In Rostelecom gibt es wie in jedem großen Unternehmen ein Corporate Data Warehouse (WCD). Unsere WCD wächst und wächst ständig, wir bauen nützliche Storefronts, Berichte und Datenwürfel darauf. Irgendwann waren wir mit der Tatsache konfrontiert, dass Daten von schlechter Qualität uns beim Erstellen von Schaufenstern stören. Die resultierenden Einheiten konvergieren nicht mit den Einheiten der Quellsysteme und verursachen ein Unverständnis für das Geschäft. Beispielsweise werden Daten mit Nullwerten in Fremdschlüsseln (Fremdschlüsseln) nicht mit Daten aus anderen Tabellen verbunden.
Kurzes Diagramm der WCD:
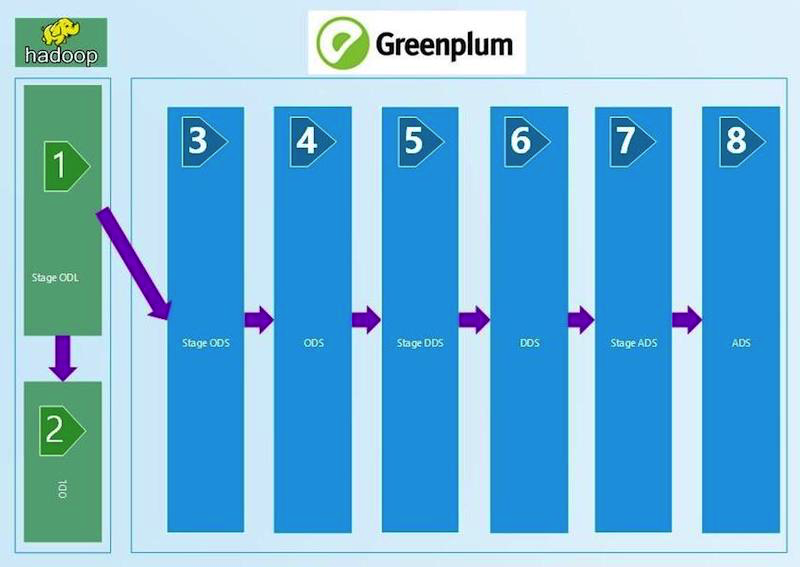
Wir haben verstanden, dass wir einen regelmäßigen Abstimmungsprozess benötigen, um das Vertrauen in die Qualität der Daten zu gewährleisten. Natürlich automatisiert und ermöglicht es jeder technologischen Ebene, die Qualität der Daten und ihre Konvergenz sowohl vertikal als auch horizontal sicherzustellen. Infolgedessen haben wir gleichzeitig drei vorgefertigte Plattformen für die Verwaltung von Abstimmungen verschiedener Anbieter überprüft und unsere eigenen geschrieben. Wir teilen unsere Erfahrungen in diesem Beitrag.
Die Minuspunkte der fertigen Plattformen sind allen bekannt: Preis, begrenzte Flexibilität, mangelnde Fähigkeit, Funktionen hinzuzufügen und zu reparieren. Vorteile - MDM-Teile (Golddaten usw.), Schulung und Support sind ebenfalls geschlossen. Nachdem wir dies erkannt hatten, vergaßen wir schnell den Kauf und konzentrierten uns auf die Entwicklung unserer Lösung.
Der Kern unseres Systems ist in Python geschrieben, und die Metadaten-Datenbank zum Speichern, Protokollieren und Speichern von Ergebnissen ist in Oracle geschrieben. Es gibt viele Bibliotheken für Python. Wir verwenden das Minimum, das für Hive- (Pyhive), GreenPlum- (pgdb) und Oracle-Verbindungen (cx_Oracle) erforderlich ist. Das Anschließen eines anderen Quellentyps sollte ebenfalls kein Problem sein.
Die resultierenden Datensätze (Ergebnismenge) werden zu den resultierenden Oracle-Tabellen hinzugefügt und bewerten den Status der Abstimmung (SUCCESS / ERROR) im laufenden Betrieb. APEX wird für die resultierenden Tabellen konfiguriert, in denen die Visualisierung der Ergebnisse erstellt wird. Dies ist sowohl für die Wartung als auch für die Verwaltung praktisch.
