Wir alle schreiben Code. Viel Code. Natürlich gibt es Fehler. Manchmal ist es nur ein krummer Code, und manchmal ist der Preis eines Fehlers ein explodiertes
Raumschiff . Natürlich macht niemand absichtliche Pfosten, jeder versucht, die Qualität nach besten Kräften zu überwachen, aber ohne statische Analysewerkzeuge ist es kaum möglich, sicher zu sein, dass alles perfekt ist.
Linters helfen dabei, Code in einen einzigen Stil zu bringen und Fehler zu vermeiden. Richtig, nur wenn Sie bereit sind zu leiden und am Ende „pylint: disable“ nicht entlassen, nur um es hinter sich zu lassen. Was ein Linter sein sollte und warum Pylint das nicht kann, kennt Nikita
Sobolevn , der Linters so sehr versteht und liebt, dass er sogar seine Firma nannte, um sie nicht zu verärgern - wemake.services.
Unten finden Sie die Textversion des Berichts über
Moscow Python Conf ++ über Linters, wie man sie richtig macht und wie man sie nicht macht. Die Präsentation hatte viel Interaktivität, Online und Kommunikation mit dem Publikum. Der Redner führte unterwegs Umfragen durch und versuchte, das Publikum zu überzeugen: Er betrachtete den Trend und versuchte wie in der Debatte, das Verhältnis auszugleichen und die öffentliche Meinung zu ändern. Ein Teil der Umfragen wurde entschlüsselt, aber nicht alle. Daher wird ein Video angehängt, um das Bild zu vervollständigen.
Warum brauchen wir Linters?
Die wichtigste Aufgabe von linter ist es
, den Code einheitlich zu machen . Es gibt viele Möglichkeiten, dasselbe in Python zu schreiben: Setzen Sie hier oder da ein Komma, vergessen Sie, die Klammern zu schließen, oder vergessen Sie nicht. Wenn Leute lange Zeit Code schreiben, wird es wie ein Patchwork-Quilt aus unterschiedlichen Teilen, die zu unterschiedlichen Zeiten genäht werden. Es ist unangenehm, mit einer solchen Decke zu arbeiten, und es wird davon abgeraten, den Code zu lesen, was sehr schlecht ist.
Linters erleichtern das Leben bei einer Überprüfung . Ich komme zur Codeüberprüfung und denke: „Ich möchte das nicht tun! Jetzt wird es zusätzliche Räume und anderen Unsinn geben! “ Ich möchte, dass jemand anderes guten Code vorbereitet, und danach werde ich die großartigen konzeptionellen Dinge zu schätzen wissen.
Manchmal schaue ich auf den Code und denke, dass alles in Ordnung ist, und dann sehe ich in einigen Funktionen zu viele Variablen oder einen Fehler, auf den ich nicht geachtet habe. Die Automatisierung würde diesen Fehler finden, aber ich habe nachgesehen. Um nicht in solche Situationen zu geraten - ich benutze den
Linter -
findet er alles, was verborgen und schwer zu finden ist.Was sind Linters?
Die einfachsten überprüfen nur den Stil , zum Beispiel
Flake8 . Zum Teil auch Schwarz, sondern ein Autoformer-Linter.
Linters testen die Semantik schwieriger und nicht nur die Stilistik: Was Sie tun, warum und schlagen Sie auf die Hände, wenn Sie mit Fehlern schreiben. Ein gutes Beispiel ist
Pylint , das wir alle kennen, benutzen und lieben. Ich nenne diese Linters -
Best Practices . Der dritte Typ ist die
Typprüfung . Diese Linter sind etwas abseits. Die Typprüfung in Python ist neu und wird jetzt von zwei konkurrierenden Plattformen durchgeführt:
Mypy und
Pyre .
Wie benutzt man Linter?
Ich behaupte nicht, dass Linter ein Allheilmittel und ein Ersatz für alles ist. Es ist nicht so. Linter - der erste Schritt der Pyramide, mit dem der Code in Produktion geht.
Die Pyramide besteht aus drei Schritten:
- Linter starten . Es ist sehr schnell und benötigt nur den Quellcode - keine Infrastruktur, keine Einstellungen. Check: Der erste Sanity Check wurde bestanden - alles ist in Ordnung, wir arbeiten daran.
- Testphase . Dieser Vorgang ist aufgrund von Nicht-Code-Fehlern komplizierter und länger. Wir benötigen bereits die korrekte und vollständige Einrichtung der gesamten Anwendung.
- Bühnenrückblick .
