Wir experimentieren weiter mit den Formaten der Mitaps. Kürzlich
kollidierten wir in einem Boxring
mit einem zentralen Datenbus und Service Mesh. Diesmal haben wir uns entschlossen, etwas friedlicheres auszuprobieren - StandUp, also ein offenes Mikrofon. Das Thema wurde als In-Memory-Datenbank ausgewählt.

In welchen Fällen sollte ich auf In-Memory umschalten? Wie und warum skalieren? Und worauf lohnt es sich zu achten? Die Antworten finden Sie in den Reden der Redner, die wir in diesem Beitrag behandeln werden.
Aber stellen Sie sich zuerst die Lautsprecher vor:
- Andrey Trushkin, Leiter des Zentrums für Innovation und fortschrittliche Technologien der Promsvyazbank
- Vladislav Shpileva, Tarantool-Entwickler
- Artyom Shitov, GridGain-Lösungsarchitekt
Wechseln Sie in den Arbeitsspeicher
Aktuelle Trends auf dem Finanzmarkt stellen viel strengere Anforderungen an die Reaktionszeit und den Betrieb der Prozessautomatisierung im Allgemeinen. Darüber hinaus versuchen heute fast alle großen Finanzinstitute, ihre eigenen Ökosysteme aufzubauen.
In dieser Hinsicht sehen wir uns zwei Hauptanwendungen von In-Memory-Lösungen. Das erste ist das Zwischenspeichern von Integrationsdaten. Nach dem klassischen Szenario gibt es in großen Unternehmen mehrere automatisierte Systeme, die auf Wunsch des Benutzers Daten bereitstellen. Oder ein externes System - aber in diesem Fall ist der Initiator in den meisten Fällen der Benutzer. Traditionell speicherten diese Systeme Daten, die auf bestimmte Weise strukturiert waren, in der Datenbank und griffen bei Bedarf darauf zu.
Solche Systeme erfüllen heute nicht mehr die Anforderungen an die Belastung. Hier sollten wir die Fernaufrufe dieser Systeme durch Verbrauchersysteme nicht vergessen. Dies impliziert die Notwendigkeit, die Ansätze für die Speicherung und Präsentation von Daten zu überarbeiten - für Benutzer, automatisierte Systeme oder einzelne Dienste. Logische Ausgabe - Speicherung relevanter Daten, die von Diensten auf der Ebene der In-Memory-Schicht verwendet werden; Es gibt viele ähnliche erfolgreiche Fälle auf dem Markt.
Dies war der erste Fall. Die zweite ist aus technischer Sicht das Geschäftsprozessmanagement. Herkömmliche BPM-Systeme automatisieren die Ausführung bestimmter Vorgänge gemäß einem vordefinierten Algorithmus. In vielen Fällen stellen sich Fragen: Warum sind diese Systeme nicht effizient und schnell genug?
In der Regel schreiben solche Systeme jeden Schritt (oder einen kleinen Satz von Schritten, die als Geschäftstransaktion konzipiert sind) in die Datenbank. Sie sind also an die Reaktionszeit und die Interaktion mit diesen Systemen gebunden. Die Anzahl der Geschäftsprozessinstanzen, die gleichzeitig in Echtzeit ausgeführt werden, liegt vor mehr als 10 Jahren um Größenordnungen. Moderne Geschäftsprozessmanagementsysteme sollten daher eine deutlich höhere Leistung aufweisen und die Ausführung dezentraler Anwendungen sicherstellen. Darüber hinaus streben heute alle Unternehmen die Bildung einer großen Microservice-Umgebung an. Die Herausforderung besteht darin, dass verschiedene Instanzen von Geschäftsprozessen Betriebsdaten gemeinsam nutzen und effizient nutzen können. Im Rahmen der Orchestrierung ist es sinnvoll, diese in einer In-Memory-Lösung zu speichern.
