"
Unternehmen " - Telekommunikationsbetreiber PJSC "Megafon"
"
Noda " ist der RabbitMQ-Server.
Ein „
Cluster “ ist in unserem Fall eine Kombination von drei RabbitMQ-Knoten, die als Ganzes arbeiten.
"
Kontur " - eine Reihe von RabbitMQ-Clustern, deren Arbeitsregeln auf dem Balancer vor ihnen festgelegt werden.
"
Balancer ", "
hap " - Haproxy - Balancer, der die Funktion zum Umschalten der Last auf Cluster innerhalb der Schleife ausführt. Für jede Schleife wird ein Paar parallel laufender Haproxy-Server verwendet.
"
Subsystem " - der Herausgeber und / oder Verbraucher von Nachrichten, die über das Kaninchen übertragen werden
"
SYSTEM " - eine Reihe von Subsystemen, bei denen es sich um eine einzige Software- und Hardwarelösung handelt, die vom Unternehmen verwendet wird und die durch die Verteilung in ganz Russland gekennzeichnet ist, jedoch über mehrere Zentren verfügt, in denen alle Informationen fließen und in denen die wichtigsten Berechnungen und Berechnungen stattfinden.
SYSTEM - ein geografisch verteiltes System - von Chabarowsk und Wladiwostok bis St. Petersburg und Krasnodar. Architektonisch sind dies mehrere zentrale Konturen, die durch die Merkmale der mit ihnen verbundenen Subsysteme unterteilt sind.
Was ist die Aufgabe des Verkehrs in der Realität der Telekommunikation?
Kurz gesagt: Es folgt die Reaktion der Subsysteme auf die Aktion jedes Teilnehmers, die wiederum andere Subsysteme über Ereignisse und nachfolgende Änderungen informiert. Nachrichten werden durch alle Aktionen mit dem SYSTEM generiert, nicht nur seitens der Abonnenten, sondern auch seitens der Mitarbeiter und Subsysteme des Unternehmens (eine sehr große Anzahl von Aufgaben wird automatisch ausgeführt).
Merkmale des Transports in der Telekommunikation: großer, kein falscher, GROSSER Strom verschiedener Daten, die durch asynchronen Transport übertragen werden.
Einige Subsysteme leben aufgrund der starken Nachrichtenflüsse in separaten Clustern. Es sind einfach keine Ressourcen mehr im Cluster vorhanden. Bei einem Nachrichtenfluss von 5 bis 6.000 Nachrichten / Sekunde kann die übertragene Datenmenge 170 bis 190 Megabyte / Sekunde erreichen. Bei einem solchen Lastprofil führt der Versuch, andere Personen in diesem Cluster zu landen, zu traurigen Konsequenzen: Da nicht genügend Ressourcen vorhanden sind, um alle Daten gleichzeitig zu verarbeiten, beginnt das Kaninchen, eingehende Verbindungen in den
Fluss zu treiben. Ein einfacher Veröffentlichungsprozess beginnt mit allen Konsequenzen für alle Subsysteme und SYSTEME ganz.
Grundvoraussetzungen für den Transport:
- Die Zugänglichkeit von Fahrzeugen sollte 99,99% betragen. In der Praxis bedeutet dies eine 24-Stunden-Betriebsanforderung und die Fähigkeit, automatisch auf Notfallsituationen zu reagieren.
- Datensicherheit:% der verlorenen Nachrichten beim Transport sollten gegen 0 tendieren.
Wenn beispielsweise ein Anruf getätigt wird, werden mehrere verschiedene Nachrichten asynchron transportiert. Einige Nachrichten sind für Subsysteme vorgesehen, die in derselben Schaltung leben, und andere sind für die Übertragung an zentrale Knoten vorgesehen. Dieselbe Nachricht kann von mehreren Subsystemen beansprucht werden. Daher wird sie zum Zeitpunkt der Veröffentlichung der Nachricht im Kaninchen kopiert und an verschiedene Verbraucher gesendet. In einigen Fällen wird das Kopieren von Nachrichten auf einer Zwischenschaltung obligatorisch implementiert - wenn Informationen von der Schaltung in Chabarowsk an die Schaltung in Krasnodar geliefert werden müssen. Die Übertragung erfolgt über eine der zentralen Konturen, in denen Kopien der Nachrichten für die zentralen Empfänger erstellt werden.