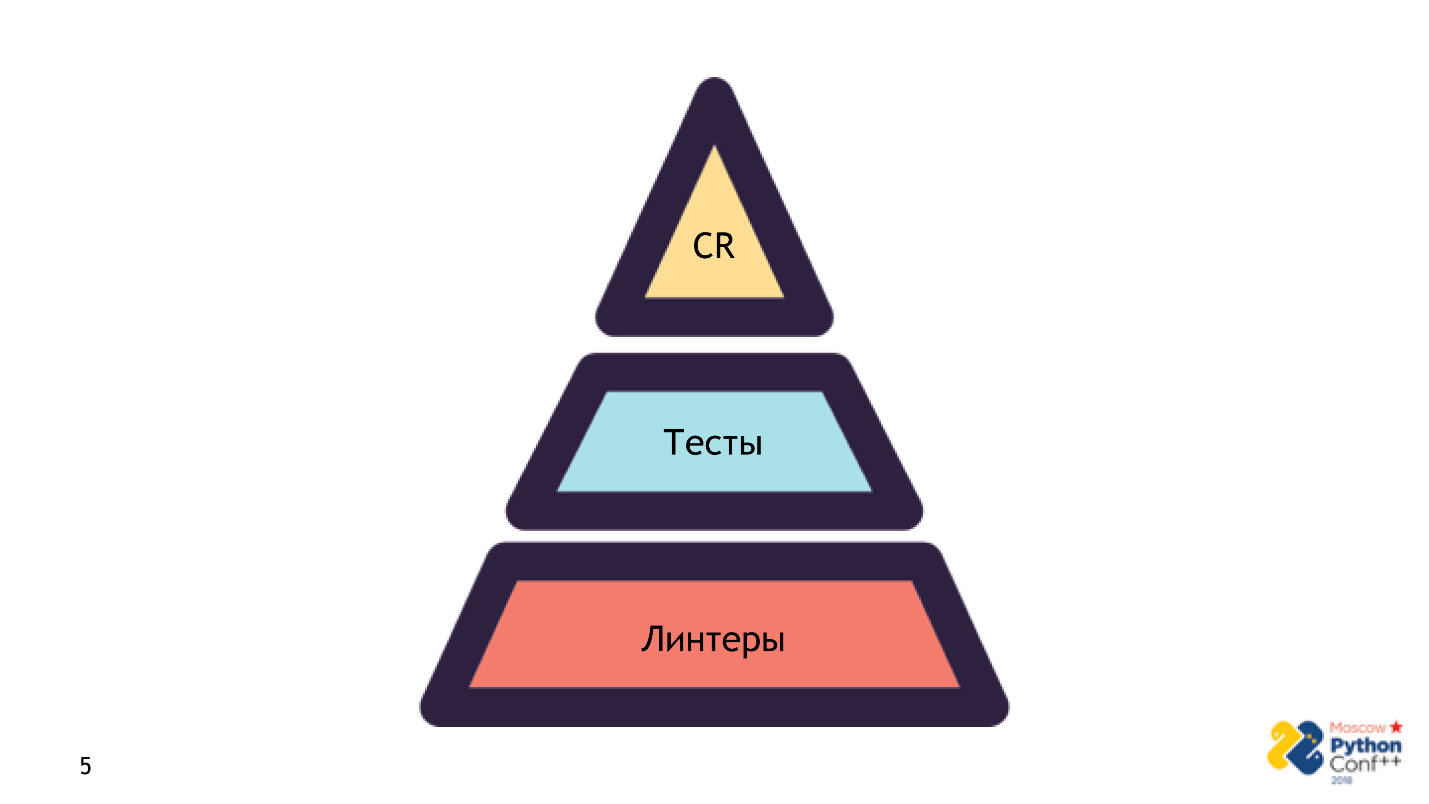 Dies sind die notwendigen Schritte,
Dies sind die notwendigen Schritte, damit der Code in Produktion geht. Wenn Sie keinen Schritt durchlaufen haben, etwas vergessen haben oder der Prüfer sagte, dass es nicht funktionieren würde, wird die Inschrift angezeigt: Fehlgeschlagen - der fehlerhafte Code wird nicht produziert.
Verwenden Sie bei der Arbeit einen Linter?
Wenn Sie Entwickler aus einem harten Unternehmen, in dem sie 7 Tage die Woche arbeiten, fragen, ob sie einen Linter verwenden, stellt sich heraus, dass mindestens ein Drittel von ihnen sehr streng Linters verwendet:
CI fällt ab, Überprüfungen sind streng . Der Rest wendet Linter ungefähr gleichermaßen
an, um den Stil zu überprüfen ,
niemals als
Berichtssystem : Sie starten den Linter, generieren einen Bericht und sehen, wie schlecht alles ist. Linters werden verwendet, und das ist gut so. In unserem Unternehmen wurde alles sehr hart gebaut: harte Verknüpfung, viele Überprüfungen, doppelte Codeüberprüfung.