Versöhnungsproblem
Angenommen, wir haben eine große Anzahl von Knoten und Diensten, es werden eine Reihe von Geschäftsprozessen ausgeführt, deren Aktionen in Form von Mikrodiensten implementiert werden. Um die Leistung zu verbessern, beginnt jeder von ihnen, seinen Status in eine lokale Speicherinstanz zu schreiben. Wir erhalten eine große Anzahl lokaler Instanzen. Wie kann Relevanz und Konsistenz für alle sichergestellt werden?
Wir verwenden In-Memory-Bereiche für Zonen. Zum Beispiel abhängig von der Geschäftsdomäne. Wenn wir eine Geschäftsdomäne ausschneiden, stellen wir fest, dass bestimmte Microservices / Geschäftsprozesse nur im Rahmen der Zone funktionieren, die für die entsprechende Domäne verantwortlich ist. Auf diese Weise können wir das Cache-Update und die gesamte In-Memory-Lösung beschleunigen.
Gleichzeitig arbeitet der für die Domäne verantwortliche Cache im vollständigen Replikationsmodus. Die begrenzte Anzahl von Knoten aufgrund der Verteilung auf die Domänen gewährleistet die Geschwindigkeit und Richtigkeit der Lösung in diesem Modus. Zoning und maximale Fragmentierung helfen, die Probleme der Synchronisation, des Clusterbetriebs usw. zu lösen. auf einer großen Gesamtzahl von Knoten.
Natürlich stellen sich häufig Fragen zur Zuverlässigkeit von In-Memory-Lösungen. Ja, da kann nicht alles hingelegt werden. Um die Zuverlässigkeit zu gewährleisten, haben wir immer Datenbanken neben dem In-Memory. Zum Beispiel für wichtige Probleme mit der Berichterstellung, die zusammengeführt werden müssen, was auf einer großen Anzahl von Knoten schwierig sein kann. Was ist unsere heutige Vision: die
Synergie der beiden Ansätze .
Es ist auch erwähnenswert, dass diese beiden Ansätze auch nur im Gegensatz nicht ganz richtig sind. Und gleichzeitig konzentrieren Sie sich auf sie. Hersteller und Anbieter fortschrittlicher containerisierter Virtualisierungssysteme wie Kubernetes bieten uns bereits Optionen für eine langfristig zuverlässige Speicherung. Es sind bereits gute industrielle Fälle für die Implementierung von Lösungen aufgetreten, in denen die Speicherung in einem solchen virtualisierten Format erfolgt.
Eine der größten US-Zeitungen bietet ihren Lesern die Möglichkeit, jede Ausgabe online zu erhalten, die seit Beginn der Veröffentlichung dieser Zeitung im 19. Jahrhundert veröffentlicht wurde. Wir können uns das Belastungsniveau vorstellen. Der Speicher wird von ihnen über die Apache Kafka-Plattform implementiert, die für Kubernetes bereitgestellt wird. Hier ist eine weitere Option zum Speichern von Informationen und zum Bereitstellen des Zugriffs unter einer großen Last für eine große Anzahl von Kunden. Bei der Entwicklung neuer Lösungen sollte diese Option ebenfalls beachtet werden.
Skalieren von In-Memory-Datenbanken mit Tarantool
Angenommen, wir haben einen Server. Es akzeptiert Anfragen, speichert Daten. Plötzlich gibt es mehr Anfragen und Daten, der Server hört auf, mit der Last fertig zu werden. Sie können mehr Hardware auf den Server hochladen, der weitere Anforderungen akzeptiert. Dies ist jedoch aus drei Gründen gleichzeitig eine Sackgasse: hohe Kosten, begrenzte technische Fähigkeiten und Probleme mit der Fehlertoleranz. Stattdessen erfolgt eine horizontale Skalierung: „Freunde“ kommen zum Server, um Aufgaben zu erledigen. Die beiden Haupttypen der horizontalen Skalierung sind Replikation und Sharding.
Bei der Replikation werden viele Server gespeichert, die alle dieselben Daten speichern, und Clientanforderungen werden auf alle diese Server verteilt. So skalieren Computer und nicht Daten. Dies funktioniert, wenn Daten auf einem Knoten platziert werden, es jedoch so viele Clientanforderungen gibt, dass ein Server diese nicht verarbeiten kann. Auch hier wird die Fehlertoleranz stark verbessert.
