Hallo Kollegen!

In der letzten Veröffentlichung des kommenden Jahres wollten wir Reinforcement Learning erwähnen - ein Thema, in das wir bereits ein
Buch übersetzen.
Überzeugen Sie sich selbst: Es gab einen elementaren Artikel mit Medium, in dem der Kontext des Problems beschrieben und der einfachste Algorithmus mit Implementierung in Python beschrieben wurde. Der Artikel hat mehrere Gifs. Und Motivation, Belohnung und die Wahl der richtigen Strategie auf dem Weg zum Erfolg sind Dinge, die für jeden von uns im kommenden Jahr äußerst nützlich sein werden.
Viel Spaß beim Lesen!
Verstärktes Lernen ist eine Form des maschinellen Lernens, bei der der Agent lernt, in der Umgebung zu handeln, Aktionen auszuführen und dadurch die Intuition zu entwickeln. Danach beobachtet er die Ergebnisse seiner Aktionen. In diesem Artikel werde ich Ihnen erklären, wie Sie das Problem des Lernens mit Verstärkung verstehen und formulieren und es dann in Python lösen können.
In letzter Zeit haben wir uns daran gewöhnt, dass Computer Spiele gegen Menschen spielen - entweder als Bots in Multiplayer-Spielen oder als Rivalen in Einzelspielen: beispielsweise in Dota2, PUB-G, Mario. Das Forschungsunternehmen
Deepmind machte
viel Aufhebens um die Neuigkeiten, als sein AlphaGo-Programm 2016 den südkoreanischen Meister 2016 besiegte. Wenn Sie ein begeisterter Spieler sind, können Sie von den fünf Spielen von Dota 2 OpenAI Five hören, bei denen Autos gegen Menschen kämpften und die besten Spieler in Dota2 in mehreren Spielen besiegten. (Wenn Sie an den Details interessiert sind, wird der Algorithmus
hier detailliert analysiert und untersucht, wie die Maschinen gespielt haben).

Die neueste Version von OpenAI Five
nimmt Roshan .
Beginnen wir also mit der zentralen Frage. Warum brauchen wir eine verstärkte Ausbildung? Wird es nur in Spielen verwendet oder ist es in realistischen Szenarien zur Lösung angewandter Probleme anwendbar? Wenn Sie zum ersten Mal ein Verstärkungstraining lesen, können Sie sich die Antwort auf diese Fragen einfach nicht vorstellen. In der Tat ist verstärktes Lernen eine der am weitesten verbreiteten und sich schnell entwickelnden Technologien auf dem Gebiet der künstlichen Intelligenz.
Hier einige Themenbereiche, in denen Lernsysteme zur Stärkung besonders gefragt sind:
- Unbemannte Fahrzeuge
- Spielebranche
- Robotik
- Empfehlungssysteme
- Werbung und Marketing
Überblick und Hintergrund des verstärkenden LernensWie hat sich das Lernphänomen mit Verstärkung entwickelt, als wir über so viele Methoden des maschinellen und tiefen Lernens verfügten? "Er wurde von Rich Sutton und Andrew Barto, Richs Forschungsleiter, erfunden, die ihm bei der Vorbereitung der Promotion geholfen haben." Das Paradigma nahm erstmals in den 1980er Jahren Gestalt an und war dann archaisch. Anschließend glaubte Rich, dass sie eine große Zukunft hatte und schließlich Anerkennung erhalten würde.
Verstärktes Lernen unterstützt die Automatisierung in der Umgebung, in der es bereitgestellt wird. Sowohl maschinelles als auch tiefes Lernen funktionieren ungefähr gleich - sie sind strategisch unterschiedlich angeordnet, aber beide Paradigmen unterstützen die Automatisierung. Warum entstand ein Verstärkungstraining?
Es erinnert sehr an den natürlichen Lernprozess, in dem der Prozess / das Modell agiert, und erhält Feedback darüber, wie sie es schafft, die Aufgabe zu bewältigen: gut und nicht.
