier haben. Aber selbst wenn wir das gesamte Rechenzentrum verlieren, wird es für uns kein großes Problem sein, denn Wir haben noch zwei weitere Kopien der Daten von vier.
Einige Fälle werden mit Unterstützung von Support-Ingenieuren direkt im Rechenzentrum ausgeführt. Schalten Sie beispielsweise die Festplatte aus und den Server oder das Rack aus.
Zuverlässigkeitsfälle: Netzwerk
Um Fälle im Zusammenhang mit der Netzwerkfragmentierung zu testen, verwenden wir iptables. Und mit dem NetEm-Dienstprogramm emulieren wir:
- Netzwerkverzögerungen mit unterschiedlicher Verteilungsfunktion
- Paketverlust
- Paketwiederholung
- Pakete neu anordnen
- Paketverzerrung
Ein weiterer interessanter Netzwerkfall, den wir testen, ist Split-Brain. In diesem Fall sind alle Knoten des Clusters aktiv, können jedoch aufgrund der Netzwerksegmentierung nicht miteinander kommunizieren. Der Begriff stammt aus der Medizin und bedeutet, dass das Gehirn in zwei Hemisphären unterteilt ist, von denen jede sich als einzigartig betrachtet. Das gleiche kann mit einem Cluster passieren.
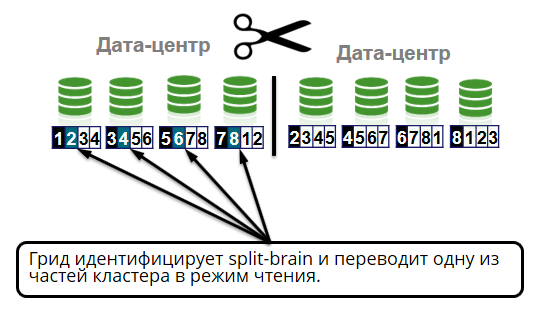
Es kommt vor, dass zwischen Rechenzentren die Verbindung verschwindet. Beispielsweise führte ein Kunde der Banken der Banken Tochka, Otkrytie und Rocketbank im vergangenen Jahr aufgrund einer Beschädigung des Glasfaserkabels durch einen Bagger mehrere Stunden lang keine Transaktionen über das Internet durch, die Terminals akzeptierten keine Karten und Geldautomaten funktionierten nicht. Über diesen Unfall wurde auf Twitter viel geschrieben.
In unserem Fall sollte die Split-Brain-Situation korrekt behandelt werden. Ein Gitter identifiziert ein geteiltes Gehirn, das einen Cluster in zwei Teile teilt. Eine Hälfte geht in den Lesemodus. Dies ist die Hälfte, in der sich mehr lebende Knoten befinden oder der Koordinator sich befindet (der älteste Knoten im Cluster).
Zuverlässigkeitsfälle: Software
Dies sind Fälle im Zusammenhang mit dem Ausfall verschiedener Subsysteme:
- DPL ORM - Datenzugriffsmodul, z. B. Hibernate ORM
- Intermodularer Transport - Messaging zwischen Modulen (Microservices)
- Protokollierungssystem
- Zugangssystem
- Apache Ignite Cluster
- ...
Da die meiste Software in Java geschrieben ist, sind wir anfällig für alle Probleme, die mit Java-Anwendungen verbunden sind. Testet verschiedene Garbage Collector-Einstellungen. Ausführen von Tests mit einem Absturz der Java Virtual Machine.
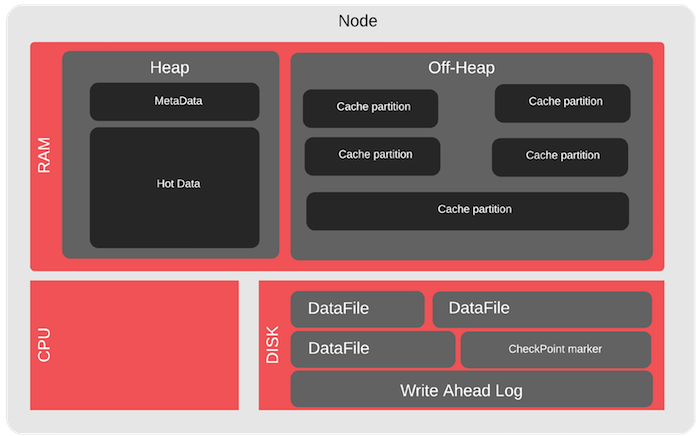
Für den Apache Ignite-Cluster gibt es Sonderfälle für Off-Heap - dies ist der Speicherbereich, den Apache Ignite steuert. Es ist viel größer als Java-Heap und dient zum Speichern von Daten und Indizes. Hier können Sie beispielsweise den Überlauf testen. Wir laufen außerhalb des Heaps über und sehen, wie der Cluster funktioniert, wenn einige der Daten nicht in den RAM passen, d. H. von der Festplatte lesen.
Andere Fälle
Dies sind Fälle, die nicht in den ersten drei Gruppen enthalten sind. Dazu gehören Dienstprogramme, die die Datenwiederherstellung im Falle eines schweren Unfalls oder bei der Migration von Daten in einen anderen Cluster ermöglichen.
- Das Dienstprogramm zum Erstellen von Snapshots (Backup) von Daten - Testen von vollständigen und inkrementellen Snapshots.
- Wiederherstellung zu einem bestimmten Zeitpunkt - PITR-Mechanismus (Point-in-Time Recovery).
Dienstprogramme zur Fehlerinjektion
Ich erinnere mich an den
Link zu Beispielen aus meinem Bericht. Sie können die Apache Ignite-Distribution von der offiziellen Website
herunterladen -
Apache Ignite Downloads . Und jetzt werde ich die Dienstprogramme, die wir bei Sberbank verwenden, teilen, wenn Sie sich plötzlich für das Thema interessieren.
Frameworks
Konfigurationsmanagement:
Linux-Dienstprogramme:
Lasttest-Tools:
Sowohl in der modernen Welt als auch in der Sberbank sind alle Veränderungen dynamisch und es ist schwierig vorherzusagen, welche Technologien in den nächsten Jahren eingesetzt werden. Aber ich weiß mit Sicherheit, dass wir die Fehlerinjektionsmethode verwenden werden. Die Methode ist universell - sie eignet sich zum Testen jeder Technologie, funktioniert wirklich, hilft, viele Fehler zu erkennen und die von uns entwickelten Produkte besser zu machen.