Codeüberprüfung
Probleme treten gerade in diesem Stadium auf. Dies ist der oberste und schwierigste Schritt der Pyramide: Die Codeüberprüfung kann nicht automatisiert werden und führt nach Möglichkeit zur Automatisierung des Code-Schreibens. Dann werden die Programmierer nicht benötigt.
Standardmäßig sieht der Vorgang folgendermaßen aus: Der Code wird überprüft, ich finde Fehler und möchte sie nicht mehr erstellen. Ich habe zum Beispiel gesehen, dass der Entwickler BaseException abgefangen hat: „Tun Sie das nicht. Bitte nicht fangen! " Nach 10 Tagen das Gleiche. Ich erinnere dich noch einmal:
-
BaseException wird nicht abgefangen."
Gut, ich verstehe."Ein Jahr vergeht - der gleiche Fehler. Ein neuer Mann kommt - der gleiche Fehler. Ich denke - wie können wir alles automatisieren, damit die Situation nicht noch einmal passiert und nur in den Sinn kommt: „
Lassen Sie uns unseren Linter zertrümmern? »Lassen Sie uns ein offenes Paket erstellen, alle Regeln, die wir in der Arbeit verwenden, dort ablegen und die Regelprüfung automatisieren, damit wir nicht jedes Mal von Hand schreiben. Wir automatisieren alles gut und sofort!
Natürlich kann man sagen: „Es
gibt bereits fertige Linters, sie funktionieren, jeder benutzt sie - warum machen sie ihre eigenen?“ Und Sie werden absolut Recht haben, denn es gibt wirklich Linters. Mal sehen, welche und was sie tun.
Pylint
Auf der Überschrift "
Warum nicht Pylint?" "Ich habe diese Frage oft gehört. Ich werde ihm leiser antworten. Pylint ist ein großartiges Rockstar-Tool für Python-Code, bietet jedoch Funktionen, die ich in meinem Linter nicht sehen möchte.
Es mischt alles zusammen: Stilprüfungen, Best Practices und Typprüfungen . Die Pylint-Typprüfung ist unterentwickelt, da keine Typinformationen vorhanden sind: Sie versucht, sie irgendwie anzuzeigen, funktioniert jedoch nicht sehr gut. Daher kann ich häufig, wenn ich
model_name.some_property auf Django schreibe, den Fehler sehen: "Entschuldigung, es gibt keine solche Eigenschaft - Sie können sie nicht verwenden!" Ich erinnere mich, dass es ein Plugin gibt, ich installiere es, dann benutze ich Sellerie, es verursacht auch Probleme, ich installiere das Plugin für Sellerie, benutze eine andere magische Bibliothek und als Ergebnis schreibe ich einfach überall: "pylint: disable" ... das ist es nicht was ich von linter bekommen will.
Eine weitere Funktion, die dem Benutzer verborgen bleibt
, ist,
dass Pylint eine eigene Implementierung des abstrakten Syntaxbaums in Python hat . So sieht der Code aus, wenn Sie ihn analysieren und Informationen über den Baum der Knoten abrufen, aus denen der Code besteht. Ich vertraue meinen eigenen Implementierungen nicht wirklich, weil sie immer falsch sind.
Neben Pylint gibt es noch andere Linters, die ihre Arbeit erledigen.
Sonarquube
Ein wunderbares, aber separates Tool, das irgendwo in der Nähe Ihres Projekts lebt.
- SonarQube kann nicht oft ausgeführt werden : Es muss irgendwo bereitgestellt, überwacht, überwacht und konfiguriert werden.
- Es ist in Java geschrieben . Wenn Sie Ihren Linter für Python reparieren möchten, schreiben Sie Code in Java. Ich denke, dass dies konzeptionell falsch ist - ein Entwickler, der in Python schreiben kann, sollte in der Lage sein, Code zum Testen von Python zu schreiben.
Das Unternehmen, das SonarQube entwickelt, befasst sich speziell mit dem Konzept der Produktentwicklung. Dies kann ein Problem sein.
Der Vorteil von SonarQube ist, dass es sehr coole Überprüfungen gibt, die Komplexität, mögliche versteckte Fehler und Fehler anzeigen. Ich mag die Schecks, ich würde sie verlassen und die Plattform wechseln.
