
Ich arbeite in einem Team der Odnoklassniki-Plattform und werde heute über die Architektur, das Design und die Implementierungsdetails des Musikvertriebsdienstes sprechen.
Der Artikel ist eine Abschrift des Berichts bei Joker 2018 .
Einige Statistiken
Zunächst ein paar Worte zu OK. Dies ist ein gigantischer Dienst, der von mehr als 70 Millionen Benutzern genutzt wird. Sie werden von 7.000 Autos in 4 Rechenzentren bedient. Vor kurzem haben wir die Verkehrsmarke mit 2 Tb / s durchbrochen, ohne die zahlreichen CDN-Standorte zu berücksichtigen. Wir schöpfen das Maximum aus unserer Hardware heraus. Die am meisten ausgelasteten Dienste bedienen bis zu 100.000 Anforderungen pro Sekunde von einem Quad-Core-Knoten. Darüber hinaus sind fast alle Dienste in Java geschrieben.
Es gibt viele Abschnitte in OK, einer der beliebtesten ist "Musik". Darin können Benutzer ihre Titel hochladen, Musik in unterschiedlicher Qualität kaufen und herunterladen. Die Sektion hat einen wunderbaren Katalog, ein Empfehlungssystem, ein Radio und vieles mehr. Aber der Hauptzweck des Dienstes ist natürlich das Abspielen von Musik.
Der Musikvertreiber ist für die Übertragung von Daten an Benutzer-Player und mobile Anwendungen verantwortlich. Sie können es im Webinspektor abrufen, wenn Sie sich die Anforderungen an die Domain musicd.mycdn.me ansehen. Die Distributor-API ist extrem einfach. Es antwortet auf
GET HTTP-Anforderungen und gibt den angeforderten Trackbereich aus.
In der Spitze erreicht die Last über eine halbe Million Verbindungen 100 Gbit / s. Tatsächlich ist der Musikdistributor ein Caching-Frontend vor unserem internen Track-Repository, das auf
One Blob Storage und
One Cold Storage basiert und Petabyte an Daten enthält.
Da ich über Caching gesprochen habe, schauen wir uns die Wiedergabestatistiken an. Wir sehen ein ausgeprägtes TOP.
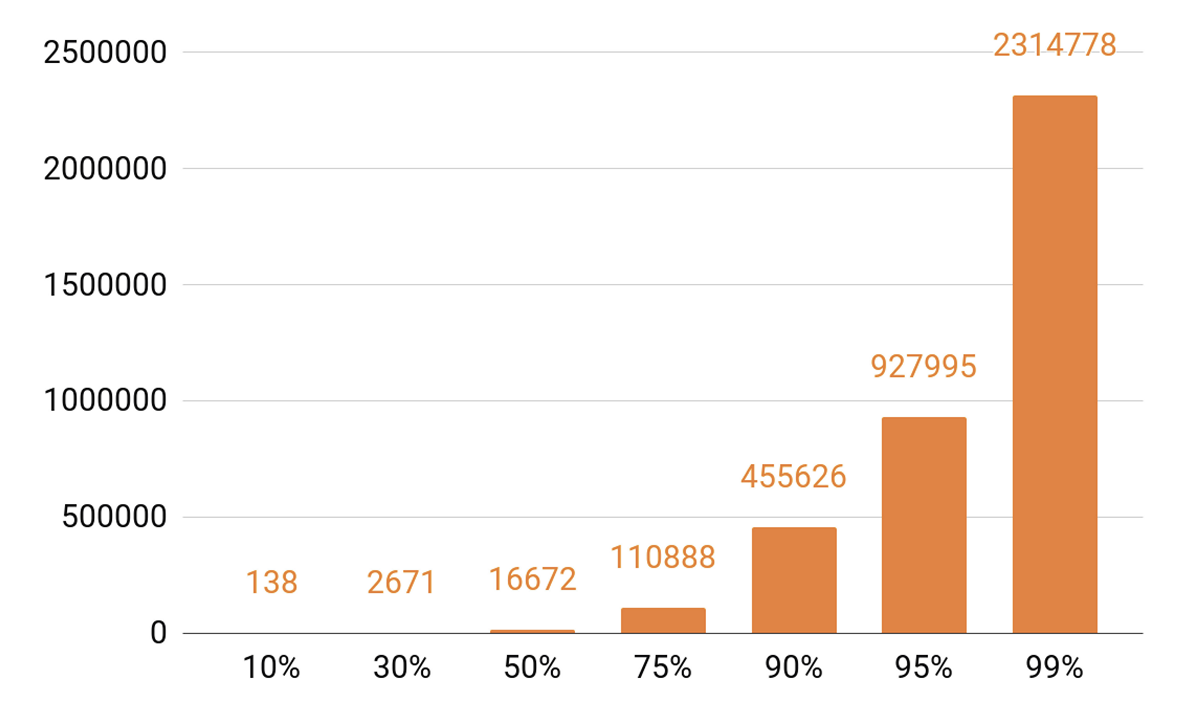
Ungefähr 140 Titel decken 10% aller Spiele pro Tag ab. Wenn unser Cache-Server einen Cache-Treffer von mindestens 90% haben soll, benötigen wir eine halbe Million Tracks, um in ihn zu passen. 95% - fast eine Million Tracks.
Händleranforderungen
Welche Ziele haben wir uns bei der Entwicklung der nächsten Version des Distributors gesetzt?
Wir wollten, dass ein Knoten 100.000 Verbindungen aufnehmen kann. Und dies sind langsame Client-Verbindungen: eine Reihe von Browsern und mobilen Anwendungen über Netzwerke mit unterschiedlichen Geschwindigkeiten. Gleichzeitig muss der Service wie alle unsere Systeme skalierbar und fehlertolerant sein.
Zunächst müssen wir die Bandbreite des Clusters skalieren, um mit der wachsenden Beliebtheit des Dienstes Schritt zu halten und immer mehr Datenverkehr bereitstellen zu können. Es ist auch erforderlich, die Gesamtkapazität des Cluster-Cache skalieren zu können, da der Cache-Treffer und der Prozentsatz der Anforderungen, die in den Speicher von Tracks fallen, direkt davon abhängen.
Heutzutage ist es notwendig, jedes verteilte System horizontal skalieren zu können, dh Maschinen und Rechenzentren hinzuzufügen. Wir wollten aber auch eine vertikale Skalierung implementieren. Unser typischer moderner Server enthält 56 Kerne, 0,5 bis 1 TB RAM, eine 10- oder 40-GB-Netzwerkschnittstelle und ein Dutzend SSD-Festplatten.
Wenn man von horizontaler Skalierbarkeit spricht, ergibt sich ein interessanter Effekt: Wenn Sie Tausende von Servern und Zehntausende von Festplatten haben, bricht ständig etwas zusammen. Festplattenfehler sind eine Routine, wir ändern sie bei 20-30 Stück pro Woche. Und Serverausfälle überraschen niemanden: 2-3 Autos pro Tag werden ersetzt. Ich musste mich auch mit Rechenzentrumsausfällen befassen, zum Beispiel gab es 2018 drei solcher Ausfälle, und dies ist wahrscheinlich nicht das letzte Mal.
Warum bin ich das alles? Wenn wir Systeme entwerfen, wissen wir, dass sie früher oder später kaputt gehen werden. Daher untersuchen wir
die Fehlerszenarien aller Systemkomponenten immer
sorgfältig . Die Hauptmethode zur Behebung von Fehlern ist die Datenreplikation: Mehrere Kopien von Daten werden auf verschiedenen Knoten gespeichert.
Wir reservieren auch Netzwerkbandbreite. Dies ist wichtig, da bei einem Ausfall einer Komponente des Systems die Last auf den verbleibenden Komponenten nicht zusammenbrechen kann.
