
Kaggle ist eine bekannte Plattform für die Ausrichtung von Wettbewerben zum maschinellen Lernen, bei denen die Anzahl der registrierten Benutzer 2,5 Millionen überschritten hat. Tausende Datenwissenschaftler aus verschiedenen Ländern nehmen an den Wettbewerben teil, und Kaggle interessierte sich für das Publikum. Im Oktober 2018 wurde die zweite Umfrage organisiert und 23.859 Personen aus 147 Ländern beantworteten sie.
Die Umfrage hatte mehrere Dutzend Fragen zu verschiedenen Themen: Geschlecht und Alter, Bildung und Arbeitsbereich, Erfahrung und Fähigkeiten, verwendete Programmiersprachen und Software und vieles mehr.
Kaggle ist jedoch nicht nur ein Austragungsort für Wettbewerbe, es ist auch möglich, Datenrecherchen oder Wettbewerbslösungen zu veröffentlichen (sie werden als Kernel bezeichnet und ähneln dem Jupyter-Notizbuch). Daher wurde der Datensatz mit den Ergebnissen der Umfrage öffentlich veröffentlicht und ein Wettbewerb für die beste Recherche dieser Daten organisiert. Ich nahm auch teil und erhielt keinen Geldpreis, aber mein Kernel belegte den sechsten Platz in der Anzahl der Stimmen. Ich möchte die Ergebnisse meiner Analyse teilen.
Es gibt viele Daten, die aus verschiedenen Blickwinkeln betrachtet werden können. Ich war an den Unterschieden zwischen Menschen aus verschiedenen Ländern interessiert, daher werden die meisten Untersuchungen Menschen aus Russland (da wir hier leben), Amerika (als das am weitesten fortgeschrittene Land in Bezug auf DS), Indien (als armes Land mit vielen DS) und anderen Ländern vergleichen.
Die meisten Grafiken und Analysen stammen aus meinem Kernel (diejenigen, die dies wünschen, können den Python-Code dort sehen), aber es gibt auch neue Ideen.
Allgemeine Überprüfung
Ich stelle sofort fest, dass diejenigen, die die Fragen beantwortet haben, keine repräsentative Stichprobe von Datenwissenschaftlern sind. Nicht jeder ist daran interessiert, Zeit für Wettbewerbe zu verbringen, jemand hat einfach nichts von dieser Plattform gehört, schließlich ~ 24.000 Befragte - nur ein kleiner Teil aller Kaggle-Teilnehmer. Wir haben jedoch nur diese Daten, daher werde ich in Zukunft davon ausgehen, dass die verfügbaren Informationen ausreichen, um Rückschlüsse auf Länder und allgemein zu ziehen.
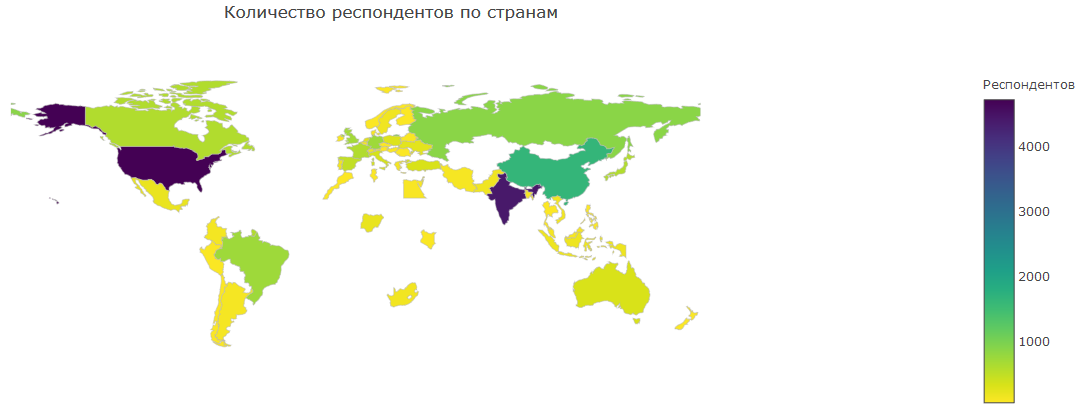
Auf dieser Karte sehen Sie die Anzahl der in verschiedenen Ländern befragten Personen. Der Großteil sind Amerika und Indien. Gegenwärtig kann Amerika vielleicht als führend in der DS bezeichnet werden, und dieses Gebiet ist dort schon früher populär geworden, was so viele Menschen erklärt. Indien ist ein Land mit einer riesigen Bevölkerung, die sich seit langem mit IT befasst. Dank der Kurse von Siraj Raval gewinnt DS an Popularität und zieht eine große Anzahl von Indern an. China bleibt weit zurück, aber ich denke, das liegt an der Nähe des Internets.
In Russland, Kanada, Brasilien und Europa gibt es auch ziemlich viele DS, aber in diesen Ländern ist die Bevölkerung viel kleiner, daher können sie hinsichtlich der Anzahl der Kaggle-Teilnehmer noch nicht mithalten.
