Tiefengenauigkeit ist ein Schmerz im Arsch, dem sich jeder Grafikprogrammierer früher oder später stellen muss. Zu diesem Thema wurden viele Artikel und Werke verfasst. In verschiedenen Spielen und Engines sowie auf verschiedenen Plattformen können Sie viele verschiedene Formate und Einstellungen für den
Tiefenpuffer sehen .
Die Tiefenkonvertierung auf einer GPU scheint aufgrund der Wechselwirkung mit der perspektivischen Projektion nicht offensichtlich zu sein, und das Studium der Gleichungen verdeutlicht die Situation nicht. Um zu verstehen, wie dies funktioniert, ist es hilfreich, einige Bilder zu zeichnen.

Dieser Artikel ist in 3 Teile gegliedert:
- Ich werde versuchen, die Motivation für die nichtlineare Tiefenumwandlung zu erklären.
- Ich werde einige Diagramme vorstellen, die Ihnen helfen zu verstehen, wie die nichtlineare Tiefenkonvertierung in verschiedenen Situationen intuitiv und visuell funktioniert.
- Eine Diskussion der wichtigsten Ergebnisse der Verschärfung der Präzision des perspektivischen Renderns [Paul Upchurch, Mathieu Desbrun (2012)] hinsichtlich der Auswirkung von Rundungs-Gleitkommafehlern auf die Tiefengenauigkeit.
Warum 1 / z?
Ein Hardware-GPU-
Tiefenpuffer speichert normalerweise keine lineare Darstellung des Abstands zwischen dem Objekt und der Kamera, im Gegensatz zu dem, was beim ersten Treffen naiv erwartet wird. Stattdessen speichert der Tiefenpuffer Werte, die umgekehrt proportional zur Tiefe des Ansichtsraums sind. Ich möchte kurz die Motivation für eine solche Entscheidung beschreiben.
In diesem Artikel werde ich
d verwenden , um die im Tiefenpuffer gespeicherten Werte darzustellen (im Bereich [0, 1] für DirectX), und
z , um den Tiefenansichtsraum darzustellen, d. H. Die tatsächliche Entfernung von der Kamera, in Welteinheiten, z. B. Meter. Im Allgemeinen hat die Beziehung zwischen ihnen die folgende Form:
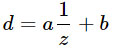
Dabei sind
a, b die Konstanten, die den Nah- und Ferneinstellungen der Ebenen zugeordnet sind. Mit anderen Worten,
d ist immer eine lineare Transformation von
1 / z .
Auf den ersten Blick scheint es, dass jede Funktion von
z als
d angenommen werden kann . Warum sieht sie so aus? Dafür gibt es zwei Hauptgründe.
Erstens passt
1 / z natürlich in die perspektivische Projektion. Und dies ist die grundlegendste Klasse von Transformationen, bei der garantiert gerade Linien erhalten bleiben. Daher ist die perspektivische Projektion für die Hardware-Rasterung geeignet, da die geraden Kanten der Dreiecke gerade auf dem Bildschirm bleiben. Wir können eine lineare Transformation von
1 / z erhalten , indem wir die Perspektiventeilung nutzen, die die GPU bereits durchführt:
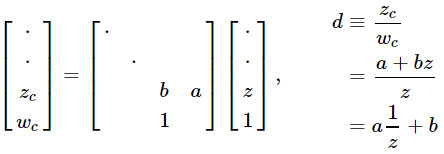
Die wahre Stärke dieses Ansatzes besteht natürlich darin, dass die Projektionsmatrix mit anderen Matrizen multipliziert werden kann, sodass Sie viele Transformationen zu einer kombinieren können.
Der zweite Grund ist, dass
1 / z im Bildschirmbereich linear ist,
wie Emil Persson feststellte . Dies macht es einfach, d im Dreieck während der Rasterung zu interpolieren, und Dinge wie
hierarchische Z-Puffer ,
frühes Z-Culling und
Komprimierungstiefenpuffer .
