In der Welt von PHP sind Tools zur Migration von Datenbankstrukturen bekannt -
Doctrine ,
Phinx von CakePHP,
Laravel ,
Yii - dies war das erste, was mir in den Sinn kam. Sicher gibt es noch ein Dutzend mehr. Und die meisten von ihnen arbeiten mit Migrationen - Befehlen zum inkrementellen Ändern des Datenbankschemas.
Ich werde nicht beschreiben, warum das so ist, es gibt viele Beiträge zu diesem Thema auf Habré. Zum Beispiel:
Weiter die Entwicklung meiner
Erfahrung als Team mit einer ständigen Änderung in der Struktur der Datenbank in verschiedenen Branchen.
Raw SQL vs PHP API
Wir schreiben Migrationen in reinem SQL. Viele Tools bieten PHP-API zum Schreiben von Anweisungen, die in SQL-Code übersetzt wurden. Jetzt verstehe ich nicht, warum das so ist? Ein solches Werkzeug wird immer in seinen Fähigkeiten eingeschränkt sein. Sie erlauben nicht, bestimmte Anweisungen für eine bestimmte Engine zu schreiben, Sie müssen immer noch reines SQL verwenden. Ich spreche nicht über Schreibverfahren und Ansichten.
Jemand beschwerte sich, dass er die Syntax von ALTER-Befehlen nicht lernen wollte ... Nun, ich weiß nicht, ich habe das Verzeichnis geöffnet und Beispiele für den Berg geschrieben, insbesondere in einem großen Projekt.
Datenmigrationen (INSERT, UPDATE) werden ebenfalls immer in SQL geschrieben. Weil Sie sich niemals auf die aktuelle Version von ORM und Models verlassen können. In einer Revision sind sie, in der anderen nicht mehr.
Zum Beispiel:
Rollback Country::delete()->where(....)->execute();
Möchten Sie den Status der Datenbank zurücksetzen? Und diese PHP-Klasse ist nicht mehr im Repo. Sie müssen nach dem letzten Commit suchen, wo er war, und von dort zurückrollen. Brrr ...
Daher ist SQL einfach und zuverlässig:
Transaktionen in DDL
Mit dem Übergang zu PostgreSQL vergaß ich kaputte Migrationen wie einen Albtraum - die Migration fiel in die Mitte, etwas rollte zusammen, etwas nicht da, setzte mich und bearbeitete die Stifte ... Dies zwang uns, atomare einzeilige Befehle zu schreiben und sie einzeln auszuführen. Bei Transaktionen ist alles einfach: Wenn etwas kaputt geht, rollt alles zurück (na ja, fast alles). Repariere es einfach und starte es neu. Die automatische Montage funktioniert mit einem Knall. Wenn etwas herunterfällt, wird es schnell repariert und steigt.
Ansichten (Ansichten) und Funktionen
Das Problem hierbei ist, dass sie nicht inkrementell aktualisiert werden können, wie z. B. ALTER in Tabellen. Brauchen Sie DROP und CREATE. Das heißt, Über das Differential (Text der Migration) ist überhaupt nicht klar, was sich am Ende geändert hat. Besonders wenn die Logik verdreht ist, ist es ziemlich unpraktisch. Zum Beispiel:
Was hat sich hier geändert?
Wir haben bei der Tatsache angehalten, dass sich neben den Migrationen ein Daddy befindet, in dem der aktuelle Ansichts- und Prozedurcode gespeichert ist, der aktualisiert und in der Rollback-Migration kopiert wird.
Und jetzt wird der Unterschied wie folgt:

Zurück in Avito haben wir eine interessante Lösung für die
Versionierung von Code für
gespeicherte Prozeduren entwickelt.Im Allgemeinen wirft dieser Fall ein gutes Problem auf - wie man den Verlauf von Änderungen in einem bestimmten Objekt der Datenbankstruktur betrachtet. Für jede Tabelle möchte ich den Verlauf der Änderungen im Zusammenhang mit der Lösung bestimmter Aufgaben anzeigen.

Auf Habré wurde ein interessanter
Ansatz zur Automatisierung der Korrektur von Änderungen in der Datenbankstruktur gefunden.
Arbeite mit Zweigen
Mein ewiger Schmerz ist, wie ich zwischen zwei A- und B-Zweigen wechseln kann, von denen jeder Änderungen an der Struktur der Datenbank vorgenommen hat.

Es ist notwendig, Migrationen im A-Zweig zurückzusetzen (wir müssen uns auch merken, welche und wie viele), dann zum B-Zweig zu wechseln und neue Migrationen zu rollen. Okay, wenn unsere Änderungen kompatibel sind und ich einfach zum zweiten Zweig wechseln und zusätzliche Migrationen von B ausführen kann.
Und wenn nicht? Und wenn ich mehr als einen solchen Zweig habe? Und dann alle diese Überprüfungsstatus zurücksetzen? Ich habe es immer gehasst ...
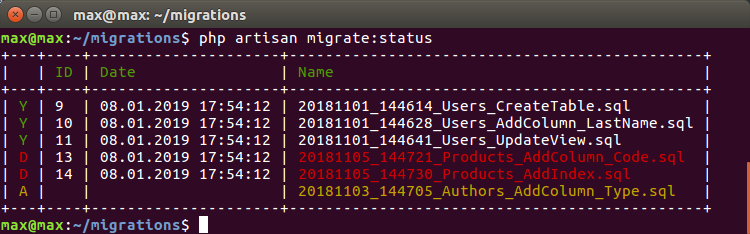
Wenn ich jetzt zu einem anderen Zweig wechsle, kann ich automatisch die Migrationen anderer Personen löschen und die aktuellen rollen:
wo:
D - A-Migrationen, die im A-Zweig gestartet wurden, sich jedoch nicht im aktuellen Zweig befinden, und es wird empfohlen, sie zu löschen
A - B-Migrationen, die im neuen Zweig erschienen sind und gerollt werden müssen
Es wird unglaublich praktisch beim Testen und automatischen Zusammenbau auf einer Basis. Wenn es für jeden Zweig keinen Sinn oder keine Möglichkeit gibt, eine Basis von Grund auf neu zu erstellen. Wechseln Sie zum Zweig und synchronisieren Sie automatisch den Status der Datenbank.
Nummerierung und Ausführungsreihenfolge
Alle Tools, die ich kenne, sind zeitgesteuerte Migrationen mit Stempel. Dies ist eine gute Lösung. Wenn ich mehrere Migrationen schreibe, bleibt die erforderliche Reihenfolge erhalten. Ein anderer Entwickler kann ein beliebiges Datum in einem anderen Thread haben, auch in meinem - aber es spielt keine Rolle, in welcher Reihenfolge wir mit ihm rollen, unsere Änderungen sind unabhängig voneinander. Selbst wenn wir mit derselben Tabelle arbeiten (nach Spalte hinzufügen), werden alle erforderlichen Änderungen in beliebiger Reihenfolge vorgenommen. Die Hauptsache ist, dass die Reihenfolge meiner abhängigen Änderungen eingehalten wird.

Ich betrachte keine Fälle, in denen wir dasselbe bearbeiten müssen - diese Punkte sind immer konsistent. Nun, oder es wird einen Fehler in der Phase der Montage und Prüfung geben.
Hier ist ein interessantes Beispiel.
Wir nehmen verschiedene Änderungen in einer Ansicht oder Prozedur vor, d. H. in den Strukturen, die durch Löschen aktualisiert werden. Das heißt, Zum Beispiel habe ich der Spalte die Spalte col_A und meinem Kollegen col_B hinzugefügt. Wenn sein Code nach meinem Code veröffentlicht wird, enthält seine Spalte meine Spalte nicht:
CREATE VIEW vusers AS SELECT login, name,
| Zweig-A | Zweig-B |
|---|
DROP VIEW vusers; CREATE VIEW vusers AS SELECT login, name, col_A, | DROP VIEW vusers; CREATE VIEW vusers AS SELECT login, name, col_B, |
In diesem Fall muss ein Zweig von einem anderen abhängig gemacht werden.
Ein weiterer interessanter Fall sind Korrekturen bei Migrationen.
Unter dem Strich wird die angewendete Migration nicht mehr erneut angewendet, unabhängig davon, wie viele Änderungen Sie daran vornehmen (Sie müssen zuerst ein Rollback durchführen und sie dann erneut anwenden). Das heißt, Sie haben Migration zum Testen gesendet, alle Regeln, und dann haben Sie es erkannt und eine kleine Bearbeitung vorgenommen. Der Test oder ein anderer Server, auf dem Sie ihn verwendet haben, weiß jedoch nichts darüber.
In diesen Fällen benennen wir die Migrationsdatei um und fügen eine neue Versionsnummer hinzu, sodass der Migrator dies als 2 Befehle interpretiert - Rollback 1 und Roll 2,
zum Beispiel:

Rollback
Schreiben Sie immer ROLLBACK, auch wenn die Basis nicht in ihren ursprünglichen Zustand zurückversetzt werden kann. Zum Beispiel, DROP TABLE, welche Art von ROLLBACK kann es sein?
In solchen Fällen schreiben wir eine leere CREATE TABLE. Das Fazit ist, dass das Entwicklungssystem immer leicht zwischen Zweigen wechseln kann. Für PROD wird das irreversible Revisionsmanagement bereits auf einer anderen Ebene festgelegt. Ich kann eine Kopie der Tabelle erstellen oder sie umbenennen, anstatt sie zu löschen. Aber das Prinzip der Schreibmigration - das Rollback ist VERPFLICHTET, um die STRUKTUR der Basis auf die ursprüngliche Ebene zurückzusetzen, und die Daten sind bereits möglich.
In einer Kampfumgebung habe ich in meinem Leben nur 1-2 Mal einen Rollback verwendet. Und die ganze Zeit in der Entwicklung. Daher überprüfe ich immer, ob der Rollback alles in den gewünschten Zustand zurückversetzt.
Oft können Entwickler beim Rollback Fehler machen. Weil Sie konzentrieren sich hauptsächlich auf neue Bearbeitungen, werden getestet und arbeiten mit ihnen. Andere Personen und Prozesse arbeiten bereits mit dem Rollback. Daher teste ich Migrationen immer UP - ROLLBACK - UP
Ein interessanter Punkt erscheint auf einer permanenten Testbasis (die Datenbank wird nicht gelöscht). Sie haben eine Migration geschrieben, das Rollback funktioniert einwandfrei, sie haben es zum Testen gesendet, der Tester hat Daten in einem neuen Format generiert und versucht, ein Rollback durchzuführen, aber sie geben keine neuen Daten an. Klassisches Beispiel
ALTER TABLE abc ALTER COLUMN code SET NULL
Großartig! Nach dem Testen ist die Datenbank voll mit NULL-Werten. ROLLBACK:
ALTER TABLE abc ALTER COLUMN code SET NOT NULL
und umgekehrt :-(
Sie müssen den folgenden Befehl hinzufügen:
DELETE FROM abc WHERE code IS NULL
Die Schwierigkeit besteht darin, dass Sie dies berücksichtigen und nicht automatisieren müssen, wenn Sie nicht jedes Mal davon sprechen, die Datenbank von Grund auf neu zu erstellen.
Ein bisschen über das Löschen von Daten
Normalerweise versuchen wir NICHT, gefüllte Tabellen und Spalten gleichzeitig zu löschen. Es ist besser, eine Kopie umzubenennen oder zu erstellen und sie später zu löschen, wenn sich alles beruhigt und die Daten an Relevanz verlieren:
ALTER TABLE user_logs RENAME TO user_logs_20190223;
Migrator
Wir arbeiten jetzt mit Laravel zusammen - er verfügt über eine standardmäßige, vertraute Migrationsmanagement-Engine. Wenn Sie möchten, schreiben Sie sogar in reinem SQL, obwohl es noch in der PHP-Klasse ist. Aber meine wiederholten Versuche, es so zu machen, wie wir es brauchten, führten zu einem separaten Repo:
- Die Lösung besteht aus 2 Teilen - lib und Implementierung für eine bestimmte Konsole (Laravel, Symfony). Sie können in jede Konsole oder zumindest in die Web-Schnauze integrieren.
- Es gibt keine Konfiguration und Verbindung - warum, wenn es bereits in Ihrem Projekt ist. Klammern Sie Ihre Verbindung an die Schnittstelle und gehen Sie.
- SQL-Rollback wird in der Datenbank gespeichert. Dies ist erforderlich, um zwischen Zweigen zu wechseln.
- Getestet auf Postgesql, MySQL (keine Transaktionen). Es ist grundsätzlich für alle Basen und Strukturen geeignet, da das Rohformat verwendet wird.
Referenzen
-
migrations-lib-
Umsetzung unter Laravel / Artisan-
Implementierung unter Symfony / Console