Kürzlich haben wir
darüber gesprochen, wie man ein Praktikum bei Google bekommt. Neben Google versuchen sich unsere Schüler bei JetBrains, Yandex, Acronis und anderen Unternehmen.
In diesem Artikel werde ich meine Praktikumserfahrung bei
JetBrains Research teilen, über die Aufgaben sprechen, die sie dort lösen, und darüber nachdenken, wie maschinelles Lernen nach Fehlern im Programmcode suchen kann.

Über mich
Mein Name ist Yegor Bogomolov, ich bin ein Student des 4. Studienjahres des HSE-Grundstudiums in Angewandter Mathematik und Informatik in St. Petersburg. In den ersten drei Jahren habe ich wie meine Klassenkameraden an der Akademischen Universität studiert und seit September sind wir mit der gesamten Abteilung an die Higher School of Economics gewechselt.
Nach dem 2. Jahr habe ich ein Sommerpraktikum bei Google Zürich absolviert. Dort habe ich drei Monate im Android Calendar-Team gearbeitet, die meiste Zeit Frontend'om und ein bisschen UX-Recherche. Der interessanteste Teil meiner Arbeit war die Untersuchung, wie Kalenderschnittstellen in Zukunft aussehen könnten. Es stellte sich als angenehm heraus, dass fast die gesamte Arbeit, die ich am Ende des Praktikums geleistet habe, in der Hauptversion der Bewerbung landete. Das Thema Praktika bei Google wurde jedoch in einem früheren Beitrag sehr gut behandelt. Ich werde daher darüber sprechen, was ich diesen Sommer gemacht habe.
Was ist JB Research?
JetBrains Research besteht aus einer Reihe von Labors, die in verschiedenen Bereichen arbeiten: Programmiersprachen, angewandte Mathematik, maschinelles Lernen, Robotik und andere. In jedem Bereich gibt es mehrere wissenschaftliche Gruppen. Aufgrund meiner Anleitung bin ich am besten mit den Aktivitäten von Gruppen im Bereich des maschinellen Lernens vertraut. Jeder von ihnen veranstaltet wöchentliche Seminare, in denen Gruppenmitglieder oder geladene Gäste über ihre Arbeit oder interessante Artikel auf ihrem Gebiet sprechen. Viele Studenten der HSE kommen zu diesen Seminaren, wenn sie vom Hauptgebäude des HSE-Campus in St. Petersburg über die Straße gehen.
In unserem Bachelor-Studiengang beschäftigen wir uns notwendigerweise mit Forschungsarbeiten (F & E) und präsentieren die Forschungsergebnisse zweimal im Jahr. Oft entwickelt sich diese Arbeit allmählich zu Sommerpraktika. Dies geschah auch mit meiner Forschungsarbeit: Diesen Sommer habe ich bei meinem Forschungsleiter Timofey Bryksin ein Praktikum im Labor „Methoden des maschinellen Lernens in der Softwareentwicklung“ absolviert. Zu den Aufgaben, an denen in diesem Labor gearbeitet wird, gehören Vorschläge für die automatische Umgestaltung, die Analyse des Codestils für Programmierer, die Code-Vervollständigung und die Suche nach Fehlern im Programmcode.
Mein Praktikum dauerte zwei Monate (Juli und August), und im Herbst beschäftigte ich mich weiterhin mit zugewiesenen Aufgaben im Rahmen der Forschung. Ich habe in verschiedenen Bereichen gearbeitet, von denen meiner Meinung nach die automatische Suche nach Fehlern im Code am interessantesten war, und ich möchte darüber sprechen. Ausgangspunkt war
ein Artikel von Michael Pradel .
Automatische Fehlersuche
Wie werden Fehler jetzt gesucht?
