
In früheren Artikeln habe ich versucht, über die Grundlagen der Preisgestaltung und die Erstellung eines Kundenentscheidungsbaums für den klassischen Einzelhandel zu sprechen. In diesem Artikel werde ich Ihnen von einem sehr ungewöhnlichen Fall erzählen und versuchen, Sie davon zu überzeugen, dass die Verwendung von maschinellem Lernen nicht so schwierig ist, wie es scheint. Der Artikel ist weniger technisch und zeigt eher, dass Sie klein anfangen können, was dem Unternehmen bereits greifbare Vorteile bringt.
Anfängliches Problem
Auf unserem Kontinent gibt es eine Ladenkette, die ihr Sortiment einmal pro Woche wechselt. Beispielsweise werden zuerst Overlocks und dann Herren-Sportbekleidung verkauft. Alle nicht verkauften Waren werden in die Lager geschickt und sechs Monate später wieder in die Läden zurückgebracht. Gleichzeitig hat das Geschäft etwa 6 verschiedene Warengruppen. Das heißt, Das Sortiment der Geschäfte für jede Woche ist wie folgt:
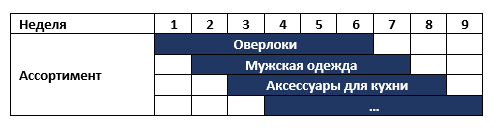
Das Netzwerk forderte ein Sortimentsplanungssystem mit der Voraussetzung für die analytische Entscheidungsunterstützung für Kategoriemanager an. Nach einem Gespräch mit dem Unternehmen haben wir zwei sehr schnelle potenzielle Lösungen vorgeschlagen, die während der Bereitstellung des Planungssystems zu Ergebnissen führen können:
- Verkauf von Waren, die während des Hauptverkaufs nicht verkauft werden
- Verbesserung der Genauigkeit der Bedarfsprognose in Geschäften
Der erste Punkt des Kunden war nicht zufrieden - das Unternehmen ist stolz darauf, dass es keine Verkäufe arrangiert und eine konstante Marge beibehält. Gleichzeitig werden enorme Geldbeträge für die Logistik und Lagerung von Waren ausgegeben. Infolgedessen wurde beschlossen, die Genauigkeit der Bedarfsprognose für eine genauere Verteilung von Filialen und Lagern zu verbessern.
Aktueller Prozess
Aufgrund der Art des Geschäfts wird nicht jedes einzelne Produkt lange Zeit verkauft und es ist problematisch, genügend Historie für die klassische Analyse zu erhalten. Der aktuelle Prognoseprozess ist sehr einfach und wie folgt strukturiert - einige Wochen vor Beginn der Hauptverkäufe in einem kleinen Teil der Filialen beginnen die Testverkäufe. Basierend auf den Ergebnissen der Testverkäufe wird beschlossen, Waren in das gesamte Netzwerk einzuführen, und es wird davon ausgegangen, dass jedes Geschäft im Durchschnitt so viel verkauft, wie es in Testgeschäften verkauft wurde.
Als wir beim Kunden ankamen, analysierten wir die aktuellen Daten, erkannten, was passierte, und boten eine sehr einfache Lösung an, um die Genauigkeit der Prognose zu verbessern.
Daten analysieren
Aus den Daten, die uns zur Verfügung gestellt wurden:
- Transaktionsverlauf für 1 Jahr und 2 Monate
- Produkthierarchie für die Planung. Leider fehlten die Eigenschaften der Waren fast vollständig, aber dazu später mehr
- Informationen zu Reichweite und Preisen für bestimmte Wochen
- Informationen zu den Städten, in denen sich die Geschäfte befinden
Wir konnten in kurzer Zeit keine Informationen über Salden entladen, was für diese Art der Analyse von entscheidender Bedeutung ist (wenn Sie diese Informationen nicht speichern, beginnen Sie). Daher haben wir in Zukunft davon ausgegangen, dass sich die Waren in den Regalen befinden und es keinen Mangel an Waren gibt.
Sofort trennten wir 2 Monate in eine Testprobe, um die Ergebnisse zu demonstrieren. Dann haben wir alle verfügbaren Daten in einem großen Schaufenster zusammengefasst und sie von Retouren und seltsamen Verkäufen befreit (zum Beispiel beträgt der Scheckbetrag 0,51 pro Warenstück). Es dauerte mehrere Tage. Nach der Vorbereitung der Vitrine haben wir uns den Verkauf von Waren [Einheiten] auf höchster Ebene angesehen und das folgende Bild gesehen:
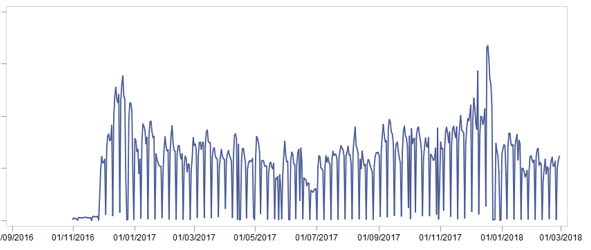
Wie kann uns dieses Bild helfen? .. Aber mit was:
- Offensichtlich gibt es Saisonalität - der Umsatz am Jahresende ist höher als in der Mitte
- Es gibt Saisonalität innerhalb des Monats - in der Mitte des Monats sind die Verkäufe höher als am Anfang und am Ende
- Es gibt Saisonalität innerhalb der Woche - es ist nicht so interessant, weil Infolgedessen wurde die Prognose nach Wochen erstellt
Die beschriebenen Punkte bestätigten das Geschäft. Dies sind aber auch großartige Funktionen, um die Prognose zu verbessern! Bevor wir sie dem Prognosemodell hinzufügen, sollten wir uns überlegen, welche anderen Merkmale des Umsatzes berücksichtigt werden sollten ... „Offensichtliche“ Ideen kommen mir in den Sinn:
- Der Umsatz variiert im Durchschnitt zwischen verschiedenen Produktgruppen
- Die Verkäufe variieren zwischen verschiedenen Geschäften
- (Ähnlich wie im vorherigen Absatz) Die Verkäufe variieren zwischen verschiedenen Städten
- (Weniger offensichtliche Idee) Aufgrund der Besonderheiten des Geschäfts ist die folgende Beziehung sichtbar: Wenn das zukünftige und das vorherige Sortiment ähnlich sind, ist der Umsatz des neuen Sortiments geringer.
Daraufhin haben wir beschlossen, anzuhalten und ein Modell zu bauen.
Im Rahmen der Konstruktion des Modells wurden alle gefundenen Merkmale in „Merkmale“ des Modells übersetzt. Hier ist die Liste der als Ergebnis verwendeten Funktionen:
- aktuelle Prognose, d.h. Durchschnittlicher Umsatz von Testgeschäften in [Einheiten], verteilt auf alle Geschäfte
- Monatsnummer und Wochennummer im Monat
- Alle kategorialen Variablen (Stadt, Geschäft, Produktkategorien) wurden mit geglätteter Wahrscheinlichkeit codiert (nützliche Technik - wer sie noch nicht verwendet, verwendet sie)
- berechnete Verzögerung 4 durchschnittliche Verkäufe von Produktkategorien. Das heißt, Wenn das Unternehmen plant, ein blaues T-Shirt zu verkaufen, wurde eine Verzögerung des durchschnittlichen Umsatzes der T-Shirt-Kategorie berechnet
ABT erwies sich als einfach, jeder Parameter war für das Unternehmen verständlich und verursachte keine Missverständnisse oder Ablehnungen. Dann war es notwendig zu verstehen, wie wir die Qualität der Prognose vergleichen werden.
Metrische Auswahl
Der Kunde hat die aktuelle Prognosegenauigkeit anhand der MAPE- Metrik gemessen. Die Metrik ist beliebt und einfach, hat jedoch bestimmte Nachteile bei der Prognose der Nachfrage. Tatsache ist, dass bei Verwendung von MAPE die Prognosetypfehler den größten Einfluss auf den endgültigen Indikator haben:

Ein relativer Prognosefehler von 900% - es scheint groß zu sein, aber schauen wir uns die Verkäufe eines anderen Produkts an:

Der relative Prognosefehler beträgt 33%, was viel weniger als 900% ist, aber die absolute Abweichung der Abweichung von 100 [Einheiten] ist für das Geschäft viel wichtiger als die Abweichung von 18 [Einheiten]. Um diese Funktionen zu berücksichtigen, können Sie Ihre eigenen interessanten Kennzahlen erstellen oder eine andere beliebte Kennzahl für die Bedarfsprognose verwenden - WAPE . Diese Maßnahme verleiht Waren mit höherem Umsatz mehr Gewicht, was für die Aufgabe großartig ist.
