Hallo! Ich bin Dima und sitze seit einiger Zeit in Python. Heute möchte ich Ihnen die Unterschiede zwischen zwei asynchronen Frameworks zeigen - Tornado und Aiohttp. Ich werde die Geschichte der Wahl zwischen den Frameworks in unserem Projekt erzählen, wie sich die Coroutinen in Tornado und AsyncIO unterscheiden. Ich werde Benchmarks zeigen und einige nützliche Tipps geben, wie Sie in die Wildnis von Frameworks gelangen und dort erfolgreich rauskommen können.

Wie Sie wissen, ist Avito ein ziemlich großer Werbedienst. Wir haben viele Daten und laden, jeden Monat 35 Millionen Nutzer und täglich 45 Millionen aktive Anzeigen. Ich arbeite als technischer Berater einer Empfehlungsentwicklungsgruppe. Mein Team schreibt Microservices, jetzt haben wir ungefähr zwanzig davon. Auf all dem stapelt sich eine Last - wie 5k RPS.
Auswählen eines asynchronen Frameworks
Zuerst erzähle ich Ihnen, wie wir dort gelandet sind, wo wir jetzt sind. 2015 mussten wir ein asynchrones Framework auswählen, weil wir wussten:
- dass Sie viele Anfragen an andere Microservices stellen müssen: http, json, rpc;
- dass Sie ständig Daten aus verschiedenen Quellen sammeln müssen: Redis, Postgres, MongoDB.
Daher haben wir viele Netzwerkaufgaben, und die Anwendung ist hauptsächlich mit Eingabe / Ausgabe beschäftigt. Die aktuelle Version von Python war zu diesem Zeitpunkt 3.4, asynchron und warten wurde noch nicht angezeigt. Aiohttp war auch - in Version 0.x. Der asynchrone Tornado von Facebook erschien 2010. Viele Datenbanktreiber sind für ihn geschrieben, die wir brauchen. Tornado zeigte stabile Ergebnisse bei Benchmarks. Dann haben wir unsere Wahl in diesem Rahmen gestoppt.
Drei Jahre später haben wir viel verstanden.
Zunächst kam Python 3.5 mit Async / Wait-Mechanik heraus. Wir haben herausgefunden, was der Unterschied zwischen Ertrag und Ertrag ist und wie Tornado mit Warten übereinstimmt (Spoiler: nicht sehr gut).
Zweitens stießen wir auf seltsame Leistungsprobleme mit einer großen Menge an Coroutine im Scheduler, selbst wenn die CPU nicht voll belegt ist.
Drittens haben wir festgestellt, dass Sie beim Ausführen einer großen Anzahl von http-Anforderungen an andere Tornado-Dienste besonders mit dem asynchronen DNS-Resolver vertraut sein müssen. Er berücksichtigt nicht die Zeitüberschreitungen für den Verbindungsaufbau und das Senden der von uns angegebenen Anforderung. Und im Allgemeinen ist Curl die beste Methode, um http-Anfragen in Tornado zu stellen, was an sich schon seltsam ist.
In seinem
Vortrag auf der PyCon Russia 2018 sagte Andrei Svetlov: „Wenn Sie eine asynchrone Webanwendung schreiben möchten, schreiben Sie einfach asynchron und warten Sie. Event-Schleife, wahrscheinlich werden Sie sie bald gar nicht mehr brauchen. Gehen Sie nicht in die Wildnis von Frameworks, um nicht verwirrt zu werden. Verwenden Sie keine einfachen Grundelemente, und alles wird gut mit Ihnen ... ". In den letzten drei Jahren mussten wir leider ziemlich oft ins Innere des Tornado klettern, von dort aus viele interessante Dinge lernen und gigantische Traysbacks für 30-40 Anrufe sehen.
Ertrag gegen Ertrag von
Eines der größten Probleme, die bei asynchronem Python zu verstehen sind, ist der Unterschied zwischen Ertrag von und Ertrag.
Guido Van Rossum hat mehr darüber geschrieben. Ich lege der Übersetzung leichte Abkürzungen bei.