Maschinelles und tiefes Lernen sind ebenfalls Trainingsoptionen, sie sind jedoch besser darauf zugeschnitten, Muster in den verfügbaren Daten zu identifizieren. Beim verstärkten Lernen hingegen werden solche Erfahrungen durch Versuch und Irrtum gewonnen. Das System findet nach und nach die richtigen Optionen oder das globale Optimum. Ein schwerwiegender zusätzlicher Vorteil des verstärkten Lernens besteht darin, dass in diesem Fall keine umfangreichen Trainingsdaten bereitgestellt werden müssen, wie dies beim Unterrichten mit einem Lehrer der Fall ist. Ein paar kleine Fragmente werden ausreichen.
Das Konzept des verstärkenden LernensStellen Sie sich vor, Sie bringen Ihren Katzen neue Tricks bei. Leider verstehen Katzen die menschliche Sprache nicht, sodass Sie ihnen nicht sagen können, was Sie mit ihnen spielen werden. Daher werden Sie anders handeln: Imitieren Sie die Situation, und die Katze wird versuchen, auf die eine oder andere Weise zu reagieren. Wenn die Katze so reagiert hat, wie Sie es wollten, gießen Sie Milch hinein. Verstehst du, was als nächstes passieren wird? In einer ähnlichen Situation wird die Katze erneut die gewünschte Aktion ausführen und dies mit noch größerer Begeisterung, in der Hoffnung, dass sie noch besser gefüttert wird. So findet das Lernen an einem positiven Beispiel statt; Wenn Sie jedoch versuchen, eine Katze mit negativen Anreizen zu „erziehen“, z. B. sie genau betrachten und die Stirn runzeln, lernt sie in solchen Situationen normalerweise nicht.
Verstärktes Lernen funktioniert ähnlich. Wir teilen der Maschine einige Eingaben und Aktionen mit und belohnen die Maschine dann abhängig von der Ausgabe. Unser oberstes Ziel ist es, die Belohnungen zu maximieren. Schauen wir uns nun an, wie das oben genannte Problem im Hinblick auf das verstärkte Lernen neu formuliert werden kann.
- Die Katze fungiert als "Agent", der der "Umwelt" ausgesetzt ist.
- Die Umgebung ist ein Heim oder ein Spielbereich, je nachdem, was Sie der Katze beibringen.
- Situationen, die sich aus dem Training ergeben, werden als „Zustände“ bezeichnet. Im Fall einer Katze sind Beispiele für Bedingungen, wenn die Katze "rennt" oder "unter das Bett kriecht".
- Agenten reagieren, indem sie Aktionen ausführen und von einem „Zustand“ in einen anderen wechseln.
- Nachdem sich der Status geändert hat, erhält der Agent je nach der von ihm ergriffenen Maßnahme eine „Belohnung“ oder eine „Geldstrafe“.
- "Strategie" ist eine Methode zur Auswahl einer Aktion, um die besten Ergebnisse zu erzielen.
Nachdem wir herausgefunden haben, was Bestärkungslernen ist, lassen Sie uns detailliert über die Ursprünge und die Entwicklung des Bestärkungslernens und des Tiefenverstärkungslernens sprechen, diskutieren, wie dieses Paradigma es uns ermöglicht, Probleme zu lösen, die für das Lernen mit oder ohne Lehrer unmöglich sind, und beachten Sie auch Folgendes Merkwürdige Tatsache: Derzeit wird die Google-Suchmaschine mithilfe von Algorithmen zum Lernen der Verstärkung optimiert.
Verständnis der Terminologie des VerstärkungslernensAgent und Umgebung spielen eine Schlüsselrolle im Verstärkungslernalgorithmus. Die Umgebung ist die Welt, in der der Agent überleben muss. Zusätzlich erhält der Agent verstärkende Signale von der Umgebung (Belohnung): Dies ist eine Zahl, die angibt, wie gut oder schlecht der aktuelle Zustand der Welt berücksichtigt werden kann. Der Zweck des Agenten ist es, die Gesamtbelohnung, den sogenannten "Gewinn", zu maximieren. Bevor Sie unsere ersten Verstärkungslernalgorithmen schreiben, müssen Sie die folgende Terminologie verstehen.