Flake8
Ein wunderbarer Linter ist sehr einfach, aber mit einem Problem: Es
gibt nur wenige Regeln, nach denen überprüft wird, wie gut der Code geschrieben ist. Gleichzeitig hat Flake8 viele sehr einfache Plugins: Das minimale Plugin besteht aus 2 Methoden, die implementiert werden müssen. Ich dachte - nehmen wir Flake8 als Basis und schreiben Plugins, aber mit unserem Verständnis der Vorteile für das Unternehmen. Und so haben wir es gemacht.
Der strengste Linter der Welt
Wir haben ein Tool erstellt, in dem wir alles gesammelt haben, was wir für Python für richtig halten, und das
wemake-python-styleguide heißt . Das Plugin wurde öffentlich veröffentlicht, da ich glaube, dass
Open Source by Default eine gute Praxis ist . Ich bin zutiefst davon überzeugt, dass viele Tools davon profitieren werden, wenn sie auf Open Source hochgeladen werden. Für unser Instrument haben wir uns den Slogan
ausgedacht :
"Der strengste Linter der Welt!"Das Schlüsselwort in unserem Linter ist streng, was Schmerz und Leiden bedeutet.
Wenn Sie den Linter verwenden und Sie dadurch nicht leiden, dass Sie Ihren Kopf umklammern: "Warum magst du ihn nicht, verdammt noch mal?", Dann ist dies ein schlechter Linter. Es überspringt Fehler, überwacht die Qualität des Codes nicht ausreichend und wir brauchen ihn nicht. Wir brauchen die strengsten der Welt, die viel kontrollieren. Jetzt haben wir ungefähr
250 verschiedene Tests in beiden Kategorien : Stil- und Best Practices, jedoch ohne Typprüfung. Mypy ist damit beschäftigt, wir kümmern uns in keiner Weise um ihn.
Unser Linter geht
keine Kompromisse ein . Wir haben keine Regeln aus der Kategorie "Ich würde das nicht wollen, aber wenn du es wirklich willst, dann kannst du es." Nein, wir sprechen immer hart - wir tun es nicht, weil es schlecht ist. Dann kommen die Leute und sagen: „Es gibt 2,5 Anwendungsfälle, in denen dies grundsätzlich möglich ist!“. Wenn es solche Fälle gibt, schreiben Sie deutlich, dass diese Zeile für den Linter zulässig ist, um sie zu ignorieren, aber erklären Sie, warum. Es sollte ein Kommentar sein, warum Sie eine seltsame Übung zugelassen haben und warum Sie dies tun. Dieser Ansatz ist auch nützlich, um Code zu dokumentieren.
Der strengste Linter
erfordert keine Einstellungen (WIP) . Wir haben noch Einstellungen, aber wir möchten sie loswerden: Mit der Freiheit wird der Benutzer sicher konfigurieren, dass der Linter nicht richtig funktioniert.
Ein gutes Werkzeug benötigt keine Einstellungen - es hat gute Standardwerte.
Mit diesem Ansatz ist der Code konsistent und funktioniert zumindest theoretisch für alle gleich. Wir arbeiten noch daran, und obwohl es Einstellungen gibt, können Sie unser Tool verwenden und es selbst anpassen.
Von wem sind wir abhängig?
Aus einer Vielzahl von Werkzeugen.
- Flake8 .
- Eradicate ist ein cooles Plugin, das auskommentierte Fragmente im Code findet und Sie dazu bringt, sie zu löschen, da das Speichern von totem Code in einem Projekt schlecht ist. Das dürfen wir nicht.
- Isort ist ein Tool, das Sie dazu zwingt, Importe korrekt zu sortieren: Einreihen, schöne Anführungszeichen.
- Bandit ist ein großartiges Tool zur statischen Überprüfung der Codesicherheit. Es findet kabelgebundene Passwörter, die ungeschickte Verwendung von
assert im Code, ruft Popen , sys.exit und sagt, dass all dies nicht verwendet werden kann, aber wenn Sie möchten, werden Sie aufgefordert, den Grund zu schreiben. - Und mehr als 20 Plugins , die Klammern, Anführungszeichen und Kommas überprüfen.
Was überprüfen wir?
Es gibt 4 Gruppen von Regeln, die wir verwenden und durchsetzen.
Komplexität ist das größte Problem. Wir wissen nicht, was Komplexität ist, und wir sehen sie nicht im Code. Wir schauen uns den Code an, mit dem wir jeden Tag arbeiten, und es scheint nicht kompliziert zu sein - nehmen Sie ihn, lesen Sie ihn, alles funktioniert. Es ist nicht so. Einfacher Code ist ein vertrauter Code. Komplexität hat klare Kriterien, die wir testen. Über die Kriterien selbst - später. Wenn der Code die Kriterien verletzt, sagen wir: "Der Code ist komplex, schreiben Sie neu!"