Sharding wird zum Skalieren von Daten verwendet: Viele Server werden erstellt und speichern unterschiedliche Daten. Sie skalieren also sowohl Berechnungen als auch Daten. Die Fehlertoleranz ist in diesem Fall jedoch gering. Wenn ein Server ausfällt, geht ein Teil der Daten verloren.
Es gibt einen dritten Ansatz - sie zu kombinieren. Wir unterteilen den Cluster in Subcluster und nennen sie Replikatsätze. Jeder von ihnen speichert dieselben Daten, und Daten überschneiden sich nicht zwischen Replikatsätzen. Das Ergebnis ist die Skalierung von Daten sowie die Berechnung und Fehlertoleranz.
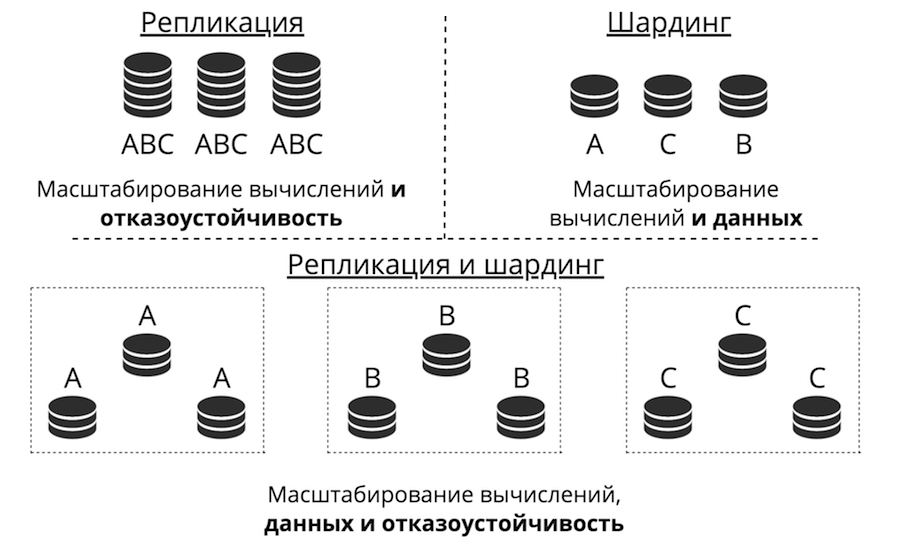
Replikation
Es gibt zwei Arten der Replikation: asynchron und synchron. Asynchron ist, wenn Clientanforderungen nicht warten, bis die Daten über die Replikate verteilt sind: Das Schreiben in ein Replikat ist ausreichend. Sobald die Daten auf die Festplatte im Protokoll gelangt sind, ist die Transaktion erfolgreich und eines Tages im Hintergrund werden diese Daten repliziert. Synchron - wenn eine Transaktion in zwei Phasen unterteilt ist: Vorbereiten und Festschreiben. Commit gibt keinen Erfolg zurück, bis die Daten auf ein Quorum von Replikaten repliziert wurden.
Die asynchrone Replikation ist offensichtlich schneller, da im Netzwerk nichts ruht. Die Daten werden im Hintergrund an das Netzwerk gesendet, und die im Protokoll aufgezeichnete Transaktion selbst ist abgeschlossen. Es gibt jedoch ein Problem: Replikate können hintereinander zurückbleiben und nicht synchron angezeigt werden.
Die synchrone Replikation ist zuverlässiger, aber viel langsamer und schwieriger zu implementieren. Es gibt komplexe Protokolle. In Tarantool können Sie je nach Aufgabe einen dieser Replikationstypen auswählen.

