
Jedes Client-Server-Projekt impliziert eine klare Trennung der Codebasis in zwei Teile (manchmal mehr) - Client und Server. Oft wird jeder dieser Teile in Form eines separaten unabhängigen Projekts ausgeführt, das von einem eigenen Entwicklerteam unterstützt wird.
In diesem Artikel schlage ich einen kritischen Blick auf die standardmäßige harte Unterteilung von Code in ein Backend und ein Frontend vor. Und überlegen Sie sich eine Alternative, bei der der Code keine klare Linie zwischen Client und Server aufweist.
Nachteile des Standardansatzes
Der Hauptnachteil der Standardaufteilung des Projekts in zwei Teile ist die Erosion der Geschäftslogik zwischen Client und Server. Wir bearbeiten die Daten im Formular im Browser, überprüfen sie im Kundencode und senden sie an das Dorf des Großvaters (an den Server). Der Server ist bereits ein anderes Projekt. Dort müssen Sie auch die Richtigkeit der empfangenen Daten überprüfen (d. H. Die Funktionalität des Clients duplizieren), einige zusätzliche Manipulationen vornehmen (in der Datenbank speichern, E-Mail senden usw.).
Um den gesamten Informationspfad vom Formular im Browser zur Datenbank auf dem Server zu verfolgen, müssen wir uns daher mit zwei verschiedenen Systemen befassen. Wenn die Rollen in einem Team aufgeteilt sind und verschiedene Spezialisten für das Backend und das Frontend verantwortlich sind, treten zusätzliche organisatorische Probleme im Zusammenhang mit ihrer Synchronisation auf.
Lass uns träumen
Angenommen, wir können den gesamten Datenpfad vom Formular auf dem Client zur Datenbank auf dem Server in einem Modell beschreiben. Im Code sieht es möglicherweise so aus (der Code funktioniert nicht):
class MyDataModel {
Somit liegt die gesamte Geschäftslogik des Modells vor unseren Augen. Die Pflege eines solchen Codes ist einfacher. Die Kombination von Client-Server-Methoden in einem Modell bietet folgende Vorteile:
- Die Geschäftslogik ist an einem Ort konzentriert. Sie muss nicht zwischen Client und Server geteilt werden.
- Während der Entwicklung des Projekts können Sie Funktionen problemlos von Server zu Client oder von Client zu Server übertragen.
- Es ist nicht erforderlich, dieselben Methoden für das Backend und das Frontend zu duplizieren.
- Ein einziger Testsatz für die gesamte Geschäftslogik des Projekts.
- Ersetzen horizontaler Linien der Verantwortungsabgrenzung im Projekt durch vertikale.
Ich werde den letzten Punkt genauer erläutern. Stellen Sie sich eine reguläre Client-Server-Anwendung in Form eines solchen Schemas vor:
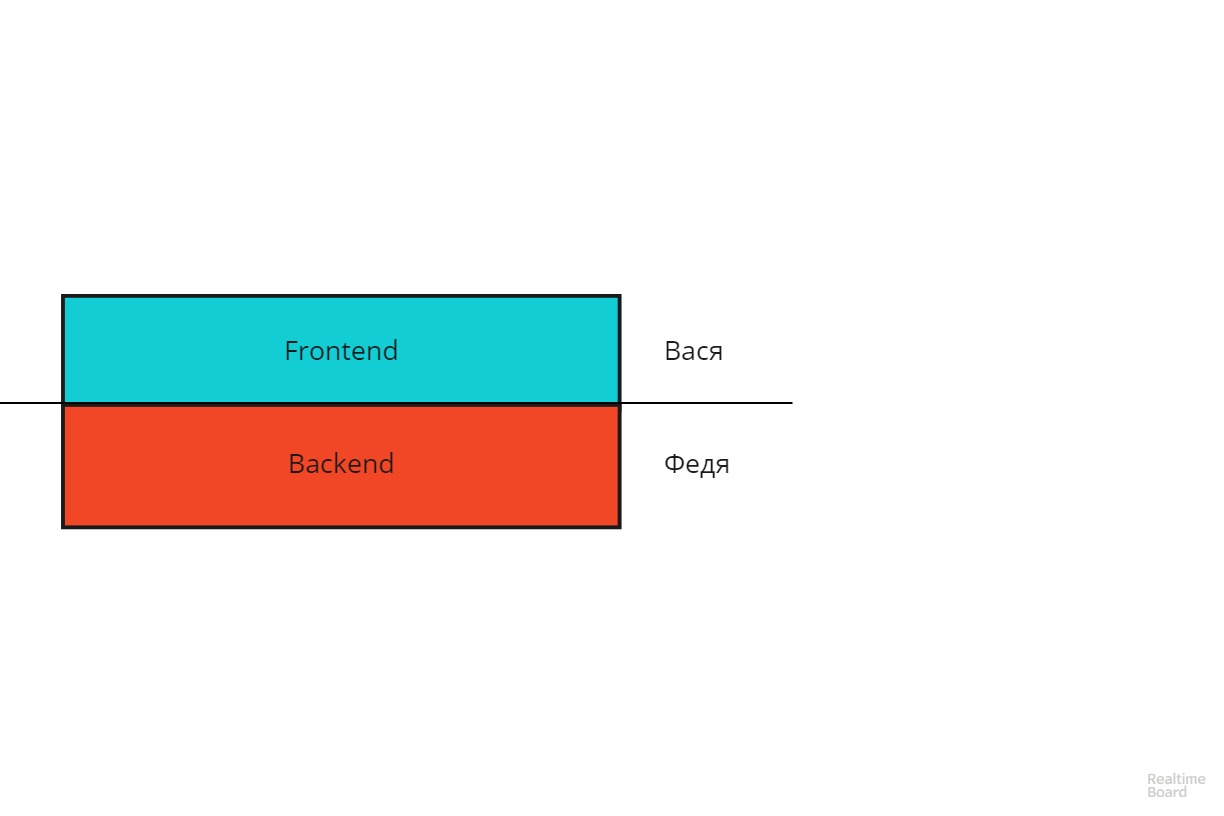
Vasya ist verantwortlich für das Frontend, Fedya - für das Backend. Die Linie der Verantwortungsabgrenzung verläuft horizontal. Dieses Schema hat die Nachteile jeder vertikalen Struktur - es ist schwierig zu skalieren und weist eine geringe Fehlertoleranz auf. Wenn das Projekt erweitert wird, müssen Sie eine ziemlich schwierige Entscheidung treffen: Wen sollen Sie Vasya oder Fedya stärken? Oder wenn Fedya krank wurde oder aufhörte, kann Vasya ihn nicht ersetzen.
Mit dem hier vorgeschlagenen Ansatz können Sie die Aufteilung der Verantwortung um 90 Grad erweitern und die vertikale Architektur in eine horizontale umwandeln.
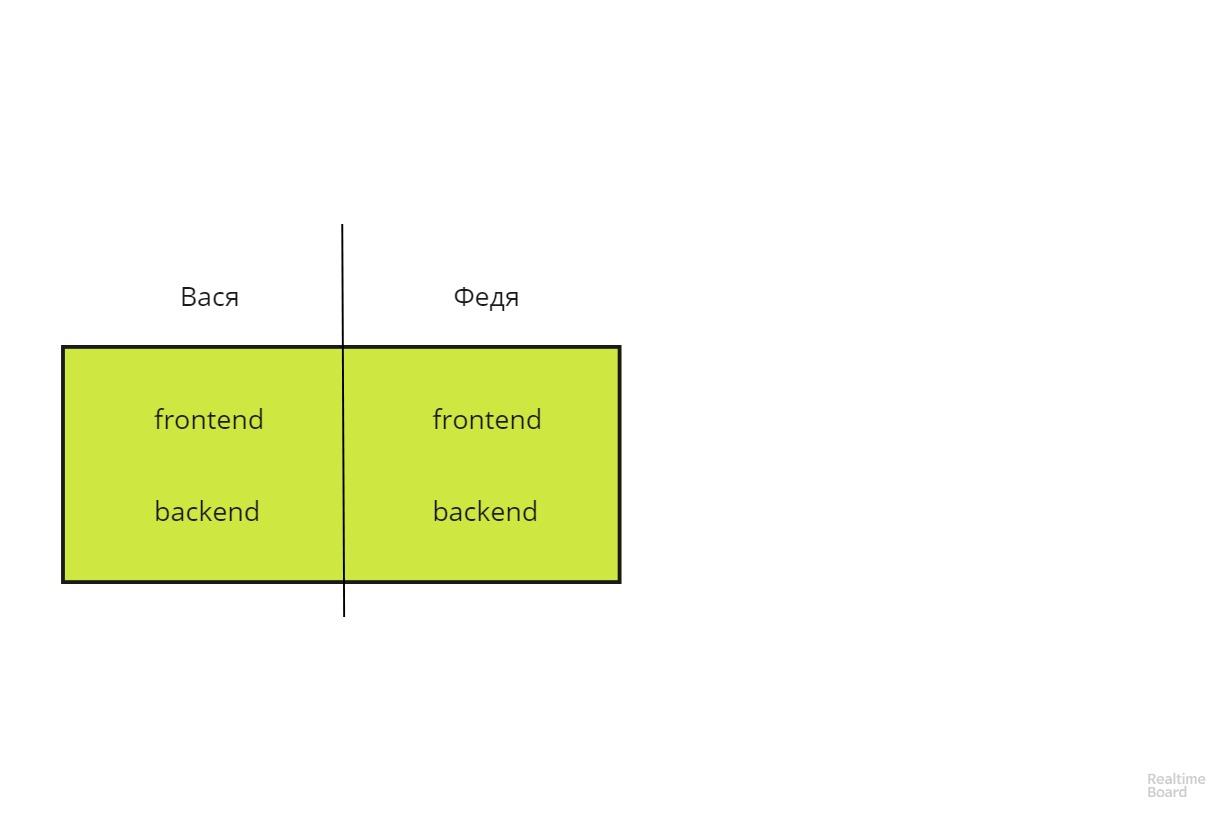
Eine solche Architektur ist viel einfacher zu skalieren und fehlertoleranter. Vasya und Fedya werden austauschbar.
Theoretisch sieht es gut aus. Versuchen wir, all dies in die Praxis umzusetzen, ohne dabei alles zu verlieren, was uns auf diesem Weg die getrennte Existenz von Client und Server ermöglicht.
Erklärung des Problems
