Das Büro von Intel in Nischni Nowgorod entwickelt unter anderem Computer-Vision-Algorithmen, die auf tiefen neuronalen Netzen basieren. Viele unserer Algorithmen werden im
Open Model Zoo- Repository veröffentlicht. Das Modelltraining erfordert eine große Anzahl von markierten Daten. Theoretisch gibt es viele Möglichkeiten, sie vorzubereiten, aber die Verfügbarkeit spezieller Software beschleunigt diesen Prozess um ein Vielfaches. Um die Effizienz und Qualität des
Markups zu verbessern, haben wir unser eigenes Tool entwickelt - das
Computer Vision Annotation Tool (CVAT) .
Natürlich finden Sie im Internet viele kommentierte Daten, aber es gibt einige Probleme. Beispielsweise entstehen ständig neue Aufgaben, für die es einfach keine solchen Daten gibt. Ein weiteres Problem ist, dass aufgrund ihrer Lizenzvereinbarungen nicht alle Daten für die Entwicklung kommerzieller Produkte geeignet sind. Daher umfasst unsere Aktivität neben der Entwicklung und dem Training von Algorithmen auch das Markup von Daten. Dies ist ein ziemlich langwieriger und zeitaufwändiger Prozess, der für Entwickler unvernünftig wäre. Um beispielsweise einen unserer Algorithmen zu trainieren, wurden ungefähr 769.000 Objekte für mehr als 3.100 Mannstunden markiert.
Es gibt zwei Lösungen für das Problem:
- Die erste besteht darin, die Markup-Daten mit entsprechender Spezialisierung an Drittunternehmen zu übertragen. Wir hatten eine ähnliche Erfahrung. Erwähnenswert ist der komplizierte Prozess der Datenvalidierung und -wiederaufteilung sowie das Vorhandensein von Bürokratie.
- Das zweite, für uns bequemere ist die Erstellung und Unterstützung unseres eigenen Annotationsteams. Bequemlichkeit liegt in der Fähigkeit, schnell neue Aufgaben zu stellen, den Fortschritt ihrer Implementierung zu steuern und das Gleichgewicht zwischen Preis und Qualität zu erleichtern. Darüber hinaus ist es möglich, benutzerdefinierte Automatisierungsalgorithmen zu implementieren und die Markup-Qualität zu verbessern.
Ursprünglich wurde das Computer Vision Annotation Tool speziell für unser Annotationsteam entwickelt.

Unser Ziel war es natürlich nicht, den „15. Standard“ zu schaffen. Zuerst verwendeten wir eine vorgefertigte Lösung -
Vatic , aber dabei stellten die Annotations- und Algorithmus-Teams neue Anforderungen dafür, deren Implementierung schließlich zu einer vollständigen Neufassung des Programmcodes führte.
Weiter im Artikel:
- Allgemeine Informationen (Funktionalität, Anwendungen, Vor- und Nachteile des Tools)
- Geschichte und Evolution (eine kurze Geschichte darüber, wie CVAT lebte und sich entwickelte)
- Internes Gerät (allgemeine Architekturbeschreibung)
- Entwicklungsrichtungen (ein wenig über die Ziele, die ich erreichen möchte, und mögliche Wege zu ihnen)
Allgemeine Informationen
Das Computer Vision Annotation Tool (CVAT) ist ein Open Source-Tool zum Markieren digitaler Bilder und Videos. Seine Hauptaufgabe besteht darin, dem Benutzer bequeme und effektive Mittel zum Markieren von Datensätzen bereitzustellen. Wir erstellen CVAT als Universaldienst, der verschiedene Arten und Formate von Markups unterstützt.
Für Endbenutzer ist CVAT eine browserbasierte Webanwendung. Es unterstützt verschiedene Arbeitsszenarien und kann sowohl für die persönliche als auch für die Teamarbeit verwendet werden. Die Hauptaufgaben des maschinellen Lernens mit einem Lehrer im Bereich der Bildverarbeitung lassen sich in drei Gruppen einteilen:
- Objekterkennung
- Bildklassifizierung
- Bildsegmentierung
CVAT ist in all diesen Szenarien geeignet.
Vorteile:- Fehlende Installation durch Endbenutzer. Um eine Aufgabe zu erstellen oder Daten zu markieren, öffnen Sie einfach einen bestimmten Link im Browser.
- Die Fähigkeit zur Zusammenarbeit. Es besteht die Möglichkeit, die Aufgabe den Benutzern öffentlich zugänglich zu machen und die Arbeit daran zu parallelisieren.
- Einfach zu implementieren. Die Installation von CVAT im lokalen Netzwerk umfasst einige Befehle mithilfe von Docker .
- Automatisierung des Markup-Prozesses. Die Interpolation ermöglicht es Ihnen beispielsweise, Markups für viele Frames zu erhalten, wobei echte Arbeit nur für einige wichtige Frames erforderlich ist.
- Die Erfahrung von Profis. Das Tool wurde unter Beteiligung von Annotationen und mehreren algorithmischen Teams entwickelt.
- Die Fähigkeit zur Integration. CVAT eignet sich zur Integration in eine breitere Plattform. Zum Beispiel Onepanel .
- Optionale Unterstützung für verschiedene Tools:
- Deep Learning Deployment Toolkit (Komponente als Teil von OpenVINO)
- Tensorflow Object Detection API (TF OD API)
- ELK-Analysesystem (Elasticsearch + Logstash + Kibana)
- NVIDIA CUDA Toolkit
- Unterstützung für verschiedene Anmerkungsszenarien.
- Open Source unter einer einfachen und kostenlosen MIT-Lizenz .