Die Verzögerung von Replikaten führt nicht nur zur Desynchronisation, sondern auch zum Unwissenheitsproblem des Masters: Er weiß nicht, wie er seine Änderungen an das Replikat weitergeben soll. Änderungen werden normalerweise schrittweise angegeben - sie werden angewendet und fliegen in derselben Form zum Replikat. Aber was tun mit ihnen, wenn das Replikat nicht verfügbar ist? Zum Beispiel kann alles in Tarantool konfiguriert werden, und der Assistent wird sehr flexibel.
Eine weitere Herausforderung: Wie kann die Topologie komplex gemacht werden? Mail.ru hat beispielsweise eine Topologie mit Hunderten von Tarantool. Es verfügt über einen Tarantool-Kernel, an den Replikat-Taranteln für Sicherungen in einem Kreis gebunden sind. In Tarantool können Sie völlig beliebige Topologien erstellen, mit denen die Replikation perfekt funktioniert.
Scherben
Fahren wir nun mit der Datenskalierung fort: Sharding. Es gibt zwei Arten: Bereiche und Hashes. Range Sharding ist, wenn alle Daten nach einem Sharding-Schlüssel sortiert sind und diese große Sequenz in Bereiche unterteilt ist, sodass jeder Bereich ungefähr die gleiche Datenmenge enthält. Und jeder Bereich wird vollständig auf einem beliebigen physischen Knoten gespeichert. Aber normalerweise ist eine solche Scherbe nicht erforderlich. Darüber hinaus ist es immer sehr kompliziert.
Es gibt auch Scherben mit Hashes. Es wird nur in Tarantool vorgestellt. Es ist viel einfacher zu implementieren, zu verwenden und fast immer geeignet, anstatt Bereiche zu teilen. Das funktioniert folgendermaßen: Wir betrachten die Hash-Funktion aus dem Datensatz und geben die Nummer des physischen Knotens zurück, auf dem gespeichert werden soll. Es gibt Probleme: Erstens ist es schwierig, eine komplexe Abfrage schnell abzuschließen.
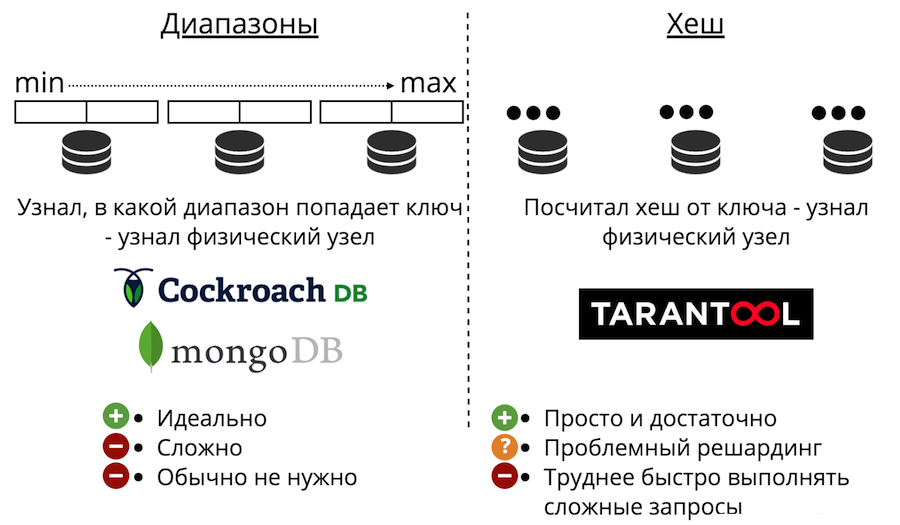
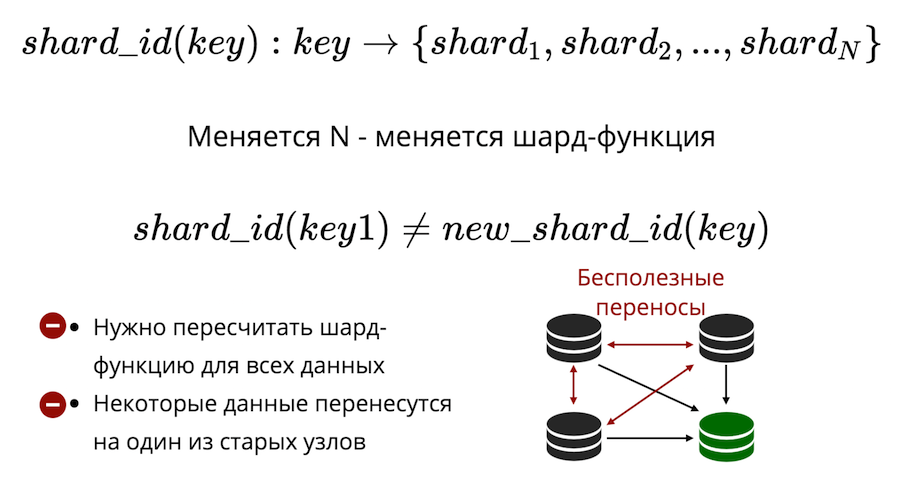
Zweitens gibt es das Problem des Resharding. Es gibt eine Art Shard-Funktion, die die Nummer des physischen Shards zurückgibt, in dem der Schlüssel gespeichert werden muss. Und wenn sich die Anzahl der Knoten ändert, ändert sich auch die Shard-Funktion. Dies bedeutet, dass alle Daten im Cluster neu berechnet und überprüft werden müssen. Darüber hinaus werden beim klassischen Sharding einige Daten nicht auf einen neuen Knoten übertragen, sondern einfach zwischen den alten Knoten gemischt. Nutzlose Übertragungen können beim klassischen Sharding nicht auf Null reduziert werden.
