Der zweite Artikel aus der Reihe "Testgesteuerte Entwicklung von Anwendungen auf Spring Boot" und dieses Mal werde ich über das Testen des Datenbankzugriffs sprechen, ein wichtiger Aspekt des Integrationstests. Ich werde Ihnen erklären, wie Sie die Schnittstelle eines zukünftigen Dienstes für den Datenzugriff durch Tests bestimmen, integrierte Speicherdatenbanken zum Testen verwenden, mit Transaktionen arbeiten und Testdaten in die Datenbank hochladen.
Ich werde nicht viel über TDD und das Testen im Allgemeinen sprechen. Ich lade alle ein, den ersten Artikel zu lesen - Wie man eine Pyramide im Kofferraum baut oder wie man Anwendungen im Spring Boot / Geek-Magazin testgetrieben entwickelt
Ich werde wie beim letzten Mal mit einem kleinen theoretischen Teil beginnen und zum End-to-End-Test übergehen.
Pyramide testen
Zunächst eine kleine, aber notwendige Beschreibung einer so wichtigen Entität beim Testen wie der Testpyramide oder der Testpyramide .
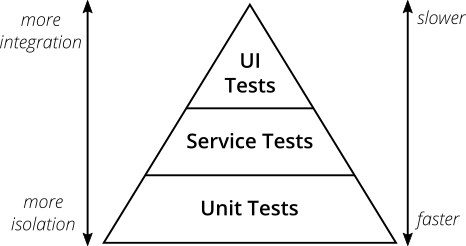
(entnommen aus der praktischen Testpyramide )
Die Testpyramide ist der Ansatz, wenn Tests auf mehreren Ebenen organisiert werden.
- UI -Tests (oder End-to-End- E2E- Tests) gibt es nur wenige und sie sind langsam, aber sie testen die reale Anwendung - keine Verspottungen und Testgegenstücke. Unternehmen denken oft auf dieser Ebene und alle BDD-Frameworks leben hier (siehe Gurke in einem vorherigen Artikel).
- Es folgen Integrationstests (Service, Komponente - jede hat ihre eigene Terminologie), die sich bereits auf eine bestimmte Komponente (Service) des Systems konzentrieren und diese durch Moki / Doubles von anderen Komponenten isolieren, aber dennoch die Integration mit realen externen Systemen überprüfen. Diese Tests sind miteinander verbunden an die Datenbank, REST-Anfragen senden, arbeite ich mit einer Nachrichtenwarteschlange. In der Tat sind dies Tests, die die Integration der Geschäftslogik in die Außenwelt verifizieren.
- Ganz unten befinden sich schnelle Komponententests , bei denen die minimalen Codeblöcke (Klassen, Methoden) vollständig isoliert getestet werden.
Spring hilft beim Schreiben von Tests für jedes Level - auch für Unit-Tests , obwohl dies seltsam klingen mag, da in der Welt der Unit-Tests überhaupt kein Wissen über das Framework vorhanden sein sollte. Nachdem ich den E2E-Test geschrieben habe, werde ich nur zeigen, wie Spring es auch solchen rein „integrationsbezogenen“ Dingen wie Controllern ermöglicht, isoliert zu testen.
Aber ich werde ganz oben in der Pyramide beginnen - dem langsamen UI-Test, der eine vollwertige Anwendung startet und testet.
End-to-End-Test
Also eine neue Funktion:
Feature: A list of available cakes Background: catalogue is updated Given the following items are promoted | Title | Price | | Red Velvet | 3.95 | | Victoria Sponge | 5.50 | Scenario: a user visiting the web-site sees the list of items Given a new user, Alice When she visits Cake Factory web-site Then she sees that "Red Velvet" is available with price £3.95 And she sees that "Victoria Sponge" is available with price £5.50
Und hier ist ein sofort interessanter Aspekt - was tun mit dem vorherigen Test über die Begrüßung auf der Hauptseite? Es scheint nicht mehr relevant zu sein, nach dem Start der Site auf der Hauptseite gibt es bereits ein Verzeichnis, keine Begrüßung. Es gibt keine einzige Antwort, würde ich sagen - es hängt von der Situation ab. Aber der wichtigste Rat - lassen Sie sich nicht auf die Tests ein! Löschen Sie, wenn sie an Relevanz verlieren, und schreiben Sie sie neu, um das Lesen zu erleichtern. Insbesondere E2E-Tests - dies sollte in der Tat eine lebendige und aktuelle Spezifikation sein . In meinem Fall habe ich nur die alten Tests gelöscht und durch neue ersetzt, wobei ich einige der vorherigen Schritte verwendet und nicht vorhandene hinzugefügt habe.