- Zustände : Ein Zustand ist eine vollständige Beschreibung einer Welt, in der kein einziges Fragment der Informationen, die diese Welt charakterisieren, fehlt. Es kann eine feste oder dynamische Position sein. Solche Zustände werden in der Regel in Form von Arrays, Matrizen oder Tensoren höherer Ordnung geschrieben.
- Aktion : Die Aktion hängt normalerweise von den Umgebungsbedingungen ab. In verschiedenen Umgebungen ergreift der Agent verschiedene Aktionen. Viele gültige Agentenaktionen werden in einem Bereich aufgezeichnet, der als "Aktionsbereich" bezeichnet wird. Normalerweise ist die Anzahl der Aktionen im Raum begrenzt.
- Umgebung : Dies ist der Ort, an dem der Agent existiert und mit dem er interagiert. Verschiedene Arten von Belohnungen, Strategien usw. werden für verschiedene Umgebungen verwendet.
- Belohnungen und Gewinne : Sie müssen die Belohnungsfunktion R ständig überwachen, wenn Sie mit Verstärkungen trainieren. Dies ist wichtig, wenn Sie einen Algorithmus einrichten, optimieren und wenn Sie aufhören zu lernen. Es hängt vom aktuellen Zustand der Welt, den gerade ergriffenen Maßnahmen und dem nächsten Zustand der Welt ab.
- Strategien : Eine Strategie ist eine Regel, nach der ein Agent die nächste Aktion auswählt. Der Satz von Strategien wird auch als "Gehirn" des Agenten bezeichnet.
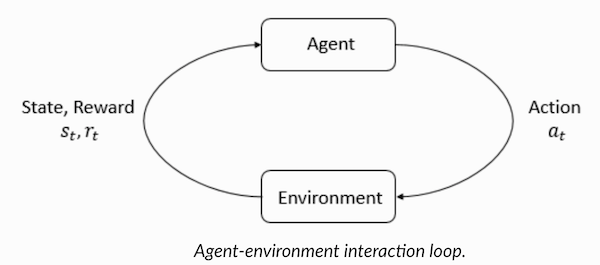
Nachdem wir uns mit der Terminologie des verstärkenden Lernens vertraut gemacht haben, lösen wir das Problem mithilfe der entsprechenden Algorithmen. Zuvor müssen Sie verstehen, wie ein solches Problem zu formulieren ist, und sich bei der Lösung dieses Problems auf die Terminologie des Trainings mit Verstärkung verlassen.
TaxilösungAlso lösen wir das Problem mithilfe von Verstärkungsalgorithmen.
Angenommen, wir haben eine Trainingszone für ein unbemanntes Taxi, die wir trainieren, um Passagiere an vier verschiedenen Punkten (
R,G,Y,B ) zum Parkplatz zu bringen. Vorher müssen Sie die Umgebung verstehen und festlegen, in der wir mit der Programmierung in Python beginnen. Wenn Sie gerade erst anfangen, Python zu lernen, empfehle ich
diesen Artikel für Sie .
Die Umgebung zum Lösen eines Problems mit einem Taxi kann mit
Gym von OpenAI konfiguriert werden - dies ist eine der beliebtesten Bibliotheken zum Lösen von Problemen mit dem Verstärkungstraining. Bevor Sie das Fitnessstudio verwenden, müssen Sie es auf Ihrem Computer installieren. Ein Python-Paketmanager namens pip ist hierfür geeignet. Das Folgende ist der Installationsbefehl.
pip install gymAls nächstes wollen wir sehen, wie unsere Umgebung angezeigt wird. Alle Modelle und die Schnittstelle für diese Aufgabe sind bereits im Fitnessstudio konfiguriert und unter
Taxi-V2 . Das folgende Codefragment wird verwendet, um diese Umgebung anzuzeigen.
