
Es war einmal, als der Himmel blau war, das Gras grüner und Dinosaurier durchstreiften die Erde ... Nein, vergessen Sie Dinosaurier. Nun, im Allgemeinen kam mir einmal die Idee, von der Standard-Webprogrammierung abzulenken und etwas Verrückteres zu tun. Könnte natürlich alles sein, aber die Wahl fiel darauf, einen eigenen Dolmetscher zu schreiben. Was soll ich sagen ...
Schreiben Sie niemals Ihre eigenen Programmiersprachen . Aber ich habe einige Erfahrungen daraus gemacht und beschlossen, sie zu teilen. Beginnen wir mit dem Fundament - dem Lexer.
Vorwort
Bevor Sie verstehen, was für ein Tier "Lexer" ist, sollten Sie herausfinden, woraus YaPs bestehen.
In der modernen Welt ist jeder Compiler / Interpreter / Transpiler / etwas anderes (ich nenne es einfach weiter "Compiler", ohne Unterscheidung zwischen Typen) in zwei Teile unterteilt. In der Terminologie der intelligenten Onkel werden solche Teile als "Frontend" und "Backend" bezeichnet. Nein, das ist überhaupt nicht das, was wir bei der Arbeit mit dem Web genannt haben, und die Vorderseite ist nicht in JS mit HTML geschrieben. Obwohl ... Okay.
Die erste Aufgabe des Frontends besteht darin, den
Text in einen
AST (abstrakten Syntaxbaum) umzuwandeln und dabei die Syntax (und manchmal auch die Semantik) zu überprüfen. Die Aufgabe des zweiten Backends ist es, alles zum Laufen zu bringen. Wenn der Code im Interpreter zusammengestellt ist, erstellt der AST einen Befehlssatz für den virtuellen Prozessor (virtuelle Maschine), wenn der Compiler, dann den Befehlssatz für den realen Prozessor. Im Leben ist alles ziemlich komplizierter und kann möglicherweise nicht so implementiert werden. Zum Beispiel ist im Fall des GCC-Compilers alles durcheinander, aber Clang ist bereits kanonischer, LLVM ist ein typischer Vertreter des „Backends“ für Compiler.
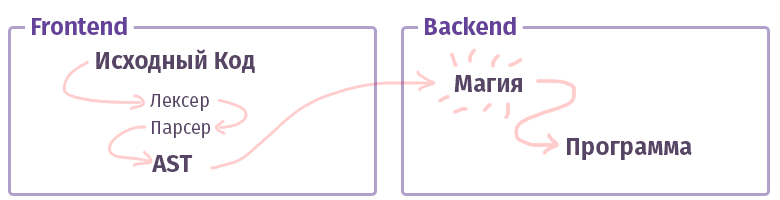
Jetzt lernen wir ein Stück namens Frontend kennen.
Lexikalische Analyse
Die Aufgabe des Lexers und die Phase der lexikalischen Analyse besteht darin, viele, viele Buchstaben am Eingang zu erhalten und sie in einige Kategorien zu gruppieren - „Token“. Daher wird die lexikalische Analyse auch als "Tokenisierung" bezeichnet. Dies ist die allererste Stufe der Textverarbeitung, die jeder vorhandene Compiler erstellt.
So etwas wie das:
$tokens = ['class', '\w+', '}', '{']; var_dump(lex('class Example {}', $tokens));
Übrigens haben wir hier bereits eine Reihe von Werkzeugen geschrieben, um das Leben leichter zu machen. Die gleichen
Preg- Funktionen, die wir zum Parsen von Text verwendet haben, sind
für diese Aufgabe durchaus
geeignet . Es gibt jedoch bequemere Werkzeuge für diese Angelegenheit:
- Phlexy , geschrieben von Nikita Popov.
- Hoa ist ein Toolkit bestehend aus Lexer + Parser + Grammatik.
- Port Yacc , geschrieben von Anthony Ferrara, das ebenfalls ein umfassendes Toolkit ist und auf dem der bekannte Popov- PHP-Parser geschrieben ist, ist in Tools anwendbar, die Code-Analyse verwenden.
- Railt Lexer meine Implementierung für PHP 7.1+
- Parle ist eine Erweiterung für PHP, die eine begrenzte Anzahl von PCRE-Ausdrücken zulässt (kein Lookahead und einige andere Syntaxkonstrukte).