Jetzt bin ich an einem wichtigen Punkt angelangt - der Wahl der Technologie zum Speichern von Daten. In Übereinstimmung mit dem Lean- Ansatz möchte ich die Auswahl bis zum allerletzten Moment verschieben - wenn ich sicher weiß, ob das relationale Modell oder nicht, was die Anforderungen an Konsistenz und Transaktionsfähigkeit sind. Im Allgemeinen gibt es Lösungen dafür - zum Beispiel die Erstellung von Testzwillingen und verschiedenen In-Memory- Speichern, aber bisher möchte ich den Artikel nicht komplizieren und sofort die Technologie auswählen - relationale Datenbanken. Um jedoch zumindest die Möglichkeit zu bewahren, eine Datenbank auszuwählen, werde ich eine Abstraktion hinzufügen - Spring Data JPA . JPA selbst ist eine ziemlich abstrakte Spezifikation für den Zugriff auf relationale Datenbanken, und Spring Data macht die Verwendung noch einfacher.
Spring Data JPA verwendet standardmäßig Hibernate als Anbieter, unterstützt jedoch auch andere Technologien wie EclipseLink und MyBatis. Für Leute, die mit der Java Persistence API nicht sehr vertraut sind - JPA ist wie eine Schnittstelle, und Hibernate ist eine Klasse, die sie implementiert.
Um die JPA-Unterstützung hinzuzufügen, habe ich einige Abhängigkeiten hinzugefügt:
implementation('org.springframework.boot:spring-boot-starter-data-jpa') runtime('com.h2database:h2')
Als Datenbank werde ich H2 verwenden - eine in Java geschriebene eingebettete Datenbank mit der Fähigkeit, im In-Memory-Modus zu arbeiten.
Mit Spring Data JPA definiere ich sofort eine Schnittstelle für den Zugriff auf Daten:
interface CakeRepository extends CrudRepository<CakeEntity, String> { }
Und die Essenz:
@Entity @Builder @AllArgsConstructor @Table(name = "cakes") class CakeEntity { public CakeEntity() { } @Id @GeneratedValue(strategy = GenerationType.IDENTITY) Long id; @NotBlank String title; @Positive BigDecimal price; @NotBlank @NaturalId String sku; boolean promoted; @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; CakeEntity cakeEntity = (CakeEntity) o; return Objects.equals(title, cakeEntity.title); } @Override public int hashCode() { return Objects.hash(title); } }
Die Beschreibung der Entität enthält einige weniger offensichtliche Dinge.
@NaturalId für das @NaturalId Feld. Dieses Feld wird als „natürlicher Bezeichner“ zum Überprüfen der Gleichheit von Entitäten verwendet. Die Verwendung aller Felder oder @Id Felder in equals / hashCode Methoden ist eher ein Anti-Pattern. Hier ist beispielsweise gut geschrieben, wie die Gleichheit von Entitäten korrekt überprüft werden kann .- Um den Boilerplate-Code ein wenig zu reduzieren, verwende ich Project Lombok - Annotation Processor für Java. Sie können verschiedene nützliche Dinge hinzufügen, z. B.
@Builder um automatisch einen Builder für die Klasse zu generieren, und @AllArgsConstructor , um einen Konstruktor für alle Felder zu erstellen.
Eine Schnittstellenimplementierung wird automatisch von Spring Data bereitgestellt.
Die Pyramide hinunter
Jetzt ist die Zeit gekommen, um zur nächsten Ebene der Pyramide zu gelangen. Als Faustregel würde ich empfehlen, immer mit dem e2e-Test zu beginnen , da Sie so das "Endziel" und die Grenzen der neuen Funktion bestimmen können, aber es gibt keine weiteren strengen Regeln. Es ist nicht erforderlich, zuerst einen Integrationstest zu schreiben, bevor Sie zur Einheitenebene wechseln. Es ist nur meistens so, dass es bequemer und einfacher ist - und es ist ganz natürlich, unterzugehen.