Wir haben dem Unternehmen verschiedene Ansätze zur Messung von Prognosefehlern vorgestellt, und der Kunde stimmte bereitwillig zu, dass die Verwendung von WAPE bei dieser Aufgabe sinnvoller ist. Danach haben wir Random Forest fast ohne Optimierung der Hyperparameter gestartet und die folgenden Ergebnisse erzielt.
Ergebnisse
Nach der Vorhersage des Testzeitraums haben wir die vorhergesagten Werte mit den tatsächlichen sowie mit der Prognose des Unternehmens verglichen. Infolgedessen verringerte sich MAPE um mehr als 15%, WAPE um mehr als 10% . Nachdem die Auswirkungen der verbesserten Prognose auf die Geschäftsindikatoren berechnet wurden, wurde eine Kostensenkung um einen relativ großen Betrag von Millionen Dollar erzielt.
1 Woche wurde für die ganze Arbeit aufgewendet!
Weitere Schritte
Als Bonus für den Kunden haben wir ein kleines DQ- Experiment durchgeführt. Für eine Produktgruppe haben wir aus den Produktnamen die Merkmale (Farbe, Produkttyp, Zusammensetzung usw.) analysiert und der Prognose hinzugefügt. Das Ergebnis war inspirierend - in dieser Kategorie verbesserten sich beide Fehlermaßnahmen um weitere mehr als 8%.
Als Ergebnis erhielt der Kunde eine Beschreibung der einzelnen Merkmale, Modellparameter und Montageparameter des ABT-Schaufensters und beschrieb weitere Schritte zur Verbesserung der Prognose (Verwendung historischer Daten für mehr als ein Jahr; Verwendung von Salden; Verwendung der Merkmale der Waren usw.).
Fazit
Während einer Woche Zusammenarbeit mit dem Kunden war es möglich, die Genauigkeit der Prognose erheblich zu erhöhen, ohne den Geschäftsprozess praktisch zu verändern.
Sicherlich denken viele Leute jetzt, dass dieser Fall sehr einfach ist und sie können mit diesem Ansatz im Unternehmen nicht durchkommen. Die Erfahrung zeigt, dass es fast immer Orte gibt, an denen nur Grundannahmen und Expertenmeinungen verwendet werden. An diesen Stellen können Sie mit dem maschinellen Lernen beginnen. Dazu müssen Sie die Daten sorgfältig vorbereiten und studieren, mit dem Unternehmen sprechen und versuchen, beliebte Modelle anzuwenden, für die keine lange Abstimmung erforderlich ist. Und Stapeln, Einbetten von Funktionen, komplexe Modelle - das ist alles für später. Ich hoffe, ich habe Sie überzeugt, dass es nicht so schwierig ist, wie es scheinen mag. Sie müssen nur ein wenig nachdenken und keine Angst haben, anzufangen.
Haben Sie keine Angst vor maschinellem Lernen, suchen Sie nach Orten, an denen es in Prozessen verwendet werden kann, haben Sie keine Angst, Ihre Daten zu recherchieren, und lassen Sie Berater zu ihnen kommen und coole Ergebnisse erzielen.
PS Wir rekrutieren junge Studenten aus Padawan für Einzelhandelspraktika unter Anleitung erfahrener Jedi. Zu Beginn reichen gesunder Menschenverstand und SQL-Kenntnisse aus, wir werden den Rest lehren. Sie können sich zu einem Geschäftsexperten oder technischen Berater entwickeln, je nachdem, was interessanter ist. Wenn es Interesse oder Empfehlungen gibt - schreiben Sie in einem persönlichen