Nachteile:- Eingeschränkte Browserunterstützung. Die Leistung des Client-Teils wird nur im Google Chrome-Browser garantiert. Wir testen CVAT nicht in anderen Browsern, aber theoretisch kann das Tool in Opera, Yandex Browser und anderen mit der Chromium-Engine arbeiten.
- Das System der automatischen Tests wurde nicht entwickelt. Alle Gesundheitsprüfungen werden manuell durchgeführt, was die Entwicklung erheblich verlangsamt. Wir arbeiten jedoch bereits gemeinsam mit Studenten der UNN an einer Lösung für dieses Problem. Lobachevsky im Rahmen des IT Lab- Projekts.
- Keine Quellcodedokumentation verfügbar. Sich an der Entwicklung zu beteiligen kann sehr schwierig sein.
- Leistungsbeschränkungen. Mit den steigenden Anforderungen an das Markup-Volumen hatten wir verschiedene Probleme, wie beispielsweise die Einschränkung der Chrome Sandbox hinsichtlich der Verwendung von RAM.
Natürlich sind diese Listen nicht vollständig, sondern enthalten grundlegende Bestimmungen.
Wie bereits erwähnt, unterstützt CVAT eine Reihe zusätzlicher Komponenten. Unter ihnen:
Deep Learning Deployment Toolkit als Teil des
OpenVINO Toolkit - wird verwendet, um den Start des TF OD API-Modells ohne GPU zu beschleunigen. Wir arbeiten an einigen anderen nützlichen Anwendungen für diese Komponente.
Tensorflow Object Detection API - wird verwendet, um Objekte automatisch zu markieren. Standardmäßig verwenden wir das Modell Faster RCNN Inception Resnet V2, das auf
COCO (80 Klassen) trainiert wurde. Es sollte jedoch keine Schwierigkeiten geben, andere Modelle miteinander zu verbinden.
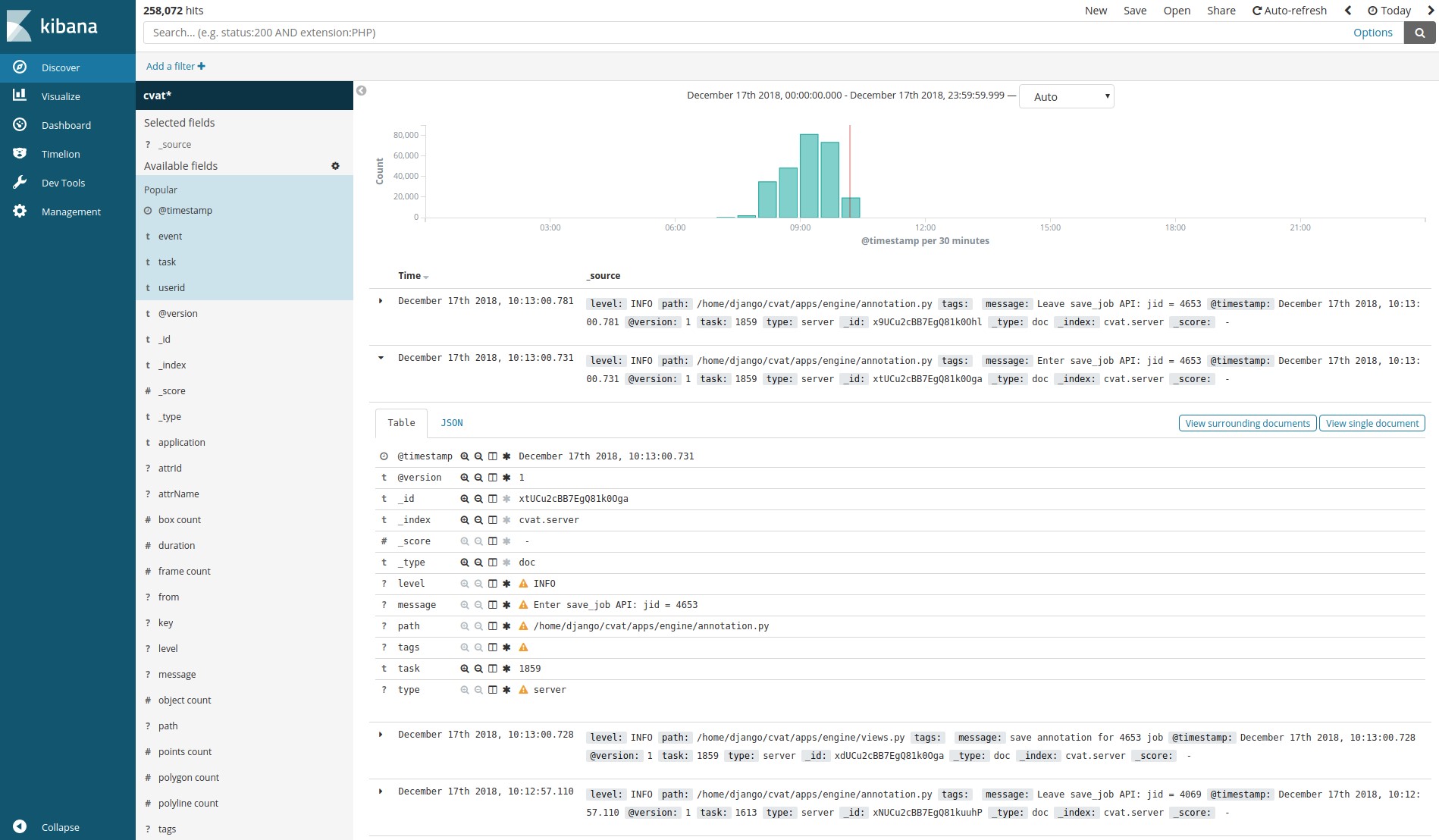
Logstash, Elasticsearch, Kibana -
Ermöglichen die Visualisierung und Analyse der von Kunden gesammelten Protokolle. Dies kann beispielsweise verwendet werden, um den Markup-Prozess zu überwachen oder nach Fehlern und deren Ursachen zu suchen.