Ich wurde mehrmals gefragt, warum PEP 3156 darauf besteht, Yield-from anstelle von Yield zu verwenden, was die Möglichkeit eines Backportings in Python 3.2 oder sogar 2.7 ausschließt.
(...)
Wann immer Sie ein zukünftiges Ergebnis wünschen, verwenden Sie Yield.
Dies wird wie folgt implementiert. Die Funktion, die Yield enthält, ist (offensichtlich) ein Generator, daher muss es eine Art iterativen Code geben. Nennen wir ihn einen Planer. Tatsächlich "iteriert" der Scheduler nicht im klassischen Sinne (mit for-Schleife); Stattdessen werden zwei zukünftige Sammlungen unterstützt.
Ich werde die erste Sammlung eine "ausführbare" Sequenz nennen. Dies ist die Zukunft, deren Ergebnisse vorliegen. Während diese Liste nicht leer ist, wählt der Scheduler ein Element aus und führt einen Iterationsschritt aus. Dieser Schritt ruft die Generatormethode .send () mit dem Ergebnis aus der Zukunft auf (dies können Daten sein, die gerade aus dem Socket gelesen wurden). Im Generator wird dieses Ergebnis als Rückgabewert des Ertragsausdrucks angezeigt. Wenn send () ein Ergebnis zurückgibt oder abgeschlossen ist, analysiert der Scheduler das Ergebnis (dies kann StopIteration, eine andere Ausnahme oder eine Art Objekt sein).
(Wenn Sie verwirrt sind, sollten Sie wahrscheinlich lesen, wie Generatoren funktionieren, insbesondere die .send () -Methode. Vielleicht ist PEP 342 ein guter Ausgangspunkt.)
(...)
Die zweite vom Scheduler unterstützte zukünftige Sammlung besteht aus der Zukunft, die noch auf I / O wartet. Sie werden irgendwie an select / poll / shell usw. übergeben. Dies gibt einen Rückruf aus, wenn der Dateideskriptor für E / A bereit ist. Der Rückruf führt tatsächlich die von der Zukunft angeforderte E / A-Operation aus, setzt den resultierenden zukünftigen Wert auf das Ergebnis der E / A-Operation und verschiebt die Zukunft in die Ausführungswarteschlange.
(...)
Jetzt haben wir das interessanteste erreicht. Angenommen, Sie schreiben ein komplexes Protokoll. In Ihrem Protokoll lesen Sie Bytes von einem Socket mit der Methode recv (). Diese Bytes gelangen in den Puffer. Die recv () -Methode ist in eine asynchrone Shell eingebunden, die die E / A festlegt und die Zukunft zurückgibt, die ausgeführt wird, wenn die E / A abgeschlossen ist, wie oben erläutert. Angenommen, ein anderer Teil Ihres Codes möchte zeilenweise Daten aus dem Puffer lesen. Angenommen, Sie haben die Methode readline () verwendet. Wenn die Puffergröße größer als die durchschnittliche Zeilenlänge ist, kann Ihre readline () -Methode einfach die nächste Zeile aus dem Puffer abrufen, ohne sie zu blockieren. Manchmal enthält der Puffer jedoch keine ganze Zeile, und readline () ruft wiederum recv () für den Socket auf.
Frage: Sollte readline () zukünftig zurückkehren oder nicht? Es wäre nicht sehr gut, wenn er manchmal eine Byte-Zeichenfolge und manchmal die Zukunft zurückgeben würde, um den Aufrufer zu zwingen, eine Typprüfung und eine bedingte Ausbeute durchzuführen. Die Antwort lautet also, dass readline () immer die Zukunft zurückgeben sollte. Wenn readline () aufgerufen wird, überprüft es den Puffer. Wenn dort mindestens eine ganze Zeile gefunden wird, wird eine Zukunft erstellt, das zukünftige Ergebnis einer aus dem Puffer entnommenen Zeile festgelegt und die Zukunft zurückgegeben. Wenn der Puffer keine ganze Zeile enthält, initiiert er die E / A und erwartet sie. Wenn die E / A abgeschlossen ist, wird sie erneut gestartet.
(...)
