Unter Hochlastbedingungen steigt die Komplexität der Optimierung relationaler Datenbanken um eine Größenordnung, da der Kauf noch leistungsfähigerer Hardware teuer ist und es nicht möglich ist, die Anwendung nachts nur für einen langen Datenbankänderungsprozess und eine Datenmigration auszuschalten.
Wir haben kürzlich darüber gesprochen, wie wir
den PHP-Code für unsere Anwendung optimiert haben . Jetzt ist die Wende des Artikels gekommen, wie wir die interne Struktur der am meisten geladenen und wichtigsten Datenbank in Badoo vollständig geändert haben, ohne eine einzige Anfrage zu verlieren.
Patient
Users DataBase oder UDB ist ein Dienst, der fast jede Anfrage an Badoo startet. Es löst mehrere Probleme: Erstens ist es das zentrale Repository der Hauptbenutzerdaten, für die die Autorisierung erfolgt (z. B. E-Mail, Benutzer-ID oder Facebook-ID). Zusätzlich zum Speichern dieser Daten bietet der Dienst eine Eindeutigkeitskontrolle (sodass sich zwei Benutzer mit derselben E-Mail-Adresse, facebook_id usw. nicht im System registrieren können). Der gleiche Dienst gibt Auskunft darüber, welcher der Tausenden von Shards alle anderen Benutzerdaten enthält.
Ende 2018 speichert UDB Daten von mehr als 800 Millionen Benutzern, die etwa 1 TB Speicherplatz belegen. All dies wird von zwei Master-Slave-MySQL-Servern in jedem unserer Rechenzentren bereitgestellt. Insgesamt verarbeiten sie mehr als 140.000 Anfragen pro Sekunde.
Der Fall von UDB bedeutet die Unzugänglichkeit aller Badoo, da der Code den Shard nicht finden kann, auf dem die Benutzerdaten liegen. Daher werden hohe Anforderungen an Zuverlässigkeit und Verfügbarkeit gestellt.
Aufgrund dieser Besonderheit ist es sehr teuer, Änderungen an der Speicherstruktur vorzunehmen. Daher haben wir das UDB-Design 2013 sehr ernst genommen. Im Laufe der Zeit ändern sich jedoch sowohl die Anforderungen als auch die Lastprofile. In dem Bestreben, das System an neue Anforderungen und Lastniveaus anzupassen, wurden viele kleine und einfache Änderungen vorgenommen, aber leider sind solche Änderungen bei weitem nicht die effektivsten. Und der Tag kam, an dem es klüger war, anstelle des nächsten Hacks oder des Kaufs teurer Hardware globaler zu optimieren. Weiter werden wir die Hauptphasen dieses Weges betrachten.
Nicht-invasive Optimierungen
Änderungen an der Struktur einer großen und geladenen Datenbank sind aufgrund der Komplexität des Datenmigrationsprozesses recht teuer. Daher sollten Sie zunächst alle Optimierungsoptionen ausschöpfen, die sich nicht auf die Datenstruktur auswirken, sondern auf Code- und SQL-Abfragen beschränkt sind. Vielleicht reicht dies aus, um das Problem der übermäßigen Arbeitsbelastung um ein paar Jahre zu verschieben, sodass Sie zu diesem Zeitpunkt etwas Wichtigeres für das Unternehmen tun können.
Je besser Sie Ihr System verstehen, desto einfacher wird es für Sie, Ansätze für solche Optimierungen zu finden. Stellen Sie sicher, dass Sie alle Metriken sammeln, die Ihnen helfen können. Hierbei handelt es sich nicht nur um Systemmetriken wie CPU-Auslastung und RAM-Auslastung oder die Metriken einer bestimmten Datenbank, sondern auch um Metriken auf Anwendungsebene einer Anwendung, die an eine optimierte Datenbank gebunden ist. Wie viele Anfragen pro Sekunde haben verschiedene Arten von Operationen? Was ist ihre Reaktionszeit? Wie groß ist die Ein- und Ausgabe? Anhand dieser Metriken können Sie den Erfolg der Optimierung beurteilen. Es ist unwahrscheinlich, dass Sie eine Optimierung benötigen, die die CPU-Auslastung auf dem Datenbankserver geringfügig verringert, gleichzeitig aber die Antwortzeit Ihrer Anwendung um das Zehnfache erhöht.

