Die offene Semantik der russischen Sprache, über deren Geschichte Sie
hier und
hier lesen können, erhielt ein großes Update. Wir haben genügend Daten gesammelt, um maschinelles Lernen zusätzlich zu dem gesammelten Markup anzuwenden und ein semantisches Sprachmodell zu erstellen. Was dabei herauskam, sehen Sie unter dem Schnitt.

Was machen wir
Nehmen Sie zwei Wortgruppen:
- Laufen, Schießen, Plotten, Wandern, Gehen;
- Läufer, Fotograf, Ingenieur, Tourist, Sportler.
Es ist für eine Person nicht schwierig festzustellen, dass die erste Gruppe Substantive enthält, die
Aktionen oder Ereignisse benennen. in der zweiten -
Menschen anrufen. Unser Ziel ist es, eine Maschine zu lehren, um solche Probleme zu lösen.
Dazu müssen Sie:
- Finden Sie heraus, welche natürlichen Klassen in der Sprache existieren.
- Markieren Sie eine ausreichende Anzahl von Wörtern zum Thema Zugehörigkeit zu den Klassen in Absatz 1 .
- Erstellen Sie einen Algorithmus, der anhand des Markups aus Element 2 lernt und die Klassifizierung in unbekannten Wörtern wiedergibt.
Ist es möglich, dieses Problem mit Hilfe der Verteilungssemantik zu lösen?word2vec ist ein ausgezeichnetes Werkzeug, bevorzugt jedoch die thematische Nähe von Wörtern und nicht die Ähnlichkeit ihrer semantischen Klassen. Um diese Tatsache zu demonstrieren, führen Sie den Algorithmus in Worten aus dem Beispiel aus:
w1 | w2 | cosine_sim | | | | | | 1.0000 | | | 0.6618 | | | 0.5410 | | | 0.3389 | | | 0.1531 | | | 0.1342 | | | 0.1067 | | | 0.0681 | | | 0.0458 | | | 0.0373 | | | | | | 1.0000 | | | 0.5782 | | | 0.2525 | | | 0.2116 | | | 0.1644 | | | 0.1579 | | | 0.1342 | | | 0.1275 | | | 0.1100 | | | 0.0975 | | | | | | 1.0000 | | | 0.3575 | | | 0.2116 | | | 0.1587 | | | 0.1207 | | | 0.1067 | | | 0.0889 | | | 0.0794 | | | 0.0705 | | | 0.0430 | | | | | | 1.0000 | | | 0.1896 | | | 0.1753 | | | 0.1644 | | | 0.1548 | | | 0.1531 | | | 0.0889 | | | 0.0794 | | | 0.0568 | | | -0.0013 | | | | | | 1.0000 | | | 0.5410 | | | 0.3442 | | | 0.2469 | | | 0.1753 | | | 0.1650 | | | 0.1207 | | | 0.1100 | | | 0.0673 | | | 0.0642 | | | | | | 1.0000 | | | 0.6618 | | | 0.4909 | | | 0.3442 | | | 0.1548 | | | 0.1427 | | | 0.1422 | | | 0.1275 | | | 0.1209 | | | 0.0705 | | | | | | 1.0000 | | | 0.5782 | | | 0.3687 | | | 0.2334 | | | 0.1911 | | | 0.1587 | | | 0.1209 | | | 0.0642 | | | 0.0373 | | | -0.0013 | | | | | | 1.0000 | | | 0.3575 | | | 0.2334 | | | 0.1579 | | | 0.1503 | | | 0.1447 | | | 0.1422 | | | 0.0673 | | | 0.0568 | | | 0.0458 | | | | | | 1.0000 | | | 0.3687 | | | 0.2525 | | | 0.1896 | | | 0.1650 | | | 0.1503 | | | 0.1495 | | | 0.1427 | | | 0.0681 | | | 0.0430 | | | | | | 1.0000 | | | 0.4909 | | | 0.3389 | | | 0.2469 | | | 0.1911 | | | 0.1495 | | | 0.1447 | | | 0.0975 | | | 0.0889 | | | 0.0889 |
Wie offene Semantik dieses Problem löstEine Suche im
semantischen Wörterbuch ergibt folgendes Ergebnis:
| | | | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | ABSTRACT:ACTION | | HUMAN | | HUMAN | | HUMAN | | HUMAN | | HUMAN |
Was wurde getan und wo kann ich herunterladen?
