
Im Netzwerk finden Sie eine Vielzahl verschiedener Artikel über Methoden zur Verwendung mathematischer Statistikalgorithmen, über neuronale Netzwerke und über die Vorteile des maschinellen Lernens im Allgemeinen. Diese Bereiche tragen zu einer signifikanten Verbesserung des menschlichen Lebens und einer besseren Zukunft für Roboter bei. Zum Beispiel eine neue Generation von Pflanzen, die ganz oder teilweise ohne menschliches Eingreifen oder eine Autopilotmaschine arbeiten können.
Entwickler kombinieren Kombinationen dieser Ansätze und Methoden des maschinellen Lernens in verschiedene Richtungen. Diese Bereiche erhalten anschließend originelle und nicht sehr originelle Namen, zum Beispiel: IOT (Internet der Dinge), WOT (Web der Dinge), Industrie 4.0 (Industrie 4.0), Künstliche Intelligenz (KI) und andere. Diese Konzepte werden durch die Tatsache vereint, dass ihre Beschreibung auf höchster Ebene erfolgt, dh weder bestimmte Tools und Technologien berücksichtigt werden noch bereit sind, das System zu implementieren, und das Hauptziel darin besteht, das gewünschte Ergebnis zu visualisieren. Technologie existiert jedoch bereits, obwohl sie häufig keine einzige Plattform hat.
Die Lösungen werden sowohl von großen Softwareanbietern bereitgestellt: SAS, SAP, Oracle, IBM als auch von kleinen Start-ups, die einen starken Wettbewerb für große Unternehmen darstellen, sowie von Open Source-Lösungen - Open Source-Lösungen. All diese Vielfalt erschwert die schnelle und effektive Umsetzung der Aufgabe erheblich, da die mühsame Integration verschiedener Systeme untereinander, die enormen Anstrengungen der Entwickler, gute Modelle für maschinelles Lernen zu erstellen, und die zukünftige Implementierung dieser Lösungen auf produktive Weise erforderlich sind. Gleichzeitig erfordert das Hauptkriterium für den Erfolg eines Innovationsprojekts, das den Geschäftsansatz des Unternehmens ändert, häufig einen schnellen Nachweis von Erfolg und Zahlungsfähigkeit, da sonst niemand den Start wagt. Dies ist ohne die Verwendung einer einzigen Plattform nicht möglich. Auf diese Weise können Sie den gesamten Zyklus der Aufbereitung (Suche, Erfassung, Bereinigung, Konsolidierung) von Daten schnell abschließen und Endergebnisse in Form hochwertiger Analysen (einschließlich der Verwendung von Algorithmen für maschinelles Lernen) und damit Gewinn erzielen für das Unternehmen.
Über SAS
Viele mögen zustimmen, dass SAS eine hohe Position auf dem Markt für fortschrittliche Analyselösungen hat. Die Bewertungen von SAS-Lösungen mögen unterschiedlich sein, aber es gibt niemanden, dem es gleichgültig ist, was durch die Präsenz einer großen Anzahl von Kunden in Russland und auf der Welt bestätigt wird. Vor allem dank vorgefertigter Algorithmen und Modelle, die einfach und schnell im Unternehmen implementiert werden können und schnell das Ergebnis liefern. Im ersten Artikel im SAS-Blog wurde viel darüber geschrieben - Sie können es hier lesen . Dieser Artikel beschreibt den Hintergrund für den Erfolg und die Geschichte von SAS. Die IT- und Geschäftswelt entwickelt sich jedoch rasant und stellt immer höhere Anforderungen an Tools. Daher hat SAS mit SAS Viya eine neue Analyseplattform veröffentlicht. Diese Plattform enthält das Beste, was SAS seit seiner Einführung bis heute geschaffen hat, um die aktuellen Trends in der Klasse der Lösungen für erweiterte Analysen zu ermitteln. SAS Viya kehrt zu schönen Namen und Definitionen zurück und bietet eine einheitliche Plattform für eine Richtung wie Self-Service Data Science mit In-Memory-Funktionen, die unter Verwendung von Ansätzen verteilter (Cloud-) Computing- und Microservice-Architektur entwickelt wurde. In diesem Artikel wird eine Reihe von Artikeln über die SAS Viya-Plattform geöffnet, um herauszufinden, was Viya ist, was es kann und wie es verwendet wird.
Schwierigkeiten bei der Auswahl
Wir haben bereits herausgefunden, dass es jetzt auf dem Markt eine große Anzahl von Produkten berühmter Anbieter und kleinerer Anbieter sowie Open Source gibt, mit denen Sie verschiedene analytische Probleme in allen Geschäftsbereichen lösen können. Welche Kriterien neben dem Preis sollten bei der Auswahl einer bestimmten Plattform berücksichtigt werden?

Zunächst wird der Geschäftsbenutzer immer mehr in den gesamten Analysezyklus einbezogen und benötigt eine größere Unabhängigkeit von der IT. Für diese Benutzer verständliche Kriterien stehen im Vordergrund - Benutzerfreundlichkeit (einzelne Schnittstellen), Minimierung des Lernens neuer Systeme (weniger Code, mehr Grafiken), Leistung (in Bezug auf Analysen - dies ist die Fähigkeit, schnell Ergebnisse auf Arrays mit großen Datenmengen zu erzielen), Verfügbarkeit vorgefertigter Algorithmen und Modelle für die Arbeit. Die Zeit für schwarze Bildschirme läuft ab. Terminalfenster sind zwar in einer anderen Form verfügbar, aber Sie können Code auch unterwegs schreiben und debuggen. Die meisten Funktionen können jedoch bereits als Blöcke in der grafischen Oberfläche implementiert werden, wodurch die Tür für alle Benutzer geöffnet wird Niveaus für die Arbeit mit fortgeschrittener Analytik (obwohl es immer noch wünschenswert ist, Mathematik zu kennen).
Der zweite Trend, der unweigerlich die Märkte erobert, ist die Cloud-Technologie. Aus Sicht der Unternehmen ist dies die Möglichkeit einer flexiblen Verwaltung der verfügbaren Ressourcen für alle Projekte. Es gibt viel Forschung über die Zeit, in der Cloud-Technologien klassische Lösungen vollständig ersetzt haben. Hier ist es jedoch wichtig zu verstehen, dass Cloud Computing nicht nur Hardware ist, die irgendwo weit entfernt in externen Rechenzentren lebt, sondern auch der Ansatz, alle Arten von Diensten flexibel in Form von Diensten bereitzustellen, die schnell und ohne den Aufbau oder die Wiederherstellung einer komplexen IT-Infrastruktur verfügbar sind.
Ein weiterer Trend ist der Einsatz von Big Data-Technologien. Und die Nutzung des gesamten Hadoop-Ökosystems als Ganzes mit seinen eigenen Sprachen und Technologien sowie anderen verfügbaren Open-Source-Systemen, die Schnittstellen für die Arbeit mit Daten wie R, Python und anderen bieten. Es macht keinen Sinn, in diesem Bereich zu konkurrieren, aber es ist sinnvoll, Technologien für die Integration in dieses Ökosystem zu haben. Oder integrieren Sie nicht nur die Funktionen dieses Ökosystems, sondern nutzen Sie sie, wie dies beim eingebetteten SAS Hadoop-Prozess der Fall ist, oder verwenden Sie Kafka, um Hochverfügbarkeit für ESP-Systeme (SAS Event Stream Processing) zu erstellen. Und manchmal sogar verbessern und beschleunigen, beispielsweise die Möglichkeit, R-Code auf der CAS-Engine in SAS Viya auszuführen.
