Der optimierende AOT-Compiler ist normalerweise folgendermaßen aufgebaut:
- Frontend-Konvertierung von Quellcode in Zwischendarstellung
- Maschinenunabhängige Optimierungspipeline (IR): Eine Folge von Durchläufen, die IR neu schreiben, um ineffiziente Abschnitte und Strukturen zu eliminieren, die nicht direkt in Maschinencode konvertiert werden können. Manchmal wird dieser Teil als mittleres Ende bezeichnet.
- Maschinenabhängiges Backend zum Generieren von Baugruppencode oder Maschinencode.

Bei einigen Compilern bleibt das IR-Format während des gesamten Optimierungsprozesses unverändert, bei anderen ändert sich das Format oder die Semantik. In LLVM sind Format und Semantik festgelegt. Daher können Durchläufe in beliebiger Reihenfolge ausgeführt werden, ohne dass das Risiko einer fehlerhaften Kompilierung oder eines Absturzes des Compilers besteht.
Die Reihenfolge der Optimierungsdurchläufe wurde von den Compiler-Entwicklern entwickelt, mit dem Ziel, die Arbeit in einer akzeptablen Zeit abzuschließen. Es ändert sich von Zeit zu Zeit, und natürlich gibt es verschiedene Durchgänge, die auf verschiedenen Optimierungsstufen ausgeführt werden können. Eines der langfristigen Themen in der Computerforschung ist die Verwendung von maschinellem Lernen oder anderen Methoden, um die beste Optimierungspipeline für den allgemeinen Gebrauch und für bestimmte Anwendungen zu finden, für die die Standardpipeline nicht sehr geeignet ist.
Die Prinzipien beim Entwerfen der Passagen sind Minimalismus und Orthogonalität: Jeder Pass sollte eine Sache gut machen und ihre Funktionalität sollte sich nicht überschneiden. In der Praxis sind manchmal Kompromisse möglich. In der Praxis können zwei Durchgänge, die Arbeit für einander erzeugen, zu einem größeren Durchgang kombiniert werden. Einige Funktionen auf IR-Ebene, wie z. B. das Falten konstanter Operatoren, sind so nützlich, dass es keinen Sinn macht, sie in einen separaten Durchgang zu setzen. LLVM minimiert standardmäßig konstante Operationen, wenn eine Anweisung erstellt wird.
In diesem Beitrag werden wir sehen, wie einige LLVM-Optimierungsdurchläufe funktionieren. Ich meine, Sie lesen
diesen Teil darüber, wie Clang eine Funktion kompiliert, oder Sie verstehen mehr oder weniger, wie LLVM IR funktioniert. Das Verständnis des SSA-Formulars (Static Single Assignment) ist besonders hilfreich:
Wikipedia gibt Ihnen eine Einführung, und
dieses Buch enthält mehr Informationen, als Sie gerne wissen würden. Lesen Sie auch die
LLVM-Sprachreferenz und eine
Liste der Optimierungsdurchläufe .
Mal sehen, wie Clang / LLVM 6.0.1 diesen C ++ - Code optimiert:
bool is_sorted(int *a, int n) { for (int i = 0; i < n - 1; i++) if (a[i] > a[i + 1]) return false; return true; }
Gleichzeitig erinnern wir uns, dass die Optimierungspipeline sehr belebt ist und wir viele lustige Momente verpassen werden, wie zum Beispiel:
Inlining ist eine einfache, aber sehr wichtige Optimierung, die in diesem Beispiel nicht auftritt, weil Wir betrachten nur eine Funktion. Fast alle Optimierungen sind spezifisch für C ++, jedoch nicht für C. Automatische Vektorisierung, die ein vorzeitiges Verlassen der Schleife verhindert
Im folgenden Text überspringe ich alle Durchgänge, die keine Änderungen am Code vornehmen. Wir werden auch nicht in das Backend schauen, das auch viel Arbeit leistet. Aber auch die restlichen Passagen sind viel! (Entschuldigen Sie die Bilder, aber dies scheint der beste Weg zu sein, um Formatierungsschwierigkeiten zu vermeiden.)
Hier ist die von Clang erstellte
IR-Datei (ich habe das von Clang eingefügte Attribut "optnone" manuell gelöscht) und die Befehlszeile, mit der die Auswirkungen jedes Optimierungsdurchlaufs angezeigt werden:
opt -O2 -print-before-all -print-after-all is_sorted2.ll
Der erste Durchgang ist die
CFG-Vereinfachung (Kontrollflussdiagramm). Da Clang keine Optimierung durchführt, enthält die von ihm erzeugte IR einfache Optimierungsoptionen:

Hier bewegt sich die Basiseinheit 26 einfach zu Block 27. Solche Blöcke können gelöscht werden, indem Verweise durch den Zielblock auf sie umgeleitet werden. LLVM nummeriert Blöcke automatisch neu. Die vollständige Liste der von SimplifyCFG erstellten Conversions befindet sich oben im Gang.
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
, . :
, , . phi- , . , . invoke nounwind- call "if (x) if (y)" "if (x&y)"
Die meisten Möglichkeiten zur CFG-Optimierung ergeben sich aus der Arbeit anderer LLVM-Pässe. Zum Beispiel kann das Löschen der Eliminierung von totem Code und das Verschieben von Schleifeninvarianten leicht zu leeren Basisblöcken führen.
Die nächste Passage,
SROA (skalarer Ersatz von Aggregaten), ist eine der am häufigsten verwendeten. Sein Name führt zu Verwirrung, da SROA nur eine seiner Funktionen ist. Der Durchlauf überprüft jeden Zuordnungsbefehl (Speicherzuordnung auf dem Funktionsstapel) und versucht, ihn in SSA-Register umzuwandeln. Ein Allokationsbefehl (dh
eine Variable auf dem Stapel von ca. Transl ..) wird in viele Register umgewandelt, wenn er mehrmals statisch zugewiesen wird, und wenn Allokation eine Klasse oder Struktur ist, wird er in Komponenten unterteilt (dies wird als "Skalar" bezeichnet). Ersatz “im Namen der Passage). Eine einfache Version von SROA würde sich Stapelvariablen ergeben, für die die Operation zum Nehmen einer Adresse verwendet wird, aber die LLVM-Version interagiert mit einem Alias-Analysealgorithmus und handelt auf intelligente Weise (obwohl dies im folgenden Beispiel nicht erforderlich ist).