Das Ergebnis der im
Repository auf dem GC veröffentlichten und zum Download verfügbaren Arbeit ist eine Beschreibung der Klassenhierarchie und des Markups (manuell und automatisch) der Substantive für diese Klassen.
Um sich mit dem Datensatz vertraut zu machen, können Sie den interaktiven Navigator (Link im Repository) verwenden. Es gibt auch eine vereinfachte Version des Satzes, in der wir die gesamte Hierarchie entfernt und jedem Wort ein einziges großes semantisches Tag zugewiesen haben: "Menschen", "Tiere", "Orte", "Dinge", "Aktionen" usw.
Link zu Github: offene Semantik der russischen Sprache (Datensatz) .
Über Wortklassen
Bei Klassifizierungsproblemen werden die Klassen selbst häufig durch das zu lösende Problem bestimmt, und die Arbeit des Dateningenieurs besteht darin, einen erfolgreichen Satz von Attributen zu finden, auf denen Sie ein Arbeitsmodell erstellen können.
In unserem Problem sind Wortklassen streng genommen nicht im Voraus bekannt. Hier hilft eine große Schicht semantischer Forschung, die von in- und ausländischen Linguisten durchgeführt wird, die Vertrautheit mit vorhandenen semantischen Wörterbüchern und WordNets.
Dies ist eine gute Hilfe, aber die endgültige Entscheidung wird bereits in unserer eigenen Forschung getroffen. Hier ist das Ding. Viele semantische Ressourcen wurden im Zeitalter vor dem Computer geschaffen (zumindest im modernen Verständnis des Computers), und die Wahl der Klassen wurde weitgehend von der Sprachintuition ihrer Schöpfer bestimmt. Ende des vorigen Jahrhunderts wurde WordNet aktiv für die automatische Textanalyse eingesetzt, und viele neu erstellte Ressourcen wurden für bestimmte praktische Anwendungen geschärft.
Das Ergebnis war, dass diese Sprachressourcen gleichzeitig sowohl sprachliche als auch extralinguistische, enzyklopädische Informationen über die Einheiten der Sprache enthalten. Es ist logisch anzunehmen, dass es unmöglich ist, ein Modell zu erstellen, das extralinguistische Informationen überprüft und sich ausschließlich auf die statistische Analyse von Texten stützt, da die Datenquelle einfach nicht die erforderlichen Informationen enthält.
Basierend auf dieser Annahme suchen wir nur nach natürlichen Klassen, die anhand eines rein sprachlichen Modells erkannt und automatisch verifiziert werden können. Gleichzeitig ermöglicht die Systemarchitektur das Hinzufügen einer beliebig großen Anzahl zusätzlicher Informationsebenen über Spracheinheiten, was in praktischen Anwendungen nützlich sein kann.
Wir werden das Obige anhand eines konkreten Beispiels demonstrieren, indem wir das Wort „Kühlschrank“ analysieren. Aus dem Sprachmodell können wir herausfinden, dass ein "Kühlschrank" ein materielles Objekt, ein Design, ein Behälter vom Typ "Kiste oder Beutel" ist, d. H. Nicht für die Lagerung von Flüssigkeiten oder Feststoffen ohne zusätzlichen Behälter vorgesehen. Darüber hinaus ist aus diesem Modell nicht klar, dass der "Kühlschrank" eine Ware ist, außerdem ein haltbares Produkt, und es ist auch nicht klar, dass dies ein Artefakt ist, d.h. menschlich gemachtes Objekt. Dies sind nichtsprachliche Informationen, die separat angegeben werden müssen.