Zusätzlich zu den Ereignissen, die durch die Aktionen des Teilnehmers verursacht werden, durchlaufen Dienstnachrichten, die die Subsysteme austauschen, den Transport. Auf diese Weise werden mehrere tausend verschiedene Nachrichtenrouten erhalten, von denen sich einige überschneiden, andere isoliert existieren. Es reicht aus, die Anzahl der Warteschlangen zu benennen, die an den Routen auf verschiedenen Konturen beteiligt sind, um den ungefähren Maßstab der Transportkarte zu verstehen: Auf den zentralen Schaltkreisen 600, 200, 260, 15 ... und auf den entfernten Schaltkreisen 80-100 ...
Mit einer solchen Einbeziehung des Verkehrs scheinen die Anforderungen an eine 100% ige Zugänglichkeit aller Verkehrsknoten nicht mehr übermäßig hoch zu sein. Wir gehen zur Umsetzung dieser Anforderungen über.
Wie wir Aufgaben lösen
Zusätzlich zu
RabbitMQ selbst wird
Haproxy verwendet, um die Last auszugleichen und eine automatische Reaktion auf Notfälle bereitzustellen.
Ein paar Worte zur Hardware- und Softwareumgebung, in der unsere Kaninchen existieren:
- Alle Kaninchen-Server sind virtuell mit Parametern von 8-12 CPU, 16 Gb Mem, 200 Gb HDD. Wie die Erfahrung gezeigt hat, bietet selbst die Verwendung von gruseligen nicht-virtuellen Servern mit 90 Kernen und einer Menge RAM einen kleinen Leistungsschub bei deutlich höheren Kosten. Verwendete Versionen: 3.6.6 (in der Praxis - die stabilste von 3.6) mit einem Erlang von 18.3, 3.7.6 mit einem Erlang von 20.1.
- Für Haproxy sind die Anforderungen viel niedriger: 2 CPU, 4 Gb Mem, die Haproxy-Version ist 1.8 stabil. Die Ressourcenbelastung auf allen Haproxy-Servern überschreitet nicht 15% CPU / Mem.
- Der gesamte Zoo befindet sich in 14 Rechenzentren an 7 Standorten im ganzen Land, die in einem einzigen Netzwerk zusammengefasst sind. In jedem der Rechenzentren gibt es einen Cluster aus drei Knoten und einem Hub.
- Für entfernte Schaltkreise werden 2 Rechenzentren für jeden der zentralen Schaltkreise verwendet - 4.
- Die zentralen Schaltkreise interagieren sowohl miteinander als auch mit den entfernten Schaltkreisen. Die entfernten Schaltkreise arbeiten wiederum nur mit den zentralen Schaltkreisen und haben keine direkte Kommunikation miteinander.
- Die Konfigurationen von Haps und Clustern innerhalb derselben Schaltung sind völlig identisch. Der Einstiegspunkt für jede Verbindung ist ein Alias für mehrere A-DNS-Einträge. Um dies zu verhindern, stehen mindestens ein Zufall und mindestens einer der Cluster (mindestens ein Knoten im Cluster) in jeder Schaltung zur Verfügung. Da der Ausfall von sogar 6 Servern in zwei Rechenzentren gleichzeitig äußerst unwahrscheinlich ist, wird eine Akzeptanz von nahezu 100% angenommen.
All dies sieht so aus (und umgesetzt):

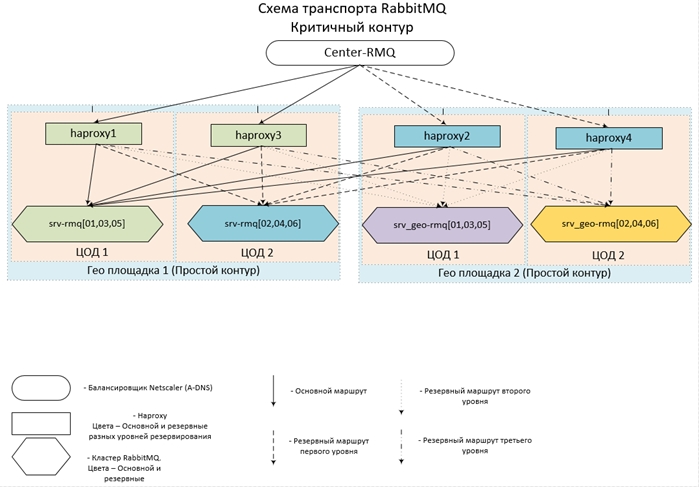
Nun ein paar Konfigurationen.
Haproxy-Konfiguration| Frontend center-rmq_5672 | |
| binden | *: 5672 |
| Modus | tcp |
| maxconn | 10.000 |
| Timeout-Client | 3h |
| Option | tcpka |
| Option | tcplog |
| default_backend | center-rmq_5672 |
| Frontend center-rmq_5672_lvl_1 | |
| binden | localhost: 56721 |
| Modus | tcp |
| maxconn | 10.000 |
| Timeout-Client | 3h |
| Option | tcpka |
| Option | tcplog |
| default_backend | center-rmq_5672_lvl_1 |
| Backend center-rmq_5672 |
| Gleichgewicht | Leastconn |
| Modus | tcp |
| fullconn | 10.000 |
| Zeitüberschreitung | Server 3h |
| Server | srv-rmq01 10/10/10/10/106767 check inter 5s steigen 2 fallen 3 on-marked-up Shutdown-Backup-Sessions |
| Server | srv-rmq03 10/10/10/2011 11672 check inter 5s steigen 2 fallen 3 on-marked-up Shutdown-Backup-Sitzungen |
| Server | srv-rmq05 10/10/10/126767 check inter 5s steigen 2 fallen 3 on-marked-up Shutdown-Backup-Sessions |
| Server | localhost 127.0.0.1 ∗ 6721 Check Inter 5s Anstieg 2 Fall 3 Backup On-Markated-Down-Shutdown-Sitzungen |
| backend center-rmq_5672_lvl_1 |
| Gleichgewicht | Leastconn |
| Modus | tcp |
| fullconn | 10.000 |
| Zeitüberschreitung | Server 3h |
| Server | srv-rmq02 10/10/10/136767 check inter 5s steigen 2 fallen 3 on-marked-up Shutdown-Backup-Sitzungen |
| Server | srv-rmq04 10/10/10/14/1067 check inter 5s steigen 2 fallen 3 on-marked-up Shutdown-Backup-Sessions |
| Server | srv-rmq06 10.10.10.5:0767 check inter 5s steigen 2 fallen 3 on-marked-up Shutdown-Backup-Sessions |
Der erste Abschnitt der Front beschreibt den Einstiegspunkt - der zweite Abschnitt führt zum Hauptcluster und dient zum Ausgleich des Reserveniveaus. Wenn Sie einfach alle Backup-Rabbit-Server im Backend-Abschnitt beschreiben (Backup-Anweisung), funktioniert dies auf die gleiche Weise. Wenn auf den Hauptcluster nicht zugegriffen werden kann, werden die Verbindungen zum Backup-Server hergestellt, alle Verbindungen werden jedoch zum ERSTEN Backup-Server in der Liste. Um den Lastausgleich auf allen Sicherungsknoten sicherzustellen, führen wir nur eine weitere Front ein, die wir nur mit localhost zur Verfügung stellen, und weisen ihr den Sicherungsserver zu.
Das obige Beispiel beschreibt den Ausgleich der Remote-Schleife, die in zwei Rechenzentren betrieben wird: dem srv-rmq-Server {01,03,05} - live im Rechenzentrum Nr. 1, srv-rmq {02,04,06} - im Rechenzentrum Nr. 2. Um die Vier-Coda-Lösung zu implementieren, müssen wir nur zwei weitere lokale Fronten und zwei Backend-Abschnitte der entsprechenden Kaninchen-Server hinzufügen.
Das Verhalten des Balancers bei dieser Konfiguration ist wie folgt: Während mindestens ein Hauptserver aktiv ist, verwenden wir ihn. Wenn die Hauptserver nicht verfügbar sind, arbeiten wir mit einer Reserve. Wenn mindestens ein Primärserver verfügbar wird, werden alle Verbindungen zu den Sicherungsservern getrennt, und wenn die Verbindung wiederhergestellt wird, fallen sie bereits auf den Primärcluster.
Die Betriebserfahrung einer solchen Konfiguration zeigt eine nahezu 100% ige Verfügbarkeit jeder der Schaltungen. Diese Lösung erfordert, dass die Subsysteme vollständig legal und einfach sind: um nach dem Trennen der Verbindung wieder eine Verbindung zum Kaninchen herstellen zu können.
Wir haben also einen Lastausgleich für eine beliebige Anzahl von Clustern bereitgestellt und wechseln automatisch zwischen diesen. Es ist Zeit, direkt zu den Kaninchen zu gehen.