Aber gerade jetzt möchte ich diese Regel sofort brechen und einen Komponententest schreiben, der dabei hilft, die Schnittstelle und den Vertrag einer neuen Komponente zu bestimmen, die noch nicht existiert. Der Controller sollte ein Modell zurückgeben, das von einer bestimmten Komponente X ausgefüllt wird, und ich habe diesen Test geschrieben:
@ExtendWith(MockitoExtension.class) class IndexControllerTest { @Mock CakeFinder cakeFinder; @InjectMocks IndexController indexController; private Set<Cake> cakes = Set.of(new Cake("Test 1", "£10"), new Cake("Test 2", "£10")); @BeforeEach void setUp() { when(cakeFinder.findPromotedCakes()).thenReturn(cakes); } @Test void shouldReturnAListOfFoundPromotedCakes() { ModelAndView index = indexController.index(); assertThat(index.getModel()).extracting("cakes").contains(cakes); } }
Dies ist ein reiner Unit-Test - keine Kontexte, keine Datenbanken hier, nur Mockito für Mok. Und dieser Test ist nur eine gute Demonstration, wie Spring Unit-Tests hilft - der Controller in Spring MVC ist nur eine Klasse, deren Methoden Parameter gewöhnlicher Typen akzeptieren und POJO-Objekte zurückgeben - Modelle anzeigen . Es gibt keine HTTP-Anforderungen, keine Antworten, Header, JSON, XML - all dies wird automatisch in Form von Konvertern und Serialisierern auf den Stapel angewendet. Ja, es gibt einen kleinen "Hinweis" auf Spring in Form von ModelAndView , aber dies ist ein reguläres POJO, und Sie können es sogar entfernen, wenn Sie möchten, es wird speziell für UI-Controller benötigt.
Ich werde nicht viel über Mockito sprechen, Sie können alles in der offiziellen Dokumentation lesen. Insbesondere gibt es in diesem Test nur interessante Punkte - ich verwende MockitoExtension.class als Testläufer und es werden automatisch Mokas für von @Mock kommentierte Felder @Mock und diese Mokas dann als Abhängigkeiten in den Konstruktor für das Objekt in das mit @InjectMocks gekennzeichnete Feld @InjectMocks . Sie können dies alles manuell mit der Mockito.mock() -Methode tun und dann eine Klasse erstellen.
Mit diesem Test können Sie die Methode der neuen Komponente ermitteln - findPromotedCakes , eine Liste der Kuchen, die auf der Hauptseite findPromotedCakes sollen. Er bestimmt nicht, was es ist oder wie es mit der Datenbank funktionieren soll. Es liegt in der alleinigen Verantwortung des Controllers, das übertragene Material zu übernehmen und die Modelle ("Kuchen") in einem bestimmten Bereich zurückzugeben. Trotzdem hat CakeFinder bereits die erste Methode in meiner Oberfläche, was bedeutet, dass Sie einen Integrationstest dafür schreiben können.
Ich habe absichtlich alle Klassen innerhalb des cakes privat gemacht, damit niemand außerhalb des Pakets sie verwenden kann. Der einzige Weg, um Daten aus der Datenbank abzurufen, ist die CakeFinder-Schnittstelle, die meine „Komponente X“ für den Zugriff auf die Datenbank ist. Es wird zu einem natürlichen „Stecker“, den ich leicht einrasten kann, wenn ich etwas isoliert testen und die Basis nicht berühren muss. Die einzige Implementierung ist JpaCakeFinder. Wenn sich beispielsweise der Datenbanktyp oder die Datenquelle in Zukunft ändern, müssen Sie eine Implementierung der CakeFinder Schnittstelle CakeFinder , ohne den Code zu ändern, der sie verwendet.
