Wahrscheinlich muss jeder Dienst, der im Allgemeinen eine Suche durchführt, früher oder später lernen, wie Fehler in Benutzerabfragen behoben werden. Errare humanum est; Benutzer sind ständig versiegelt und irren sich, und die Qualität der Suche leidet unweigerlich darunter - und damit die Benutzererfahrung.
Darüber hinaus hat jeder Dienst seine eigenen Besonderheiten, sein eigenes Vokabular, das in der Lage sein sollte, den Tippfehler zu korrigieren, was die Verwendung vorhandener Lösungen erheblich erschwert. Zum Beispiel mussten solche Anfragen lernen, unseren Vormund zu bearbeiten:
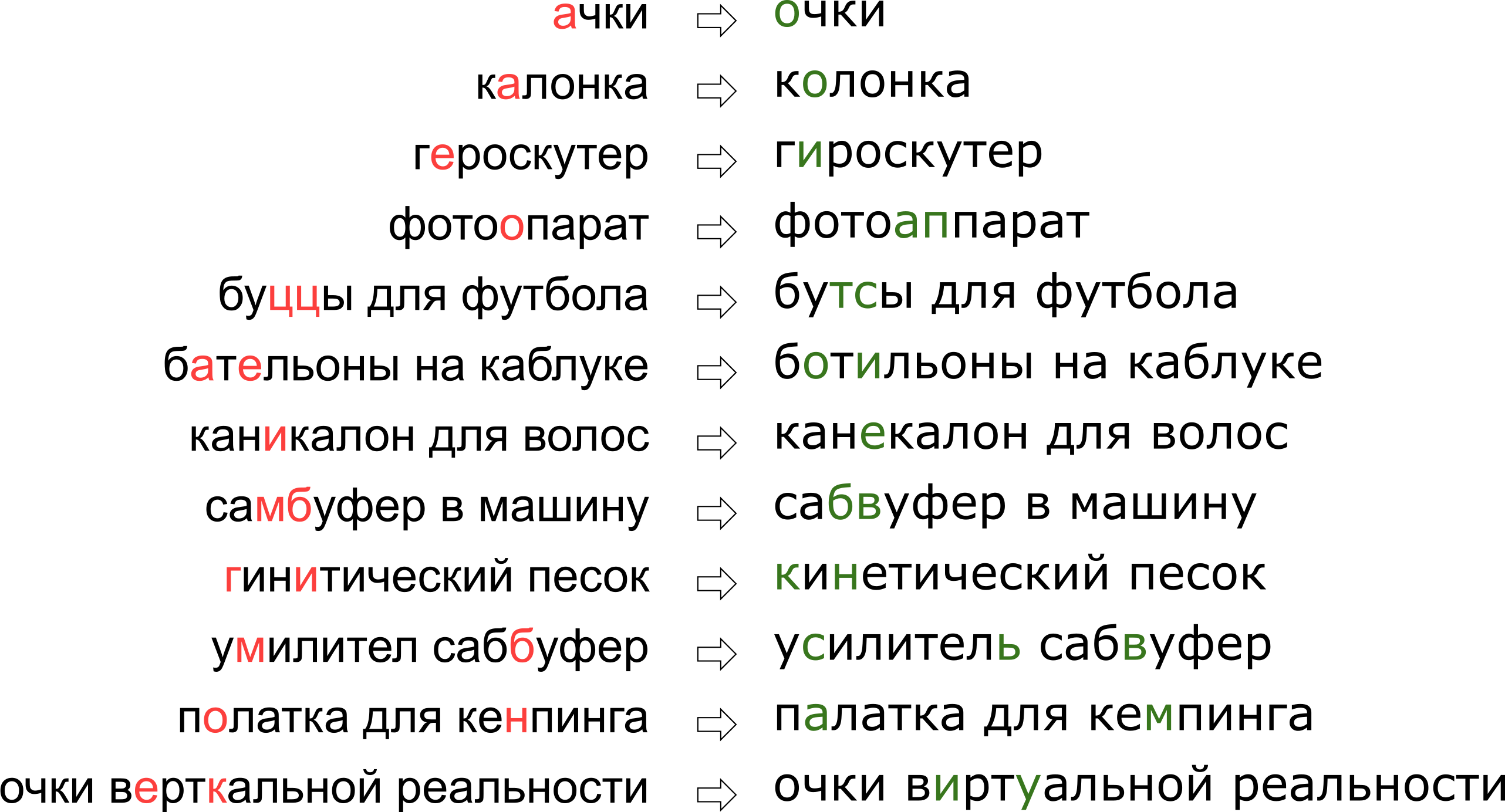 Es mag den Anschein haben, als hätten wir dem Benutzer seinen Traum von der vertikalen Realität verweigert, aber tatsächlich steht der Buchstabe K einfach auf der Tastatur neben dem Buchstaben U.