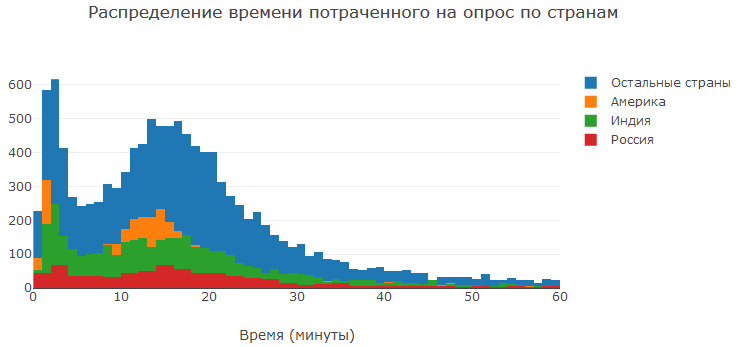
Mal sehen, wie viel Zeit die Leute für die Umfrage aufgewendet haben. Wie Sie sehen, haben viele Menschen 10 bis 20 Minuten mit der Umfrage verbracht, was für eine nachdenkliche Antwort auf Fragen völlig ausreicht. Die Befragten beantworteten die Fragen offenbar in weniger als ein paar Minuten sofort oder fast sofort. Jemand mag die Umfrage vielleicht nicht, jemand ist möglicherweise zu faul, um sie zu beantworten, jemand wollte die Frage nach seinem Geschlecht nicht beantworten (mehr dazu weiter unten). Im Allgemeinen gab es immer noch Menschen, die zehn Stunden an der Umfrage teilgenommen haben. Sie haben wahrscheinlich nur den offenen Tab vergessen :)
Alters- und Geschlechtsstruktur
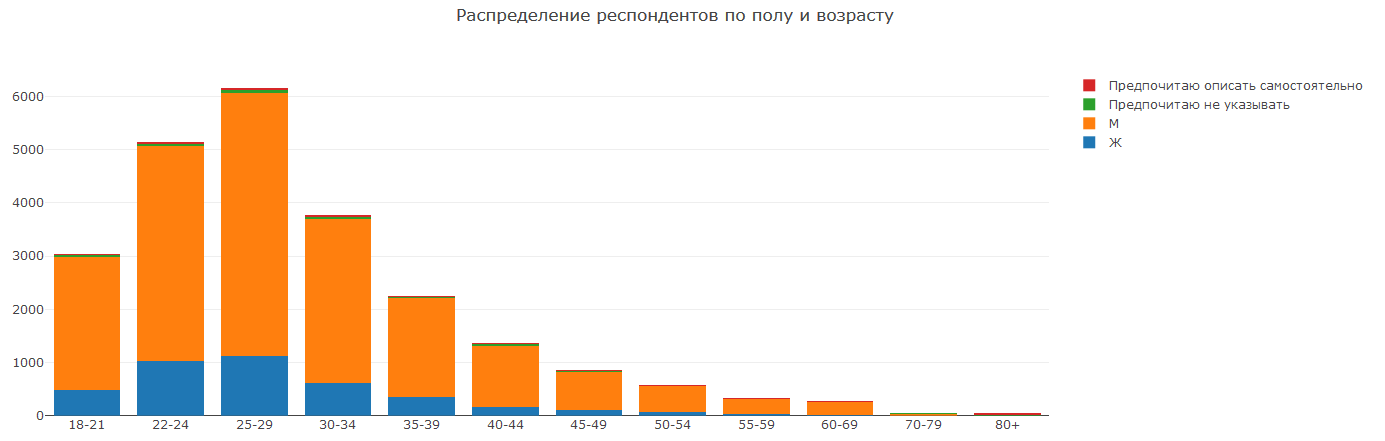
Im Allgemeinen ist das Bild nicht überraschend. Vor allem junge Menschen im Alter von 22 bis 29 Jahren oder sogar 18 bis 34 Jahren nehmen an Kaggle teil. Dies sind Schüler, Studenten und Absolventen. Höchstwahrscheinlich versuchen alle, sich Wissen anzueignen oder beeindruckende Ergebnisse zu erzielen, um sich bei der Arbeitssuche einen Vorteil zu verschaffen. Es gibt deutlich mehr Männer als Frauen. Dies ist im Allgemeinen nicht überraschend, da unsere Sphäre IT, Mathematik und andere Bereiche kombiniert, in denen seit langem ein Ungleichgewicht zwischen den Geschlechtern besteht. Muss aktiv etwas unternommen werden, um dieses Ungleichgewicht zu korrigieren? Ich möchte diesen Artikel lieber nicht diskutieren.
Es ist erwähnenswert, dass es auch möglich war, das Geschlecht nicht oder selbst anzugeben. Schauen wir uns die beliebtesten Optionen an:
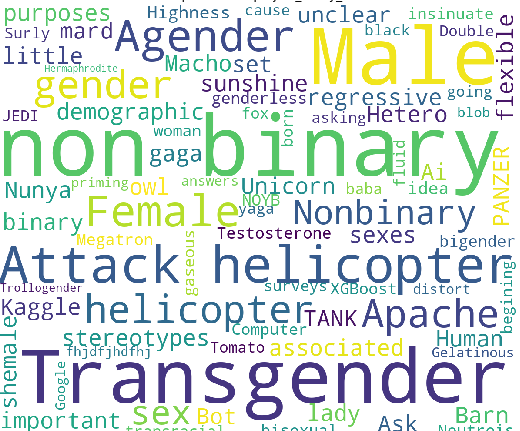
Unter den Antworten in freier Form:
- nicht binär (ausreichend)
- Kampfhubschrauber (cool! Ich würde meine Eltern wirklich gerne sehen)
- Männlich (warum nicht einfach diese Option wählen?)
- Wer bist du, um anzudeuten, dass ich ein Geschlecht habe? (Nun, weil du ein Mensch bist?)
- Kaggle (zumindest nicht kagglosexuell)
- Eure Hoheit (Sie haben diese Frage definitiv nicht mit anderen verwechselt?)
- Ein bisschen Sonnenschein. :) (es ist so süß!)
- Doppelter Mann (gerader Macho!)
- Mann und Frau sind Geschlechter, nicht Geschlecht. Geschlecht ist eine regressive Reihe von Stereotypen, die mit unserem Geschlecht verbunden sind. Fragen Sie, welches Geschlecht wir für demografische Zwecke haben, ob dies wichtig ist. (SWJ erkannt!)