Nachdem wir begonnen hatten, zusätzliche Metriken auf Anwendungsebene für UDB zu sammeln, konnten wir besser verstehen, welche der durchgeführten Vorgänge 80% der Last verursachen und die ersten Kandidaten für das Studium sind und welche nur wenig oder gar nicht verwendet werden.
Eine detaillierte Analyse des häufigsten Vorgangs (Abrufen von Benutzern, die bestimmte Kriterien erfüllen) ergab, dass die Anwendung in 95% der Fälle nur user_id verwendet, obwohl alle verfügbaren Benutzerdaten aus der Datenbank angefordert werden. Durch die Aufteilung dieses Falls in eine separate API-Methode, die nur eine Spalte aus der Tabelle extrahiert, konnten wir von der Verwendung des Deckungsindex profitieren und damit etwa 5% der CPU-Auslastung vom Datenbankserver entfernen.
Die Analyse eines anderen häufigen Vorgangs ergab, dass die abgerufenen Daten trotz der Tatsache, dass sie für jede HTTP-Anforderung ausgeführt werden, in der Realität äußerst selten sind. Wir haben diese Anfrage in ein faules Modell übersetzt.
Das Hauptziel von Metriken im Fall eines Optimierungsprojekts besteht darin, Ihre Datenbank besser zu verstehen und die dicksten Teile zu finden. Es macht keinen Sinn, viel Zeit und Mühe in die Optimierung von Abfragen zu investieren, die weniger als 1% Ihres Lastprofils ausmachen. Wenn Sie keine Metriken haben, mit denen Sie das Profil Ihrer Last verstehen können, sammeln Sie sie. Mit solchen Optimierungen auf der Codeseite ist es uns gelungen, etwa 15% der CPU-Auslastung aus 80% der verbrauchten Datenbank zu entfernen.
Ideen testen
Wenn Sie eine geladene Datenbank durch Ändern ihrer Struktur optimieren möchten, sollten Sie zunächst Ihre Ideen auf einem Prüfstand überprüfen, da selbst Optimierungen, die theoretisch sehr vielversprechend aussehen, in der Praxis möglicherweise keine positiven Auswirkungen haben (und manchmal sogar negative Auswirkungen haben). Und es ist unwahrscheinlich, dass Sie dies erst nach einer langen Datenmigration in der Produktion wissen möchten.
Je näher Ihre Standkonfiguration an der Produktionskonfiguration liegt, desto zuverlässiger erhalten Sie Ergebnisse. Ein wichtiger Punkt ist die korrekte Belastung des Ständers. Das Ausführen von zufälligen oder denselben Abfragen kann zu falschen Ergebnissen führen. Die beste Option ist die Verwendung realer Anforderungen aus der Produktion. Für UDB haben wir jede zehnte API-Leseanforderung (einschließlich Parameter) in Form eines JSON-Protokolls in einer Datei aus der Produktion protokolliert. Für einen Tag haben wir aus 700 Millionen Anfragen ein Protokoll mit einer Größe von 65 GB gesammelt.
Wir haben den Datensatz nicht getestet, da er im Vergleich zur Anzahl der Leseanforderungen sehr klein ist und unsere Last nicht beeinflusst. Dies ist jedoch in Ihrem Fall möglicherweise nicht der Fall. Wenn Sie den Prüfstand mit Schreibanforderungen laden möchten, müssen Sie jede Anforderung erfassen, da das Überspringen von Schreibanforderungen zu Konsistenzfehlern auf dem Prüfstand führen kann.
Der nächste Schritt besteht darin, das Protokoll auf dem Stand korrekt zu verlieren. Wir haben 400 PHP-Mitarbeiter verwendet, die über unsere
Skript-Cloud gestartet wurden und das gesammelte Protokoll aus der schnellen Warteschlange lesen und Anforderungen nacheinander ausführen. In diesem Fall wird die Warteschlange mit einem anderen Skript mit einer genau definierten Geschwindigkeit gefüllt. Zum Testen von Ideen haben wir die Geschwindigkeit von x10 verwendet, die multipliziert mit der Tatsache, dass wir nur jede zehnte Anfrage aus der Produktion gesammelt haben, die gleiche Anzahl von RPS ergab wie in der Produktion.