Es mag den Anschein haben, als hätten wir dem Benutzer seinen Traum von der vertikalen Realität verweigert, aber tatsächlich steht der Buchstabe K einfach auf der Tastatur neben dem Buchstaben U.In diesem Artikel werden wir uns einen der klassischen Ansätze zur Korrektur von Tippfehlern ansehen, vom Erstellen eines Modells bis zum Schreiben von Code in Python und Go. Und als Bonus - ein Video aus meinem Bericht „
Vertically Reality Glasses“: Wir korrigieren Tippfehler in Suchanfragen “auf Highload ++.
Erklärung des Problems
Wir haben also eine versiegelte Anfrage erhalten und müssen diese beheben. Normalerweise ist das Problem mathematisch wie folgt gestellt:
- das Wort gegeben s fehlerhaft an uns übermittelt;
- habe ein Wörterbuch S i g m a die richtigen Worte;
- Für alle Wörter w im Wörterbuch gibt es bedingte Wahrscheinlichkeiten P ( w | s ) was mit dem Wort gemeint war w vorausgesetzt, wir haben das Wort bekommen s ;;
- Sie müssen das Wort w mit maximaler Wahrscheinlichkeit aus dem Wörterbuch finden P ( w | s ) .
Diese Aussage - die elementarste - legt nahe, dass wir jedes Wort einzeln korrigieren, wenn wir eine Anfrage mit mehreren Wörtern erhalten haben. In Wirklichkeit werden wir natürlich die gesamte Phrase als Ganzes korrigieren wollen, da benachbarte Wörter kompatibel sind. Ich werde später im Abschnitt "Korrigieren von Phrasen" darüber sprechen.
Es gibt zwei unklare Momente - wo man das Wörterbuch bekommt und wie man zählt
P ( w | s ) . Die erste Frage wird als einfach angesehen. 1990 [1] wurde das Wörterbuch aus der Datenbank der
Zauberdienstprogramme und elektronisch verfügbaren Wörterbüchern zusammengestellt. Im Jahr 2009 hat Google [4] es einfacher gemacht und einfach die beliebtesten Wörter im Internet verwendet (zusammen mit beliebten Rechtschreibfehlern). Ich habe diesen Ansatz gewählt, um meinen Vormund aufzubauen.
Die zweite Frage ist komplizierter. Wenn auch nur, weil seine Entscheidung normalerweise mit der Anwendung der Bayes-Formel beginnt!
P ( w | s ) = m a t h r m C o n s t c d o t P ( s | w ) c d o t P ( w )
Anstelle der anfänglich unverständlichen Wahrscheinlichkeit müssen wir nun zwei neue, etwas verständlichere bewerten:
P ( s | w ) - die Wahrscheinlichkeit, dass beim Eingeben eines Wortes
w kann versiegelt werden und bekommen
s und
P ( w ) - im Prinzip die Wahrscheinlichkeit, dass der Benutzer das Wort verwendet
w .
Wie zu bewerten
P ( s | w ) ? Offensichtlich ist es wahrscheinlicher, dass der Benutzer A mit O verwechselt als b mit S. Und wenn wir den aus dem gescannten Dokument erkannten Text korrigieren, besteht eine hohe Verwechslungsgefahr zwischen rn und m. Auf die eine oder andere Weise brauchen wir eine Art Modell, das die Fehler und ihre Wahrscheinlichkeiten beschreibt.
Ein solches Modell wird als verrauschtes Kanalmodell bezeichnet (das verrauschte Kanalmodell; in unserem Fall beginnt der verrauschte Kanal irgendwo in der
Mitte des Brock des Benutzers und endet auf der anderen Seite seiner Tastatur) oder kurz gesagt, das Fehlermodell ist das Fehlermodell. Dieses Modell, das in einem separaten Abschnitt weiter unten erläutert wird, ist dafür verantwortlich, sowohl Rechtschreibfehler als auch Tippfehler zu berücksichtigen.
Bewerten Sie die Wahrscheinlichkeit, das Wort zu verwenden -
P ( w ) - Es ist auf verschiedene Arten möglich. Die einfachste Möglichkeit besteht darin, die Häufigkeit zu bestimmen, mit der das Wort in einem großen Textkorpus vorkommt. Für unseren Vormund ist unter Berücksichtigung des Kontextes des Satzes natürlich etwas Komplizierteres erforderlich - ein anderes Modell. Dieses Modell heißt Sprachmodell, ein Sprachmodell.
Fehlermodell
Die ersten Fehlermodelle wurden berücksichtigt
P ( s | w ) Zählen Sie die Wahrscheinlichkeiten elementarer Substitutionen im Trainingssatz: Wie oft anstelle von E haben sie UND geschrieben, wie oft anstelle von T haben sie T geschrieben, anstelle von T - T und so weiter [1]. Das Ergebnis war ein Modell mit einer kleinen Anzahl von Parametern, die einige lokale Effekte lernen konnten (zum Beispiel, dass Menschen E und I oft verwechseln).