„Wir haben 4 Standorte (durch verschiedene Buchstaben gekennzeichnet); Unsere Aufgabe ist es, einen Passagier an einem Punkt abzuholen und an einem anderen abzusetzen. Wir erhalten +20 Punkte für eine erfolgreiche Passagierlandung und verlieren 1 Punkt für jeden Schritt, der dafür ausgegeben wird. Es gibt auch eine Strafe von 10 Punkten für jedes unbeabsichtigte Ein- und Aussteigen eines Passagiers. (Quelle:
gym.openai.com/envs/Taxi-v2 )
Hier ist die Ausgabe, die wir in unserer Konsole sehen:

Taxi V2 ENV
Großartig,
env ist das Herz von OpenAi Gym, es ist eine einheitliche Umgebung. Die folgenden env-Methoden finden wir nützlich:
env.reset :
env.reset die Umgebung zurück und gibt einen zufälligen Anfangszustand zurück.
env.step(action) :
env.step(action) Entwicklung der Umwelt schrittweise.
env.step(action) :
env.step(action) die folgenden Variablen zurück
observation : Beobachtung der Umwelt.reward : reward ob Ihre Aktion von Vorteil war.done : Gibt an, ob es uns gelungen ist, den Passagier ordnungsgemäß aufzunehmen und abzusetzen, was auch als "eine Episode" bezeichnet wird.info : Zusätzliche Informationen wie Leistung und Latenz, die für Debugging-Zwecke benötigt werden.env.render : Zeigt einen Frame der Umgebung an (nützlich zum Rendern)
Nachdem wir die Umgebung untersucht haben, versuchen wir, das Problem besser zu verstehen. Taxis sind das einzige Auto auf diesem Parkplatz. Das Parken kann in ein
5x5 Raster unterteilt werden, in dem wir 25 mögliche Taxistandorte erhalten. Diese 25 Werte sind eines der Elemente unseres Zustandsraums. Bitte beachten Sie: Im Moment befindet sich unser Taxi am Punkt mit den Koordinaten (3, 1).
Es gibt 4 Punkte in der Umgebung, an denen Passagiere einsteigen dürfen: Dies sind:
R, G, Y, B oder
[(0,0), (0,4), (4,0), (4,3)] in Koordinaten ( horizontal; vertikal), wenn es möglich wäre, die obige Umgebung in kartesischen Koordinaten zu interpretieren. Wenn Sie auch einen weiteren (1) Zustand des Passagiers berücksichtigen: Innerhalb des Taxis können Sie alle Kombinationen von Passagierstandorten und deren Zielen berücksichtigen, um die Gesamtzahl der Zustände in unserer Umgebung für das Taxitraining zu berechnen: Wir haben vier (4) Ziele und fünf (4+) 1) Passagierstandorte.
In unserer Umgebung für ein Taxi gibt es also 5 × 5 × 5 × 4 = 500 mögliche Zustände. Ein Agent behandelt eine von 500 Bedingungen und ergreift Maßnahmen. In unserem Fall stehen folgende Optionen zur Verfügung: Bewegung in die eine oder andere Richtung oder Entscheidung, den Passagier abzuholen / abzusetzen. Mit anderen Worten, wir haben sechs mögliche Aktionen zur Verfügung:
Pickup, Drop, Nord, Ost, Süd, West (Die letzten vier Werte sind Richtungen, in die sich ein Taxi bewegen kann.)
Dies ist der
action space : Die Menge aller Aktionen, die unser Agent in einem bestimmten Status ausführen kann.
Wie aus der obigen Abbildung hervorgeht, kann ein Taxi in bestimmten Situationen bestimmte Aktionen nicht ausführen (Wände stören). In dem Code, der die Umgebung beschreibt, weisen wir einfach eine Strafe von -1 für jeden Treffer in der Wand und ein Taxi zu, das mit der Wand kollidiert. Daher werden sich solche Geldstrafen ansammeln, sodass das Taxi versucht, nicht gegen die Wände zu stoßen.
Belohnungstabelle: Beim Erstellen einer Taxi-Umgebung kann auch eine primäre Belohnungstabelle mit dem Namen P erstellt werden. Sie können sie als Matrix betrachten, wobei die Anzahl der Status der Anzahl der Zeilen und die Anzahl der Aktionen der Anzahl der Spalten entspricht. Das heißt, wir sprechen über die Matrix
states × actions .
Da absolut alle Bedingungen in dieser Matrix aufgezeichnet sind, können Sie die Standardbelohnungswerte anzeigen, die dem Status zugewiesen sind, den wir zur Veranschaulichung ausgewählt haben:
>>> import gym >>> env = gym.make("Taxi-v2").env >>> env.P[328] {0: [(1.0, 433, -1, False)], 1: [(1.0, 233, -1, False)], 2: [(1.0, 353, -1, False)], 3: [(1.0, 333, -1, False)], 4: [(1.0, 333, -10, False)], 5: [(1.0, 333, -10, False)] }
Die Struktur dieses Wörterbuchs ist wie folgt:
{action: [(probability, nextstate, reward, done)]} .
- Die Werte 0–5 entsprechen den Aktionen (Süd, Nord, Ost, West, Abholung, Rückgabe), die ein Taxi im in der Abbildung gezeigten aktuellen Zustand ausführen kann.
- Mit done können Sie beurteilen, wann wir den Passagier erfolgreich an der gewünschten Stelle abgesetzt haben.
Um dieses Problem ohne Training mit Verstärkung zu lösen, können Sie den Zielstatus festlegen, eine Auswahl von Feldern treffen und dann, wenn Sie den Zielstatus für eine bestimmte Anzahl von Iterationen erreichen können, davon ausgehen, dass dieser Moment der maximalen Belohnung entspricht. In anderen Staaten nähert sich der Wert der Belohnung entweder dem Maximum, wenn das Programm korrekt funktioniert (nähert sich dem Ziel) oder sammelt Geldstrafen, wenn es Fehler macht. Darüber hinaus kann der Wert der Geldbuße nicht unter -10 liegen.
Schreiben wir Code, um dieses Problem ohne Verstärkungstraining zu lösen.
Da wir für jeden Staat eine P-Tabelle mit Standardbelohnungswerten haben, können wir versuchen, die Navigation unseres Taxis nur anhand dieser Tabelle zu organisieren.
Wir erstellen eine Endlosschleife, in der gescrollt wird, bis der Passagier das Ziel erreicht (eine Episode) oder mit anderen Worten, bis die Belohnungsrate 20 erreicht. Die Methode
env.action_space.sample() wählt automatisch eine zufällige Aktion aus der Menge aller verfügbaren Aktionen aus . Überlegen Sie, was passiert:
import gym from time import sleep
Fazit:
Credits: OpenAI
Das Problem ist gelöst, aber nicht optimiert, oder dieser Algorithmus funktioniert nicht in allen Fällen. Wir benötigen einen geeigneten Interaktionsagenten, damit die Anzahl der von der Maschine / dem Algorithmus zur Lösung des Problems aufgewendeten Iterationen minimal bleibt. Hier hilft uns der Q-Learning-Algorithmus, dessen Implementierung wir im nächsten Abschnitt betrachten werden.
Einführung in Q-LearningIm Folgenden finden Sie den beliebtesten und einfachsten Algorithmus zum Erlernen von Verstärkungen. Die Umgebung belohnt den Agenten für die schrittweise Ausbildung und für die Tatsache, dass er in einem bestimmten Zustand den optimalsten Schritt unternimmt. In der oben diskutierten Implementierung hatten wir eine Belohnungstabelle "P", nach der unser Agent lernen wird. Basierend auf der Belohnungstabelle wählt er die nächste Aktion aus, je nachdem, wie nützlich sie ist, und aktualisiert dann einen anderen Wert, den Q-Wert. Als Ergebnis wird eine neue Tabelle erstellt, die als Q-Tabelle bezeichnet wird und in der Kombination angezeigt wird (Status, Aktion). Wenn die Q-Werte besser sind, erhalten wir optimierte Belohnungen.
Befindet sich ein Taxi beispielsweise in einem Zustand, in dem sich der Passagier am selben Punkt wie das Taxi befindet, ist es sehr wahrscheinlich, dass der Q-Wert für die Aktion „Abholen“ höher ist als für andere Aktionen, z. B. „Passagier absetzen“ oder „Nach Norden fahren“ ".
Q-Werte werden mit zufälligen Werten initialisiert. Wenn der Agent mit der Umgebung interagiert und durch Ausführen bestimmter Aktionen verschiedene Belohnungen erhält, werden die Q-Werte gemäß der folgenden Gleichung aktualisiert:

Dies wirft die Frage auf: Wie werden Q-Werte initialisiert und wie werden sie berechnet? Während Aktionen ausgeführt werden, werden Q-Werte in dieser Gleichung ausgeführt.
Hier sind Alpha und Gamma die Parameter des Q-Learning-Algorithmus. Alpha ist das Lerntempo und Gamma ist der Abzinsungsfaktor. Beide Werte können zwischen 0 und 1 liegen und sind manchmal gleich eins. Gamma kann gleich Null sein, Alpha jedoch nicht, da der Wert der Verluste während der Aktualisierung kompensiert werden muss (die Lernrate ist positiv). Der Alpha-Wert ist hier der gleiche wie beim Unterrichten mit einem Lehrer. Gamma bestimmt, wie wichtig wir die Belohnungen geben möchten, die uns in Zukunft erwarten.
Dieser Algorithmus ist unten zusammengefasst:
- Schritt 1: Initialisieren Sie die Q-Tabelle, füllen Sie sie mit Nullen und setzen Sie für Q-Werte beliebige Konstanten.
- Schritt 2: Lassen Sie den Agenten nun auf die Umgebung reagieren und verschiedene Aktionen ausprobieren. Für jede Zustandsänderung wählen wir eine aller in diesem Zustand möglichen Aktionen aus (S).
- Schritt 3: Gehen Sie basierend auf den Ergebnissen der vorherigen Aktion (a) zum nächsten Zustand (S ').
- Schritt 4: Wählen Sie für alle möglichen Aktionen aus dem Status (S ') eine mit dem höchsten Q-Wert aus.
- Schritt 5: Aktualisieren Sie die Werte der Q-Tabelle gemäß der obigen Gleichung.
- Schritt 6: Verwandeln Sie den nächsten Zustand in den aktuellen.
- Schritt 7: Wenn der Zielzustand erreicht ist, schließen wir den Vorgang ab und wiederholen ihn.
Q-Learning in Python import gym import numpy as np import random from IPython.display import clear_output
Großartig, jetzt werden alle Ihre Werte in der Variablen
q_table gespeichert.
Ihr Modell ist also unter Umgebungsbedingungen geschult und weiß jetzt, wie Passagiere genauer ausgewählt werden können. Sie haben das Phänomen des verstärkenden Lernens kennengelernt und können den Algorithmus so programmieren, dass ein neues Problem gelöst wird.
Andere Techniken des verstärkenden Lernens:
- Markov-Entscheidungsprozesse (MDP) und Bellman-Gleichungen
- Dynamische Programmierung: Modellbasierte RL, Strategieiteration und Wertiteration
- Tiefes Q-Training
- Strategie Gradientenabstiegsmethoden
- Sarsa
Der Code für diese Übung befindet sich unter:
Vihar / Python-Verstärkung-Lernen