Nach SROA verschwinden die Allokationsanweisungen (und die entsprechenden Lade- und Speicheranweisungen), und der Code wird sauberer und eignet sich besser für nachfolgende Optimierungen (natürlich kann SROA im allgemeinen Fall nicht alle Allokationen löschen, dies geschieht nur, wenn die Zeigeranalyse dies kann Aliase vollständig loswerden). Dabei fügt SROA Phi-Anweisungen in den Code ein. Die Phi-Anweisungen bilden den Kern der SSA-Darstellung, und das Fehlen von Phi im von Clang generierten Code zeigt, dass Clang eine triviale Version von SSA generiert, bei der die Basisblöcke über den Speicher und nicht über SSA-Register verbunden sind.
Was folgt, ist "
Early Common Subexpression Elimination ", CSE (Early Removal of Common Subexpressions). CSE versucht, Fälle übermäßiger Unterausdrücke zu beseitigen, die sowohl in von Menschen geschriebenem Code als auch in teilweise optimiertem Code auftreten können. "Early CSE" ist eine schnelle und einfache Version von CSE, die triviale redundante Berechnungen identifiziert.

Hier machen% 10 und% 17 dasselbe, dh der Code kann neu geschrieben werden, sodass ein Wert verwendet und der zweite gelöscht wird. Dies gibt einen Einblick in die Vorteile von SSA: Wenn jedes Register nur einmal zugewiesen wird, gibt es nicht mehrere Versionen eines einzelnen Registers. Somit können redundante Berechnungen unter Verwendung syntaktischer Äquivalenz erkannt werden, ohne eine eingehende Analyse des Programms zu verwenden (dies ist nicht der Fall für Speicherorte, die außerhalb der SSA-Welt existieren).
Als nächstes werden mehrere Durchgänge gestartet, die in unserem Fall keine Auswirkung haben, und dann wird der "
Global Variable Optimizer " gestartet, der wie folgt beschrieben wird:
, . , , , , ..Diese Passage nimmt folgende Änderungen vor:
Er fügte ein Funktionsattribut hinzu: Metadaten, die von einem Teil des Compilers verwendet werden, um Informationen darüber zu speichern, was für einen anderen Teil des Compilers nützlich sein könnte. Über den Zweck dieses Attributs können Sie
hier lesen.
Im Gegensatz zu anderen Optimierungen, die wir in Betracht gezogen haben, ist der Optimierer globaler Variablen interprocedural und bezieht sich ausschließlich auf das LLVM-Modul. Ein Modul entspricht (mehr oder weniger) einer Kompilierungseinheit in C und C ++. Im Gegensatz zur interproceduralen Optimierung sieht intraprocedural jeweils nur eine Funktion.
Die nächste Passage kombiniert Anweisungen und heißt „
Anweisungskombinierer “, InstCombine. Dies ist eine große und vielfältige Sammlung von
Gucklochoptimierungen , die (normalerweise) einige Anweisungen, kombiniert mit gemeinsamen Daten, in einer effizienteren Form umschreiben. InstCombine ändert den Kontrollfluss einer Funktion nicht. Im obigen Beispiel hat er nicht viel geändert:
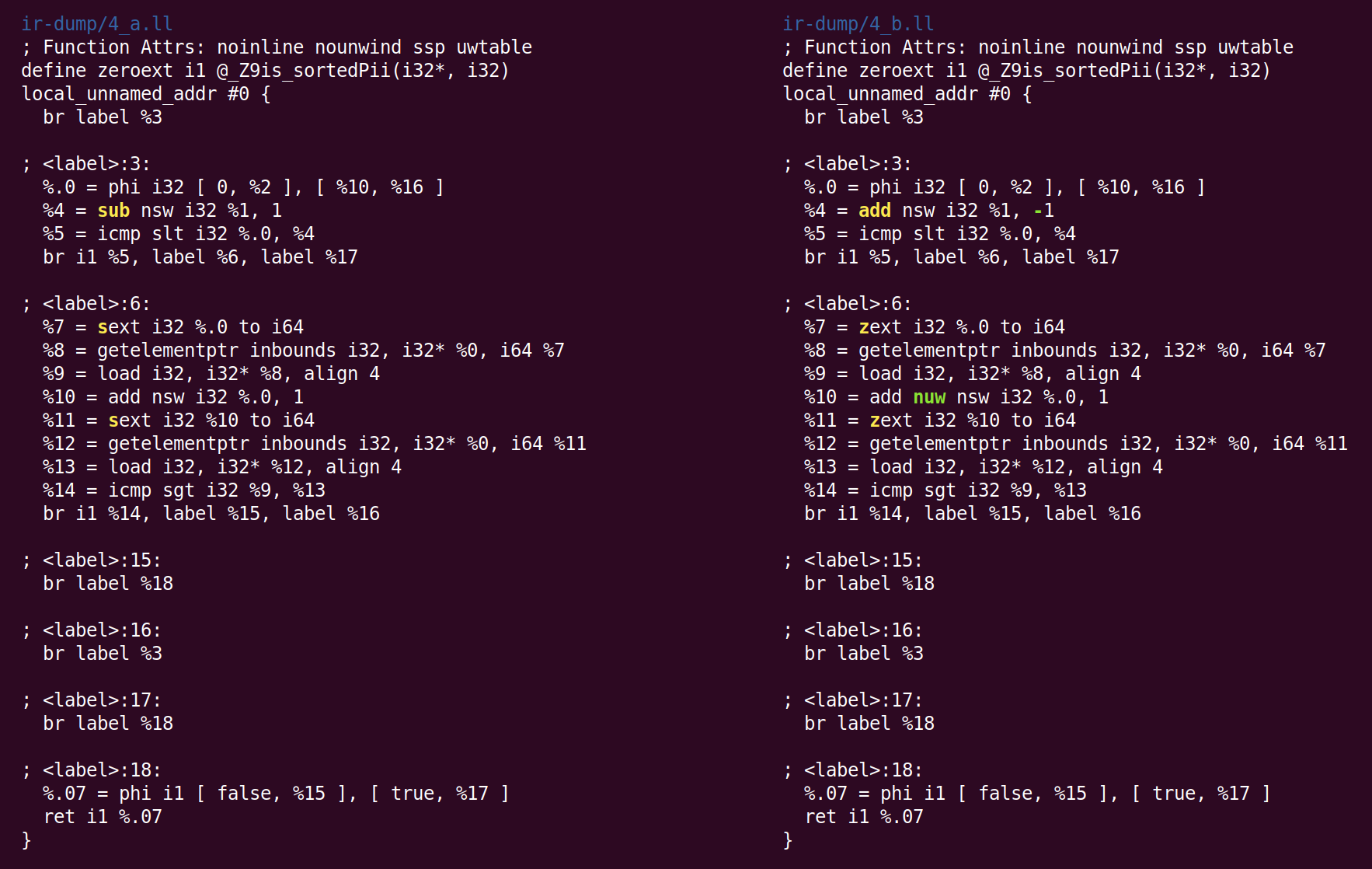
Anstatt 1 von% 1 zu subtrahieren, addieren wir hier -1, um% 4 zu berechnen. Dies ist keine Optimierung, sondern eine Kanonisierung. Wenn es viele Möglichkeiten gibt, die Berechnung durchzuführen, versucht LLVM, sie in die kanonische (oft zufällig ausgewählte) Form zu bringen, die nachfolgende Durchläufe und Backends erwarten. Die zweite Änderung, die InstCombine vorgenommen hat, ist die kanonische Form von zwei vorzeichenbehafteten Erweiterungsoperationen (der Sext-Anweisung), die% 7 und% 11 berechnen, die in eine Null-Erweiterung (zext) konvertiert wurden. Diese Konvertierung ist sicher, wenn der Compiler nachweisen kann, dass der Sext-Operand nicht negativ ist. In diesem Fall liegt dies daran, dass sich die Schleifenvariable von 0 auf n ändert (wenn n negativ ist, wird die Schleife überhaupt nicht ausgeführt). Die letzte Änderung war das Hinzufügen des Flags "nuw" (kein vorzeichenloser Wrap) zu der Anweisung, die% 10 berechnet. Wir können sehen, dass es sicher ist, dass (1) die Schleifenvariable immer zunimmt und (2) wenn die Variable bei Null beginnt und zunimmt, sie undefiniert wird, wenn das Vorzeichen an der Kreuzung INT_MAX geändert wird, bevor sie einen vorzeichenlosen Überlauf erreicht. folgenden UINT_MAX. Dieses Flag kann für nachfolgende Optimierungen verwendet werden.