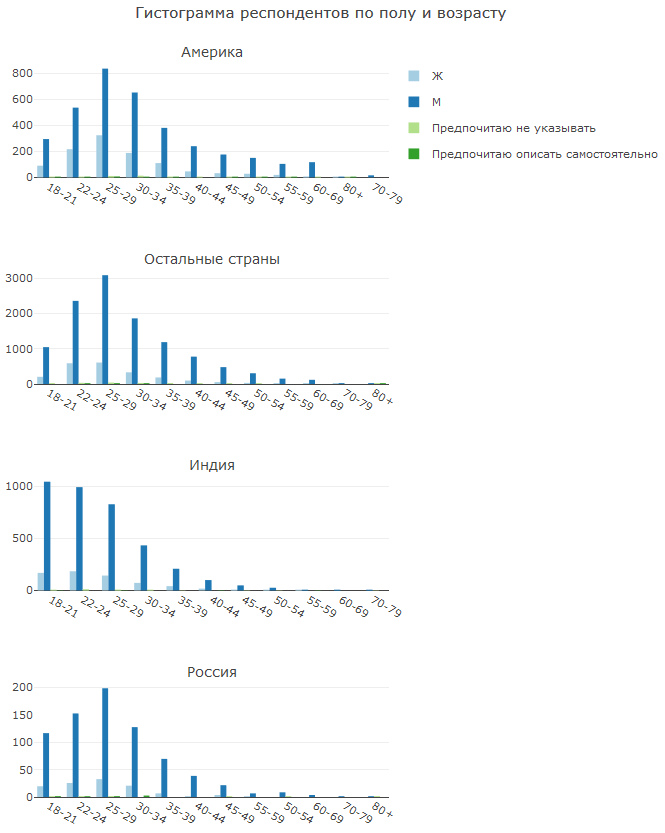
Es ist sehr interessant, die Unterschiede in der Alters- und Geschlechtsstruktur der verschiedenen Länder zu betrachten.
In Amerika ist der Frauenanteil höher als in anderen Ländern. Dies liegt daran, dass in den letzten Jahren ein aktiver Kampf gegen die "Ungleichheit der Geschlechter" stattgefunden hat. Ob sie es braucht oder nicht, ist eine Frage, aber die Ergebnisse sind sichtbar.
Indien zeichnet sich durch eine große Anzahl junger DS aus. Es scheint, dass die Jungs im Voraus über die Zukunft nachdenken und Fähigkeiten von Kindheit an pumpen. Später werden wir sehen, dass das Bildungssystem in Indien zu wünschen übrig lässt.
Russland als Ganzes ähnelt anderen Ländern.
Bildung

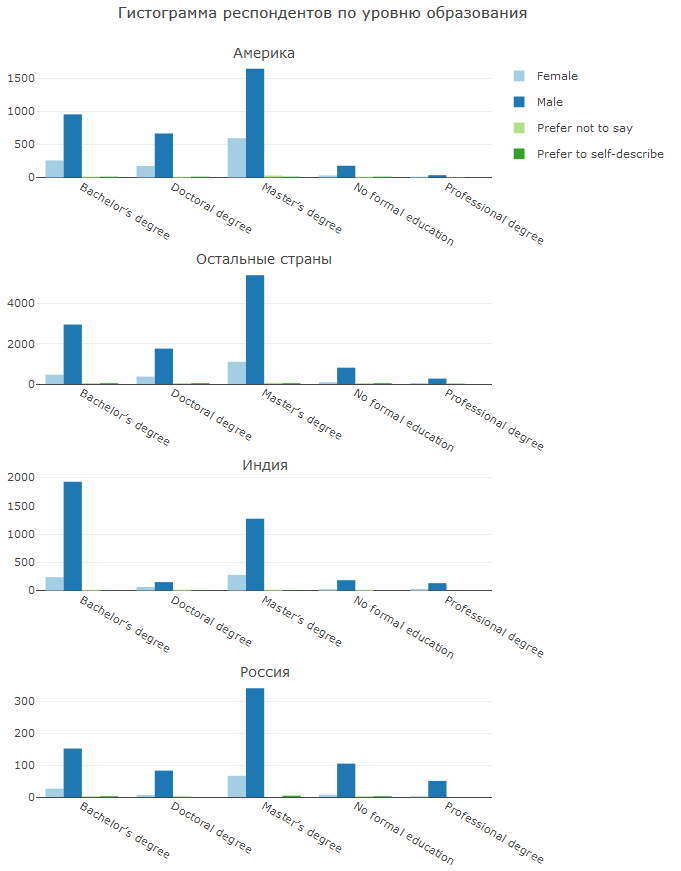

Wie bereits erwähnt, gibt es in Indien einen hohen Anteil an Studenten oder Junggesellen, aber es gibt praktisch keine Inhaber einer Promotion. Russland zeichnet sich dadurch aus, dass viele DS keine formelle Ausbildung haben (oder nicht antworten wollten). Im Allgemeinen ist dies beeindruckend - anscheinend konnten sie mit ihrer harten Arbeit und Ausdauer in die DS-Sphäre eintreten.
Es ist interessant zu sehen, wie DS in verschiedenen Ländern aus verschiedenen Richtungen erscheint. CS, IT und Mathematik / Statistik sind in allen Ländern vorherrschend, aber in Indien gibt es eine Tendenz in technischer Richtung, in Amerika ist die Geschäftsdisziplin (einschließlich Wirtschaft) wichtiger und in Russland ist auch die Physik wichtiger.