 NVIDIA CUDA Toolkit
NVIDIA CUDA Toolkit - eine Reihe von Tools zum Durchführen von Berechnungen auf dem Grafikprozessor (GPU). Es kann verwendet werden, um das automatische Layout mit der TF OD-API oder in anderen benutzerdefinierten Add-Ons zu beschleunigen.
Datenmarkup
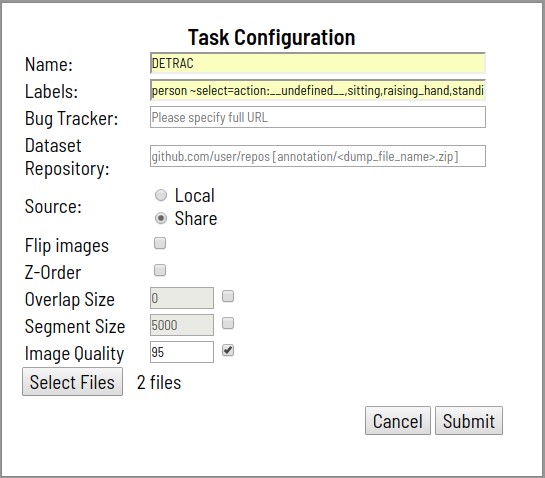
- Der Prozess beginnt mit der Angabe des Problems für das Layout. Die Inszenierung beinhaltet:
- Angeben eines Aufgabennamens
- Aufzählung der zu markierenden Klassen und ihrer Attribute
- Angeben von Dateien zum Herunterladen
- Daten werden vom lokalen Dateisystem oder von einem verteilten Dateisystem heruntergeladen, das in einem Container bereitgestellt ist
- Eine Aufgabe kann ein Archiv mit Bildern, ein Video, eine Reihe von Bildern und sogar eine Verzeichnisstruktur mit Bildern enthalten, wenn sie über einen verteilten Speicher heruntergeladen wird
- Optional einstellen:
- Link zu detaillierten Markup-Spezifikationen sowie weiteren zusätzlichen Informationen (Bug Tracker)
- Link zu einem Remote-Git-Repository zum Speichern von Anmerkungen (Dataset Repository)
- Alle Bilder um 180 Grad drehen (Bilder spiegeln)
- Ebenenunterstützung für Segmentierungsaufgaben (Z-Reihenfolge)
- Segmentgröße Eine herunterladbare Aufgabe kann für paralleles Arbeiten in mehrere Unteraufgaben unterteilt werden