Ausbalancieren
Zuerst müssen Sie lernen, wie Sie Benutzerabfragen zwischen Rechenzentren ausgleichen und dies automatisch tun. Dies ist der Fall, wenn Sie Netzwerkarbeiten durchführen müssen oder wenn das Rechenzentrum ausgefallen ist. Ein Ausgleich ist jedoch auch in Rechenzentren erforderlich. Und wir möchten Anforderungen nicht zufällig, sondern mit Gewichten auf Knoten verteilen. Zum Beispiel, wenn wir eine neue Version eines Dienstes hochladen und einen neuen Knoten reibungslos in Rotation versetzen möchten. Gewichte helfen auch beim Stresstest sehr: Wir erhöhen das Gewicht und belasten den Knoten viel stärker, um die Grenzen seiner Fähigkeiten zu verstehen. Und wenn ein Knoten unter Last ausfällt, setzen wir das Gewicht schnell auf Null und entfernen es mithilfe von Ausgleichsmechanismen aus der Rotation.
Wie sieht der Anforderungspfad vom Benutzer zum Knoten aus, der die Daten unter Berücksichtigung des Ausgleichs zurückgibt?

Der Benutzer meldet sich über die Website oder die mobile Anwendung an und erhält die URL des Titels:
musicd.mycdn.me/v0/stream?id=...Um die IP-Adresse vom Hostnamen in der URL zu erhalten, kontaktiert der Client unser GSLB-DNS, das alle unsere Rechenzentren und CDN-Sites kennt. GSLB DNS gibt dem Client die IP-Adresse des Balancers eines der Rechenzentren und der Client stellt eine Verbindung zu diesem her. Der Balancer kennt alle Knoten in den Rechenzentren und deren Gewicht. Es stellt im Namen des Benutzers eine Verbindung zu einem der Knoten her. Wir
verwenden N4Ware-basierte L4-Balancer . Noda gibt die Benutzerdaten direkt unter Umgehung des Balancers. Bei Diensten wie einem Distributor ist der ausgehende Datenverkehr erheblich höher als der eingehende.
Wenn ein Rechenzentrum abstürzt, erkennt GSLB DNS dies und entfernt es schnell aus der Rotation: Es gibt den Benutzern nicht mehr die IP-Adresse des Balancers dieses Rechenzentrums. Wenn ein Knoten im Rechenzentrum ausfällt, wird sein Gewicht zurückgesetzt und der Balancer im Rechenzentrum sendet keine Anforderungen mehr an ihn.
Betrachten Sie nun das Ausgleichen von Tracks nach Knoten in einem Rechenzentrum. Wir werden Rechenzentren als unabhängige autonome Einheiten betrachten, von denen jede leben und arbeiten wird, selbst wenn alle anderen gestorben sind. Die Tracks müssen gleichmäßig über die Maschinen verteilt sein, damit keine Lastverzerrungen auftreten, und sie müssen auf verschiedene Knoten repliziert werden. Wenn ein Knoten ausfällt, sollte die Last gleichmäßig auf die verbleibenden Knoten verteilt werden.
Dieses Problem kann
auf verschiedene Arten gelöst werden . Wir haben uns für
konsequentes Hashing entschieden . Wir wickeln den gesamten möglichen Bereich von Hashes von Spurkennungen in einen Ring ein, und dann wird jede Spur an einem Punkt auf diesem Ring angezeigt. Dann verteilen wir die Ringbereiche mehr oder weniger gleichmäßig auf die Knoten im Cluster. Die Knoten, in denen die Spur gespeichert wird, werden ausgewählt, indem die Spuren zu einem Punkt auf dem Ring gehasht und im Uhrzeigersinn bewegt werden.
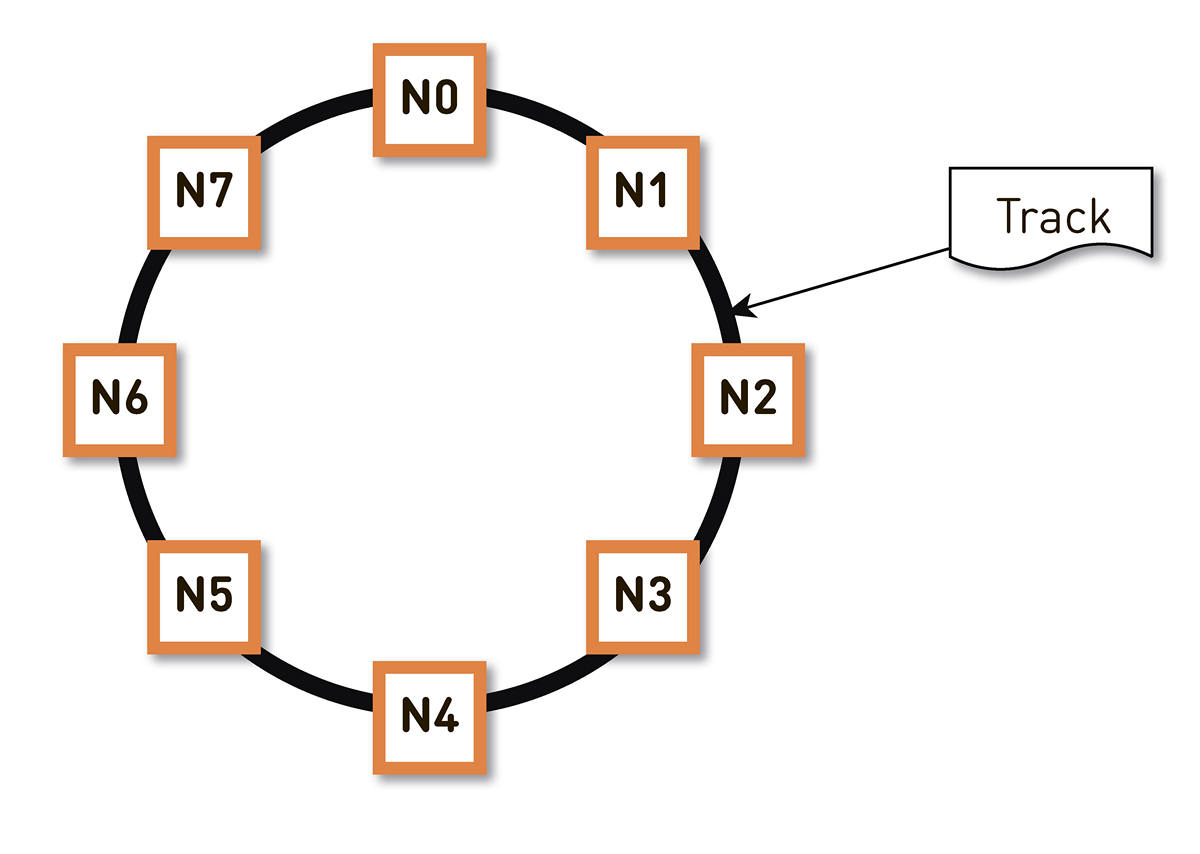
Ein solches Schema hat jedoch einen Nachteil: Wenn beispielsweise der Knoten N2 ausfällt, fällt seine gesamte Last auf die nächste Replik im Ring - N3. Und wenn es keine doppelte Leistungsspanne gibt - und dies ist wirtschaftlich nicht gerechtfertigt -, wird der zweite Knoten höchstwahrscheinlich auch eine schlechte Zeit haben. N3 mit hoher Wahrscheinlichkeit wird sich entwickeln, die Last wird auf N4 gehen und so weiter - es wird einen Kaskadenfehler entlang des gesamten Rings geben.
Dieses Problem kann durch Erhöhen der Anzahl der Replikate gelöst werden, aber dann nimmt die gesamte nutzbare Kapazität des Clusters im Ring ab. Deshalb machen wir es anders. Bei gleicher Anzahl von Knoten ist der Ring in eine wesentlich größere Anzahl von Bereichen unterteilt, die zufällig über den Ring verteilt sind. Repliken für die Spur werden gemäß dem obigen Algorithmus ausgewählt.

Im obigen Beispiel ist jeder Knoten für zwei Bereiche verantwortlich. Wenn einer der Knoten ausfällt, liegt seine gesamte Last nicht auf dem nächsten Knoten im Ring, sondern wird auf die beiden anderen Knoten des Clusters verteilt.
Der Ring wird basierend auf einem kleinen Satz von Parametern algorithmisch berechnet und an jedem Knoten bestimmt. Das heißt, wir speichern es nicht in einer Art Konfiguration. Wir haben mehr als hunderttausend dieser Bereiche in der Produktion, und im Falle eines Ausfalls eines der Knoten wird die Last absolut gleichmäßig auf alle anderen lebenden Knoten verteilt.
Wie sieht die Rückspur für den Benutzer in einem solchen System mit konsistentem Hashing aus?
Der Benutzer gelangt über den L4-Balancer zu einem zufälligen Knoten. Die Knotenauswahl ist zufällig, da der Balancer nichts über die Topologie weiß. Aber dann weiß jedes Replikat im Cluster davon. Der Knoten, der die Anforderung empfangen hat, bestimmt, ob es sich um eine Replik der angeforderten Spur handelt. Wenn nicht, wechselt es mit einem der Replikate in den Proxy-Modus, stellt eine Verbindung zu ihm her und sucht in seinem lokalen Speicher nach Daten. Wenn der Track nicht vorhanden ist, zieht das Replikat ihn aus dem Track-Speicher, speichert ihn im lokalen Speicher und gibt den Proxy, der die Daten an den Benutzer weiterleitet.
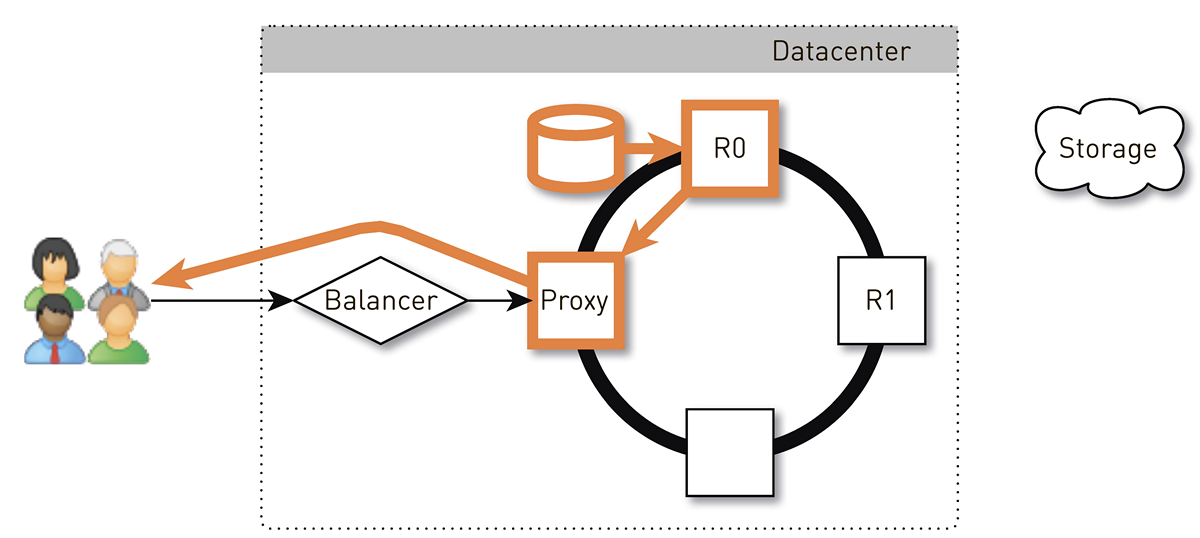
Wenn das Laufwerk im Replikat ausfällt, werden die Daten aus dem Speicher direkt an den Benutzer übertragen. Wenn das Replikat fehlschlägt, kennt der Proxy alle anderen Replikate für diesen Track. Er stellt eine Verbindung zu einem anderen Live-Replikat her und empfängt Daten von diesem. Wir garantieren also, dass ein Benutzer, der einen Track anfordert und mindestens ein Replikat lebt, eine Antwort erhält.
Wie funktioniert ein Knoten?
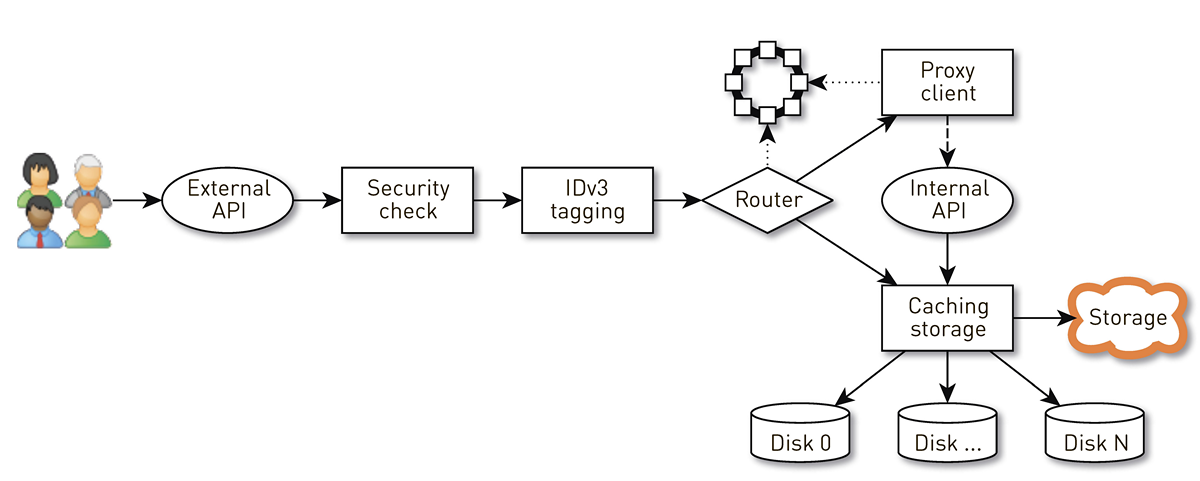
Ein Knoten ist eine Pipeline aus einer Reihe von Phasen, durch die die Anforderung eines Benutzers geleitet wird. Zunächst geht die Anfrage an eine externe API (wir senden alles über HTTPS). Dann wird die Anfrage validiert - Signaturen werden verifiziert. Dann werden bei Bedarf IDv3-Tags erstellt, beispielsweise beim Kauf eines Tracks. Die Anforderung geht an die Routing-Phase, in der anhand der Clustertopologie festgelegt wird, wie die Daten zurückgegeben werden: Entweder ist der aktuelle Knoten eine Replik für diese Spur, oder wir werden von einem anderen Knoten aus einen Proxy erstellen. Im zweiten Fall stellt der Knoten über den Proxy-Client eine Verbindung zum Replikat über die interne HTTP-API her, ohne die Signaturen zu überprüfen. Das Replikat sucht nach Daten im lokalen Speicher. Wenn es eine Spur findet, gibt es diese von seiner Festplatte ab. Wenn dies nicht der Fall ist, werden Tracks aus dem Speicher abgerufen, zwischengespeichert und ausgegeben.
Knotenlast
Lassen Sie uns abschätzen, welche Last ein Knoten in dieser Konfiguration halten soll. Lassen Sie uns drei Rechenzentren mit jeweils vier Knoten haben.

Der gesamte Dienst sollte 120 Gbit / s, dh 40 Gbit / s pro Rechenzentrum, bereitstellen. Angenommen, Netzwerker haben Manöver durchgeführt oder es ist ein Unfall aufgetreten, und es sind noch zwei Rechenzentren DC1 und DC3 übrig. Jetzt sollte jeder von ihnen 60 Gbit / s geben. Aber hier war es an den Entwicklern, ein Update herauszubringen. In jedem Rechenzentrum waren noch 3 Live-Knoten übrig, und jeder von ihnen sollte 20 Gbit / s liefern.