Universelle Plattform
Nachfrage schafft Angebot und SAS Viya ist keine Ausnahme von der Regel. Wenn wir uns auf die offizielle Definition von SAS Viya beziehen, die Jim Goodnight während der Ankündigung im Jahr 2016 auf dem globalen SAS-Forum gegeben hat (sehr reduziert, aber die Bedeutung bleibt erhalten), dann lautet SAS Viya: „Ein Cloud-System, das verteilte Computeransätze verwendet ... und gibt einheitliche Analyseplattform
Wenn Sie kurz die Idee und die Ziele der SAS Viya-Plattform darlegen, ist dies eine universelle Plattform für jede Art von Analyse in allen Phasen des Projekts, von der Datenaufbereitung bis zur Verwendung komplexer Algorithmen für maschinelles Lernen. Es gibt 4 Aufgabenblöcke:
1. Datenaufbereitung
2. Datenvisualisierung und -recherche
3. Predictive Analytics
4. Erweiterte Analyse in Form von Algorithmen für maschinelles Lernen
Informationen für Leser
Da es ziemlich schwierig ist, alles im Rahmen eines Artikels unbeschadet wichtiger Nuancen zu erzählen, werden diese Schritte in den folgenden Artikeln anhand von Beispielen betrachtet. In diesem Artikel werden wir ein wichtiges Thema der SAS Viya-Engine behandeln, die eine schnelle Arbeit mit Analysetools ermöglicht. Als nächstes folgen Artikel über moderne und schöne Schnittstellen.
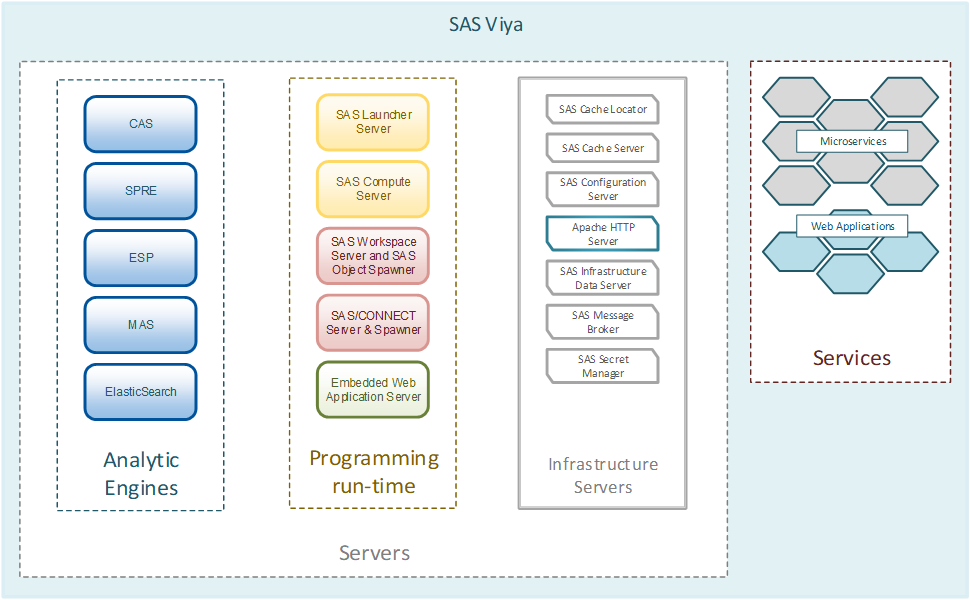
Die Basis der SAS Viya Plattform
SAS Viya bietet verschiedene wichtige Funktionen für den Einstieg. Diejenigen, die mit SAS-Lösungen gearbeitet haben, wissen, dass SAS auf der speziellen Analysesprache SAS Base basiert, die Analyseaufgaben für die Engine ausführt. Es kann in einer Grid-Konfiguration in einem Cluster oder auf einem leistungsstarken Computer verwendet werden. Hier liegt der Hauptunterschied zwischen SAS Viya und den klassischen SAS 9-Analyselösungen. SAS Viya basiert auf einer neuen einzigartigen
CAS- Datenverarbeitungs-Engine
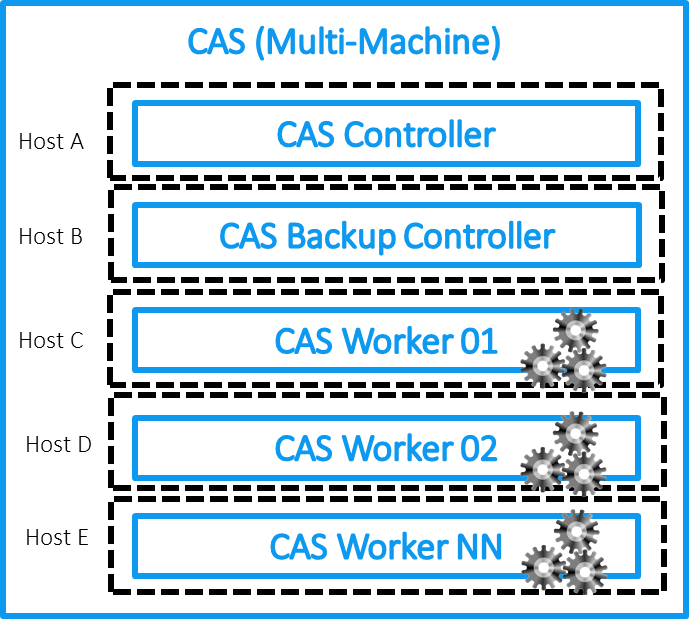
(Cloud Analytics Service) . Zwei Hauptmerkmale: Das erste ist eine In-Memory-Technologie, die alle Operationen mit Daten im RAM ausführt, und das zweite ist ein verteilter Computeransatz. CAS kann auf einem einzelnen Host ausgeführt werden, ist jedoch für die Arbeit auf einem Cluster von Computern optimiert - dem Controller und den Datenverarbeitungsservern, mit denen Sie Daten auf verschiedenen Knoten des Clusters speichern und verarbeiten können, um die Last zu parallelisieren (der ideologische Ansatz kommt dem Konzept von Hadoop-Systemen sehr nahe). Wenn wir die CAS-Architektur im Diagramm zeigen, erhalten wir das folgende Bild für die MPP- oder SMP-Installation:

Warum Wolke?
SAS nutzte bei der Entwicklung der Viya-Plattform und insbesondere CAS das Konzept des Cloud Computing. Sie können in 4 Gruppen unterteilt werden:
1. Zugänglichkeit über eine große Anzahl von APIs verschiedener Clients. Für SAS ist dies ein großer Schritt nach vorne. Es gibt keine Einschränkungen mehr, nur die SAS-Basissprache für die Analyse zu verwenden. Sie können Python (z. B. aus einem Jupiter-Notizbuch), R, Lua usw. verwenden, das in CAS auf der SAS Viya-Plattform ausgeführt wird.
2. Elastizität. Sie können das System einfach skalieren, indem Sie Knoten des CAS-Clusters verbinden / trennen. Anwendungen sind über das Internet zugänglich und als Microservices organisiert. Sie sind in Bezug auf Installation, Aktualisierung und Betrieb unabhängig voneinander.
3. Hohe Verfügbarkeit. CAS verwendet ein Datenspiegelungssystem zwischen Clusterknoten. Ein Datensatz wird auf mehreren Knoten gespeichert, wodurch das Risiko eines Datenverlusts verringert wird. Das Umschalten bei einem Ausfall eines der Knoten erfolgt automatisch, während der Status der Aufgabe beibehalten wird, was häufig für umfangreiche analytische Berechnungen von entscheidender Bedeutung ist.
4. Erhöhte Sicherheit. Da die Cloud von einem öffentlichen Anbieter bezogen werden kann, muss die Implementierung strengere Anforderungen an die Zuverlässigkeit von Datenübertragungskanälen erfüllen.