- Segmentschnittbereich (Überlappung). Wird im Video verwendet, um Anmerkungen in verschiedenen Segmenten zusammenzuführen
- Qualitätsstufe beim Konvertieren von Bildern (Bildqualität)
- Nach der Verarbeitung der Anforderung wird die erstellte Aufgabe in der Aufgabenliste angezeigt.

- Jeder der Links im Abschnitt Jobs entspricht einem Segment. In diesem Fall wurde die Aufgabe zuvor nicht segmentiert. Durch Klicken auf einen der Links wird die Markup-Seite geöffnet.

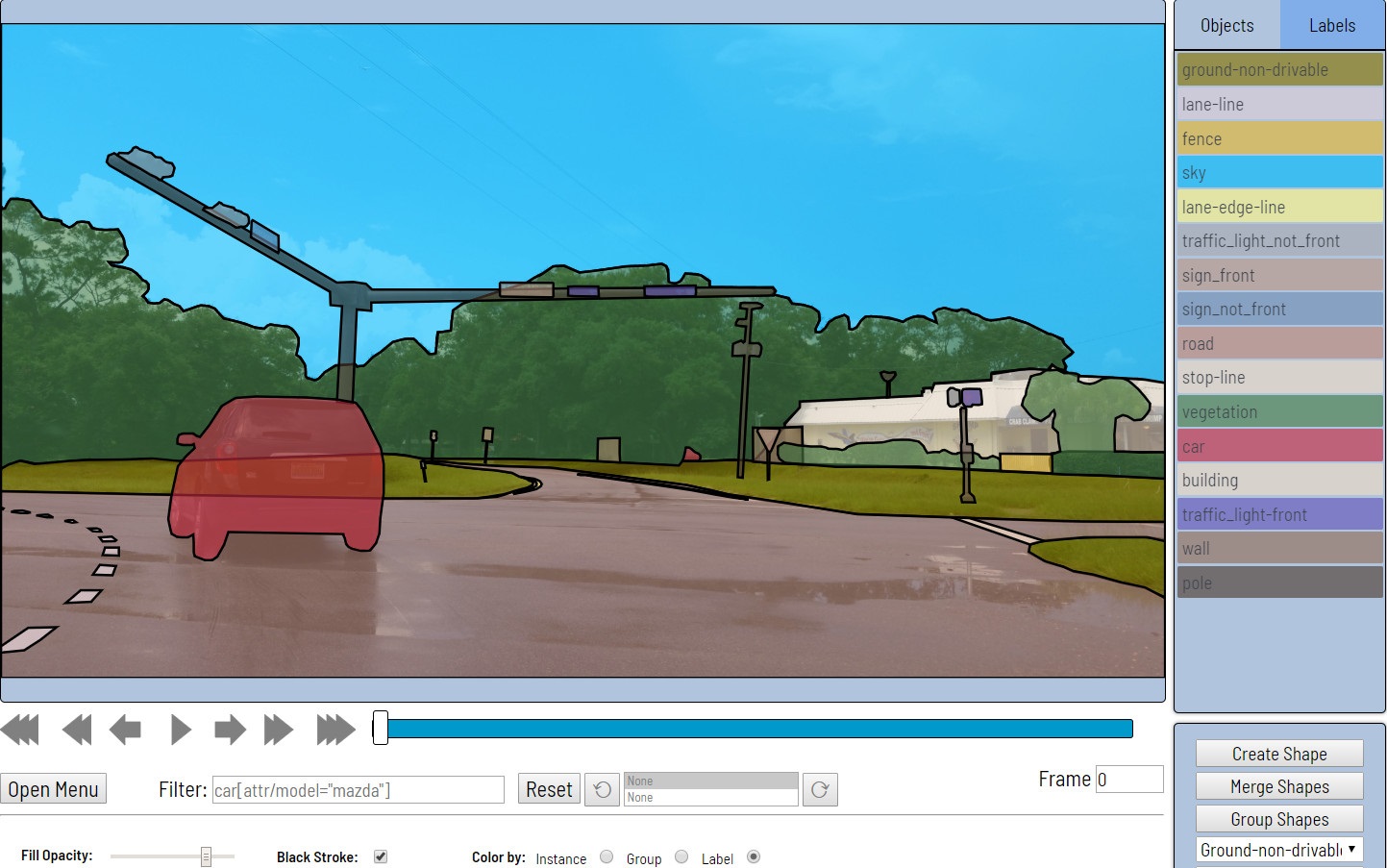
- Als nächstes werden die Daten direkt markiert. Rechtecke, Polygone (hauptsächlich für Segmentierungsaufgaben), Polylinien (können beispielsweise zur Straßenmarkierung nützlich sein) und viele Punkte (z. B. zum Markieren von Landmarken oder zur Posenschätzung) werden als Grundelemente bereitgestellt.
Es stehen auch verschiedene Automatisierungstools zur Verfügung (Kopieren, Multiplizieren mit anderen Frames, Interpolation, vorläufige Markierung mit der TF OD-API), visuelle Einstellungen, viele Tastenkombinationen, Suchen, Filtern und andere nützliche Funktionen. Im Einstellungsfenster können Sie eine Reihe von Parametern ändern, um das Arbeiten zu vereinfachen.
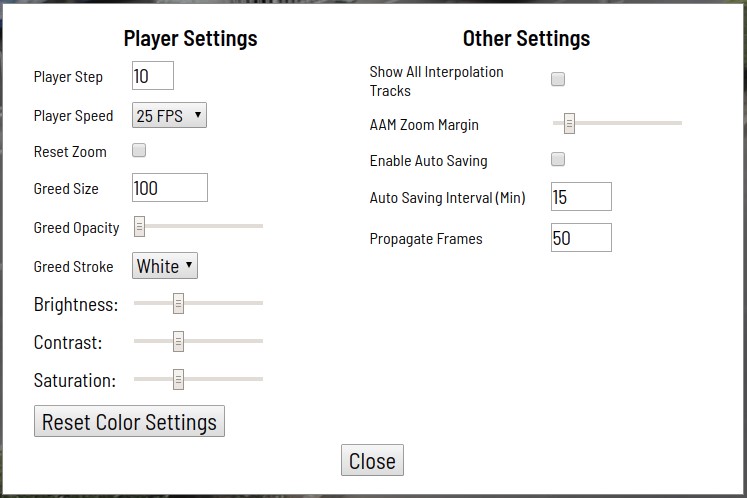
Das Hilfedialogfeld enthält viele unterstützte Tastaturkürzel und einige andere Tipps.

Der Markup-Prozess ist in den folgenden Beispielen dargestellt.