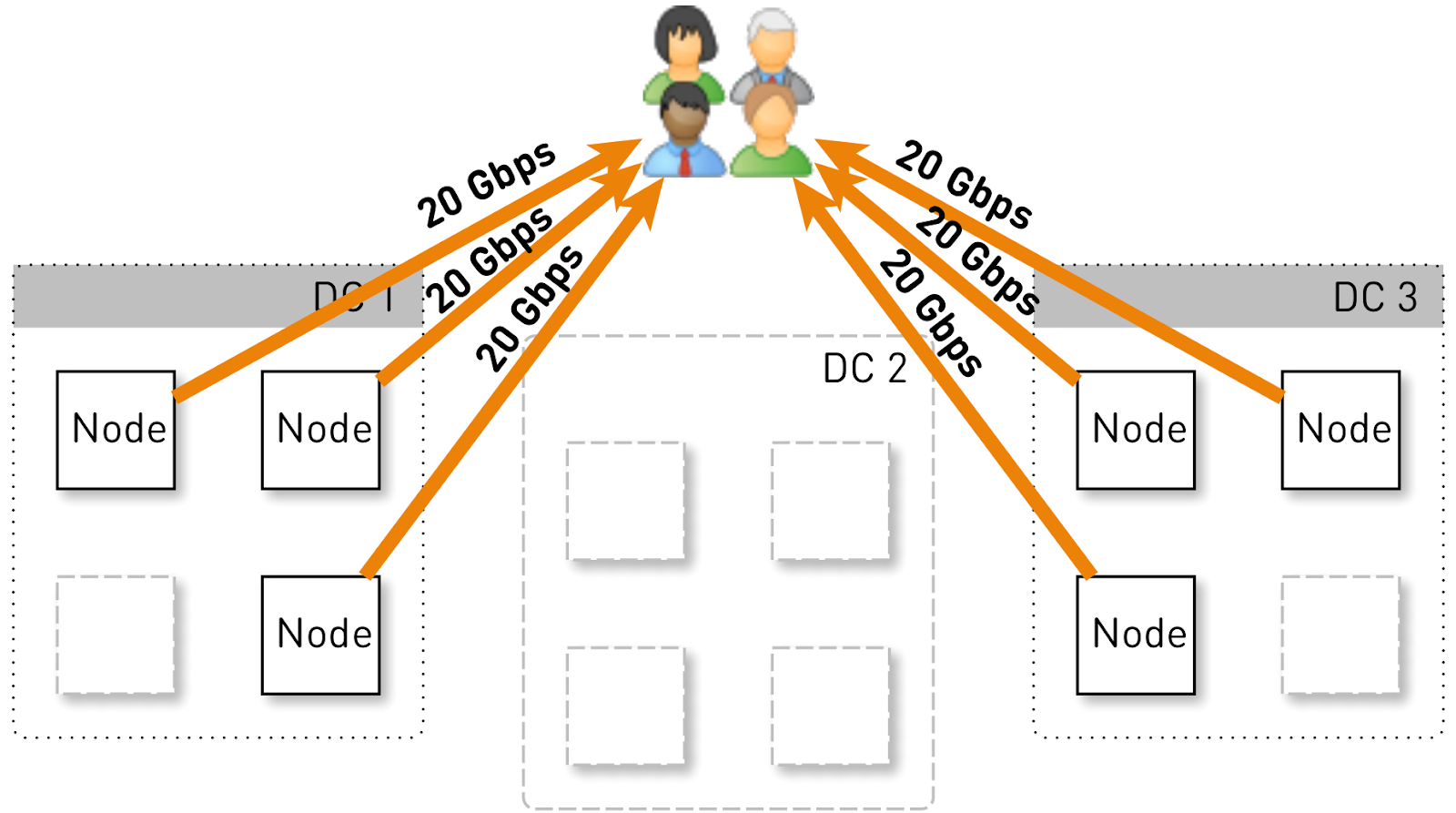
Anfangs gab es in jedem Rechenzentrum 4 Knoten. Wenn wir zwei Replikate im Rechenzentrum speichern, ist der Knoten, der die Anforderung empfangen hat, mit einer Wahrscheinlichkeit von 50% keine Replik des angeforderten Tracks und ersetzt die Daten. Das heißt, die Hälfte des Datenverkehrs im Rechenzentrum wird übertragen.
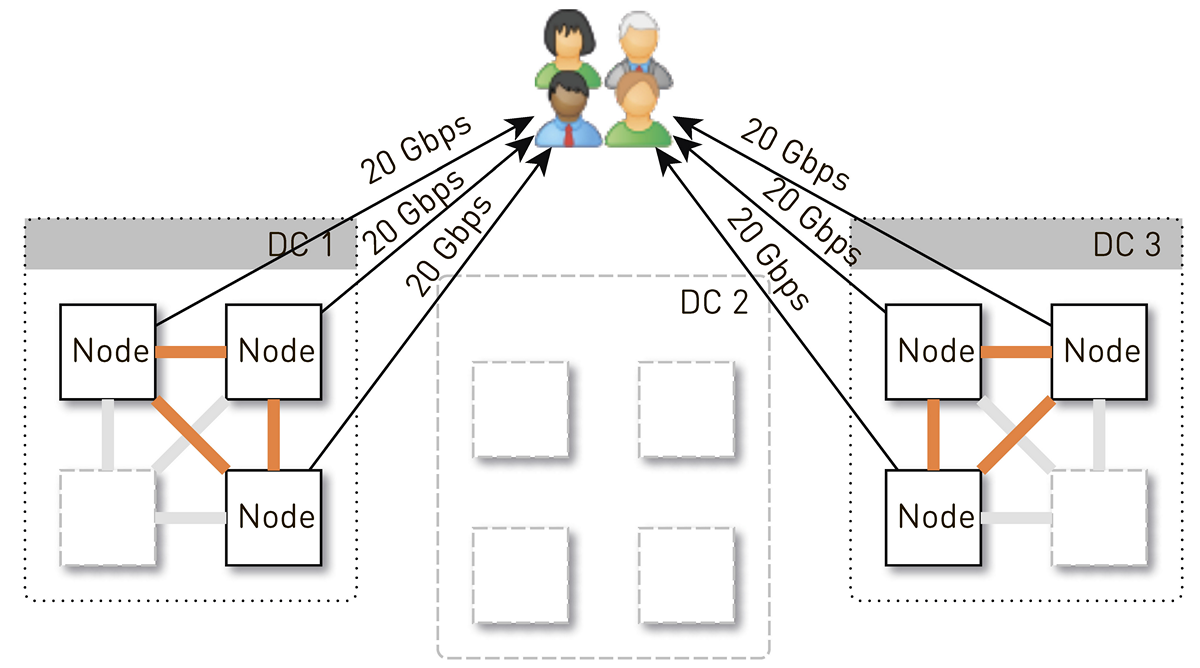
Ein Knoten sollte den Benutzern also 20 Gbit / s geben. Davon werden 10 Gbit / s von seinen Nachbarn im Rechenzentrum abgezogen. Das Schema ist jedoch symmetrisch: Der Knoten gibt den Nachbarn im Rechenzentrum die gleichen 10 Gbit / s. Es stellt sich heraus, dass 30 Gbit / s aus dem Knoten herausgehen, von denen 20 Gbit / s selbst bedient werden sollten, da es sich um eine Replik der angeforderten Daten handelt. Darüber hinaus werden die Daten entweder von Festplatten oder vom RAM übertragen, der ungefähr 50.000 "heiße" Spuren enthält. Basierend auf unseren Wiedergabestatistiken können Sie auf diese Weise 60-70% der Last von den Festplatten entfernen und bleiben bei etwa 8 Gbit / s. Dieser Thread kann durchaus ein Dutzend SSDs liefern.
Datenspeicherung auf einem Knoten
Wenn Sie jeden Track in eine separate Datei einfügen, ist der Aufwand für die Verwaltung dieser Dateien enorm. Selbst ein Neustart der Knoten und das Scannen der Daten auf den Festplatten dauert Minuten, wenn nicht sogar zehn Minuten.
Es gibt weniger offensichtliche Einschränkungen für dieses Schema. Beispielsweise können Sie Tracks nur von Anfang an laden. Wenn der Benutzer die Wiedergabe aus der Mitte angefordert hat und der Cache fehlgeschlagen ist, können wir kein einzelnes Byte senden, bis wir die Daten aus dem Track-Repository an den gewünschten Speicherort geladen haben. Darüber hinaus können wir die Titel nur als Ganzes speichern, auch wenn es sich um ein riesiges Hörbuch handelt, das sie in der dritten Minute nicht mehr hören. Es wird weiterhin totes Gewicht auf der Festplatte liegen, teuren Speicherplatz verschwenden und den Cache-Treffer dieses Knotens reduzieren.