Tarantool verwendet virtuelles Sharding: Daten werden nicht auf physischen, sondern auf virtuellen Knoten verteilt. Virtueller Bucket in einem virtuellen Cluster. Und virtuelle Geschichten sind auf physischen Geschichten aufgebaut. Und schon dort ist garantiert, dass jedes virtuelle Stockwerk vollständig auf einem physischen Stockwerk liegt.
Wie löst dies das Problem des Weiterverkaufs? Tatsache ist, dass die Anzahl der Buckets festgelegt ist und die Anzahl der physischen Knoten erheblich überschreitet. Unabhängig davon, wie stark Sie Ihren Cluster physisch skalieren, reicht der Bucket immer aus, um Daten zu speichern und gleichmäßig zu verteilen. Und da die Shard-Funktion unverändert bleibt, müssen Sie sie nicht neu berechnen, wenn sich die Zusammensetzung des Clusters ändert.
Als Ergebnis erhalten wir
drei Arten von Sharding: Bereiche, Hashes und virtuelle Buckets . Bei Bereichen und Buckets liegt ein physikalisches Suchproblem vor.
Wie kann man es lösen? Der erste Weg: Verbieten Sie einfach das Resharding. Dann müssen Sie zum Resharding einen neuen Cluster erstellen und alles dorthin übertragen. Der zweite Weg: Gehen Sie immer zu allen Knoten. Dies macht jedoch keinen Sinn, da Sie skalieren müssen und die Berechnungen nicht so skalieren. Dritte Option: ein Proxy-Modul, das als eine Art Router für Buckets dient. Sie starten es, senden dort eine Anfrage, die die Nummer des Buckets angibt, und es sendet Ihre Anfrage als Proxy an den gewünschten physischen Knoten.
Erweiterter In-Memory mit dem Beispiel der GridGain-Plattform
Das Unternehmen hat zusätzliche Datenbankanforderungen. Er möchte, dass all dies fehlertolerant und katastrophal ist. Er will hohe Verfügbarkeit: damit nie etwas verloren geht, damit Sie sich schnell erholen können. Ebenfalls erforderlich sind einfache und kostengünstige Skalierbarkeit, unkomplizierter Support, Vertrauen in die Plattform und effiziente Zugriffsmechanismen.
Alle diese Ideen sind nicht neu. Viele dieser Dinge sind bis zu einem gewissen Grad in klassischen DBMS implementiert, insbesondere die Replikation zwischen Rechenzentren.