Warum nach Fehlern suchen, ist mehr oder weniger klar. Mal sehen, wie es ihnen jetzt geht. Moderne Fehlerdetektoren basieren hauptsächlich auf statischer Code-Analyse. Suchen Sie für jeden Fehlertyp nach zuvor festgestellten Mustern, anhand derer er bestimmt werden kann. Um die Anzahl der falsch positiven Ergebnisse zu verringern, werden Heuristiken erfunden, die für jeden Einzelfall erfunden werden. Muster können sowohl in einem durch Code erstellten abstrakten Syntaxbaum (AST) als auch in Diagrammen eines Kontrollflusses oder von Daten gesucht werden.
int foo() { if ((x < 0) || x > MAX) { return -1; } int ret = bar(x); if (ret != 0) { return -1; } else { return 1; } }
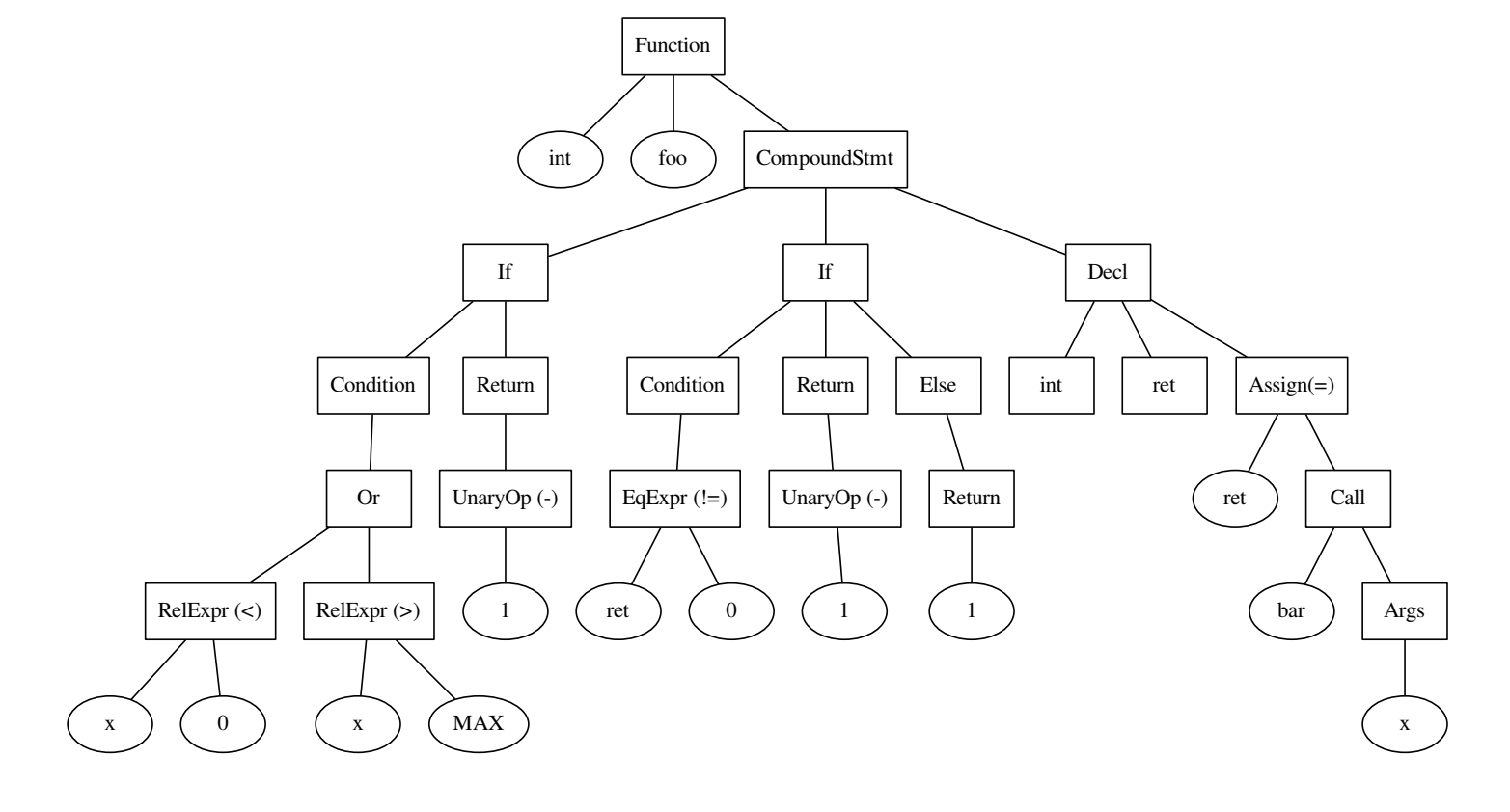
Der Code und der darauf erstellte Baum.