In unserer Forschung haben wir uns für ein weiter entwickeltes Fehlermodell entschieden, das im Jahr 2000 von Brill und Moore [2] vorgeschlagen und später wiederverwendet wurde (z. B. von Google-Experten [4]). Stellen Sie sich vor, Benutzer denken nicht in getrennten Zeichen (verwechseln Sie E und I, drücken Sie K anstelle von Y, überspringen Sie ein weiches Zeichen), sondern können beliebige Wortteile in andere ändern - ersetzen Sie beispielsweise TSYA durch TYSYA, Y durch K, SHCHA durch SHCHYA, SS nach C und so weiter. Die Wahrscheinlichkeit, dass der Benutzer versiegelt ist und anstelle von TSYA THY geschrieben hat, bezeichnen wir
P( texttausend rightarrow texttausend) Ist ein Parameter unseres Modells. Wenn für alle möglichen Fragmente
alpha, beta wir können zählen
P( alpha rightarrow beta) , dann die gewünschte Wahrscheinlichkeit
P(s|w) Eine Menge der Wörter s beim Versuch, das Wort w im Brill and Moore-Modell einzugeben, kann wie folgt erhalten werden: Wir teilen die Wörter w und s auf alle möglichen Arten in kürzere Fragmente, so dass die Fragmente in zwei Wörtern dieselbe Nummer haben. Für jede Partition berechnen wir das Produkt der Wahrscheinlichkeiten aller Fragmente w, um sie in die entsprechenden Fragmente s umzuwandeln. Das Maximum für alle diese Partitionen wird als Wert von angenommen
P(s|w) ::
P(s|w)= maxs= alpha1 alpha2 ldots alphak,w= beta1 beta2 ldots betakP( alpha1 rightarrow beta1) cdotP( alpha2 rightarrow beta2) cdot ldots cdotP( alphak rightarrow betak) ,.
Schauen wir uns ein Beispiel für die Partition an, die bei der Berechnung der Wahrscheinlichkeit des Druckens von "Zubehör" anstelle von "Zubehör" auftritt:
\ begin {matrix} \ text {ak} & \ text {cec} & \ text {sou} & \ text {a} & \ text {p} \\ \ downarrow & \ downarrow & \ downarrow & \ downarrow & \ downarrow \\ \ text {a} & \ text {cc} & \ text {e} & \ text {soua} & \ text {p} \ end {matrix}
Wie Sie wahrscheinlich bemerkt haben, ist dies ein Beispiel für eine nicht sehr erfolgreiche Partition: Es ist klar, dass Teile der Wörter nicht so erfolgreich untereinander lagen, wie sie konnten. Wenn die Mengen
P( textak rightarrow texta) und
P( textp rightarrow textp) immer noch nicht so schlimm dann
P( textsou rightarrow texte) und
P( texta rightarrow textsoua) höchstwahrscheinlich werden sie die endgültige „Punktzahl“ dieser Partition völlig traurig machen. Eine erfolgreichere Partition sieht ungefähr so aus:
\ begin {matrix} \ text {ak} & \ text {ce} & \ text {ss} & \ text {y} & \ text {ar} \\ \ downarrow & \ downarrow & \ downarrow & \ downarrow & \ downarrow \\ \ text {ak} & \ text {ce} & \ text {c} & \ text {y} & \ text {ar} \ end {matrix}
Hier passte alles sofort zusammen, und es ist klar, dass die endgültige Wahrscheinlichkeit in erster Linie durch den Wert bestimmt wird
P( textss rightarrow texts) .
Wie zu berechnen P(s|w)
Trotz der Tatsache, dass es Ordnungen möglicher Partitionen für zwei Wörter gibt
O(2|s|+|w|) unter Verwendung eines dynamischen Programmierberechnungsalgorithmus
P(s|w) kann ziemlich schnell gemacht werden - für
O(|s|2|w|2) . Der Algorithmus selbst ähnelt stark
dem Wagner-Fisher-Algorithmus zur Berechnung der
Levenshtein-Entfernung .
Wir werden eine rechteckige Tabelle erstellen, deren Zeilen den Buchstaben des richtigen Wortes und die Spalten der versiegelten entsprechen. Die Zelle am Schnittpunkt von Zeile i und Spalte j am Ende des Algorithmus hat genau die Wahrscheinlichkeit,
s[:j] wenn versucht wird,
w[:i] zu drucken. Um es zu berechnen, reicht es aus, die Werte aller Zellen in den vorherigen Zeilen und Spalten zu berechnen und sie mit den entsprechenden zu multiplizieren
P( alpha rightarrow beta) . Zum Beispiel, wenn wir eine Tabelle gefüllt haben
Um die Zelle in der vierten Zeile und dritten Spalte (grau) zu füllen, müssen Sie das Maximum von nehmen
0.8 cdotP( textcc rightarrow textc) und
0.16 cdotP( textc rightarrow textk) . Gleichzeitig haben wir alle im Bild grün hervorgehobenen Zellen durchlaufen. Berücksichtigen wir auch Änderungen des Formulars
P( alpha rightarrow textleereZeile) und
P( textleereZeile rightarrow beta) , dann müssen Sie über die gelb hervorgehobenen Zellen gehen.