Namen für Variablen sind ein ungelöstes Programmierproblem. Wer wann und in welchem Kontext liest, ist unklar. Wir versuchen, die Namen so konsistent und verständlich wie möglich zu machen, aber obwohl wir es versuchen, ist das Problem noch nicht vollständig gelöst.
Aus
Gründen der Konsistenz haben wir eine einfache Regel: Schreiben Sie überall dasselbe. Wenn es einen genehmigten Ansatz gibt, verwenden Sie ihn überall. Es spielt keine Rolle, ob Sie es mögen oder nicht, Konsistenz ist wichtiger.
Wir versuchen, nur die
Best Practices zu verwenden. Wenn wir wissen, dass einige Praktiken nicht sehr gut sind, verbieten wir ihre Verwendung. Wenn der Entwickler verbotene Praktiken anwenden möchte, erwarten wir von ihm Argumente: Warum und warum? Vielleicht wird während des Beschreibungsprozesses ein Verständnis dafür entstehen, warum es schlecht ist.
Was ist Komplexität?
Die Komplexität verfügt über bestimmte Metriken, anhand derer Sie feststellen können, ob es schwierig ist oder nicht. Es gibt viele davon.
Zyklomatische Komplexität - jedermanns beliebteste zyklomatische Komplexität. Es findet im Code eine große Anzahl verschachtelter,
if auch
for andere Strukturen, und zeigt zu viel Verzweigung des Codes und Schwierigkeiten beim Lesen an. Mit dem eingebetteten Code ist alles schlecht: Sie lesen, lesen, lesen - gingen zurück, lesen, lesen, lesen - sprangen auf und gingen dann in einen anderen Zyklus. Es ist unmöglich, einen solchen Code sicher von oben nach unten zu übergeben.
Argumente, Anweisungen und Rückgaben. Dies sind quantitative Metriken: Wie viele Argumente befinden sich in der Funktion oder in der Methode, wie viele befinden sich im Hauptteil dieser Funktion oder in der Anweisung und der Rückgabemethode.
Kohäsion und Kopplung sind beliebte OOP-Metriken.
Der Zusammenhalt zeigt die Verbundenheit der Klasse im Inneren. Zum Beispiel gibt es eine Klasse, in der Sie alle Methoden und Eigenschaften verwenden - alles, was Sie deklariert haben. Dies ist eine gute Klasse mit hoher Konnektivität im Inneren.
Die Kopplung gibt an, wie stark die verschiedenen Teile des Systems miteinander verbunden sind: Module und Klassen. Wir wollen maximale Konnektivität innerhalb der Klasse und minimale Konnektivität außerhalb erreichen. Dann ist das System leicht zu warten und funktioniert gut.
Jones Complexity - Ich habe diese Metrik ausgeliehen, aber nur, weil es eine Bombe ist! Die Jones-Komplexität bestimmt die Komplexität einer Linie - je komplexer die Linie ist, desto schwieriger ist es, sie zu verstehen, da das menschliche Kurzzeitgedächtnis nicht mehr als 5-9 Objekte gleichzeitig verarbeiten kann. Dies ist die sogenannte
Miller-Brieftasche .
Wir betrachten diese wichtigen Metriken und einige andere, die viel größer sind, und bestimmen, ob der Code geeignet ist oder nicht.
Komplexität ist nach unserem Verständnis
ein Wasserfall .
Wasserfall Schwierigkeit
Die Schwierigkeit beginnt mit der Tatsache, dass wir die Zeile geschrieben haben und sie immer noch gut ist. Aber dann kommt das Geschäft und sagt, dass sich die Preise verdoppelt haben und wir mit 2 multiplizieren. Zu diesem Zeitpunkt wird Jones Complexity verrückt und berichtet, dass die Linie jetzt zu kompliziert ist - es gibt zu viel Logik.
Nun, wir starten eine neue Variable und der Funktionskomplexitätsanalysator sagt:
-
Nein, das ist nicht so - jetzt gibt es zu viele Variablen in der Funktion.Ich werde eine neue
Methode erstellen und ihr Argumente übergeben. Wenn Sie nun die Anzahl der Funktionsargumente oder die Anzahl der Methoden innerhalb der
Klasse überprüfen, ist dies ebenfalls unmöglich - die Klasse ist zu komplex und muss in zwei Teile unterteilt werden. Absturz durch Hervorheben einer anderen Klasse. Jetzt gibt es mehr Klassen und alles ist in Ordnung. Wenn Sie jedoch die Komplexität des
Moduls überprüfen, wird
festgestellt , dass das Modul jetzt zu komplex ist und überarbeitet werden muss. Warum ?!