Deshalb machen wir das ganz anders: Wir teilen die Spuren in 256-KB-Blöcke auf, da dies mit der Blockgröße in der SSD korreliert und wir bereits mit diesen Blöcken arbeiten. Eine Festplatte mit 1 TB enthält 4 Millionen Blöcke. Jede Festplatte in einem Knoten ist ein unabhängiger Speicher, und alle Blöcke jeder Spur sind auf alle Festplatten verteilt.
Wir sind nicht sofort zu einem solchen Schema gekommen, zuerst lagen alle Blöcke einer Spur auf einer Platte. Dies führte jedoch zu einer starken Verzerrung der Last zwischen den Datenträgern, da alle Anforderungen für seine Daten an einen Datenträger gesendet werden, wenn ein beliebter Track auf einen der Datenträger trifft. Um dies zu verhindern, haben wir die Blöcke jeder Spur auf alle Festplatten verteilt und die Last ausgeglichen.
Außerdem vergessen wir nicht, dass wir eine Menge RAM haben, aber wir haben uns entschieden, den semantischen Cache nicht zu verwenden, da wir unter Linux einen wunderbaren Seiten-Cache haben.
Wie speichere ich Blöcke auf Festplatten?
Zuerst haben wir beschlossen, eine riesige XFS-Datei von der Größe einer Festplatte zu erhalten und alle Blöcke darin abzulegen. Dann kam die Idee auf, direkt mit einem Blockgerät zu arbeiten. Wir haben beide Optionen implementiert, verglichen und festgestellt, dass bei der direkten Arbeit mit einem Blockgerät die Aufzeichnung 1,5-mal schneller ist, die Reaktionszeit 2-3-mal kürzer ist und die Gesamtsystemlast 2-mal niedriger ist.
Index
Es reicht jedoch nicht aus, Blöcke speichern zu können. Sie müssen einen Index von Blöcken von Musiktiteln zu Blöcken auf der Festplatte verwalten.

Es stellte sich als ziemlich kompakt heraus, ein Indexeintrag benötigt nur 29 Bytes. Bei einem 10-TB-Speicher beträgt der Index etwas mehr als 1 GB.
Hier gibt es einen interessanten Punkt. In jedem solchen Datensatz müssen Sie die Gesamtgröße des gesamten Tracks speichern. Dies ist ein klassisches Beispiel für Denormalisierung. Der Grund dafür ist, dass wir gemäß der Spezifikation in der HTTP-Bereichsantwort die Gesamtgröße der Ressource zurückgeben und einen Header mit Inhaltslänge bilden müssen. Wenn dies nicht der Fall wäre, wäre alles noch kompakter.
Wir haben eine Reihe von Anforderungen für den Index formuliert: schnell arbeiten (vorzugsweise im RAM gespeichert), kompakt sein und keinen Platz im Seitencache beanspruchen. Ein anderer Index sollte persistent sein. Wenn wir es verlieren, verlieren wir Informationen darüber, an welcher Stelle auf der Festplatte welcher Titel gespeichert ist, und dies ist gleichbedeutend mit der Reinigung der Festplatten. Und im Allgemeinen möchte ich, dass die alten Blöcke, auf die seit langem nicht mehr zugegriffen wurde, irgendwie ersetzt werden, um Platz für populärere Tracks zu schaffen. Wir haben die
LRU-Verdrängungsrichtlinie gewählt: Blöcke werden einmal pro Minute
verdrängt , 1% der Blöcke werden frei gehalten. Natürlich muss die Indexstruktur threadsicher sein, da wir 100.000 Verbindungen pro Knoten haben. All diese Bedingungen werden von
SharedMemoryFixedMap aus unserer
One-Nio- Open-Source-Bibliothek ideal erfüllt.
Wir setzen den Index auf
tmpfs , es funktioniert schnell, aber es gibt eine Nuance. Beim Neustart des Computers geht alles verloren, was sich auf
tmpfs , einschließlich des Index. Wenn unser Prozess aufgrund der
sun.misc.Unsafe abstürzte, ist außerdem unklar, in welchem Zustand der Index verblieben ist. Deshalb machen wir einmal pro Stunde einen Eindruck davon. Dies reicht jedoch nicht aus: Da wir die Blockextrusion verwenden, müssen wir
WAL unterstützen , in dem wir Informationen über extrudierte Blöcke schreiben. Einträge zu Blöcken in Casts und WALs müssen während der Wiederherstellung irgendwie sortiert werden. Dazu verwenden wir den Generierungsblock. Es spielt die Rolle eines globalen Transaktionszählers und wird bei jeder Änderung des Index erhöht. Schauen wir uns ein Beispiel an, wie das funktioniert.
Nehmen Sie einen Index mit drei Einträgen: zwei Blöcke von Spur Nr. 1 und einen Block von Spur Nr. 2.
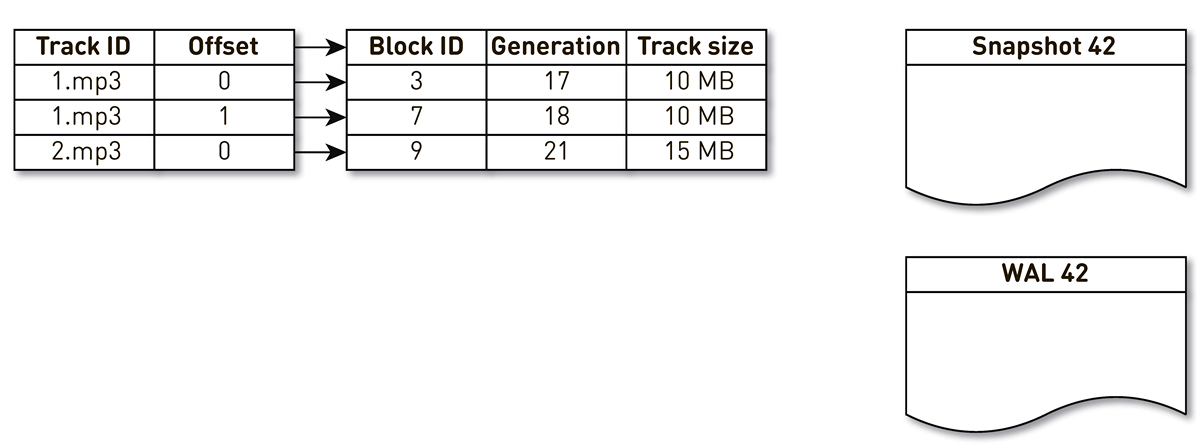
Der Strom der Erstellung von Casts wird durch diesen Index geweckt und wiederholt: Das erste und das zweite Tupel fallen in die Besetzung. Dann wendet sich der Überfüllungsfluss dem Index zu, stellt fest, dass auf den siebten Block schon lange nicht mehr zugegriffen wurde, und beschließt, ihn für etwas anderes zu verwenden. Der Prozess erzwingt die Blockierung und schreibt einen Datensatz in die WAL. Er kommt zu Block 9, sieht, dass er schon lange nicht mehr kontaktiert wurde und markiert ihn auch als überfüllt. Hier greift der Benutzer auf das System zu und es tritt ein Cache-Fehler auf - ein Track wird angefordert, den wir nicht haben. Wir speichern den Block dieser Spur in unserem Repository und überschreiben Block 9. Gleichzeitig wird die Generierung inkrementiert und gleich 22. Anschließend wird der Prozess zum Erstellen einer Form aktiviert, der seine Arbeit noch nicht abgeschlossen hat, den letzten Datensatz erreicht und in die Form schreibt. Als Ergebnis haben wir zwei Live-Aufzeichnungen im Index, eine Besetzung und WAL.
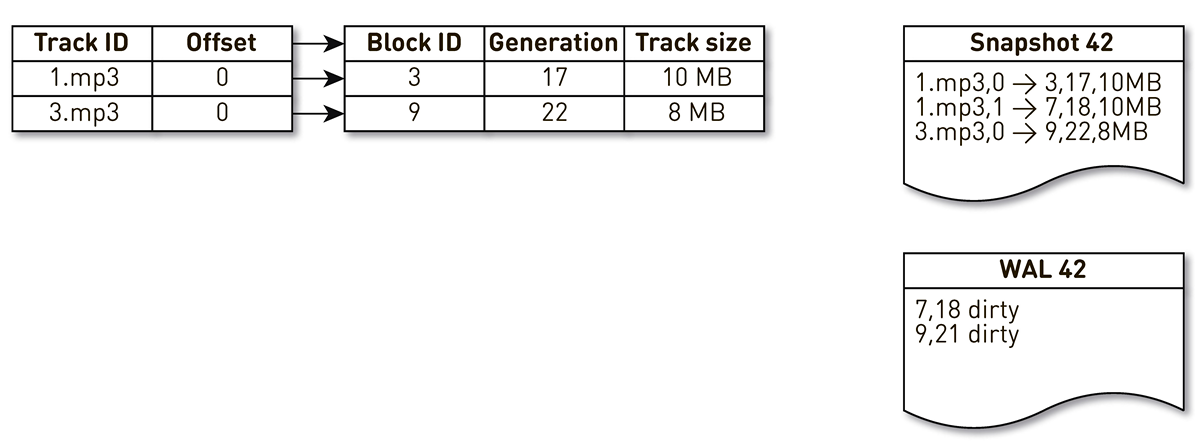
Wenn der aktuelle Knoten ausfällt, wird der Ausgangszustand des Index wie folgt wiederhergestellt. Scannen Sie zuerst die WAL und erstellen Sie eine schmutzige Blockkarte. Die Karte speichert die Zuordnung von der Blocknummer zur Generation, als dieser Block ersetzt wurde.

Danach beginnen wir mit der Karte als Filter über die Form zu iterieren. Wir schauen uns die erste Aufzeichnung der Besetzung an, sie bezieht sich auf Block Nummer 3. Er wird unter den Dreckigen nicht erwähnt, was bedeutet, dass er lebt und in den Index aufgenommen wird. Wir kommen mit der achtzehnten Generation zu Block Nummer 7, aber die schmutzige Blockkarte sagt uns, dass der Block gerade in der 18. Generation überfüllt war. Daher fällt es nicht in den Index. Wir kommen zum letzten Datensatz, der den Inhalt von Block 9 mit 22 Generationen beschreibt. Dieser Block wird in der Dirty-Block-Map erwähnt, wurde jedoch früher ersetzt. Es wird also für neue Daten wiederverwendet und gelangt in den Index. Das Ziel ist erreicht.
Optimierungen
Aber das ist noch nicht alles, wir gehen tiefer.
Beginnen wir mit dem Seiten-Cache. Wir haben anfangs damit gerechnet, aber als wir mit dem Auslastungstest der ersten Version begannen,
stellte sich heraus, dass die Trefferquote im Seiten-Cache nicht 20% erreichte. Sie schlugen vor, dass das Problem im Voraus gelesen werden sollte: Wir speichern keine Dateien, sondern blockieren, während wir eine Reihe von Verbindungen bedienen, und in dieser Konfiguration ist die Arbeit mit der Festplatte zufällig effizient. Wir lesen fast nie etwas nacheinander. Glücklicherweise gibt es unter Linux einen Aufruf von
posix_fadvise , mit dem Sie dem Kernel mitteilen können, wie wir mit dem Dateideskriptor arbeiten werden. Insbesondere können wir sagen, dass wir nicht
POSIX_FADV_RANDOM müssen, indem
POSIX_FADV_RANDOM Flag
POSIX_FADV_RANDOM . Dieser Systemaufruf ist über
one-nio verfügbar . Im Betrieb beträgt unser Cache-Treffer 70-80%. Die Anzahl der physischen Messwerte von Datenträgern verringerte sich um mehr als das Zweifache, die Verzögerung der HTTP-Antwort verringerte sich um 20%.
. heap. TLB- , Huge Pages Java-. (GC Time/Safepoint Total Time 20-30% ), , HTTP latency .
( ) .
. , , , , . , - . , . , , . , Daft Punk №2 sdc, sdd.
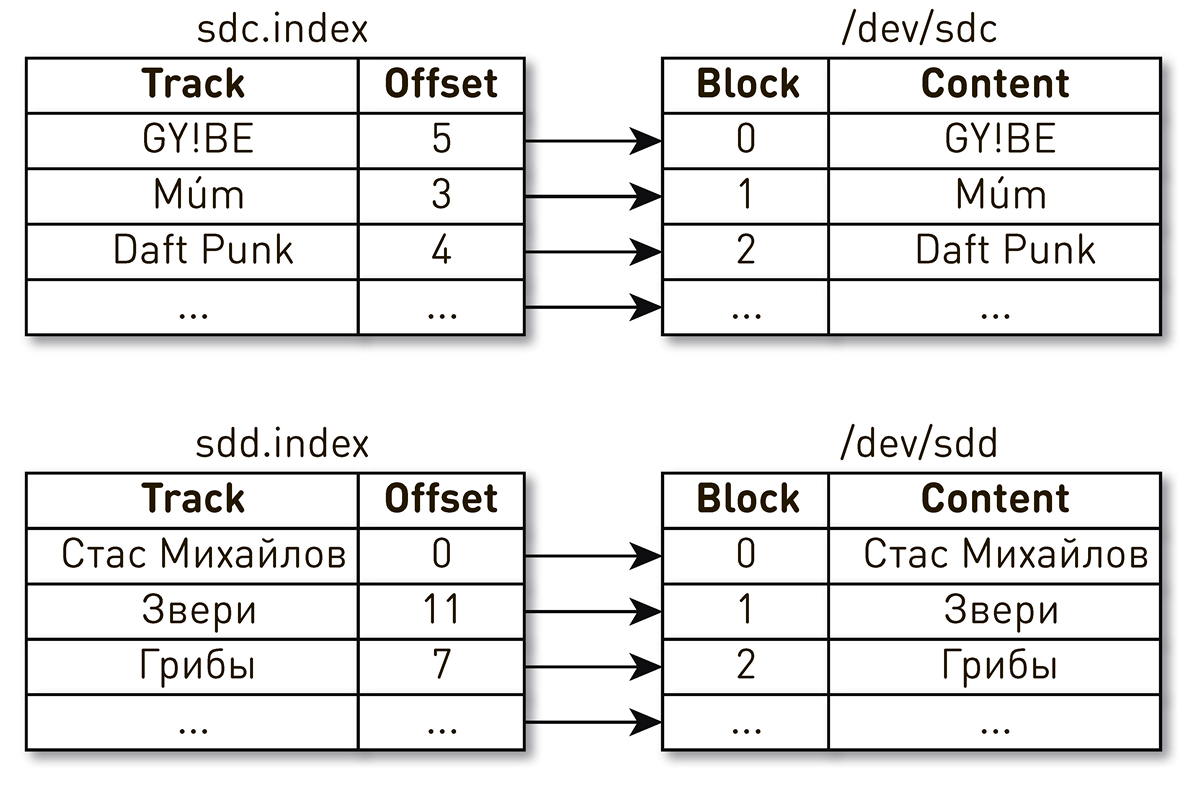
, . Linux
: , .

. ID.
WWN , WAL. , , .
Die Analyse von Problemen in solchen verteilten Systemen ist schwierig, da eine Benutzeranforderung viele Stufen durchläuft und die Grenzen von Knoten überschreitet. Bei CDN wird alles noch komplizierter, da bei CDN der Upstream das Heimdatenzentrum ist. Es kann ziemlich viele solcher Hoffnungen geben. Darüber hinaus bedient das System Hunderttausende von Benutzerverbindungen. Es ist ziemlich schwer zu verstehen, zu welchem Zeitpunkt ein Problem bei der Verarbeitung einer Anfrage eines bestimmten Benutzers vorliegt.Wir vereinfachen unser Leben so. Beim Login markieren wir alle Anfragen mit einem Tag ähnlich wie Open Tracing und Zipkin . , . , , HTTP- . , , , , , , .
. , : , , .
ByteBuffer buffer = ByteBuffer.allocate(size); int count = fileChannel.read(buffer, position); if (count <= 0) {
, :
FileChannel.read() kernel space user space;SocketChannel.write() , user space kernel space.
, Linux
sendfile() , , user space. ,
one-nio . ,
sendfile() — 10 /
sendfile() 0.
user-space SSL-
sendfile() , . .
SocketChannel FileChannel ,
Async Profiler ,
sun.nio.ch.IOUtil ,
read() write() . .
ByteBuffer bb = Util.getTemporaryDirectBuffer(dst.remaining()); try { int n = readIntoNativeBuffer(fd, bb, position, nd); bb.flip(); if (n > 0) dst.put(bb); return n; } finally { Util.offerFirstTemporaryDirectBuffer(bb); }
. heap
ByteBuffer , , , heap
ByteBuffer , . .
.
one-nio .
MallocMT — , . SSL , Java heap,
ByteBuffer ,
FileChannel . .
final Allocator allocator = new MallocMT(size, concurrency); int write(Socket socket) { if (socket.getSslContext() != null) { long address = allocator.malloc(size); ByteBuffer buf = DirectMemory.wrap(address, size); int available = channel.read(buf, offset); socket.writeRaw(address, available, flags);
100 000
. . 100 . . ?
, — . , . , . .
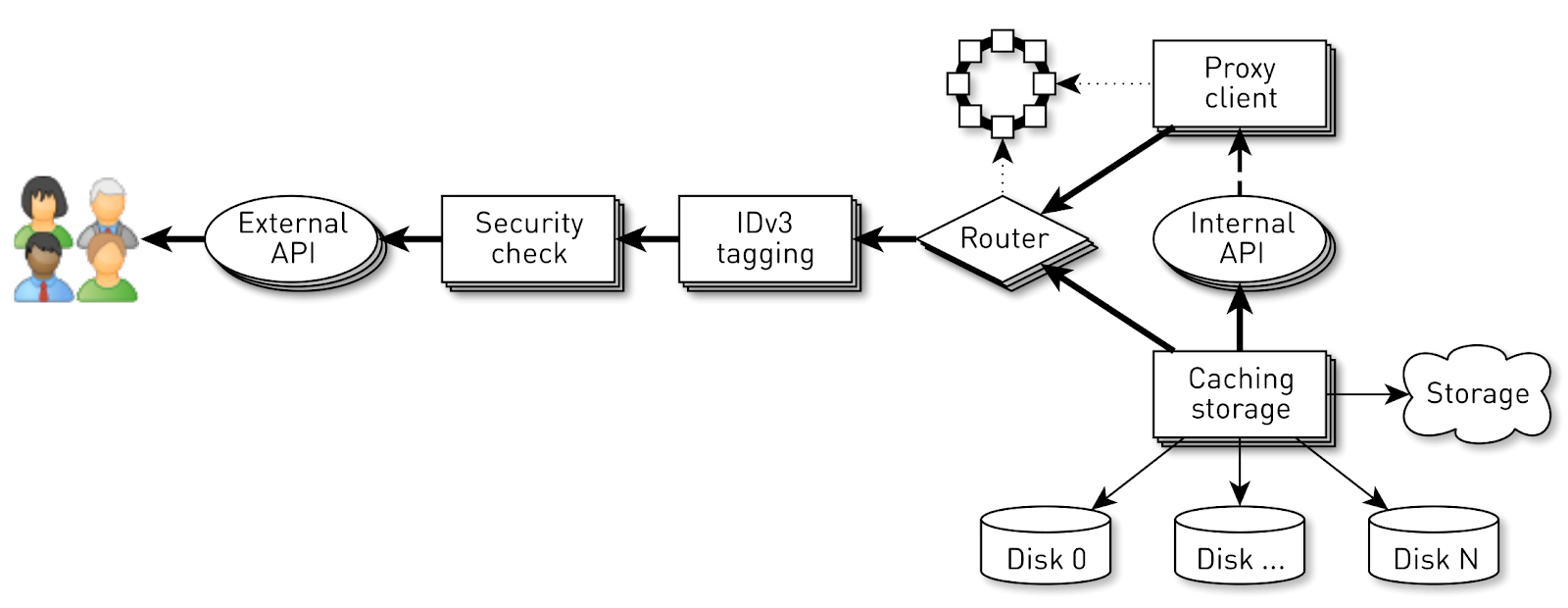 Für jede Verbindung wird eine logische Pipeline erstellt, die aus Stufen besteht, die asynchron miteinander interagieren. Jede Stufe hat eine Runde, in der eingehende Anfragen gespeichert werden. Für die Ausführung von Stufen werden kleine gemeinsame Thread-Pools verwendet. Wenn Sie eine Nachricht aus der Anforderungswarteschlange verarbeiten müssen, nehmen wir einen Stream aus dem Pool, verarbeiten die Nachricht und geben den Stream an den Pool zurück. Mit diesem Schema werden Daten vom Speicher zum Client übertragen.Ein solches Schema ist jedoch nicht ohne Mängel. Backends sind viel schneller als Benutzerverbindungen. Wenn Daten die Pipeline durchlaufen, sammeln sie sich in der langsamsten Phase an, d.h. in der Phase des Schreibens von Blöcken in den Client-Verbindungssocket. Früher oder später wird dies zum Zusammenbruch des Systems führen. Wenn Sie versuchen, die Warteschlangen in diesen Phasen zu begrenzen, wird alles sofort blockiert, da die Pipelines in der Kette zum Socket des Benutzers blockiert werden. Und da sie gemeinsam genutzte Thread-Pools verwenden, blockieren sie alle Threads in ihnen. Benötigen Sie Gegendruck.Dazu haben wir Jetstreams verwendet. Das Wesentliche des Ansatzes besteht darin, dass der Abonnent die Geschwindigkeit der vom Verlag kommenden Daten mithilfe der Nachfrage steuert. Nachfrage bedeutet, wie viel mehr Daten der Teilnehmer zusammen mit der vorherigen Nachfrage, die er bereits signalisiert hat, verarbeiten kann. Der Herausgeber hat das Recht, Daten zu senden, jedoch nicht die derzeit akkumulierte Gesamtnachfrage abzüglich der bereits gesendeten Daten.Somit schaltet das System dynamisch zwischen Push- und Pull-Modus um. Im Push-Modus ist der Abonnent schneller als der Herausgeber, was bedeutet, dass der Herausgeber immer eine unbefriedigte Nachfrage vom Abonnenten hat, jedoch keine Daten. Sobald die Daten erscheinen, sendet er sie sofort an den Teilnehmer. Der Pull-Modus tritt auf, wenn der Publisher schneller als der Abonnent ist. Das heißt, der Verlag würde gerne Daten senden, nur die Nachfrage ist Null. Sobald der Abonnent angibt, dass er bereit ist, etwas mehr zu verarbeiten, sendet der Verlag ihm sofort ein Datenelement als Teil der Nachfrage.Unser Förderer verwandelt sich in einen Jetstream. Jede Stufe wird zum Herausgeber für die vorherige Stufe und zum Abonnenten für die nächste.Die Schnittstelle von Jetstreams sieht extrem einfach aus.
Für jede Verbindung wird eine logische Pipeline erstellt, die aus Stufen besteht, die asynchron miteinander interagieren. Jede Stufe hat eine Runde, in der eingehende Anfragen gespeichert werden. Für die Ausführung von Stufen werden kleine gemeinsame Thread-Pools verwendet. Wenn Sie eine Nachricht aus der Anforderungswarteschlange verarbeiten müssen, nehmen wir einen Stream aus dem Pool, verarbeiten die Nachricht und geben den Stream an den Pool zurück. Mit diesem Schema werden Daten vom Speicher zum Client übertragen.Ein solches Schema ist jedoch nicht ohne Mängel. Backends sind viel schneller als Benutzerverbindungen. Wenn Daten die Pipeline durchlaufen, sammeln sie sich in der langsamsten Phase an, d.h. in der Phase des Schreibens von Blöcken in den Client-Verbindungssocket. Früher oder später wird dies zum Zusammenbruch des Systems führen. Wenn Sie versuchen, die Warteschlangen in diesen Phasen zu begrenzen, wird alles sofort blockiert, da die Pipelines in der Kette zum Socket des Benutzers blockiert werden. Und da sie gemeinsam genutzte Thread-Pools verwenden, blockieren sie alle Threads in ihnen. Benötigen Sie Gegendruck.Dazu haben wir Jetstreams verwendet. Das Wesentliche des Ansatzes besteht darin, dass der Abonnent die Geschwindigkeit der vom Verlag kommenden Daten mithilfe der Nachfrage steuert. Nachfrage bedeutet, wie viel mehr Daten der Teilnehmer zusammen mit der vorherigen Nachfrage, die er bereits signalisiert hat, verarbeiten kann. Der Herausgeber hat das Recht, Daten zu senden, jedoch nicht die derzeit akkumulierte Gesamtnachfrage abzüglich der bereits gesendeten Daten.Somit schaltet das System dynamisch zwischen Push- und Pull-Modus um. Im Push-Modus ist der Abonnent schneller als der Herausgeber, was bedeutet, dass der Herausgeber immer eine unbefriedigte Nachfrage vom Abonnenten hat, jedoch keine Daten. Sobald die Daten erscheinen, sendet er sie sofort an den Teilnehmer. Der Pull-Modus tritt auf, wenn der Publisher schneller als der Abonnent ist. Das heißt, der Verlag würde gerne Daten senden, nur die Nachfrage ist Null. Sobald der Abonnent angibt, dass er bereit ist, etwas mehr zu verarbeiten, sendet der Verlag ihm sofort ein Datenelement als Teil der Nachfrage.Unser Förderer verwandelt sich in einen Jetstream. Jede Stufe wird zum Herausgeber für die vorherige Stufe und zum Abonnenten für die nächste.Die Schnittstelle von Jetstreams sieht extrem einfach aus. Publisherlass uns unterschreibenSubscriber und er sollte nur vier Handler implementieren: interface Publisher<T> { void subscribe(Subscriber<? super T> s); } interface Subscriber<T> { void onSubscribe(Subscription s); void onNext(T t); void onError(Throwable t); void onComplete(); } interface Subscription { void request(long n); void cancel(); }
Subscription ermöglicht es Ihnen, Nachfrage zu signalisieren und sich abzumelden. Nirgendwo ist es einfacher.
Als Datenelement übergeben wir keine Byte-Arrays, sondern eine solche Abstraktion wie Chunk. Wir tun dies, um die Daten im Heap möglichst nicht herauszuziehen. Chunk ist eine Datenverbindung mit einer sehr eingeschränkten Schnittstelle, mit der Sie nur Daten lesen ByteBuffer, in einen Socket oder in eine Datei schreiben können. interface Chunk { int read(ByteBuffer dst); int write(Socket socket); void write(FileChannel channel, long offset); }
Es gibt viele Implementierungen von Chunks:- Die beliebteste, die bei Cache-Treffern und beim Senden von Daten von der Festplatte verwendet wird, ist die Implementierung oben
RandomAccessFile. Der Block enthält nur einen Link zur Datei, den Versatz in dieser Datei und die Größe der Daten. Es durchläuft die gesamte Pipeline, erreicht den Benutzerverbindungssocket und wird dort zu einem Anruf sendfile(). Das heißt, Speicher wird überhaupt nicht verbraucht. - cache miss : . , — , , — .
- , - heap.
ByteBuffer .
API, , . Typed Actor Model,
. , , , . .
, .. publisher subscriber , , executor, .
AtomicBoolean happens before .
:
@Override void request(final long n) { enqueue(new Request(n)); } void enqueue(final M message) { mailbox.offer(message); tryScheduleToExecute(); }
tryScheduleToExecute() :
if (on.compareAndSet(false, true)) { try { executor.execute(this); } catch (Exception e) { ... } }
run() :
if (on.get()) try { dequeueAndProcess(); } finally { on.set(false); if (!messages.isEmpty()) { tryScheduleToExecute(); } } }
dequeueAndProcess() :
M message; while ((message = mailbox.poll()) != null) {
. ,
volatile ,
Atomic* , contention . 100 000 200 .
Zusammenfassend
production 12 , . 10 / . . Java
one-nio .
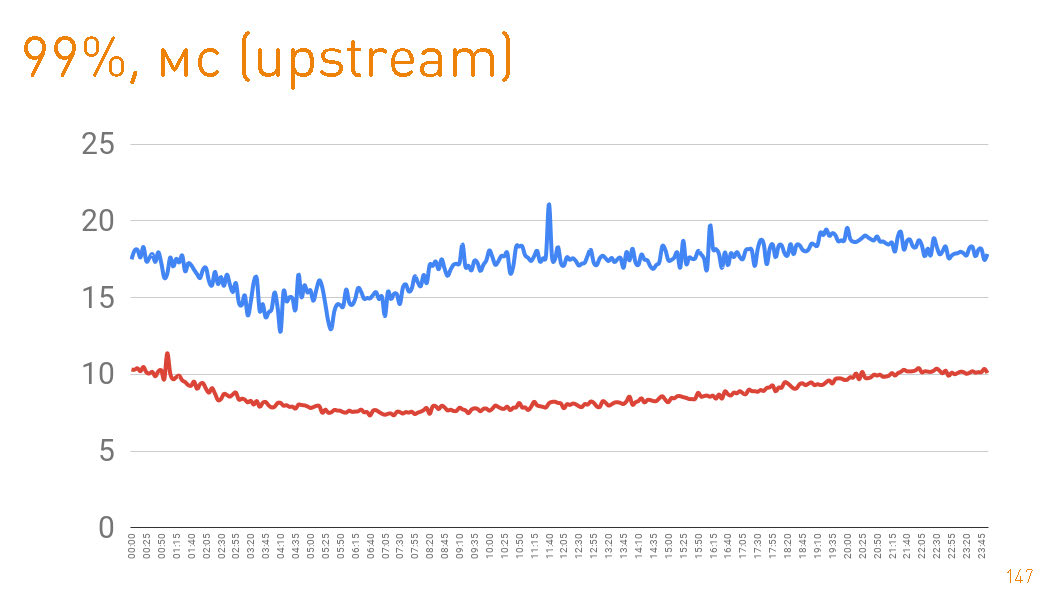
, . 99- 20 . — HTTPS-. —
sendfile() HTTP.
cache hit production 97%, latency , , , .
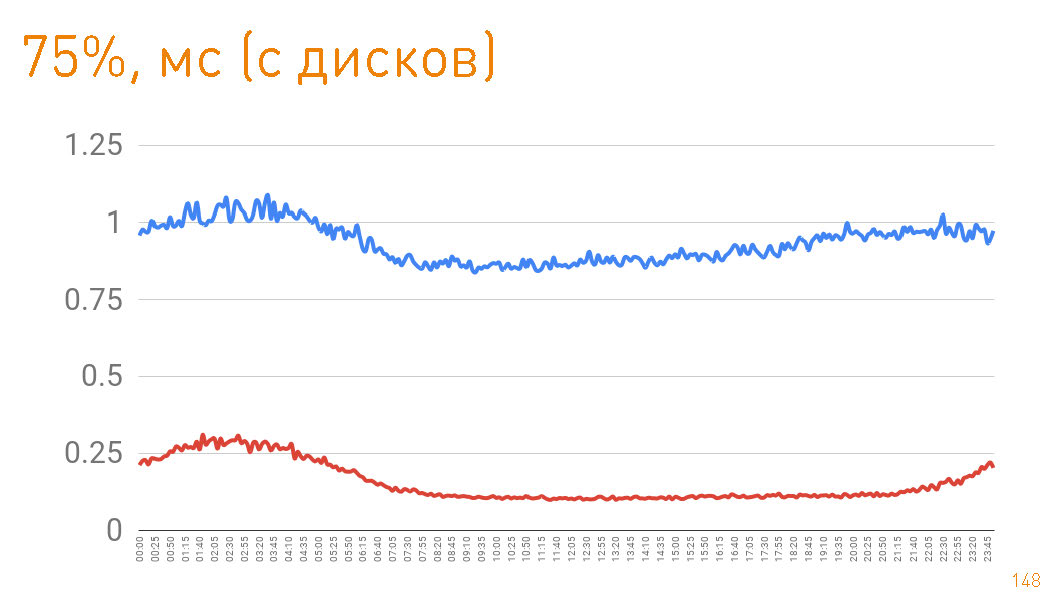
75- , 1 . — 300 . Das heißt, 0.7 — .
, , , . , .