Integrationstest für JPA mit @DataJpaTest
Integrationstests sind Frühlingsbrot und Butter. Tatsächlich wurde für Integrationstests alles so gut gemacht, dass Entwickler manchmal nicht auf die Einheitenebene wechseln oder die UI-Ebene vernachlässigen möchten. Das ist weder schlecht noch gut - ich wiederhole, dass das Hauptziel der Tests das Vertrauen ist. Eine Reihe schneller und effektiver Integrationstests kann ausreichen, um dieses Vertrauen zu schaffen. Es besteht jedoch die Gefahr, dass diese Tests im Laufe der Zeit entweder langsamer oder langsamer werden oder einfach mit dem isolierten Testen von Komponenten anstelle der Integration beginnen.
Integrationstests können die Anwendung @SpringBootTest ( @SpringBootTest ) oder ihre separate Komponente (JPA, Web) @SpringBootTest . In meinem Fall möchte ich einen gezielten Test für JPA schreiben, sodass ich keine Controller oder andere Komponenten konfigurieren muss. Die Annotation @DataJpaTest ist im Spring Boot Test dafür verantwortlich. Dies ist eine Meta- Annotation, d.h. Es kombiniert verschiedene Anmerkungen, die verschiedene Aspekte des Tests konfigurieren.
- @AutoConfigureDataJpa
- @AutoConfigureTestDatabase
- @AutoConfigureCache
- @AutoConfigureTestEntityManager
- @Transactional
Zuerst erzähle ich Ihnen jedes einzeln und dann zeige ich Ihnen den fertigen Test.
@AutoConfigureDataJpa
Es lädt eine ganze Reihe von Konfigurationen und richtet Repositorys (automatische Generierung von Implementierungen für CrudRepositories ) sowie Migrationstools für die FlyWay- und Liquibase-Datenbanken ein und stellt mithilfe von DataSource, Transaktionsmanager und schließlich Hibernate eine Verbindung zur Datenbank her. Tatsächlich handelt es sich hierbei nur um eine Reihe von Konfigurationen, die für den Zugriff auf Daten relevant sind. Weder DispatcherServlet von Web MVC noch andere Komponenten sind hier enthalten.
@AutoConfigureTestDatabase
Dies ist einer der interessantesten Aspekte des JPA-Tests. Diese Konfiguration durchsucht den Klassenpfad nach einer der unterstützten eingebetteten Datenbanken und konfiguriert den Kontext neu, sodass die DataSource auf eine zufällig erstellte speicherinterne Datenbank verweist . Da ich die Abhängigkeit zur H2-Basis hinzugefügt habe, muss ich nichts weiter tun. Nur diese Annotation automatisch für jeden Testlauf zu haben, ergibt eine leere Basis, und dies ist einfach unglaublich praktisch.
Es sei daran erinnert, dass diese Basis ohne Schema vollständig leer sein wird. Um die Schaltung zu erzeugen, gibt es mehrere Möglichkeiten.
- Verwenden Sie die Auto-DDL- Funktion aus dem Ruhezustand. Der Spring Boot Test setzt diesen Wert automatisch auf
create-drop sodass Hibernate aus der Entitätsbeschreibung ein Schema generiert und es am Ende der Sitzung löscht. Dies ist eine unglaublich leistungsstarke Funktion von Hibernate, die für Tests sehr nützlich ist. - Verwenden Sie Migrationen, die von Flyway oder Liquibase erstellt wurden .
Weitere Informationen zu den verschiedenen Ansätzen zur Initialisierung der Datenbank finden Sie in der Dokumentation .
@AutoConfigureCache
Es konfiguriert nur den Cache für die Verwendung von NoOpCacheManager - d. H. Cache nichts. Dies ist nützlich, um Überraschungen bei Tests zu vermeiden.