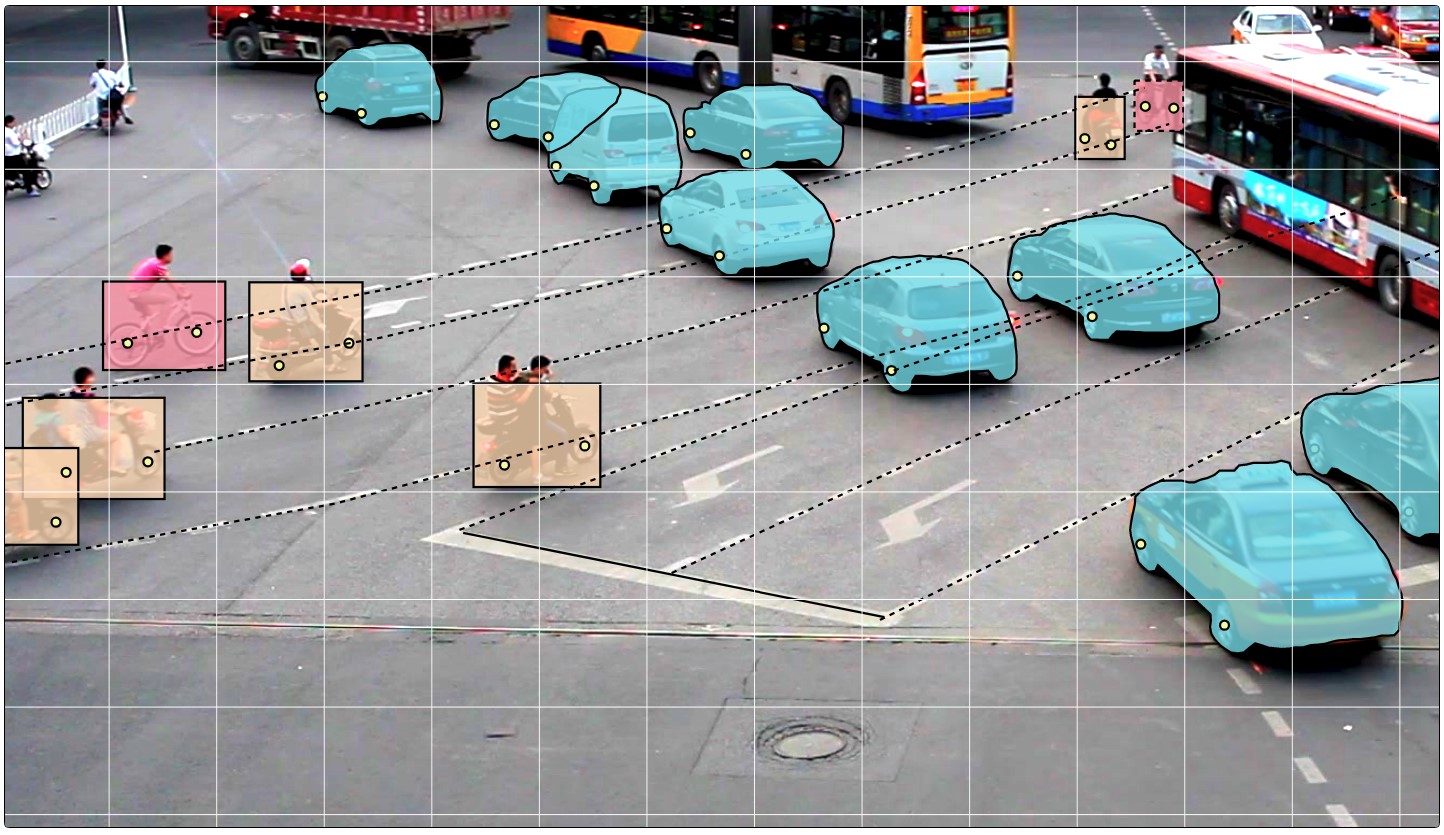
CVAT kann Rechtecke und Attribute zwischen Keyframes in einem Video linear interpolieren. Aus diesem Grund wird die Anmerkung auf dem Framesatz automatisch angezeigt.
Der Attributanmerkungsmodus wurde für das Klassifizierungsszenario entwickelt, mit dem Sie die Annotation von Attributen beschleunigen können, indem Sie das Markup auf eine bestimmte Eigenschaft konzentrieren. Zusätzlich erfolgt das Markup hier durch die Verwendung von "Hotkeys".
Polygone unterstützen Skripte für semantische Segmentierung und Instanzsegmentierung. Unterschiedliche visuelle Einstellungen erleichtern den Validierungsprozess.
- Anmerkung erhalten
Durch Drücken der Schaltfläche "Dump Annotation" wird die Vorbereitung und das Laden von Markup-Ergebnissen als einzelne Datei gestartet. Eine Anmerkungsdatei ist eine angegebene XML- Datei, die einige Aufgabenmetadaten und die gesamte Anmerkung enthält. Das Markup kann direkt in das Git-Repository heruntergeladen werden, wenn dieses bei der Erstellung der Aufgabe verbunden war.
Geschichte und Evolution
Anfangs hatten wir keine Vereinheitlichung, und jede Markup-Aufgabe wurde mit eigenen Tools ausgeführt, die hauptsächlich in C ++ unter Verwendung der
OpenCV-Bibliothek geschrieben wurden . Diese Tools wurden lokal auf Endbenutzercomputern installiert, es gab keinen Mechanismus zum Teilen von Daten, eine gemeinsame Pipeline zum Festlegen und Markieren von Aufgaben, viele Dinge mussten manuell erledigt werden.
Der Ausgangspunkt der CVAT-Historie kann als Ende 2016 angesehen werden, als
Vatic als Layout-Tool eingeführt wurde, dessen Benutzeroberfläche im Folgenden vorgestellt wird. Vatic war Open Source und führte einige großartige allgemeine Ideen ein, z. B. das Interpolieren von Markups zwischen Keyframes in einer Video- oder Client-Server-Anwendungsarchitektur. Im Allgemeinen bot es jedoch eher bescheidene Markup-Funktionen, und wir haben viel selbst gearbeitet.
