Der erste Dienst in Nomad I wurde im September 2016 gestartet. Im Moment benutze ich es als Programmierer und unterstütze als Administrator von zwei Nomad-Clustern - ein "Zuhause" für meine persönlichen Projekte (6 mikro-virtuelle Maschinen in Hetzner Cloud und ArubaCloud in 5 verschiedenen Rechenzentren in Europa) und das zweite funktionierende (ungefähr 40 private virtuelle und physische Server) in zwei Rechenzentren).
In der letzten Zeit wurde viel Erfahrung mit der Nomad-Umgebung gesammelt. In dem Artikel werde ich die Probleme beschreiben, auf die Nomad stößt, und wie man damit umgeht.

Yamal Nomad erstellt eine Continuous Delivery-Instanz Ihrer Software © National Geographic Russia
1. Die Anzahl der Serverknoten pro Rechenzentrum
Lösung: Ein Serverknoten reicht für ein Rechenzentrum.
In der Dokumentation wird nicht explizit angegeben, wie viele Serverknoten in einem Rechenzentrum erforderlich sind. Es wird nur angegeben, dass 3-5 Knoten pro Region benötigt werden, was für den Raft-Protokoll-Konsens logisch ist.
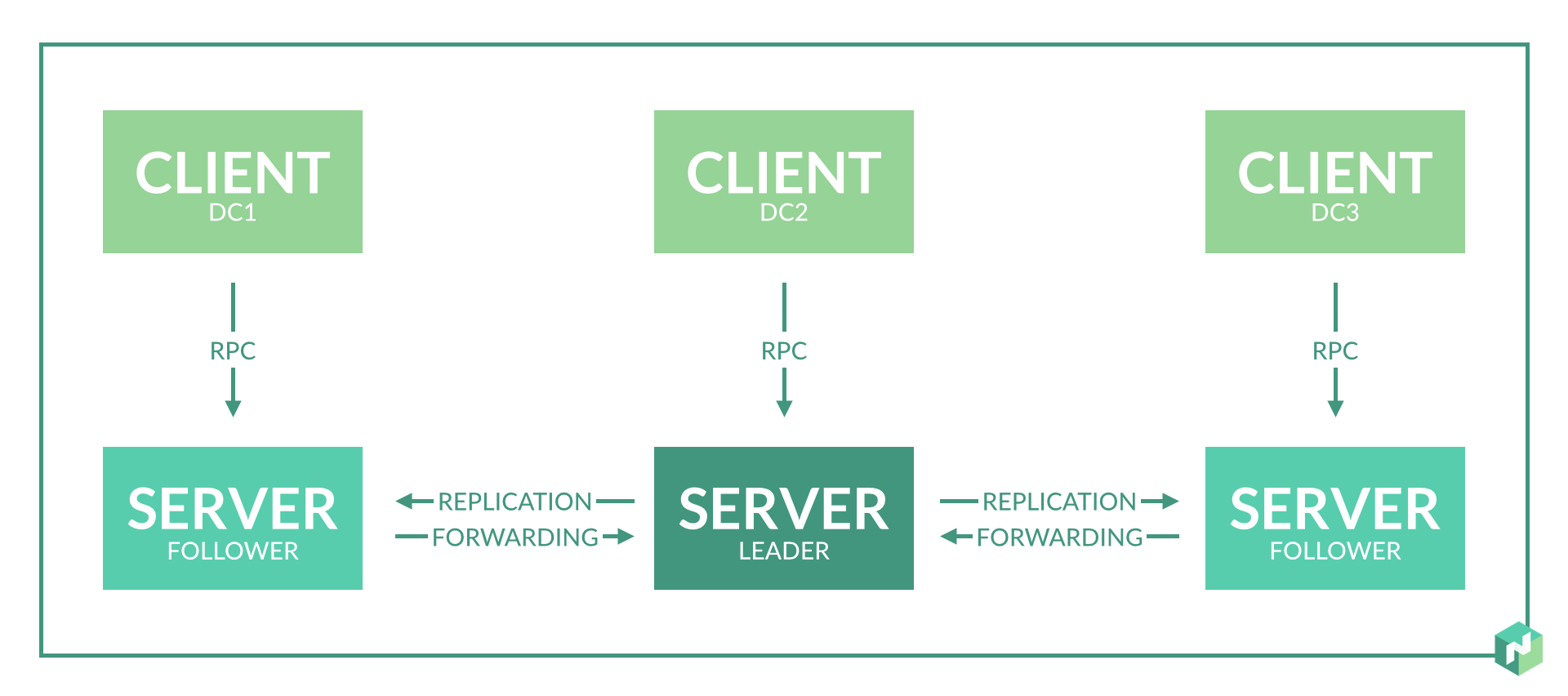
Am Anfang plante ich 2-3 Serverknoten in jedem Rechenzentrum, um Redundanz zu gewährleisten.