@AutoConfigureTestEntityManager
Fügt dem TestEntityManager ein spezielles TestEntityManager Objekt hinzu, das an sich schon ein interessantes Tier ist. EntityManager ist die Hauptklasse von JPA, die für das Hinzufügen von Entitäten zur Sitzung, das Löschen und ähnliche Dinge verantwortlich ist. Nur wenn beispielsweise der Ruhezustand in Betrieb genommen wird - das Hinzufügen einer Entität zu einer Sitzung bedeutet nicht, dass eine Anforderung an die Datenbank ausgeführt wird, und das Laden aus einer Sitzung bedeutet nicht, dass eine ausgewählte Anforderung ausgeführt wird. Aufgrund der internen Mechanismen von Hibernate werden reale Vorgänge mit der Datenbank zum richtigen Zeitpunkt ausgeführt, den das Framework selbst bestimmt. Bei Tests kann es jedoch erforderlich sein, etwas zwangsweise an die Datenbank zu senden, da der Zweck der Tests darin besteht, die Integration zu testen. Und TestEntityManager ist nur ein TestEntityManager mit dem einige Vorgänge mit der Datenbank zwangsweise ausgeführt werden können. Beispielsweise persistAndFlush() Hibernate, alle Anforderungen auszuführen.
@Transactional
Diese Annotation macht alle Tests in der Klasse transaktional, wobei die Transaktion nach Abschluss des Tests automatisch zurückgesetzt wird. Dies ist nur ein Mechanismus zum „Bereinigen“ der Datenbank vor jedem Test, da Sie sonst Daten aus jeder Tabelle manuell löschen müssten.
Ob ein Test eine Transaktion verwalten sollte, ist keine so einfache und offensichtliche Frage, wie es scheinen mag. Trotz der Bequemlichkeit des "sauberen" Status der Datenbank kann das Vorhandensein von @Transactional in Tests eine unangenehme Überraschung sein, wenn der "Battle" -Code die Transaktion nicht selbst startet, sondern eine vorhandene erfordert. Dies kann dazu führen, dass der Integrationstest bestanden wird. Wenn jedoch der reale Code vom Controller und nicht vom Test ausgeführt wird, hat der Dienst keine aktive Transaktion und die Methode löst eine Ausnahme aus. Obwohl dies gefährlich aussieht, sind Transaktionstests bei Tests der Benutzeroberfläche auf hoher Ebene nicht so schlecht. Nach meiner Erfahrung habe ich nur einmal gesehen, dass ein bestehender Integrationstest den Produktionscode zum Absturz brachte, was eindeutig das Vorhandensein einer vorhandenen Transaktion erforderte. Wenn Sie jedoch weiterhin überprüfen müssen, ob die Services und Komponenten selbst Transaktionen korrekt verwalten, können Sie die Annotation @Transactional für den Test im gewünschten Modus „blockieren“ (z. B. die Transaktion nicht starten).
Integrationstest mit @SpringBootTest
Ich möchte auch darauf hinweisen, dass @DataJpaTest kein einzigartiges Beispiel für einen @DataJpaTest ist. Es gibt @WebMvcTest , @DataMongoTest und viele andere. Eine der wichtigsten @SpringBootTest bleibt jedoch @SpringBootTest , mit dem die Anwendung "wie sie ist" für die Tests @SpringBootTest wird - mit allen konfigurierten Komponenten und Integrationen. Es stellt sich eine logische Frage: Wenn Sie die gesamte Anwendung ausführen können, warum werden beispielsweise fokale DataJpa-Tests durchgeführt? Ich würde sagen, dass es hier wieder keine strengen Regeln gibt.
Wenn es möglich ist , jedes Mal Anwendungen auszuführen, Abstürze in Tests zu isolieren, das Setup des Tests nicht zu überlasten und nicht erneut zu komplizieren, können und sollten Sie natürlich @SpringBootTest verwenden.
Im wirklichen Leben können Anwendungen jedoch viele verschiedene Einstellungen erfordern, eine Verbindung zu verschiedenen Systemen herstellen, und ich möchte nicht, dass meine Datenbankzugriffstests fallen, weil Die Verbindung zur Nachrichtenwarteschlange ist nicht konfiguriert. Daher ist es wichtig, den gesunden Menschenverstand zu verwenden. Wenn der Test mit der Annotation @SpringBootTest funktioniert, müssen Sie die Hälfte des Systems sperren. Ist dies dann in @SpringBootTest überhaupt sinnvoll?