Wie die Praxis zeigt, wird jeder Cluster aus drei Knoten erstellt - der optimalsten Anzahl von Knoten, wodurch ein optimales Gleichgewicht zwischen Verfügbarkeit / Fehlertoleranz / Geschwindigkeit sichergestellt wird. Da das Kaninchen nicht horizontal skaliert (die Clusterleistung entspricht der Leistung des langsamsten Servers), erstellen wir alle Knoten mit denselben optimalen Parametern für CPU / Mem / Hdd. Wir positionieren die Server so nah wie möglich beieinander - in unserem Fall legen wir virtuelle Maschinen in derselben Farm ab.
Was die Voraussetzungen betrifft, nach denen die Subsysteme den stabilsten Betrieb und die Erfüllung der Anforderung zum Speichern empfangener Nachrichten sicherstellen:
- Die Arbeit mit dem Kaninchen erfolgt nur über das amqp / amqps-Protokoll - durch Balancing. Autorisierung unter lokalen Konten - innerhalb jedes Clusters (gut und der gesamten Schaltung)
- Subsysteme sind im passiven Modus mit dem Kaninchen verbunden: Es sind keine Manipulationen mit den Entitäten der Kaninchen (Erstellen von Warteschlangen / eschendzhey / bind) zulässig und auf der Ebene der Kontorechte beschränkt - wir geben einfach keine Konfigurationsrechte.
- Alle erforderlichen Entitäten werden zentral erstellt, nicht mithilfe von Subsystemen, und auf allen Cluster-Clustern werden die gleichen Schritte ausgeführt, um ein automatisches Umschalten auf den Sicherungscluster und umgekehrt sicherzustellen. Andernfalls können wir uns ein Bild machen: Wir sind in die Reserve gewechselt, aber die Warteschlange oder die Bindung ist nicht vorhanden, und wir können zwischen einem Verbindungsfehler oder einem Verlust von Nachrichten wählen.
Jetzt direkt Einstellungen an Kaninchen:
- Lokale Hosts haben keinen Zugriff auf die Weboberfläche
- Der Zugriff auf das Web wird über LDAP organisiert. Wir integrieren uns in AD und protokollieren, wer und wo auf der Webcam war. Auf der Konfigurationsebene schränken wir die Rechte von AD-Konten ein. Wir müssen nicht nur einer bestimmten Gruppe angehören, sondern geben auch nur Rechte zum "Sehen". Überwachungsgruppen sind mehr als genug. Und wir hängen Administratorrechte an eine andere Gruppe in AD, sodass der Einflussbereich auf den Transport stark eingeschränkt ist.
- So erleichtern Sie die Verwaltung und Nachverfolgung:
Auf allen VHOSTs legen wir sofort eine Richtlinie der Stufe 0 mit Anwendung auf alle Warteschlangen auf (Muster:. *):
- ha-mode: all - speichert alle Daten auf allen Knoten des Clusters, die Verarbeitungsgeschwindigkeit von Nachrichten nimmt ab, aber ihre Sicherheit und Verfügbarkeit sind gewährleistet.
- ha-sync-mode: automatisch - Weist den Crawler an, Daten auf allen Knoten des Clusters automatisch zu synchronisieren. Die Sicherheit und Verfügbarkeit von Daten erhöht sich ebenfalls.
- Warteschlangenmodus: faul - vielleicht eine der nützlichsten Optionen, die seit Version 3.6 bei Kaninchen aufgetaucht sind - sofortige Aufzeichnung von Nachrichten auf der Festplatte. Diese Option reduziert den RAM-Verbrauch erheblich und erhöht die Datensicherheit beim Stoppen / Herunterfallen von Knoten oder des gesamten Clusters.
- Einstellungen in der Konfigurationsdatei ( rabbitmq-main / conf / rabbitmq.config ):
- Abschnitt Kaninchen : {vm_memory_high_watermark_paging_ratio, 0.5} - Schwellenwert für das Herunterladen von Nachrichten auf die Festplatte 50%. Wenn Lazy aktiviert ist, dient es eher als Versicherung, wenn wir eine Police abschließen, z. B. Stufe 1, in der wir vergessen, Lazy einzubeziehen.
- {vm_memory_high_watermark, 0.95} - Wir beschränken das Kaninchen auf 95% des gesamten Arbeitsspeichers, da nur das Kaninchen auf den Servern lebt. Es macht keinen Sinn, strengere Einschränkungen einzuführen. 5% "breite Geste" also sei es - lass das Betriebssystem, die Überwachung und andere nützliche Kleinigkeiten. Da dieser Wert die Obergrenze ist, gibt es genug für alle.
- {cluster_partition_handling, pause_minority} - beschreibt das Verhalten des Clusters beim Auftreten der Netzwerkpartition. Für drei oder mehr Knotencluster wird dieses Flag empfohlen. Dadurch kann sich der Cluster selbst wiederherstellen.
