 Von einem Übersetzer:
Von einem Übersetzer: Heute veröffentlichen wir für Sie einen gemeinsamen Artikel der drei Entwickler Akaash Chikarmane, Erte Bablu und Nikhil Gaur, in dem die Methode zur Vorhersage der Bewertung von Anwendungen im Google Play Store beschrieben wird.
In diesem Artikel zeigen wir, wie wir Informationen verarbeiten, die wir zur Vorhersage von Bewertungen verwenden. Wir werden auch erklären, warum wir diese oder jene von ihnen verwenden. Wir werden über die Transformationen des Datenpakets sprechen, mit dem wir arbeiten, und darüber, was mit Hilfe der Visualisierung erreicht werden kann.
Skillbox empfiehlt: Zweijähriger Praktikumskurs "Ich bin ein PRO-Webentwickler . "
Wir erinnern Sie daran: Für alle Leser von „Habr“ - ein Rabatt von 10.000 Rubel bei der Anmeldung für einen Skillbox-Kurs mit dem Promo-Code „Habr“.
Warum wir uns dazu entschlossen haben
Mobile Anwendungen sind seit langem ein fester Bestandteil des Lebens. Immer mehr Entwickler beschäftigen sich ausschließlich mit ihrer Erstellung. Darüber hinaus sind viele direkt von den Einnahmen abhängig, die Anträge bringen. Daher ist die Prognose des Erfolgs für sie von großer Bedeutung.
Unser Ziel ist es, die Gesamtbewertung der Anwendung zu ermitteln, um dies umfassend zu tun, da zu viele Personen das Programm beurteilen und sich nur auf die Anzahl der von den Benutzern festgelegten "Sterne" verlassen. Bewerbungen mit 4-5 Punkten sind glaubwürdiger.
Vorbereitung
Der größte Teil dieses Projekts arbeitet mit Daten, einschließlich Vorverarbeitung. Da alle Informationen aus dem Google Play Store stammen, enthielten die resultierenden Arrays viele Fehler. Wir haben verschiedene Regressionsmodelle verwendet, darunter den Gradient-Boosting-Regressor aus dem XGBoost-Paket, Linear Regression und RidgeRegression.
Datenerfassung und -analyse
Den Datensatz, mit dem wir gearbeitet haben,
finden Sie hier . Es besteht aus zwei Teilen. Das erste sind objektive Informationen wie Anwendungsgröße, Anzahl der Installationen, Kategorie, Anzahl der Überprüfungen, Art der Anwendung, Genre, Datum der letzten Aktualisierung usw. und subjektive, dh Benutzerbewertungen.
Die Bewertungen selbst wurden einer Analyse unterzogen. Nach dem Vergleich der Ergebnisse haben wir entschieden, ob die Umfragedaten in das endgültige Modell aufgenommen werden sollen oder nicht.
Wir haben einen objektiven Datensatz aus 12 Funktionen und einer Zielvariablen (Bewertung) gebildet. Das Paket enthielt 10,8 Tausend Informationseinheiten. Für die Bewertungen der Benutzer haben wir die 100 relevantesten ausgewählt und fünf Funktionen für 64,3 Tausend Elemente verwendet. Alle Daten wurden direkt aus dem Google Play Store gesammelt, als sie vor drei Monaten das letzte Mal aktualisiert wurden.