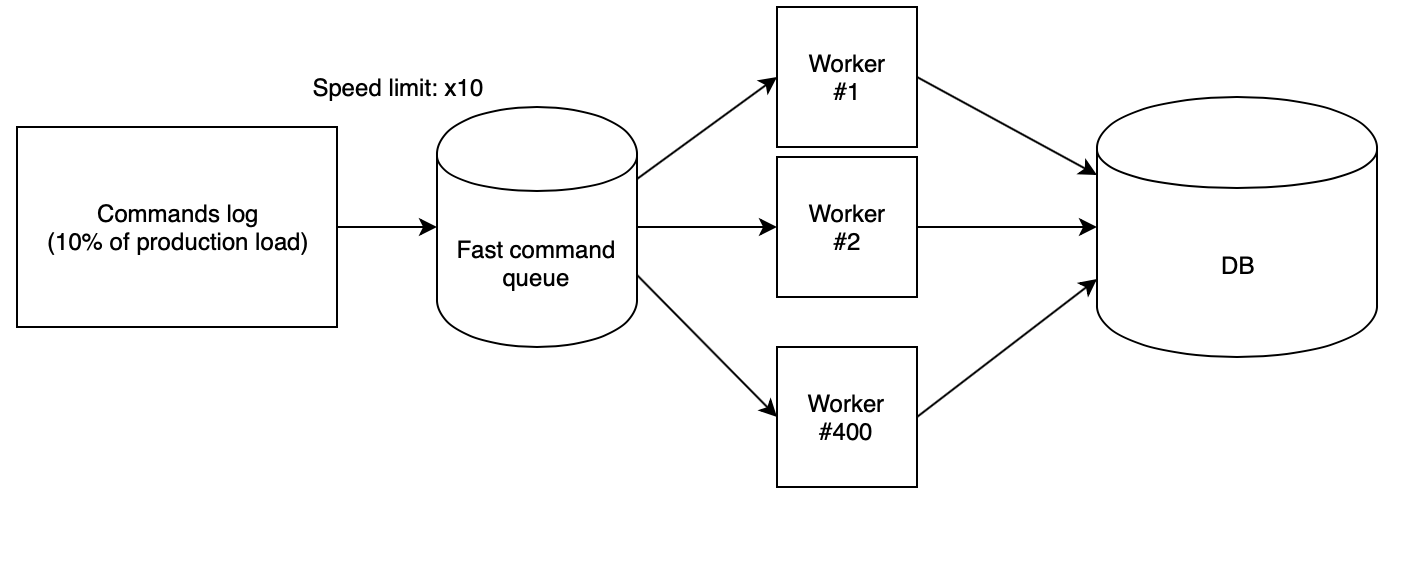
Mit diesen Koeffizienten stellt sich heraus, dass der Produktionstag mit allen Lastabfällen auf dem Prüfstand in nur zweieinhalb Stunden fliegt.