In-Memory ist keine Startup-Technologie mehr, sondern ausgereifte Produkte, die von den größten Unternehmen der Welt (Barclays, Citi Group, Microsoft usw.) eingesetzt werden. Es wird davon ausgegangen, dass dort alle diese Anforderungen erfüllt sind.
Wenn also plötzlich eine Katastrophe eintritt, sollte die Möglichkeit bestehen, sich von der Sicherung zu erholen. Wenn es sich um eine Finanzorganisation handelt, ist es wichtig, dass diese Sicherung konsistent ist und nicht nur eine Kopie aller Laufwerke. Damit es keine Situation gibt, in der auf einigen Teilen der Knoten die Daten zum Zeitpunkt X und auf dem anderen Teil zum Zeitpunkt Y wiederhergestellt wurden. Es ist sehr wichtig, eine Wiederherstellung zu einem bestimmten Zeitpunkt durchzuführen, damit selbst in einer Situation der Datenbeschädigung oder eines besonders schweren Unfalls der Verlust minimiert wird.
Es ist wichtig, Daten auf die Festplatte übertragen zu können. Damit der Cluster nicht überlastet wird und noch langsamer arbeitet. Und schnell von der Festplatte aufzusteigen und dann schon die Daten in den Speicher zu pumpen.
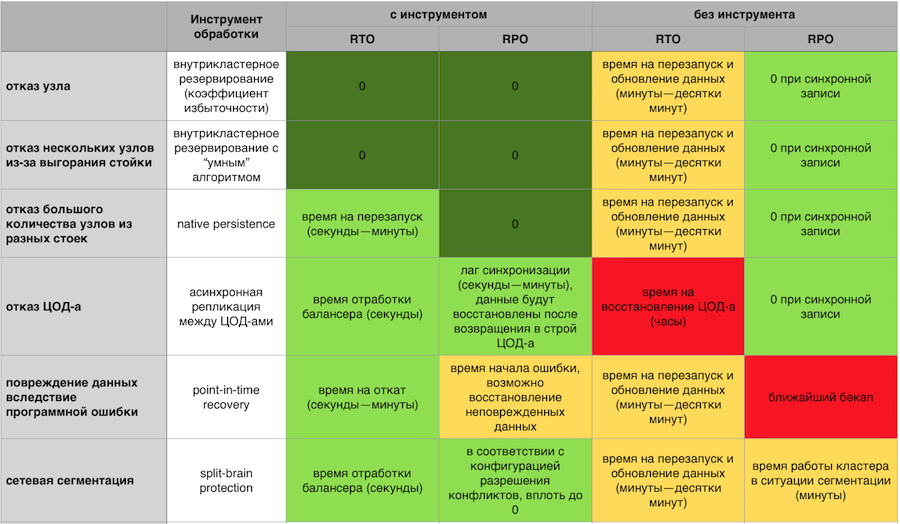 In-Memory-Reaktion auf Abstürze mit und ohne GridGain-Fehlertoleranzkomponenten
In-Memory-Reaktion auf Abstürze mit und ohne GridGain-FehlertoleranzkomponentenEin Failovercluster sollte sich leicht horizontal und vertikal skalieren lassen. Ich möchte nicht für meinen Server bezahlen und beobachten, wie die Hälfte der Ressourcen leer ist. Ich möchte nicht die Hölle aus Hunderten von Prozessen heraus haben, die verwaltet werden müssen. Ich möchte ein einfaches System aus Sicht der Unterstützung mit einer einfachen Eingabe / Ausgabe von Knoten aus dem Cluster und einem entwickelten, ausgereiften Überwachungssystem.
Betrachten Sie MongoDB in dieser Perspektive. Jeder, der mit MongoDB gearbeitet hat, kennt eine Vielzahl von Prozessen. Wenn wir eine schattierte MongoDB von 5 Shards haben, hat jeder Shard einen Replikatsatz von drei Prozessen (mit einem Redundanzverhältnis von 3). Und das sind 15 Prozesse nur für die Daten selbst. Der Cluster-Konfigurationsspeicher ist ein weiterer Plus-3-Prozess, insgesamt werden es 18, und dies schließt keine Router ein. Wenn Sie 20 Shards möchten, begrüßen Sie die Hölle aus 63+ (zum Beispiel weiteren 8, insgesamt 71) Prozessen.
