Guten Abend!
In unserem Kurs
„C ++ Developer“ bieten
wir Ihnen eine kleine und interessante Studie über parallele Algorithmen.
Lass uns gehen.
Mit dem Aufkommen paralleler Algorithmen in C ++ 17 können Sie Ihren Computercode einfach aktualisieren und von der parallelen Ausführung profitieren. In diesem Artikel möchte ich den STL-Algorithmus betrachten, der natürlich die Idee des unabhängigen Rechnens offenbart. Können wir mit einem 10-Kern-Prozessor eine 10-fache Beschleunigung erwarten? Oder vielleicht mehr? Oder weniger? Reden wir darüber.
Einführung in parallele Algorithmen
C ++ 17 bietet eine Ausführungsrichtlinieneinstellung für die meisten Algorithmen:
- sequenced_policy - Typ der Ausführungsrichtlinie, der als eindeutiger Typ verwendet wird, um die Parallelität des parallelen Algorithmus und die Anforderung zu beseitigen, dass eine Parallelisierung der Ausführung des parallelen Algorithmus nicht möglich ist: Das entsprechende globale Objekt lautet
std::execution::seq ; - parallel_policy - Typ der Ausführungsrichtlinie, die als eindeutiger Typ verwendet wird, um die Überlastung des parallelen Algorithmus zu beseitigen und anzuzeigen, dass eine Parallelisierung der Ausführung des parallelen Algorithmus möglich ist: Das entsprechende globale Objekt ist
std::execution::par ; - parallel_unsequenced_policy - Eine Art von Ausführungsrichtlinie, die als eindeutiger Typ verwendet wird, um die Überlastung des parallelen Algorithmus zu beseitigen und anzuzeigen, dass Parallelisierung und Vektorisierung der Ausführung paralleler Algorithmen möglich sind: Das entsprechende globale Objekt ist
std::execution::par_unseq ;
Kurz:
- Verwenden Sie
std::execution::seq für die sequentielle Ausführung des Algorithmus. - Verwenden Sie
std::execution::par , um den Algorithmus parallel auszuführen (normalerweise unter Verwendung einer Thread-Pool-Implementierung (Thread-Pool)). - Verwenden Sie
std::execution::par_unseq für die parallele Ausführung des Algorithmus mit der Möglichkeit, Vektorbefehle (z. B. SSE, AVX) zu verwenden.
Rufen Sie als schnelles Beispiel
std::sort parallel auf:
std::sort(std::execution::par, myVec.begin(), myVec.end());
Beachten Sie, wie einfach es ist, dem Algorithmus einen parallelen Ausführungsparameter hinzuzufügen! Aber wird eine signifikante Leistungsverbesserung erreicht? Wird es die Geschwindigkeit erhöhen? Oder gibt es Verlangsamungen?
Parallele std::transformIn diesem Artikel möchte ich auf den
std::transform Algorithmus achten, der möglicherweise die Grundlage für andere parallele Methoden sein könnte (zusammen mit
std::transform_reduce ,
for_each ,
scan ,
sort ...).
Unser Testcode wird gemäß der folgenden Vorlage erstellt:
std::transform(execution_policy,
Angenommen, die
ElementOperation Funktion verfügt über keine Synchronisationsmethoden. In diesem Fall kann der Code parallel ausgeführt oder sogar vektorisiert werden. Jede Elementberechnung ist unabhängig, die Reihenfolge spielt keine Rolle, sodass eine Implementierung mehrere Threads (möglicherweise in einem Thread-Pool) für die unabhängige Verarbeitung von Elementen erzeugen kann.
Ich möchte mit folgenden Dingen experimentieren:
- die Größe des Vektorfeldes ist groß oder klein;
- eine einfache Konvertierung, die die meiste Zeit auf den Speicher zugreift;
- mehr arithmetische (ALU) Operationen;
- ALU in einem realistischeren Szenario.
Wie Sie sehen, möchte ich nicht nur die Anzahl der Elemente testen, die für die Verwendung des parallelen Algorithmus „gut“ sind, sondern auch die ALU-Operationen, die den Prozessor belegen.
Andere Algorithmen wie Sortieren, Akkumulieren (in Form von std :: reduzieren) bieten ebenfalls eine parallele Ausführung, erfordern jedoch auch mehr Arbeit, um die Ergebnisse zu berechnen. Daher werden wir sie als Kandidaten für einen anderen Artikel betrachten.