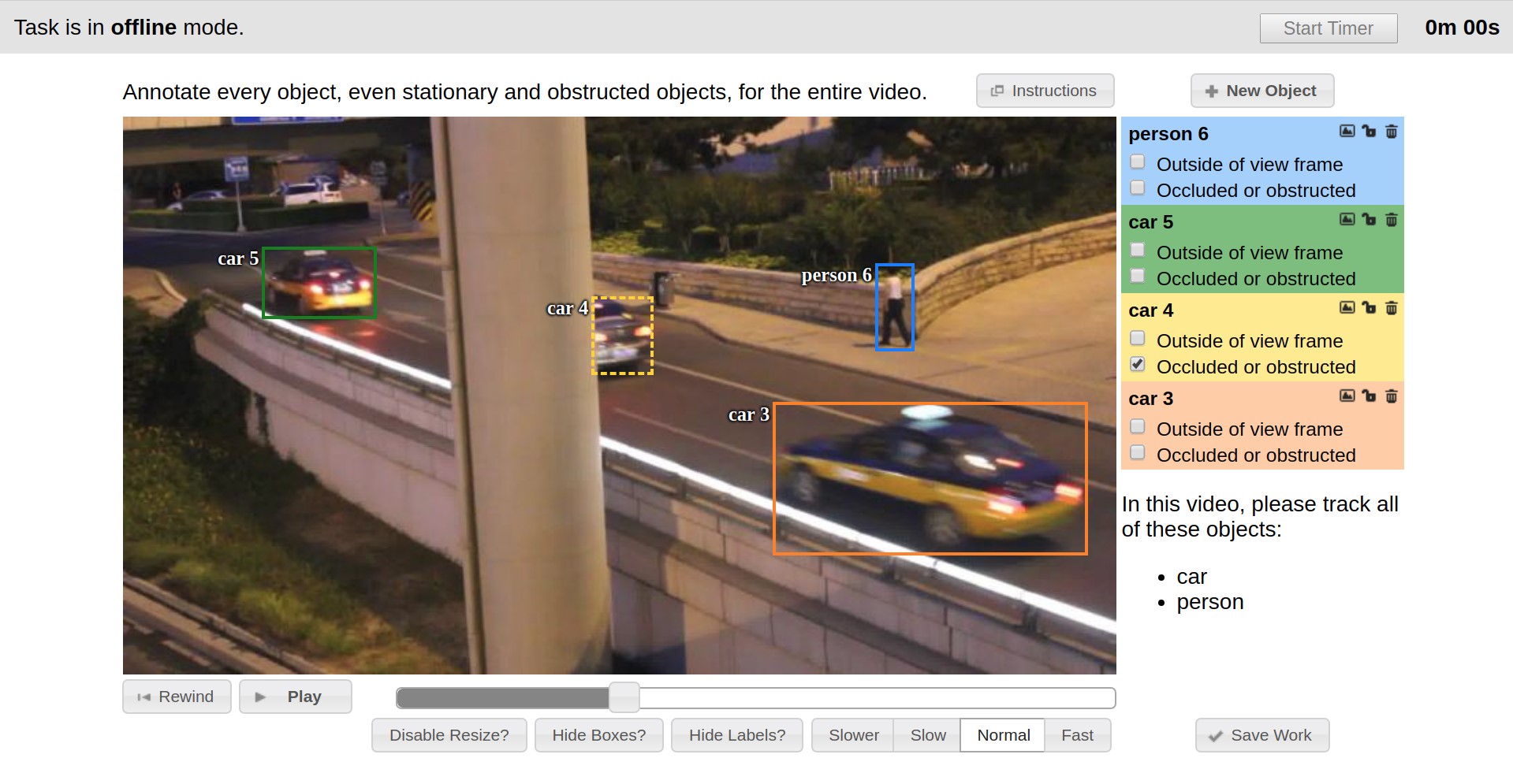
So wurde beispielsweise in den ersten sechs Monaten die Möglichkeit zum Kommentieren von Bildern implementiert, Benutzerattribute von Objekten hinzugefügt, eine Seite mit einer Liste vorhandener Aufgaben entwickelt und die Möglichkeit, neue Aufgaben über die Weboberfläche hinzuzufügen.
In der zweiten Jahreshälfte 2017 haben wir die Tensorflow-Objekterkennungs-API eingeführt, um ein vorläufiges Markup zu erhalten. Es gab viele kleinere Verbesserungen am Kunden, aber am Ende waren wir mit der Tatsache konfrontiert, dass der Client-Teil sehr langsam zu arbeiten begann. Tatsache war, dass die Größe der Aufgaben zunahm, die Zeit ihres Öffnens proportional zur Anzahl der Frames und markierten Daten zunahm, die Benutzeroberfläche aufgrund der ineffizienten Darstellung markierter Objekte langsamer wurde und der Fortschritt im Laufe der Arbeitsstunden häufig verloren ging. Die Produktivität sank hauptsächlich bei Aufgaben mit Bildern, da die Grundlage der damaligen Architektur ursprünglich für die Arbeit mit Videos ausgelegt war. Es bestand Bedarf an einer vollständigen Änderung der Client-Architektur, mit der wir erfolgreich fertig wurden. Die meisten Leistungsprobleme waren zu dieser Zeit weg. Das Webinterface ist viel schneller und stabiler geworden. Das Markieren größerer Aufgaben ist möglich geworden. Im gleichen Zeitraum wurde versucht, Unit-Tests einzuführen, um die Automatisierung von Überprüfungen während Änderungen in gewissem Maße zu automatisieren. Diese Aufgabe wurde nicht so erfolgreich gelöst. Wir haben QUnit, Karma und Headless Chrome im Docker-Container konfiguriert, einige Tests geschrieben und dies alles auf CI gestartet. Ein großer Teil des Codes blieb und bleibt jedoch durch Tests freigelegt. Eine weitere Neuerung war ein System zur Protokollierung von Benutzeraktionen mit anschließender Suche und Visualisierung auf der Basis von ELK Stack. Sie können den Prozess von Annotatoren überwachen und nach Aktionsszenarien suchen, die zu Software-Ausnahmen führen.