Die Komplexität dieses Algorithmus ist, wie oben erwähnt,
O(|s|2|w|2) : Wir füllen die Tabelle aus
|s| times|w| und um die Zelle (i, j) zu füllen, die Sie benötigen
O(i cdotj) Operationen. Wenn wir uns jedoch auf Fragmente beschränken, die nicht länger als eine begrenzte Länge sind
L (zum Beispiel nicht mehr als zwei Buchstaben, wie in [4]), verringert sich die Komplexität auf
O(|s| cdot|w| cdotL2) . Für die russische Sprache habe ich in meinen Experimenten genommen
L=3 .
So maximieren Sie P(s|w)
Wir haben gelernt zu finden
P(s|w) denn die Polynomzeit ist gut. Aber wir müssen lernen, wie man schnell die besten Wörter im gesamten Wörterbuch findet. Und die besten nicht
P(s|w) , aber
P(w|s) ! Tatsächlich reicht es für uns aus, einige vernünftige Top-Wörter (zum Beispiel die besten 20) für zu bekommen
P(s|w) , die wir dann an das Sprachmodell senden, um die am besten geeigneten Korrekturen auszuwählen (mehr dazu weiter unten).
Um zu lernen, wie man schnell durch das gesamte Wörterbuch geht, stellen wir fest, dass die oben dargestellte Tabelle für zwei Wörter mit gemeinsamen Präfixen viel gemeinsam hat. Wenn wir das Wort „Zubehör“ korrigieren und versuchen, es für die beiden Vokabeln „Zubehör“ und „Zubehör“ auszufüllen, werden wir feststellen, dass sich die ersten neun Zeilen überhaupt nicht unterscheiden! Wenn wir einen Wörterbuchdurchlauf so arrangieren können, dass die nächsten beiden Wörter ausreichend lange gemeinsame Präfixe haben, können wir viele Berechnungen speichern.
Und wir können. Nehmen wir die Vokabeln und lassen sie
versuchen . Wenn wir uns eingehend damit befassen, erhalten wir die gewünschte Eigenschaft: Die meisten Schritte sind Schritte vom Knoten zu seinem Nachkommen, wenn die Tabelle die letzten Zeilen ausfüllen muss.
Dieser Algorithmus ermöglicht es uns mit einigen zusätzlichen Optimierungen, ein Wörterbuch einer typischen europäischen Sprache in 50-100.000 Wörtern innerhalb von hundert Millisekunden zu sortieren [2]. Durch das Zwischenspeichern der Ergebnisse wird der Prozess noch schneller.
Wie komme ich? P( alpha rightarrow beta)
Berechnung
P( alpha rightarrow beta) für alle betrachteten Fragmente - der interessanteste und nicht trivialste Teil der Konstruktion eines Fehlermodells. Von diesen Mengen hängt seine Qualität ab.
Der in [2, 4] verwendete Ansatz ist relativ einfach. Lassen Sie uns viele Paare finden
(si,wi) wo
wi Ist das richtige Wort aus dem Wörterbuch und
si - seine versiegelte Version. (Wie genau man sie findet, ist etwas niedriger.) Nun müssen wir die Wahrscheinlichkeiten bestimmter Tippfehler aus diesen Paaren extrahieren (einige Fragmente durch andere ersetzen).
Für jedes Paar nehmen wir seine Komponenten
w und
s und konstruiere eine Entsprechung zwischen ihren Briefen, um den Levenshtein-Abstand zu minimieren:
\ begin {matrix} \ text {} & \ text {} & \ text {} & \ text {} & \ text {} & \ text {} & \ text {} & \ text {a} & \ text {p} \\ \ text {a} & \ text {k} & \ text {c} & \ text {e} & \ text {c} & \ text {} & \ text {y } & \ text {a} & \ text {p} \ end {matrix}
Jetzt sehen wir sofort die Substitutionen: a → a, e → und c → c, c → eine leere Zeichenfolge und so weiter. Wir sehen auch Ersetzungen von zwei oder mehr Zeichen: ak → ak, ce → si, ec → ist, ss → s, ses → sis, ess → ist und andere und so weiter. Alle diese Ersetzungen müssen gezählt werden und jeweils so oft, wie das Wort s im Korpus vorkommt (wenn wir die Wörter aus dem Korpus genommen haben, was sehr wahrscheinlich ist).