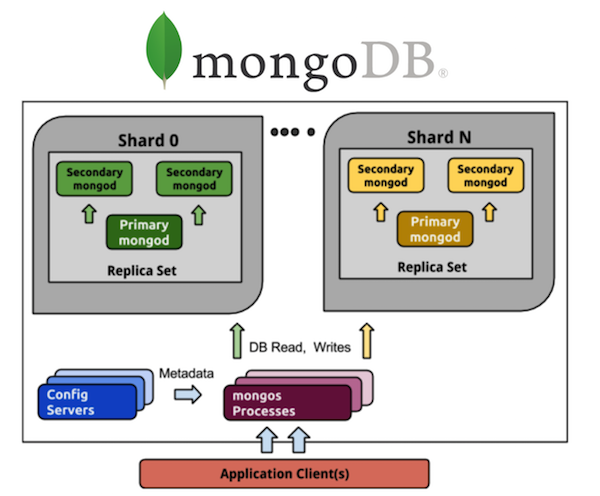
Vergleiche mit Cassandra. Wir nehmen alle die gleichen 5 Shards - dies sind 5 Prozesse und 5 Knoten mit dem gleichen Redundanzverhältnis von 3, was in Bezug auf die Steuerung viel einfacher ist. Ich möchte 20 Shards - das sind 20 Prozesse. Ich kann meinen Cluster auf eine beliebige Anzahl von Knoten skalieren, nicht unbedingt auf ein Vielfaches von 3 (oder auf einen anderen Wert des Redundanzkoeffizienten). Viel einfacher und billiger zu implementieren und zu warten als Replikatsätze.

Darüber hinaus müssen Sie dem System vertrauen, um zu verstehen, welche Personen hinter jedem einzelnen Produkt stehen. Idealerweise sollte die Lizenz Open Source oder Open Core sein. Damit im Falle des Todes des Verkäufers etwas getan werden kann. Es ist auch gut, wenn der Quellcode von einer unabhängigen Community verwaltet wird - wir alle erinnern uns, wie MongoDB und Redis auf Anfrage der Verwaltungsgesellschaft die Lizenzen geändert haben. Wie Aerospike Anfang des Jahres Beschränkungen für die Community-Edition „Open Source“ einführte.
Benötigen Sie einen effektiven Zugriff auf Daten. Fast alle haben eine strukturierte Abfragesprache in der einen oder anderen Form. Meistens verwenden sie SQL, es ist notwendig, dass die Anpassung mit dieser Sprache so einfach wie möglich ist. Dies hilft bei der Ausführung verteilter Abfragen, wenn Sie nicht eine Anforderung separat an jeden Knoten senden müssen, sondern mit dem Cluster wie mit einem „einzelnen Fenster“ kommunizieren können. Ohne aus Sicht der API zu denken, handelt es sich um eine Reihe von Knoten (denken Sie daran, wie schwierig es ist, mit Memcache auf großen Volumes zu arbeiten, selbst auf der einfachsten Put / Get-Ebene, ohne potenziell komplexe SQL-Abfragen), verteilte DDL- und ACID-Garantien.
Und schließlich Unterstützung. Wenn etwas plötzlich nicht mehr funktioniert, verliert das Unternehmen einfach Geld. Für einige Bereiche ist dies nicht kritisch, aber es ist oft wichtig, dass jemand die Verantwortung für das Produkt und seine Arbeit trägt. Dass es jederzeit möglich war, einen Anspruch geltend zu machen, und es wurde schnell gelöst.
Mit diesem Beitrag beenden wir das Jahr der Promsvyazbank auf Habré. In einem kurzen Video haben wir Neujahrswünsche für die Bewohner von Chabrowsk gesammelt: