Anfang Dezember fand in Montreal die 32. jährliche Konferenz über
neuronale Informationsverarbeitungssysteme zum Thema maschinelles Lernen statt. Laut einer inoffiziellen Rangliste ist diese Konferenz die Top-1-Veranstaltung dieses Formats weltweit. Alle Konferenztickets in diesem Jahr waren in Rekordzeit von 13 Minuten ausverkauft. Wir haben ein großes Team von MTS-Datenwissenschaftlern, aber nur eine von ihnen - Marina Yaroslavtseva (
magoli ) - hatte das Glück, nach Montreal zu kommen. Zusammen mit Danila Savenkov (
danila_savenkov ), die kein Visum hatte und die Konferenz aus Moskau verfolgte, werden wir über die Werke sprechen, die uns am interessantesten erschienen. Dieses Beispiel ist sehr subjektiv, aber es wird Sie hoffentlich interessieren.
 Relationale wiederkehrende neuronale NetzeZusammenfassungCode
Relationale wiederkehrende neuronale NetzeZusammenfassungCodeBei der Arbeit mit Sequenzen ist es oft sehr wichtig, wie die Elemente der Sequenz miteinander in Beziehung stehen. Die Standardarchitektur von Wiederholungsnetzwerken (GRU, LSTM) kann die Beziehung zwischen zwei Elementen, die ziemlich weit voneinander entfernt sind, kaum modellieren. Bis zu einem gewissen Grad hilft Aufmerksamkeit, damit umzugehen (
https://youtu.be/SysgYptB198 ,
https://youtu.be/quoGRI-1l0A ), aber dies ist immer noch nicht ganz richtig. Mit Achtung können Sie das Gewicht bestimmen, mit dem der verborgene Zustand aus jedem der Schritte der Sequenz den endgültigen verborgenen Zustand und dementsprechend die Vorhersage beeinflusst. Wir interessieren uns für die Beziehung der Elemente der Sequenz.
Letztes Jahr schlug Google erneut auf NIPS vor, die Wiederholung ganz aufzugeben und die
Selbstaufmerksamkeit zu nutzen . Der Ansatz erwies sich als sehr gut, allerdings hauptsächlich für seq2seq-Aufgaben (der Artikel liefert Ergebnisse zur maschinellen Übersetzung).
Der diesjährige Artikel verwendet die Idee der Selbstaufmerksamkeit als Teil von LSTM. Es gibt nicht viele Änderungen:
- Wir ändern den Zellzustandsvektor in die "Speicher" -Matrix M. Bis zu einem gewissen Grad besteht die Speichermatrix aus vielen Zellzustandsvektoren (vielen Speicherzellen). Wenn wir ein neues Element der Sequenz erhalten, legen wir fest, um wie viel dieses Element jede der Speicherzellen aktualisieren soll.
- Für jedes Element der Sequenz aktualisieren wir diese Matrix mithilfe der Aufmerksamkeit für Produkte mit mehreren Kopfpunkten (MHDPA, über diese Methode können Sie im genannten Artikel von Google lesen). Das MHPDA-Ergebnis für das aktuelle Element der Sequenz und der Matrix M wird durch ein vollständig verbundenes Netz, das Sigmoid, geführt, und dann wird die Matrix M auf die gleiche Weise wie der Zellzustand in LSTM aktualisiert
Es wird argumentiert, dass das Netz durch MHDPA die Verbindung von Sequenzelementen berücksichtigen kann, selbst wenn sie voneinander entfernt sind.
Als Spielzeugproblem wird das Modell in der Folge von Vektoren gebeten, den N-ten Vektor anhand des Abstands vom M-ten als euklidischen Abstand zu ermitteln. Zum Beispiel gibt es eine Folge von 10 Vektoren, und wir bitten Sie, einen zu finden, der sich in der Nähe des fünften auf dem dritten Platz befindet. Es ist klar, dass es zur Beantwortung dieser Frage des Modells notwendig ist, die Abstände von allen Vektoren zum fünften irgendwie zu bewerten und zu sortieren. Hier besiegt das von den Autoren vorgeschlagene Modell LSTM und
DNC zuversichtlich. Darüber hinaus vergleichen die Autoren ihr Modell mit anderen Architekturen zu Learning to Execute (wir erhalten ein paar Codezeilen, geben das Ergebnis ein), Mini-Pacman, Language Modeling und berichten überall über die besten Ergebnisse.
Multivariate Zeitreihen-Imputation mit generativen kontradiktorischen NetzwerkenZusammenfassungCode (obwohl sie hier im Artikel nicht verlinkt sind)
In mehrdimensionalen Zeitreihen gibt es in der Regel eine Vielzahl von Auslassungen, die die Verwendung fortschrittlicher statistischer Methoden verhindern. Standardlösungen - Füllen mit Mittelwert / Null, Löschen unvollständiger Fälle, Wiederherstellen von Daten basierend auf Matrixerweiterungen in dieser Situation funktionieren häufig nicht, da sie Zeitabhängigkeiten und die komplexe Verteilung mehrdimensionaler Zeitreihen nicht reproduzieren können.
Die Fähigkeit generativer gegnerischer Netzwerke (GANs), jede Verteilung von Daten nachzuahmen, ist allgemein bekannt, insbesondere bei der Aufgabe, Gesichter zu „vervollständigen“ und Sätze zu generieren. In der Regel erfordern solche Modelle jedoch entweder eine erste Schulung für einen vollständigen Datensatz ohne Lücken oder berücksichtigen nicht die Konsistenz der Daten.
Die Autoren schlagen vor, das GAN durch ein neues Element zu ergänzen - die Gated Recurrent Unit for Imputation (GRUI). Der Hauptunterschied zur üblichen GRU besteht darin, dass die GRUI aus Daten in Intervallen unterschiedlicher Länge zwischen den Beobachtungen lernen und den Effekt der Beobachtungen in Abhängigkeit von ihrer zeitlichen Entfernung vom aktuellen Punkt anpassen kann. Es wird ein spezieller Dämpfungsparameter β berechnet, dessen Wert von 0 bis 1 variiert und je kleiner die Zeitverzögerung zwischen der aktuellen Beobachtung und der vorherigen nicht leeren ist.


Sowohl der Diskriminator als auch der GAN-Generator bestehen aus einer GRUI-Schicht und einer vollständig verbundenen Schicht. Wie in GANs üblich, lernt der Generator, die Quelldaten zu simulieren (in diesem Fall füllen Sie einfach die Lücken in den Zeilen aus), und der Diskriminator lernt, die mit dem Generator gefüllten Zeilen von den realen zu unterscheiden.