Wir müssen absolut keinen integrierten Client-Server im Produkt haben. Im Gegenteil, eine solche Entscheidung wäre unter allen Gesichtspunkten äußerst schädlich. Die Aufgabe besteht darin, dass wir im Entwicklungsprozess eine einzige Codebasis für Datenmodelle für das Backend und das Frontend haben würden, die Ausgabe jedoch ein unabhängiger Client und Server wäre. In diesem Fall erhalten wir alle Vorteile des Standardansatzes und erhalten die oben aufgeführten Annehmlichkeiten für die Entwicklung und Unterstützung des Projekts.
Lösung
Ich experimentiere seit einiger Zeit mit der Integration von Client und Server in eine Datei. Bis vor kurzem bestand das Hauptproblem darin, dass in Standard-JS die Verbindung von Modulen von Drittanbietern auf dem Client und dem Server zu unterschiedlich war: erfordern (...) in node.js alle AJAX-Magie auf dem Client. Mit dem Aufkommen der ES-Module hat sich alles geändert. In modernen Browsern wird „Importieren“ seit langem unterstützt. Node.js liegt in dieser Hinsicht leicht zurück und ES-Module werden nur mit aktiviertem Flag "--experimental-modules" unterstützt. Es ist zu hoffen, dass in absehbarer Zeit Module in node.js sofort funktionieren. Darüber hinaus ist es unwahrscheinlich, dass sich etwas stark ändert, weil In Browsern funktioniert diese Funktionalität seit langer Zeit standardmäßig. Ich denke, dass Sie jetzt ES-Module nicht nur auf dem Client, sondern auch auf der Serverseite verwenden können (wenn Sie Gegenargumente zu diesem Thema haben, schreiben Sie in die Kommentare).
Das Lösungsschema sieht folgendermaßen aus:

Das Projekt enthält drei Hauptkataloge:
geschützt - Backend;
öffentliches Frontend;
Shared - Shared Client-Server-Modelle.
Ein separater Beobachterprozess überwacht Dateien im freigegebenen Verzeichnis und erstellt bei Änderungen Versionen der geänderten Datei separat für den Client und separat für den Server (in den Verzeichnissen protected / shared und public / shared).
Implementierung
Betrachten Sie das Beispiel eines einfachen Echtzeit-Messenger. Wir benötigen frische node.js (ich habe Version 11.0.0) und Redis (deren Installation wird hier nicht behandelt).
Klonen Sie ein Beispiel:
git clone https://github.com/Kolbaskin/both-example cd ./both-example npm i
Installieren Sie den Beobachterprozess und führen Sie ihn aus (Beobachter im Diagramm):
npm i both-js -g both ./index.mjs
Wenn alles in Ordnung ist, startet der Beobachter den Webserver und beginnt, Änderungen an den Dateien in den freigegebenen und geschützten Verzeichnissen zu überwachen. Wenn Änderungen an der Freigabe vorgenommen werden, werden entsprechende Versionen der Datenmodelle für den Client und den Server erstellt. Bei Änderungen an protected startet der Watcher den Webserver automatisch neu.
Sie können die Leistung des Messenger im Browser sehen, indem Sie auf den Link klicken
http://localhost:3000/index.html?token=123&user=Vasya(Token und Benutzer sind beliebig). Um mehrere Benutzer zu emulieren, öffnen Sie dieselbe Seite in einem anderen Browser, indem Sie ein anderes Token und einen anderen Benutzer angeben.
Nun ein kleiner Code.
Webserver
protected / server.mjs
import express from 'express'; import bodyParser from 'body-parser';
Dies ist ein regulärer Express-Server, hier gibt es nichts Interessantes. Die Erweiterung mjs wird für ES-Module in node.js benötigt. Aus Gründen der Konsistenz verwenden wir diese Erweiterung für den Client.
Kunde
public / index.html
<!DOCTYPE html> <html lang="en"> <head> ... <script src="https://cdn.jsdelivr.net/npm/vue/dist/vue.js"></script> <script src="/main.mjs" type="module"></script> </head> <body> ... <ul id="users"> <li v-for="user in users"> {{ user.name }} ({{user.id}}) </li> </ul> <div id="messages"> <div> <input type="text" v-model="msg" /> <button v-on:click="sendMessage()"></button> </div> <ul> <li v-for="message in messages">[{{ message.date }}] <strong>{{ message.text }}</strong></li> </ul> </div> </body> </html>
Zum Beispiel verwende ich Vue auf dem Client, aber das ändert nichts an der Essenz. Anstelle von Vue kann es alles geben, wo Sie das Datenmodell in eine separate Klasse (Knockout, Angular) unterteilen können.
public / main.mjs
main.mjs ist ein Skript, das Datenmodelle mit entsprechenden Ansichten verknüpft. Um den Code zu vereinfachen, werden Beispieldarstellungen für die Liste der aktiven Benutzer und Nachrichtenfeeds direkt in index.html integriert
Datenmodell
shared / messages / model / dataModel.mjs
Diese verschiedenen Methoden implementieren alle Funktionen zum Senden und Empfangen von Nachrichten in Echtzeit. Die Anweisungen! #Client und! #Server teilen dem Beobachterprozess mit, welche Methode für welchen Teil (Client oder Server) vorgesehen ist. Wenn diese Anweisungen vor dem Definieren einer Methode nicht vorhanden sind, ist eine solche Methode sowohl auf dem Client als auch auf dem Server verfügbar. Schrägstriche vor der Direktive sind optional und nur vorhanden, um zu verhindern, dass die Standard-IDE auf Syntaxfehler schwört.
In der ersten Zeile des Pfads wird die & root-Suche verwendet. Beim Generieren der Client- und Serverversionen wird & root durch den relativen Pfad zu den öffentlichen bzw. geschützten Verzeichnissen ersetzt.
Ein weiterer wichtiger Punkt: Von der Client-Methode aus können Sie nur die Server-Methode aufrufen, deren Name mit "$" beginnt:
...
Dies geschieht aus Sicherheitsgründen: Von außen können Sie hierfür nur auf speziell entwickelte Methoden zurückgreifen.
Schauen wir uns die Versionen der Datenmodelle an, die der Beobachter für den Client und den Server generiert hat.
Client (public / shared / messages / model / dataModel.mjs)
import Base from '/lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"}
Auf der Clientseite ist das Modell ein Nachkomme der Vue-Klasse (über Base.mjs). Somit können Sie damit wie mit einem normalen Vue-Datenmodell arbeiten. Der Beobachter fügte der Client-Version des Modells die Methode __getFilePath__ hinzu, die den Pfad zur Klassendatei zurückgibt, und ersetzte den Server-Methodencode $ sendMessage durch ein Konstrukt, das im Wesentlichen die auf dem Server benötigte Methode über den RPC-Mechanismus aufruft (__runSharedFunction ist in der übergeordneten Klasse definiert).
Server (protected / shared / messages / model / dataModel.mjs)
import Base from '../../lib/Base.mjs'; export default class dataModel extends Base { __getFilePath__() {return "messages/model/dataModel.mjs"} ... ...
In der Serverversion wurde auch die Methode __getFilePath__ hinzugefügt und die mit der Direktive gekennzeichneten Client-Methoden wurden entfernt! #Client
In beiden generierten Versionen des Modells werden alle gelöschten Zeilen durch leere ersetzt. Dies geschieht, damit die Fehlermeldung im Debugger die problematische Zeile im Quellcode des Modells leicht finden kann.
Client-Server-Interaktion
Wenn wir eine Servermethode auf dem Client aufrufen müssen, tun wir es einfach.
Wenn sich der Anruf innerhalb desselben Modells befindet, ist alles einfach:
... !#client async sendMessage(e) { await this.$sendMessage(this.msg); this.msg = ''; } !#server async $sendMessage(msg) {
Sie können ein anderes Modell „ziehen“:
import dataModel from "/shared/messages/model/dataModel.mjs"; var msg = new dataModel(); msg.$sendMessage('blah-blah-blah');
In der entgegengesetzten Richtung, d.h. Das Aufrufen einer Clientmethode auf dem Server funktioniert nicht. Technisch ist dies machbar, aber aus praktischer Sicht macht es keinen Sinn, weil Der Server ist einer, aber es gibt viele Clients. Wenn wir einige Aktionen auf dem Server auf dem Client initiieren müssen, verwenden wir den Ereignismechanismus:
Die fireEvent-Methode verwendet drei Parameter: den Namen des Ereignisses, an das es gerichtet ist, und Daten. Sie können den Empfänger auf verschiedene Arten festlegen: Schlüsselwort "all" - Das Ereignis wird an alle Benutzer oder im Array gesendet, um die Sitzungstoken der Clients aufzulisten, an die das Ereignis gerichtet ist.
Das Ereignis ist nicht an eine bestimmte Instanz der Datenmodellklasse gebunden, und Handler werden in allen Instanzen der Klasse ausgelöst, in der fireEvent aufgerufen wurde.
Horizontale Backend-Skalierung
Die Monolithizität von Client-Server-Modellen in der vorgeschlagenen Implementierung sollte auf den ersten Blick die Möglichkeit einer horizontalen Skalierung des Serverteils erheblich einschränken. Dies ist jedoch nicht der Fall: Technisch gesehen ist der Server nicht vom Client abhängig. Sie können das "öffentliche" Verzeichnis überall kopieren und seinen Inhalt über einen anderen Webserver (Nginx, Apache usw.) bereitstellen.
Die Serverseite kann einfach durch Starten neuer Backend-Instanzen erweitert werden. Redis und das Kue-Warteschlangensystem werden verwendet, um mit einzelnen Instanzen zu interagieren.
API und verschiedene Clients zu einem Backend
In realen Projekten können verschiedene Server-Clients eine Server-API verwenden - Websites, mobile Anwendungen und Dienste von Drittanbietern. In der vorgeschlagenen Lösung ist all dies ohne zusätzliche Tänze verfügbar. Unter der Haube des Aufrufs von Servermethoden befindet sich der gute alte RPC. Der Webserver selbst ist eine klassische Expressanwendung. Es reicht aus, dort einen Wrapper für Routen hinzuzufügen, bei dem die erforderlichen Methoden derselben Datenmodelle aufgerufen werden.
Post scriptum
Der in diesem Artikel vorgeschlagene Ansatz gibt keine revolutionären Änderungen in Client-Server-Anwendungen vor. Es bietet dem Entwicklungsprozess nur ein wenig Komfort, sodass Sie sich auf die an einem Ort zusammengestellte Geschäftslogik konzentrieren können.
Dieses Projekt ist experimentell. Schreiben Sie in die Kommentare, ob es sich Ihrer Meinung nach lohnt, dieses Experiment fortzusetzen.