Das nennt man Leiden. Deshalb sage ich, dass ein Linter dich leiden lassen sollte. Wir haben zunächst in einer Zeile mit 2 multipliziert und schließlich
das gesamte System überarbeitet . Das Hinzufügen eines kleinen Codeteils führt zur Umgestaltung ganzer Module, da sich die Komplexität wie ein Wasserfall ausbreitet und alles abdeckt, was möglich ist.
"Need to Refactor" - Mit diesem Ding können Sie den Code umgestalten. Sie können sich nicht einfach zurücklehnen: "Ich berühre diesen Code nicht, er scheint zu funktionieren." Nein, eines Tages werden Sie den Code an einer anderen Stelle ändern, und ein Wasserfall von Komplexität wird das Modul überfluten, das Sie nicht berührt haben, und Sie müssen es umgestalten. Ich glaube, dass Refactoring gut ist und je mehr es ist, desto stabiler und besser funktioniert Ihr System.
Und alles andere ist subjektiv!Sprechen wir jetzt über den Geschmack. Dies ist ein ganzheitlicher und interaktiver Teil!
Holivar
Lassen Sie uns unterstützen, Kommentare sind offen. Lassen Sie mich zunächst daran erinnern, dass Namen ein komplexes und ungelöstes Problem sind. Sie können darüber streiten, wie eine Variable benannt werden soll, aber wir haben einige Ansätze, die zumindest helfen, keine offensichtlichen Fehler zu machen.
Namen
Wie gefällt Ihnen:
var, value, item, obj, data, result ? Was sind
Daten ? Einige Daten. Was ist das
Ergebnis ? Eine Art Ergebnis. Oft sehe ich die
Ergebnisvariable und einen Aufruf einer höllischen Methode in einer unverständlichen Klasse - und ich denke: „Was ist dieses Ergebnis? Warum ist er hier? "
Es gibt viele Entwickler, die mir nicht zustimmen und sagen, dass
value ein ganz normaler Variablenname ist:
-
Ich benutze immer Schlüssel und Wert!-
Warum nicht Schlüssel und Wert verwenden, aber sagen, dass der Schlüssel der Name und der Wert der Nachname ist? Warum es unmöglich ist, Vorname und Nachname zu benennen - jetzt gibt es einen Kontext.Normalerweise stimmen die Leute zu, aber sie streiten sich trotzdem. Dies ist eine sehr ganzheitliche Sache: Mindestens 3 Menschen haben eine Stunde ihres Lebens mit mir verbracht, um mit mir darüber zu streiten.
Ist es in Ordnung, Variablen mit einem Buchstaben zu benennen?
Zum Beispiel
q ? Wir alle kennen den klassischen Fall:
for i in some_iterable: Was bin
ich In C ist dies Standard, und alles kommt davon. Aber in Python Sammlungen und Iteratoren. Die Sammlungen enthalten Elemente mit Namen - nennen wir sie irgendwie anders.
Die Hälfte der Entwickler hält das Aufrufen der Variablen i, x, y, z für normal.
Ich glaube, dass Sie Namen nicht mit einem Buchstaben benennen können. Ich möchte mehr Kontext und es ist gut, dass die zweite Hälfte der Entwickler mir zustimmt. Wenn dies in C aufgrund des historischen Erbes immer noch zulässig ist, ist dies in Python ein sehr großes Problem, und Sie müssen dies nicht tun.
Konsistenz
Wählen wir einfach einen Weg aus vielen heraus und sagen: "Lass es uns tun." Ob es gut oder schlecht ist - es spielt keine Rolle mehr - ist einfach konsistent.
Wir sprechen nur über Python 3, Legacy wird überhaupt nicht berücksichtigt.
Ich habe ein Argument: Wenn wir von etwas erben, sollten wir wissen, von was - es wäre schön, den Namen des Elternteils zu sehen. Das Lustige ist, dass wir normalerweise den Namen des Elternteils sehen, außer wenn dies ein
Objekt ist . Deshalb habe ich mir eine Regel formuliert: Wenn ich eine Klasse schreibe, erbe ich von etwas - ich schreibe immer den Namen des Elternteils. Es spielt keine Rolle, was es sein wird - Modell, Objekt oder etwas anderes.