Nach dem Übergeben in allen Paaren
(si,wi) für die Wahrscheinlichkeit
P( alpha rightarrow beta) Die Anzahl der Substitutionen α → β, die in unseren Paaren aufgetreten sind, wird akzeptiert (unter Berücksichtigung des Auftretens der entsprechenden Wörter) geteilt durch die Anzahl der Wiederholungen des Fragments α.
Wie man Paare findet
(si,wi) ? In [4] wurde dieser Ansatz vorgeschlagen. Nehmen Sie die große Menge an benutzergenerierten Inhalten (UGC). Im Fall von Google waren es nur die Texte von Hunderten Millionen Webseiten; Unsere hat Millionen von Benutzersuchen und Bewertungen. Es wird angenommen, dass normalerweise das richtige Wort häufiger im Korpus gefunden wird als jede der fehlerhaften Varianten. Lassen Sie uns also Wörter für jedes Wort in der Nähe von Levenshtein aus dem Korpus finden, die viel weniger beliebt sind (zum Beispiel zehnmal). Nehmen Sie beliebt
w , weniger beliebt - für
s . So bekommen wir eine laute, aber ziemlich große Anzahl von Paaren, auf denen wir trainieren können.
Dieser Paaranpassungsalgorithmus lässt viel Raum für Verbesserungen. In [4] wird nur ein Filter nach Vorkommen (
w zehnmal beliebter als
s ), aber die Autoren dieses Artikels versuchen, Klatsch und Tratsch zu machen, ohne a priori Kenntnisse der Sprache zu verwenden. Wenn wir nur die russische Sprache betrachten, können wir zum Beispiel eine
Reihe von Wörterbüchern russischer Wortformen nehmen und nur Paare mit dem Wort belassen
w im Wörterbuch gefunden (keine gute Idee, da das Wörterbuch höchstwahrscheinlich kein dienstspezifisches Vokabular enthält) oder umgekehrt Paare mit den im Wörterbuch gefundenen Wörtern verwerfen (dh es ist fast garantiert, dass es nicht versiegelt wird).
Um die Qualität der empfangenen Paare zu verbessern, habe ich eine einfache Funktion geschrieben, die bestimmt, ob Benutzer zwei Wörter als Synonyme verwenden. Die Logik ist einfach: Wenn die Wörter w und s oft von denselben Wörtern umgeben sind, handelt es sich wahrscheinlich um Synonyme - was angesichts ihrer Nähe nach Levenshtein bedeutet, dass ein weniger populäres Wort höchstwahrscheinlich eine fehlerhafte Version eines populäreren ist. Für diese Berechnungen habe ich die Statistik des Auftretens von Trigrammen (Phrasen mit drei Wörtern) verwendet, die für das folgende Sprachmodell erstellt wurden.
Sprachmodell
Nun müssen wir für ein gegebenes Wörterbuchwort w berechnen
P(w) - die Wahrscheinlichkeit seiner Verwendung durch den Benutzer. Die einfachste Lösung besteht darin, das Auftreten eines Wortes in einem großen Fall anzunehmen. Im Allgemeinen beginnt wahrscheinlich jedes Sprachmodell damit, eine große Anzahl von Texten zu sammeln und das Auftreten von Wörtern darin zu zählen. Wir sollten uns jedoch nicht darauf beschränken: Tatsächlich können wir bei der Berechnung von P (w) auch die Phrase berücksichtigen, in der wir versuchen, das Wort zu korrigieren, sowie jeden anderen externen Kontext. Die Aufgabe wird zu einer Berechnungsaufgabe
P(w1w2 ldotswk) wo einer von
wi - das Wort, in dem wir den Tippfehler korrigiert haben und für das wir jetzt zählen
P(w) und der Rest
wi - Die Wörter, die das korrigierte Wort in der Benutzeranforderung umgeben.
Um zu lernen, wie man sie berücksichtigt, lohnt es sich, den Korpus noch einmal durchzugehen und Statistiken über n-Gramm und Wortsequenzen zu erstellen. Nehmen Sie normalerweise Sequenzen von begrenzter Länge; Ich habe mich auf Trigramme beschränkt, um den Index nicht aufzublähen, aber alles hängt von Ihrer geistigen Stärke ab (und der Größe des Falls - in einem kleinen Fall sind sogar die Statistiken zu den Trigrammen zu laut).
Das traditionelle n-Gramm-Sprachmodell sieht so aus. Für den Satz
w1w2 ldotswk seine Wahrscheinlichkeit wird durch die Formel berechnet
P(w1w2 ldotswk)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2)P(wk|w1w2wk−1) ,,
wo
P(w1) - direkt die Häufigkeit des Wortes, und
P(w3|w1w2) - Wortwahrscheinlichkeit
w3 vorausgesetzt, dass vor ihm gehen
w1w2 - nichts als das Verhältnis der Trigrammfrequenz
w1w2w3 zu Bigram Frequenz
w1w2 . (Beachten Sie, dass diese Formel einfach das Ergebnis der wiederholten Verwendung der Bayes-Formel ist.)
Mit anderen Worten, wenn wir berechnen wollen
P( textMutterSeifenrahmen) , bezeichnet die Frequenz eines beliebigen n-Gramms in
f Wir bekommen die Formel
P( textMutterSeifenrahmen)=f( TextMutter) cdot fracf( TextMutterSeife)f( TextMutter) cdot fracf( textMutterseifenrahmen)f( textMutter s e i f e n r a h m e n ) =f(text M u t t e r s e i f e n r ein h m e n ),.
Ist es logisch? Ist logisch. Schwierigkeiten beginnen jedoch, wenn Phrasen länger werden. Was ist, wenn ein Benutzer eine Suchabfrage mit zehn Wörtern und beeindruckenden Details eingibt? Wir möchten keine Statistiken für alle 10 Gramm führen - dies ist teuer und die Daten sind wahrscheinlich verrauscht und nicht indikativ. Wir wollen mit n-Gramm begrenzter Länge auskommen - zum Beispiel mit der oben bereits vorgeschlagenen Länge 3.
Hier bietet sich die obige Formel an. Nehmen wir an, dass die Wahrscheinlichkeit, dass ein Wort am Ende einer Phrase erscheint, nur durch einige Wörter unmittelbar davor erheblich beeinflusst wird, d. H.
P(wk|w1w2 ldotswk−1) ungefährP(wk|wk−L+1 ldotswk−1) ,.
Putten
L=3 Für eine längere Phrase erhalten wir die Formel
P( textcarlhatClaraKorallengestohlen) approxf( textcarl) cdot fracf( textcarl)f( textcarl) cdot fracf( textcarlvonclara)f( textcarlvon) cdot fracf( textvonclaragestohlen)f( textvonclara) cdot fracf( textclairestolecoral)f( textclairestole) ,.Bitte beachten Sie: Die Phrase besteht aus fünf Wörtern, aber in der Formel erscheinen nicht mehr als drei n-Gramm. Genau das haben wir gesucht.
Es war noch ein dünner Moment übrig. Was ist, wenn der Benutzer eine sehr seltsame Phrase und die entsprechenden n-Gramm in unsere Statistik eingegeben hat und überhaupt nicht? Es wäre leicht für unbekannte n-Gramm zu setzen
f=0 wenn es nicht notwendig wäre, durch diesen Wert zu dividieren. Hier kommt die Glättung (Glättung) zu Hilfe, die auf verschiedene Arten erfolgen kann; Eine ausführliche Erörterung schwerwiegender Anti-Aliasing-Ansätze wie der
Kneser-Ney-Glättung würde jedoch den Rahmen dieses Artikels sprengen.
So korrigieren Sie Phrasen
Wir diskutieren den letzten subtilen Punkt, bevor wir zur Implementierung übergehen. Die Aussage des oben beschriebenen Problems implizierte, dass es ein Wort gibt und es behoben werden muss. Dann haben wir klargestellt, dass dieses eine Wort unter einigen anderen Wörtern in der Mitte einer Phrase stehen kann und dass sie auch berücksichtigt werden müssen, um die beste Korrektur auszuwählen. In Wirklichkeit senden uns Benutzer einfach Phrasen, ohne anzugeben, welches Wort geschrieben wird. oft müssen ein paar Wörter oder sogar alle korrigiert werden.
Es kann viele Ansätze geben. Beispielsweise können Sie nur den linken Kontext des Wortes in der Phrase berücksichtigen. Wenn wir dann den Wörtern von links nach rechts folgen und sie nach Bedarf korrigieren, erhalten wir eine neue Phrase von einiger Qualität. Die Qualität wird schlecht sein, wenn sich beispielsweise herausstellt, dass das erste Wort mehreren populären Wörtern ähnelt und wir die falsche Option wählen. Die gesamte verbleibende Phrase (möglicherweise anfangs völlig fehlerfrei) wird von uns auf das falsche erste Wort eingestellt und wir können den Text erhalten, der für das Original völlig irrelevant ist.
Sie können die Wörter einzeln betrachten und einen bestimmten Klassifikator anwenden, um zu verstehen, ob das angegebene Wort versiegelt ist oder nicht, wie in [4] vorgeschlagen. Der Klassifikator wird auf die Wahrscheinlichkeiten trainiert, die wir bereits zählen können, und auf eine Reihe anderer Merkmale. Wenn der Klassifikator sagt, was behoben werden muss, korrigieren wir dies angesichts des vorhandenen Kontexts. Wenn mehrere Wörter falsch geschrieben sind, müssen Sie eine Entscheidung über das erste Wort treffen, basierend auf dem Kontext mit den Fehlern, was zu Qualitätsproblemen führen kann.