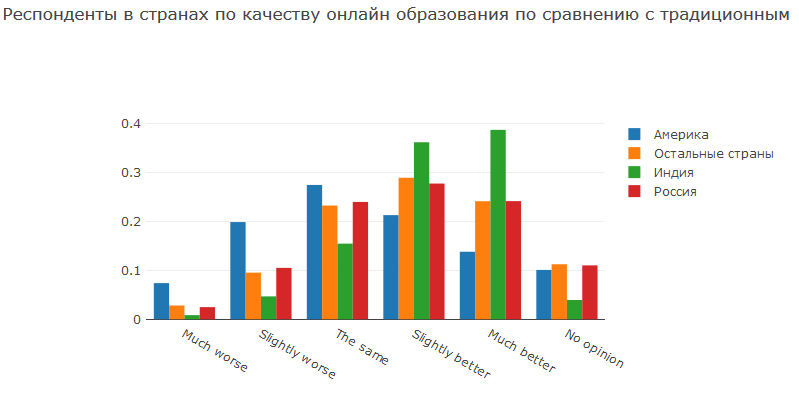
In dieser Frage wurden die Teilnehmer gefragt, ob die Qualität der Kurse auf Online-Plattformen besser oder schlechter ist als die der traditionellen Bildung. Und hier sehen Sie den Unterschied zwischen den Ländern. Die Bildung in Indien ist schlecht. Vielleicht gibt es einfach nicht genug Lehrer, vielleicht ist die Qualität der Ausbildung eher gering, auf jeden Fall bevorzugen die meisten Inder Online-Kurse. Amerika hat ein entwickeltes Bildungssystem, daher glaubt fast ein Drittel der Menschen, dass die Universitätsausbildung von höherer Qualität ist. In Russland und dem Rest der Welt ist die Qualität der traditionellen Bildung nicht schlecht und den Wettbewerbern fast unterlegen.
Berufsbezeichnung
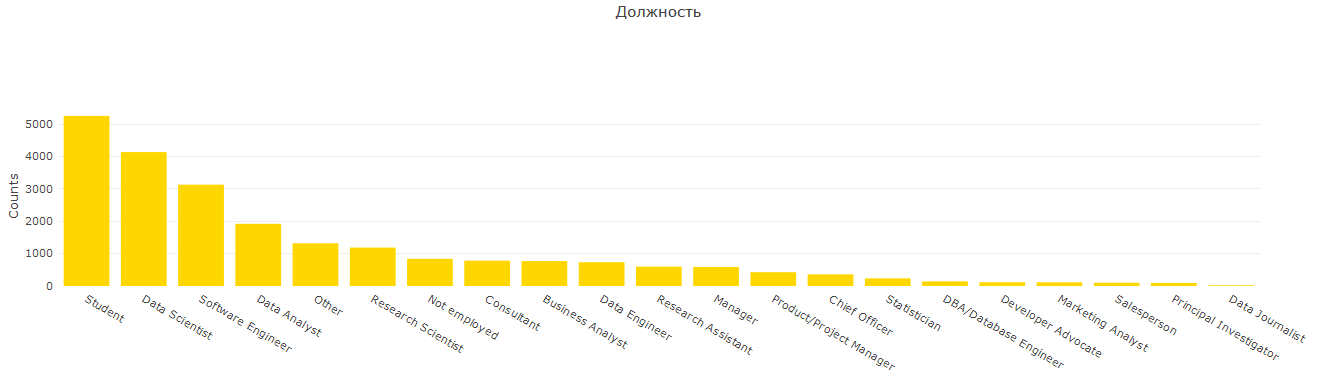
Als Teil einer der Fragen, die sie gestellt haben, um die Position anzugeben, scheint es mir, dass für die Aufgaben dieses Berichts so viele Optionen einfach nicht benötigt werden. Nach einigem Überlegen bildete ich 7 Gruppen und bekam folgendes Bild:
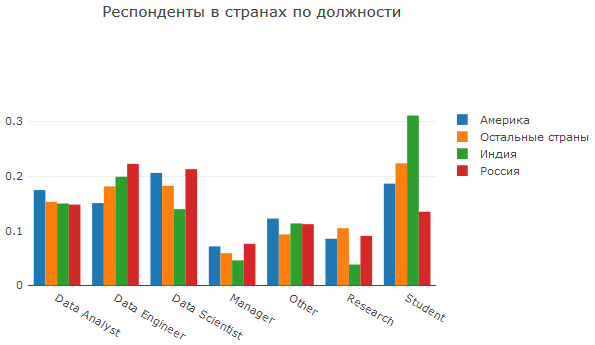
Hier sehen wir eine weitere Bestätigung, dass viele Huggle-Indianer Studenten und / oder Vertreter technischer Bereiche sind. Amerika zeichnet sich durch seinen Schwerpunkt auf Analytik aus, und Russland zeichnet sich in angewandten Bereichen aus.
Aber schauen wir uns ein detaillierteres Bild an:
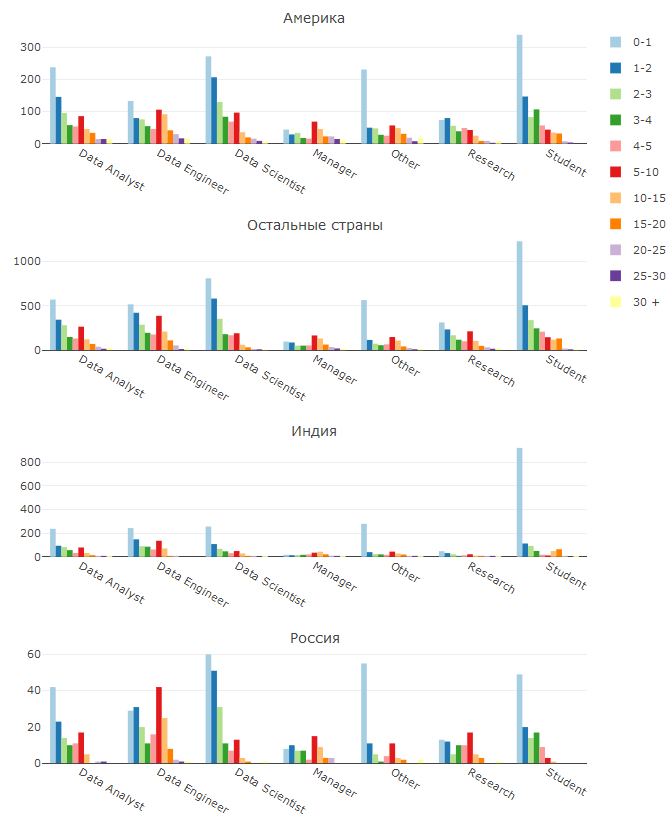
Hier sehen wir, wie lange eine Person in ihrer aktuellen Position gearbeitet hat.