Bei Gebrauch stellte sich heraus:
- Dies ist einfach nicht erforderlich, da bei einem Knotenausfall im Rechenzentrum die Rolle des Serverknotens für die Agenten in diesem Rechenzentrum von anderen Serverknoten in der Region gespielt wird.
- Es wird noch schlimmer, wenn Problem 8 nicht gelöst ist. Wenn der Assistent wiedergewählt wird, können Inkonsistenzen auftreten und Nomad startet einen Teil der Dienste neu.
2. Serverressourcen für den Serverknoten
Lösung: Eine kleine virtuelle Maschine reicht für den Serverknoten. Auf demselben Server dürfen andere nicht ressourcenintensive Dienste ausgeführt werden.
Der Speicherverbrauch des Nomad-Daemons hängt von der Anzahl der ausgeführten Aufgaben ab. CPU-Verbrauch - basierend auf der Anzahl der Aufgaben und der Anzahl der Server / Agenten in der Region (nicht linear).
In unserem Fall: Für 300 ausgeführte Aufgaben beträgt der Speicherverbrauch für den aktuellen Masterknoten ca. 500 MB.
In einem funktionierenden Cluster eine virtuelle Maschine für einen Serverknoten: 4 CPU, 6 GB RAM.
Zusätzlich gestartet: Consul, Etcd, Vault.
3. Konsens über den Mangel an Rechenzentren
Lösung: Wir erstellen drei virtuelle Rechenzentren und drei Serverknoten für zwei physische Rechenzentren.
Die Arbeit von Nomad in der Region basiert auf dem Floßprotokoll. Für einen korrekten Betrieb benötigen Sie mindestens 3 Serverknoten in verschiedenen Rechenzentren. Dies ermöglicht einen korrekten Betrieb mit einem vollständigen Verlust der Netzwerkkonnektivität mit einem der Rechenzentren.
Wir haben aber nur zwei Rechenzentren. Wir machen einen Kompromiss: Wir wählen ein Rechenzentrum aus, dem wir mehr vertrauen, und machen darin einen zusätzlichen Serverknoten. Dazu führen wir ein zusätzliches virtuelles Rechenzentrum ein, das sich physisch im selben Rechenzentrum befindet (siehe Unterabsatz 2 von Problem 1).
Alternative Lösung: Wir unterteilen Rechenzentren in separate Regionen.
Infolgedessen funktionieren Rechenzentren unabhängig voneinander, und ein Konsens ist nur innerhalb eines Rechenzentrums erforderlich. In einem Rechenzentrum ist es in diesem Fall besser, drei Serverknoten zu erstellen, indem drei virtuelle Rechenzentren in einem physischen implementiert werden.
Diese Option ist für die Aufgabenverteilung weniger praktisch, bietet jedoch eine 100% ige Garantie für die Unabhängigkeit der Dienste bei Netzwerkproblemen zwischen Rechenzentren.
4. "Server" und "Agent" auf demselben Server
Lösung: Gültig, wenn Sie eine begrenzte Anzahl von Servern haben.
Laut Nomadendokumentation ist dies unerwünscht. Wenn Sie jedoch nicht die Möglichkeit haben, separate virtuelle Maschinen für Serverknoten zuzuweisen, können Sie die Server- und Agentenknoten auf demselben Server platzieren.