So sah beispielsweise der erste Test, den wir einen halben Tag lang mit einer Geschwindigkeit von x5 (50% der Produktionslast) im Abfrageprotokoll durchgeführt haben, folgendermaßen aus:
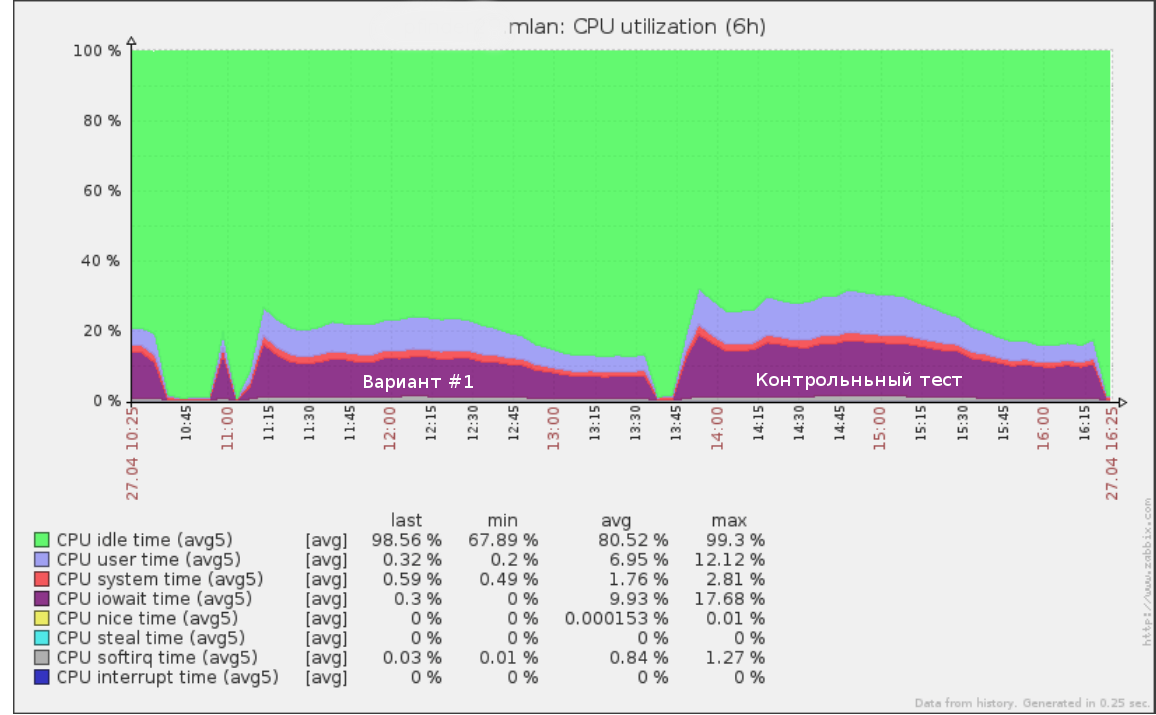
Dieselben Werkzeuge können zur Durchführung eines Fehlertests verwendet werden: Erhöhen der Geschwindigkeit (und damit des RPS), bis sich die Basis am Stand zu verschlechtern beginnt. Auf diese Weise erhalten Sie ein klares Verständnis dafür, wie viel mehr Last Ihre Datenbank aushalten kann.
Nach dem Testen des neuen Datenschemas ist es auch wichtig, einen Kontrolltest für die ursprüngliche Datenbankstruktur durchzuführen. Wenn die Ergebnisse und die aktuelle Leistung in der Produktion sehr unterschiedlich sind, sollten Sie zuerst die Gründe verstehen. Möglicherweise ist der Testserver falsch konfiguriert und Sie können den Lasttestdaten nicht vertrauen.
Es lohnt sich auch sicherzustellen, dass der neue Code korrekt funktioniert. Es ist wenig sinnvoll, die Leistung von Abfragen zu testen, die den Job nicht ausführen. Integrationstests, bei denen überprüft wird, ob die alte und die neue API bei denselben API-Aufrufen dieselben Werte zurückgeben, werden Sie gut bedienen.
Nachdem Sie zu allen Ideen Ergebnisse erhalten haben, müssen Sie nur noch Optionen mit dem besten Gleichgewicht zwischen Preis und Qualität auswählen und ein neues Produktionsschema einführen.
Schemaänderung
Zunächst stelle ich fest, dass das Ändern des Datenschemas ohne Unterbrechung des Betriebs des Dienstes immer recht schwierig, teuer und riskant ist. Wenn Sie also die Möglichkeit haben, Ihre Anwendung zu stoppen, während Sie die Struktur ändern, tun Sie es einfach. Bei UDB konnten wir uns das leider nicht leisten.
Der zweite Faktor, der die Komplexität der Änderung einer Schaltung beeinflusst, ist das geplante Ausmaß der Änderung. Wenn alle vorgeschlagenen Änderungen an den Tabellen nicht über eine Änderung hinausgehen (z. B. Hinzufügen eines Paares neuer Indizes oder Spalten), können Sie sie mit typischen Prozessen wie
pt-online-schema-change und
gh-ost für MySQL oder einem alternativen Slave
starten und anschließend ihre
Positionen ändern .