Benchmark Note
Für meine Tests verwende ich Visual Studio 2017, 15.8 - da dies derzeit (November 2018) die einzige Implementierung in der beliebten Compiler- / STL-Implementierung ist (GCC unterwegs!). Außerdem habe ich mich nur auf
execution::par , da
execution::par_unseq in MSVC nicht verfügbar ist (es funktioniert ähnlich wie
execution::par ).
Es gibt zwei Computer:
- i7 8700 - PC, Windows 10, i7 8700 - 3,2 GHz, 6 Kerne / 12 Threads (Hyperthreading);
- i7 4720 - Laptop, Windows 10, i7 4720, 2,6 GHz, 4 Kerne / 8 Threads (Hyperthreading).
Der Code ist in x64 kompiliert. Release more, die automatische Vektorisierung ist standardmäßig aktiviert. Außerdem habe ich einen erweiterten Befehlssatz (SSE2) und OpenMP (2.0) hinzugefügt.
Der Code befindet sich in meinem Github:
github / fenbf / ParSTLTests / TransformTests / TransformTests.cppFür OpenMP (2.0) verwende ich Parallelität nur für Schleifen:
#pragma omp parallel for for (int i = 0; ...)
Ich führe den Code 5 Mal aus und schaue mir die minimalen Ergebnisse an.
Warnung : Die Ergebnisse geben nur grobe Beobachtungen wieder. Überprüfen Sie Ihr System / Ihre Konfiguration, bevor Sie es in der Produktion verwenden. Ihre Anforderungen und Ihre Umgebung können von meinen abweichen.Weitere Informationen zur MSVC-Implementierung finden Sie in
diesem Beitrag . Und
hier ist Bill O'Neills jüngster
Bericht mit der CppCon 2018 (Bill hat Parallel STL in MSVC implementiert).
Beginnen wir mit einfachen Beispielen!
Einfache KonvertierungBetrachten Sie den Fall, wenn Sie eine sehr einfache Operation auf einen Eingabevektor anwenden. Es kann das Kopieren oder Multiplizieren von Elementen sein.
Zum Beispiel:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return v * 2.0; } );
Mein Computer hat 6 oder 4 Kerne ... kann ich eine 4..6x schnellere sequentielle Ausführung erwarten? Hier sind meine Ergebnisse (Zeit in Millisekunden):
| Bedienung | Vektorgröße | i7 4720 (4 Kerne) | i7 8700 (6 Kerne) |
|---|
| Ausführung :: seq | 10k | 0,002763 | 0,001924 |
| Ausführung :: Par | 10k | 0,009869 | 0,008983 |
| openmp parallel für | 10k | 0,003158 | 0,002246 |
| Ausführung :: seq | 100k | 0,051318 | 0,028872 |
| Ausführung :: Par | 100k | 0,043028 | 0,025664 |
| openmp parallel für | 100k | 0,022501 | 0,009624 |
| Ausführung :: seq | 1000k | 1,69508 | 0,52419 |
| Ausführung :: Par | 1000k | 1,65561 | 0,359619 |
| openmp parallel für | 1000k | 1,50678 | 0,344863 |
Auf einer schnelleren Maschine können wir sehen, dass ungefähr 1 Million Elemente erforderlich sind, um eine Leistungsverbesserung festzustellen. Auf meinem Laptop hingegen waren alle parallelen Implementierungen langsamer.
Daher ist es schwierig, bei Verwendung solcher Transformationen eine signifikante Leistungsverbesserung festzustellen, selbst wenn die Anzahl der Elemente zunimmt.
Warum so?
Da die Operationen elementar sind, können die Prozessorkerne sie mit nur wenigen Zyklen fast sofort aufrufen. Prozessorkerne verbringen jedoch mehr Zeit damit, auf den Hauptspeicher zu warten. In diesem Fall werden sie also größtenteils warten und keine Berechnungen durchführen.
Das Lesen und Schreiben einer Variablen im Speicher dauert etwa 2-3 Zyklen, wenn sie zwischengespeichert ist, und mehrere hundert Zyklen, wenn sie nicht zwischengespeichert ist.https://www.agner.org/optimize/optimizing_cpp.pdfSie können grob feststellen, dass Sie bei parallelem Computing keine Leistungsverbesserungen erwarten sollten, wenn Ihr Algorithmus speicherabhängig ist.