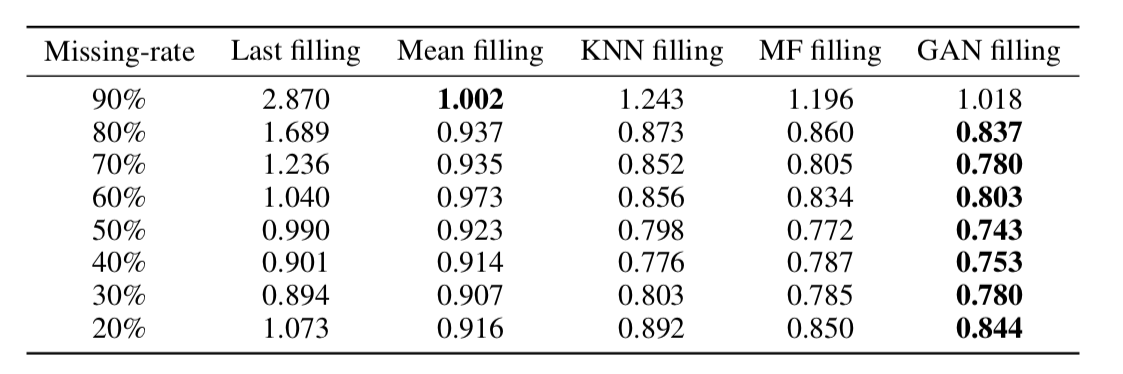
Wie sich herausstellte, stellt dieser Ansatz Daten auch in Zeitreihen mit einem sehr großen Anteil an Auslassungen sehr angemessen wieder her (in der folgenden Tabelle - MSE-Datenwiederherstellung im KDD-Datensatz in Abhängigkeit vom Prozentsatz der Auslassungen und der Wiederherstellungsmethode. In den meisten Fällen bietet die GAN-basierte Methode die größte Genauigkeit Erholung).
 Zur Dimensionalität von WorteinbettungenZusammenfassungCode
Zur Dimensionalität von WorteinbettungenZusammenfassungCodeDie Worteinbettung / Vektordarstellung von Wörtern ist ein Ansatz, der häufig für verschiedene NLP-Anwendungen verwendet wird: von Empfehlungssystemen bis zur Analyse der emotionalen Färbung von Texten und maschineller Übersetzung.
Darüber hinaus bleibt die Frage offen, wie ein so wichtiger Hyperparameter wie die Dimension von Vektoren optimal eingestellt werden kann. In der Praxis wird es meistens durch empirisch erschöpfende Suche ausgewählt oder standardmäßig festgelegt, beispielsweise auf der Ebene von 300. Gleichzeitig erlaubt eine zu kleine Dimension nicht, alle signifikanten Beziehungen zwischen Wörtern widerzuspiegeln, und eine zu große Dimension kann zu einer Umschulung führen.
Die Autoren der Studie schlagen ihre Lösung für dieses Problem vor, indem sie den PIP-Verlustparameter minimieren, ein neues Maß für den Unterschied zwischen den beiden Einbettungsoptionen.
Die Berechnung basiert auf PIP-Matrizen, die die Skalarprodukte aller Paare von Vektordarstellungen von Wörtern im Korpus enthalten. Der PIP-Verlust wird als Frobenius-Norm zwischen den PIP-Matrizen zweier Einbettungen berechnet: trainiert auf Daten (trainierte Einbettung E_hat) und ideal, trainiert auf verrauschte Daten (Orakel-Einbettung E).
Es scheint einfach zu sein: Sie müssen eine Dimension auswählen, die den PIP-Verlust minimiert. Der einzige unverständliche Moment ist, wo Sie die Orakel-Einbettung erhalten. In den Jahren 2015-2017 wurde eine Reihe von Arbeiten veröffentlicht, in denen gezeigt wurde, dass verschiedene Methoden zur Konstruktion von Einbettungen (word2vec, GloVe, LSA) die Signalmatrix des Falls implizit faktorisieren (die Dimension verringern). Im Fall von word2vec (Skip-Gramm) ist die Signalmatrix
PMI , im Fall von GloVe ist es die Log-Count-Matrix. Es wird vorgeschlagen, ein nicht sehr großes Wörterbuch zu verwenden, eine Signalmatrix zu erstellen und SVD zu verwenden, um eine Orakeleinbettung zu erhalten. Somit ist die Orakel-Einbettungsdimension gleich dem Signalmatrixrang (in der Praxis liegt die Dimension für ein Wörterbuch mit 10.000 Wörtern in der Größenordnung von 2.000). Unsere empirische Signalmatrix ist jedoch immer verrauscht und wir müssen auf knifflige Schemata zurückgreifen, um eine Orakeleinbettung zu erhalten und den PIP-Verlust durch eine verrauschte Matrix abzuschätzen.
Die Autoren argumentieren, dass es zur Auswahl der optimalen Einbettungsdimension ausreicht, ein Wörterbuch mit 10.000 Wörtern zu verwenden, was nicht sehr viel ist und es Ihnen ermöglicht, dieses Verfahren in angemessener Zeit auszuführen.
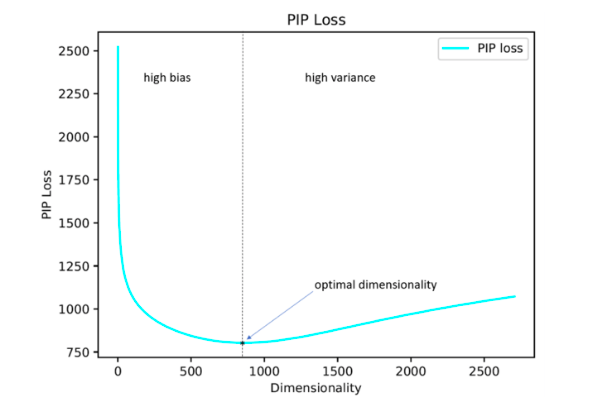
Wie sich herausstellte, stimmt die auf diese Weise berechnete Einbettungsdimension in den meisten Fällen mit einem Fehler von bis zu 5% mit der optimalen Dimension überein, die auf der Grundlage von Expertenschätzungen ermittelt wurde. Es stellte sich heraus (erwartet), dass Word2Vec und GloVe praktisch nicht umgeschult wurden (der PIP-Verlust fällt bei sehr großen Dimensionen nicht ab), aber LSA wird ziemlich stark umgeschult.
Mit dem von den Autoren auf dem Github veröffentlichten Code kann nach der optimalen Dimension von Word2Vec (Sprunggramm), GloVe, LSA gesucht werden.
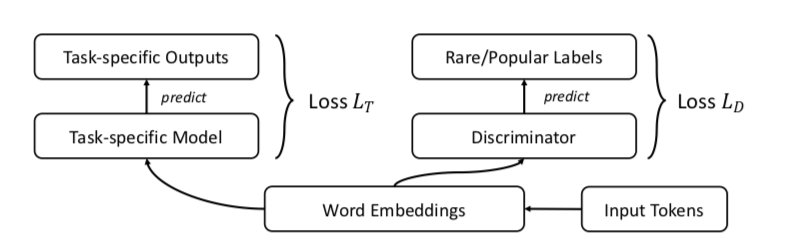
FRAGE: Frequenzunabhängige WortrepräsentationZusammenfassungCodeDie Autoren sprechen darüber, wie Einbettungen für seltene und beliebte Wörter unterschiedlich funktionieren. Mit populär meine ich nicht Stoppwörter (wir betrachten sie überhaupt nicht), sondern informative Wörter, die nicht sehr selten sind.
Die Beobachtungen sind wie folgt:
Wenn wir über populäre Wörter sprechen, spiegelt sich ihre Nähe im Kosinusmaß sehr gut wider
- ihre semantische Affinität. Bei seltenen Wörtern ist dies nicht der Fall (was erwartet wird), und (was weniger erwartet wird) Top-n der einem seltenen Wort am nächsten liegenden Kosinuswörter sind ebenfalls selten und gleichzeitig semantisch nicht miteinander verbunden. Das heißt, seltene und häufige Wörter im Raum der Einbettungen leben an verschiedenen Orten (in verschiedenen Kegeln, wenn wir über Kosinus sprechen).