Als nächstes startet SimplifyCFG ein zweites Mal und entfernt zwei leere Basisblöcke:
Anschließend kommentiert der Pass "Funktionsattribute ableiten" die Funktion:

"Norecurse" bedeutet, dass die Funktion nicht in rekursiven Aufrufen enthalten ist. "Readonly" bedeutet, dass die Funktion den globalen Status nicht ändert. Das Parameterattribut "nocapture" bedeutet, dass der Parameter nach dem Beenden der Funktion nirgendwo gespeichert wird, und "readonly" bedeutet, dass der Speicher von der Funktion nicht geändert wird. Sie sehen eine
Liste von Funktionsattributen und
Parameterattributen .
Dann verschiebt der Durchlauf "
Schleifen drehen " den Code, um die Bedingungen für nachfolgende Optimierungen zu verbessern:

Obwohl der Unterschied einschüchternd aussieht, sind die Änderungen tatsächlich gering. Wir können besser lesbar sehen, was passiert ist, wenn wir LLVM bitten, vor und nach den Rotationszyklen einen Kontrollübertragungsgraphen zu zeichnen. Hier ist ihre Ansicht vor (links) und nach (rechts):
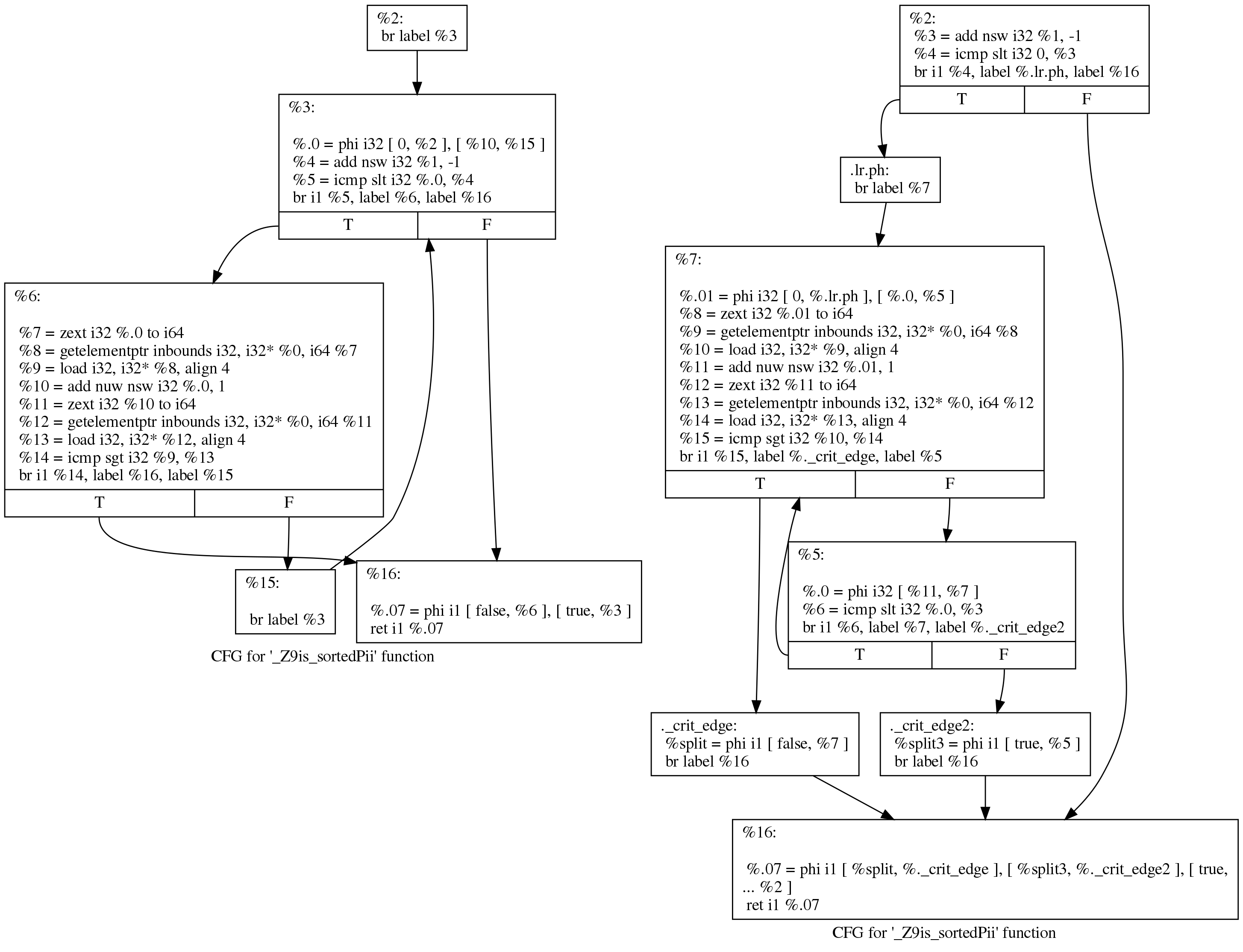
Der ursprüngliche Code folgt weiterhin der von Clang generierten Schleifenstruktur:
initializer goto COND COND: if (condition) goto BODY else goto EXIT BODY: body modifier goto COND EXIT:
Nach dem Lauf sieht die Schleife folgendermaßen aus:
initializer if (condition) goto BODY else goto EXIT BODY: body modifier if (condition) goto BODY else goto EXIT EXIT:
(Von Johannes Durfert vorgeschlagene Korrekturen sind unten aufgeführt - danke!)