Das erste, was auffällt - die überwiegende Mehrheit der Menschen in allen Positionen sind Neulinge. Ich sehe zwei Erklärungen für diese Tatsache: entweder Hochschulabsolventen oder eine Änderung des Arbeitsumfangs. Hyp auf DS / ML begann vor kurzem und scheint mir immer stärker zu werden, was dazu führt, dass immer mehr Menschen eine neue Richtung einschlagen und ihre eigene künstliche Intelligenz schaffen wollen (weil Menschen außerhalb von DS selten erkennen, dass es keine KI geben wird und nicht kommen wird Jahre).
Ein weiteres interessantes Phänomen ist ein ziemlich großer Anteil erfahrener Dateningenieure. Ich nehme an, dass viele erfahrene Programmierer beschlossen haben, auf DS umzusteigen, aber DE war ihnen näher - die meisten verfügbaren Fähigkeiten eignen sich für die Ausgabe von ML-Lösungen in der Produktion. Es ist interessant, dass in Russland der Anteil von DE aus 5-10 und 10-15 Jahren Erfahrung ziemlich hoch ist. Anscheinend handelt es sich dabei um leitende Entwicklungen in Java und anderen Sprachen, die für Hochlastsysteme sehr gefragt sind. Persönlich bin ich von dem hohen Anteil erfahrener Forscher in Russland separat überrascht, bis ich die Gründe dafür verstehe.
Amerika zeichnet sich unter anderem durch einen hohen Anteil an Analysten aus. Dafür gibt es viele Gründe: Die Tatsache, dass DS in Amerika häufig für analytische Positionen verwendet wird, und die Tatsache, dass in einer Reihe großer Unternehmen ein Datenanalyst tatsächlich DS-Arbeiten ausführt und dass Statistiken umgeschult werden können.
Da es sich um Arbeit handelt, können wir nur die Frage des Gehalts ansprechen.
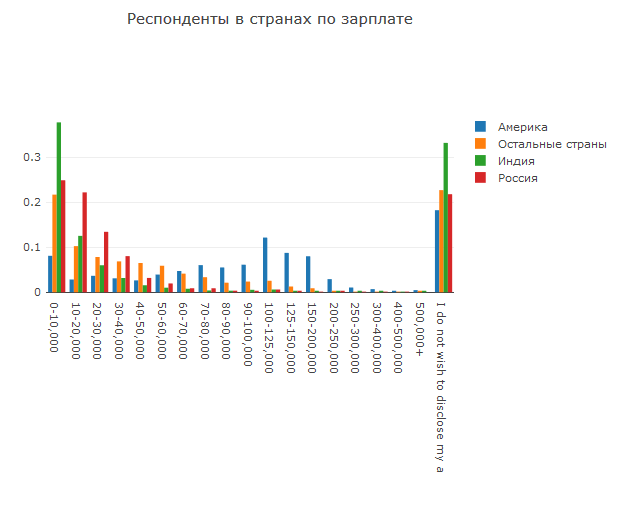
Hier wird alles erwartet: Die Gehälter in Indien sind am niedrigsten, in Russland etwas höher und die amerikanischen Gehälter am höchsten.
Selbstvertrauen

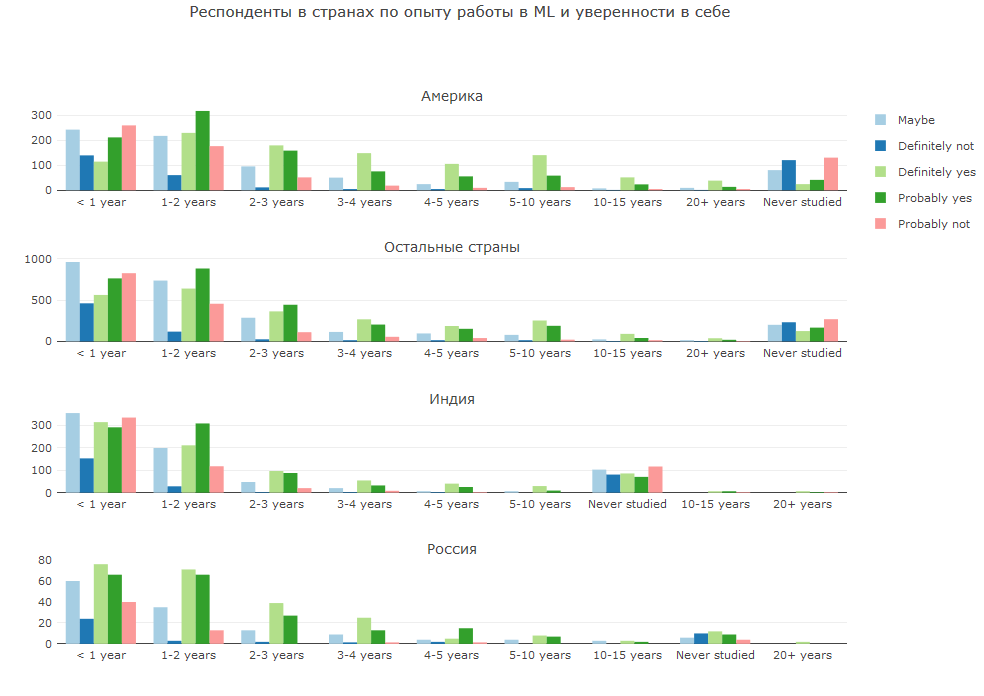
Die Kombination der Antworten auf 2 Fragen erschien mir sehr interessant. Die erste Frage ist die Erfahrung in ML, die zweite ist, ob Sie sich als DS betrachten. Hier können Sie entweder einen Unterschied in der Weltanschauung und Selbstwahrnehmung oder ein anderes Verständnis von Themen beobachten.
