Wie normalisiere ich das Ereignis richtig? Wie kann man ähnliche Ereignisse aus verschiedenen Quellen normalisieren, ohne etwas zu vergessen oder zu verwirren? Was aber, wenn zwei Experten dies unabhängig voneinander tun? In diesem Artikel werden wir eine gemeinsame Normalisierungsmethode vorstellen, die zur Lösung dieses Problems beitragen kann.
Bild: Martinoflynn.comAm häufigsten basieren Korrelationsregeln auf normalisierten Ereignissen. Somit beeinflusst die Normalisierung von Ereignissen und wie korrekt sie ausgeführt werden, direkt die Genauigkeit der Korrelationsregeln.
Die Probleme, die sich aus der Normalisierung von Ereignissen ergeben, wurden im ersten Artikel (
hier ) formuliert, und die Lösungen wurden in nachfolgenden Artikeln (
hier und
hier ) vorgeschlagen. Nun fassen wir die zuvor beschriebenen zusammen und bilden einen allgemeinen Ansatz zur Normalisierung von Ereignissen.
Zunächst erinnern wir uns, welche Werkzeuge der Normalisierungsstufe wir entwickelt haben:
- Allgemeines Feldschema zum Speichern von Daten, die aus Ereignissen abgerufen wurden. Seine Eigenschaften:
- Es berücksichtigt das Vorhandensein von Entitäten im Ereignis: Betreff, Objekt, Quelle und Sender von Ereignissen sowie Ressource.
- Bietet eine korrekte Normalisierung in Fällen, in denen das Ereignis Entitäten von Netzwerkebenen und Anwendungen enthält und mehr als ein Subjekt und / oder Objekt enthält.
- Ermöglicht es Ihnen, die Struktur des Interaktionsprozesses zwischen dem Subjekt und dem Objekt explizit zu identifizieren und beizubehalten
- Ereigniskategorisierungssystem, das die Semantik eines IT- oder IB-Ereignisses widerspiegeln kann.
Ereignisnormalisierungsmethode
Die gesamte Methode zur Normalisierung von Ereignissen besteht aus drei Schritten:
- Expertenbewertung der Veranstaltung.
- Definition des Interaktionsschemas.
- Definition der Ereigniskategorie.
Um das Verständnis der Funktionsweise des Tools zu erleichtern, wählen wir ein Ereignis aus und betrachten alle Normalisierungsschritte gemäß unserer Methodik im Detail.
Angenommen, wir haben eine Quelle - DBMS Oracle Database mit der folgenden Netzwerkadressierung:
- IP : 10.0.0.1;
- Hostname : myoracle;
- FQDN : myoracle.local.
Aus dieser Quelle entlädt der SIEM-Agent das folgende Ereignis:

Schritt 1. Expertenbewertung der Veranstaltung
Zu Beginn des Normalisierungsprozesses eines Ereignisses ist es wichtig zu verstehen, worum es bei diesem Ereignis geht. Es reicht aus, sich selbst seine Essenz zu sagen. Wenn ein Experte vom ersten, noch nicht normalisierten Ereignis an nicht versteht, welche Prozesse an der Quelle ablaufen, handelt es sich mit hoher Wahrscheinlichkeit um eine falsche Normalisierung. Über welche Art der korrekten Funktionsweise der Korrelationsregeln können wir dann sprechen?
Das Problem, wie gut der Experte das Ereignis richtig interpretiert, ist real. Kann ein Experte beispielsweise verstehen, was das nächste Ereignis bedeutet?
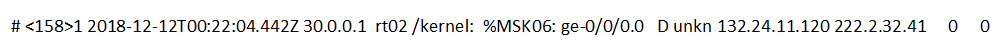
Wenn im ursprünglichen Beispiel die Essenz aus dem Text des Ereignisses selbst entnommen werden kann, müssen Sie in diesem Fall genau verstehen, mit welcher Quelle Sie arbeiten und in welchen Fällen ein ähnliches Ereignis generiert wird. Manchmal müssen Sie sogar einen separaten Stand mit einer Quelle bereitstellen, um die Situation, in der ein komplexes und schwer interpretierbares Ereignis an SIEM gesendet wird, vollständig zu reproduzieren.
Kehren wir mit einem Ereignis aus der Oracle-Datenbank zum ursprünglichen
Beispiel zurück . Zu diesem Zeitpunkt sollte der Experte folgendermaßen denken:
"
Als Experte glaube ich, dass das erste Ereignis den Prozess des Widerrufs einer Rolle durch einen Benutzer von einem anderen in einer Oracle-Datenbank beschreibt ."
Schritt 2. Bestimmen des Interaktionsschemas
Im vorherigen Schritt können wir sicherstellen, dass wir zumindest die allgemeine Bedeutung des Ereignisses verstehen. Jetzt werden wir detailliert analysieren, wie Entitäten unterschieden und das Schema ihrer Interaktion bestimmt werden können.
Gemäß dieser Methodik müssen für jedes
Interaktionsschema die Regeln für die Verteilung von Schlüsselentitätskennungen in den Feldern eines normalisierten Ereignisses beschrieben werden. Gleichzeitig werden Regeln definiert für:
- Entitäten auf Netzwerkebene
- Entitäten der Anwendungsebene.
Es ist wichtig, sich daran zu erinnern, dass es Schemata gibt, bei denen das Subjekt gleich dem Objekt und gleich der Quelle ist. Für solche Schemata müssen die Regeln für das Ausfüllen der Felder aller drei Einheiten klar definiert werden. Wenn dies nicht erfolgt, beginnen auf der Ebene der Korrelationsregeln oder der Suche nach Ereignissen Probleme und es erscheint zusätzliche Logik für die korrekte Interpretation leerer Felder. Darüber - in dem Artikel
über Interaktionsschemata .
Mal sehen, wie dieser Schritt der Methodik am ersten
Beispiel funktioniert:
- Interaktionsschema auf Netzwerkebene : Ein vollständiges direktes Erfassungsschema ohne Sender.
- Interaktionsschema auf Anwendungsebene : Interaktion über eine Ressource.
Für diese Schemata können die folgenden Normalisierungsregeln definiert werden:
- Entitäten der Netzwerkschicht:
- Betreff :
- Feld: src.ip = <leer>
- Feld: src.hostname = alex_host
- Feld: src.fqdn = <leer>
- Objekt
- Feld: dst.ip = 10.0.0.1
- Feld: dst.hostname = myoracle
- Feld: dst.fqdn = myoracle.local
- Quelle (entspricht Objekt) :
- Feld: event_source.ip = 10.0.0.1
- Feld: event_source.hostname = myoracle
- Feld: event_source.fqdn = myoracle.local
- Sender :
- Feld: forwarder.ip = <leer>
- Feld: forwarder.hostname = <leer>
- Feld: forwarder.fqdn = <leer>
- Kanal der Interaktion :
- Feld: Interaction.id = 2342594
- Entitäten der Anwendungsebene (Sammlung von Elementen):
- Betreff :
- Feld: Betreff [1] .name = "Alex"
- Feld: Betreff [1] .type = "Konto"
- Objekt
- Feld: Objekt [1] .name = "Bob"
- Feld: Objekt [1] .type = "Konto"
- Ressource :
- Feld: resource [1] .name = "MYROLE"
- Feld: Ressource [1] .type = "Rolle"
Schritt 3. Definieren einer Ereigniskategorie
Nachdem alle Schlüsselentitäten des Ereignisses identifiziert wurden, muss das Wesentliche des im Ereignis reflektierten Prozesses beschrieben und in die Normalisierungssprache übertragen werden. Zu diesem Zweck wird ein System zur Kategorisierung von Ereignissen verwendet. Das Ereigniskategorisierungssystem wurde in einem separaten
Artikel ausführlich besprochen. Lassen Sie uns nun sehen, wie es in der Praxis funktioniert.
Um die Normalisierung zu vereinheitlichen, definiert das Kategorisierungssystem die folgenden Regeln:
- Für jede Kategorie jeder Ebene von IT- und Informationssicherheitsereignissen bildet ein Experte ein Verzeichnis mit einer Liste der Informationen, die im Anfangsereignis gefunden und normalisiert werden müssen.
- Wenn einem Ereignis eine Kategorie zugewiesen wurde, ist der Experte gemäß dem Verzeichnis verpflichtet, die erforderlichen Informationen zu finden und zu normalisieren.
- Jede Kategorie definiert eine Reihe von normalisierten Ereignisschemafeldern, die ausgefüllt werden müssen.
Somit stellt die für die Veranstaltung ausgewählte Kategorie eine direkte Korrespondenz her zwischen:
- Ereignissemantik;
- wichtige Informationen, die gemäß der angehängten Kategorie aus dem Ereignis extrahiert werden sollen;
- eine Reihe von Feldern des Schemas eines normalisierten Ereignisses, in die diese Informationen "eingefügt" werden müssen.
Mit diesem Ansatz können Sie anhand der Kategorie eines Ereignisses klar verstehen, welche Daten sich in welchen Feldern des normalisierten Ereignisses befinden.
Wenn sich mit Unterstützung neuer Quellen herausstellt, dass einige wichtige Informationen zusätzlich aus den Ereignissen einer bestimmten Kategorie extrahiert werden müssen, werden sie in das Verzeichnis eingetragen. In diesem Fall benötigen Sie:
- Regeln zum Ausfüllen der Felder des Ereignisschemas definieren;
- Führen Sie eine Prüfung der Normalisierung für Ereignisse in dieser Kategorie aller zuvor unterstützten Quellen durch.
- Fügen Sie zuvor normalisierten Ereignissen neue Informationen hinzu.
Auf diese Weise bleibt die Konsistenz der vorgenommenen Änderungen erhalten. Betrachten Sie das ursprüngliche Beispiel.
Gemäß dem Kategorisierungssystem hat dieses Ereignis die folgenden Kategorien:
- Kategorisierungssystem : IT-Ereignisse
- Kategorie der ersten Ebene (Ebene 1) : Benutzer und Rechte
- Kategorie der zweiten Ebene (Ebene 2) : Benutzer
- Kategorie der dritten Ebene (Ebene 3) : Manipulation
Das Verzeichnis für diese Kategorie sieht folgendermaßen aus:
- Wenn Sie Ereignisse in der Kategorie Benutzer und Rechte normalisieren, ist es wichtig zu verstehen:
- Wenn eine Eskalation von Berechtigungen verwendet wurde, in deren Auftrag der Prozess implementiert wird.
- Feld: Betreff [i] .zuweisen
- Waren die Aktionen erfolgreich?
- Was ist der Rückkehrcode?
- Wenn Sie die Ereignisse der Benutzerkategorie normalisieren, ist es wichtig zu verstehen:
- Gibt es Informationen über die IP-Adresse, den Hostnamen oder die FQDN des Computers des Benutzers?
- Felder: src.ip, src.hostname, src.fqdn
- Felder: dst.ip, dst.hostname, dst.fqdn
- Unter welchem Konto hat sich der Benutzer verbunden.
- Felder: Betreff [i] .name, Objekt [i] .name
- Gibt es Informationen zu seinem Konto im Betriebssystem?
- Felder: Betreff [i] .osname, Objekt [i] .osname
- Gibt es Domain-Kontoinformationen?
- Felder: Subjekt [i] .Domäne, Objekt [i] .Domäne
- Gibt es Informationen zur Anwendung des Benutzers?
- Felder: Betreff [i] .Anwendung, Objekt [i] .Anwendung
- Beim Normalisieren von Ereignissen in der Kategorie Manipulation ist es wichtig zu verstehen:
- Art der Operation.