Betrachten Sie ein Beispiel, um zu verstehen, wie dies funktioniert. Die Art von Fehlern kann die Verwendung von = anstelle von == in C ++ sein. Schauen wir uns den folgenden Code an:
int value = 0; … if (value = 1) { ... } else { … }
Es gab einen Fehler im bedingten Ausdruck, während das erste = bei der Zuordnung des Werts zur Variablen korrekt ist. Das Muster stammt von hier: Wenn die Zuweisung innerhalb der Bedingung in if verwendet wird, ist dies ein potenzieller Fehler. Wenn Sie in AST nach einem solchen Muster suchen, können wir den Fehler erkennen und korrigieren.
int value = 0; … if (value == 1) { ... } else { … }
In einem allgemeineren Fall können wir den Fehler nicht so einfach beschreiben. Angenommen, wir möchten die richtige Reihenfolge der Operanden bestimmen. Schauen Sie sich noch einmal die Codefragmente an:
for (int i = 2; i < n; i++) { a[i] = a[1 - i] + a[i - 2]; }
int bitReverse(int i) { return 1 - i; }
Im ersten Fall war die Verwendung von 1-i fehlerhaft, und im zweiten Fall war sie völlig korrekt, was aus dem Kontext hervorgeht. Aber wie soll man es in Form eines Musters beschreiben? Mit der Komplikation der Art der Fehler müssen wir einen größeren Codeabschnitt berücksichtigen und immer mehr Einzelfälle analysieren.
Das letzte motivierende Beispiel: Nützliche Informationen sind auch in den Namen von Methoden und Variablen enthalten. Es ist noch schwieriger, sich durch einige manuell festgelegte Bedingungen auszudrücken.
int getSquare(int xDim, int yDim) { … } int x = 3, y = 4; int s = getSquare(y, x);
Eine Person versteht, dass die Argumente im Funktionsaufruf höchstwahrscheinlich verwechselt sind, weil wir verstehen, dass x eher xDim als yDim ähnelt. Aber wie soll man das dem Detektor melden? Sie können eine Art Heuristik der Form "Der Variablenname ist das Präfix des Argumentnamens" hinzufügen. Nehmen Sie jedoch an, dass x häufiger eine Breite als eine Höhe ist, also nicht mehr ausdrücken.
Fazit: Das Problem des modernen Ansatzes zum Auffinden von Fehlern besteht darin, dass viel Arbeit mit Ihren Händen erledigt werden muss: Um Muster zu bestimmen, fügen Sie Heuristiken hinzu. Aus diesem Grund wird das Hinzufügen von Unterstützung für einen neuen Fehlertyp im Detektor zeitaufwändig. Darüber hinaus ist es schwierig, einen wichtigen Teil der Informationen zu verwenden, die der Entwickler im Code hinterlassen hat: die Namen von Variablen und Methoden.
Wie kann maschinelles Lernen helfen?
Wie Sie vielleicht bemerkt haben, sind in vielen Beispielen Fehler für Menschen sichtbar, aber formal schwer zu beschreiben. In solchen Situationen können maschinelle Lernmethoden oft helfen. Hören wir auf, in einem Funktionsaufruf nach neu angeordneten Argumenten zu suchen, und verstehen, was wir brauchen, um sie mithilfe von maschinellem Lernen zu suchen:
- Eine große Anzahl von Beispielcode ohne Fehler
- Eine große Menge an Code mit Fehlern eines bestimmten Typs
- Methode zur Vektorisierung von Codefragmenten
- Das Modell, das wir lehren werden, um zwischen Code mit und ohne Fehler zu unterscheiden
Wir können hoffen, dass in den meisten öffentlich zugänglichen Codes die Argumente in den Funktionsaufrufen in der richtigen Reihenfolge sind. Daher können Sie für Beispielcode ohne Fehler einen großen Datensatz verwenden. Im Fall des Autors des Originalartikels war es JS 150K (150.000 Dateien in Javascript), in unserem Fall ein ähnlicher Datensatz für Python.
Das Finden von Code mit Fehlern ist viel schwieriger. Aber wir können nicht nach Fehlern anderer suchen, sondern sie selbst machen! Für die Art der Fehler müssen Sie eine Funktion angeben, die sie gemäß dem richtigen Code beschädigt. In unserem Fall ordnen Sie die Argumente im Funktionsaufruf neu an.