Bei der Implementierung unseres Vormunds haben wir diesen Ansatz verwendet. Lassen Sie uns für jedes Wort
si In unserer Phrase finden wir unter Verwendung des Fehlermodells die Top-N-Wörterbuchwörter, die gemeint sein könnten, und verketten sie auf jede mögliche Weise und für jede von ihnen zu Phrasen
NK resultierende Sätze wo
K - die Anzahl der Wörter in der ursprünglichen Phrase, berechnen Sie ehrlich den Wert
P(s1|w1) cdotP(sK|wK) cdotP(sK|wK) cdotP(w1w2 ldotswK) lambda ,.
Hier
si - vom Benutzer eingegebene Wörter,
wi - für sie ausgewählte Korrekturen (die wir jetzt sortieren) und
lambda - Koeffizient bestimmt durch die Vergleichsqualität des Fehlermodells und des Sprachmodells (großer Koeffizient - wir vertrauen dem Sprachmodell mehr, kleiner Koeffizient - wir vertrauen dem Fehlermodell mehr), vorgeschlagen in [4]. Insgesamt multiplizieren wir für jede Phrase die Wahrscheinlichkeiten einzelner zu korrigierender Wörter in den entsprechenden Wörterbuchvarianten und multiplizieren dies auch mit der Wahrscheinlichkeit der gesamten Phrase in unserer Sprache. Das Ergebnis des Algorithmus ist eine Phrase aus Wörterbuchwörtern, die diesen Wert maximiert.
Also hör auf was? Brute Force
NK Sätze?
Glücklicherweise ist es aufgrund der Tatsache, dass wir die Länge von n-Gramm begrenzt haben, möglich, ein Maximum in allen Phrasen viel schneller zu finden. Denken Sie daran: oben haben wir die Formel für vereinfacht
P(w1w2 ldotswK) so dass es nur von Frequenzen von n-Gramm mit einer Länge von nicht mehr als drei abhing:
P(w1w2 ldotswK)=P(w1) cdotP(w2|w1) cdotP(w3|w1w2) cdot ldots cdotP(wK|wK−2wK−1) ,.
Wenn wir diesen Wert mit multiplizieren
P(si|wi) und versuchen, durch zu maximieren
wK Wir werden sehen, dass es ausreicht, alle Arten von Problemen zu lösen
wK−2 und
wK−1 und lösen Sie das Problem für sie - das heißt für Phrasen
w1w2 ldotswK−2wK−1 . Insgesamt wird das Problem durch dynamische Programmierung in gelöst
O(KN3) .
Implementierung
Den Koffer zusammensetzen und die n-Gramm zählen
Ich werde sofort eine Reservierung vornehmen: Es standen mir nicht so viele Daten zur Verfügung, um ein komplexes MapReduce zu starten. Deshalb habe ich alle Texte von Bewertungen, Kommentaren und Suchanfragen in russischer Sprache (die Beschreibungen der Waren sind leider in englischer Sprache und die Verwendung der Ergebnisse der automatischen Übersetzung eher verschlechtert als die Ergebnisse verbessert) aus unserem Service in einer Textdatei zusammengefasst und den Server so eingestellt, dass die Nacht zählt Trigramme mit einem einfachen Python-Skript.
Als Wörterbuch habe ich die häufigsten Wörter in der Häufigkeit genommen, so dass ich ungefähr hunderttausend Wörter bekomme. Zu lange Wörter (mehr als 20 Zeichen) und zu kurze Wörter (weniger als drei Zeichen, mit Ausnahme von fest codierten bekannten russischen Wörtern) wurden ausgeschlossen. Separat verschont die Wörter auf der Regelmäßigkeit
r"^[a-z0-9]{2}$" - so dass Versionen von iPhones und anderen interessanten Bezeichnern der Länge 2 überlebten.
Beim Zählen von Bigrams und Trigrammen in einer Phrase kann ein Nicht-Wörterbuchwort vorkommen. In diesem Fall habe ich dieses Wort weggeworfen und die ganze Phrase in zwei Teilen (vor und nach diesem Wort) geschlagen, mit denen ich separat gearbeitet habe. Also, für den Satz "
Weißt du was" abyrvalg "ist? Dies ist ... DER KOPFMANN, Kollege "wird die Trigramme" Weißt du "," Weißt du was "," Weißt du was "und" Dies ist der
Hauptfischerkollege "berücksichtigen (es sei denn, das Wort" Häuptling "fällt natürlich in das Wörterbuch ...).