Datenvorverarbeitung
Die anfänglichen Informationen sahen ungefähr so aus:
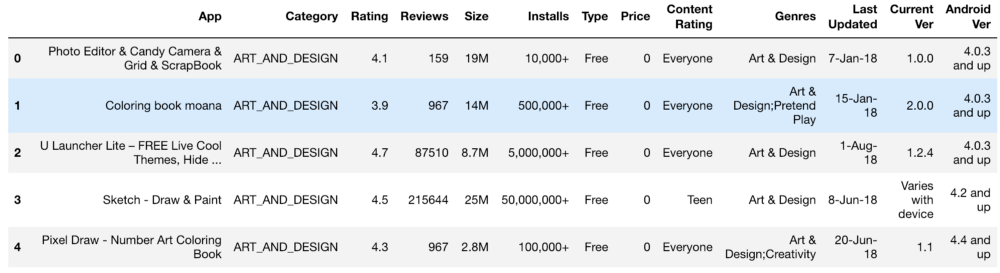
Einstellungen, Bewertung, Kosten und Größe - all dies haben wir so verarbeitet, dass Zahlen erhalten werden, die für das Verständnis der Maschine zugänglich sind. Bei der Verarbeitung verschiedener Funktionen traten Probleme auf, beispielsweise die Notwendigkeit, das "+" zu entfernen. Bei den Kosten haben wir $ entfernt. Das Volumen der Anwendung erwies sich als das problematischste in Bezug auf die Verarbeitung, da sowohl KB als auch MB auftauchten. Daher mussten einige Arbeiten durchgeführt werden, um alles auf ein einziges Format zu reduzieren. Die Primärdaten werden unten angezeigt und sind auch nach der Verarbeitung.
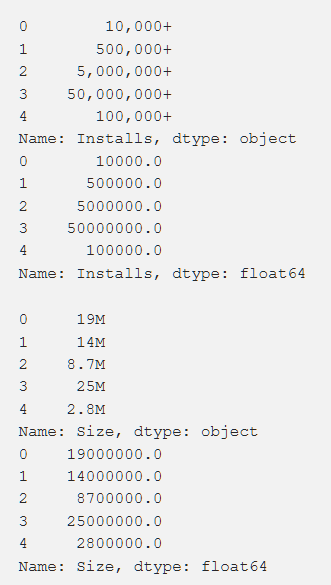
Darüber hinaus haben wir einige Daten transformiert, um sie für unsere Arbeit relevanter zu machen. Beispielsweise waren Informationen zum neuesten Anwendungsupdate nicht sehr nützlich. Um sie aussagekräftiger zu machen, haben wir dies in Informationen über die seit dem letzten Update verstrichene Zeit umgewandelt. Der Code für diese Aufgabe wird unten angezeigt.
from datetime import datetime from dateutil.relativedelta import relativedelta n = 3
Es war auch notwendig, einzelne Standardvariablen mit mehreren unterschiedlichen Werten (z. B. "Genre") zusammenzufassen. Wie dies gemacht wurde, ist unten gezeigt.