Um Überprüfungen im Repository durchzuführen, wird das Informatica-Orchester verwendet, das Daten herunterlädt. Nach Erhalt eines Download-Erfolgsstatus werden diese Daten automatisch überprüft. Die Verwendung von Abfrageparametrisierung und WCD-Metadaten ermöglicht die Verwendung von Abfrageabgleichsvorlagen für Tabellensätze.
Nun zu den auf dieser Plattform implementierten Abstimmungen.
Wir haben mit technischen Abstimmungen begonnen, bei denen die Datenmenge an den Eingängen und Schichten der WCD mit der Anwendung bestimmter Filter verglichen wird. Wir nehmen die ctl-Datei, die zur WCD-Eingabe gelangt ist, lesen die Anzahl der Datensätze daraus und vergleichen sie mit der Tabelle in Stage ODL und / oder Stage ODS (1, 2, 3 im Diagramm). Das Überprüfungskriterium wird in der Gleichheit der Anzahl der Datensätze (Anzahl) definiert. Wenn die Menge konvergiert, ist das Ergebnis ERFOLG, KEIN FEHLER und manuelle Analyse des Fehlers.
Diese Kette technischer Abstimmungen erstreckt sich im Vergleich zur Anzahl der Datensätze auf die ADS-Schicht (8 im Diagramm). Die Filter werden zwischen den Ebenen geändert, abhängig von der Art des Ladens - DIM (Nachschlagewerk), HDIM (historisches Nachschlagewerk), FACT (tatsächliche Abgrenzungstabellen) usw. sowie der Versionierung von SCD und der Schicht. Je näher an der Anzeigeebene, desto ausgefeiltere Filteralgorithmen verwenden wir.
Außerdem wurde eine technische Überprüfung der Eingabe in Python durchgeführt, bei der Duplikate in Schlüsselfeldern erkannt werden. In unserem GreenPlum sind Schlüsselfelder (PK) durch Datenbanksystem-Tools nicht vor Duplikaten geschützt. Deshalb haben wir ein Python-Skript geschrieben, das die Felder der geladenen Tabelle aus den PK-Metadaten liest und ein SQL-Skript generiert, das nach Duplikaten sucht. Die Flexibilität des Ansatzes ermöglicht es uns, PK zu verwenden, die aus einem oder mehreren Feldern besteht, was äußerst praktisch ist. Eine solche Abstimmung erstreckt sich auf die STG-ADS-Schicht.
unique_check import sys import os from datetime import datetime log_tmstmp = datetime.now().strftime("%Y-%m-%d %H:%M:%S") def do_check(args, context): tab = args[0] data = [] fld_str = "" try: sql = """SELECT 't_'||lower(table_id) as tn, lower(column_name) as cn FROM src_column@meta_data WHERE table_id = '%s' and is_primary_key = 'Y'""" % (tab,) for fld in context['ora_get_data'](context['ora_con'], sql): fld_str = fld_str + (fld_str and ",") + fld[1] if fld_str: config = context['script_config'] con_gp = context['pg_open_con'](config['user'], config['pwd'], config['host'], config['port'], config['dbname']) sql = """select %s as pkg_id, 't_%s' as table_name, 'PK fields' as column_name, coalesce(sum(cnt), 0) as NOT_UNIQUE_PK, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS') as sys_creation from (select 1 as cnt from edw_%s.t_%s where %s group by %s having count(*) > 1 ) sq; """ % (context["package"] or '0',tab.lower(), args[1], tab.lower(), (context["package"] and ("package_id = " + context["package"]) or "1=1"), fld_str ) data.extend(context['pg_get_data'](con_gp, sql)) con_gp.close() except Exception as e: raise return data or [[(context["package"] or 0),'t_'+tab.lower(), None, 0, log_tmstmp]] if __name__ == '__main__': sys.exit(do_check([sys.argv[1], sys.argv[2]], {}))
Beispiel für den Python-Code für die Abstimmung der Eindeutigkeit. Der Aufruf, die Übertragung der Verbindungsparameter und das Einfügen der Ergebnisse in die resultierende Tabelle erfolgt durch das Steuermodul in Python.Die Abstimmung für das Fehlen von NULL-Werten ist ähnlich wie die vorherige und auch in Python aufgebaut. Wir lesen aus den Lademetadatenfeldern, die keine leeren (NULL) Werte haben dürfen, und überprüfen ihre Fülle. Die Abstimmung wird vor der DDS-Schicht verwendet (6 im ersten Diagramm).
