Wir bei OpenAI haben festgestellt, dass die Gradientenrauschskala, eine einfache statistische Methode, die Parallelisierbarkeit des Lernens eines neutralen Netzwerks für eine Vielzahl von Aufgaben vorhersagt. Da der Gradient bei komplexeren Aufgaben normalerweise lauter wird, wird sich eine Vergrößerung der für die gleichzeitige Verarbeitung verfügbaren Pakete in Zukunft als nützlich erweisen und eine der potenziellen Einschränkungen von KI-Systemen beseitigen. Im allgemeinen Fall zeigen diese Ergebnisse, dass das Training neuronaler Netze nicht als mysteriöse Kunst betrachtet werden sollte und dass es genau und systematisiert werden kann.
In den letzten Jahren war es KI-Forschern zunehmend gelungen, das Lernen neuronaler Netze durch Parallelisierung von Daten zu beschleunigen und große Datenpakete in mehrere Computer aufzuteilen. Forscher haben erfolgreich Zehntausende von Einheiten für
die Bildklassifizierung und
Sprachmodellierung und sogar für Millionen
von verstärkenden Lernagenten verwendet , die Dota 2 gespielt haben. Solche großen Pakete können die Rechenleistung erhöhen, die effektiv für das Unterrichten eines Modells erforderlich ist, und sind eins der Kräfte, die das
Wachstum im KI-
Training vorantreiben. Bei zu großen Datenpaketen nehmen die algorithmischen Rückgaben jedoch rapide ab, und es ist nicht klar, warum sich diese Einschränkungen für einige Aufgaben als größer und für andere als kleiner herausstellen.
 Die über Trainingsansätze gemittelte Gradientenrauschskalierung erklärt die Mehrheit (r 2 = 80%) der kritischen Variationen der Datenpaketgröße für verschiedene Probleme, die sich um sechs Größenordnungen unterscheiden. Die Paketgrößen werden anhand der Anzahl der Bilder, Token (für Sprachmodelle) oder Beobachtungen (für Spiele) gemessen.
Die über Trainingsansätze gemittelte Gradientenrauschskalierung erklärt die Mehrheit (r 2 = 80%) der kritischen Variationen der Datenpaketgröße für verschiedene Probleme, die sich um sechs Größenordnungen unterscheiden. Die Paketgrößen werden anhand der Anzahl der Bilder, Token (für Sprachmodelle) oder Beobachtungen (für Spiele) gemessen.Wir haben festgestellt, dass durch Messen der Gradientenrauschskala, einfache Statistiken, die das Signal-Rausch-Verhältnis in den Gradienten des Netzwerks numerisch bestimmen, wir die maximale Paketgröße ungefähr vorhersagen können. Heuristisch misst die Rauschskala die Variation von Daten aus Sicht des Modells (in einem bestimmten Trainingsstadium). Wenn die Rauschskala klein ist, wird paralleles Lernen mit einer großen Datenmenge schnell überflüssig, und wenn sie groß ist, können wir mit großen Datenmengen viel lernen.
Statistiken dieser Art werden häufig verwendet,
um die Größe der Stichprobe zu
bestimmen , und es wurde
vorgeschlagen, sie für tiefes Lernen zu verwenden , sie wurden jedoch nicht systematisch für das moderne Training neuronaler Netze verwendet. Wir haben diese Vorhersage für eine Vielzahl von maschinellen Lernaufgaben bestätigt, die in der obigen Grafik dargestellt sind, einschließlich Mustererkennung, Sprachmodellierung, Atari- und Dota-Spielen. Insbesondere haben wir neuronale Netze trainiert, um jedes dieser Probleme an Datenpaketen unterschiedlicher Größe zu lösen (wobei die Lerngeschwindigkeit für jedes von ihnen separat angepasst wurde), und die Lernbeschleunigung mit der durch die Rauschskala vorhergesagten verglichen. Da große Datenpakete häufig eine sorgfältige und kostspielige Anpassung oder einen speziellen Zeitplan für die Trainingsgeschwindigkeit erfordern, damit das Training effektiv ist und Sie die Obergrenze im Voraus kennen, können Sie beim Training neuer Modelle einen erheblichen Vorteil erzielen.
Wir fanden es nützlich, die Ergebnisse dieser Experimente als Kompromiss zwischen der tatsächlichen Trainingszeit und dem für das Training insgesamt erforderlichen Rechenaufwand (proportional zu den Geldkosten) zu visualisieren. Bei sehr kleinen Datenpaketen kann durch Verdoppeln der Paketgröße das Training ohne zusätzlichen Rechenaufwand doppelt so schnell durchgeführt werden (wir führen doppelt so viele einzelne Threads aus, die doppelt so schnell arbeiten). Bei sehr großen Datenmodellen beschleunigt die Parallelisierung das Lernen nicht. Die Kurve in der mittleren Biegung und die Gradientenrauschskala sagen voraus, wo genau die Biegung auftritt.
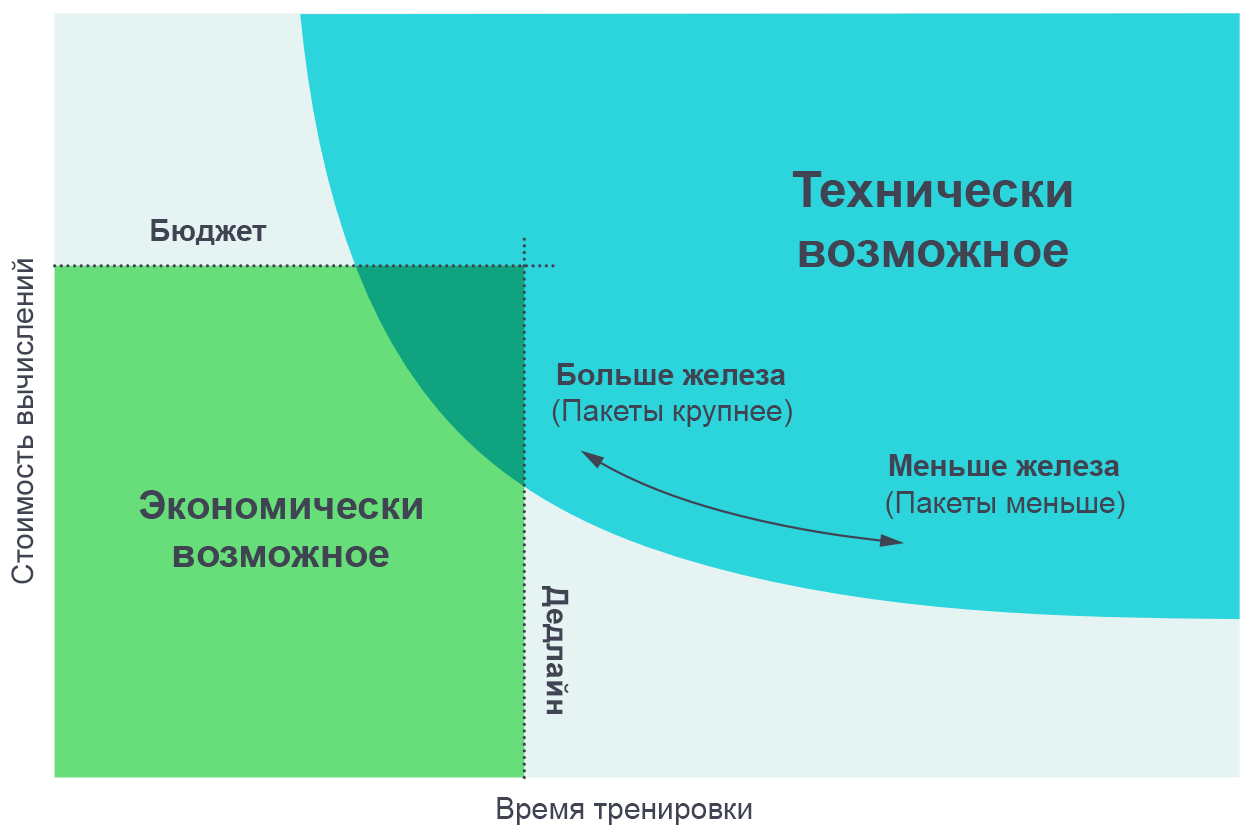 Durch Erhöhen der Anzahl paralleler Prozesse können Sie komplexere Modelle in angemessener Zeit trainieren. Das Pareto-Grenzdiagramm ist die intuitivste Möglichkeit, Vergleiche von Algorithmen und Skalen zu visualisieren.
Durch Erhöhen der Anzahl paralleler Prozesse können Sie komplexere Modelle in angemessener Zeit trainieren. Das Pareto-Grenzdiagramm ist die intuitivste Möglichkeit, Vergleiche von Algorithmen und Skalen zu visualisieren.Wir erhalten diese Kurven, indem wir der Aufgabe ein Ziel zuweisen (z. B. 1000 Punkte im Atari Beam Rider-Spiel) und beobachten, wie lange es dauert, das neuronale Netzwerk zu trainieren, um dieses Ziel bei verschiedenen Paketgrößen zu erreichen. Die Ergebnisse stimmen ziemlich genau mit den Vorhersagen unseres Modells überein, wobei die verschiedenen Werte der von uns gesetzten Ziele berücksichtigt werden.
[
Die Seite mit dem Originalartikel enthält interaktive Grafiken eines Kompromisses zwischen Erfahrung und Trainingszeit, die zur Erreichung eines bestimmten Ziels erforderlich sind. ]
Muster der Gradientenrauschskala
Wir sind auf verschiedene Muster in der Skala des Gradientenrauschens gestoßen, auf deren Grundlage wir Annahmen über die Zukunft des KI-Trainings treffen können.
Erstens nimmt in unseren Experimenten im Lernprozess die Rauschskala normalerweise um eine Größenordnung oder mehr zu. Anscheinend bedeutet dies, dass das Netzwerk zu Beginn des Trainings mehr „offensichtliche“ Merkmale des Problems lernt und dann die kleineren Details untersucht. Beispielsweise kann ein neuronales Netzwerk bei der Klassifizierung von Bildern zunächst lernen, Merkmale in kleinem Maßstab wie die auf den meisten Bildern gezeigten Kanten oder Texturen zu identifizieren und diese kleinen Dinge erst später miteinander zu vergleichen, um allgemeinere Konzepte wie Katzen oder Hunde zu erstellen. Um sich ein Bild von der ganzen Vielfalt der Gesichter und Texturen zu machen, müssen neuronale Netze eine kleine Anzahl von Bildern sehen, damit die Rauschskala kleiner ist. Sobald das Netzwerk mehr über größere Objekte weiß, kann es viel mehr Bilder gleichzeitig verarbeiten, ohne doppelte Daten zu berücksichtigen.
Wir haben einige
vorläufige Hinweise gesehen, dass ein ähnlicher Effekt auch bei anderen Modellen mit demselben Datensatz funktioniert - bei leistungsstärkeren Modellen ist die Gradientenrauschskala höher, jedoch nur, weil sie weniger Verluste aufweisen. Daher gibt es Hinweise darauf, dass die Erhöhung des Rauschmaßstabs während des Trainings nicht nur ein Konvergenzartefakt ist, sondern auch auf eine Verbesserung des Modells zurückzuführen ist. Wenn ja, dann können wir erwarten, dass zukünftige, verbesserte Modelle ein großes Maß an Rauschen aufweisen und besser für die Parallelisierung geeignet sind.
Zweitens lassen sich objektiv komplexere Aufgaben besser parallelisieren. Im Zusammenhang mit dem Unterrichten mit einem Lehrer sind beim Übergang von MNIST zu SVHN und ImageNet offensichtliche Fortschritte zu verzeichnen. Im Rahmen des Verstärkungstrainings sind beim Übergang von Atari Pong zu
Dota 1v1 und
Dota 5v5 deutliche Fortschritte zu
verzeichnen , und die Größe des optimalen Datenpakets variiert 10.000-mal. Da die KI immer komplexere Aufgaben bewältigt, wird erwartet, dass Modelle immer größere Datenmengen bewältigen.
Die Folgen
Der Grad der Datenparallelisierung beeinflusst die Geschwindigkeit der Entwicklung von KI-Fähigkeiten erheblich. Durch die Beschleunigung des Lernens können leistungsfähigere Modelle erstellt und die Forschung beschleunigt werden, sodass Sie die Zeit für jede Iteration verkürzen können.
In einer früheren Studie, „
KI und Berechnungen “, haben wir gesehen, dass sich die Berechnungen für das Training der größten Modelle alle 3,5 Monate verdoppeln, und festgestellt, dass dieser Trend auf einer Kombination aus Wirtschaftlichkeit (dem Wunsch, Geld für Berechnungen auszugeben) und algorithmischen Fähigkeiten zur Parallelisierung des Lernens beruht . Der letzte Faktor (algorithmische Parallelisierbarkeit) ist schwieriger vorherzusagen, und seine Grenzen wurden noch nicht vollständig untersucht. Unsere aktuellen Ergebnisse sind jedoch ein Fortschritt in der Systematisierung und im numerischen Ausdruck. Insbesondere haben wir Hinweise darauf, dass komplexere Aufgaben oder leistungsfähigere Modelle, die auf eine bekannte Aufgabe abzielen, eine parallelere Arbeit mit Daten ermöglichen. Dies wird ein Schlüsselfaktor sein, der das exponentielle Wachstum des lernbezogenen Rechnens unterstützt. Und wir berücksichtigen nicht einmal die
jüngsten Entwicklungen auf dem Gebiet der parallelen Modelle, die es uns ermöglichen, die Parallelisierung weiter zu verbessern, indem wir sie der vorhandenen parallelen Datenverarbeitung hinzufügen.
Das anhaltende Wachstum des Bereichs des Trainingscomputers und seine vorhersehbare algorithmische Basis sprechen für die Möglichkeit einer explosiven Steigerung der Fähigkeiten der KI in den nächsten Jahren und unterstreichen die Notwendigkeit einer frühzeitigen
Untersuchung des sicheren und
verantwortungsvollen Einsatzes solcher Systeme. Die Hauptschwierigkeit bei der Erstellung einer KI-Politik wird darin bestehen, zu entscheiden, wie solche Maßnahmen zur Vorhersage der Merkmale künftiger KI-Systeme verwendet werden können, und dieses Wissen zu nutzen, um Regeln zu erstellen, die es der Gesellschaft ermöglichen, ihren Nutzen zu maximieren und den Schaden dieser Technologien zu minimieren.
OpenAI plant eine strenge Analyse, um die Zukunft der KI vorherzusagen und die durch diese Analyse aufgeworfenen Herausforderungen proaktiv anzugehen.