In unserem Fall wurde ein hervorragendes Ergebnis beim vertikalen Sharding einer etwa ein Dutzend kleineren riesigen Tabelle mit anderen Spalten, Indizes und Daten in einem anderen Format gezeigt. Eine solche Konvertierung mit typischen Werkzeugen ist nicht mehr möglich. Was tun?
Wir haben den folgenden Algorithmus angewendet:
- Wir erreichen einen Zustand, in dem sowohl das alte als auch das neue Schema mit aktuellen Daten gleichzeitig existieren. Die Aufzeichnung erfolgt in beiden Versionen, und gleichzeitig besteht in beiden Versionen eine Garantie für die Datenkonsistenz. Wir werden diesen Punkt unten im Detail betrachten.
- Schalten Sie den gesamten Messwert schrittweise auf einen neuen Stromkreis um und steuern Sie die Last.
- Schalten Sie die Aufnahme im alten Schema aus und löschen Sie sie.
Die Hauptvorteile dieses Ansatzes:
- Sicherheit: Es besteht die Möglichkeit eines sofortigen Rollbacks bis zur letzten Stufe (schalten Sie den Messwert einfach auf das alte Schema zurück, wenn ein Fehler aufgetreten ist).
- Volllastkontrolle während der Datenmigration;
- Es ist keine schwere Änderung des großen Tisches der alten Schaltung erforderlich.
Es gibt jedoch auch Nachteile:
- Die Notwendigkeit, beide Versionen der Schemas während des Migrationsprozesses auf der Festplatte zu belassen (dies kann ein Problem sein, wenn Sie wenig Speicherplatz haben und die zu migrierende Tabelle sehr groß ist).
- viel temporärer Code zur Unterstützung des Migrationsprozesses, der nach Abschluss abgeschnitten wird;
- Es ist möglich, den Cache durch paralleles Lesen aus zwei Schemata zu waschen. Es bestand die Befürchtung, dass die alte und die neue Version um RAM konkurrieren könnten, was zu einer Verschlechterung des Dienstes führen könnte (in Wirklichkeit verursachte dies eine zusätzliche Belastung, da die Migration jedoch außerhalb der Spitzenzeiten durchgeführt wurde, verursachte dies keine Probleme für uns).
Die Hauptschwierigkeit bei diesem Algorithmus ist der erste Punkt. Wir werden es im Detail betrachten.
Synchronisierung ändern
Die Migration statischer Daten ist nicht besonders schwierig. Was ist jedoch, wenn Sie nicht einfach die gesamte Aufzeichnung stoppen können, während die Datenbank migriert wird?
Es gibt verschiedene Optionen, um eine Synchronisierung des neuen Schemas zu erreichen: Migration mit fortlaufendem Protokoll und idempotente Aufzeichnung der Migration.
Migrieren eines Datenschnappschusses und anschließende Wiedergabe des Protokolls der folgenden Änderungen
Jede Datenaktualisierungstransaktion wird durch Trigger entweder auf Anwendungsebene in einer speziellen Tabelle protokolliert, oder das Replikations-Binlog wird als Protokoll verwendet. Nachdem Sie ein solches Protokoll erstellt haben, können Sie eine Transaktion öffnen und einen Datenschnappschuss migrieren, wobei Sie sich die Position im Protokoll merken. Dann muss noch begonnen werden, das gesammelte Protokoll auf das neue Schema anzuwenden. In ähnlicher
Weise funktioniert beispielsweise das beliebte
Backup-Tool MySQL
Percona XtraBackup .
Nachdem das neue Schema das Protokoll des aktuellen Datensatzes eingeholt hat, beginnt die wichtigste Phase: Sie müssen die Aufzeichnung im alten Schema noch für einen kurzen Zeitraum anhalten und sicherstellen, dass das gesamte verfügbare Protokoll auf das neue Schema angewendet wird. Dies bedeutet, dass die Daten zwischen den Schemata konsistent sind. Aktivieren Sie auf Anwendungsebene die gleichzeitige Aufzeichnung in beiden Quellen.