Das Ergebnis des Modells für das Wort "Kühlschrank" Warum das alles gebraucht wird
Wie dem auch sei, während des Lernens und Erkennens der Realität reiht eine Person zusätzliche Informationen über die sie umgebenden Objekte und Phänomene auf den natürlichen Rahmen, den sie in ihrer Kindheit gelernt hat. Einige Konzepte sind jedoch universell, unabhängig vom Themenbereich und können erfolgreich wiederverwendet werden.
Sagen wir "Verkäufer" ist eine
Person + eine
funktionale Rolle . In einigen Fällen kann der Verkäufer eine Gruppe von Personen oder eine Organisation sein, die Subjektivität bleibt jedoch immer erhalten. Andernfalls ist die Zielaktion nicht möglich. Die Wörter "Austausch" oder "Training" beziehen sich auf Aktionen, d.h. Sie haben Teilnehmer, Dauer und Ergebnis. Der genaue Inhalt dieser Aktionen kann je nach Situation und Themenbereich erheblich variieren, bestimmte Aspekte sind jedoch unveränderlich. Dies ist der Sprachrahmen, auf dem variables extralinguistisches Wissen basiert.
Unser Ziel ist es, die maximal verfügbaren intralinguistischen Informationen zu finden und zu erforschen und auf dieser Grundlage ein Erklärungsmodell der Sprache aufzubauen. Dies wird die vorhandenen Algorithmen für die automatische Textverarbeitung verbessern, einschließlich so komplexe wie das Auflösen von lexikalischen Mehrdeutigkeiten, das Auflösen von Anaphoren, komplizierte Fälle von morphologischer Markierung. Dabei werden wir uns notwendigerweise irgendwo gegen die Notwendigkeit ausruhen, außersprachliches Wissen anzuziehen, aber zumindest werden wir wissen, wo die Grenze liegt, wenn interne Sprachkenntnisse nicht mehr ausreichen.
Klassifizierung und Schulung, Satz von Attributen
Derzeit arbeiten wir nur mit Substantiven. Wenn wir also unten „Wort“ sagen, meinen wir Zeichen, die sich nur auf diesen Teil der Sprache beziehen. Da wir uns entschieden haben, nur intralinguistische Informationen zu verwenden, werden wir mit Texten arbeiten, die mit morphologischen Markups ausgestattet sind.
Als Zeichen nehmen wir alle möglichen Mikrokontexte, in denen dieses Wort vorkommt. Für Substantive sind dies:
- APP + X (schönes X: Augen)
- GLAG + X (vdite X: Thread)
- VL + PRED + X (X eingeben: Tür)
- X + SUSCH_ROD (X: Tabellenkante)
- SUSHCH + X_ROD (Griff X: Säbel)
- X_ SUBJECT + GL (X: Die Handlung entwickelt sich)
Es gibt mehr Arten von Mikrokontexten, aber die oben genannten sind die häufigsten und liefern bereits beim Lernen ein gutes Ergebnis.
Alle Mikrokontexte werden auf die Grundform reduziert und wir setzen daraus eine Reihe von Merkmalen zusammen. Als nächstes setzen wir für jedes Wort einen Vektor zusammen, dessen
i-te Koordinate mit dem Auftreten eines gegebenen Wortes im
i-ten Mikrokontext korreliert.
Mikrokontexttabelle für das Wort "Rucksack" | | | | | | | | | VBP_ | 3043 | 1.0000 | | ADJ | 2426 | 0.9717 | | NX_NG | 1438 | 0.9065 | | VBP_ | 1415 | 0.9045 | | VBP__ | 1300 | 0.8940 | | NX_NG | 1292 | 0.8932 | | NX_NG | 1259 | 0.8900 | | ADJ | 1230 | 0.8871 | | ADJ | 1116 | 0.8749 | | ADJ | 903 | 0.8485 | | ADJ | 849 | 0.8408 | | NX_NG | 814 | 0.8356 | | ADJ | 795 | 0.8326 | | ADJ | 794 | 0.8325 | | VBP_ | 728 | 0.8217 | | ADJ | 587 | 0.7948 | | ADJ | 587 | 0.7948 | | VBP__ | 567 | 0.7905 | | VBP_ | 549 | 0.7865 | | VBP__ | 538 | 0.7840 | | VBP_ | 495 | 0.7736 | | VBP_ | 484 | 0.7708 | | NX_NG | 476 | 0.7687 | | ADJ | 463 | 0.7652 | | NX_NG | 459 | 0.7642 |
Zielwert, semantische Slicing-Hierarchie
Die Sprache verfügt über natürliche Mechanismen für die Wiederverwendung von Wörtern, wodurch ein Phänomen wie die Polysemie entsteht. Darüber hinaus werden manchmal nicht nur einzelne Wörter wiederverwendet, sondern es wird eine metaphorische Übertragung ganzer Konzepte vorgenommen. Dies macht sich insbesondere beim Übergang von materiellen zu abstrakten Konzepten bemerkbar.