from copy import deepcopy from sklearn.preprocessing import LabelEncoder def one_hot_encode_by_label(df, labels): df_new = deepcopy(df) for label in labels: dummies = df_new[label].str.get_dummies(sep = ";") df_new = df_new.drop(labels = label, axis = 1) df_new = df_new.join(dummies) return df_new def label_encode_by_label(df, labels): df_new = deepcopy(df) le = LabelEncoder() for label in labels: print(label + " is label encoded") le.fit(df_new[label]) dummies = le.transform(df_new[label]) df_new.drop(label, axis = 1) df_new[label] = pd.Series(dummies) return df_new
Um die Daten zu normalisieren, haben wir versucht, log1p zu konvertieren. Vor ihm:
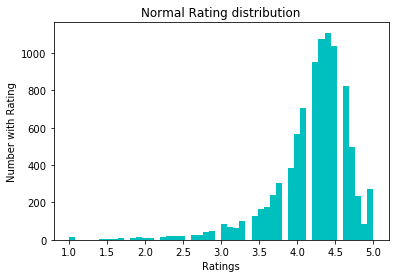
Nachher:
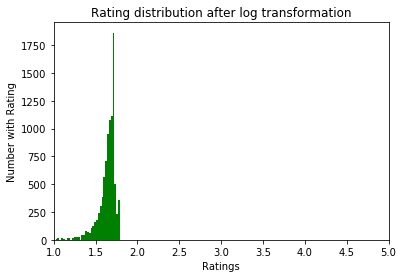
Datenexploration
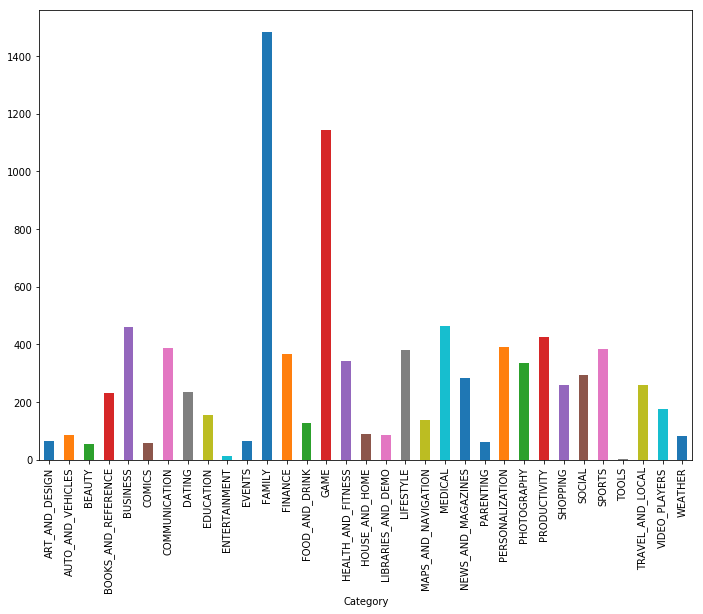
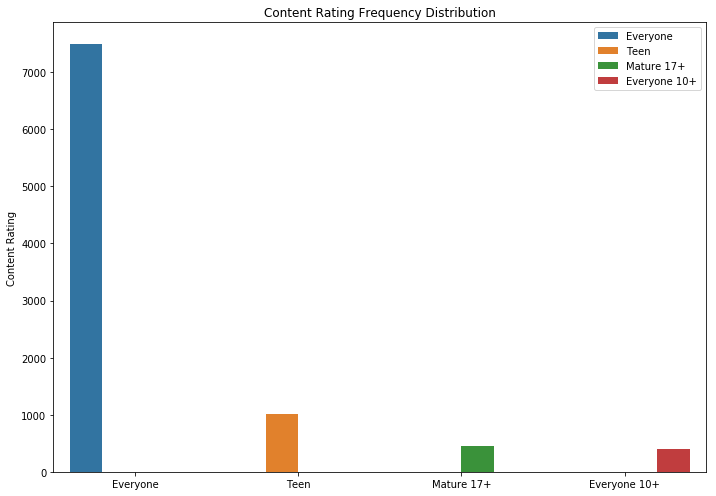
Wie Sie sehen können, sind Spiele und Anwendungen für die Familie die beiden beliebtesten Kategorien. Die meisten Bewerbungen fielen auch in die Kategorie "Für alle Altersgruppen".

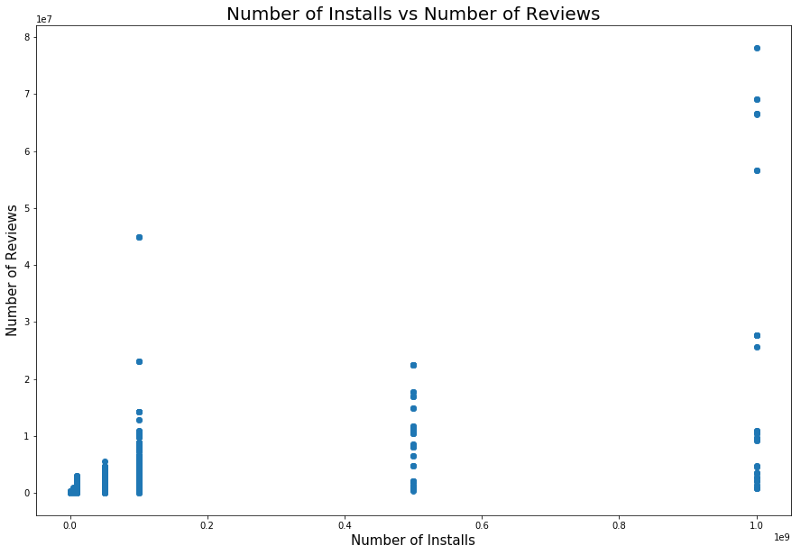
Es ist logisch, dass Anwendungen mit einer maximalen Bewertung mehr Bewertungen haben als Anwendungen mit einer niedrigen Bewertung. Einige von ihnen haben viel mehr Bewertungen als alle anderen. Möglicherweise ist der Grund dafür eine Popup-Nachricht, ein Aufruf zum Bewerten oder andere ähnliche Techniken.