Sie können die Viya-Plattform überall bereitstellen - in der Cloud, auf einem dedizierten Computer in Ihrem eigenen Rechenzentrum, in einem Cluster mit einer beliebigen Anzahl von Computern. Die Fehlertoleranz der Lösung wird automatisch bereitgestellt.
Wie funktioniert CAS?
Ich werde die Arbeit von CAS am Beispiel der MPP-Installation analysieren. SMP vereinfacht, behält aber die Prinzipien von CAS bei. In der Praxis kann SMP als lokale Testumgebung zum Testen von Modellen verwendet werden, wobei die Entwicklung anschließend auf die MPP-Plattform übertragen wird, um eine bessere Leistung zu erzielen.
Schauen wir uns noch einmal die CAS-Architektur der obersten Ebene auf SAS Viya an:
Wenn wir über CAS sprechen, besteht es aus einem Controller, auf andere Weise einem Masterknoten (und es ist möglich, einen anderen Knoten für den Backup-Controller-Knoten zuzuweisen) und Arbeitsknoten. Der Masterknoten speichert Metainformationen zu Daten auf den Clusterknoten und ist für die Verteilung von Anforderungen an diese Knoten (CAS-Mitarbeiter) verantwortlich, die Daten verarbeiten und speichern. Separat wird ein Server zugewiesen, auf dem Analysedienste und zusätzliche Module vorhanden sind, damit die Plattform funktioniert. Abhängig von den Aufgaben kann es auch mehrere geben. Beispielsweise können Sie den Server für SPRE (SAS Programming Runtime Environment) verwenden, mit dem Sie klassische SAS 9-Aufgaben auf der Viya-Plattform mit CAS und SPRE auf einem separaten Computer im Rahmen der Viya-Installation ausführen können.
Es gibt eine interessante Konfiguration, die die Möglichkeiten der Verwendung von CAS auf der Viya-Plattform erweitert und den ersten Buchstaben seines Namens Cloud rechtfertigt:
Multitenancy bietet die Möglichkeit, Ressourcen und Daten zwischen Abteilungen auszutauschen. Gleichzeitig erhalten „Mieter“ eine einzige Schnittstelle für den Zugriff auf die Plattform und eine logische Trennung der verschiedenen Funktionen der Viya-Plattform. Es gibt viele Möglichkeiten. Vielleicht wird dieses Problem in einem separaten Artikel behandelt.
Was ist mit der Zuverlässigkeit des Arbeitsspeichers und wie werden Daten in CAS geladen?
Da es sich um Analysen handelt, insbesondere um fortschrittliche Lösungen für erweiterte Analysen, ist klar, dass es sich um große Datenmengen handelt. Ein wichtiger Teil des Prozesses ist das schnelle Laden von Daten in den Arbeitsspeicher für den Betrieb mit ihnen und die Sicherstellung der hohen Verfügbarkeit dieser Daten.
Jedes In-Memory-System erfordert aus Gründen der Zuverlässigkeit das Sichern von Daten im RAM. Der RAM weiß nicht, wie er den Zustand beibehalten soll, wenn die Stromversorgung ausgeschaltet wird. Außerdem passen möglicherweise nicht alle Daten in den Bereich des RAM, und es ist ein Mechanismus erforderlich, um Daten im RAM schnell neu zu laden. Daher werden für Tabellen, die zur Analyse in CAS geladen werden, Kopien im Nur-Lese-Speicherbereich des speziellen SASHDAT-Formats erstellt. Um eine hohe Verfügbarkeit sicherzustellen, werden diese Dateien auf mehreren Knoten im Cluster gespiegelt. Dieser Parameter kann konfiguriert werden. Die Idee ist, dass bei einem Knotenverlust Daten automatisch aus einer Kopie der SASHDAT-Datei in den RAM eines benachbarten Knotens geladen werden. Der Speicherbereich für diese Kopien in der CAS-Struktur heißt CAS_DISK_CACHE .
CAS_DISK_CACHE ist ein wichtiger Bestandteil von CAS, der nicht nur zur Gewährleistung der Fehlertoleranz, sondern auch zur Optimierung der Speichernutzung benötigt wird. Das folgende Diagramm zeigt die verschiedenen Möglichkeiten zum Speichern von SASHDAT und das Prinzip des Ladens von Daten in den RAM. Beispielsweise wird Datensatz A aus einer Oracle-Datenbank abgerufen und auf demselben CAS-Knoten im RAM und auf der Festplatte gespeichert. Außerdem wird dieser Datensatz A nur auf der Festplatte auf einem anderen Knoten dupliziert. Es gibt viele Optionen (einige erfordern keine zusätzliche Sicherung - dies wird weiter unten erläutert), aber die Hauptidee besteht darin, immer eine Kopie zu haben, um zuvor heruntergeladene Daten schnell im RAM wiederherzustellen. Übrigens, wenn Sie zwei Parameter einstellen: MAXTABLEMEM = 0 und COPIES = 0 auf Sitzungsebene, werden die Daten nur im RAM gespeichert.
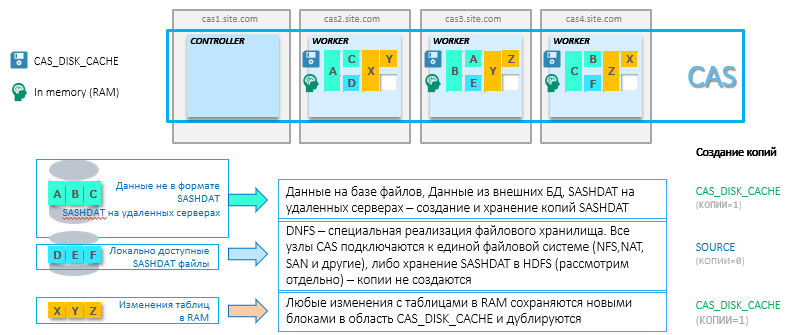
Ich möchte auch eine interessante Konfiguration von CAS mit Hadoop in Betracht ziehen. Um diese CAS-Konfiguration mit einem Hadoop-System zu verwenden, müssen Sie SAS-Plugins für Hadoop installieren. Die Hauptidee des Ansatzes besteht darin, dass die Knoten des Hadoop-Clusters auch zu funktionierenden CAS-Knoten werden. Daten werden direkt aus Dateien in HDFS ohne Netzwerklast in den RAM gezogen. Dies ist die beste Option in Bezug auf die Leistung. Sie können Hadoop entweder nur zum Speichern von SASHDAT-Dateien (HDFS im Cluster spielt die Rolle von CAS_DISK_CACHE - Reservierung auf HDFS-Ebene) oder zusammen mit anderen Daten verwenden. Die Ressourcenzuweisung im Hadoop-Cluster erfolgt über YARN. Das Schema für die Installation von CAS auf einem Hadoop-Cluster:
Laden
Das Laden von Daten ist einfach. Wir können verschiedene Quellen für die Eingabe in das CAS angeben. Sie können entweder in einem einzelnen Stream oder parallel geladen werden. Da relationale Datenbanken viel häufiger als Quellen verwendet werden, werden wir das Thema des Ladens von Daten aus RDBMS in CAS betrachten. Um das Laden von Daten in den CAS-Cluster zu optimieren, ist es wünschenswert, die Client-Software der Quellendatenbank auf jedem Knoten des Clusters zu installieren. In diesem Fall empfängt jeder Knoten des CAS-Clusters seinen Datenanteil parallel. Wenn Sie den Client nur auf dem Controller installieren, werden alle Daten über den CAS-Controller übertragen.
Wenn Sie beispielsweise den Parameter numreadnodes = 3 setzen, wird die Tabelle automatisch in 3 Datenblöcke zum Laden auf verschiedene CAS-Knoten unterteilt. In diesem Fall basiert die Datenverteilung auf der Gruppierung nach der ersten numerischen Spalte mithilfe der Mod 3-Operation.