Wie vektorisiere ich den Code?
Mit viel gutem und schlechtem Code sind wir fast bereit, etwas zu lehren. Vorher müssen wir noch die Frage beantworten: Wie werden Codefragmente dargestellt?
Ein Funktionsaufruf kann als Tupel aus dem Namen einer Methode, dem Namen ihrer Methode, den Namen und Typen von Argumenten dargestellt werden, die an Variablen übergeben werden. Wenn wir lernen, wie man einzelne Token vektorisiert (Namen von Variablen und Methoden, alle im Code enthaltenen „Wörter“), können wir die Verkettung von Vektoren von Token von Interesse für uns nehmen und den gewünschten Vektor für das Fragment erhalten.
Um Token zu vektorisieren, schauen wir uns an, wie Wörter in gewöhnlichen Texten vektorisieren. Eine der erfolgreichsten und beliebtesten Möglichkeiten ist das 2013 vorgeschlagene word2vec.
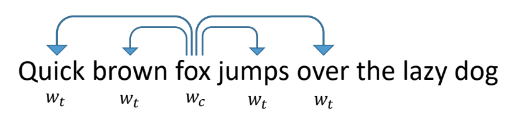
Es funktioniert wie folgt: Wir bringen dem Netzwerk bei, andere Wörter, die in Texten daneben erscheinen, durch Worte vorherzusagen. Das Netzwerk sieht gleichzeitig aus wie eine Eingabeebene von der Größe eines Wörterbuchs, eine verborgene Ebene von der Größe der Vektorisierung, die wir erhalten möchten, und eine Ausgabeschicht, die ebenfalls die Größe eines Wörterbuchs hat. Während des Trainings werden die Netzwerke mit einem Eingabeeinheitenvektor mit einer Einheit anstelle des betreffenden Wortes (Fuchs) gespeist, und an der Ausgabe möchten wir Wörter erhalten, die innerhalb des Fensters um dieses Wort auftreten (schnell, braun, springt, über). In diesem Fall übersetzt das Netzwerk zuerst alle Wörter in einen Vektor auf einer verborgenen Ebene und macht dann eine Vorhersage.
Die resultierenden Vektoren für einzelne Wörter haben gute Eigenschaften. Beispielsweise sind Wortvektoren mit einer ähnlichen Bedeutung nahe beieinander, und die Summe und Differenz der Vektoren sind die Addition und Differenz der "Bedeutungen" der Wörter.
Um eine ähnliche Vektorisierung von Token im Code vorzunehmen, müssen Sie die vorhergesagte Umgebung irgendwie festlegen. Dies können Informationen von AST sein: Arten von Scheitelpunkten, angetroffene Token, Position in einem Baum.
Nachdem Sie eine Vektorisierung erhalten haben, können Sie sehen, welche Token einander ähnlich sind. Berechnen Sie dazu den Kosinusabstand zwischen ihnen. Als Ergebnis werden die folgenden benachbarten Vektoren für Javascript erhalten (Zahl ist der Kosinusabstand):
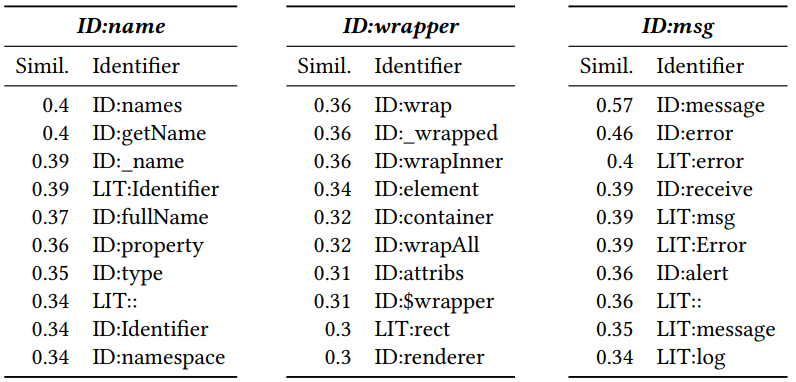
Die am Anfang hinzugefügte ID und LIT geben an, ob das Token ein Bezeichner (Name einer Variablen, Methode) oder ein Literal (Konstante) ist. Es ist ersichtlich, dass die Nähe sinnvoll ist.
Klassifikator Training
Nachdem Sie eine Vektorisierung für einzelne Token erhalten haben, ist es ganz einfach, eine Ansicht für einen Code mit einem potenziellen Fehler zu erhalten: Es handelt sich um eine Verkettung von Vektoren, die für die Klassifizierung von Token wichtig sind. Ein zweischichtiges Perzeptron wird in Codeteilen mit ReLU als Aktivierungsfunktion und Dropout trainiert, um eine Überanpassung zu reduzieren. Das Lernen konvergiert schnell, das resultierende Modell ist klein und kann Vorhersagen für Hunderte von Beispielen pro Sekunde treffen. Auf diese Weise können Sie es in Echtzeit verwenden, was später erläutert wird.
Ergebnisse
Die Qualitätsbewertung des resultierenden Klassifikators wurde in zwei Teile unterteilt: Bewertung einer großen Anzahl künstlich erzeugter Beispiele und manuelle Überprüfung einer kleinen Anzahl (50 für jeden Detektor) von Beispielen mit der höchsten vorhergesagten Wahrscheinlichkeit. Die Ergebnisse für die drei Detektoren (neu angeordnete Argumente, die Richtigkeit des binären Operators und des binären Operanden) waren wie folgt:
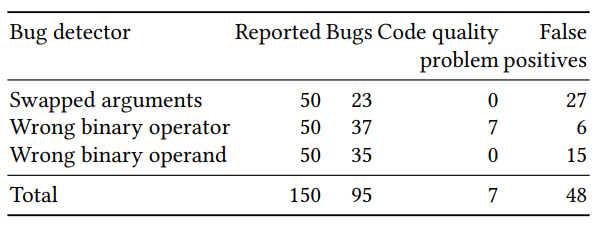
Einige der vorhergesagten Fehler wären mit klassischen Suchmethoden schwer zu finden. Ein Beispiel mit neu angeordneten res und err in einem Aufruf von p.done:
var p = new Promise (); if ( promises === null || promises . length === 0) { p. done (error , result ) } else { promises [0](error, result).then( function(res, err) { p.done(res, err); }); }
Es gab auch Beispiele, bei denen kein Fehler auftrat, die Variablen jedoch umbenannt werden sollten, um die Person, die versucht, den Code herauszufinden, nicht irrezuführen. Zum Beispiel scheint das Hinzufügen von Breite und jeder keine gute Idee zu sein, obwohl sich herausstellte, dass dies kein Fehler ist:
var cw = cs[i].width + each;
Python-Portierung
Ich war daran beteiligt, Michael Pradels Arbeit von js auf Python zu portieren und dann ein Plug-In für PyCharm zu erstellen, das Inspektionen basierend auf der oben beschriebenen Methode implementiert. Wir haben den
Python 150K- Datensatz verwendet (150.000 Python-Dateien auf GitHub verfügbar).
Zunächst stellte sich heraus, dass es in Python mehr verschiedene Token als in Javascript gibt. Für js machten die 10.000 beliebtesten Token mehr als 90% aller angetroffenen Token aus, während für Python etwa 40.000 verwendet werden mussten. Dies führte zu einer Vergrößerung der Token in Vektoren, was die Portierung auf das Plugin schwierig machte.
Zweitens, nachdem ich für Python eine Suche nach falschen Argumenten in Funktionsaufrufen implementiert und die Ergebnisse manuell betrachtet hatte, erhielt ich eine Fehlerrate von mehr als 90%, was im Widerspruch zu den Ergebnissen für js stand. Nachdem ich die Gründe verstanden hatte, stellte sich heraus, dass in Javascript mehr Funktionen in derselben Datei deklariert wurden wie ihre Aufrufe. Nach dem Beispiel des Autors des Artikels habe ich zunächst die Deklaration von Funktionen aus anderen Dateien nicht zugelassen, was zu schlechten Ergebnissen führte.
Gegen Ende August habe ich die Implementierung für Python abgeschlossen und die Basis für das Plugin geschrieben. Das Plugin wird weiterentwickelt, jetzt ist die Studentin Anastasia Tuchina aus unserem Labor damit beschäftigt.
Die Schritte zum Testen der Funktionsweise des Plugins finden Sie im Repository-Wiki.
Links auf Github:
Repository mit Python-ImplementierungRepository mit Plugin