Der Zweck des Schleifendrehungsdurchlaufs besteht darin, einen Zweig zu entfernen, was weitere Optimierungen ermöglicht. Ich habe im Internet keine bessere Beschreibung dieser Konvertierung gefunden.
Der CFG-Vereinfachungsdurchlauf minimiert zwei Basisblöcke, die nur entartete Phi-Anweisungen (mit einem Eingang) enthalten:

Der Befehlskombinierer-Durchgang verwandelt "% 4 = 0 s <(% 1 - 1)" in "% 4 =% 1 s> 1" (wobei s <und s> Operationen zum Vergleichen von vorzeichenbehafteten Operanden sind) Eine nützliche Transformation, die die Länge von Abhängigkeitsketten verringert und auch tote (unerreichbare) Anweisungen erstellen kann (siehe den
Patch , der dies tut). Dieser Durchgang entfernt auch die trivialen Phi-Anweisungen, die durch den Schleifenrotationsdurchlauf hinzugefügt wurden.

Das Folgende ist die Passage „
Kanonisieren natürlicher Schleifen “, die in ihrem eigenen Quellcode wie folgt beschrieben wird:
, .
(Loop pre-header) , , . ,, LICM.
, , ( ) ( ). , , "store-sinking", LICM.
, (backedge).
Indirectbr . , . , , .
, simplifycfg , , , .
, , CFG, .
Hier sehen wir, dass der Ausgabeblock eingefügt wurde:
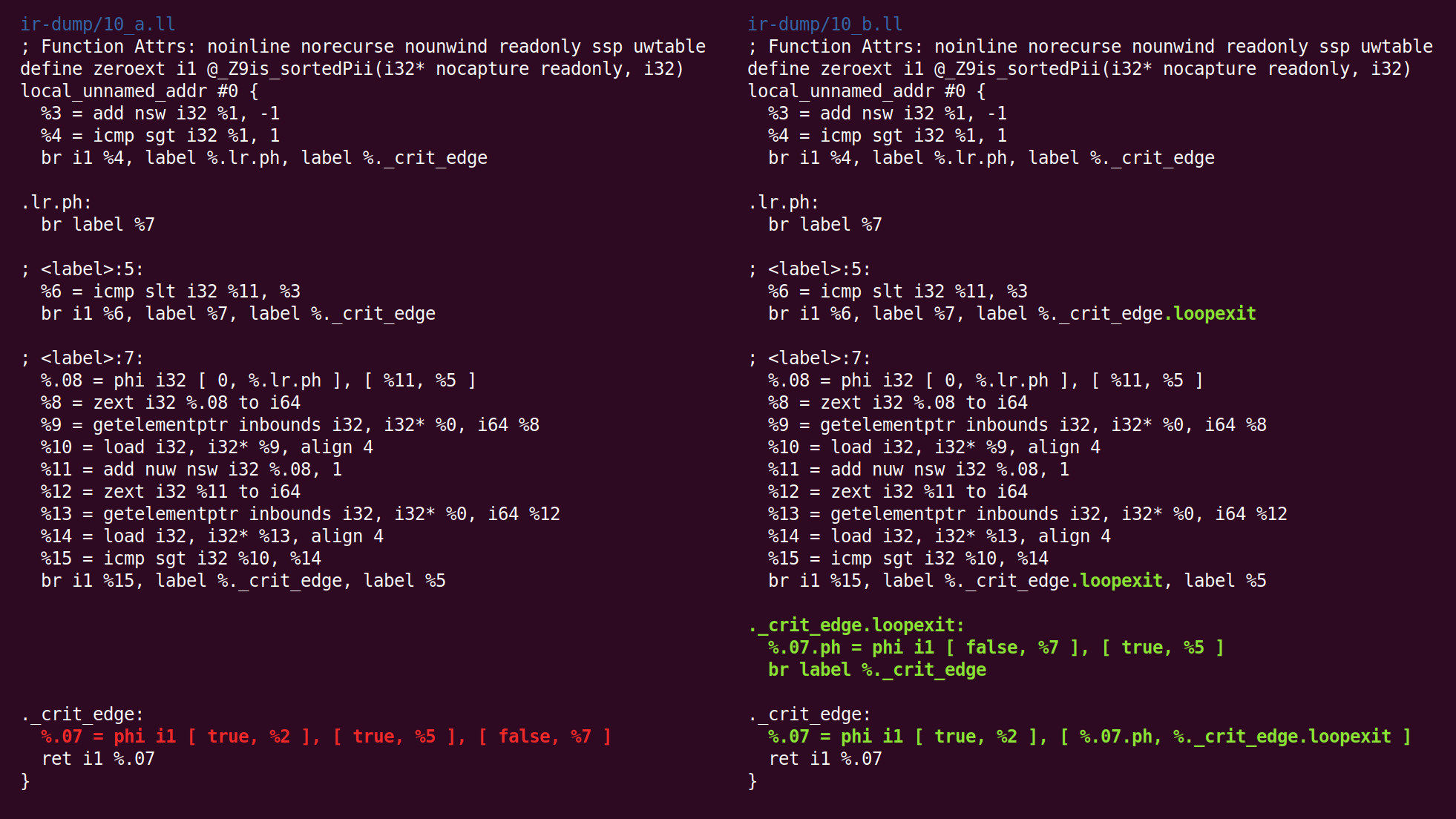
Dann folgt die "
Vereinfachung der Schleifenvariablen ":
( , ), , .
, :
, . , 'for (i = 7; i*i < 1000; ++i)' 'for (i = 0; i != 25; ++i)'.
indvar , . , "".