In den meisten Ländern haben Neuankömmlinge mit weniger als zweijähriger Erfahrung eine gemischte Meinung - jemand ist bereits selbstbewusst, jemand ist sehr zweifelhaft. Mit zunehmender Erfahrung wächst das Selbstvertrauen. In Russland betrachtet sich die überwiegende Mehrheit der Anfänger als DS, aber mit dem Erfahrungsgewinn nimmt das Vertrauen in diese ab.
Weitere Fragen werden gestellt, bei denen mehrere Antworten angegeben werden könnten, sodass die Summe der Aktien durchaus mehr als 100% ergeben kann
Ressourcen besucht
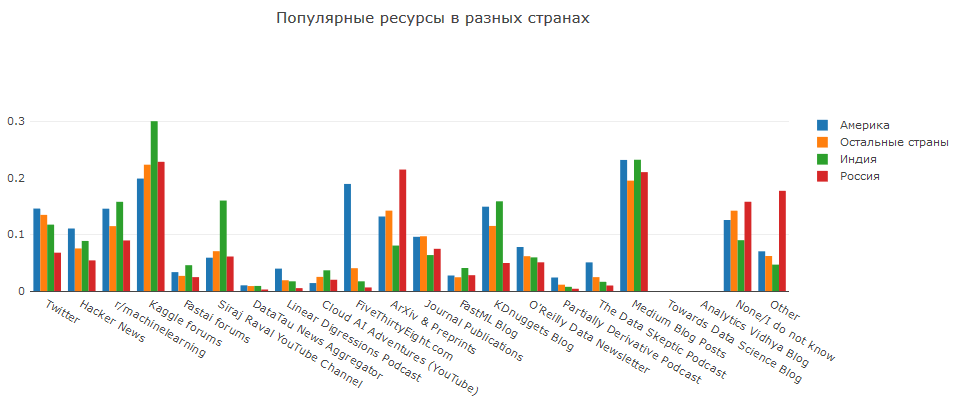
Kaggle und Medium respektieren alles. In Russland lesen sie gerne Artikel über ArXiV, in Amerika bevorzugen sie https://fivethirtyeight.com (und sie besuchen es fast nie in anderen Ländern) und in Indien lieben sie Siraj.
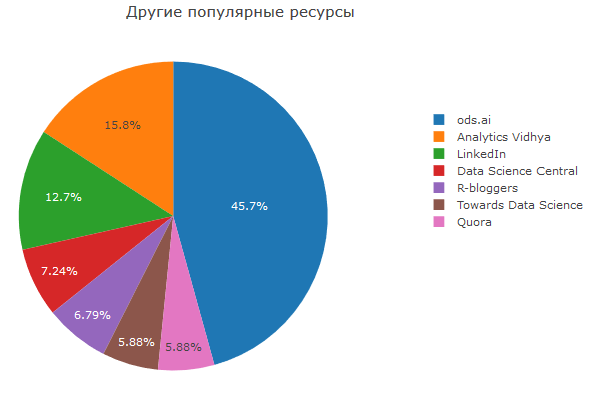
Ich möchte auch ods.ai erwähnen, das sich als die beliebteste Ressource unter den manuell angegebenen herausstellte. Wer noch nicht in unserer Community ist, mach mit :)
IDE und Programmiersprachen


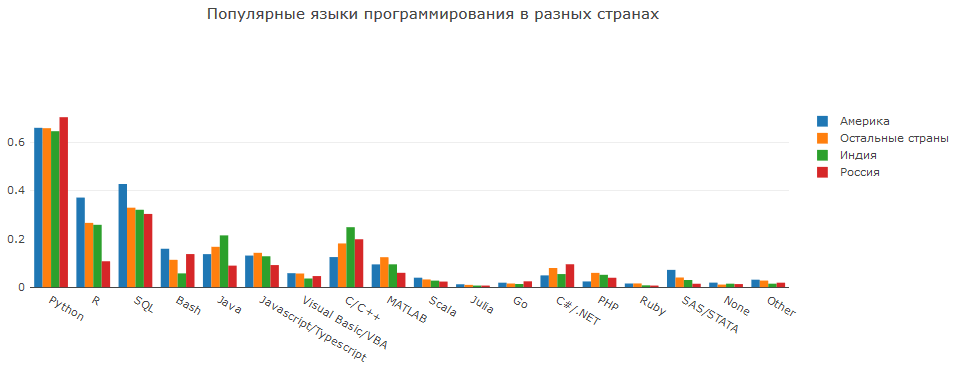
In Bezug auf die Verwendung von IDEs können Personen in zwei Hauptgruppen unterteilt werden: Verwendung von IDEs mit integrierter Visualisierung (Jupyter Notebook, RStudio, Spyder) und Verwendung klassischer IDEs (VS Code, Vim).
Amerika zeichnet sich durch einen hohen Anteil von Analysten aus, die R und damit RStudio verwenden. Es sind jedoch auch Ideen wie Vim oder Atom bekannt. Pycharm ist in Russland nicht nur bei DS, sondern auch bei Programmierern im Allgemeinen beliebt, daher ist die Anzahl der Benutzer nicht überraschend.