Wenn Sie die Wahl haben,
Class Some(object) oder
class Some zu schreiben, werde ich die erste auswählen. Einerseits zeigt es, dass wir immer klar schreiben, wovon wir erben. Auf der anderen Seite gibt es keine besondere
Ausführlichkeit : Wir verlieren nichts durch ein paar zusätzliche Tastenanschläge.
Zwei Drittel der Entwickler kennen die zweite Option besser, und ich weiß sogar warum. Meine Hypothese: Alles nur, weil wir lange von der zweiten Version von Python auf die dritte migriert sind und jetzt zeigen wir, dass wir in der dritten Python schreiben. Ich weiß nicht, wie die Hypothese richtig ist, aber es scheint mir so.
F-Linien sind schrecklich?
Antwortoptionen:
- Ja: Sie verlieren den Kontext, fügen Logik in die Vorlage ein und fusseln nicht - (38%).
- Nein! Sie sind ein Wunder! - (62%).
Es gibt eine Hypothese, dass F-Linien schrecklich sind. Sie schieben alles in sie hinein! f-Zeilen sind nicht dasselbe wie
.format , die Unterschiede sind dramatisch. Wenn wir eine Vorlage deklarieren und dann formatieren, führen wir zwei Aktionen separat aus: Zuerst definieren wir die Vorlage und formatieren sie dann. Wenn wir eine f-Zeile deklarieren, führen wir zwei Aktionen gleichzeitig aus: Wir deklarieren die Vorlage sofort und formatieren sie im selben Moment.
Es gibt zwei Probleme mit F-Linien. Wir haben eine Vorlage für die F-Linie deklariert und alles funktioniert. Und dann entscheiden wir uns, die Vorlage 2 in eine Reihe zu verschieben oder in eine andere Funktion zu verschieben - und alles bricht.
Jetzt gibt es keinen Kontext, in dem wir Zeichenfolgen formatieren konnten , und wir können sie nicht richtig verarbeiten. Das zweite große Problem mit F-Linien: Sie ermöglichen es Ihnen, das Schreckliche zu tun -
die Logik in die Vorlage zu stecken . Angenommen, es gibt eine Zeile, in die wir einfach den Benutzernamen und das Wort "Hallo" einfügen - das ist normal. Es gibt nichts besonders Schreckliches, aber dann sehen wir, dass der Benutzername in Großbuchstaben geschrieben wird. Wir beschließen, ihn in eine Titel-Groß- und Kleinschreibung zu übersetzen und direkt in die Vorlage
username.title() schreiben. Anschließend werden Bedingungen, Zyklen und Importe in der Vorlage angezeigt. Und alle anderen Teile von PHP.
All diese Probleme lassen mich sagen, dass
F-Linien ein schlechtes Thema sind , wir verwenden sie nicht. Das Lustige ist, dass wir keinen Fall haben, in dem nur F-Linien für uns geeignet sind. Normalerweise ist jede Formatierung geeignet, aber wir haben
.format - alles andere ist unmöglich - weder
% noch F-Zeilen. Die Arbeit von
.format ebenfalls fusselig, da Sie darin geschweifte Anführungszeichen setzen und entweder den Namen der Variablen oder ihre Reihenfolge schreiben können.
Während des Berichts stieg die Anzahl der F-Line-Gegner von 33 auf 38% - dies ist ein kleiner, aber siegreicher Sieg.
Die Zahlen
Mögen Sie Zahlen wie diese:
final_score = 69 * previous result / 3.14 . Dies scheint eine Standard-Codezeile zu sein, aber was ist 69? Solche Fragen stellen sich oft, wenn ich mir den Code ansehe, den ich vor einiger Zeit geschrieben habe, und der Manager sagt in diesem Moment:
-
Bitte mit 147 multiplizieren.-
Warum bei 147?-
Wir haben solche Tarife.Ich habe multipliziert und vergessen, oder ich habe lange Zeit einen Wert des Koeffizienten aufgenommen, damit alles funktioniert - und dann habe ich vergessen, wie ich ihn aufgenommen habe und warum. Es stellt sich heraus, dass wichtige Forschungsarbeiten hinter einer unbenannten Zahl verborgen blieben. Ich weiß nicht einmal, was diese Nummer ist, aber ich kann sie nur finden, zurückrufen und irgendwie wiederherstellen, indem ich sie später festschreibe.
Warum nicht anders machen - alle komplexen Zahlen mit Name und Dokumentation in eine eigene Variable einfügen? Schreiben Sie beispielsweise für die Zahl 69, dass dies der durchschnittliche Indikator auf dem Markt ist und die Konstante nun einen Namen und einen Kontext hat. Ich werde einen Kommentar schreiben, dass ich die Konstante an der Stelle einer solchen Studie genommen habe. Wenn sich die Forschung in Zukunft ändert, werde ich kommen und die Daten aktualisieren.
Somit garantieren wir, dass keine magischen Zahlen durch unseren Code gelangen und ihn von innen heraus komplizieren. Sie überprüfen die Komplexität jeder Zeile und sagen: "Hier ist die Nummer 4766. Was ist das, ich weiß nicht, klären Sie es selbst!" Dies war eine großartige Entdeckung für mich.
Als Ergebnis haben wir erkannt, dass wir dies befolgen müssen, und wir verpassen keine magischen Zahlen im Code. Es ist gut, dass fast 100% unserer Kollegen uns zustimmen und solche Zahlen auch nicht verwenden.
Es gibt jedoch Ausnahmen - dies sind Zahlen von –10 bis 10, Zahlen 100, 1000 und dergleichen, einfach weil sie oft gefunden werden und ohne sie schwierig ist.
Wir sind hart, aber nicht sadistisch und denken ein wenig nach.
Verwenden Sie '@staticmethod'?
Lassen Sie uns darüber nachdenken, was
statische Methode ist . Haben Sie sich jemals gefragt, warum es in Python ist? Ich nicht. Ich hatte einen schönen Pylint, der sagte:
-
Schau, du benutzt nicht self ,
cls -
mach eine statische Methode!-
Okay, Pylint, ich mache eine statische Methode.Dann brachte ich Anfängern Python bei und sie fragten, was statische Methode ist und warum sie benötigt wird. Ich kannte die Antwort nicht und dachte, ob es möglich ist, dasselbe mit einer Funktion zu schreiben oder sich selbst nicht in einer regulären Funktion zu verwenden, einfach weil es eine solche Klasse ist und etwas passiert. Warum brauchen wir ein statisches Methodenkonstrukt?
Ich habe die Frage gegoogelt und sie war so tief wie ein Kaninchenbau. Es gibt viele andere Programmiersprachen, in denen die statische Methode ebenfalls nicht beliebt ist. Und gut begründet - staticmethod bricht das Objektmodell. Als Ergebnis wurde mir klar, dass die
statische Methode hier nicht der richtige Ort ist , und wir haben sie herausgesägt. Wenn wir nun den StaticMethod Decorator verwenden, sagt der Linter: "Nein, sorry, Refactor!"
Die meisten Entwickler sind mit mir nicht einverstanden, aber ungefähr die Hälfte ist immer noch der Meinung, dass es besser ist, reguläre Methoden oder reguläre Funktionen anstelle von statischen Methoden zu schreiben.
Logik in __init __. Ru - gut oder schlecht?
Das ist mein Lieblingsthema. Sicherlich, wenn Sie ein neues Paket erstellen und es irgendwie aufrufen - es erzeugt __init __. Ru und Sie fragen sich, was Sie darin einfügen sollen? Was in __init __. Ru einfügen und was - in Dateien nebeneinander? Für mich war dies eine nicht triviale Frage, und ich war immer verloren: wahrscheinlich etwas Wichtigstes? Dann dachte ich - nein, im Gegenteil, ich werde das Wichtigste in den verständlichsten Kontext stellen. Wenn Sie etwas in __init __. Ru einfügen und dann alles importieren, stellt sich heraus, dass zyklische Importe ebenfalls schlecht sind.
Ich habe mir verschiedene populäre Bibliotheken angesehen, ihre __init __. Ru geklettert und festgestellt, dass es im Grunde entweder Müll oder Abwärtskompatibilität gibt. Für mich stellte sich diese Frage sehr stark, als ich anfing, große Pakete mit vielen Unterpaketen zu erstellen - Sie verlieren sich. , . Python, , , __init__. , 90% .
— , API, , - , , ? , , . API . , __init__. - : , , .
,
I_CONTROL_CODE — . , . , , __init__. — . , , , - , .
hasattr ?
hasattr ? , , Python — . hasattr , ().
, , hasattr , , . , hasattr, , . - , Python -, hasattr . , .
getattr « , ». hasattr — getattr,
exception .
50 50 — , , .
,
layer-linter . ? : , , , . , - . - . Ich kann es nur empfehlen.
cohesion . , . Cohesion , . False Positive , — , , .
vulture Python . - , Python , . ohesion.
Radon , :
Halstead ,
Maintainability Index , . , — .
Final type
Final- Python. Typing Extensions, , . , - , — , . , - - , ? Nicht nötig. . - — , , , .
Gratis
, .

, .
, . , . , Python- , .
, Moscow Python Conf++ , . , , Python-.
. . , , , .