Der Effekt dieses Durchlaufs besteht darin, die 32-Bit-Schleifenvariable in 64-Bit zu ändern:
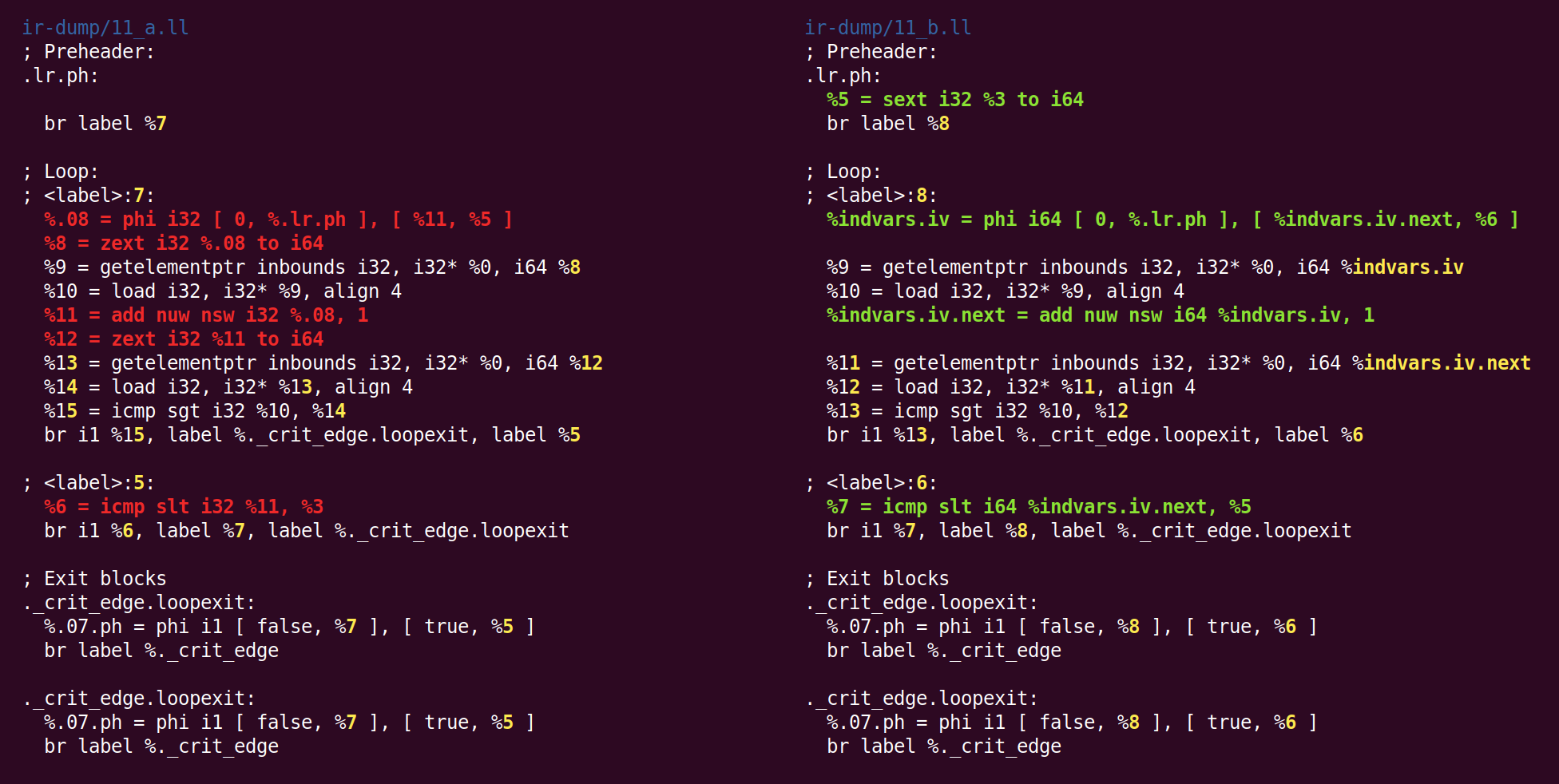
Ich weiß nicht, warum zext - zuvor von sext in die kanonische Form gegossen, wieder zu sext zurückgekehrt.
Jetzt führt der Durchgang "
Globale Wertnummerierung " eine sehr intelligente Optimierung durch. Einer der Gründe für das Schreiben dieses Beitrags ist der Wunsch, ihn zu zeigen. Kannst du sie hier sehen?

Hast du gesehen Ja, zwei Ladeanweisungen in der Schleife links, die einem [i] und einem [i + 1] entsprechen. Hier stellte die GVN fest, dass ein [i] zum Laden nicht benötigt wurde, da ein [i + 1] von einer Iteration der Schleife wie ein [i] zur nächsten übertragen werden konnte. Dieser einfache Trick reduziert die Anzahl der von der Funktion durchgeführten Speicherlesevorgänge um die Hälfte. Sowohl LLVM als auch
GCC haben erst kürzlich gelernt, diese Transformation durchzuführen.
Sie könnten sich fragen, ob dieser Trick funktioniert, wenn wir ein [i] mit einem [i + 2] vergleichen. Es stellt sich heraus, dass nein, aber GCC kann für solche Fälle
bis zu vier Register zuweisen.