Wir trainieren das Fehlermodell
Weiterhin habe ich die gesamte Datenverarbeitung in Jupyter durchgeführt. Statistiken über n-Gramm werden aus JSON geladen, die Nachbearbeitung wird durchgeführt, um Wörter nach Levenshtein schnell nahe beieinander zu finden, und für Paare in der Schleife wird eine (ziemlich umständliche) Funktion aufgerufen, die Wörter anordnet und kurze Änderungen der Form ss → c (unter dem Spoiler) extrahiert.
Python-Code def generate_modifications(intended_word, misspelled_word, max_l=2):
Die Berechnung der Änderungen selbst sieht elementar aus, kann jedoch lange dauern.
Fehlermodell anwenden
Dieser Teil ist als Mikrodienst auf Go implementiert, der über gRPC mit dem Haupt-Backend verbunden ist. Der von Brill und Moore selbst beschriebene Algorithmus [2] mit geringfügigen Optimierungen wurde implementiert. Infolgedessen funktioniert es für mich ungefähr doppelt so langsam, wie die Autoren behaupteten; Ich nehme nicht an zu beurteilen, ob es in Go oder in mir ist. Aber im Verlauf der Profilerstellung habe ich etwas Neues über Go gelernt.
- Verwenden Sie
math.Max nicht, um das math.Max zu zählen. Dies ist ungefähr dreimal langsamer als if a > b { b = a } ! Schauen Sie sich einfach die Implementierung dieser Funktion an :
Verwenden Sie math.Max nicht, es sei denn, Sie benötigen plötzlich +0, um unbedingt größer als -0 zu math.Max .
- Verwenden Sie keine Hash-Tabelle, wenn Sie ein Array verwenden können. Dies ist natürlich ein ziemlich offensichtlicher Rat. Ich musste Unicode-Zeichen zu Beginn des Programms in Zahlen umnummerieren, um sie als Indizes im Nachkommen-Array des Trie-Knotens zu verwenden (eine solche Suche war eine sehr häufige Operation).
- Rückrufe in Go sind nicht billig. Während des Refactorings während der Codeüberprüfung haben einige meiner Versuche, eine Entkopplung vorzunehmen, das Programm erheblich verlangsamt, obwohl sich der Algorithmus formal nicht geändert hat. Seitdem bin ich der Meinung, dass der Go-Optimierungs-Compiler Raum zum Wachsen hat.
Wenden Sie ein Sprachmodell an
Hier wurde ohne Überraschungen der im obigen Abschnitt beschriebene dynamische Programmieralgorithmus implementiert. Diese Komponente hatte am wenigsten Arbeit - der langsamste Teil ist die Anwendung des Fehlermodells.
Daher wurde zwischen diesen beiden Schichten das Caching des Fehlermodells zu Redis zusätzlich verschraubt.Ergebnisse
Basierend auf den Ergebnissen dieser Arbeit (die ungefähr einen Monat dauerte) haben wir einen A / B-Testschutz für unsere Benutzer durchgeführt. Anstelle von 10% der leeren Suchergebnisse unter allen Suchanfragen, die wir vor der Einführung des Vormunds hatten, gab es 5%; Grundsätzlich handelt es sich bei den verbleibenden Anfragen um Waren, die wir einfach nicht auf der Plattform haben. Die Anzahl der Sitzungen ohne zweite Suchabfrage hat ebenfalls zugenommen (und mehrere weitere Metriken dieser Art in Bezug auf UX). Die mit Geld verbundenen Kennzahlen haben sich jedoch nicht wesentlich geändert - dies war unerwartet und führte uns zu einer gründlichen Analyse und Gegenprüfung anderer Kennzahlen.Fazit
Stephen Hawking wurde einmal gesagt, dass jede Formel, die er in das Buch aufnahm, die Anzahl der Leser halbieren würde. Nun, in diesem Artikel gibt es ungefähr fünfzig von ihnen - ich gratuliere Ihnen, einer von ungefähr10−10 Leser, die diesen Ort erreichen!Bonus
Referenzen
[1] MD Kernighan, KW Church, WA Gale. Ein Rechtschreibkorrekturprogramm basierend auf einem verrauschten Kanalmodell . Vorträge der 13. Konferenz über Computerlinguistik - Band 2, 1990.[2] E.Brill, RC Moore. Ein verbessertes Fehlermodell für die Rechtschreibkorrektur bei verrauschten Kanälen . Bericht über die 38. Jahrestagung der Vereinigung für Computerlinguistik, 2000.[3] T. Brants, AC Popat, P. Xu, FJ Och, J. Dean. Große Sprachmodelle in der maschinellen Übersetzung . Vorträge der Konferenz 2007 über empirische Methoden in der Verarbeitung natürlicher Sprache.[4] C. Whitelaw, B. Hutchinson, GY Chung, G. Ellis. Verwenden des Webs zur sprachunabhängigen Rechtschreibprüfung und Autokorrektur. Tagungsband der Konferenz 2009 über empirische Methoden in der Verarbeitung natürlicher Sprache: Band 2.