Weitere BerechnungenDa die Speicherbandbreite von entscheidender Bedeutung ist und die Geschwindigkeit der Dinge beeinflussen kann, erhöhen wir den Rechenaufwand, der sich auf jedes Element auswirkt.
Die Idee ist, dass es besser ist, Prozessorzyklen zu verwenden, als Zeit damit zu verschwenden, auf Speicher zu warten.
Zunächst verwende ich trigonometrische Funktionen, zum Beispiel
sqrt(sin*cos) (dies sind bedingte Berechnungen in nicht optimaler Form, nur um den Prozessor zu belegen).
Wir verwenden
sqrt ,
sin und
cos , die ~ 20 pro
sqrt und ~ 100 pro trigonometrischer Funktion annehmen können. Dieser Rechenaufwand kann die Speicherzugriffsverzögerung abdecken.
Weitere Informationen zu Teamverzögerungen finden Sie im ausgezeichneten
Perf Guide von Agner Fogh .
Hier ist der Benchmark-Code:
std::transform(std::execution::par, vec.begin(), vec.end(), out.begin(), [](double v) { return std::sqrt(std::sin(v)*std::cos(v)); } );
Und was nun? Können wir mit einer Leistungsverbesserung gegenüber dem vorherigen Versuch rechnen?
Hier sind einige Ergebnisse (Zeit in Millisekunden):
| Bedienung | Vektorgröße | i7 4720 (4 Kerne) | i7 8700 (6 Kerne) |
|---|
| Ausführung :: seq | 10k | 0,105005 | 0,070577 |
| Ausführung :: Par | 10k | 0,055661 | 0,03176 |
| openmp parallel für | 10k | 0,096321 | 0,024702 |
| Ausführung :: seq | 100k | 1,08755 | 0,707048 |
| Ausführung :: Par | 100k | 0,259354 | 0,17195 |
| openmp parallel für | 100k | 0,898465 | 0,189915 |
| Ausführung :: seq | 1000k | 10.5159 | 7.16254 |
| Ausführung :: Par | 1000k | 2.44472 | 1.10099 |
| openmp parallel für | 1000k | 4.78681 | 1,89017 |
Endlich sehen wir schöne Zahlen :)
Für 1000 Elemente (hier nicht gezeigt) waren die parallelen und sequentiellen Berechnungszeiten ähnlich, daher sehen wir für mehr als 1000 Elemente eine Verbesserung in der parallelen Version.
Bei 100.000 Elementen ist das Ergebnis auf einem schnelleren Computer fast neunmal besser als bei der seriellen Version (ähnlich wie bei der OpenMP-Version).
In der größten Version von einer Million Elementen ist das Ergebnis fünf- oder achtmal schneller.
Für solche Berechnungen habe ich eine "lineare" Beschleunigung erreicht, abhängig von der Anzahl der Prozessorkerne. Welches war zu erwarten.
Fresnel- und dreidimensionale VektorenIm obigen Abschnitt habe ich "erfundene" Berechnungen verwendet, aber was ist mit echtem Code?
Lösen wir die Fresnel-Gleichungen, die die Reflexion und Krümmung von Licht von einer glatten, flachen Oberfläche beschreiben. Dies ist eine beliebte Methode zur Erzeugung realistischer Beleuchtung in 3D-Spielen.
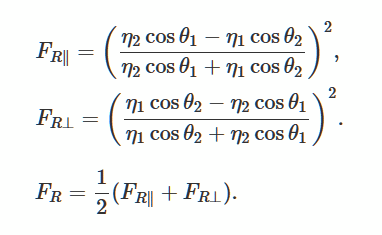
 Foto aus Wikimedia
Foto aus WikimediaAls gutes Beispiel fand ich
diese Beschreibung und Implementierung .
Informationen zur Verwendung der GLM-BibliothekAnstatt meine eigene Implementierung zu erstellen, habe ich
die glm-Bibliothek verwendet . Ich benutze es oft in meinen OpenGl-Projekten.
Der Zugriff auf die Bibliothek ist über den
Conan Package Manager einfach, daher werde ich sie auch verwenden.
Link zum Paket.