Diese Tatsache diktiert die Notwendigkeit einer hierarchischen Klassifizierung, bei der semantische Abschnitte in einer Baumstruktur angeordnet sind und die Partition in jedem internen Knoten auftritt. Auf diese Weise können Sie vieldeutiger mit Mehrdeutigkeiten in Mikrokontexten umgehen.
Beispiele für metaphorische KonzeptübertragungNeben der Lösung dringender praktischer Probleme der Computerlinguistik sollen in unserer Arbeit das Wort und verschiedene sprachliche Phänomene untersucht werden. Die metaphorische Übertragung von Konzepten von der realen Ebene auf die abstrakte Ebene ist ein Phänomen, das kognitiven Linguisten bekannt ist. So ist beispielsweise eines der hellsten Konzepte in der materiellen Welt die Klasse "Container" (in der russischsprachigen Literatur wird sie oft als "Container" bezeichnet).
Eine andere allgegenwärtige ontologische Metapher ist die Metapher des Containers oder Containers, die impliziert, Grenzen im Kontinuum unserer Erfahrung zu ziehen und sie durch räumliche Kategorien zu verstehen. Den Autoren zufolge wird die Art und Weise, wie ein Mensch die Welt um sich herum wahrnimmt, durch seine Erfahrung im Umgang mit diskreten materiellen Objekten und insbesondere durch seine Wahrnehmung von sich selbst und seinem Körper bestimmt. Der Mensch ist eine Kreatur, die durch die Haut vom Rest der Welt abgegrenzt ist. Er ist ein Container, und deshalb ist es für ihn üblich, andere Wesenheiten als Container mit einem inneren Teil und einer äußeren Oberfläche wahrzunehmen.
Skrebtsova T. G. Kognitive Linguistik: Klassische Theorien, Neu
Ansätze
Das von uns konstruierte Modell arbeitet in einem einzigen Raum von Attributen und ermöglicht es uns, aus realen Beispielen zu lernen und Vorhersagen im Bereich der Zusammenfassung zu treffen. Auf diese Weise können Sie die oben beschriebene Übertragung durchführen. So sind beispielsweise die folgenden Wörter abstrakte Container, was mit der intuitiven Idee übereinstimmt:

Ein weiteres interessantes Beispiel ist die Übertragung des Begriffs "Flüssigkeit" in die Sphäre des Immateriellen:
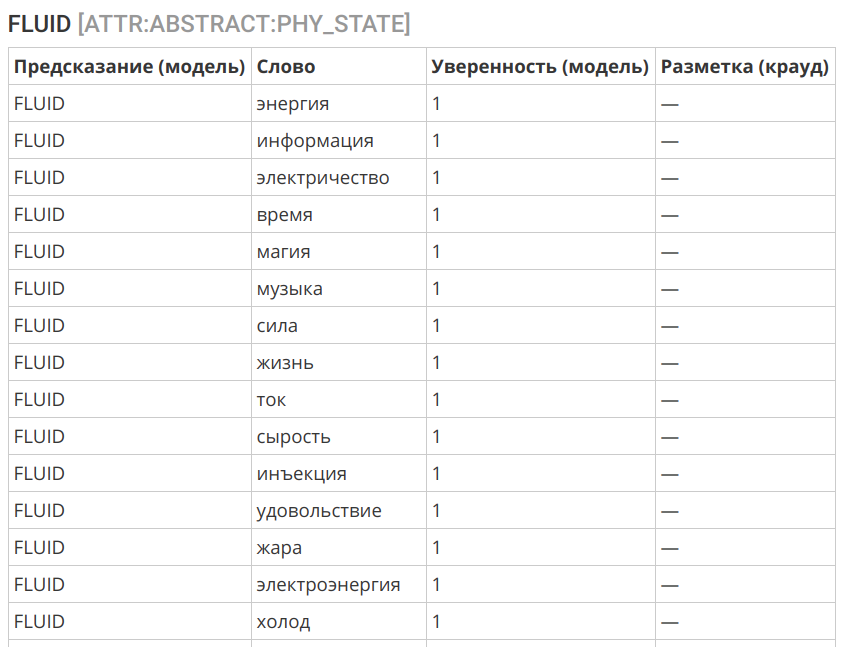
Algorithmusauswahl
Als Algorithmus verwendeten wir die logistische Regression. Dies ist auf mehrere Faktoren zurückzuführen:
- Auf die eine oder andere Weise enthält das anfängliche Markup eine bestimmte Anzahl von Fehlern und Rauschen.