Kurz aus dem ArtikelWährend der Wert von
w (Ansichtsraumtiefe) im Ansichtsraum linear ist, ist er im Bildschirmraum nicht linear.
z (Tiefe) , nicht linear im Sichtraum, andererseits linear im Bildschirmraum. Dies kann leicht mit einem einfachen DX10-Shader überprüft werden:
float dx = ddx(In.position.z); float dy = ddy(In.position.z); return 1000.0 * float4(abs(dx), abs(dy), 0, 0);
Hier ist In.position SV_Position. Das Ergebnis sieht ungefähr so aus:

Beachten Sie, dass alle Oberflächen monochrom aussehen. Der Unterschied in
z von Pixel zu Pixel ist für jedes Grundelement gleich. Dies ist sehr wichtig für die GPU. Ein Grund ist, dass die
z- Interpolation billiger ist als die
w- Interpolation. Für
z ist keine perspektivische Korrektur erforderlich. Mit billigeren Hardwareeinheiten können Sie mehr Pixel pro Zyklus mit dem gleichen Budget für Transistoren verarbeiten. Dies ist natürlich sehr wichtig für die
Pre-Z-Pass- und
Schattenkarte . Bei moderner Hardware ist die Linearität des Bildschirmbereichs auch eine sehr nützliche Funktion für Z-Optimierungen. Da der Gradient für das gesamte Grundelement linear ist, ist es auch relativ einfach, den genauen Tiefenbereich innerhalb der Kachel für das
Hi-z-Keulen zu berechnen. Dies bedeutet auch, dass eine
Z-Komprimierung möglich ist. Mit einer Konstanten
Δz in
x und
y müssen Sie nicht viele Informationen speichern, um alle
z- Werte in einer Kachel vollständig wiederherstellen zu können, vorausgesetzt, das Grundelement hat die gesamte Kachel abgedeckt.
Tiefendiagramme
Gleichungen sind kompliziert, schauen wir uns ein paar Bilder an!
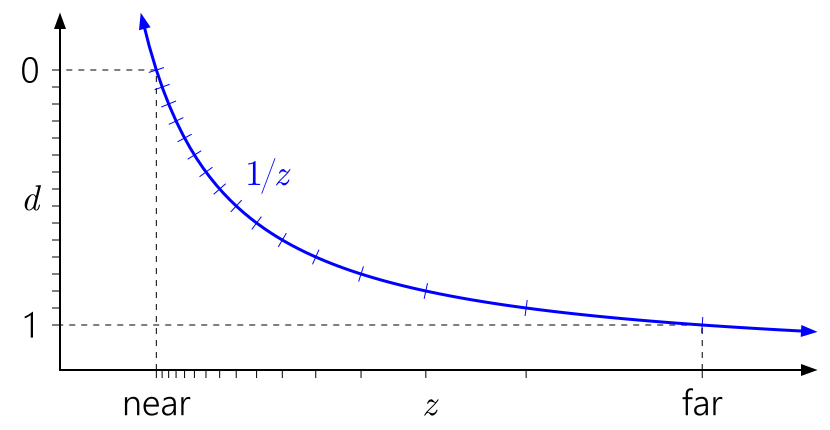
Sie können diese Diagramme von links nach rechts und dann von unten lesen. Beginnen Sie mit
d auf der linken Achse. Da
d eine beliebige lineare Transformation von
1 / z sein kann , können wir 0 und 1 an jeder geeigneten Stelle auf der Achse anordnen. Markierungen zeigen unterschiedliche
Tiefenpufferwerte an . Aus Gründen der Übersichtlichkeit modelliere ich einen normalisierten 4-Bit-Ganzzahl-Tiefenpuffer, sodass 16 Markierungen mit gleichmäßigem Abstand vorhanden sind.
Die obige Grafik zeigt die Standard-Vanille-Tiefenkonvertierung in D3D und ähnliche APIs. Sie können sofort feststellen, dass aufgrund der
1 / z- Kurve Werte nahe der nahen Ebene gruppiert und Werte nahe der fernen Ebene gestreut werden.
Es ist auch leicht zu verstehen, warum die Nähe einer Ebene die Tiefengenauigkeit so stark beeinflusst. Der Abstand in der Nähe der Ebene führt zu einem raschen Anstieg der Werte von
d relativ zu den Werten von
z , was zu einer noch ungleichmäßigeren Verteilung der Werte führt:
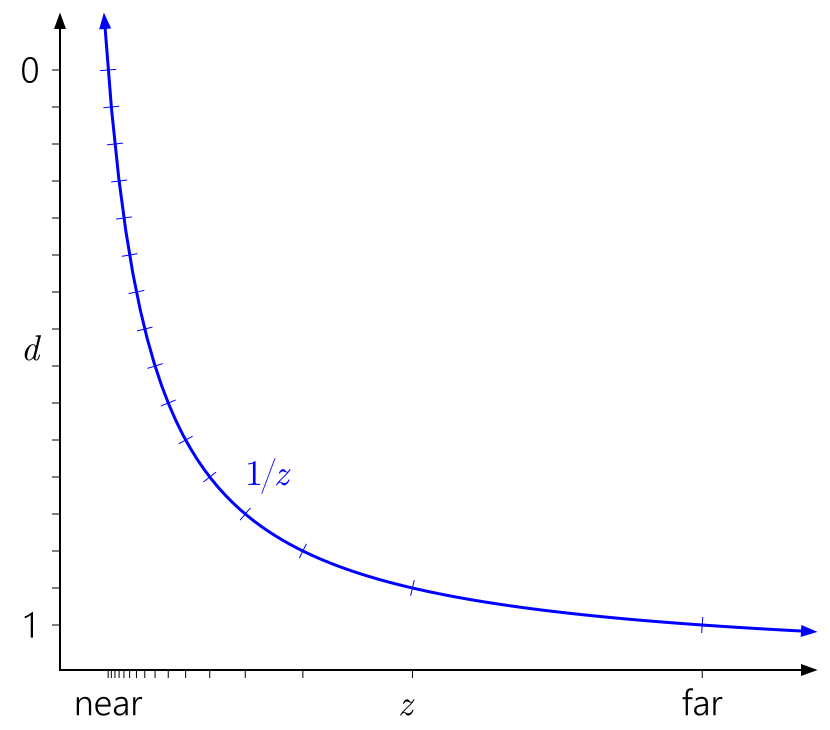
In ähnlicher Weise ist in diesem Zusammenhang leicht zu erkennen, warum das Verschieben der fernen Ebene ins Unendliche keinen so großen Effekt hat. Es bedeutet nur, den Bereich von
d auf
1 / z = 0 zu erweitern :
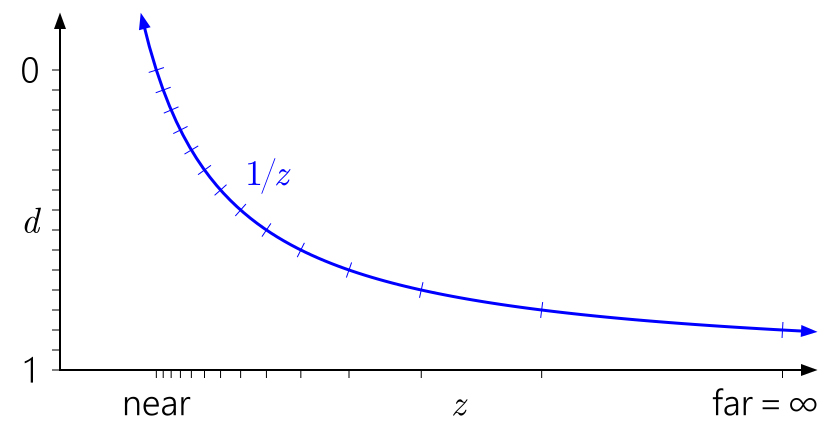
Aber was ist mit der Gleitkommatiefe? Dem folgenden Diagramm wurden Markierungen hinzugefügt, die dem Float-Format mit 3 Bits des Exponenten und 3 Bits der Mantisse entsprechen:
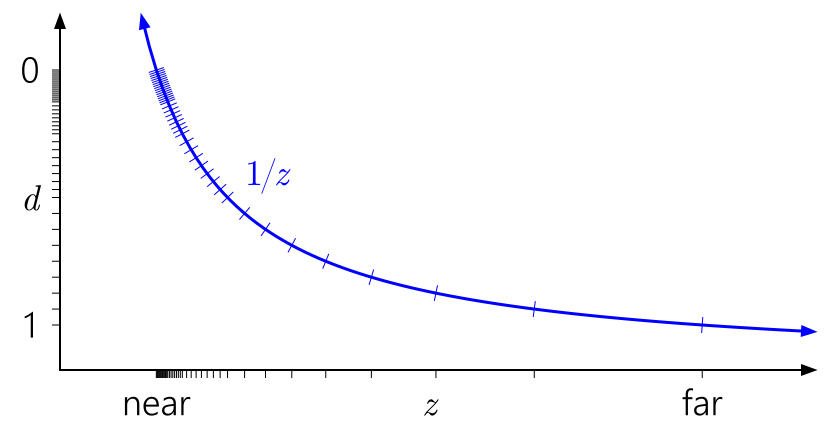
Jetzt gibt es im Bereich [0,1] 40 verschiedene Werte - etwas mehr als 16 Werte früher, aber die meisten von ihnen sind nutzlos nahe der nahen Ebene gruppiert (näher an 0 hat der Schwimmer eine höhere Genauigkeit), wo wir wirklich nicht viel Genauigkeit benötigen.
Ein bekannter Trick besteht nun darin, die Tiefe umzukehren und die nahe Ebene auf
d = 1 und die ferne Ebene auf
d = 0 anzuzeigen:
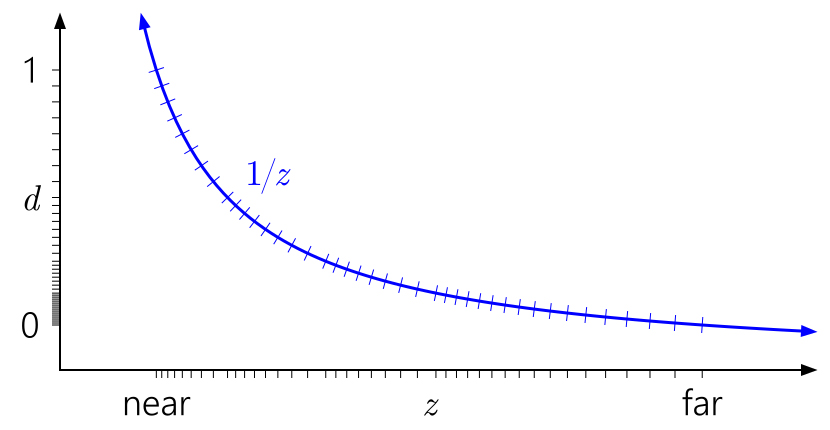
Viel besser! Jetzt kompensiert die quasi-logarithmische Verteilung des Schwimmers irgendwie die Nichtlinearität von
1 / z , während sie näher an der nahen Ebene eine Genauigkeit ergibt, die dem ganzzahligen Tiefenpuffer ähnlich ist, und an anderer Stelle eine signifikant größere Genauigkeit ergibt. Die Tiefengenauigkeit verschlechtert sich sehr langsam, wenn Sie sich weiter von der Kamera entfernen.
Der
umgekehrte Z- Trick wurde möglicherweise mehrmals unabhängig voneinander neu erfunden, aber zumindest die erste Erwähnung erfolgte in der
Veröffentlichung von SIGGRAPH '99 [Eugene Lapidous und Guofang Jiao (leider nicht öffentlich verfügbar)]. Und kürzlich wurde er auf dem Blog von
Matt Petineo und
Brano Kemen sowie in einer Rede von Emil Persson
Creating Vast Game Worlds SIGGRAPH 2012 erneut erwähnt.
Alle vorherigen Diagramme nahmen nach der Projektion einen Tiefenbereich [0,1] an, was in D3D eine Konvention ist. Was ist mit
OpenGL ?
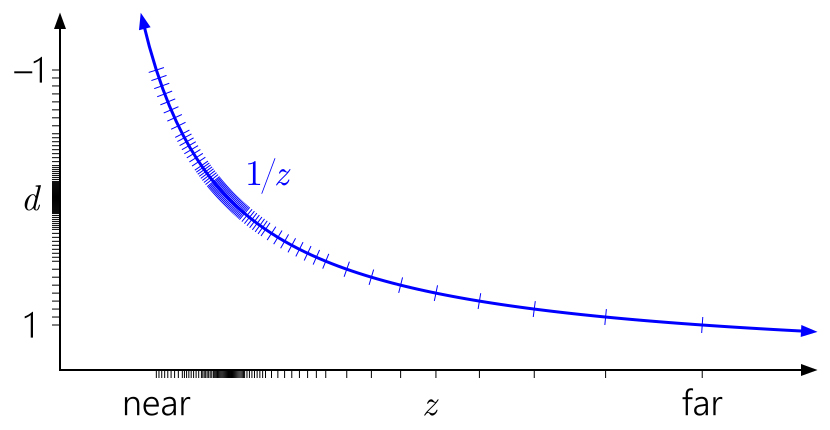 OpenGL
OpenGL nimmt standardmäßig nach der Projektion einen Tiefenbereich [-1, 1] an. Bei ganzzahligen Formaten ändert sich nichts, aber bei Gleitkommazahlen konzentriert sich jede Genauigkeit nutzlos auf die Mitte. (Der Tiefenwert wird für die anschließende Speicherung im Tiefenpuffer auf den Bereich [0,1] abgebildet, dies hilft jedoch nicht weiter, da die anfängliche Zuordnung zu [-1,1] bereits die gesamte Genauigkeit in der anderen Hälfte des Bereichs zerstört hat.) Und aufgrund der Symmetrie
umgekehrt-Z funktioniert hier nicht.
Glücklicherweise kann dies in Desktop-OpenGL mit der weit verbreiteten Erweiterung
ARB_clip_control behoben werden (ebenfalls ab OpenGL 4.5 ist
glClipControl Standard ). Leider ist GL ES im Flug.
Die Auswirkung von Rundungsfehlern
Die
1 / z- Konvertierung und die Wahl zwischen
Float und Int-Tiefenpuffer sind ein großer Teil der Geschichte der Genauigkeit, aber nicht alle. Selbst wenn Sie über eine ausreichende Tiefengenauigkeit verfügen, um die Szene darzustellen, die Sie rendern möchten, kann die Genauigkeit während des Scheitelpunktkonvertierungsprozesses leicht durch Rechenfehler beeinträchtigt werden.
Zu Beginn des Artikels wurde erwähnt, dass Upchurch und Desbrun dieses Problem untersucht haben. Sie schlugen zwei Hauptempfehlungen vor, um Rundungsfehler zu minimieren:
- Verwenden Sie die unendliche Fernebene.
- Halten Sie die Projektionsmatrix von anderen Matrizen getrennt und wenden Sie sie als separate Operation im Vertex-Shader an, anstatt sie mit der Ansichtsmatrix zu kombinieren.
Upchurch und Desbrun gaben diese Empfehlungen unter Verwendung einer Analysemethode ab, die auf der Verarbeitung von Rundungsfehlern als kleine zufällige Fehler basiert, die in jeder arithmetischen Operation dargestellt werden, und deren Verfolgung in der ersten Reihenfolge im Konvertierungsprozess. Ich beschloss, die Ergebnisse in der Praxis zu testen.
Die Quellen
hier sind Python 3.4 und numpy. Das Programm funktioniert wie folgt: Es wird eine Folge von zufälligen Punkten erzeugt, die nach Tiefe geordnet sind und linear oder logarithmisch zwischen nahen und fernen Ebenen liegen. Dann werden die Punkte mit der Ansicht multipliziert und die Matrix projiziert, und die Perspektiventeilung wird unter Verwendung von 32-Bit-Gleitkommazahlen durchgeführt, und optional wird das Endergebnis in ein 24-Bit-Int konvertiert. Am Ende durchläuft es die Sequenz und zählt, wie oft 2 benachbarte Punkte (die anfangs unterschiedliche Tiefen hatten) entweder identisch wurden, weil sie dieselbe Tiefe hatten oder die Reihenfolge überhaupt geändert wurde. Mit anderen Worten, das Programm misst in verschiedenen Szenarien die Häufigkeit, mit der Tiefenvergleichsfehler auftreten - was Problemen wie
Z-Kämpfen entspricht.
Hier sind die Ergebnisse für nah = 0,1, fern = 10 K mit einer linearen Tiefe von 10 K. (Ich habe das logarithmische Tiefenintervall und andere Nah / Fern-Verhältnisse ausprobiert, und obwohl die spezifischen Zahlen variierten, waren die allgemeinen Trends in den Ergebnissen dieselben.)
In der Tabelle werden "eq" - zwei Punkte mit der nächsten Tiefe erhalten den gleichen Wert im Tiefenpuffer und "swap" - zwei Punkte mit der nächsten Tiefe werden getauscht.
| Zusammengesetzte Ansichtsprojektionsmatrix | Separate Ansichts- und Projektionsmatrizen |
| float32 | int24 | float32 | int24 |
| Unveränderte Z-Werte (Kontrolltest) | 0% Gl
0% Swap | 0% Gl
0% Swap | 0% Gl
0% Swap | 0% Gl
0% Swap |
| Standardprojektion | 45% Äq
18% Swap | 45% Äq
18% Swap | 77% Äq
0% Swap | 77% Äq
0% Swap |
| Unendlich weit | 45% Äq
18% Swap | 45% Äq
18% Swap | 76% Äq
0% Swap | 76% Äq
0% Swap |
| Umgekehrt z | 0% Gl
0% Swap | 76% Äq
0% Swap | 0% Gl
0% Swap | 76% Äq
0% Swap |
| Unendlich + umgekehrt-Z | 0% Gl
0% Swap | 76% Äq
0% Swap | 0% Gl
0% Swap | 76% Äq
0% Swap |
| Standard + GL-Stil | 56% Äq
12% Swap | 56% Äq
12% Swap | 77% Äq
0% Swap | 77% Äq
0% Swap |
| Unendlich + GL-Stil | 59% Äq
10% Swap | 59% Äq
10% Swap | 77% Äq
0% Swap | 77% Äq
0% Swap |
Ich entschuldige mich für die Tatsache, dass es ohne Grafik hier zu viele Dimensionen gibt und ich sie einfach nicht erstellen kann! In jedem Fall sind bei Betrachtung der Zahlen die folgenden Schlussfolgerungen offensichtlich:
- In den meisten Fällen gibt es keinen Unterschied zwischen int- und float-Tiefenpuffer . Arithmetische Fehler zur Berechnung von Tiefenüberschreibungsfehlern bei der Konvertierung in int. Zum Teil, weil float32 und int24 fast gleich ULP haben (die Einheit mit der geringsten Genauigkeit ist der Abstand zur nächsten benachbarten Zahl), und zwar um [0.5.1] (da float32 eine 23-Bit-Mantisse hat), sodass ein Konvertierungsfehler nicht über fast den gesamten Tiefenbereich hinzugefügt wird in int.
- In den meisten Fällen verbessert die Trennung von Ansichts- und Projektionsmatrizen (gemäß den Empfehlungen von Upchurch und Desbrun) das Ergebnis. Trotz der Tatsache, dass die Gesamtfehlerrate nicht abnimmt, werden „Swaps“ zu gleichen Werten, und dies ist ein Schritt in die richtige Richtung.
- Die unendliche Fernebene ändert die Fehlerhäufigkeit geringfügig. Upchurch und Desbrun sagten eine Verringerung der Häufigkeit numerischer Fehler (Genauigkeitsfehler) um 25% voraus, dies scheint jedoch nicht zu einer Verringerung der Häufigkeit von Vergleichsfehlern zu führen.
Die obigen Befunde sind jedoch im Vergleich zu Magic
Reverse-Z nicht real. Überprüfen Sie:
- Reversed-Z mit Float-Tiefenpuffer ergibt im Test eine Fehlerrate von Null . Jetzt können natürlich einige Fehler auftreten, wenn Sie das Intervall der Eingabetiefenwerte weiter erhöhen. Reverse-Z mit Float ist jedoch lächerlich genauer als jede andere Option.
- Reversed-Z mit Integer-Tiefenpuffer ist genauso gut wie andere Integer-Optionen.
- Reversed-Z verwischt die Unterscheidung zwischen zusammengesetzten und separaten Ansichts- / Projektionsmatrizen sowie endlichen und unendlichen Fernebenen. Mit anderen Worten, mit umgekehrtem Z können Sie die Projektion mit anderen Matrizen multiplizieren und jede gewünschte ferne Ebene verwenden, ohne die Genauigkeit zu beeinträchtigen.
Fazit
Ich denke, die Schlussfolgerung ist klar. Verwenden Sie in jeder Situation bei der perspektivischen Projektion einfach den
Float-Tiefenpuffer und das umgekehrte Z ! Und wenn Sie den Float-Tiefenpuffer nicht verwenden können, sollten Sie immer noch das umgekehrte Z verwenden. Dies ist kein Allheilmittel für alle Krankheiten, insbesondere wenn Sie eine offene Umgebung mit extremen Tiefenbereichen schaffen. Aber das ist ein guter Anfang.