Conan-Datei:
[requires] glm/0.9.9.1@g-truc/stable [generators] visual_studio
und die Befehlszeile zum Installieren der Bibliothek (sie generiert Requisitendateien, die ich in einem Visual Studio-Projekt verwenden kann):
conan install . -s build_type=Release -if build_release_x64 -s arch=x86_64
Die Bibliothek besteht aus einem Header, sodass Sie sie bei Bedarf einfach manuell herunterladen können.
Tatsächlicher Code und BenchmarkIch habe den Code für glm von
Scratchapixel.com angepasst :
Der Code verwendet mehrere mathematische Anweisungen, Skalarprodukt, Multiplikation, Division, sodass der Prozessor etwas zu tun hat. Anstelle des Doppelvektors verwenden wir einen Vektor mit 4 Elementen, um den verwendeten Speicher zu erhöhen.
Benchmark:
std::transform(std::execution::par, vec.begin(), vec.end(), vecNormals.begin(),
Und hier sind die Ergebnisse (Zeit in Millisekunden):
| Bedienung | Vektorgröße | i7 4720 (4 Kerne) | i7 8700 (6 Kerne) |
|---|
| Ausführung :: seq | 1k | 0,032764 | 0,016361 |
| Ausführung :: Par | 1k | 0,031186 | 0,028551 |
| openmp parallel für | 1k | 0,005526 | 0,007699 |
| Ausführung :: seq | 10k | 0,246722 | 0,169383 |
| Ausführung :: Par | 10k | 0,090794 | 0,067048 |
| openmp parallel für | 10k | 0,049739 | 0,029835 |
| Ausführung :: seq | 100k | 2,49722 | 1,69768 |
| Ausführung :: Par | 100k | 0,530157 | 0,283268 |
| openmp parallel für | 100k | 0,495024 | 0,291609 |
| Ausführung :: seq | 1000k | 25.08.28 | 16.9457 |
| Ausführung :: Par | 1000k | 5.15235 | 2,33768 |
| openmp parallel für | 1000k | 5.11801 | 2,95908 |
Beim „echten“ Computing sehen wir, dass parallele Algorithmen eine gute Leistung bieten. Für solche Vorgänge auf meinen beiden Windows-Computern erreichte ich eine Beschleunigung mit einer nahezu linearen Abhängigkeit von der Anzahl der Kerne.
Bei allen Tests habe ich auch Ergebnisse von OpenMP und zwei Implementierungen gezeigt: MSVC und OpenMP funktionieren ähnlich.
FazitIn diesem Artikel habe ich drei Fälle der Verwendung von parallelem Rechnen und parallelen Algorithmen untersucht. Das Ersetzen von Standardalgorithmen durch die Version std :: execute :: par mag sehr verlockend erscheinen, aber das lohnt sich nicht immer! Jede Operation, die Sie innerhalb des Algorithmus verwenden, funktioniert möglicherweise anders und hängt stärker vom Prozessor oder Speicher ab. Betrachten Sie daher jede Änderung separat.
Dinge, an die man sich erinnern sollte:
- Die parallele Ausführung ist normalerweise mehr als sequentiell, da sich die Bibliothek auf die parallele Ausführung vorbereiten muss.
- Nicht nur die Anzahl der Elemente ist wichtig, sondern auch die Anzahl der Befehle, mit denen der Prozessor beschäftigt ist.
- Es ist besser, Aufgaben zu übernehmen, die unabhängig voneinander und von anderen gemeinsam genutzten Ressourcen sind.
- Parallele Algorithmen bieten eine einfache Möglichkeit, die Arbeit in separate Threads aufzuteilen.
- Wenn Ihre Vorgänge speicherabhängig sind, sollten Sie keine Leistungsverbesserungen erwarten. In einigen Fällen sind die Algorithmen möglicherweise langsamer.
- Um eine anständige Leistungsverbesserung zu erzielen, messen Sie immer die Zeitpunkte jedes Problems. In einigen Fällen können die Ergebnisse völlig unterschiedlich sein.
Besonderer Dank geht an JFT für die Hilfe bei diesem Artikel!
Achten Sie auch auf meine anderen Quellen zu parallelen Algorithmen:
Schauen Sie sich einen weiteren Artikel zu parallelen Algorithmen an:
So steigern Sie die Leistung mit parallelen Intel STL- und C ++ 17-ParallelalgorithmenDAS ENDE
Wir warten auf Kommentare und Fragen, die Sie hier oder bei unserem
Lehrer an
der offenen Tür hinterlassen können.