Es gibt auch einen Zusammenhang zwischen der Anzahl der Installationen und der Anzahl der Überprüfungen. Die Korrelation ist im folgenden Screenshot dargestellt.
Eine detaillierte Analyse dieser Abhängigkeit kann ein Verständnis dafür vermitteln, warum beliebte Anwendungskategorien mehr Installationen und mehr Überprüfungen aufweisen.
Modelle und Ergebnisse
Wir haben die Testaufteilung verwendet, um die Daten in Test- und Trainingssätze aufzuteilen. Die Kreuzvalidierung mit GridSearchCV wurde verwendet, um die Ergebnisse des Modelltrainings zu verbessern und das beste Alpha mit Lasso, Ridge Regression und XGBRegressor aus dem XGBoost-Paket zu finden. Das letztere Modell ist im Allgemeinen äußerst effektiv, aber wenn man es verwendet, muss man sich davor hüten, die Ergebnisse anzupassen - dies ist eine der Gefahren, die Forscher erwarten. Der anfängliche Effektivwert ohne besonders sorgfältige Bearbeitung von Objekten (nur Codierung und Reinigung) betrug etwa 0,228.
Nach der logarithmischen Umrechnung der Bewertungen fiel der Standardfehler auf 0,219, was eine leichte Verbesserung darstellte, aber wir stellten fest, dass wir alles richtig gemacht haben.
Wir haben die lineare Regression verwendet, nachdem wir die Beziehung zwischen Bewertungen, Einstellungen und Bewertungen bewertet haben. Insbesondere haben wir die statistischen Informationen dieser Variablen analysiert, einschließlich des r-Quadrats und des p, und als Ergebnis eine Entscheidung über die lineare Regression getroffen. Das erste verwendete lineare Regressionsmodell zeigte eine Korrelation zwischen den Einstellungen und einer Bewertung von 0,2233, das lineare Regressionsmodell Unsere Bewertungen und Bewertungen ergaben eine MSE von 0,2107 und das kombinierte lineare Regressionsmodell, Bewertungen, Einstellungen und Bewertungen ", Hat uns eine MSE von 0,214 gegeben.
Zusätzlich haben wir das KNeighborsRegressor-Modell verwendet. Die Ergebnisse seiner Verwendung sind unten gezeigt.

Schlussfolgerungen
Nachdem die Primärdaten aus dem Google Play Store in ein verwendbares Format konvertiert wurden, haben wir Funktionen geplottet und abgeleitet, um die Korrelationen zwischen den einzelnen Werten zu verstehen. Diese Ergebnisse wurden dann verwendet, um ein optimales Modell zu erstellen.
Anfangs glaubten wir, dass es nicht allzu schwierig sein würde, es zu finden, um ein genaues Modell zu erstellen. Aber die Aufgabe war schwieriger als wir erwartet hatten.
Zusätzlich zu dem, was getan wurde, können Sie auch:
- Erstellen Sie für jedes Genre ein eigenes Modell.
- Erstellen Sie neue Funktionen aus Android-Betriebssystemversionen, wie wir es zuvor mit Datumsangaben getan haben.
- um den Algorithmus genauer zu lernen - wir hatten eine ausreichende Anzahl von kategorialen und numerischen Datenpunkten;
- Daten aus dem Google App Store unabhängig analysieren und löschen.
Alle Ergebnisse finden Sie
hier .
Skillbox empfiehlt: