Sie sind hier, wenn Sie wissen möchten, wie Sie ein Framework zähmen können, das in den Kreisen der Python-Entwickler namens Celery weithin bekannt ist. Und selbst wenn Sellerie grundlegende Befehle in Ihrem Projekt sicher ausführt, kann die Fintech-Erfahrung Ihnen unbekannte Seiten eröffnen. Weil Fintech immer Big Data ist und damit Hintergrundaufgaben, Stapelverarbeitung, asynchrone API usw. erforderlich sind.

Das Schöne an Oleg Churkins Geschichte über Sellerie in
Moskau Python Conf ++ ist, dass Sie nützliche Ideen ausleihen können
, zusätzlich zu detaillierten Anweisungen zum Konfigurieren und Überwachen von Sellerie unter Last.
Über den Sprecher und das Projekt: Oleg
Churkin (
Bahusss ) entwickelt seit 8 Jahren Python-Projekte unterschiedlicher Komplexität und hat in vielen bekannten Unternehmen gearbeitet: Yandex, Rambler, RBC, Kaspersky Lab. Jetzt Techlide im Fintech-StatusPoney-Startup.
Das Projekt arbeitet mit einer großen Menge an Finanzdaten von Benutzern (1,5 Terabyte): Konten, Transaktionen, Händler usw. Es werden täglich bis zu eine Million Aufgaben ausgeführt. Vielleicht scheint diese Zahl für jemanden nicht wirklich groß zu sein, aber für ein kleines Startup mit bescheidenen Kapazitäten ist dies eine erhebliche Datenmenge, und die Entwickler mussten sich auf dem Weg zu einem stabilen Prozess verschiedenen Problemen stellen.
Oleg sprach über die wichtigsten Punkte der Arbeit:
- Welche Aufgaben wollten Sie mit dem Framework lösen, warum haben Sie sich für Sellerie entschieden?
- Wie Sellerie half.
- So konfigurieren Sie Sellerie unter Last.
- So überwachen Sie den Selleriestatus.
Und er teilte einige Design-Dienstprogramme, die die fehlende Funktionalität in Sellerie implementieren. Wie sich herausstellte, im Jahr 2018, und das kann sein. Das Folgende ist eine Textversion des Berichts aus der ersten Person.
Problem
Es war erforderlich, um die folgenden Aufgaben zu lösen:
- Führen Sie separate Hintergrundaufgaben aus .
- Führen Sie eine Stapelverarbeitung von Aufgaben durch , dh führen Sie viele Aufgaben gleichzeitig aus.
- Betten Sie den Prozess Extrahieren, Transformieren, Laden ein .
- Implementieren Sie die asynchrone API . Es stellt sich heraus, dass die asynchrone API nicht nur mithilfe asynchroner Frameworks implementiert werden kann, sondern auch vollständig synchron.
- Führen Sie regelmäßige Aufgaben aus . Kein einziges Projekt kann ohne regelmäßige Aufgaben auskommen, für einige kann auf Cron verzichtet werden, aber es gibt auch bequemere Werkzeuge.
- Erstellen einer Triggerarchitektur : Um einen Trigger auszulösen, führen Sie eine Aufgabe aus, die die Daten aktualisiert. Dies geschieht, um den Mangel an Laufzeitleistung durch Vorberechnung von Daten im Hintergrund auszugleichen.
Hintergrundaufgaben umfassen alle Arten von Benachrichtigungen: E-Mail, Push, Desktop - all dies wird in Hintergrundaufgaben durch einen Auslöser gesendet. Ebenso wird eine regelmäßige Aktualisierung der Finanzdaten gestartet.
Im Hintergrund werden verschiedene spezifische Überprüfungen durchgeführt, beispielsweise die Überprüfung eines Benutzers auf Betrug. Bei Finanz-Startups wird
viel Aufmerksamkeit und Aufmerksamkeit speziell der Datensicherheit gewidmet , da wir Benutzern ermöglichen, ihre Bankkonten zu unserem System hinzuzufügen, und wir alle ihre Transaktionen sehen können. Betrüger können versuchen, unseren Service für etwas Schlechtes zu nutzen, um beispielsweise den Kontostand eines gestohlenen Kontos zu überprüfen.
Die letzte Kategorie von Hintergrundaufgaben sind
Wartungsaufgaben : etwas optimieren, sehen, reparieren, überwachen usw.
Für Massenbenachrichtigungen wird die
Stapelverarbeitung verwendet . Eine große Menge von Daten, die wir von unseren Benutzern erhalten, muss auf eine bestimmte Weise berechnet und verarbeitet werden, einschließlich im Batch-Modus.
Das gleiche Konzept beinhaltet das klassische
Extrahieren, Transformieren, Laden :
- Laden von Daten aus externen Quellen (externe API);
- unverarbeitet halten;
- Führen Sie Aufgaben aus, die Daten lesen und verarbeiten.
- Wir speichern die verarbeiteten Daten an der richtigen Stelle im richtigen Format, damit sie später beispielsweise bequem in der Benutzeroberfläche verwendet werden können.
Es ist kein Geheimnis, dass die asynchrone API mit einer einfachen Abfrageanforderung ausgeführt werden kann: Das Frontend initiiert den Prozess im Backend, das Backend startet eine Aufgabe, die sich regelmäßig selbst startet, die Ergebnisse "vergießt" und den Status in der Datenbank aktualisiert. Das Frontend zeigt dem Benutzer, dass sich dieser interaktive Status ändert. Dies ermöglicht Ihnen:
- Abrufaufgaben von anderen Aufgaben ausführen;
- Führen Sie je nach Bedingungen unterschiedliche Aufgaben aus.