Am Eingang des Speichers wird auch eine Trendanalyse der am Eingang ankommenden Datenpakete implementiert. Die Datenmenge, die beim Eintreffen eines neuen Pakets empfangen wird, wird in die Verlaufstabelle eingetragen. Bei einer signifikanten Änderung der Datenmenge erhält die für die Tabelle und den SI (Quellsystem) verantwortliche Person eine Benachrichtigung per E-Mail (in Plänen), sieht einen Fehler in APEX, bevor das Datenpaket in das Warehouse gelangt, und ermittelt den Grund dafür mit dem SI.
Zwischen STG (STAGE) _ODS und ODS (Betriebsdatenschicht) (3 und 4 im Diagramm) erscheinen technische Löschfelder (Löschindikator = deleted_ind), deren Richtigkeit wir auch anhand von SQL-Abfragen überprüfen. Fehlende Eingaben sollten in ODS als gelöscht markiert werden.
Es wird erwartet, dass das Ergebnis des Abstimmungsskripts keine Fehler enthält. Im vorgestellten Abstimmungsbeispiel werden die Parameter ~ # PKG_ID # ~ durch den Python-Steuerblock übergeben, und Parameter vom Typ ~ P_JOIN_CONDITION ~ und ~ PERIOD_COL ~ werden aus den Tabellenmetadaten ausgefüllt, der Tabellenname selbst ~ TABLE ~ aus den Startparametern.
Das Folgende ist eine parametrisierte Abstimmung. Beispiel für einen SQL-Abstimmungscode zwischen STG_ODS und ODS für den Typ HDIM:
select package_id as pkg_id, 'T_~TABLE~' as table_name, to_char(current_timestamp, 'YYYY-MM-DD HH24:MI:SS'), coalesce(empty_in_ods, 0) as empty_in_ods, coalesce(not_equal_md5, 0) as not_equal_md5, coalesce(deleted_in_ods, 0) as deleted_in_ods, coalesce(not_deleted_in_ods, 0) as not_deleted_in_ods, max_load_dttm from (select max (src.package_id) as package_id, sum (case when tgt.md5 is null then 1 else 0 end) as empty_in_ods, sum (case when src.md5<>tgt.md5 and tgt.~PK~ is not null and tgt.deleted_ind = 0 then 1 else 0 end) as not_equal_md5, sum (case when tgt.deleted_ind = 1 and src.md5=tgt.md5 then 1 else 0 end) as deleted_in_ods from EDW_STG_ODS.T_~TABLE~ src left join EDW_ODS.T_~TABLE~ tgt on ~P_JOIN_CONDITION~ and tgt.active_ind ='Y' where ~
Ein Beispiel für einen SQL-Abstimmungscode zwischen STG_ODS und ODS für einen HDIM-Typ mit ersetzten Parametern:
Beginnend mit ODS wird der Verlauf in den Verzeichnissen verwaltet und muss daher auf das Fehlen von Schnittpunkten und Lücken überprüft werden. Dazu wird die Anzahl der falschen Werte im Verlauf gezählt und die resultierende Anzahl von Fehlern in die resultierende Tabelle geschrieben. Wenn die Tabelle Verlaufsfehler enthält, müssen diese manuell durchsucht werden. Die Abstimmung hängt in erster Linie von der Art des Downloads ab - HDIM (History Reference Guide). Wir führen Abstimmungen der Richtigkeit des Verlaufs für Verzeichnisse bis zur ADS-Schicht durch.
Auf der DDS-Ebene (6 im ersten Diagramm) werden verschiedene SIs (Quellsysteme) in einer Tabelle zusammengefasst. HUB-Tabellen zum Generieren von Ersatzschlüsseln zum Verknüpfen von Daten aus verschiedenen Quellsystemen werden angezeigt. Wir überprüfen sie auf Eindeutigkeit mit einem Python-Check ähnlich der Stage-Layer.
Auf der DDS-Ebene müssen Sie überprüfen, ob nach dem Kombinieren mit der HUB-Tabelle keine Werte der Typen 0, -1, -2 in den Schlüsselfeldern angezeigt wurden. Dies bedeutet, dass die Tabelle falsch verbunden ist und keine Daten vorliegen. Sie können angezeigt werden, wenn die erforderlichen Daten nicht in der HUB-Tabelle enthalten sind. Und dies ist ein Fehler beim manuellen Parsen.
Die komplexesten Abstimmungen für die Daten der ADS-Schaufensterschicht (8 im ersten Diagramm). Um ein vollständiges Vertrauen in die Konvergenz des erhaltenen Ergebnisses zu erhalten, wird hier eine Überprüfung mit einem Quellsystem zur Aggregation der Gebührenmenge durchgeführt. Einerseits gibt es eine Klasse von Indikatoren, die aggregierte Rückstellungen enthalten. Wir sammeln sie für einen Monat aus den Fenstern der WCD. Auf der anderen Seite nehmen wir Aggregate der gleichen Gebühren aus dem Quellsystem. Eine Abweichung von höchstens 1% oder ein bestimmter und vereinbarter absoluter Wert ist zulässig. Die durch Abgleich erhaltenen Ergebnismengen werden in speziell erstellten Datensätzen abgelegt, die Oracle-Tabellen empfangen. Wir führen Datenvergleiche in der Oracle-Ansicht durch. Visualisierung der Ergebnisse in APEX. Das Vorhandensein eines ganzen Datensatzes (Ergebnismenge) ermöglicht es uns, bei Fehlern tiefer zu gehen und die detaillierten Daten des Ergebnisses zu analysieren, einen bestimmten Artikel zu finden, bei dem die Diskrepanz aufgetreten ist, und nach den Gründen zu suchen.
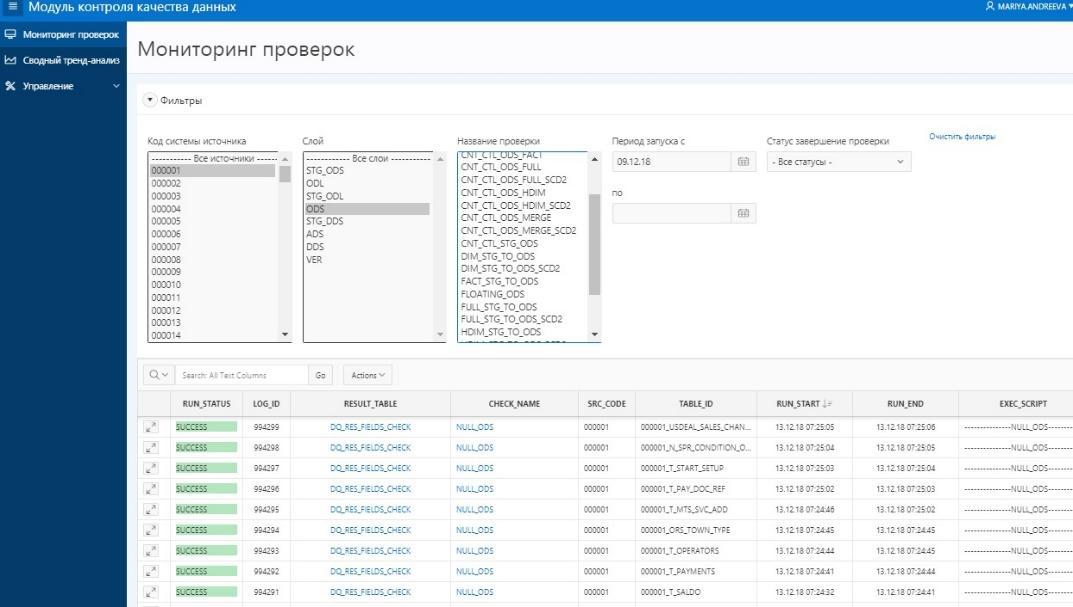 Präsentation der Abstimmungsergebnisse für Benutzer in APEX
Präsentation der Abstimmungsergebnisse für Benutzer in APEXIm Moment haben wir eine funktionsfähige und aktiv genutzte Anwendung zum Abgleichen von Daten erhalten. Natürlich planen wir, sowohl die Quantität und Qualität der Abstimmungen als auch die Entwicklung der Plattform selbst weiterzuentwickeln. Durch die eigene Entwicklung können wir die Funktionalität schnell genug ändern und modifizieren.
Dieser Artikel wurde vom Datenverwaltungsteam von Rostelecom erstellt