- {disk_free_limit, "500MB"} - alles ist einfach, wenn 500 MB freier Speicherplatz vorhanden sind - das Veröffentlichen von Nachrichten wird gestoppt, nur die Subtraktion ist verfügbar.
- {auth_backends, [rabbit_auth_backend_internal, rabbit_auth_backend_ldap]} - Autorisierungsreihenfolge für Kaninchen: Zuerst wird das Vorhandensein von Ultraschall in der lokalen Datenbank überprüft, und wenn nicht, gehen Sie zum LDAP-Server.
- Abschnitt rabbitmq_auth_backend_ldap - Konfiguration der Interaktion mit AD: {servers, ["srv_dc1", "srv_dc2"]} - eine Liste der Domänencontroller, auf denen die Authentifizierung stattfinden wird.
- Die Parameter, die den Benutzer in AD, den LDAP-Port usw. direkt beschreiben, sind rein individuell und werden in der Dokumentation ausführlich beschrieben.
- Das Wichtigste für uns ist eine Beschreibung der Rechte und Einschränkungen für die Verwaltung und den Zugriff auf die Weboberfläche von Kaninchen: tag_queries:
[{Administrator, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{Überwachung,
{in_group, "cn = rabbitmq-web, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}
}] - Dieses Design bietet Administratorrechten für alle Benutzer der Gruppe rabbitmq-admins und Überwachungsrechte (minimal ausreichend für die Anzeige des Zugriffs) für die Gruppe rabbitmq-web.
- resource_access_query :
{für,
[{Erlaubnis, konfigurieren, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{Erlaubnis, schreibe, {in_group, "cn = rabbitmq-admins, ou = GRP, ou = GRP_MAIN, dc = My_domain, dc = ru"}},
{Erlaubnis, lesen, {Konstante, wahr}}
]]
} - Wir gewähren die Rechte zum Konfigurieren und Schreiben nur für die Gruppe der Administratoren, für alle anderen, die sich erfolgreich anmelden. Die Rechte sind schreibgeschützt. Sie können Nachrichten über die Weboberfläche lesen.
Wir erhalten einen konfigurierten Cluster (auf der Ebene der Konfigurationsdatei und der Einstellungen im Kaninchen selbst), der die Verfügbarkeit und Sicherheit von Daten maximiert. Damit setzen wir die Anforderung um - Gewährleistung der Verfügbarkeit und Sicherheit von Daten ... in den meisten Fällen.
Beim Betrieb derart hoch belasteter Systeme sollten mehrere Punkte berücksichtigt werden:
- Es ist besser, alle zusätzlichen Eigenschaften von Warteschlangen (TTL, Ablaufdatum, maximale Länge usw.) von Politikern zu organisieren, als beim Erstellen von Warteschlangen Parameter aufzuhängen. Es stellt sich eine flexibel anpassbare Struktur heraus, die im laufenden Betrieb an sich ändernde Realitäten angepasst werden kann.
- Verwenden von TTL. Je länger die Warteschlange ist, desto höher ist die Belastung der CPU. Um ein "Durchbrechen der Decke" zu verhindern, ist es besser, die Länge der Warteschlange auch über die maximale Länge zu begrenzen.
- Zusätzlich zum Kaninchen selbst drehen sich auf dem Server eine Reihe von Dienstprogrammanwendungen, die seltsamerweise auch CPU-Ressourcen erfordern. Ein gefräßiges Kaninchen nimmt standardmäßig alle verfügbaren Kerne ein ... Eine unangenehme Situation kann sich herausstellen: ein Kampf um Ressourcen, der leicht zu Bremsen des Kaninchens führen kann. Um das Auftreten einer solchen Situation zu vermeiden, gehen Sie beispielsweise wie folgt vor: Ändern Sie die Parameter für den Start des erlang - führen Sie eine obligatorische Begrenzung für die Anzahl der verwendeten Kerne ein. Wir machen das wie folgt: Suchen Sie die Datei rabbitmq-env , suchen Sie nach dem Parameter SERVER_ERL_ARGS = und fügen Sie + sct L0-Xc0-X + SY: Y hinzu. Wobei X die Anzahl der Kerne-1 ist (Zählen beginnt bei 0), Y - Die Anzahl der Kerne -1 (Zählen von 1). + sct L0-Xc0-X - ändert die Bindung an die Kernel, + SY: Y - ändert die Anzahl der vom erlang gestarteten Sheduler. Für ein System mit 8 Kernen haben die hinzugefügten Parameter die Form: + sct L0-6c0-6 + S 7: 7. Auf diese Weise geben wir dem Kaninchen nur 7 Kerne und erwarten, dass das Betriebssystem durch Starten anderer Prozesse optimal funktioniert und sie an einen entladenen Kernel hängt.