Dann beginnt der Durchgang "
Bit-Tracking Dead Code Elimination ":
"Bit-Tracking Dead Code Elimination". (, "" "" ..) "" . , "" .Hier stellt sich jedoch heraus, dass solche Tricks nicht benötigt werden, da der einzige tote Code der Befehl GEP (get element pointer) ist und er trivial tot ist (der GVN-Durchgang hat den Ladebefehl gelöscht, der die von diesem Befehl berechnete Adresse verwendet hat):
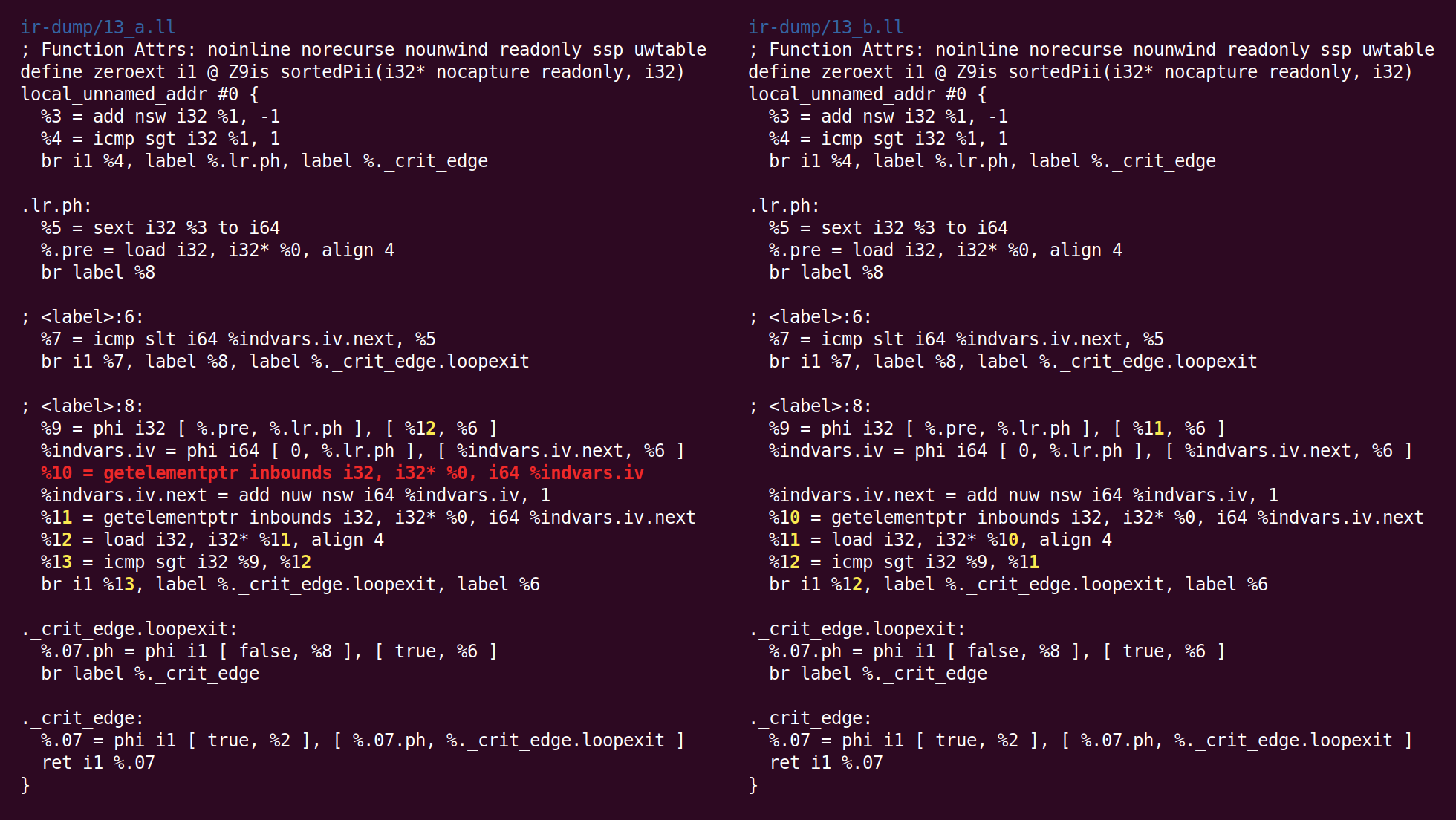
Jetzt hat der Algorithmus zum Kombinieren von Anweisungen add in eine andere Basiseinheit eingefügt. Die Logik, mit der diese Transformation in InstCombine platziert wurde, ist mir nicht klar, vielleicht gab es keinen offensichtlichen Ort, an dem sie platziert werden konnte:

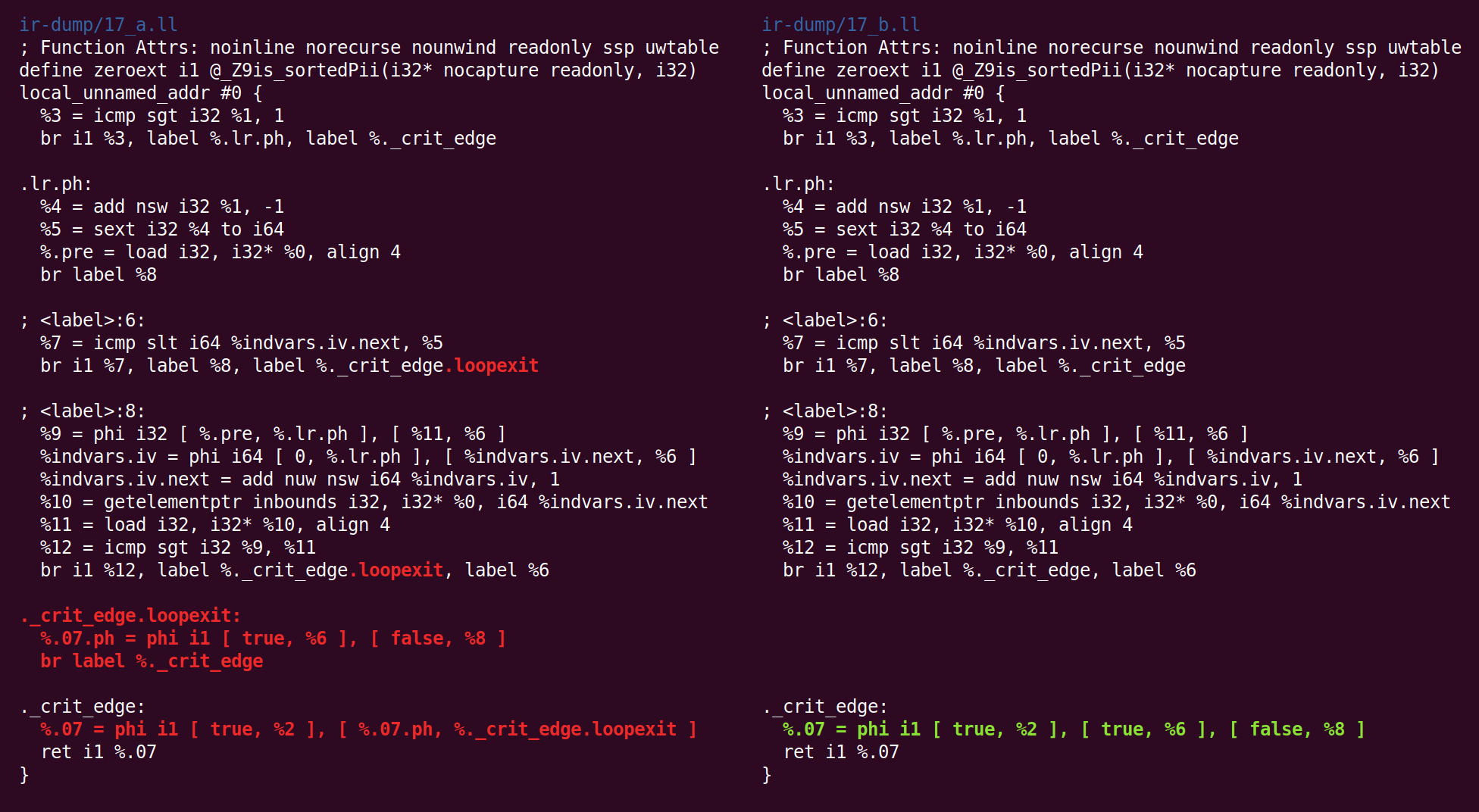
Jetzt passiert etwas Seltsameres: Der "
Jump Threading " -Pass hat gelöscht, was der "Canonicalize Natural Loops" -Pass zuvor getan hat:

Dann werfen wir wieder auf die kanonische Form:
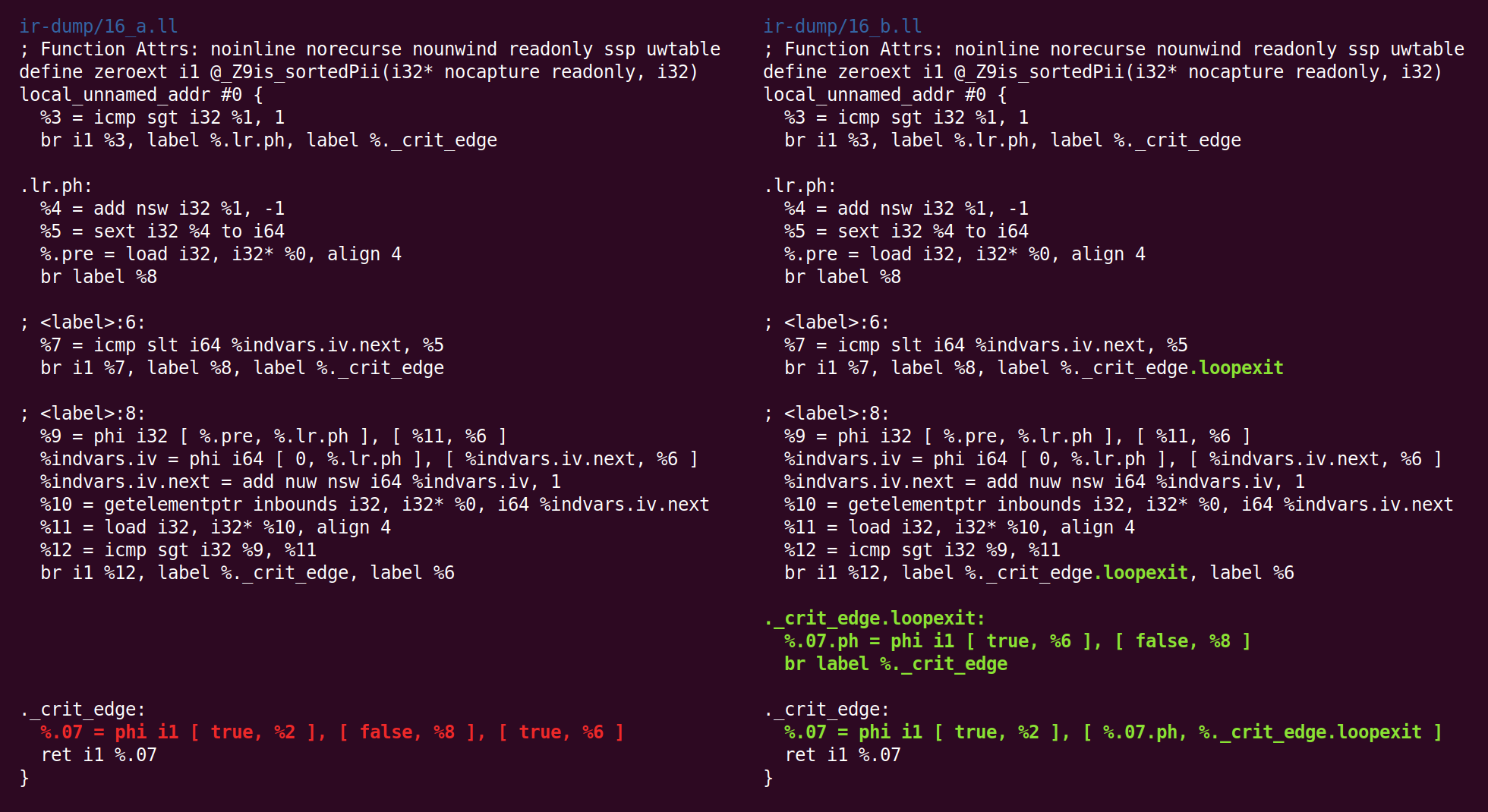
Und die CFG-Vereinfachung transformiert es anders:
Und zurück:
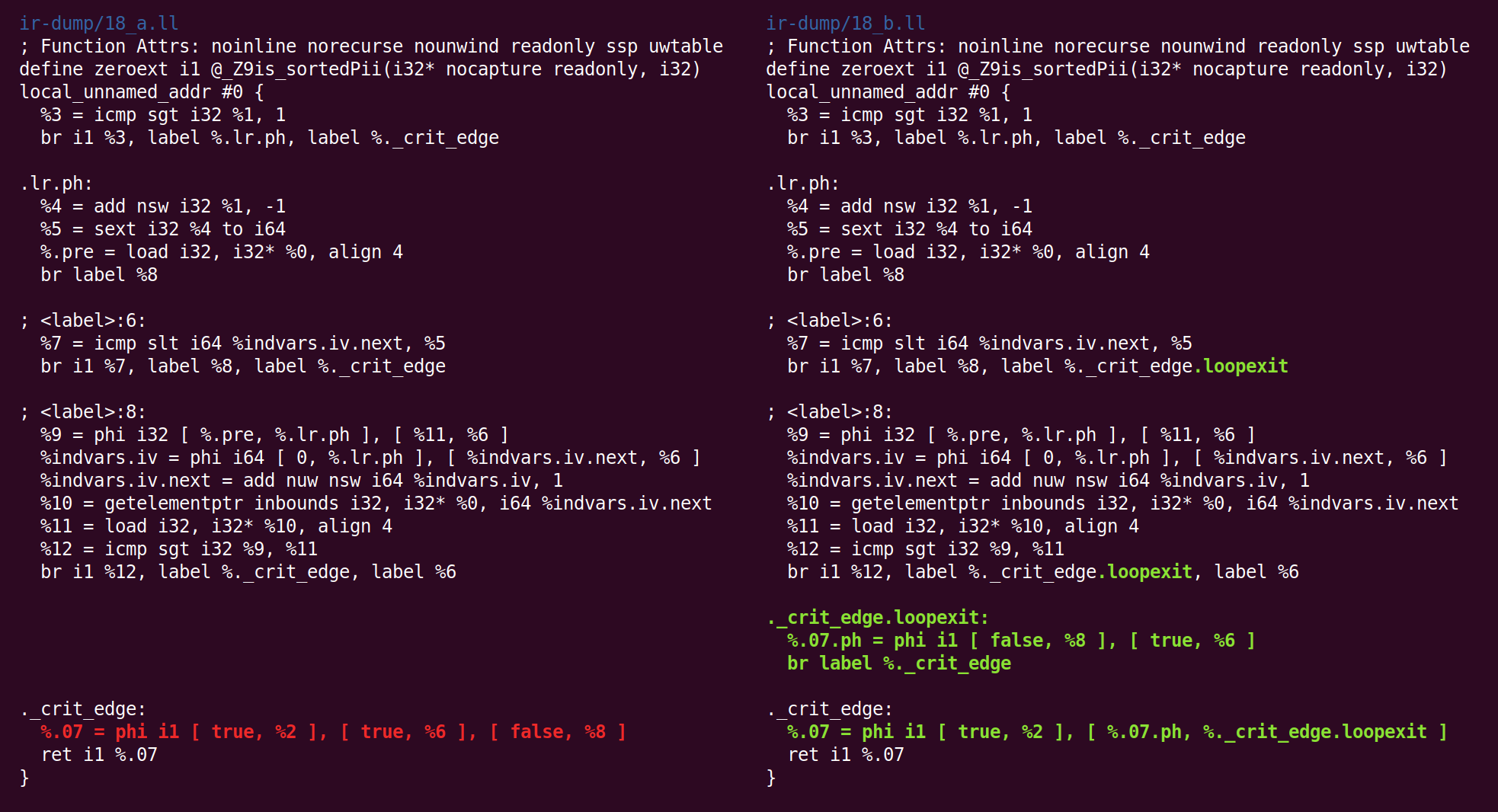
Und da nochmal:

Und zurück:
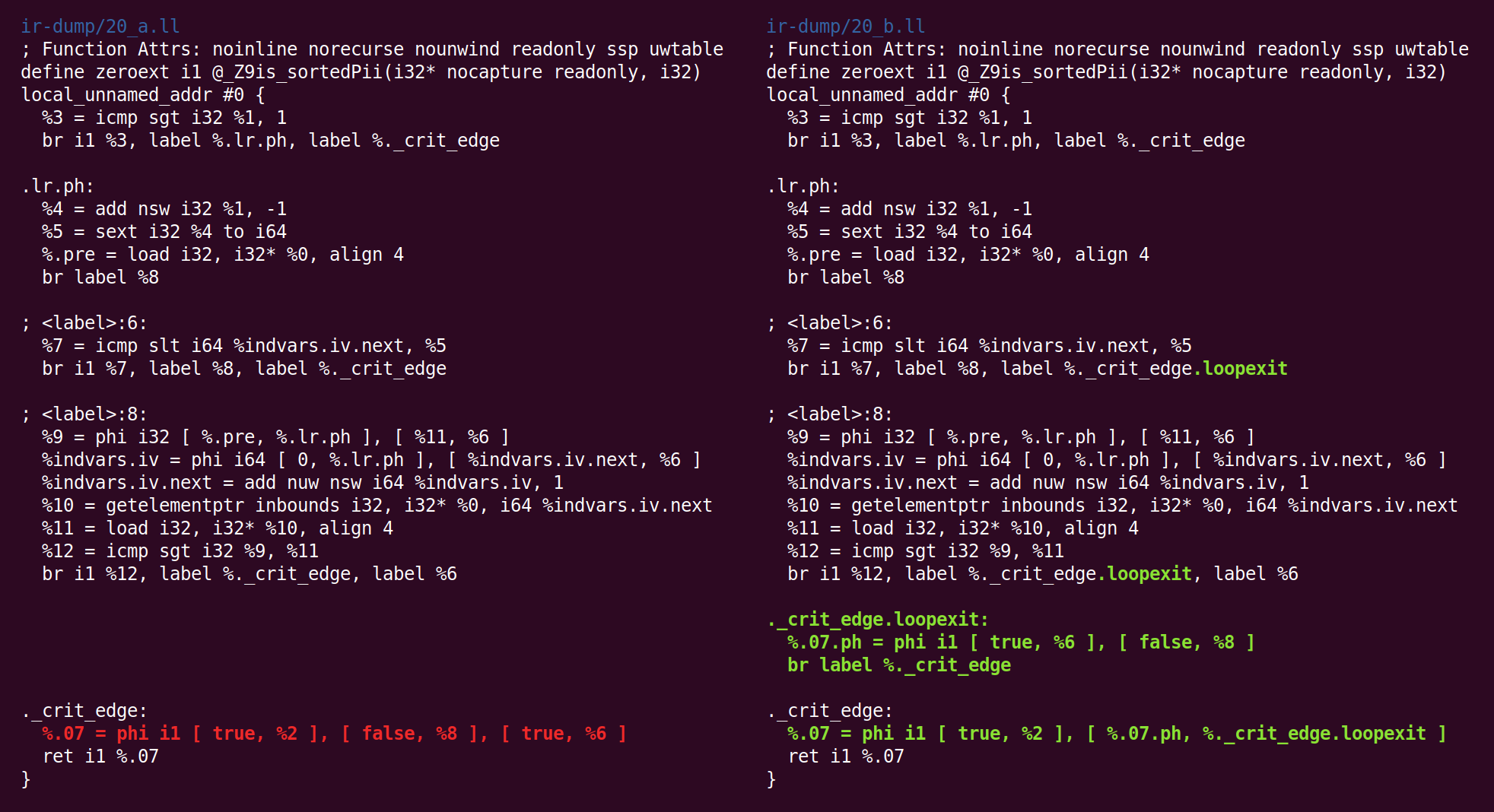
Und da:

Und schließlich sind wir mit dem Mittelland fertig! Der Code auf der rechten Seite ist der Code, den wir (in unserem Fall) an das x86-64-Backend übergeben.
Sie mögen neugierig sein, ob Schwankungen im Verhalten am Ende der Pipeline das Ergebnis eines Compiler-Fehlers sind, aber lassen Sie uns berücksichtigen, dass diese Funktion sehr, sehr einfach ist und viele Durchgänge in ihrer Verarbeitung involviert sind, aber ich habe sie nicht einmal erwähnt, weil sie hat keine Änderungen am Code vorgenommen. In der zweiten Hälfte der Optimierungspipeline beobachten wir hauptsächlich entartete Fälle für diese Funktion.
Danksagung: Einige Studenten in meinem ausführlichen Compiler-Kurs in diesem Herbst haben Feedback zu einem Entwurf dieses Beitrags hinterlassen (und ich habe dieses Material auch für Hausaufgaben verwendet). Ich ging durch die Funktionen, die hier in
dieser guten Reihe von Vorlesungen zur Schleifenoptimierung besprochen wurden.