Wenn Hadoop oder Teradata als Quelle verwendet wird, wird das Laden mithilfe des eingebetteten Prozesses für Hadoop oder Teradata direkt von jedem Knoten des Hadoop- oder Teradata-Clusters durchgeführt. Beachten Sie, dass bei einer separaten Installation des Hadoop-Clusters (CAS ist nicht auf den Hadoop-Knoten installiert) der Bereich CAS_DISK_CACHE im CAS-Cluster erstellt wird.
Wie fange ich mit CAS an?
Wichtige Begriffe in der Arbeit von CAS sind Bibliotheken und Sitzungen. Wenn Sie mit CAS arbeiten, wird als Erstes eine Sitzung erstellt. Es kann manuell definiert werden, wenn Sie über SAS Studio arbeiten, oder es wird automatisch über die verfügbaren grafischen Oberflächen auf SAS Viya erstellt, wenn eine Verbindung zu CAS besteht. Innerhalb einer Sitzung werden alle Daten und Transformationen, die in neuen Bibliotheken definiert sind, standardmäßig mit einem lokalen Bereich erstellt. Die Daten (in caslib definiert) und die Ergebnisse der Schritte der lokalen Sitzung sind nur in dieser Sitzung sichtbar. Falls wir die Ergebnisse öffentlich zugänglich machen müssen, können wir caslib mit dem globalen Parameter und dem Promotionsoperator neu definieren, und die Daten werden aus anderen Sitzungen verfügbar sein. Bibliotheken, die bereits mit dem globalen Parameter definiert wurden, sind in allen Sitzungen verfügbar. Dies geschieht, um Ressourcen optimal gemeinsam zu nutzen und Datenzugriffsrechte zu verwalten. Nach dem Trennen von der lokalen Sitzung werden alle temporären Daten gelöscht, wenn caslib nicht global neu definiert wurde. Wir können den Parameter TIMEOUT so konfigurieren, dass Daten beim Trennen von der Sitzung gelöscht werden, um mögliche Verluste bei kurzfristigen Netzwerkfehlern zu vermeiden oder zur weiteren Analyse zu dieser Sitzung zurückzukehren (z. B. können Sie den Parameter TIMEOUT auf 3600 Sekunden setzen, wodurch wir 60 Minuten Zeit haben, zu der Sitzung zurückzukehren Sitzung). Außerdem können die Daten bei jedem Schritt der Konvertierung in ein spezielles SASHDAT-Format oder in eine zugängliche Datenbank gespeichert werden, zu der die Verbindung von einem einfachen SAVE-Operator konfiguriert wird.
Die caslibs-Bibliotheken beschreiben die Datensätze, die in CAS verfügbar sein werden. Beim Erstellen von caslib werden der Verbindungstyp und die Verbindungsparameter angegeben. Bei der Definition von caslib verweisen wir sofort auf die Datenquelle und den Zielbereich im Arbeitsspeicher. Auch auf Caslib-Ebene ist es zweckmäßig, Zugriffsrechte für Benutzergruppen auf die in Caslib beschriebenen Daten festzulegen. Dies erfolgt in der grafischen Oberfläche.
Beispiel einer Caslib-Beschreibung für verschiedene Arten von Quellen:
caslib caspth path="/data/cust/" type=path; caspth – , path - caslib pgdvd datasource=( srctype="postgres", username="casdm", password="xxxxxx", server="sasdb.race.sas.com", database="dvdrental", schema="public", numreadnodes=3) ; caslib hivelib desc="HIVE Caslib" datasource=(SRCTYPE="HIVE",SERVER="gatekrbhdp01.gatehadoop.com", HADOOPCONFIGDIR="/opt/sas/hadoop/client_conf/", HADOOPJARPATH="/opt/sas/hadoop/client_jar/", schema="default",dfDebug=sqlinfo) GLOBAL ;
Nach der Bestimmung von caslib können wir Daten zur weiteren Verarbeitung in den RAM laden. Ein Beispiel für das Laden von Caslib-Hivelib-Daten:
proc casutil; load casdata="stocks" casout="stocks" outcaslib="hivelib" incaslib="hivelib" PROMOTE ; quit; /* casdata – ( hive), casout – CAS, outcaslib – caslib, , incaslib – caslib, .*/ /* in/out caslib , */
Innerhalb jeder Sitzung werden Anforderungen nacheinander ausgeführt. Dies ist wichtig, wenn Sie Code manuell schreiben. Wenn Sie jedoch die in Viya verfügbaren grafischen Oberflächen verwenden, können Sie nicht darüber nachdenken. GUI-Clientanwendungen selbst erstellen separate Sitzungen, um Schritte parallel auszuführen.
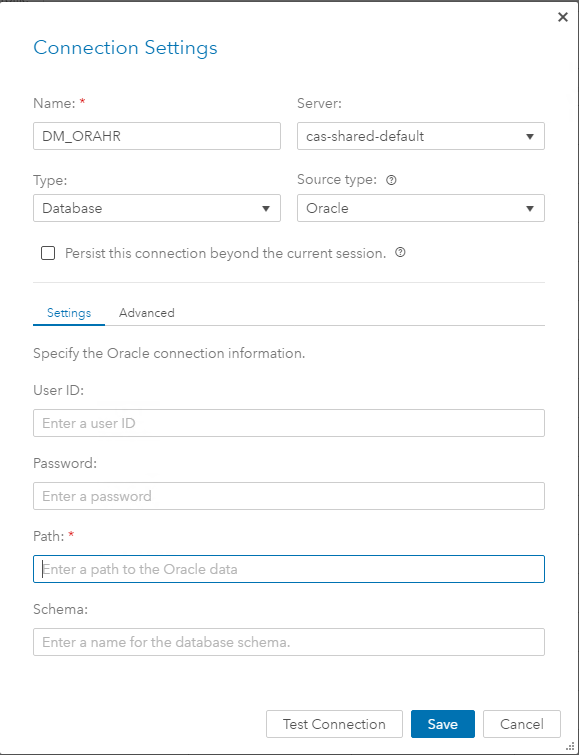
Vollständig grafische Schnittstellen und Ansätze zu deren Bearbeitung werden in den folgenden Artikeln behandelt. Hier werde ich Screenshots der Schritte zum Erstellen einer caslib DM_ORAHR und zum Laden von Daten in den RAM über die GUI hinzufügen:
Dies ist nur der Anfang.
Damit beende ich den Teil über CAS und kehre zur Viya-Plattform zurück. Da Viya für Geschäftsanwender entwickelt wurde, ist es im Verlauf der Arbeit nicht erforderlich, die Besonderheiten des CAS genau zu verstehen. Es gibt bequeme grafische Oberflächen für alle Vorgänge, und CAS bietet dank In-Memory und verteiltem Computing eine schnelle Abwicklung aller Analyseschritte.
Jetzt können Sie zu den Benutzeroberflächen wechseln, die auf Viya verfügbar sind. Derzeit gibt es viele davon, und die Anzahl der Produkte nimmt ständig zu. Zu Beginn des Artikels wurden sie in 4 Gruppen eingeteilt, die für einen vollständigen Analysezyklus benötigt werden. Zurück zur Hauptidee: Viya ist eine einzige Plattform für Data Mining und erweiterte Analyse. Die Arbeit beginnt mit der Vorbereitung und Suche nach diesen Daten. Und im nächsten Teil der Artikelserie über Viya werde ich über Datenaufbereitungstools sprechen, die Analysten zur Verfügung stehen.
Anstelle einer Schlussfolgerung kommt der Name Viya vom Wort Via (aus dem Englischen "durch" oder "durch"). Die Hauptidee dieses Namens ist ein einfacher Übergang von der klassischen SAS 9-Lösung zu einer neuen Plattform, die erstellt wurde, um die Analyse auf ein neues Niveau zu heben.