Die Nuancen des Betriebs des resultierenden Zoos
Was jede Einstellung nicht schützen kann, ist die zusammengebrochene Basis der Mnesie - leider geschieht dies mit einer Wahrscheinlichkeit ungleich Null. Solch ein katastrophales Ergebnis wird nicht durch globale Ausfälle verursacht (z. B. einen vollständigen Ausfall eines gesamten Rechenzentrums - die Last wird einfach auf einen anderen Cluster umgeschaltet), sondern durch mehr lokale Ausfälle innerhalb desselben Netzwerksegments.
Darüber hinaus sind lokale Netzwerkfehler beängstigend, weil Das Herunterfahren eines oder zweier Knoten im Notfall führt nicht zu schwerwiegenden Konsequenzen. Alle Anforderungen werden einfach an einen Knoten gesendet. Wie wir uns erinnern, hängt die Leistung nur von der Leistung des Knotens selbst ab. Netzwerkfehler (kleine Kommunikationsunterbrechungen werden nicht berücksichtigt - sie treten schmerzlos auf) führen dazu, dass die Knoten den Synchronisierungsprozess miteinander beginnen und die Verbindung dann einige Sekunden lang immer wieder unterbrochen wird.
Zum Beispiel mehrfaches Blinken des Netzwerks und mit einer Frequenz von mehr als 5 Sekunden (genau ein solches Timeout ist in den Hapov-Einstellungen festgelegt, Sie können sie sicherlich abspielen, aber um die Effektivität zu überprüfen, müssen Sie den Fehler wiederholen, den niemand will).
Der Cluster kann immer noch ein oder zwei solcher Iterationen aushalten, aber mehr - die Chancen sind bereits minimal. In einer solchen Situation kann ein Stopp eines heruntergefallenen Knotens gespeichert werden, aber es ist fast unmöglich, dies manuell zu tun. In den meisten Fällen ist das Ergebnis nicht nur der Verlust eines Knotens aus dem Cluster mit der Meldung
„Netzwerkpartition“ , sondern auch das Bild, in dem die Daten der Warteschlangen nur diesen Knoten lebten und keine Zeit hatten, sich mit den verbleibenden zu synchronisieren. Visuell - in der Warteschlange sind Daten
NaN .
Und jetzt ist dies ein eindeutiges Signal - wechseln Sie zum Backup-Cluster. Das Umschalten ist ein Zufall. Sie müssen nur die Kaninchen im Hauptcluster stoppen - eine Frage von mehreren Minuten. Dadurch erhalten wir die Wiederherstellung der Arbeitsfähigkeit des Transports und können sicher mit der Analyse des Unfalls und seiner Beseitigung fortfahren.
Um einen beschädigten Cluster unter der Last zu entfernen und eine weitere Verschlechterung zu verhindern, ist es am einfachsten, das Kaninchen an anderen Ports als 5672 arbeiten zu lassen. Da wir die Kaninchen durch den regulären Port überwachen, wird seine Verschiebung beispielsweise um 5673 In den Einstellungen des Kaninchens können Sie den Cluster problemlos und vollständig starten und versuchen, seine Funktionsfähigkeit und die darauf verbleibenden Nachrichten wiederherzustellen.
Wir machen das in wenigen Schritten:
- Stoppen Sie alle Knoten des ausgefallenen Clusters. Der Hap wechselt die Last zum Sicherungscluster
- RABBITMQ_NODE_PORT=5673 rabbitmq-env – , Web - 15672.
- .