Vorbereitung der Daten für den Test
Einer der wichtigsten Punkte beim Testen ist die Datenaufbereitung. Jeder Test sollte isoliert durchgeführt werden und die Umgebung vor dem Start vorbereiten, um das System in den ursprünglich gewünschten Zustand zu bringen. Die einfachste Möglichkeit, dies zu tun, besteht darin, die Anmerkungen @BeforeEach / @BeforeAll und dort mithilfe des Repositorys, EntityManager oder TestEntityManager Einträge zur Datenbank TestEntityManager . Es gibt jedoch noch eine andere Option, mit der Sie ein vorbereitetes Skript ausführen oder die gewünschte SQL-Abfrage ausführen können. Dies ist die @Sql SQL-Annotation. Vor dem Ausführen des Tests führt der Spring Boot-Test automatisch das angegebene Skript aus, sodass der Block @Transactional mehr @Transactional werden @BeforeAll , und @Transactional kümmert sich um die Datenbereinigung.
@DataJpaTest class JpaCakeFinderTest { private static final String PROMOTED_CAKE = "Red Velvet"; private static final String NON_PROMOTED_CAKE = "Victoria Sponge"; private CakeFinder finder; @Autowired CakeRepository cakeRepository; @Autowired TestEntityManager testEntityManager; @BeforeEach void setUp() { this.testEntityManager.persistAndFlush(CakeEntity.builder().title(PROMOTED_CAKE) .sku("SKU1").price(BigDecimal.TEN).promoted(true).build()); this.testEntityManager.persistAndFlush(CakeEntity.builder().sku("SKU2") .title(NON_PROMOTED_CAKE).price(BigDecimal.ONE).promoted(false).build()); finder = new JpaCakeFinder(cakeRepository); } ... }
Rot-Grün-Refaktor-Zyklus
Trotz dieser Textmenge sieht der Test für den Entwickler immer noch wie eine einfache Klasse mit der Annotation @DataJpaTest aus, aber ich hoffe, dass ich zeigen konnte, wie viele nützliche Dinge unter der Haube passieren, an die der Entwickler nicht denken kann. Jetzt können wir zum TDD-Zyklus übergehen und dieses Mal werde ich einige TDD-Iterationen mit Beispielen für Refactoring und minimalem Code zeigen. Um es klarer zu machen, empfehle ich dringend, dass Sie sich den Verlauf in Git ansehen, in dem jedes Commit ein separater und wichtiger Schritt mit einer Beschreibung dessen ist, was und wie es funktioniert.
Datenaufbereitung
Ich verwende den Ansatz mit @BeforeAll / @BeforeEach und erstelle manuell alle Datensätze in der Datenbank. Das Beispiel mit der Annotation @Sql wird in eine separate Klasse JpaCakeFinderTestWithScriptSetup . Es dupliziert Tests, die natürlich nicht sein sollten und nur zum Zweck der Demonstration des Ansatzes existieren.
Der Anfangszustand des Systems - es gibt zwei Einträge im System, ein Kuchen nimmt an der Aktion teil und muss in das von der Methode zurückgegebene Ergebnis einbezogen werden, der zweite - Nr.
Erster Test Integrationstest
Der erste Test ist der einfachste - findPromotedCakes sollte eine Beschreibung und einen Preis des an der Aktion teilnehmenden Kuchens enthalten.
Rot
@Test void shouldReturnPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle).contains(PROMOTED_CAKE); assertThat(promotedCakes).extracting(Cake::getPrice).contains("£10.00"); }
Der Test stürzt natürlich ab - die Standardimplementierung gibt einen leeren Satz zurück.
Grün
Natürlich möchten wir die Filterung sofort schreiben, eine Anfrage an die Datenbank mit where und so weiter. Aber nach der TDD-Praxis muss ich den Mindestcode schreiben , damit der Test bestanden wird . Und dieser minimale Code soll alle Datensätze in der Datenbank zurückgeben. Ja, so einfach und kitschig.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); } private String formatPrice(BigDecimal price) { return "£" + price.setScale(2, RoundingMode.DOWN).toPlainString(); }
Wahrscheinlich würden einige argumentieren, dass Sie hier den Test auch ohne Basis grün machen können - codieren Sie einfach das vom Test erwartete Ergebnis fest. Ich höre gelegentlich ein solches Argument, aber ich denke, jeder versteht, dass TDD kein Dogma oder eine Religion ist. Es macht keinen Sinn, dies auf den Punkt der Absurdität zu bringen. Wenn Sie dies jedoch wirklich möchten, können Sie beispielsweise Daten in der Installation nach dem Zufallsprinzip sortieren, damit sie nicht fest codiert werden.