Aber jetzt erstellen wir viele zukünftige, die keine E / A-Blockierung erfordern, aber dennoch einen Aufruf an den Scheduler erzwingen, da readline () die Zukunft zurückgibt, vom Aufrufer eine Ausbeute verlangt wird und dies einen Aufruf an den Scheduler bedeutet.
Der Scheduler kann die Steuerung direkt an die Coroutine übertragen, wenn er sieht, dass die bereits abgeschlossene Zukunft angezeigt wird, oder die Zukunft in die Ausführungswarteschlange zurückgeben. Letzteres verlangsamt die Arbeit erheblich (vorausgesetzt, es gibt mehr als eine ausführbare Coroutine), da nicht nur das Warten am Ende der Warteschlange erforderlich ist, sondern wahrscheinlich auch die Lokalität des Speichers (falls überhaupt vorhanden) verloren geht.
(...)
Der Nettoeffekt all dessen ist, dass Coroutine-Autoren über die Ertragszukunft Bescheid wissen müssen, und daher gibt es eine größere psychologische Barriere für die Reorganisation von komplexem Code in besser lesbare Coroutinen - viel stärker als der vorhandene Widerstand, da Funktionsaufrufe in Python ziemlich langsam sind. Und ich erinnere mich aus einem Gespräch mit Glyph, dass Geschwindigkeit in einer typischen asynchronen E / A-Struktur wichtig ist.
Vergleichen wir dies nun mit dem Ertrag von.
(...)
Sie haben vielleicht gehört, dass „Ausbeute aus S“ ungefähr gleichbedeutend ist mit „für i in S: Ausbeute i“. Im einfachsten Fall ist dies wahr, aber dies reicht nicht aus, um Coroutine zu verstehen. Beachten Sie Folgendes (denken Sie noch nicht an asynchrone E / A):
def driver(g): print(next(g)) g.send(42) def gen1(): val = yield 'okay' print(val) driver(gen1())
Dieser Code druckt zwei Zeilen mit "okay" und "42" (und erzeugt dann eine nicht behandelte StopIteration, die Sie unterdrücken können, indem Sie am Ende von gen1 Ausbeute hinzufügen). Sie können diesen Code in Aktion auf pythontutor.com unter dem Link sehen .
Betrachten Sie nun Folgendes:
def gen2(): yield from gen1() driver(gen2())
Es funktioniert genauso . Jetzt denke nach. Wie funktioniert es Die einfache Yield-From-Erweiterung in der for-Schleife kann hier nicht verwendet werden, da in diesem Fall der Code None zurückgeben würde. (Probieren Sie es aus) . Yield-from fungiert als "transparenter Kanal" zwischen Treiber und Gen1. Das heißt, wenn gen1 den Wert "okay" gibt, verlässt es gen2 durch Yield-From an den Treiber, und wenn der Treiber 42 an Gen2 zurücksendet, wird dieser Wert durch Yield-From wieder an Gen1 zurückgegeben (wo er das Ergebnis von Yield wird )
Dasselbe würde passieren, wenn der Treiber einen Fehler in den Generator werfen würde: Der Fehler geht durch die Ausbeute an den internen Generator, der ihn verarbeitet. Zum Beispiel:
def throwing_driver(g): print(next(g)) g.throw(RuntimeError('booh')) def gen1(): try: val = yield 'okay' except RuntimeError as exc: print(exc) else: print(val) yield throwing_driver(gen1())
Der Code gibt "okay" und "bah" sowie den folgenden Code:
def gen2(): yield from gen1()
(Siehe hier: goo.gl/8tnjk )
Jetzt möchte ich einfache (ASCII) Grafiken einführen, um über diese Art von Code sprechen zu können. Ich benutze [f1 -> f2 -> ... -> fN), um den Stapel mit f1 unten (ältester Aufrufrahmen) und fN oben (neuester Aufrufrahmen) darzustellen, wobei jedes Element in der Liste ein Generator ist und -> Rendite ergibt . Das erste Beispiel, Treiber (gen1 ()), hat keine Ausbeute, aber einen Gen1-Generator, also sieht es so aus:
[ gen1 )
Im zweiten Beispiel ruft gen2 gen1 mit Yield-from auf, also sieht es so aus:
[ gen2 -> gen1 )
Ich verwende die mathematische Notation für das halboffene Intervall [...), um zu zeigen, dass rechts ein weiterer Frame hinzugefügt werden kann, wenn der Generator ganz rechts Yield-from verwendet, um einen anderen Generator aufzurufen, während das linke Ende mehr oder weniger fest ist. Das linke Ende ist das, was der Fahrer sieht (d. H. Der Scheduler).