Beim Start werden die Indizes neu erstellt und in den allermeisten Fällen werden alle Daten vollständig wiederhergestellt. Leider treten Abstürze auf, die dazu führen, dass alle Nachrichten physisch von der Festplatte gelöscht werden müssen und nur die Konfiguration übrig bleibt. Die Verzeichnisse msg_store_persistent , msg_store_transient , queues (für Version 3.6) oder msg_stores (für Version 3.7) werden im Ordner mit der Datenbank gelöscht .Nach einer solchen radikalen Therapie wird der Cluster unter Beibehaltung der inneren Struktur, jedoch ohne Botschaften, gestartet.Und die unangenehmste Option (einmal beobachtet): Die Basis wurde so beschädigt, dass die gesamte Basis vollständig entfernt und der Cluster von Grund auf neu aufgebaut werden musste.Für die Verwaltung und Aktualisierung von Kaninchen wird keine fertige Baugruppe in U / min verwendet, sondern ein mit cpio zerlegtes und neu konfiguriertes Kaninchen (die Pfade in den Skripten wurden geändert). Der Hauptunterschied: Für die Installation / Konfiguration sind keine Root-Rechte erforderlich, es ist nicht auf dem System installiert (das neu erstellte Kaninchen ist perfekt in tgz gepackt) und wird von jedem Benutzer ausgeführt. Mit diesem Ansatz können Sie Versionen flexibel aktualisieren (wenn kein vollständiger Stopp des Clusters erforderlich ist - in diesem Fall wechseln Sie einfach zum Sicherungscluster und aktualisieren Sie, ohne den vergessenen Port für den Betrieb anzugeben). Es ist sogar möglich, mehrere Instanzen von RabbitMQ auf demselben Computer auszuführen - die Option ist sehr praktisch zum Testen - Sie können eine reduzierte Architekturkopie des Kampfzoos bereitstellen.Als Ergebnis des Schamanismus mit cpio und Pfaden in Skripten haben wir eine Build-Option erhalten: zwei rabbitmq-Basisordner (in der ursprünglichen Assembly - der Mnesia-Ordner) und rabbimq-main - hier habe ich alle notwendigen Skripte des Kaninchens und erlang selbst platziert.In rabbimq-main / bin - Symlinks zu Kaninchen- und Erlang-Skripten und einem Kaninchen-Tracking-Skript (Beschreibung unten).In rabbimq-main / init.d - das rabbitmq-Server-Skript, über das die Protokolle gestartet / gestoppt / gedreht werden; in lib das Kaninchen selbst; in lib64 - erlang (verwendet eine abgespeckte Version von erlang, nur für Kaninchen).Es ist äußerst einfach, die resultierende Assembly zu aktualisieren, wenn neue Versionen veröffentlicht werden. Fügen Sie den Inhalt von rabbimq-main / lib und rabbimq-main / lib64 aus den neuen Versionen hinzu und ersetzen Sie die Symlinks in bin. Wenn sich das Update auch auf Steuerungsskripte auswirkt, ändern Sie einfach die Pfade zu unseren darin.Ein wesentlicher Vorteil dieses Ansatzes ist die vollständige Kontinuität der Versionen - alle Pfade, Skripte und Steuerbefehle bleiben unverändert, sodass Sie selbst geschriebene Hilfsskripte ohne Doping für jede Version verwenden können.Seit dem Sturz der Kaninchen, obwohl selten, aber vorkommend, war es notwendig, einen Mechanismus zur Überwachung ihrer Gesundheit zu implementieren - Erhöhung im Falle eines Sturzes (unter Beibehaltung der Protokolle der Gründe für den Sturz). Der Ausfall eines Knotens geht in 99% der Fälle mit einem Protokolleintrag einher, sogar das Abtöten hinterlässt Spuren. Dies ermöglichte die Überwachung des Zustands des Kaninchens mithilfe eines einfachen Skripts.In den Versionen 3.6 und 3.7 unterscheidet sich das Skript aufgrund der Unterschiede in den Protokolleinträgen geringfügig.Für 3.7 werden nur zwei Zeilen geändert if (os.path.isfile('/data/logs/rabbitmq/startup_log')) and (os.path.isfile('/data/logs/rabbitmq/startup_err')): if ((b' OK ' in LastRow('/data/logs/rabbitmq/startup_log')) or (b'FAILED' in LastRow('/data/logs/rabbitmq/startup_log'))) and not (b'Gracefully halting Erlang VM' in LastRow('/data/logs/rabbitmq/startup_err')):
Wir richten ein Crontab-Konto ein, unter dem das Kaninchen (standardmäßig rabbitmq) arbeitet und dieses Skript (Skriptname: check_and_run) jede Minute ausführt (zuerst bitten wir den Administrator, dem Konto das Recht zu geben, crontab zu verwenden, aber wenn wir Root-Rechte haben, tun wir es selbst):
* / 1 * * * * ~ / rabbitmq-main / bin / check_and_runDer zweite Punkt bei der Verwendung des wieder zusammengesetzten Kaninchens ist die Drehung der Stämme.
Da wir nicht an das Logrotate-System gebunden sind, verwenden wir die vom Entwickler bereitgestellten Funktionen: das
Rabbitmq-Server- Skript von init.d (für Version 3.6).