- Und schließlich die Standard-PHP-Funktion token_get_all , die direkt für die lexikalische Analyse von PHP vorgesehen ist.
Nun, es ist klar, dass es viele Dinge gibt, die Text durch Token teilen können. Vielleicht habe ich sogar etwas vergessen, wie den
Doctrine Lexer. Aber wie geht es weiter?
Arten von Lexern
Und wie immer ist nicht alles so einfach, wie es schien. Es gibt mindestens zwei verschiedene Kategorien von Lexern. Es gibt die übliche, ziemlich triviale Option, nach der Sie die Regeln verschieben, und die bereits alles in Token unterteilt. Die Konfiguration unterscheidet sich nicht wesentlich von dem oben gezeigten Beispiel. Es gibt jedoch eine andere Option namens
Multistate . Solche Lexer sind etwas schwieriger zu verstehen, deshalb möchte ich etwas mehr über sie sprechen.
Die Aufgabe eines Multistate-Lexers besteht darin, je nach vorherigem Status verschiedene Token anzuzeigen. Nun, zum Beispiel werden in PHP solche "Übergangszustände" unter Verwendung der <? Php +?> -Tags, innerhalb von Zeilen, Kommentaren und
HEREDOC /
NOWDOC- Konstrukten gebildet.
Erinnern Sie sich an das vorherige Beispiel mit 4 Token oben? Lassen Sie es uns ein wenig modifizieren, um zu verstehen, was diese Zustände sind:
class Example {
In diesem Fall erhalten wir den folgenden Satz von Token, wenn wir den einfachsten Lexer ohne die umfassenden Funktionen von PCRE haben:
var_dump(lex(...));
Wie Sie sehen können, haben wir einen völlig banalen Pfosten zu den Elementen 3-5 erhalten: Der Kommentar wurde ziemlich unerwartet empfangen und in Token unterteilt, obwohl er als ganzes Stück hätte betrachtet werden sollen.
Natürlich könnte mit der PCRE-Funktion ein solches Token mit Hilfe einer einfachen Regelmäßigkeit "
// [^ \ n] * \ n " herausgerissen werden, aber wenn nicht? Oder wollen wir es mit unseren Händen zertrümmern? Kurz gesagt, im Fall des mehrstufigen Lexers können wir sagen, dass sich alle Token in Gruppe
Nr. 1 befinden sollten , sobald das Token "
// " gefunden wird, sollte ein Übergang zu Gruppe
Nr .
2 erfolgen. Und innerhalb der zweiten Gruppe der umgekehrte Übergang, wenn das Token "
\ n " gefunden wird - der Übergang zurück zur ersten Gruppe.
So etwas wie das:
$tokens = [ 'group-1' => [ 'class', '\w+', '{', '}', '//' => 'group-2'
Ich denke, jetzt wird klarer, wie HEREDOC analysiert wird, denn trotz aller Möglichkeiten von PCRE ist das Schreiben eines Regulars für diesen Fall äußerst problematisch, da diese HEREDOC-Syntax die variable Interpolation unterstützt. Versuchen Sie einfach, so etwas mit der
integrierten Funktion
token_get_all zu analysieren (Hinweis> 12 Token):
<?php $example = 42; $a = <<<EOL Your answer is $example !!! EOL; var_dump(token_get_all(file_get_contents(__FILE__)));
Nun, es scheint, wir sind bereit zu üben.
Übe
Erinnern wir uns, was wir in PHP für solche Dinge haben? Na klar, preg_match! Okay, komm runter. Der preg_match-basierte Algorithmus ist in
Hoa und
in dieser Implementierung von Phelxy implementiert . Ihre Aufgabe ist ganz einfach:
- Wir haben den Quelltext und eine Reihe von Stammgästen zur Hand.
- Wir passen zusammen, bis etwas Passendes gefunden ist.
- Sobald Sie ein Stück gefunden haben, schneiden Sie es aus dem Text aus und passen Sie es weiter an.
In Codeform sieht es ungefähr so aus:
Codeblatt <?php class SimpleLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[$name] = \sprintf('/\G%s/isSum', $definition); } } public function lex(string $sources): iterable { [$offset, $length] = [0, \strlen($sources)]; while ($offset < $length) { [$name, $token] = $this->next($sources, $offset); yield $name => $token; $offset += \strlen($token); } } private function next(string $sources, int $offset): array { foreach ($this->tokens as $name => $pcre) { \preg_match($pcre, $sources, $matches, 0, $offset); $token = \reset($matches); if (\count($matches) && \strpos($sources, $token, $offset) === $offset) { return [$name, $token]; } } throw new \RuntimeException('Unrecognized token at offset ' . $offset); } }
Verwenden eines Codeblatts $lexer = new SimpleLexer([ 'T_CLASS' => 'class', 'T_CONST' => '\w+', 'T_BRACE_OPEN' => '{', 'T_BRACE_CLOSE' => '}', 'T_WHITESPACE' => '\s+', ]); echo \sprintf('| %-10s | %-20s |', 'VALUE', 'NAME') . "\n"; foreach ($lexer->lex('class Example {}') as $name => $token) { echo \sprintf('| %-10s | %-20s |', '"' . \trim($token, "\n") . '"', $name) . "\n"; }
Dieser Ansatz ist ziemlich trivial und ermöglicht ein paar Tastendrücke, um den Lexer im Bereich der next () -Methode zu modifizieren, einen Übergang zwischen Zuständen hinzuzufügen und dieses Stück Masturbation in einen primitiven mehrstufigen Lexer zu verwandeln.
Fügen Sie im Bereich $ this-> tokens einfach so etwas wie
$ this-> tokens [$ this-> state] hinzu .
Zusätzlich zum Primitivismus selbst gibt es jedoch einen weiteren Nachteil, der nicht fatal ist, wie sich herausstellen könnte, aber dennoch ... Eine solche Implementierung ist unglaublich langsam. Auf i7 7600k, dessen Besitzer ich zufällig war - ein ähnlicher Algorithmus verarbeitet ungefähr 400 Token pro Sekunde und mit einer Zunahme ihrer Variationen (dh der Definitionen, die wir an den Konstruktor weitergegeben haben) - kann er sich auf die Geschwindigkeit des Präsidentenwechsels in Russland verlangsamen ... ähm Entschuldigung. Ich wollte natürlich sagen, dass es
sehr langsam funktionieren
wird .
Okay, was können wir tun? Für den Anfang können Sie verstehen, was falsch läuft. Tatsache ist, dass jedes Mal, wenn wir
preg_match in der Wildnis der Sprache aufrufen, ein Compiler mit seiner JIT namens PCRE aufsteigt (und mit PHP 7.3 ist PCRE2 bereits vorhanden). Jedes Mal analysiert er die Stammgäste selbst und sammelt einen Parser für sie, mit dem wir den Text analysieren, um Token zu erstellen. Es klingt etwas seltsam und tautologisch. Kurz gesagt, jedes Token erfordert eine Kompilierung von 1 bis N Stammgästen, wobei N die Anzahl der Definitionen dieser Token ist. Gleichzeitig ist anzumerken, dass selbst das angewendete "
S " -Flag und die Optimierung mit "
\ G " im Konstruktor, in dem reguläre Ausdrücke für Token generiert werden, nicht helfen.
Es gibt nur einen Ausweg aus dieser Situation - Sie müssen den gesamten Text in einem Durchgang analysieren, d. H. durch Ausführen nur einer
preg_match- Funktion. Es bleiben zwei Probleme zu lösen:
- Wie kann angezeigt werden, dass das Ergebnis des regulären Ausdrucks N1 dem Token N2 entspricht? Das heißt, wie man angibt, dass " \ w + " zum Beispiel T_CONST ist .
- So bestimmen Sie die Reihenfolge der Token als Ergebnis. Wie Sie wissen, enthält das Ergebnis von preg_match oder preg_match_all alles durcheinander. Und selbst mit Hilfe von Flaggen, die als viertes Argument übergeben wurden, wird sich die Situation nicht ändern.
Hier können Sie innehalten und ein wenig nachdenken. Gut oder nicht.
Die Lösung für das erste Problem heißt
PCRE-Gruppen , die auch als "Submasken" bezeichnet werden. Mit den Regeln: "
(? <T_WHITESPACE> \ s + | <T_WORD> \ w + | ...) " können Sie alle Token in einem Durchgang erhalten, indem Sie sie mit ihren Namen vergleichen. Als Ergebnis der Übereinstimmung wird ein assoziatives Array gebildet, das aus den Paaren "
[TOKEN_NAME => TOKEN_VALUE] " besteht.
Der zweite ist etwas komplizierter. Hier können Sie jedoch einen taktischen Trick anwenden und die Funktion
preg_replace_callback verwenden. Seine Besonderheit ist, dass die als zweites Argument übergebene Anonymität für jedes Token vom ersten bis zum letzten streng nacheinander aufgerufen wird.
Um nicht zu schmachten - die Implementierung ist wie folgt:
Noch eine Codeklappe class PregReplaceLexer { private $tokens = []; public function __construct(array $tokens) { foreach ($tokens as $name => $definition) { $this->tokens[] = \sprintf('(?<%s>%s)', $name, $definition); } } public function lex(string $sources): iterable { $result = []; \preg_replace_callback($this->compilePcre(), function (array $matches) use (&$result) { foreach (\array_reverse($matches) as $name => $value) { if (\is_string($name) && $value !== '') { $result[] = [$name, $value]; break; } } }, $sources); foreach ($result as [$name, $value]) { yield $name => $value; } } private function compilePcre(): string { return \sprintf('/\G(?:%s)/isSum', \implode('|', $this->tokens)); } }
Und seine Verwendung unterscheidet sich nicht von der vorherigen Version. Gleichzeitig erhöht sich die Arbeitsgeschwindigkeit von
400 auf
57.000 Token pro Sekunde. Diesen Algorithmus habe ich
in meiner Implementierung angewendet und das Umschreiben des Hoa-Quellcodes übernommen. Wenn Sie Parle verwenden, können Sie übrigens bis zu
600.000 Token pro Sekunde drücken. Und das Gesamtbild sieht ungefähr so aus (wenn XDebug in PHP 7.1 aktiviert ist, sind die Zahlen niedriger, aber das Verhältnis kann grob dargestellt werden).
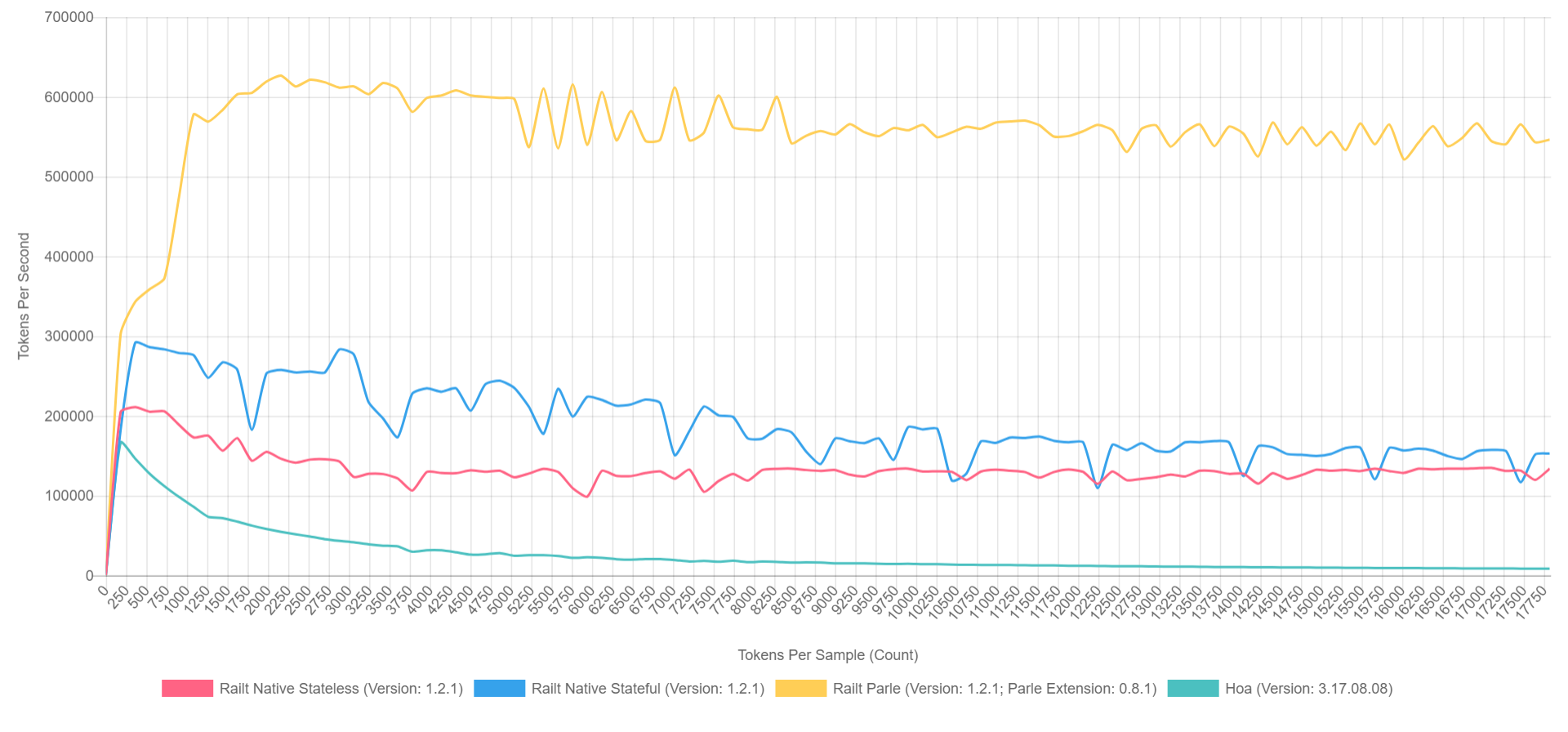
- Gelb ist die native Erweiterung von Parle.
- Blau - Implementierung durch preg_replace_callback mit vormontiertem Regular.
- Rot - egal , aber mit der generierten Regelmäßigkeit während des Aufrufs von preg_replace_callback .
- Grün - Implementierung durch preg_match .
Warum?
Nun, das alles ist natürlich wunderbar, aber die Ungeduldigen wollen unbedingt die Frage stellen: "Wer braucht das überhaupt?" In der abstrakten Welt von PHP, in der das Prinzip "fig-fig-and-site-ready" dominiert - solche Bibliotheken werden nicht benötigt, werden wir ehrlich sein. Wenn wir jedoch über das Ökosystem als Ganzes sprechen, können wir uns an die berüchtigten Bibliotheken wie
Symfony / Yaml oder
Doctrine erinnern. Anmerkungen in Symfony sind dieselbe Untersprache in PHP und erfordern eine separate lexikalische und syntaktische Analyse. Darüber hinaus gibt es in PHP noch etwas weniger bekannte CoffeeScript-, Less- und Scss / Sass-Transpiler. Nun, oder
Yay und
Vorverarbeitung basierend darauf. Ich werde nicht einmal Code-Analyse-Tools wie phpmd oder phpcs erwähnen. Und Dokumentationsgeneratoren wie phpDocumentnor oder Sami sind ziemlich trivial. Jedes dieser Projekte verwendet bis zu dem einen oder anderen Grad eine lexikalische Analyse in der ersten Phase des Parsens von Text / Code.
Dies ist keine vollständige Liste der Projekte, und vielleicht hoffe ich, dass meine Geschichte Ihnen hilft, etwas Neues zu entdecken und es wieder aufzufüllen.
Nachwort
Wenn sich jemand für das Thema Parser und Compiler interessiert, gibt es in der Zukunft einige interessante Berichte zu diesem Thema, insbesondere von den Jungs von JetBrains:
Trotzdem natürlich die meisten Aufführungen von Andrei Breslav (
abreslav ), die auf der Weite von YouTube zu finden sind - ich rate Ihnen, sie anzuschauen.
Nun, für Fans von Belletristik
gibt es eine solche Ressource , die für mich persönlich äußerst nützlich war.
Post post scriptum. Wenn Sie irgendwo in der Weite dieses Epos versiegelt sind, können Sie den Autor sicher in jeder für Sie geeigneten Form informieren.
Als Bonus möchte ich
ein Beispiel für einen einfachen PHP-Lexer geben . Es scheint, dass es jetzt nicht so beängstigend ist und jetzt sogar klar ist, was es tut, oder? Obwohl wen ich täusche, bluten die Augen von den Stammgästen. =)
Vielen Dank!