SQL, Java, Bash, C / C ++ sind ebenfalls wichtige Sprachen für DS.
Frameworks
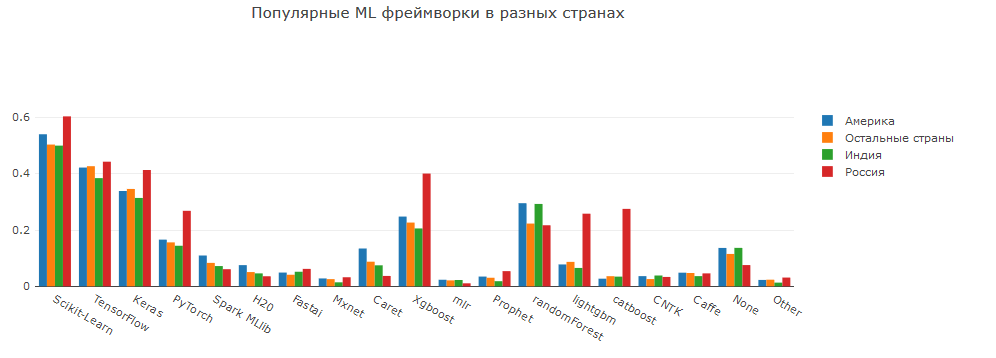
Es ist für mich etwas überraschend, dass der Anteil der Verwendung von DL-Frameworks nicht viel geringer ist als der Anteil der Verwendung von sklearn. Vielleicht fühlen sich viele von neuronalen Netzen angezogen und wollen sie von Anfang an studieren. Vielleicht beginnt ein Unternehmen, Neuronen für seine Aufgaben zu verwenden. und vielleicht ist es nur so, dass viele Kaggle-Teilnehmer daran interessiert sind, Wettbewerbe in Bildern und Texten auszuprobieren.
Unabhängig davon möchte ich auf den hohen Anteil der Menschen hinweisen, die in Russland Bibliotheken mit Pytorch- und Gradientenverstärkung verwenden. LGB / XGB / Catboost sind die bekannteste Implementierung der Gradientenverstärkung und weisen bei Tabellendaten eine hohe Qualität auf. Pytorch erschien vor langer Zeit, gewann aber in den letzten 1-2 Jahren an Popularität.
Visualisierung
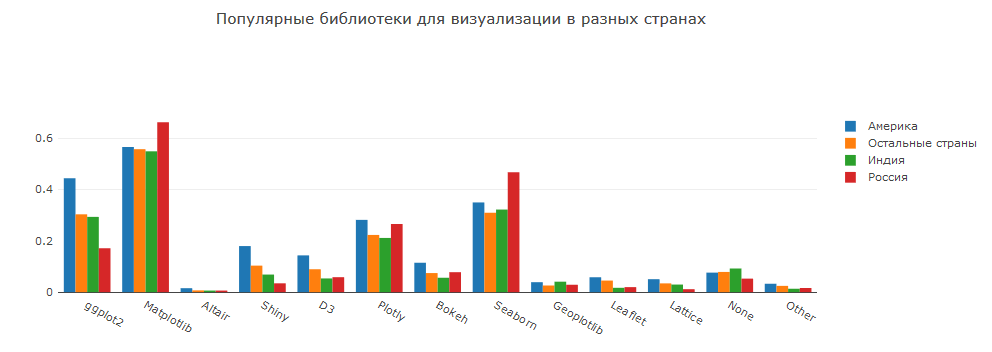
Was für eine Datenanalyse ohne Visualisierungen! Im Allgemeinen ist das Bild nicht überraschend. R ist ggplot2 und glänzend. Python ist matplotlib + seaborn, plotly / bokeh.
Mit D3 können Sie coole Visualisierungen erstellen, aber es ist ziemlich schwierig, damit zu arbeiten.
Altair ist eine Bibliothek auf Vega-Lite. Ich hoffe, dass sie in Zukunft dank der interessanten interaktiven Visualisierungen an Popularität gewinnen wird.
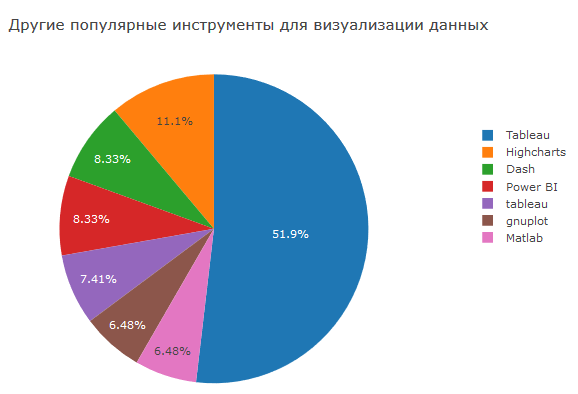
Tableau und andere BI-Software sind nach wie vor beliebt, was nicht verwunderlich ist. Hierbei handelt es sich um hochwertige Lösungen, die unterstützt werden und sich in alles integrieren lassen.