Refactor
Ich sehe hier nicht viel Refactoring, daher kann diese Phase für diesen speziellen Test übersprungen werden. Aber ich würde immer noch nicht empfehlen, diese Phase zu ignorieren. Es ist besser, jedes Mal im „grünen“ Zustand des Systems anzuhalten und nachzudenken. Ist es möglich, etwas umzugestalten, um es besser und einfacher zu machen?
Zweiter Test
Der zweite Test bestätigt jedoch bereits, dass kein beworbener Kuchen in das von findPromotedCakes Ergebnis findPromotedCakes .
@Test void shouldNotReturnNonPromotedCakes() { Iterable<Cake> promotedCakes = finder.findPromotedCakes(); assertThat(promotedCakes).extracting(Cake::getTitle) .doesNotContain(NON_PROMOTED_CAKE); }
Rot
Der Test stürzt erwartungsgemäß ab - die Datenbank enthält zwei Datensätze, und der Code gibt einfach alle zurück.
Grün
Und wieder können Sie denken - und was ist der Mindestcode, den Sie schreiben können, um den Test zu bestehen? Da es bereits einen Stream und dessen Assembly gibt, können Sie dort einfach einen filter hinzufügen.
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findAll() .spliterator(); return StreamSupport.stream(cakes, false) .filter(cakeEntity -> cakeEntity.promoted) .map(cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
Wir starten Tests neu - Integrationstests sind jetzt grün. Ein wichtiger Moment ist gekommen - aufgrund der Kombination aus dem Komponententest des Controllers und dem Integrationstest für die Arbeit mit der Datenbank ist meine Funktion bereit - und der UI-Test ist jetzt erfolgreich!
Refactor
Und da alle Tests grün sind, ist es Zeit für eine Umgestaltung. Ich denke, es muss nicht klargestellt werden, dass das Filtern im Speicher keine gute Idee ist. Es ist besser, dies in der Datenbank zu tun. Zu diesem CakesRepository ich im CakesRepository eine neue Methode CakesRepository - findByPromotedIsTrue :
interface CakeRepository extends CrudRepository<CakeEntity, String> { Iterable<CakeEntity> findByPromotedIsTrue(); }
Für diese Methode hat Spring Data automatisch eine Methode generiert, die eine Abfrage der Formularauswahl select from cakes where promoted = true ausführt select from cakes where promoted = true . Weitere Informationen zur Generierung von Abfragen finden Sie in der Spring Data- Dokumentation .
public Set<Cake> findPromotedCakes() { Spliterator<CakeEntity> cakes = this.cakeRepository.findByPromotedIsTrue() .spliterator(); return StreamSupport.stream(cakes, false).map( cakeEntity -> new Cake(cakeEntity.title, formatPrice(cakeEntity.price))) .collect(Collectors.toSet()); }
Dies ist ein gutes Beispiel für die Flexibilität, die Integrationstests und der Black-Box-Ansatz bieten. Wenn das Repository gesperrt war, war das Hinzufügen einer neuen Methode ohne Änderung der Tests nicht unmöglich.
Verbindung zur Produktionsbasis
Um ein wenig „Realismus“ hinzuzufügen und zu zeigen, wie Sie die Konfiguration für Tests und die Hauptanwendung trennen können, füge ich eine Datenzugriffskonfiguration für die Anwendung „Produktion“ hinzu.
Alles wird traditionell durch den Abschnitt in application.yml hinzugefügt:
datasource: url: jdbc:h2:./data/cake-factory
Dadurch werden die Daten im Dateisystem automatisch im Ordner ./data . Ich @DataJpaTest fest, dass dieser Ordner in Tests nicht erstellt wird. @DataJpaTest ersetzt aufgrund des Vorhandenseins der Annotation @DataJpaTest automatisch die Verbindung zur @DataJpaTest durch eine zufällige Datenbank im Speicher.
Zwei nützliche Dinge, die nützlich sein können, sind die schema.sql data.sql und schema.sql . , Spring Boot . , , , .
Fazit
, , , TDD .
Spring Security — Spring, .