- Zeichen können unausgeglichen sein und auch Fehler enthalten - Polysemie und metaphorische (bildliche) Verwendung des Wortes.
- Die vorläufige Analyse legt nahe, dass eine ausreichend ausgewählte Schnittstelle mit einem relativ einfachen Algorithmus repariert werden sollte.
- Eine gute Interpretierbarkeit des Algorithmus ist wichtig.
Der Algorithmus zeigte eine recht gute Genauigkeit:
Protokolle des Markup-Algorithmus == ENTITY == slice | label | count | correctCount | accuracy | | | | | | ENTITY | PHYSICAL | 12249 | 11777 | 0.9615 | ENTITY | ABSTRACT | 9854 | 9298 | 0.9436 | | | | | | | | | | 0.9535 | == PHYSICAL:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ROLE | ORGANIC | 7001 | 6525 | 0.9320 | PHYSICAL:ROLE | INORGANIC | 3805 | 3496 | 0.9188 | | | | | | | | | | 0.9274 | == PHYSICAL:ORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:ORGANIC:ROLE | HUMAN | 4879 | 4759 | 0.9754 | PHYSICAL:ORGANIC:ROLE | ANIMAL | 675 | 629 | 0.9319 | PHYSICAL:ORGANIC:ROLE | FOOD | 488 | 411 | 0.8422 | PHYSICAL:ORGANIC:ROLE | ANATOMY | 190 | 154 | 0.8105 | PHYSICAL:ORGANIC:ROLE | PLANT | 285 | 221 | 0.7754 | | | | | | | | | | 0.9474 | == PHYSICAL:INORGANIC:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:INORGANIC:ROLE | CONSTRUCTION | 1045 | 933 | 0.8928 | PHYSICAL:INORGANIC:ROLE | THING | 2385 | 2123 | 0.8901 | PHYSICAL:INORGANIC:ROLE | SUBSTANCE | 399 | 336 | 0.8421 | | | | | | | | | | 0.8859 | == PHYSICAL:CONSTRUCTION:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:CONSTRUCTION:ROLE | TRANSPORT | 188 | 178 | 0.9468 | PHYSICAL:CONSTRUCTION:ROLE | APARTMENT | 270 | 241 | 0.8926 | PHYSICAL:CONSTRUCTION:ROLE | TERRAIN | 285 | 253 | 0.8877 | | | | | | | | | | 0.9044 | == PHYSICAL:THING:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:THING:ROLE | WEARABLE | 386 | 357 | 0.9249 | PHYSICAL:THING:ROLE | TOOLS | 792 | 701 | 0.8851 | PHYSICAL:THING:ROLE | DISHES | 199 | 174 | 0.8744 | PHYSICAL:THING:ROLE | MUSIC_INSTRUMENTS | 63 | 51 | 0.8095 | PHYSICAL:THING:ROLE | WEAPONS | 107 | 69 | 0.6449 | | | | | | | | | | 0.8739 | == PHYSICAL:TOOLS:ROLE == slice | label | count | correctCount | accuracy | | | | | | PHYSICAL:TOOLS:ROLE | PHY_INTERACTION | 213 | 190 | 0.8920 | PHYSICAL:TOOLS:ROLE | INFORMATION | 101 | 71 | 0.7030 | PHYSICAL:TOOLS:ROLE | EM_ENERGY | 72 | 49 | 0.6806 | | | | | | | | | | 0.8031 | == ATTR:INORGANIC:WEARABLE == slice | label | count | correctCount | accuracy | | | | | | ATTR:INORGANIC:WEARABLE | NON_WEARABLE | 538 | 526 | 0.9777 | ATTR:INORGANIC:WEARABLE | WEARABLE | 282 | 269 | 0.9539 | | | | | | | | | | 0.9695 | == ATTR:PHYSICAL:CONTAINER == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER | CONTAINER | 636 | 627 | 0.9858 | ATTR:PHYSICAL:CONTAINER | NOT_A_CONTAINER | 1225 | 1116 | 0.9110 | | | | | | | | | | 0.9366 | == ATTR:PHYSICAL:CONTAINER:TYPE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:CONTAINER:TYPE | CONFINED_SPACE | 291 | 287 | 0.9863 | ATTR:PHYSICAL:CONTAINER:TYPE | CONTAINER | 140 | 131 | 0.9357 | ATTR:PHYSICAL:CONTAINER:TYPE | OPEN_AIR | 72 | 64 | 0.8889 | ATTR:PHYSICAL:CONTAINER:TYPE | BAG_OR_BOX | 43 | 31 | 0.7209 | ATTR:PHYSICAL:CONTAINER:TYPE | CAVITY | 30 | 20 | 0.6667 | | | | | | | | | | 0.9253 | == ATTR:PHYSICAL:PHY_STATE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PHY_STATE | SOLID | 308 | 274 | 0.8896 | ATTR:PHYSICAL:PHY_STATE | FLUID | 250 | 213 | 0.8520 | ATTR:PHYSICAL:PHY_STATE | FABRIC | 72 | 51 | 0.7083 | ATTR:PHYSICAL:PHY_STATE | PLASTIC | 78 | 42 | 0.5385 | ATTR:PHYSICAL:PHY_STATE | SAND | 70 | 31 | 0.4429 | | | | | | | | | | 0.7853 | == ATTR:PHYSICAL:PLACE == slice | label | count | correctCount | accuracy | | | | | | ATTR:PHYSICAL:PLACE | NOT_A_PLACE | 855 | 821 | 0.9602 | ATTR:PHYSICAL:PLACE | PLACE | 954 | 914 | 0.9581 | | | | | | | | | | 0.9591 | == ABSTRACT:ROLE == slice | label | count | correctCount | accuracy | | | | | | ABSTRACT:ROLE | ACTION | 1497 | 1330 | 0.8884 | ABSTRACT:ROLE | HUMAN | 473 | 327 | 0.6913 | ABSTRACT:ROLE | PHYSICS | 257 | 171 | 0.6654 | ABSTRACT:ROLE | INFORMATION | 222 | 146 | 0.6577 | ABSTRACT:ROLE | ABSTRACT | 70 | 15 | 0.2143 | | | | | | | | | | 0.7896 |
Fehleranalyse
Fehler, die sich aus der automatischen Klassifizierung ergeben, werden durch drei Hauptfaktoren verursacht:
- Homonymie und Polysemie: Wörter, die den gleichen Typ haben, können unterschiedliche Bedeutungen haben (quälen Sie a und m u ka, stoppen Sie als Prozess und stoppen Sie als Ort ). Dies kann auch die metaphorische Verwendung von Wörtern und Metonymien umfassen (z. B. wird eine Tür als geschlossener Raum klassifiziert - dies ist ein erwartetes Merkmal der Sprache).