Durch kleine Änderungen an
rotate_logs_rabbitmq ()Hinzufügen:
find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.*.back -maxdepth 0 -type f | xargs -i gzip {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Das Ergebnis der Ausführung des Rabbitmq-Server-Skripts mit dem Schlüssel Rotate-Logs: Protokolle werden von gzip komprimiert und nur für die letzten 30 Tage gespeichert.
http_api - der Pfad, in dem das Kaninchen die Protokolle http - konfiguriert in der Konfigurationsdatei
ablegt :
{rabbitmq_management, [{Ratenmodus, detailliert}, {http_log_dir, Pfad_zu_Logs / http_api "}]}Gleichzeitig
achte ich auf
{Rates_Mode, detailliert } - die Option erhöht die Last geringfügig, ermöglicht es Ihnen jedoch, Informationen über den Benutzer anzuzeigen, der Nachrichten in EXCHENGE auf der WEB-Oberfläche veröffentlicht (und dementsprechend über die API zu gelangen). Informationen sind äußerst notwendig, weil Alle Verbindungen gehen über den Balancer - wir sehen nur die IP der Balancer selbst. Und wenn Sie alle Subsysteme, die mit dem Kaninchen arbeiten, so rätseln, dass sie die Client-Eigenschaftenparameter in die Eigenschaften ihrer Verbindungen zu den Kaninchen eintragen, können Sie auf Verbindungsebene detaillierte Informationen darüber erhalten, wer genau, wo und mit welcher Intensität Nachrichten veröffentlicht.
Mit der Veröffentlichung der neuen Versionen 3.7 wurde das
Rabbimq-Server- Skript in init.d vollständig abgelehnt. Um die Bedienung (die Einheitlichkeit der Steuerbefehle unabhängig von der Version des Kaninchens) und einen reibungsloseren Übergang zwischen den Versionen zu erleichtern, verwenden wir beim wieder zusammengesetzten Kaninchen weiterhin dieses Skript. Die Wahrheit ist wieder: Wir werden
rotate_logs_rabbitmq () ein wenig ändern, da sich der Mechanismus zum Benennen von Protokollen nach der Rotation in 3.7 geändert hat:
mv ${RABBITMQ_LOG_BASE}/$NODENAME.log.0 ${RABBITMQ_LOG_BASE}/$NODENAME.log.$(date +%Y%m%d-%H%M%S).back mv ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.0 ${RABBITMQ_LOG_BASE}/$(echo $NODENAME)_upgrade.log.$(date +%Y%m%d-%H%M%S).back find ${RABBITMQ_LOG_BASE}/http_api/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.log.* -maxdepth 0 -type f ! -name "*.gz" | xargs -i gzip --force {} find ${RABBITMQ_LOG_BASE}/*.gz -type f -mtime +30 -delete find ${RABBITMQ_LOG_BASE}/http_api/*.gz -type f -mtime +30 -delete
Jetzt muss nur noch die Aufgabe für die Protokollrotation zu crontab hinzugefügt werden - zum Beispiel jeden Tag um 23:00 Uhr:
00 23 * * * ~ / rabbitmq-main / init.d / rabbitmq-server rotate-logsKommen wir zu den Aufgaben, die im Rahmen des Betriebs der "Kaninchenfarm" gelöst werden müssen:
- Manipulationen mit Kaninchenentitäten - Erstellen / Löschen von Kaninchenentitäten: ekschendzhey, Warteschlangen, Bindungen, Schaufeln, Benutzer, Richtlinien. Und dies ist auf allen Cluster-Clustern absolut identisch.
- Nach dem Wechsel zum / vom Sicherungscluster müssen die darauf verbliebenen Nachrichten an den aktuellen Cluster übertragen werden.
- Erstellen von Sicherungskopien der Konfigurationen aller Cluster aller Schaltkreise
- Vollständige Synchronisation der Cluster-Konfigurationen innerhalb der Kontur
- Kaninchen stoppen / starten
- So analysieren Sie die aktuellen Datenströme: Gehen alle Nachrichten und wenn sie gehen, wohin sollen sie gehen oder ...
- Suchen und Abfangen von Nachrichten nach beliebigen Kriterien
Der Betrieb unseres Zoos und die Lösung von Aufgaben mit Hilfe des mitgelieferten regulären
rabbitmq_management- Plug-
Ins ist möglich, aber äußerst unpraktisch. Aus diesem Grund wurde eine Shell entwickelt und implementiert,
um die gesamte Vielfalt der Kaninchen zu
kontrollieren .