Jetzt bin ich bereit, zum Beispiel readline () zurückzukehren. Wir können readline () als Generator umschreiben, der read () aufruft, einen anderen Generator, der Yield-from verwendet. Letzteres ruft wiederum recv () auf, das die eigentliche Eingabe / Ausgabe über den Socket übernimmt. Auf der linken Seite befindet sich die Anwendung, die wir auch als Generator betrachten, der readline () aufruft und wiederum Yield-from verwendet. Das Schema ist wie folgt:
[ app -> readline -> read -> recv )
Jetzt setzt der Generator recv () E / A, bindet es an die Zukunft und übergibt es mit *ield * (nicht Yield-from!) An den Scheduler. Die Zukunft geht nach links entlang der beiden Ertragspfeile im Scheduler (links von "["). Beachten Sie, dass der Scheduler nicht weiß, dass er einen Stapel von Generatoren enthält. Er weiß nur, dass er den Generator ganz links enthält und gerade eine Zukunft ausgegeben hat. Wenn die E / A abgeschlossen ist, legt der Scheduler das zukünftige Ergebnis fest und sendet es an den Generator zurück. Das Ergebnis bewegt sich entlang der beiden Pfeile nach rechts zum Recv-Generator, der die Bytes empfängt, die er als Ertragsergebnis aus dem Socket lesen wollte.
Mit anderen Worten, der Yield-from-Framework-Scheduler verarbeitet E / A-Operationen genauso wie der zuvor beschriebene Yield-basierte Framework-Scheduler. * Aber: * Er muss sich nicht um die Optimierung kümmern, wenn die Zukunft bereits ausgeführt wird, da der Scheduler nicht an der Übertragung der Kontrolle zwischen readline () und read () oder zwischen read () und recv () beteiligt ist und umgekehrt. Daher nimmt der Scheduler überhaupt nicht teil, wenn app () readline () aufruft und readline () die Anforderung aus dem Puffer erfüllen kann (ohne read ()) aufzurufen - die Interaktion zwischen app () und readline () wird in diesem Fall vollständig vom Bytecode-Interpreter verarbeitet Python Der Scheduler kann einfacher sein und die Anzahl der vom Scheduler erstellten und verwalteten zukünftigen ist geringer, da es keine zukünftigen gibt, die bei jedem Aufruf von coroutine erstellt und zerstört werden. Die einzige Zukunft, die noch benötigt wird, sind diejenigen, die die tatsächliche E / A darstellen, die beispielsweise von recv () erstellt wurde.
Wenn Sie bis zu diesem Punkt gelesen haben, verdienen Sie eine Belohnung. Ich habe viele Implementierungsdetails weggelassen, aber die obige Abbildung spiegelt das Bild im Wesentlichen korrekt wider.
Eine andere Sache, auf die ich hinweisen möchte. * Sie können * einen Teil des Codes dazu bringen, Yield-From zu verwenden, und den anderen Teil Yield verwenden. Der Ertrag erfordert jedoch, dass jedes Glied in der Kette eine Zukunft hat, nicht nur Coroutine. Da die Verwendung von Yield-From mehrere Vorteile bietet, möchte ich, dass sich der Benutzer nicht daran erinnern muss, wann Yield-From verwendet werden soll, und wenn Yield-From verwendet wird, ist es einfacher, immer Yield-From zu verwenden. Eine einfache Lösung ermöglicht es recv () sogar, Yield-from zu verwenden, um zukünftige E / A an den Scheduler zu übergeben: Die Methode __iter__ ist tatsächlich der Generator, den die Zukunft ausgibt.
(...)