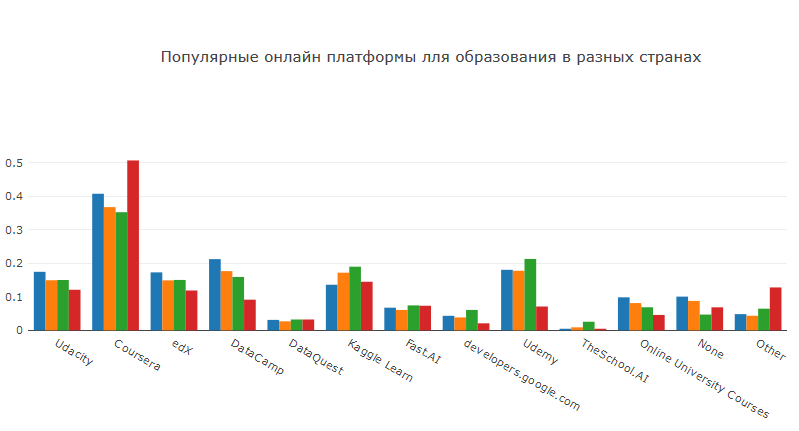
Coursera ist Marktführer bei Online-Bildungskursen. Dort finden Sie Kurse zu fast jedem Thema und Niveau. Ein wichtiger Faktor ist, dass Sie finanzielle Unterstützung beantragen und kostenlos Kurse belegen können. Udacity, Udemy und edX sind weniger beliebt, aber Sie können auch eine große Anzahl interessanter Kurse auf ihnen finden. Kaggle hat vor einiger Zeit seine eigene Bildungsinitiative ins Leben gerufen. Das Schöne ist, dass die Kurse in Form von Kerneln erstellt werden, wodurch die Verwendung der Funktionen von Kaggle geübt wird. Kurse von DataCamp haben ein einzigartiges Format, mit dem Sie zu bestimmten Themen punktgenau üben können. Es ist jedoch unwahrscheinlich, dass diese Plattform fundiertes Wissen vermittelt.
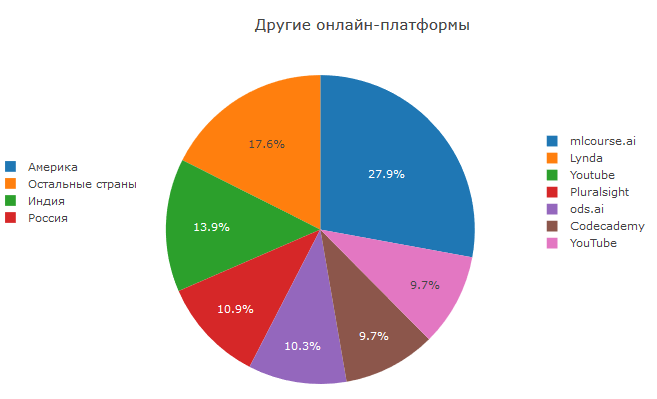
Unabhängig davon ist anzumerken, dass mls.course.ai von ods.ai die beliebteste der von Benutzern angegebenen Optionen ist. Vor kurzem endete die vierte Sitzung des Kurses, in der mehr als 7,5 Tausend Personen registriert waren. Aufgrund der Tatsache, dass die Hauptkommunikation in Ruhe stattfindet, endet der Kurs mit einem beeindruckenden Anteil an Personen - deutlich höher als bei anderen kostenlosen ML-Kursen. Dieser Kurs vermittelt nicht nur theoretisches Wissen und komplexe Hausaufgaben, sondern auch die Praxis der Teilnahme an Wettbewerben bei Kaggle.
Interpretationswerkzeuge
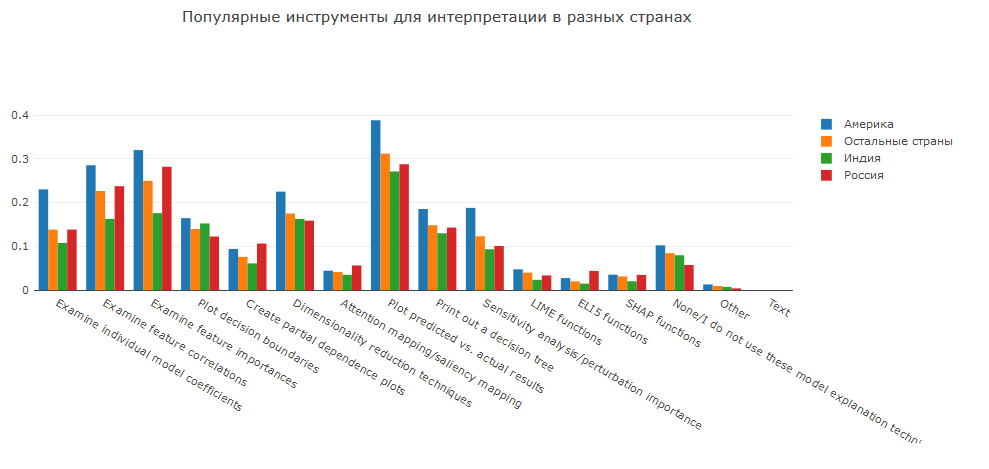
Lassen Sie uns abschließend sehen, wie verschiedene Personen die Ergebnisse der Modelle analysieren.
Eine Analyse der Vorhersagen selbst und ein Vergleich ihrer Verteilung mit der Verteilung der Zielvariablen ist eine grundlegende, aber qualitative Art der Analyse. Wenn Sie die Koeffizienten linearer Modelle oder die Bedeutung von Merkmalen in Holzmodellen untersuchen, können Sie die Merkmale finden, die die Vorhersagen am meisten beeinflussen.
Darüber hinaus sind in letzter Zeit spezielle Frameworks für die Modellanalyse populär geworden: SHAP, LIME und ELI5. Sie ermöglichen es uns, nicht nur einfache Modelle zu erklären, sondern auch einige, die als Black Box gelten.
Zusammenfassung
Wir haben untersucht, wie sich DS in verschiedenen Ländern der Welt voneinander unterscheiden, und herausgefunden, was sie zusammenbringt. Diese Analyse deckt nicht alle verfügbaren Daten ab, sondern zeigt diejenigen, die mir am interessantesten erschienen. Wer möchte, kann diese Daten recherchieren :)
Vielen Dank für Ihre Aufmerksamkeit!