- Ungleichgewicht im Zusammenhang mit der Verwendung des Wortes. Einige organische Verwendungen sind möglicherweise nicht in der Originalverpackung enthalten, was zu Klassifizierungsfehlern führt.
- Ungültige Klassengrenze. Sie können Grenzen ziehen, die nicht aus Kontexten berechenbar sind und die die Einbeziehung von außersprachlichem Wissen erfordern. Hier wird der Algorithmus machtlos sein.
In dieser Phase achten wir nur auf Fehler des dritten Typs und passen die ausgewählte Grenze zwischen den Klassen an. Fehler der ersten beiden Typen in einer bestimmten Konfiguration des Systems können nicht beseitigt werden, aber bei einer ausreichenden Menge beschrifteter Daten stellen sie kein großes Problem dar - dies lässt sich an der Genauigkeit des Markups der oberen Projektionen ablesen.
Was weiter
Derzeit deckt der Datensatz die meisten Substantive ab, die in der russischen Sprache existieren und im Korpus in einer ausreichenden Vielfalt von Kontexten vertreten sind. Das Hauptaugenmerk lag auf materiellen Objekten - als die verständlichsten und in wissenschaftlichen Arbeiten ausgearbeiteten. Es bleibt die Aufgabe, das vorhandene Markup unter Berücksichtigung der vom Algorithmus empfangenen Daten zu verfeinern und mit Klassen auf den unteren Ebenen zu arbeiten, bei denen eine Verringerung der Vorhersagegenauigkeit aufgrund einer Verwischung der Grenzen zwischen den Kategorien beobachtet wird.
Aber das ist eine Art Routinearbeit, die immer da ist. Eine qualitativ neue Forschungsebene wird die Möglichkeit betreffen, ein bestimmtes Wort in einen bestimmten Kontext oder Satz zu klassifizieren, wodurch die Phänomene der Homonymie und Polysemie einschließlich der Metapher (bildliche Bedeutungen) berücksichtigt werden können.
Außerdem arbeiten wir derzeit an mehreren verwandten Projekten:
- Wörterbuch der Erkennbarkeit der Wörter RY: Eine Variation des Frequenzwörterbuchs, bei der die Verständlichkeit und Vertrautheit des Wortes als Ergebnis eines Crowdsourcing-Markups bewertet und nicht anhand des Textkörpers berechnet wird.
- Offener Korpus zur Lösung lexikalischer Mehrdeutigkeiten: Basierend auf dem RUSSE 2018 WSI & D Shared Task- Wettbewerb, der im Rahmen der Konferenz Dialogue 2018 durchgeführt wurde , wurde die Nützlichkeit des Korpus mit entfernter lexikalischer Mehrdeutigkeit zum Testen automatischer Algorithmen zur Begriffsklärung und Clusterbildung von Wortbedeutungen deutlich. Wir werden dieses Gremium auch brauchen, um zur im vorherigen Absatz beschriebenen Phase der Arbeit an offener Semantik überzugehen.
Tonwörterbuch der russischen Sprache
Das Tonwörterbuch sind die Wörter und Ausdrücke des ABl., Die durch die Tonalität und Stärke der Schwere der emotional-bewertenden Ladung gekennzeichnet sind. Einfach ausgedrückt, wie viel ein bestimmtes Wort "schlecht" oder "gut" ist.
Derzeit sind 67.392 Zeichen markiert (davon 55.532 Wörter und 11.860 Ausdrücke).
Feedback und Verteilung
Wir freuen uns über jegliches Feedback in den Kommentaren - von Kritik an der Arbeit und unseren Ansätzen bis hin zu Links zu interessanten Studien und verwandten Artikeln.
Wenn Sie Bekannte oder Kollegen haben, die an dem veröffentlichten Datensatz interessiert sein könnten, senden Sie ihnen einen Link zum Artikel oder Repository, um die Verbreitung offener Daten zu unterstützen.
Download-Link und Lizenz
Datensatz: offene Semantik der russischen SpracheDer Datensatz ist unter
CC BY-NC-SA 4.0 lizenziert.