Gleichzeitiges Ausführen bedeutet, dass der Nomad-Daemon sowohl im Client- als auch im Servermodus gestartet wird.
Was bedroht das? Bei einer hohen Belastung der CPU dieses Servers funktioniert der Nomad-Serverknoten instabil, es kann zu einem Verlust des Konsenses und des Herzschlags sowie zum erneuten Laden von Diensten kommen.
Um dies zu vermeiden, erhöhen wir die Grenzen aus der Beschreibung von Problem Nr. 8.
5. Implementierung von Namespaces
Lösung: Möglicherweise durch die Organisation eines virtuellen Rechenzentrums.
Manchmal müssen Sie einen Teil der Dienste auf separaten Servern ausführen.
Die Lösung ist die erste, einfache, aber anspruchsvollere. Wir unterteilen alle Dienste nach ihrem Zweck in Gruppen: Frontend, Backend, ... Fügen Sie den Servern Metaattribute hinzu und schreiben Sie die Attribute vor, die für alle Dienste ausgeführt werden sollen.
Die zweite Lösung ist einfach. Wir fügen neue Server hinzu, schreiben ihnen Metaattribute vor, schreiben diese Startattribute den erforderlichen Diensten vor, alle anderen Dienste schreiben ein Startverbot für Server mit diesem Attribut vor.
Die dritte Lösung ist kompliziert. Wir erstellen ein virtuelles Rechenzentrum: Starten Sie Consul für ein neues Rechenzentrum, starten Sie den Nomad-Serverknoten für dieses Rechenzentrum, ohne die Anzahl der Serverknoten für diese Region zu vergessen. Jetzt können Sie einzelne Dienste in diesem dedizierten virtuellen Rechenzentrum ausführen.
6. Integration mit Vault
Lösung: Vermeiden Sie zirkuläre Abhängigkeiten von Nomad <-> Vault.
Der gestartete Tresor sollte keine Abhängigkeiten von Nomad haben. Die in Nomad registrierte Vault-Adresse sollte vorzugsweise direkt auf den Vault verweisen, ohne Schichten von Balancern (aber gültig). Die Tresorreservierung kann in diesem Fall über DNS - Consul DNS oder extern erfolgen.
Wenn Vault-Daten in die Nomad-Konfigurationsdateien geschrieben sind, versucht Nomad beim Start, auf Vault zuzugreifen. Wenn der Zugriff nicht erfolgreich ist, weigert sich Nomad zu starten.
Ich habe vor langer Zeit einen Fehler mit einer zyklischen Abhängigkeit gemacht, der den Nomad-Cluster einmal kurzzeitig fast vollständig zerstört hat. Vault wurde unabhängig von Nomad korrekt gestartet, aber Nomad überprüfte die Vault-Adresse über die Balancer, die in Nomad selbst ausgeführt wurden. Die Neukonfiguration und der Neustart der Nomad-Serverknoten führten zu einem Neustart der Balancer-Dienste, was dazu führte, dass die Serverknoten selbst nicht gestartet werden konnten.
7. Starten wichtiger staatlicher Dienste
Lösung: gültig, aber ich nicht.
Ist es möglich, PostgreSQL, ClickHouse, Redis Cluster, RabbitMQ, MongoDB über Nomad auszuführen?
Stellen Sie sich vor, Sie haben eine Reihe wichtiger Dienste, deren Arbeit mit den meisten anderen Diensten verbunden ist. Zum Beispiel eine Datenbank in PostgreSQL / ClickHouse. Oder allgemeine Kurzzeitspeicherung in Redis Cluster / MongoDB. Oder ein Datenbus in Redis Cluster / RabbitMQ.
Alle diese Dienste implementieren in irgendeiner Form ein fehlertolerantes Schema: Stolon / Patroni für PostgreSQL, eine eigene Raft-Implementierung in Redis Cluster, eine eigene Cluster-Implementierung in RabbitMQ, MongoDB, ClickHouse.
Ja, alle diese Dienste können über Nomad unter Bezugnahme auf bestimmte Server gestartet werden. Aber warum?
Plus - einfacher Start, ein einziges Skriptformat, wie bei anderen Diensten. Sie müssen sich keine Sorgen um ansible Skripte / irgendetwas anderes machen.
Minus ist ein zusätzlicher Fehlerpunkt, der keine Vorteile bringt. Persönlich habe ich den Nomad-Cluster aus verschiedenen Gründen zweimal vollständig gelöscht: einmal "zu Hause", einmal arbeiten. Dies war in den frühen Stadien der Einführung von Nomad und aufgrund von Schlamperei.
Außerdem verhält sich Nomad aufgrund von Problem Nummer 8 schlecht und startet die Dienste neu. Aber selbst wenn dieses Problem gelöst ist, bleibt die Gefahr bestehen.
8. Die Stabilisierung von Arbeit und Service wird in einem instabilen Netzwerk neu gestartet
Lösung: Verwenden Sie die Optionen zur Optimierung des Herzschlags.
Standardmäßig ist Nomad so konfiguriert, dass kurzfristige Netzwerkprobleme oder CPU-Auslastungen zu einem Konsensverlust und einer Wiederwahl des Assistenten führen oder den Agentenknoten als unzugänglich markieren. Dies führt zu spontanen Neustarts von Diensten und deren Übertragung auf andere Knoten.
Statistik des "Home" -Clusters vor Behebung des Problems: Die maximale Lebensdauer des Containers vor dem Neustart beträgt ca. 10 Tage. Hier wird es immer noch belastet, indem der Agent und der Server auf einem Server ausgeführt und in 5 verschiedenen Rechenzentren in Europa platziert werden, was eine große Belastung der CPU und ein weniger stabiles Netzwerk impliziert.
Statistik des Arbeitsclusters vor Behebung des Problems: Die maximale Lebensdauer des Containers vor dem Neustart beträgt mehr als 2 Monate. Aufgrund der separaten Server für die Nomad-Serverknoten und des hervorragenden Netzwerks zwischen den Rechenzentren ist hier alles relativ gut.
Standardwerte
heartbeat_grace = "10s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
Nach dem Code zu urteilen: In dieser Konfiguration werden alle 10 Sekunden Herzschläge ausgeführt. Mit dem Verlust von zwei Herzschlägen beginnt die Wiederwahl des Masters oder die Übertragung von Diensten vom Agentenknoten. Meiner Meinung nach umstrittene Einstellungen. Wir bearbeiten sie je nach Anwendung.
Wenn alle Dienste in mehreren Instanzen ausgeführt werden und von Rechenzentren verteilt werden, spielt es für Sie höchstwahrscheinlich keine Rolle, wie lange der Zugriff auf den Server bestimmt wird (im folgenden Beispiel etwa 5 Minuten). Wir machen das Heartbeat-Intervall weniger häufig und den Zeitraum für die Ermittlung der Unzugänglichkeit länger. Dies ist ein Beispiel für die Einrichtung meines Heimclusters:
heartbeat_grace = "300s" min_heartbeat_ttl = "30s" max_heartbeats_per_second = 10.0
Wenn Sie über eine gute Netzwerkkonnektivität, separate Server für Serverknoten und die Zeitspanne für die Feststellung der Unzugänglichkeit von Servern verfügen (in einer Instanz wird ein Dienst ausgeführt und es ist wichtig, ihn schnell zu übertragen), verlängern Sie die Zeitspanne für die Feststellung der Unzugänglichkeit (heartbeat_grace). Optional können Sie mehr Herzschläge ausführen (indem Sie min_heartbeat_ttl verringern) - dies erhöht die CPU-Belastung geringfügig. Beispiel für eine funktionierende Clusterkonfiguration:
heartbeat_grace = "60s" min_heartbeat_ttl = "10s" max_heartbeats_per_second = 50.0
Diese Einstellungen beheben das Problem vollständig.
9. Starten Sie regelmäßige Aufgaben
Lösung: Periodische Nomadendienste können verwendet werden, aber cron ist für den Support bequemer.
Nomad kann den Dienst regelmäßig starten.
Das einzige Plus ist die Einfachheit dieser Konfiguration.
Das erste Minus ist, dass wenn der Dienst häufig gestartet wird, die Liste der Aufgaben verschmutzt wird. Beispielsweise werden beim Start alle 5 Minuten stündlich 12 zusätzliche Aufgaben zur Liste hinzugefügt, bis der GC Nomad ausgelöst wird, wodurch alte Aufgaben gelöscht werden.
Das zweite Minus - es ist nicht klar, wie die Überwachung eines solchen Dienstes richtig konfiguriert werden kann. Wie kann man verstehen, dass ein Dienst beginnt, sich erfüllt und seine Arbeit bis zum Ende erledigt?
Infolgedessen kam ich für mich zur "Cron" -Implementierung periodischer Aufgaben:
- Es kann ein normaler Cron in einem ständig laufenden Container sein. Cron führt regelmäßig ein bestimmtes Skript aus. Ein Skript-Healthcheck kann einfach zu einem solchen Container hinzugefügt werden, der jedes Flag überprüft, das ein laufendes Skript erstellt.
- Es kann sich um einen ständig laufenden Container mit einem ständig laufenden Dienst handeln. Innerhalb des Dienstes wurde bereits ein periodischer Start implementiert. Zu einem solchen Dienst, der den Status sofort anhand seiner "Innenseiten" überprüft, kann problemlos ein ähnlicher Script-Healthcheck oder ein http-Healthcheck hinzugefügt werden.
Momentan schreibe ich die meiste Zeit in Go. Ich bevorzuge die zweite Option mit http healthcheck - on Go und periodischem Start, und http healthcheck'i wird mit ein paar Codezeilen hinzugefügt.
10. Bereitstellung redundanter Dienste
Lösung: Es gibt keine einfache Lösung. Es gibt zwei schwierigere Optionen.
Das von Nomad-Entwicklern bereitgestellte Bereitstellungsschema soll die Anzahl der ausgeführten Dienste unterstützen. Sie sagen, der Nomade "starte mir 5 Instanzen des Dienstes" und er startet sie irgendwo dort. Es gibt keine Kontrolle über die Verteilung. Instanzen können auf demselben Server ausgeführt werden.
Wenn der Server abstürzt, werden die Instanzen auf andere Server übertragen. Während die Instanzen übertragen werden, funktioniert der Dienst nicht. Dies ist eine schlechte Rückstellungsoption.
Wir machen es richtig:
- Wir verteilen Instanzen auf Servern über different_hosts .
- Wir verteilen Instanzen auf Rechenzentren. Leider nur durch Erstellen einer Kopie des Skripts des Formulars service1, service2 mit demselben Inhalt, unterschiedlichen Namen und einer Angabe des Starts in verschiedenen Rechenzentren.
In Nomad 0.9 wird eine Funktionalität angezeigt, die dieses Problem behebt: Es ist möglich, Dienste in einem prozentualen Verhältnis zwischen Servern und Rechenzentren zu verteilen.
11. Web UI Nomad
Lösung: Die eingebaute Benutzeroberfläche ist schrecklich, Hashi-UI ist wunderschön.
Der Konsolenclient führt die meisten erforderlichen Funktionen aus, aber manchmal möchten Sie die Grafiken sehen, die Tasten drücken ...
Nomad verfügt über eine integrierte Benutzeroberfläche. Es ist nicht sehr praktisch (noch schlimmer als die Konsole).
Die einzige Alternative, die ich kenne, ist Hashi-UI .
Tatsächlich brauche ich den Konsolen-Client jetzt persönlich nur für "Nomad Run". Und selbst das plant, auf CI zu übertragen.
12. Unterstützung für Überzeichnung aus dem Speicher
Lösung: nein.
In der aktuellen Version von Nomad müssen Sie ein striktes Speicherlimit für den Dienst angeben. Wenn das Limit überschritten wird, wird der Dienst von OOM Killer beendet.
Überzeichnung ist, wenn Grenzwerte für einen Dienst "von und bis" angegeben werden können. Einige Dienste benötigen beim Start mehr Speicher als im normalen Betrieb. Einige Dienste verbrauchen möglicherweise für kurze Zeit mehr Speicher als gewöhnlich.
Die Wahl einer strengen Einschränkung oder einer weichen Einschränkung ist ein Diskussionsthema, aber beispielsweise ermöglicht Kubernetes dem Programmierer, eine Wahl zu treffen. Leider gibt es in aktuellen Versionen von Nomad keine solche Möglichkeit. Ich gebe zu, dass dies in zukünftigen Versionen erscheinen wird.
13. Reinigen des Servers von Nomad-Diensten
Lösung:
sudo systemctl stop nomad mount | fgrep alloc | awk '{print $3}' | xargs -I QQ sudo umount QQ sudo rm -rf /var/lib/nomad sudo docker ps | grep -v '(-1|-2|...)' | fgrep -v IMAGE | awk '{print $1}' | xargs -I QQ sudo docker stop QQ sudo systemctl start nomad
Manchmal "geht etwas schief." Auf dem Server wird der Agentenknoten beendet und der Start verweigert. Oder der Agentenknoten reagiert nicht mehr. Oder der Agentenknoten "verliert" Dienste auf diesem Server.
Dies geschah manchmal mit älteren Versionen von Nomad, jetzt passiert dies entweder nicht oder sehr selten.
Was ist in diesem Fall am einfachsten, da der Drain-Server nicht das gewünschte Ergebnis liefert? Wir reinigen den Server manuell:
- Stoppen Sie den Nomadenagenten.
- Machen Sie umount auf der Halterung, die es erstellt.
- Löschen Sie alle Agentendaten.
- Wir entfernen alle Container durch Filtern von Service-Containern (falls vorhanden).
- Wir starten den Agenten.
14. Wie kann Nomad am besten bereitgestellt werden?
Lösung: natürlich durch Konsul.
Consul ist in diesem Fall keineswegs eine zusätzliche Schicht, sondern ein Dienst, der organisch in die Infrastruktur passt und mehr Pluspunkte als Minuspunkte bietet: DNS, KV-Speicher, Suche nach Diensten, Überwachung der Verfügbarkeit des Dienstes, Fähigkeit zum sicheren Informationsaustausch.
Außerdem entfaltet es sich so leicht wie Nomad selbst.
15. Was ist besser - Nomad oder Kubernetes?
Lösung: hängt ab von ...
Früher hatte ich manchmal den Gedanken, eine Migration zu Kubernetes zu starten - ich war so verärgert über den regelmäßigen spontanen Neustart von Diensten (siehe Problem Nummer 8). Aber nach einer vollständigen Lösung des Problems kann ich sagen: Nomad passt im Moment zu mir.
Auf der anderen Seite: Kubernetes hat auch ein halb-spontanes Neuladen von Diensten - wenn der Kubernetes-Scheduler Instanzen abhängig von der Last neu verteilt. Das ist nicht sehr cool, aber dort ist es höchstwahrscheinlich konfiguriert.
Vorteile von Nomad: Die Infrastruktur ist sehr einfach bereitzustellen, einfache Skripte, gute Dokumentation, integrierte Unterstützung für Consul / Vault, was wiederum Folgendes bietet: eine einfache Lösung für das Problem der Kennwortspeicherung, integriertes DNS und einfach zu konfigurierende Helchecks.
Vorteile von Kubernetes: Jetzt ist es ein "De-facto-Standard". Gute Dokumentation, viele vorgefertigte Lösungen mit einer guten Beschreibung und Standardisierung des Starts.
Leider habe ich nicht das gleiche große Fachwissen in Kubernetes, um die Frage eindeutig zu beantworten - was für den neuen Cluster zu verwenden ist. Kommt auf die geplanten Bedürfnisse an.
Wenn Sie viele Namespaces geplant haben (Problem Nr. 5) oder Ihre spezifischen Dienste zu Beginn viel Speicher verbrauchen, dann geben Sie ihn frei (Problem Nr. 12) - definitiv Kubernetes, weil Diese beiden Probleme in Nomad sind nicht vollständig gelöst oder unpraktisch.