- Was hat sich geändert?
- Feld: Objekt [i] .name, Objekt [i] .type - beim Ändern von Konten
- Feld: resource [i] .name, resource [i] .type - beim Ändern von Ressourcen
- Was hat sich geändert?
- Feld: Objekt [i] .modifizieren
- Feld: Ressource [i] .modifizieren
- Wenn sich die Operation auf einer Ressource befand, wer ist ihr Eigentümer?
- Feld: Ressource [i]. Eigentümer
Wir haben diesen Leitfaden gegeben, um das Prinzip seiner Entstehung zu demonstrieren, daher gibt er nicht vor, genau und vollständig zu sein.
Infolgedessen sieht das durch diese Methode normalisierte Ereignis folgendermaßen aus:
 Ein Beispiel für ein normalisiertes Ereignis im dritten Schritt der Methodik.
Ein Beispiel für ein normalisiertes Ereignis im dritten Schritt der Methodik.Schlussfolgerungen
Die Erfahrung zeigt, dass es häufig Normalisierungsfehler und das Fehlen einheitlicher Normalisierungsregeln sind, die häufig zu falsch positiven Ergebnissen von Korrelationsregeln führen. Jetzt haben wir einen Ansatz, der es ermöglicht, die Auswirkungen des Problems zumindest zu minimieren, wenn sie nicht beseitigt werden.
Zusammenfassend umfasst der Ansatz drei Schritte:
- Schritt 1 Der Experte versucht, das allgemeine Wesen des im Anfangsereignis beschriebenen Phänomens zu verstehen.
- Schritt 2 Der Experte identifiziert die Hauptentitäten der Netzwerk- und Anwendungsebene für das Ereignis: Betreff, Objekt, Quelle, Sender, Ressource, Interaktionskanal. Es isoliert sie im Ereignis und bestimmt das Interaktionsmuster dieser Entitäten. Jedes Schema generiert Regeln zum Platzieren dieser Entitäten in den Feldern eines normalisierten Ereignisses - eines Schemas. Dies wurde ausführlich in einem Artikel über Entitätsinteraktionsschemata beschrieben.
- Schritt 3 Der Experte bestimmt die Kategorie der ersten, zweiten und dritten Ebene. Für jede Kategorie wird ein Verzeichnis erstellt, das eine Beschreibung der Daten enthält, die während der Normalisierung im Ereignis zu finden sind, sowie Informationen darüber, in welchen Feldern des normalisierten Ereignisses die gefundenen Daten "abgelegt" werden müssen.
Von der Konstruktion der Korrelationsregeln für „out of the box“ unterscheiden wir uns nur noch durch das Problem der ständigen Änderungen der Entitäten selbst - der Vermögenswerte. Ihre Adressen ändern sich, neue Assets werden eingeführt, alte werden außer Betrieb genommen, Clusterknoten wechseln und virtuelle Maschinen wechseln von einem Rechenzentrum in ein anderes und manchmal sogar bei einer Änderung der Adressierung. Wie diese Probleme überwunden werden können, erfahren Sie im nächsten Artikel des Zyklus.
Artikelserie:SIEM-Tiefen: Out-of-Box-Korrelationen. Teil 1: Reines Marketing oder ein unlösbares Problem?SIEM-Tiefen: Out-of-Box-Korrelationen. Teil 2. Datenschema als Reflexion des WeltmodellsSIEM-Tiefen: Out-of-Box-Korrelationen. Teil 3.1. EreigniskategorisierungSIEM-Tiefen: Out-of-Box-Korrelationen. Teil 3.2. Ereignisnormalisierungsmethode (
Dieser Artikel )
SIEM-Tiefen: Out-of-Box-Korrelationen. Teil 4. Systemmodell als Kontext von KorrelationsregelnSIEM-Tiefen: Out-of-Box-Korrelationen. Teil 5. Methodik zur Entwicklung von Korrelationsregeln