Im ersten Halbjahr 2018 haben wir unsere Kundenfunktionalität erweitert. Der Attribut-Anmerkungsmodus wurde hinzugefügt, der ein effektives Skript zum Markieren von Attributen implementiert, dessen Idee wir von Kollegen ausgeliehen und verallgemeinert haben. Jetzt können Sie Objekte nach einer Reihe von Zeichen filtern, einen gemeinsamen Speicher zum Herunterladen von Daten anschließen, wenn Sie Aufgaben mit der Anzeige über einen Browser festlegen, und viele andere. Die Aufgaben wurden umfangreicher und es traten wieder Leistungsprobleme auf, aber diesmal war der Serverteil der Engpass. Das Problem mit Vatic war, dass es viel selbstgeschriebenen Code für Aufgaben enthielt, die mit vorgefertigten Lösungen einfacher und effizienter gelöst werden konnten. Also haben wir uns entschlossen, die Serverseite zu wiederholen. Wir haben Django als Server-Framework ausgewählt, vor allem wegen seiner Beliebtheit und der Verfügbarkeit vieler Dinge, wie sie sagen, sofort. Nach der Änderung des Serverteils, als von Vatic nichts mehr übrig war, haben wir festgestellt, dass wir bereits eine Menge Arbeit geleistet haben, die mit der Community geteilt werden kann. Also wurde beschlossen, auf Open Source umzusteigen. Die Erlaubnis dafür in einem großen Unternehmen zu erhalten, ist ein ziemlich heikler Prozess. Hierfür gibt es eine große Liste von Anforderungen. Einschließlich war es notwendig, einen Namen zu finden. Wir haben Optionen skizziert und eine Reihe von Umfragen unter Kollegen durchgeführt. Infolgedessen wurde unser internes Tool CVAT genannt, und am 29. Juni 2018 wurde der Quellcode auf
GitHub in der OpenCV-Organisation unter der MIT-Lizenz und mit der ursprünglichen Version 0.1.0 veröffentlicht. Die Weiterentwicklung erfolgte in einem öffentlichen Repository.
Ende September 2018 wurde die Hauptversion 0.2.0 veröffentlicht. Es gab viele kleine Änderungen und Korrekturen, aber das Hauptaugenmerk lag auf der Unterstützung neuer Arten von Anmerkungen. So erschien eine Reihe von Werkzeugen zum Markieren und Validieren der Segmentierung sowie die Möglichkeit, mit Polylinien oder Punkten zu kommentieren.
Die nächste Veröffentlichung ist wie ein Weihnachtsgeschenk für den 31. Dezember 2018 geplant. Die wichtigsten Punkte hierbei sind die optionale Integration des Deep Learning Deployment Toolkit als Teil von OpenVINO, mit dem der Start der TF OD-API ohne NVIDIA-Grafikkarte beschleunigt wird. Benutzerprotokoll-Analysesystem, das zuvor in der öffentlichen Version nicht verfügbar war; viele Verbesserungen auf der Client-Seite.
Wir haben die bisherige CVAT-Historie (Dezember 2018) zusammengefasst und die wichtigsten Ereignisse überprüft. Weitere
Informationen zum Änderungsverlauf finden Sie im
Änderungsprotokoll .
Internes Gerät
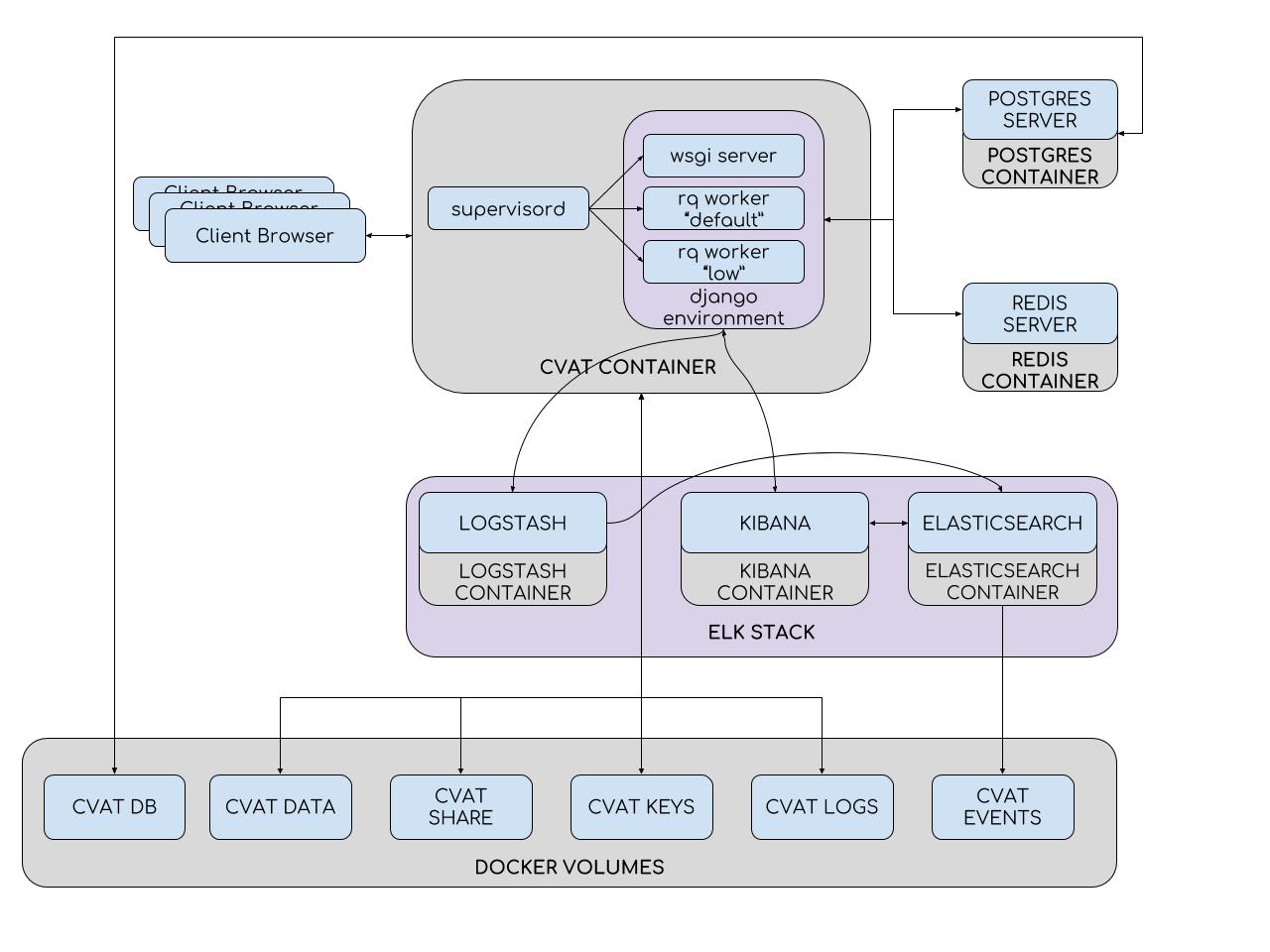
Um die Installation und Bereitstellung zu vereinfachen, verwendet CVAT Docker-Container. Das System besteht aus mehreren Containern. Im CVAT-Container wird ein Supervisord-Prozess ausgeführt, der mehrere Python-Prozesse in der Django-Umgebung erzeugt. Einer davon ist der wsgi-Server, der Client-Anfragen verarbeitet. Andere Prozesse, RQ-Worker, werden verwendet, um „lange“ Aufgaben aus den Redis-Warteschlangen zu verarbeiten: Standard und Niedrig. Zu diesen Aufgaben gehören Aufgaben, die nicht innerhalb einer einzelnen Benutzeranforderung verarbeitet werden können (Festlegen einer Aufgabe, Vorbereiten einer Anmerkungsdatei, Markup mit der TF OD-API usw.). Die Anzahl der Worker kann in der Supervisord-Konfigurationsdatei konfiguriert werden.