- Während des Trainings werden die Vektoren beliebter Wörter viel häufiger aktualisiert und sind im Durchschnitt doppelt so weit von der Initialisierung entfernt wie die Vektoren seltener Wörter. Dies führt dazu, dass die Einbettung seltener Wörter im Durchschnitt näher am Ursprung liegt. Um ehrlich zu sein, habe ich immer geglaubt, dass Einbettungen seltener Wörter im Durchschnitt länger dauern und ich nicht weiß, wie ich mich auf die Aussage der Autoren beziehen soll =)
Unabhängig von der Beziehung zwischen den L2-Normen für Einbettungen ist die Trennbarkeit von populären und seltenen Wörtern kein sehr gutes Phänomen. Wir möchten, dass Einbettungen die Semantik eines Wortes widerspiegeln, nicht seine Häufigkeit.
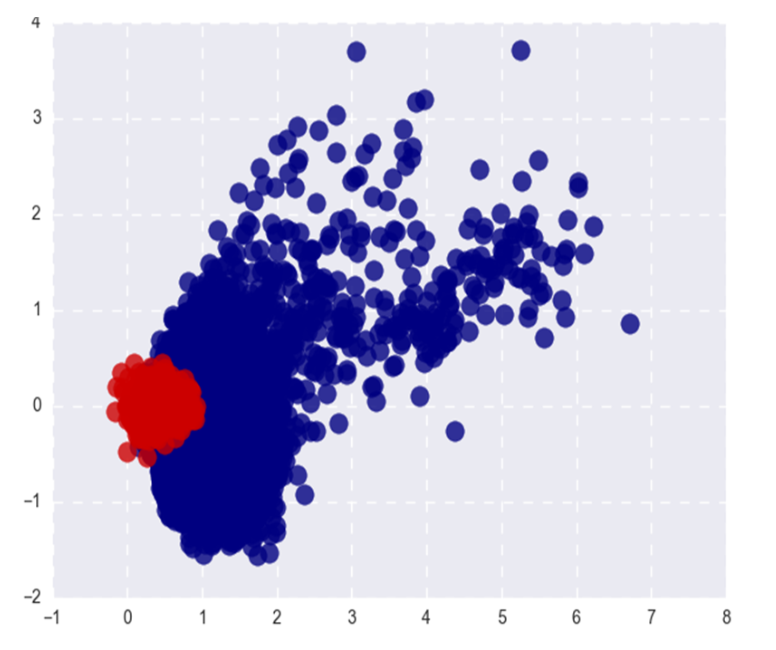
Das Bild zeigt Word2Vec beliebte (rot) und seltene (blau) Wörter nach SVD. Beliebt bezieht sich hier auf die Top 20% der Wörter in der Häufigkeit.
Wenn das Problem nur in den L2-Normen für Einbettungen liege, könnten wir sie normalisieren und glücklich leben, aber wie ich im ersten Absatz sagte, werden seltene Wörter auch durch Kosinusnähe (in Polarkoordinaten) von populären Wörtern getrennt.
Die Autoren schlagen natürlich GAN vor. Lassen Sie uns das Gleiche wie zuvor tun, aber einen Diskriminator hinzufügen, der versucht, zwischen populären und seltenen Wörtern zu unterscheiden (wiederum betrachten wir die Top-n% der Wörter in der Häufigkeit als populär).
Es sieht ungefähr so aus:
Die Autoren testen den Ansatz in Bezug auf die Aufgaben Wortähnlichkeit, maschinelle Übersetzung, Textklassifizierung und Sprachmodellierung und überall dort, wo sie besser abschneiden als die Basislinie. In Bezug auf die Wortähnlichkeit wird angegeben, dass die Qualität bei seltenen Wörtern besonders deutlich zunimmt.
Ein Beispiel: Staatsbürgerschaft. Skip-Gramm-Probleme: Glückseligkeit, Pakistans, Entlassung, Verstärkung. FRAGE-Themen: Bevölkerung, Rechte, Würde, Bürger. Die Wörter Bürger und Bürger in FRAGE stehen an 79. bzw. 7. Stelle (in der Nähe der Staatsbürgerschaft), in Skip-Gramm sind sie nicht in den Top 10000.
Aus irgendeinem Grund haben die Autoren den Code nur für maschinelle Übersetzung und Sprachmodellierung veröffentlicht. Wortähnlichkeits- und Textklassifizierungsaufgaben im Repository sind leider nicht vertreten.
Unüberwachte modalübergreifende Ausrichtung von Sprach- und TexteinbettungsräumenZusammenfassungCode: kein Code, aber ich möchte
Jüngste Studien haben gezeigt, dass zwei Vektorräume, die mithilfe von Einbettungsalgorithmen (z. B. word2vec) auf Textkörpern in zwei verschiedenen Sprachen trainiert wurden, ohne Markup und Inhaltsabgleich zwischen den beiden Gebäuden miteinander abgeglichen werden können. Dieser Ansatz wird insbesondere für die maschinelle Übersetzung bei Facebook verwendet. Eine der Schlüsseleigenschaften beim Einbetten von Räumen wird verwendet: In ihnen sollten ähnliche Wörter geometrisch nahe beieinander liegen, und ungleiche Wörter sollten im Gegenteil weit voneinander entfernt sein. Es wird angenommen, dass im Allgemeinen die Struktur des Vektorraums unabhängig von der Sprache, in der der Korpus unterrichtet wurde, erhalten bleibt.
Die Autoren des Artikels gingen noch weiter und wendeten einen ähnlichen Ansatz auf das Gebiet der automatischen Spracherkennung und -übersetzung an. Es wird vorgeschlagen, den Vektorraum separat für den Textkorpus in der interessierenden Sprache (z. B. Wikipedia), separat für den Korpus der aufgezeichneten Sprache (im Audioformat), möglicherweise in einer anderen Sprache, die zuvor in Wörter unterteilt war, zu trainieren und diese beiden Räume dann auf dieselbe Weise wie mit zwei zu vergleichen Textfälle.
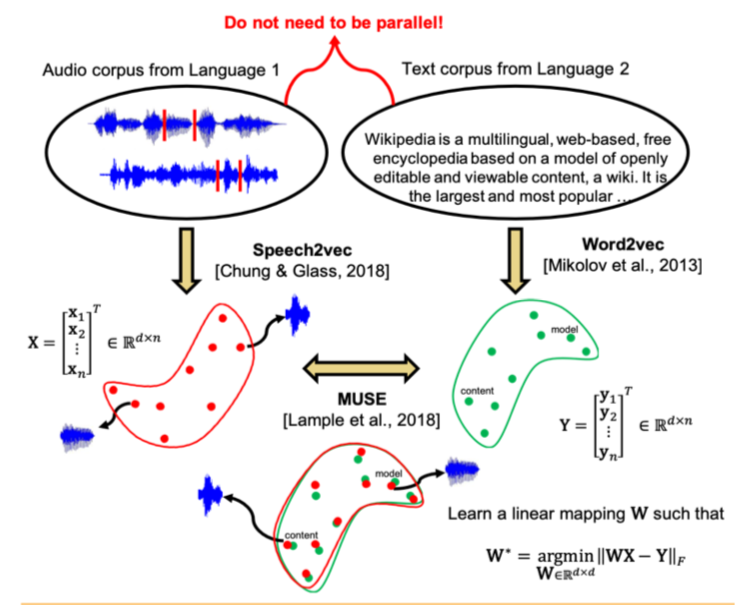
Für den Textkorpus wird word2vec verwendet, und für die Sprache basiert ein ähnlicher Ansatz, der von Speech2vec genannt wird, auf LSTM und den für word2vec verwendeten Methoden (CBOW / skip-gram), sodass angenommen wird, dass Wörter genau nach kontextuellen und semantischen Merkmalen kombiniert werden klingt nicht.
Nachdem beide Vektorräume trainiert wurden und es zwei Sätze von Einbettungen gibt - S (auf dem Sprachkörper), bestehend aus n Einbettungen der Dimension d1 und T (auf dem Textkörper), bestehend aus m Einbettungen der Dimension d2, müssen Sie sie vergleichen. Idealerweise haben wir ein Wörterbuch, das bestimmt, welcher Vektor aus S welchem Vektor aus T entspricht. Dann werden zum Vergleich zwei Matrizen gebildet: k Einbettungen werden aus S ausgewählt, die eine Matrix X der Größe d1 xk bilden; aus T werden auch k Einbettungen ausgewählt, die (gemäß dem Wörterbuch) entsprechen, die zuvor aus S ausgewählt wurden, und eine Matrix Y der Größe d2 x k wird erhalten. Als nächstes müssen Sie eine lineare Abbildung W finden, so dass:
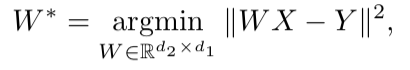
Da der Artikel jedoch den unbeaufsichtigten Ansatz berücksichtigt, gibt es zunächst kein Wörterbuch. Daher wird ein Verfahren zum Generieren eines synthetischen Wörterbuchs vorgeschlagen, das aus zwei Teilen besteht. Zunächst erhalten wir die erste Annäherung von W mithilfe eines domänen-kontradiktorischen Trainings (ein Wettbewerbsmodell wie GAN, jedoch anstelle des Generators - eine lineare Abbildung von W, mit der wir versuchen, S und T voneinander zu unterscheiden, und der Diskriminator versucht, den tatsächlichen Ursprung der Einbettung zu bestimmen). Basierend auf den Wörtern, deren Einbettungen am besten zueinander passten und am häufigsten in beiden Gebäuden vorkommen, wird dann ein Wörterbuch gebildet. Danach erfolgt die Verfeinerung von W gemäß der obigen Formel.
Dieser Ansatz liefert Ergebnisse, die mit dem Lernen mit beschrifteten Daten vergleichbar sind. Dies kann sehr nützlich sein, um Sprache aus seltenen Sprachen zu erkennen und zu übersetzen, für die es zu wenige parallele Sprach-Text-Fälle gibt oder die fehlen.
Erkennung tiefer Anomalien mithilfe geometrischer TransformationenZusammenfassungCodeEin eher ungewöhnlicher Ansatz bei der Erkennung von Anomalien, der nach Ansicht der Autoren andere Ansätze stark zunichte macht.
Die Idee ist folgende: Lassen Sie uns K verschiedene geometrische Transformationen (eine Kombination aus Verschiebungen, 90-Grad-Drehung und Reflexion) entwickeln und auf jedes Bild des Originaldatensatzes anwenden. Das Bild, das als Ergebnis der i-ten Transformation erhalten wurde, gehört nun zur Klasse i, dh es gibt insgesamt K Klassen, von denen jede durch die Anzahl der Bilder dargestellt wird, die ursprünglich im Datensatz enthalten waren. Jetzt werden wir eine Mehrklassenklassifizierung für ein solches Markup unterrichten (die Autoren haben sich für ein breites Resnet entschieden).
Jetzt können wir K Vektoren y (Ti (x)) der Dimension K für ein neues Bild erhalten, wobei Ti die i-te Transformation ist, x das Bild ist, y die Modellausgabe ist. Die grundlegende Definition von „Normalität“ lautet wie folgt:
Hier haben wir für Bild x die vorhergesagten Wahrscheinlichkeiten der richtigen Klassen für alle Transformationen hinzugefügt. Je größer die „Normalität“ ist, desto wahrscheinlicher ist es, dass das Bild aus derselben Verteilung wie das Trainingsmuster stammt. Die Autoren behaupten, dass dies bereits sehr cool funktioniert, bieten aber dennoch einen komplexeren Weg, der noch ein wenig besser funktioniert. Wir nehmen an, dass der Vektor y (Ti (x)) für jede Ti-Transformation
Dirichlet- verteilt ist, und nehmen den Wahrscheinlichkeitslogarithmus als Maß für die „Normalität“ des Bildes. Die Dirichlet-Verteilungsparameter werden anhand eines Trainingssatzes geschätzt.
Die Autoren berichten über die unglaubliche Leistungssteigerung im Vergleich zu anderen Ansätzen.
Ein einfaches, einheitliches Framework zum Erkennen von Stichproben und Angriffen, die nicht in der Verteilung sindZusammenfassungCodeDie Identifizierung in der Stichprobe für die Anwendung des Fallmodells, das sich erheblich von der Verteilung der Trainingsstichprobe unterscheidet, ist eine der Hauptanforderungen für die Erzielung zuverlässiger Klassifizierungsergebnisse. Gleichzeitig sind neuronale Netze dafür bekannt, dass sie Objekte mit einem hohen Maß an Sicherheit (und fälschlicherweise) klassifizieren, die im Training nicht angetroffen oder absichtlich beschädigt wurden (gegnerische Beispiele).
Die Autoren des Artikels bieten eine neue Methode zur Identifizierung dieser und anderer "schlechter" Fälle. Der Ansatz wird wie folgt implementiert: Zuerst wird ein neuronales Netzwerk mit der üblichen Softmax-Ausgabe trainiert, dann wird die Ausgabe seiner vorletzten Schicht genommen und der generative Klassifikator darauf trainiert. Es sei x - das der Modelleingabe für ein bestimmtes Klassifizierungsobjekt zugeführt wird, y - die entsprechende Klassenbezeichnung, und es sei angenommen, dass wir einen vorab trainierten Softmax-Klassifizierer der Form haben:
Wobei wc und bc die Gewichte und Konstanten der Softmax-Schicht für Klasse c sind und f (.) Die Ausgabe des vorletzten Sojabohnen-DNN ist.
Ferner wird ohne Änderungen an dem vorab trainierten Klassifikator ein Übergang zum generativen Klassifikator vorgenommen, nämlich eine Diskriminanzanalyse. Es wird angenommen, dass Merkmale, die der vorletzten Schicht des Softmax-Klassifikators entnommen wurden, eine mehrdimensionale Normalverteilung aufweisen, von der jede Komponente einer Klasse entspricht. Dann kann die bedingte Verteilung durch den Vektor der Mittelwerte der mehrdimensionalen Verteilung und ihrer Kovarianzmatrix spezifiziert werden:
Um die Parameter des generativen Klassifikators zu bewerten, werden empirische Mittelwerte für jede Klasse sowie die Kovarianz für Fälle aus der Trainingsstichprobe {(x1, y1), ..., (xN, yN)} berechnet:
Dabei ist N die Anzahl der Fälle der entsprechenden Klasse im Trainingssatz. Dann wird ein Maß für die Zuverlässigkeit an der Testprobe berechnet - der Mahalanobis-Abstand zwischen dem Testfall und der diesem Fall am nächsten liegenden normalen Klassenverteilung.
Wie sich herausstellte, funktioniert eine solche Metrik bei atypischen oder beschädigten Objekten viel zuverlässiger, ohne hohe Schätzungen wie die Softmax-Schicht abzugeben. Bei den meisten Vergleichen mit verschiedenen Daten zeigte die vorgeschlagene Methode Ergebnisse, die den aktuellen Stand der Technik übertrafen, indem beide Fälle gefunden wurden, die nicht im Training waren und absichtlich verwöhnt wurden.
Darüber hinaus betrachten die Autoren eine weitere interessante Anwendung ihrer Methodik: Verwenden Sie den generativen Klassifikator, um neue Klassen hervorzuheben, die sich nicht im Training für den Test befanden, und aktualisieren Sie dann die Parameter des Klassifikators selbst, damit er diese neue Klasse in Zukunft bestimmen kann.
Widersprüchliche Beispiele, die sowohl Computer Vision als auch zeitlich begrenzte Menschen zum Narren haltenZusammenfassung:
https://arxiv.org/abs/1802.08195adversarial examples . , . adversarial example . , , , , , , , adversarial attacks.

adversarial examples. adversarial examples , ( , ).
, adversarial example, . , , 63 . accuracy 10% , adversarial. , adversarial , . , perturbation perturbation , accuracy .
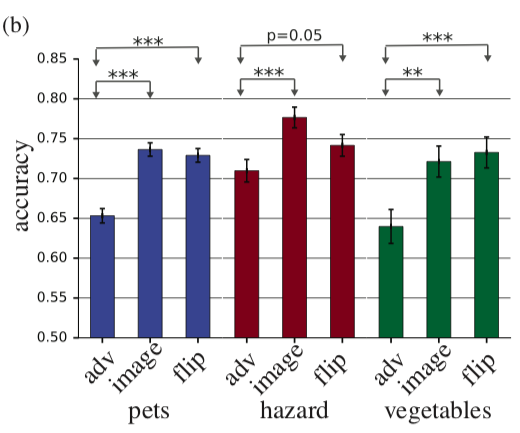
adv — adversarial example, image — , flip — + adversarial perturbation, .
Sanity Checks for Saliency MapsAbstract— . deep learning, saliency maps. Saliency maps . saliency map, , “”.

: “ saliency maps?” , :
- Saliency map
- Saliency map ,
, : cascading randomization ( , , saliency map) independent randomization ( ). : , saliency maps.
saliency map , , saliency maps. : “To our surprise, some widely deployed saliency methods are independent of both the data the model was trained on, and the model parameters”, — . , , saliency maps, , cascading randomization:
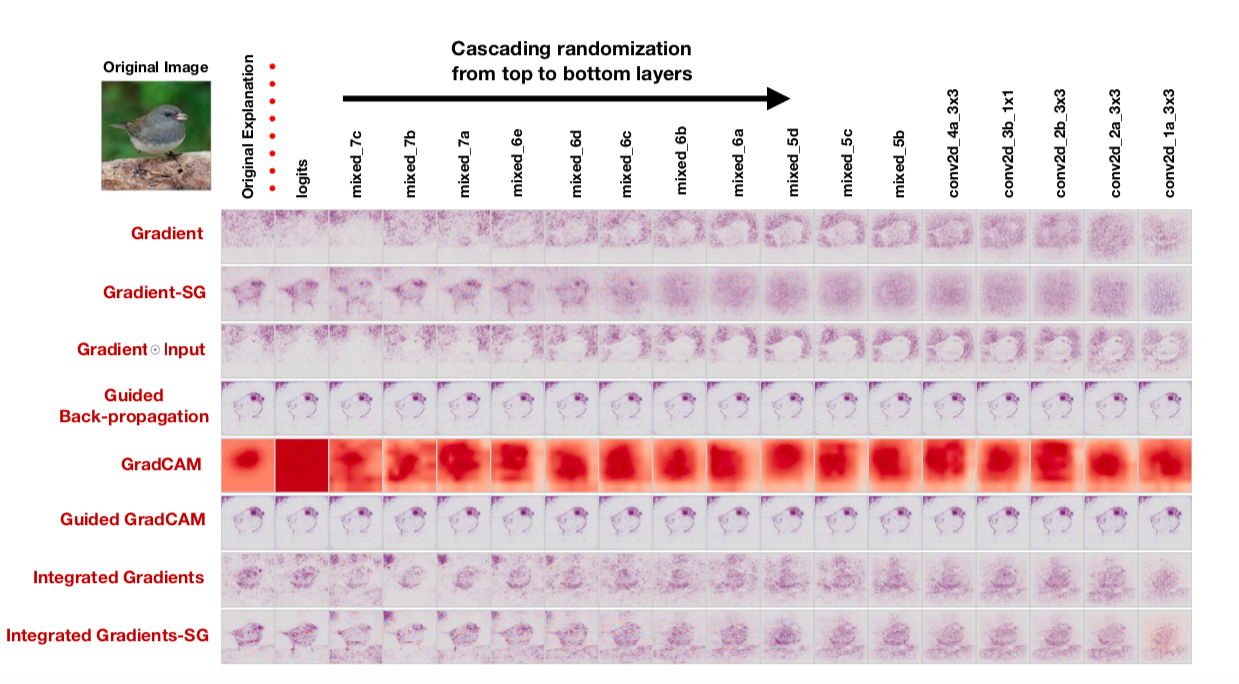
, . , saliency maps .
, — saliency maps , , confirmation bias. , .
An intriguing failing of convolutional neural networks and the CoordConv solutionAbstract:
https://arxiv.org/abs/1807.03247: , 10 .
Uber. , , , . , :
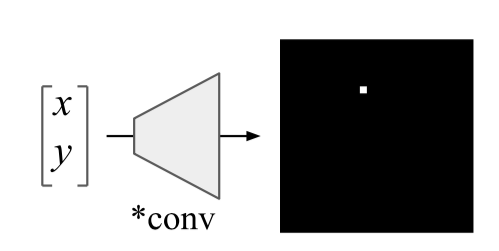
: ( CoodrConv ) i j, :
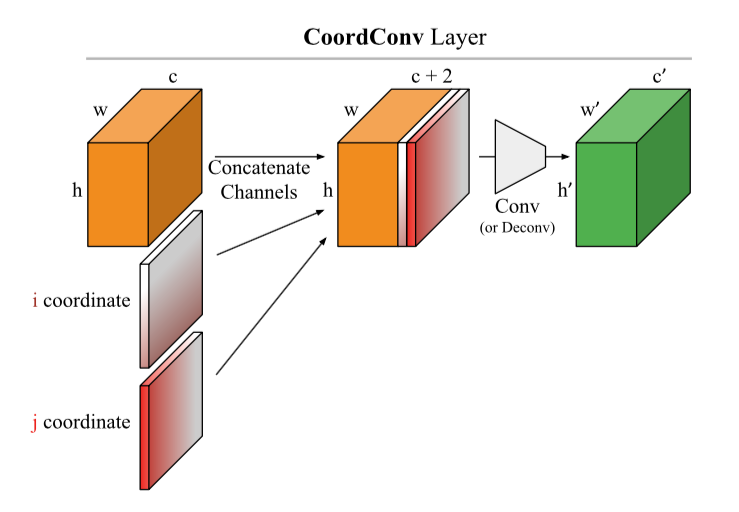
, :
- ImageNet'. , , , ,
- CoordConv object detection. MNIST, Faster R-CNN, IoU 21%
- CoordConv GAN .
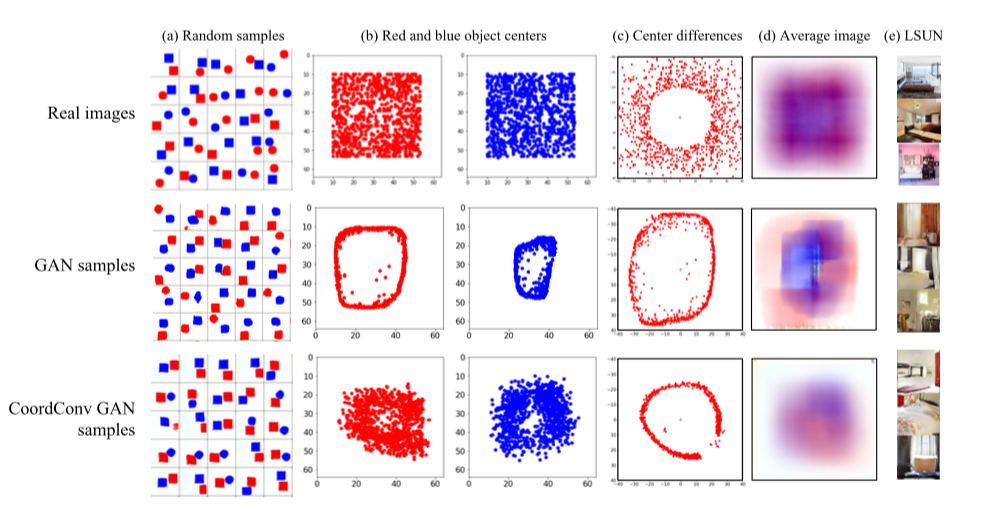
GAN' : LSUN. , — c. , GAN' , , . CoordConv , . LSUN d , , CoordConv GAN,
- 4. CoordConv A2C ( ) .
, , . CoordConv
U-net :
https://arxiv.org/abs/1812.01429, https://www.kaggle.com/c/tgs-salt-identification-challenge/discussion/69274 ,
https://github.com/mjDelta/Kaggle-RSNA-Pneumonia-Detection-Challenge .
.
Regularizing by the Variance of the Activations' Sample-VariancesAbstractbatch normalization. - . : S1 S2 :
wobei σ2 Probenvarianzen in S1 bzw. S2 sind, ist β der trainierte positive Koeffizient. Die Autoren nennen dieses Ding Varianzkonstanzverlust (VCL) und addieren es zum Gesamtverlust.
Im Abschnitt über Experimente beschweren sich die Autoren darüber, dass die Ergebnisse der Artikel anderer Personen nicht reproduziert werden, und verpflichten sich, einen reproduzierbaren Code (angelegt) zu erstellen. Zunächst experimentierten sie mit einem kleinen 11-Lagen-Netz am Datensatz kleiner Bilder (CIFAR-10 und CIFAR-100). Wir haben festgestellt, dass VCL beweist, wenn Sie Leaky ReLU oder ELU als Aktivierungen verwenden, aber die Batch-Normalisierung mit ReLU besser funktioniert. Dann erhöhen sie die Anzahl der Ebenen um das Zweifache und wechseln zu Tiny Imagenet - einer vereinfachten Version von Imagenet mit 200 Klassen und einer Auflösung von 64 x 64. Bei der Validierung übertrifft VCL die Batch-Normalisierung im Grid mit ELU sowie ResNet-110 und DenseNet-40, übertrifft jedoch Wide-ResNet-32. Ein interessanter Punkt ist, dass die besten Ergebnisse erzielt werden, wenn die Teilmengen S1 und S2 aus zwei Stichproben bestehen.
Darüber hinaus testen die Autoren VCL in Feed-Forward-Netzwerken, und VCL gewinnt etwas häufiger als ein Netzwerk mit Batch-Normalisierung oder ohne Regularisierung.
DropMax: Adaptiver Variations-SoftmaxZusammenfassungCodeIn dem Mehrklassenklassifizierungsproblem wird vorgeschlagen, bei jeder Iteration des Gradientenabfalls für jede Probe eine zufällige Anzahl falscher Klassen zufällig fallen zu lassen. Darüber hinaus wird auch die Wahrscheinlichkeit trainiert, mit der wir die eine oder andere Klasse für das eine oder andere Objekt fallen lassen. Infolgedessen stellt sich heraus, dass sich das Netzwerk auf die Unterscheidung zwischen den am schwierigsten zu trennenden Klassen konzentriert.
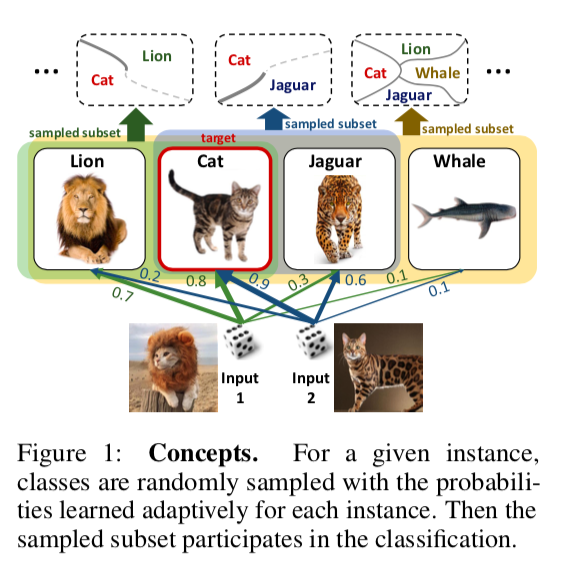
Experimente mit MNIST-, CIFAR- und Imagenet-Untergruppen zeigen, dass DropMax eine bessere Leistung als Standard-SoftMax und einige seiner Modifikationen aufweist.
Genaue verständliche Modelle mit paarweisen Interaktionen(Freunde lassen Freunde keine Black-Box-Modelle bereitstellen: Die Bedeutung der Verständlichkeit beim maschinellen Lernen)
Zusammenfassung:
http://www.cs.cornell.edu/~yinlou/papers/lou-kdd13.pdfCode: Es ist nicht da. Ich bin sehr daran interessiert, wie die Autoren einen so leicht zwingenden Namen mit einem Mangel an Code versehen. Akademiker, Sir =)
Sie können sich dieses Paket beispielsweise ansehen:
https://github.com/dswah/pyGAM . Vor nicht allzu langer Zeit wurden Feature-Interaktionen hinzugefügt (was GAM tatsächlich von GA2M unterscheidet).
Dieser Artikel wurde im Rahmen des Workshops „Interpretierbarkeit und Robustheit in Audio, Sprache und Sprache“ vorgestellt, obwohl er sich der Interpretierbarkeit von Modellen im Allgemeinen und nicht dem Bereich der Ton- und Sprachanalyse widmet. Wahrscheinlich war jeder in gewissem Maße mit dem Dilemma konfrontiert, zwischen Modellinterpretierbarkeit und zu wählen seine Genauigkeit. Wenn wir die übliche lineare Regression verwenden, können wir anhand der Koeffizienten verstehen, wie sich jede unabhängige Variable auf die abhängige auswirkt. Wenn wir Black-Box-Modelle verwenden, z. B. Gradientenverstärkung ohne Einschränkung der Komplexität oder tiefe neuronale Netze, ist ein korrekt abgestimmtes Modell für geeignete Daten sehr genau, aber die Verfolgung und Erklärung aller Muster, die das in den Daten gefundene Modell enthält, ist problematisch. Dementsprechend wird es schwierig sein, dem Kunden das Modell zu erklären und zu verfolgen, ob er etwas gelernt hat, das wir nicht möchten. Die folgende Tabelle enthält Schätzungen der relativen Interpretierbarkeit und Genauigkeit verschiedener Modelltypen.

Ein Beispiel für eine Situation, in der eine schlechte Interpretierbarkeit des Modells mit großen Risiken verbunden ist: In einem der medizinischen Datensätze wurde das Problem der Vorhersage der Wahrscheinlichkeit, dass der Patient an einer Lungenentzündung stirbt, gelöst. Das folgende interessante Muster wurde in den Daten gefunden: Wenn eine Person Asthma bronchiale hat, ist die Wahrscheinlichkeit, an einer Lungenentzündung zu sterben, geringer als bei Menschen ohne diese Krankheit. Als sich die Forscher an praktizierende Ärzte wandten, stellte sich heraus, dass ein solches Muster tatsächlich besteht, da Menschen mit Asthma im Falle einer Lungenentzündung die schnellste Hilfe und die stärksten Medikamente erhalten. Wenn wir xgboost auf diesen Datensatz trainiert hätten, hätte er dieses Muster höchstwahrscheinlich erkannt, und unser Modell würde Patienten mit Asthma als Gruppe mit geringem Risiko klassifizieren und dementsprechend eine niedrigere Priorität und Behandlungsintensität für sie empfehlen.
Die Autoren des Artikels bieten eine Alternative, die gleichzeitig interpretierbar und genau ist - dies ist GA2M, eine Unterart verallgemeinerter additiver Modelle.
Klassisches GAM kann als weitere Verallgemeinerung von GLM betrachtet werden: Ein Modell ist eine Summe, deren Term den Einfluss nur einer unabhängigen Variablen auf die abhängige Variable widerspiegelt. Der Einfluss wird jedoch nicht durch einen Gewichtskoeffizienten wie in GLM ausgedrückt, sondern durch eine glatte nichtparametrische Funktion (in der Regel stückweise definiert) Funktionen - Splines oder Bäume von geringer Tiefe, einschließlich "Stümpfe"). Aufgrund dieser Funktion können GAMs komplexere Beziehungen modellieren als ein einfaches lineares Modell. Andererseits können gelernte Abhängigkeiten (Funktionen) visualisiert und interpretiert werden.
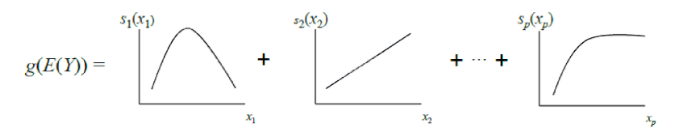
Standard-GAMs erreichen jedoch häufig immer noch nicht die Genauigkeit von Black-Box-Algorithmen. Um dies zu beheben, bieten die Autoren des Artikels einen Kompromiss an - um der Modellgleichung zusätzlich zu den Funktionen einer Variablen eine kleine Anzahl von Funktionen zweier Variablen hinzuzufügen - sorgfältig ausgewählte Paare, deren Interaktion für die Vorhersage der abhängigen Variablen von Bedeutung ist. Somit wird GA2M erhalten.
Zuerst wird ein Standard-GAM erstellt (ohne die Interaktion von Variablen zu berücksichtigen), und dann werden schrittweise Variablenpaare hinzugefügt (das verbleibende GAM wird als Zielvariable verwendet). Für den Fall, dass viele Variablen vorhanden sind und die Aktualisierung des Modells nach jedem Schritt rechenintensiv ist, wird ein FAST-Ranking-Algorithmus vorgeschlagen, mit dem Sie potenziell nützliche Paare vorab auswählen und eine vollständige Aufzählung vermeiden können.
Dieser Ansatz ermöglicht es uns, Qualität in der Nähe von Modellen mit unbegrenzter Komplexität zu erzielen. Die Tabelle zeigt die Fehlerrate verallgemeinerter additiver Modelle im Vergleich zu einer zufälligen Gesamtstruktur zur Lösung des Klassifizierungsproblems in verschiedenen Datensätzen. In den meisten Fällen unterscheidet sich die Qualität der Vorhersage für GA2M mit FAST und für zufällige Gesamtstrukturen nicht signifikant.
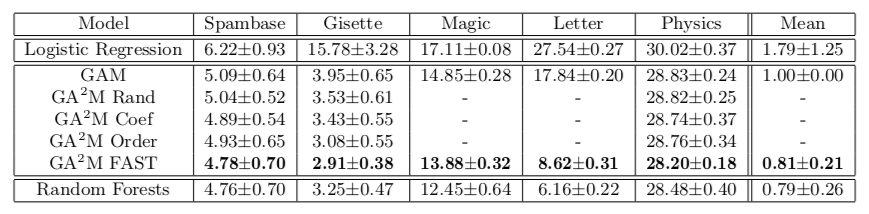
Ich möchte auf die Merkmale der Arbeit von Akademikern aufmerksam machen, die anbieten, diese Verstärkungen und Tiefschneidungen an den Ofen zu senden. Bitte beachten Sie, dass die Datensätze, auf denen die Ergebnisse dargestellt werden, nicht mehr als 20.000 Objekte enthalten (alle Datensätze aus dem UCI-Repository). Es stellt sich natürlich die Frage: Gibt es für solche Experimente im Jahr 2018 wirklich keinen offenen Datensatz normaler Größe? Sie können noch weiter gehen und einen Datensatz mit 50 Objekten vergleichen. Es besteht die Möglichkeit, dass sich das konstante Modell nicht wesentlich von einer zufälligen Gesamtstruktur unterscheidet.
Der nächste Punkt ist die Regularisierung. Bei einer Vielzahl von Zeichen ist es sehr einfach, auch ohne Wechselwirkungen umzuschulen. Die Autoren glauben möglicherweise, dass dieses Problem nicht besteht, und das einzige Problem ist das Black-Box-Modell. Zumindest in dem Artikel wird von Regularisierung nirgendwo gesprochen, obwohl dies offensichtlich notwendig ist.
Und das letzte, was die Interpretierbarkeit betrifft. Selbst lineare Modelle sind nicht interpretierbar, wenn wir viele Funktionen haben. Wenn Sie 10 Tausend normalverteilte Gewichte haben (bei Verwendung der L2-Regularisierung ist dies ungefähr so), ist es unmöglich, genau zu sagen, welche Vorzeichen für die Tatsache verantwortlich sind, dass Predict_Proba 0,86 ergibt. Zur Interpretierbarkeit wollen wir nicht nur ein lineares Modell, sondern ein lineares Modell mit geringen Gewichten. Es scheint, dass dies durch L1-Regularisierung erreicht werden kann, aber auch hier ist es nicht so einfach. Aus einer Reihe stark korrelierter Merkmale wird die L1-Regularisierung fast zufällig eines auswählen. Der Rest erhält eine Gewichtung von 0, obwohl, wenn eines dieser Merkmale Vorhersagefähigkeit besitzt, die anderen eindeutig nicht nur Rauschen sind. In Bezug auf die Modellinterpretation kann dies in Ordnung sein. In Bezug auf das Verständnis der Beziehung zwischen Merkmalen und der Zielvariablen ist dies sehr schlecht. Das heißt, selbst bei linearen Modellen ist nicht alles so einfach. Weitere Details zu interpretierbaren und glaubwürdigen Modellen finden Sie
hier .
Visualisierung für maschinelles Lernen: UMAPAbsorbierenCodeAm Tag der Tutorials war einer der ersten, der durchgeführt wurde, "Visualisierung für maschinelles Lernen" von Google Brain. Im Rahmen des Tutorials wurden wir über die Geschichte der Visualisierungen informiert, beginnend mit dem Ersteller der ersten Grafiken, sowie über verschiedene Merkmale des menschlichen Gehirns und die Wahrnehmung und Techniken, mit denen die Aufmerksamkeit auf das Wichtigste im Bild gelenkt werden kann, selbst wenn es viele kleine Details enthält - zum Beispiel das Hervorheben Form, Farbe, Rahmen usw. wie im Bild unten. Ich werde diesen Teil überspringen, aber es gibt eine
gute Bewertung .

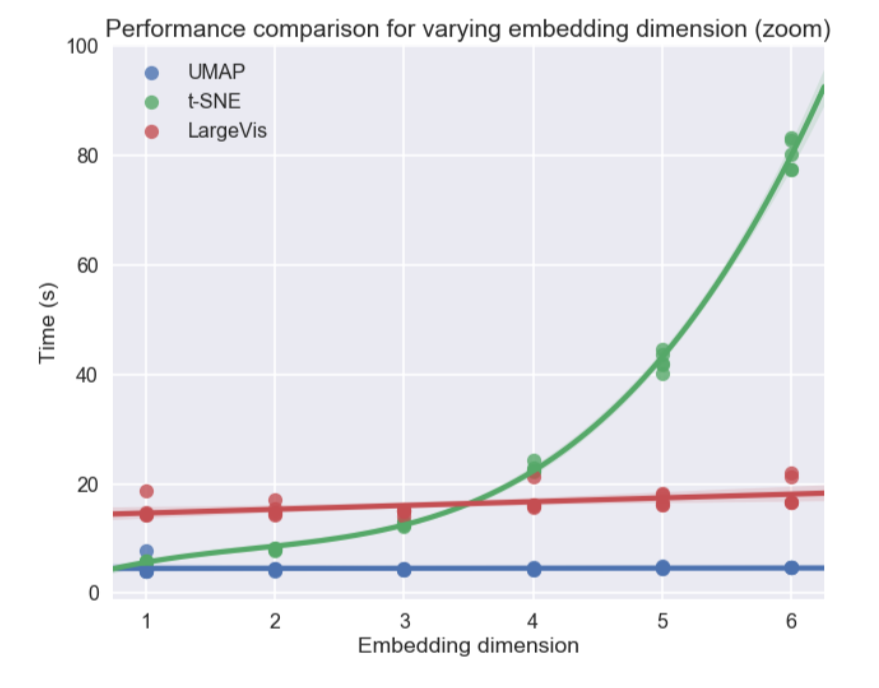
Persönlich interessierte mich am meisten das Thema der Visualisierung mehrdimensionaler Datensätze, insbesondere der UMAP-Ansatz (Uniform Manifold Approximation and Projection) - eine neue nichtlineare Methode zur Dimensionsreduzierung. Es wurde im Februar dieses Jahres vorgeschlagen, so dass es bisher nur wenige Menschen verwenden, aber es sieht sowohl in Bezug auf die Arbeitszeit als auch in Bezug auf die Qualität der Klassentrennung in zweidimensionalen Visualisierungen vielversprechend aus. In verschiedenen Datensätzen ist UMAP t-SNE und anderen Methoden in Bezug auf die Geschwindigkeit 2-10 Mal voraus. Je größer die Datendimension, desto größer ist die Leistungslücke:
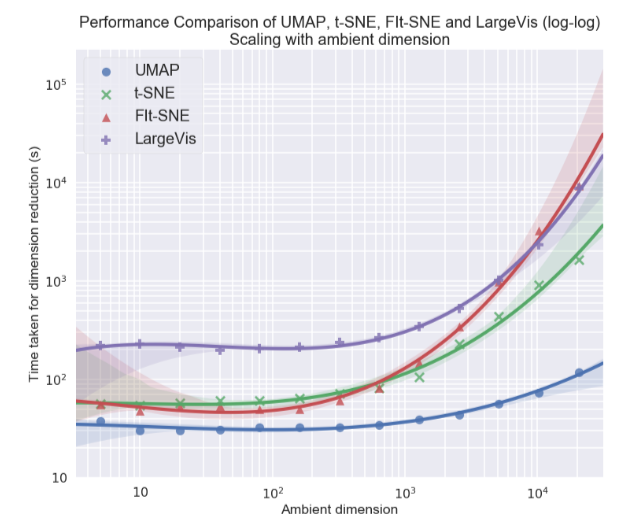
Darüber hinaus ist die UMAP-Betriebszeit im Gegensatz zu t-SNE nahezu unabhängig von der Dimension des neuen Raums, in den wir unseren Datensatz einbetten (siehe Abbildung unten), was ihn zu einem geeigneten Werkzeug für andere Aufgaben (neben der Visualisierung) macht - insbesondere für um die Abmessung vor dem Training des Modells zu reduzieren.
Gleichzeitig haben Tests an verschiedenen Datensätzen gezeigt, dass UMAP für die Visualisierung nicht schlechter funktioniert und t-SNE stellenweise besser ist: Beispielsweise sind Klassen in MNIST- und Fashion MNIST-Datensätzen in der Version mit UMAP besser getrennt:
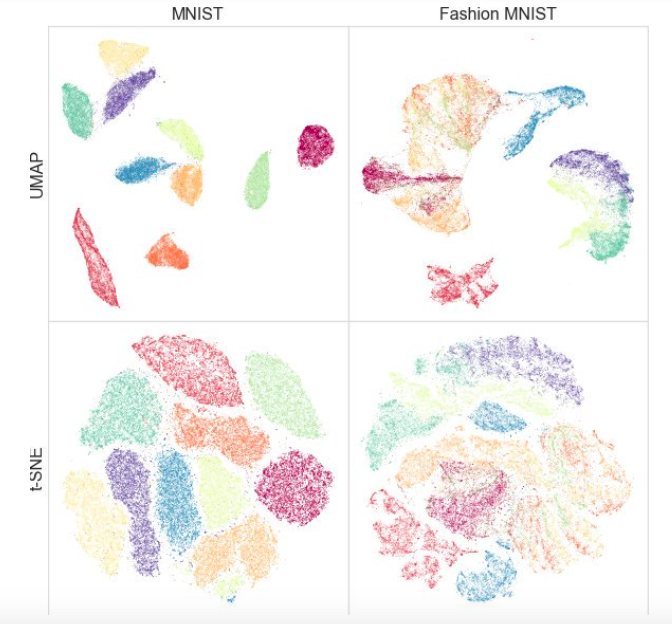
Ein zusätzliches Plus ist eine praktische Implementierung: Die UMAP-Klasse erbt von den sklearn-Klassen, sodass Sie sie als regulären Transformator in der sklearn-Pipeline verwenden können. Darüber hinaus wird argumentiert, dass UMAP besser interpretierbar ist als t-SNE unterhält eine globale Datenstruktur besser.
In Zukunft planen die Autoren, Unterstützung für halbüberwachtes Training hinzuzufügen. Wenn wir also Tags für mindestens einige der Objekte haben, können wir UMAP basierend auf diesen Informationen erstellen.
Welche Artikel haben Ihnen gefallen? Schreiben Sie Kommentare, stellen Sie Fragen, wir werden sie beantworten.