Die Hauptnachteile dieses Ansatzes sind, dass Sie das Betriebsprotokoll irgendwie speichern müssen, was an sich eine Last im komplexen Schaltprozess erzeugen kann, sowie in der Wahrscheinlichkeit, den Rekord zu brechen, wenn sich die Schaltkreise aus irgendeinem Grund als inkonsistent herausstellen.
Idempotenter Rekord
Die Hauptidee dieses Ansatzes besteht darin, parallel zum Schreiben in das alte Schema zu schreiben, bevor die Änderungen vollständig synchronisiert sind, und dann die Migration der verbleibenden Daten abzuschließen. Ebenso werden normalerweise neue Spalten in große Tabellen gefüllt.
Die synchrone Aufzeichnung kann sowohl bei Datenbank-Triggern als auch im Quellcode implementiert werden. Ich rate Ihnen, dies genau im Code zu tun, da Sie in jedem Fall irgendwann Code schreiben müssen, der Daten in das neue Schema schreibt, und die Implementierung der Migration auf der Codeseite Ihnen mehr Kontrolle bietet.
Ein wichtiger zu berücksichtigender Punkt ist, dass sich das neue Schema bis zum Abschluss der Migration in einem inkonsistenten Zustand befindet. Aus diesem Grund ist ein Szenario möglich, wenn das Aktualisieren einer neuen Tabelle zu einer Verletzung der Datenbankkonstante (Fremdschlüssel oder ein eindeutiger Index) führt, während die Transaktion aus Sicht des aktuellen Schemas vollständig korrekt ist und ausgeführt werden sollte.
Diese Situation kann aufgrund des Migrationsprozesses zu einem Rollback guter Transaktionen führen. Der einfachste Weg, um dieses Problem zu umgehen, besteht darin, den Modifikator IGNORE zu allen Anforderungen hinzuzufügen, um Daten in ein neues Schema zu schreiben oder das Rollback einer solchen Transaktion abzufangen und die Version auszuführen, ohne in das neue Schema zu schreiben.
Der Synchronisationsalgorithmus durch idempotente Aufzeichnung ist in unserem Fall wie folgt:
- Wir aktivieren die Aufzeichnung in einem neuen Schema parallel zur Aufzeichnung im alten im Kompatibilitätsmodus (IGNORE).
- Wir führen ein Skript aus, das das neue Schema schrittweise umgeht und inkonsistente Daten erfasst. Danach sollten die Daten in beiden Tabellen synchronisiert werden. Dies ist jedoch aufgrund möglicher Konflikte in Abschnitt 1 ungenau.
- Wir starten die Datenkonsistenzprüfung - wir öffnen die Transaktion und lesen nacheinander die Zeilen aus den neuen und alten Schemata, um deren Korrespondenz zu vergleichen.
- Wenn es Konflikte gibt, beenden wir und kehren zu Absatz 3 zurück.
- Nachdem der Prüfer gezeigt hat, dass die Daten in beiden Schemata synchronisiert sind, sollte es keine weiteren Diskrepanzen zwischen den Schemata geben, es sei denn, wir haben natürlich eine Nuance übersehen. Daher warten wir einige Zeit (z. B. eine Woche) und führen eine Kontrollprüfung durch. Wenn er zeigt, dass alles in Ordnung ist, ist die Aufgabe erfolgreich abgeschlossen und Sie können die Lesung übersetzen.
Ergebnisse
Durch die Änderung des Datenformats konnten wir die Größe der Haupttabelle von 544 GB auf 226 GB reduzieren, wodurch die Belastung der Festplatte verringert und die Menge nützlicher Daten erhöht wurde, die in den Arbeitsspeicher passen.
Insgesamt konnten wir von Beginn des Projekts an mit allen beschriebenen Ansätzen die CPU-Auslastung des Datenbankservers bei Spitzenverkehr von 80% auf 35% reduzieren. Die Ergebnisse des anschließenden Stresstests zeigten, dass wir bei der aktuellen Wachstumsrate der Last noch mindestens drei Jahre auf der vorhandenen Hardware bleiben können.
Das Aufteilen einer großen Tabelle in mehrere vereinfachte die Durchführung zukünftiger Änderungen in der Datenbank und beschleunigte einige Skripte, die Daten für BI sammelten, erheblich.