In unserem Dienst reicht dies vorerst aus, aber in Zukunft müssen wir wahrscheinlich etwas anderes umschreiben.
Werkzeuganforderungen
Um diese Aufgaben zu implementieren, hatten wir die folgenden Anforderungen an Werkzeuge:
- Funktionalität, die notwendig ist, um unsere Ambitionen zu verwirklichen.
- Skalierbarkeit ohne Krücken.
- Überwachung des Systems, um zu verstehen, wie es funktioniert. Wir verwenden die Fehlerberichterstattung, damit die Integration mit Sentry nicht fehl am Platz ist, auch nicht mit Django.
- Leistung , weil wir viele Aufgaben haben.
- Reife, Zuverlässigkeit und aktive Entwicklung sind offensichtliche Dinge. Wir suchten nach einem Tool, das unterstützt und entwickelt wird.
- Angemessenheit der Dokumentation - keine Dokumentation irgendwo .
Welches Tool soll ich wählen?
Welche Optionen gibt es 2018 auf dem Markt, um diese Probleme zu lösen?
Es war einmal eine Zeit für weniger ehrgeizige Aufgaben, als ich eine handliche
Bibliothek schrieb, die noch in einigen Projekten verwendet wird. Es ist einfach zu bedienen und führt Aufgaben im Hintergrund aus. Gleichzeitig werden jedoch keine Broker benötigt (weder Sellerie noch andere),
sondern nur der
uwsgi- Anwendungsserver, der über einen Spooler verfügt, beginnt als separater Worker. Dies ist eine sehr einfache Lösung - alle Aufgaben werden bedingt in Dateien gespeichert. Für einfache Projekte ist das genug, aber für unsere war es nicht genug.
Irgendwie haben wir überlegt:
- Sellerie (10K Sterne auf GitHub);
- RQ (5K Sterne auf GitHub);
- Huey (2K Sterne auf GitHub);
- Dramatiq (1K Sterne auf GitHub);
- Tasktiger (0,5K Sterne auf GitHub);
- Luftstrom? Luigi
Vielversprechender Kandidat 2018
Jetzt möchte ich Ihre Aufmerksamkeit auf
Dramatiq lenken. Dies ist eine Bibliothek des erfahrenen Selleries, der alle Nachteile von Sellerie kannte und beschloss, alles neu zu schreiben, nur sehr schön. Vorteile von Dramatiq:
- Eine Reihe aller notwendigen Funktionen.
- Steigerung der Produktivität.
- Unterstützung für Wachposten und Metriken für Prometheus sofort
- Eine kleine und klar geschriebene Codebasis, Code-Autoreload.
Vor einiger Zeit hatte Dramatiq Probleme mit Lizenzen: Zuerst gab es AGPL, dann wurde es durch LGPL ersetzt. Aber jetzt können Sie es versuchen.
Aber im Jahr 2016 gab es neben Sellerie nichts Besonderes zu nehmen. Wir mochten seine reichhaltige Funktionalität und dann passte es ideal zu unseren Aufgaben, denn selbst dann war es ausgereift und funktional:
- hatte regelmäßige Aufgaben aus der Box;
- unterstützte mehrere Makler;
- Integriert mit Django und Sentry.
Projektfunktionen
Ich werde Ihnen von unserem Kontext erzählen, damit die weitere Geschichte klarer wird.
Wir verwenden
Redis als Nachrichtenbroker . Ich habe viele Geschichten und Gerüchte gehört, dass Redis Nachrichten verliert, dass es nicht als Nachrichtenvermittler geeignet ist. Aus Produktionsgründen wird dies nicht bestätigt, aber wie sich herausstellt, arbeitet Redis jetzt effizienter als RabbitMQ (zumindest bei Celery liegt das Problem anscheinend im Integrationscode mit Brokern). In Version 4 wurde der Redis-Broker behoben, er hat beim Neustart wirklich aufgehört, Aufgaben zu verlieren, und funktioniert recht stabil. 2016 wollte Celery Redis aufgeben und sich auf die Integration mit RabbitMQ konzentrieren, aber dies geschah glücklicherweise nicht.
Wenn wir bei Problemen mit Redis ernsthafte Hochverfügbarkeit benötigen, wechseln wir zu Amazon SQS oder Amazon MQ, da wir die Leistung von Amazon nutzen.
Wir
verwenden das Ergebnis-Backend nicht zum Speichern der Ergebnisse , da wir es vorziehen, die Ergebnisse selbst dort zu speichern, wo wir möchten, und sie so zu überprüfen, wie wir es möchten. Wir wollen nicht, dass Sellerie dies für uns tut.
Wir verwenden einen
Pefork-Pool ,
dh Prozessarbeiter, die separate Prozessgabeln für zusätzliche Parallelität erstellen.
Arbeitseinheit
Wir werden die Grundelemente diskutieren, um diejenigen auf den neuesten Stand zu bringen, die Sellerie nicht probiert haben, sondern nur werden.
Arbeitseinheit für Sellerie ist eine Herausforderung . Ich werde ein Beispiel für eine einfache Aufgabe geben, die eine E-Mail sendet.
Einfache Funktion und Dekorateur:
@current_app.task def send_email(email: str): print(f'Sending email to email={email}')
Das Starten der Aufgabe ist einfach: Entweder rufen wir die Funktion auf und die Aufgabe wird zur Laufzeit (send_email (email = "python@example.com")) oder im Worker ausgeführt, dh die Auswirkung der Aufgabe im Hintergrund:
send_email.delay(email="python@example.com") send_email.apply_async( kwargs={email: "python@example.com"} )
Für zwei Jahre Arbeit mit Sellerie unter hoher Belastung haben wir uns die Regeln für gute Form ausgedacht. Es gab viele Rechen, wir haben gelernt, wie man um sie herumkommt, und ich werde erzählen, wie.
Code-Design
Die Aufgabe kann unterschiedliche Logik enthalten. Im Allgemeinen hilft Ihnen Sellerie dabei, Aufgaben in Dateien oder Paketen zu speichern oder von irgendwoher zu importieren. Manchmal erhalten Sie einen Stapel Geschäftslogik in einem Modul. Unserer Meinung nach besteht der richtige Ansatz unter dem Gesichtspunkt der Modularität der Anwendung darin, ein
Minimum an Logik in der Aufgabe zu halten . Wir verwenden Rätsel nur als "Auslöser" des Codes. Das heißt, die Aufgabe enthält keine Logik an sich, sondern löst den Start von Code im Hintergrund aus.
@celery_app.task(queue='...') def run_regular_update(provider_account_id, *args, **kwargs): """...""" flow = flows.RegularSyncProviderAccountFlow(provider_account_id) return flow.run(*args, **kwargs)
Wir setzen den gesamten Code in externe Klassen ein, die einige andere Klassen verwenden. Alle Aufgaben bestehen im Wesentlichen aus zwei Zeilen.
Einfache Objekte in Parametern
Im obigen Beispiel wird eine bestimmte ID an die Aufgabe übergeben. Bei allen Aufgaben, die wir verwenden, übertragen wir
nur kleine skalare Daten , id. Wir serialisieren keine Django-Modelle, um sie zu übertragen. Selbst in ETL speichern wir einen großen Daten-Blob, der von einem externen Dienst stammt, zuerst und führen dann eine Aufgabe aus, die diesen gesamten Blob anhand seiner ID liest und verarbeitet.
Wenn Sie dies nicht tun, haben wir in Redis eine sehr große Mischung aus verbrauchtem Speicher gesehen. Die Nachricht nimmt mehr Speicherplatz ein, das Netzwerk ist stark ausgelastet, die Anzahl der verarbeiteten Aufgaben (Leistung) sinkt. Solange das Objekt fertig ist, sind die Aufgaben irrelevant, das Objekt wurde bereits gelöscht. Die Daten mussten serialisiert werden - in JSON in Python ist nicht alles gut serialisiert. Wir brauchten die Gelegenheit, bei Wiederholungsaufgaben irgendwie schnell zu entscheiden, was mit diesen Daten geschehen soll, sie erneut abzurufen und einige Überprüfungen durchzuführen.
Wenn Sie Big Data in Parametern übertragen, denken Sie noch einmal darüber nach! Es ist besser, einen kleinen Skalar mit einer kleinen Menge an Informationen im Problem zu übertragen und aus diesen Informationen in der Aufgabe alles zu erhalten, was Sie benötigen.
Idempotente Probleme
Sellerieentwickler selbst empfehlen diesen Ansatz. Wenn der Codeabschnitt wiederholt wird, sollten keine Nebenwirkungen auftreten, das Ergebnis sollte das gleiche sein. Dies ist nicht immer einfach zu erreichen, insbesondere wenn eine Interaktion mit vielen Diensten oder zweiphasigen Commits besteht.
Wenn Sie jedoch alles lokal erledigen, können Sie jederzeit überprüfen, ob die eingehenden Daten vorhanden und relevant sind. Sie können wirklich daran arbeiten und Transaktionen verwenden. Wenn für eine Aufgabe viele Abfragen in der Datenbank vorhanden sind und zur Laufzeit möglicherweise ein Fehler auftritt, verwenden Sie Transaktionen, um unnötige Änderungen zurückzusetzen.
Abwärtskompatibilität
Wir hatten einige interessante Nebenwirkungen, als wir die Anwendung bereitstellten. Unabhängig davon, welche Art von Bereitstellung Sie verwenden (blau + grün oder fortlaufendes Update), wird es immer eine Situation geben, in der der alte Servicecode Nachrichten für den neuen Worker-Code erstellt, und umgekehrt empfängt der alte Worker Nachrichten vom neuen Service-Code, da er "zuerst" eingeführt wurde. und da ging der Verkehr.
Wir haben Fehler entdeckt und Aufgaben verloren, bis wir gelernt haben, wie man die
Abwärtskompatibilität zwischen Releases aufrechterhält. Abwärtskompatibilität besteht darin, dass die Aufgaben zwischen den Releases sicher funktionieren sollten, unabhängig davon, welche Parameter in diese Aufgabe eingehen. Daher machen wir jetzt bei allen Aufgaben eine "Gummi" -Signatur (** kwargs). Wenn Sie in der nächsten Version einen neuen Parameter hinzufügen müssen, übernehmen Sie ihn von ** kwargs in der neuen Version, aber nicht in der alten - nichts wird kaputt gehen. Sobald sich die Signatur ändert und Sellerie nichts davon weiß, stürzt sie ab und gibt den Fehler aus, dass die Aufgabe keinen solchen Parameter enthält.
Eine strengere Möglichkeit, solche Probleme zu vermeiden, besteht darin, die Task-Warteschlangen zwischen den Releases zu versionieren. Die Implementierung ist jedoch recht schwierig, und wir haben sie vorerst im Backlog belassen.
Zeitüberschreitungen
Probleme können aufgrund unzureichender Anzahl oder falscher Zeitüberschreitungen auftreten.
Es ist böse, keine Zeitüberschreitung für eine Aufgabe festzulegen. Dies bedeutet, dass Sie nicht verstehen, was in der Aufgabe vor sich geht und wie die Geschäftslogik funktionieren sollte.
Daher sind alle unsere Aufgaben mit Zeitüberschreitungen versehen, einschließlich globaler für alle Aufgaben, und Zeitüberschreitungen werden auch für jede bestimmte Aufgabe festgelegt.
Muss angebracht werden: soft_limit_timeout und
läuft ab.Läuft ab, wie viel eine Aufgabe in einer Linie leben kann. Bei Problemen müssen sich keine Aufgaben in den Warteschlangen ansammeln. Wenn wir jetzt beispielsweise dem Benutzer etwas melden möchten, aber etwas passiert ist und die Aufgabe erst morgen ausgeführt werden kann, ist dies nicht sinnvoll. Morgen ist die Nachricht nicht mehr relevant. Daher haben wir für Benachrichtigungen einen relativ kleinen Ablauf.
Beachten Sie die Verwendung von
eta (Countdown) + Sichtbarkeit _timeout . Die FAQ beschreibt ein solches Problem mit Redis - das sogenannte Sichtbarkeits-Timeout des Redis-Brokers. Standardmäßig beträgt der Wert eine Stunde: Wenn der Mitarbeiter nach einer Stunde feststellt, dass niemand die Aufgabe ausgeführt hat, fügt er sie erneut der Warteschlange hinzu. Wenn der Countdown zwei Stunden beträgt, stellt der Broker nach einer Stunde fest, dass diese Aufgabe noch nicht abgeschlossen ist, und erstellt eine weitere Aufgabe derselben. Und in zwei Stunden sind zwei identische Aufgaben erledigt.
Wenn die geschätzte Zeit oder der Countdown 1 Stunde überschreitet, führt die Verwendung von Redis höchstwahrscheinlich zu doppelten Aufgaben, es sei denn, Sie haben den Wert für sichtbarkeitszeitüberschreitung in den Einstellungen für die Verbindung zum Broker geändert.
Wiederholen Sie die Richtlinie
Für Aufgaben, die wiederholt werden können oder fehlschlagen können, verwenden wir die Wiederholungsrichtlinie. Wir setzen es jedoch sorgfältig ein, um externe Dienste nicht zu überfordern. Wenn Sie Aufgaben schnell wiederholen, ohne ein exponentielles Backoff anzugeben, kann es sein, dass ein externer oder möglicherweise ein interner Dienst dies einfach nicht aushält.
Die Parameter
retry_backoff ,
retry_jitter und
max_retries lassen sich gerne explizit angeben, insbesondere max_retries. retry_jitter - ein Parameter, mit dem Sie ein wenig Chaos verursachen können, damit sich die Aufgaben nicht gleichzeitig wiederholen.
Speicherlecks
Leider sind Speicherlecks sehr einfach und es ist schwierig, sie zu finden und zu beheben.
Im Allgemeinen ist die Arbeit mit Speicher in Python sehr kontrovers. Sie werden viel Zeit und Nerven aufwenden, um zu verstehen, warum das Leck auftritt, und dann stellt sich heraus, dass es nicht einmal in Ihrem Code enthalten ist. Legen Sie daher beim Starten eines Projekts immer ein
Speicherlimit für den Worker fest : worker_max_memory_per_child.
Dies stellt sicher, dass OOM Killer nicht eines Tages kommt, nicht alle Arbeiter tötet und Sie nicht alle Aufgaben verlieren. Sellerie startet die Arbeiter bei Bedarf neu.
Prioritätsaufgaben
Es gibt immer Aufgaben, die vor allen anderen erledigt werden müssen, schneller als alle anderen - sie müssen sofort erledigt werden! Es gibt Aufgaben, die nicht so wichtig sind - lassen Sie sie tagsüber erledigen. Hierzu hat die Aufgabe einen
Prioritätsparameter. In Redis funktioniert es sehr interessant - eine neue Warteschlange wird mit einem Namen erstellt, in dem Priorität hinzugefügt wird.
Wir verwenden einen anderen Ansatz -
getrennte Arbeiter für Prioritäten , d. H. Auf altmodische Weise schaffen wir Sellerie-Arbeiter mit unterschiedlicher „Bedeutung“:
celery multi start high_priority low_priority -c:high_priority 2 -c:low_priority 6 -Q:high_priority urgent_notifications -Q:low_priority emails,urgent_notifications
Celery Multi Start ist ein Helfer, mit dem Sie die gesamte Selleriekonfiguration auf einem Computer und über dieselbe Befehlszeile ausführen können. In diesem Beispiel erstellen wir Knoten (oder Worker): High_priority und Low_priority, 2 und 6 sind Parallelität.
Zwei Mitarbeiter mit hoher Priorität verarbeiten ständig die Warteschlange für dringende Benachrichtigungen. Niemand sonst nimmt diese Mitarbeiter mit, sie lesen nur wichtige Aufgaben aus der Warteschlange für dringende Benachrichtigungen.
Für unwichtige Aufgaben gibt es eine Warteschlange mit niedriger Priorität. Es gibt 6 Mitarbeiter, die Nachrichten aus allen anderen Warteschlangen erhalten. Wir abonnieren auch Mitarbeiter mit niedriger Priorität für dringende Benachrichtigungen, damit sie helfen können, wenn Mitarbeiter mit hoher Priorität nicht damit umgehen können.
Wir verwenden dieses klassische Schema, um Aufgaben zu priorisieren.
Extrahieren, transformieren, laden
In den meisten Fällen sieht ETL wie eine Kette von Aufgaben aus, von denen jede Eingabe von der vorherigen Aufgabe erhält.
@task def download_account_data(account_id) … return account_id @task def process_account_data(account_id, processing_type) … return account_data @task def store_account_data(account_data) …
Das Beispiel hat drei Aufgaben. Sellerie hat einen Ansatz für die verteilte Verarbeitung und mehrere nützliche Dienstprogramme, einschließlich der
Kettenfunktion , die eine Pipeline aus drei solchen Aufgaben macht:
chain( download_account_data.s(account_id), process_account_data.s(processing_type='fast'), store_account_data.s() ).delay()
Sellerie zerlegt die Pipeline, führt die erste Aufgabe der Reihe nach aus, überträgt dann die empfangenen Daten an die zweite und überträgt die Daten, die die zweite Aufgabe an die dritte zurückgibt. So implementieren wir einfache ETL-Pipelines.
Für komplexere Ketten müssen Sie zusätzliche Logik verbinden. Es ist jedoch wichtig zu beachten, dass die
gesamte Kette auseinander fällt , wenn in einer Aufgabe ein Problem in dieser Kette
auftritt . Wenn Sie dieses Verhalten nicht möchten, behandeln Sie die Ausnahme und setzen Sie die Ausführung fort, oder stoppen Sie die gesamte Kette ausnahmsweise.
Tatsächlich sieht diese Kette im Inneren wie eine große Aufgabe aus, die alle Aufgaben mit allen Parametern enthält. Wenn Sie also die Anzahl der Aufgaben in der Kette missbrauchen, erhalten Sie einen sehr hohen Speicherverbrauch und eine Verlangsamung des Gesamtprozesses.
Das Erstellen von Ketten mit Tausenden von Aufgaben ist eine schlechte Idee.Stapelaufgabenverarbeitung
Das Interessanteste: Was passiert, wenn Sie eine E-Mail an zwei Millionen Benutzer senden müssen?
Sie schreiben eine solche Funktion, um alle Benutzer zu umgehen:
@task def send_report_emails_to_users(): for user_id in User.get_active_ids(): send_report_email.delay(user_id=user_id)
In den meisten Fällen erhält die Funktion jedoch nicht nur die Benutzer-ID, sondern auch die gesamte Benutzertabelle im Allgemeinen. Jeder Benutzer hat seine eigene Aufgabe.
Bei dieser Aufgabe gibt es mehrere Probleme:
- Aufgaben werden nacheinander gestartet, dh die letzte Aufgabe (zweimillionster Benutzer) wird in 20 Minuten gestartet und funktioniert möglicherweise bereits zu diesem Zeitpunkt.
- Alle Benutzer-IDs werden zuerst in den Anwendungsspeicher geladen und dann in die Warteschlange - delay () führt 2 Millionen Aufgaben aus.
Ich habe es Task Flood genannt, das Diagramm sieht ungefähr so aus.
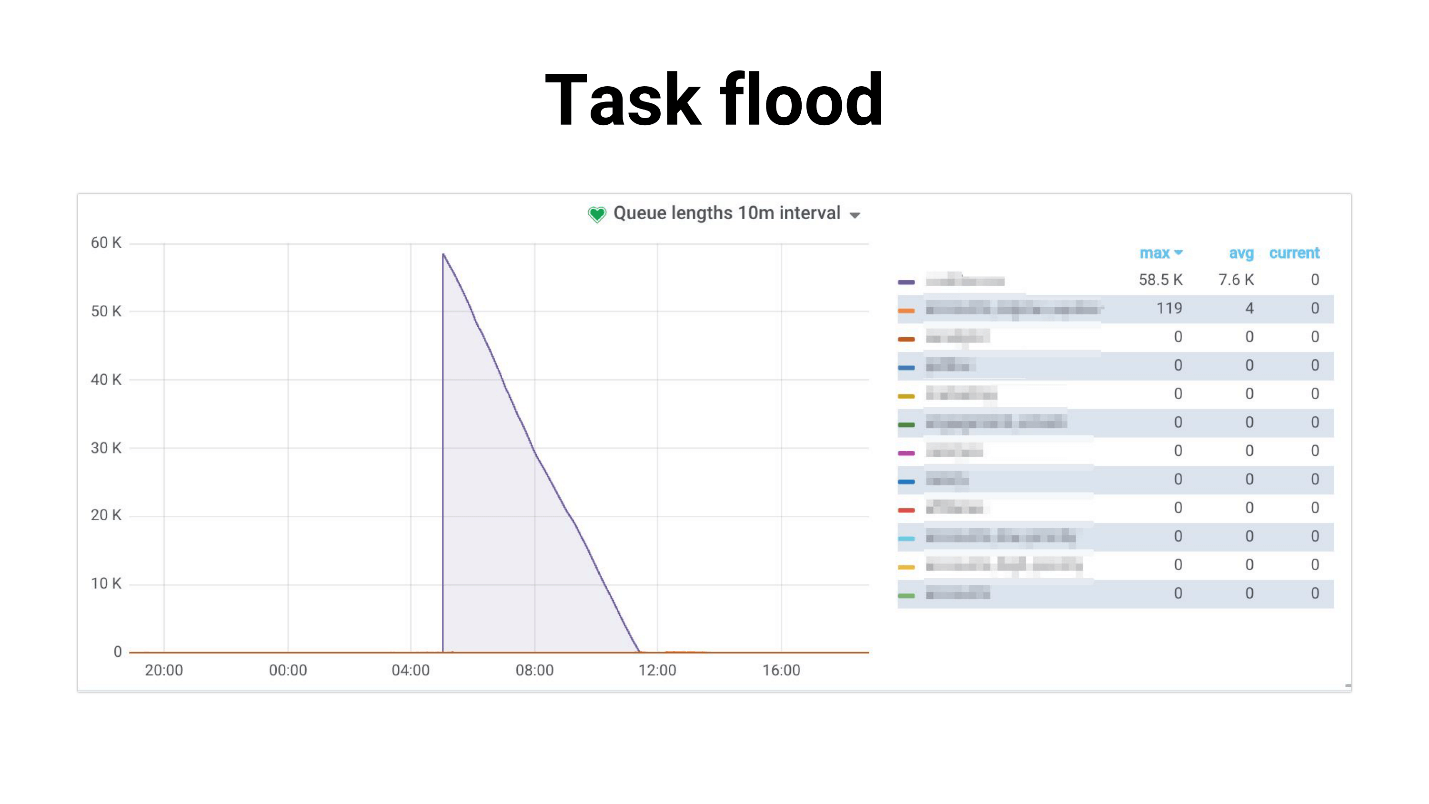
Es gibt einen Zustrom von Aufgaben, die die Mitarbeiter langsam zu bearbeiten beginnen. Folgendes passiert, wenn Aufgaben eine Master-Replik verwenden, das gesamte Projekt zu knacken beginnt und nichts funktioniert. Nachfolgend finden Sie ein Beispiel aus unserer Praxis, in der die DB-CPU-Auslastung mehrere Stunden lang 100% betrug. Um ehrlich zu sein, haben wir es geschafft, Angst zu bekommen.

Das Problem ist, dass das System mit zunehmender Anzahl von Benutzern stark beeinträchtigt wird. Die Aufgabe, die sich mit der Planung befasst:
- erfordert immer mehr Speicher;
- läuft länger und kann durch Timeout "getötet" werden.
Aufgabenüberflutung tritt auf: Aufgaben sammeln sich in Warteschlangen an und verursachen eine große Belastung nicht nur für interne, sondern auch für externe Dienste.
Wir haben versucht
, die Wettbewerbsfähigkeit der Arbeitnehmer zu verringern. Dies hilft in gewissem Sinne - die Belastung des Dienstes wird verringert. Oder Sie können
interne Services skalieren . Dies wird jedoch das Problem des Generatorproblems nicht lösen, das immer noch viel in Anspruch nimmt. Und beeinflusst in keiner Weise die Abhängigkeit von der Leistung externer Dienste.
Aufgabengenerierung
Wir haben uns für einen anderen Weg entschieden. In den meisten Fällen müssen wir derzeit nicht alle 2 Millionen Aufgaben ausführen. Es ist normal, dass das Versenden von Benachrichtigungen an alle Benutzer beispielsweise 4 Stunden dauert, wenn diese Briefe nicht so wichtig sind.
Zuerst haben wir versucht,
Celery.chunks zu verwenden :
send_report_email.chunks( ({'user_id': user.id} for user in User.objects.active()), n=100 ).apply_async()
Dies hat die Situation nicht geändert, da trotz des Iterators alle Benutzer-IDs in den Speicher geladen werden. Und alle Arbeiter bekommen eine Reihe von Aufgaben, und obwohl sich die Arbeiter ein wenig entspannen werden, waren wir am Ende mit dieser Entscheidung nicht zufrieden.
Wir haben versucht,
rate_limit auf Worker
festzulegen , damit diese nur eine bestimmte Anzahl von Aufgaben pro Sekunde verarbeiten, und wir haben herausgefunden, dass rate_limit, das für die Aufgabe angegeben wurde, rate_limit für den Worker ist. Wenn Sie also rate_limit für die Aufgabe angeben, bedeutet dies nicht, dass die Aufgabe 70 Mal pro Sekunde ausgeführt wird. Dies bedeutet, dass der Arbeiter es 70 Mal pro Sekunde ausführt, und abhängig davon, was Sie mit den Arbeitern haben, kann sich diese Grenze dynamisch ändern, d. H. real limit rate_limit * len (Arbeiter).
Wenn der Worker startet oder stoppt, ändert sich das gesamte rate_limit. Wenn Ihre Aufgaben langsam sind, wird außerdem der gesamte Prefetch in der Warteschlange, die den Worker füllt, mit diesen langsamen Aufgaben verstopft. Der Arbeiter sieht aus: „Oh, ich habe diese Aufgabe in rate_limit, ich kann sie nicht mehr ausführen. Und alle folgenden Aufgaben in der Warteschlange sind genau gleich - lassen Sie sie hängen! “ - und warten.
Chunkificator
Am Ende beschlossen wir, unsere eigene zu schreiben, und erstellten eine kleine Bibliothek namens Chunkificator.
@task @chunkify_task(sleep_timeout=...l initial_chunk=...) def send_report_emails_to_users(chunk: Chunk): for user_id in User.get_active_ids(chunk=chunk): send_report_email.delay(user_id=user_id)
Es benötigt sleep_timeout und initial_chunk und ruft sich selbst mit einem neuen Chunk auf. Chunk ist eine Abstraktion entweder über Ganzzahllisten oder über Datums- oder Datums- / Uhrzeitlisten. Wir übergeben den Block an eine Funktion, die nur Benutzer mit diesem Block empfängt und Aufgaben nur für diesen Block ausführt.
Somit führt der Aufgabengenerator nur die Anzahl der benötigten Aufgaben aus und verbraucht nicht viel Speicher. Das Bild ist so geworden.

Das Highlight ist, dass wir einen spärlichen Block verwenden, dh wir verwenden Instanzen in der Datenbank als Block-ID (einige von ihnen werden möglicherweise übersprungen, sodass möglicherweise weniger Aufgaben vorhanden sind). Infolgedessen stellte sich heraus, dass die Last gleichmäßiger war, der Prozess länger wurde, aber jeder lebt und es geht ihm gut, die Basis ist nicht anstrengend.
Die Bibliothek ist für Python 3.6+ implementiert und auf GitHub verfügbar. Es gibt eine Nuance, die ich beheben möchte, aber für den Moment benötigt datetime-chunk einen Pickle-Serializer - viele werden dies nicht können.
Ein paar rhetorische Fragen - woher kamen all diese Informationen? Wie haben wir herausgefunden, dass wir Probleme hatten? Woher wissen Sie, dass ein Problem bald kritisch wird und Sie bereits mit der Lösung beginnen müssen?
Die Antwort ist natürlich Überwachung.
Überwachung
Ich mag es wirklich zu überwachen, ich mag es alles zu überwachen und meinen Finger am Puls der Zeit zu halten. Wenn Sie Ihren Finger nicht am Puls der Zeit halten, treten Sie ständig auf den Rechen.
Standardüberwachungsfragen:
- Übernimmt die aktuelle Worker- / Parallelitätskonfiguration die Last?
- Was ist die Verschlechterung der Ausführungszeit von Aufgaben?
- Wie lange hängen Aufgaben in der Schlange? Plötzlich ist die Leitung schon überfüllt?
Wir haben verschiedene Optionen ausprobiert. Sellerie hat eine
CLI- Oberfläche, es ist ziemlich reichhaltig und bietet:
- inspizieren - Informationen über das System;
- Steuerung - Systemeinstellungen verwalten;
- Löschen - Löschen von Warteschlangen (höhere Gewalt);
- Ereignisse - Benutzeroberfläche der Konsole zum Anzeigen von Informationen zu ausgeführten Aufgaben.
Aber es ist schwer, etwas wirklich zu überwachen. Es ist besser für lokale Schnickschnack geeignet oder wenn Sie zur Laufzeit etwas rate_limit ändern möchten.
NB: Sie benötigen Zugriff auf den Produktionsbroker, um die CLI-Schnittstelle verwenden zu können.
Mit Celery Flower können Sie dasselbe wie mit der CLI tun, nur über die Weboberfläche, und das ist noch nicht alles. Es werden jedoch einige einfache Diagramme erstellt, und Sie können die Einstellungen im laufenden Betrieb ändern.
Im Allgemeinen ist Sellerieblume geeignet, um zu sehen, wie alles in kleinen Aufbauten funktioniert. Darüber hinaus unterstützt es die HTTP-API, was praktisch ist, wenn Sie Automatisierung schreiben.
Aber wir haben uns
für Prometheus entschieden. Sie nahmen den aktuellen
Exporteur : feste Speicherlecks darin; Metriken für Ausnahmetypen hinzugefügt; Metriken für die Anzahl der Nachrichten in den Warteschlangen hinzugefügt; Integriert in Warnungen in Grafana und freut euch. Es ist auch auf GitHub veröffentlicht, Sie können es
hier sehen .
Beispiele in Grafana

Oben Statistik für alle Ausnahmen: Welche Ausnahmen für welche Aufgaben. Unten ist die Zeit, um die Aufgaben zu erledigen.

Was fehlt in Sellerie?
Dies ist ein grüner Rahmen, er hat viele Dinge, aber wir fehlen! Es gibt nicht genügend kleine Funktionen wie:
- Automatisches Neuladen von Code während der Entwicklung - unterstützt diesen Sellerie nicht - Neustart.
- Metriken für Prometheus sind sofort einsatzbereit , Dramatiq jedoch.
- Unterstützung für die Aufgabensperre, sodass jeweils nur eine Aufgabe ausgeführt wird. Sie können es selbst tun, aber Dramatiq und Tasktiger haben einen praktischen Dekorateur, der sicherstellt, dass alle anderen ähnlichen Aufgaben blockiert werden.
- Rate_limit für eine Aufgabe - nicht für den Arbeiter.
Schlussfolgerungen
Trotz der Tatsache, dass Sellerie ein Framework ist, das viele in der Produktion verwenden, besteht es aus 3 Bibliotheken - Sellerie, Kombu und Billard. Alle drei Bibliotheken werden von Mitentwicklern entwickelt und können eine Abhängigkeit aufheben und Ihre Assembly unterbrechen.
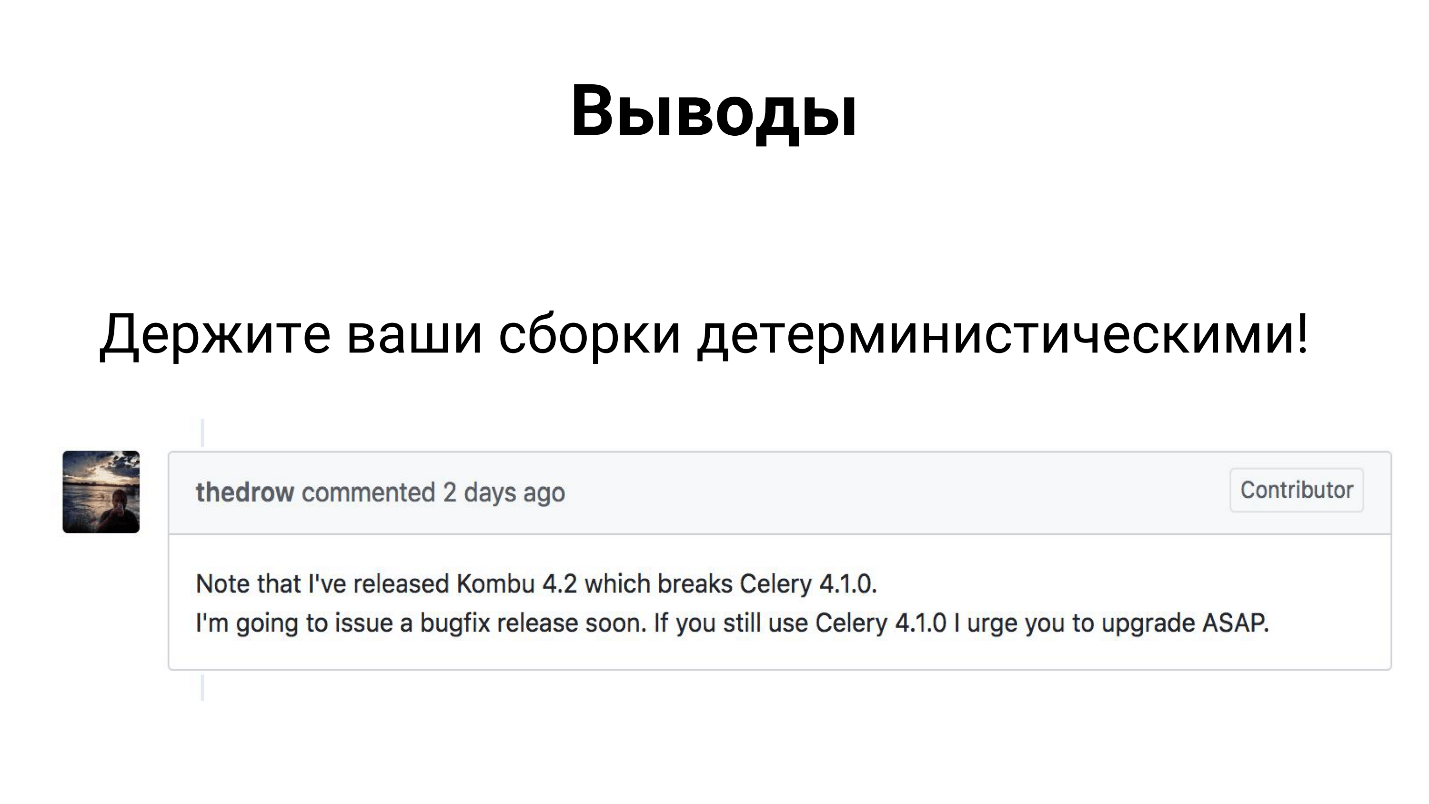
Daher hoffe ich, dass Sie es bereits irgendwie geklärt und Ihre Versammlungen deterministisch gemacht haben.
In der Tat sind die Schlussfolgerungen nicht so traurig.
Sellerie bewältigt seine Aufgaben in unserem Fintech-Projekt unter unserer Last. Wir haben Erfahrungen gesammelt, die ich mit Ihnen geteilt habe, und Sie können unsere Lösungen anwenden oder verfeinern und auch alle Ihre Schwierigkeiten überwinden.
Vergessen Sie nicht, dass die
Überwachung ein wesentlicher Bestandteil Ihres Projekts sein sollte . Nur durch Überwachung können Sie herausfinden, wo etwas nicht stimmt, was behoben, hinzugefügt, behoben werden muss.
Ansprechpartner Oleg Churkin :
Bahusss ,
Facebook und
Github .
Die nächste große Moscow Python Conf ++ findet am 5. April in Moskau statt . In diesem Jahr werden wir versuchen, alle Vorteile an einem Tag in einem experimentellen Modus zu vereinen. Es wird nicht weniger Berichte geben, wir werden ausländischen Entwicklern bekannter Bibliotheken und Produkte einen ganzen Strom zuweisen. Darüber hinaus ist Freitag ein idealer Tag für After-Partys, der, wie Sie wissen, ein wesentlicher Bestandteil der Konferenz über Kommunikation ist.
Nehmen Sie an unserer professionellen Python-Konferenz teil - reichen Sie Ihren Bericht hier ein und buchen Sie Ihr Ticket hier . In der Zwischenzeit laufen die Vorbereitungen, Artikel zu Moscow Python Conf ++ 2018 werden hier erscheinen.