Die Django-Umgebung interagiert mit zwei Datenbankservern. Der Redis-Server speichert den Status von Aufgabenwarteschlangen, und die CVAT-Datenbank enthält alle Informationen zu Aufgaben, Benutzern, Anmerkungen usw. PostgreSQL (und SQLite 3 in Entwicklung) wird als DBMS für CVAT verwendet. Alle Daten werden auf einer steckbaren Partition (cvat db volume) gespeichert. Abschnitte werden verwendet, in denen Datenverluste beim Aktualisieren des Containers vermieden werden müssen. Somit sind im CVAT-Container Folgendes montiert:
- Abschnitt mit Videos und Bildern (cvat-Datenvolumen)
- Abschnitt mit Schlüsseln (cvat keys volume)
- Abschnitt mit Protokollen (cvat logs volume)
- Freigegebener Dateispeicher (freigegebenes cvat-Volume)
Das Analysesystem besteht aus Elasticsearch, Logstash und Kibana, die in Docker-Containern verpackt sind. Beim Speichern der Arbeit auf dem Client werden alle Daten, einschließlich der Protokolle, auf den Server übertragen. Der Server sendet sie wiederum zur Filterung an Logstash. Darüber hinaus besteht die Möglichkeit, Benachrichtigungen automatisch an E-Mails zu senden, wenn Fehler auftreten. Als nächstes fallen die Protokolle in Elasticsearch. Letzteres speichert sie auf einer steckbaren Partition (cvat events volume). Anschließend kann der Benutzer die Kibana-Oberfläche verwenden, um Statistiken und Protokolle anzuzeigen. Gleichzeitig wird Kibana aktiv mit Elasticsearch interagieren.
Auf der Quellenebene besteht CVAT aus vielen Django-Anwendungen:
- Authentifizierung - Authentifizierung von Benutzern im System (Basic und LDAP)
- Engine - eine Schlüsselanwendung (grundlegende Datenbankmodelle; Laden und Speichern von Aufgaben; Laden und Entladen von Anmerkungen; Markup-Client-Schnittstelle; Server-Schnittstelle zum Erstellen, Ändern und Löschen von Aufgaben)
- Dashboard - Client-Oberfläche zum Erstellen, Bearbeiten, Suchen und Löschen von Aufgaben
- Dokumentation - Anzeige der Benutzerdokumentation in der Client-Oberfläche
- tf_annotation - automatische Annotation mit der Tensorflow Object Detection API
- log_viewer - Senden von Protokollen vom Client an Logstash beim Speichern einer Aufgabe
- log_proxy - CVAT-Proxy-Verbindung → Kibana
- git - Git-Repository-Integration zum Speichern von Anmerkungen
Wir bemühen uns, ein Projekt mit einer flexiblen Struktur zu erstellen. Aus diesem Grund haben optionale Anwendungen keine Hardcode-Einbettung. Leider haben wir zwar keinen idealen Prototyp des Plug-In-Systems, aber mit der Entwicklung neuer Anwendungen verbessert sich die Situation hier allmählich.
Der Client-Teil ist in JavaScript- und Django-Vorlagen implementiert. JavaScript , , - ( ) model-view-controller. , (, , ) , . ( - UI), (, , : , , models, views controllers).
open source, . , . . , CVAT. , , . :
- CVAT , , , , . UI .
- . , .
- , . , .
- . deep learning , . , Deep Learning Deployment Toolkit OpenVINO - . , . , .
- demo- CVAT, , , . demo- Onepanel, CVAT .
- Amazon Mechanical Turk CVAT . SDK .
, . , , . open source . – , .
, PR . , ,
Gitter . , ! Viel Glück an alle!
Referenzen