Und noch etwas. Welchen Wert hat die Rendite? Es stellt sich heraus, dass dies der Rückgabewert des * externen * Generators ist.
(...)
Obwohl die Pfeile den linken und den rechten Rahmen an das * nachgebende * Ziel binden, übergeben sie auch die üblichen Rückgabewerte auf die übliche Weise, jeweils einen Stapelrahmen nach dem anderen. Ausnahmen werden auf die gleiche Weise verschoben. Natürlich ist auf jeder Ebene ein Versuch / eine Ausnahme erforderlich, um sie zu fangen.
Es stellt sich heraus, dass der Ertrag von so ziemlich dem entspricht, was man erwartet.
Ausbeute von vs async
def coro () ^ y = Ausbeute aus a | async def async_coro (): y = warte auf a |
| 0 load_global | 0 load_global |
| 2 get_yield_from_iter | 2 get_awaitable |
| 4 load_const | 4 load_const |
| 6 Ausbeute_von | 6 Ausbeute_von |
| 8 store_fast | 8 store_fast |
| 10 load_const | 10 load_const
|
| 12 return_value | 12 return_value |
Die beiden Coroutinen der alten und der neuen Schule haben nur einen kleinen Unterschied: Erhalten Sie Ertrag von iter vs erwarten Sie.
Warum ist das alles? Tornado verwendet eine einfache Ausbeute. Vor Version 5 verbindet es diese gesamte Kette von Aufrufen durch Yield, was mit dem neuen Cool Yield from / await-Paradigma schlecht kompatibel ist.
Der einfachste asynchrone Benchmark
Es ist schwierig, ein wirklich gutes Gerüst zu finden, das nur nach synthetischen Tests ausgewählt wird. Im wirklichen Leben können viele Dinge schief gehen.
Ich nahm Aiohttp Version 3.4.4, Tornado 5.1.1, uvloop 0.11, nahm den Intel Xeon Serverprozessor, CPU E5 v4, 3.6 GHz und begann mit Python 3.6.5, Webserver auf Wettbewerbsfähigkeit zu überprüfen.
Das typische Problem, das wir mit Hilfe von Microservices lösen und das im asynchronen Modus arbeitet, sieht so aus. Wir werden Anfragen erhalten. Für jeden von ihnen werden wir eine Anfrage an einen Microservice stellen, Daten von dort abrufen, dann zu zwei oder drei weiteren Microservices gehen, ebenfalls asynchron, dann die Daten irgendwo in die Datenbank schreiben und das Ergebnis zurückgeben. Es stellt sich heraus, dass wir an vielen Punkten warten werden.
Wir führen eine einfachere Operation durch. Wir schalten den Server ein und lassen ihn 50 ms schlafen. Erstellen Sie eine Coroutine und vervollständigen Sie sie. Wir werden kein sehr großes RPS haben (es ist möglicherweise keine Größenordnung ähnlich wie bei vollsynthetischen Benchmarks) mit einer akzeptablen Verzögerung, da sich auf einem wettbewerbsfähigen Server gleichzeitig viel Coroutine dreht.
@tornado.gen.coroutine def old_school_work(): yield tornado.gen.sleep(SLEEP_TIME) async def work(): await tornado.gen.sleep(SLEEP_TIME)
Laden - http-Anfragen abrufen. Dauer - 300s, 1s - Aufwärmen, 5 Wiederholungen der Last.
 Ergebnisse zu Perzentilen der Service-Antwortzeit.
Ergebnisse zu Perzentilen der Service-Antwortzeit.Was sind Perzentile?Sie haben eine große Anzahl von Zahlen. Das 95. Perzentil X bedeutet, dass 95% der Werte in dieser Stichprobe kleiner als X sind. Mit einer Wahrscheinlichkeit von 5% ist Ihre Zahl größer als X.
Wir sehen, dass Aiohttp bei 1000 RPS bei einem so einfachen Test gute Arbeit geleistet hat. Alles soweit ohne
Uvloop .
Vergleichen Sie Tornado mit den Coroutinen der alten (Ertrag) und neuen (Async) Schule. Autoren empfehlen dringend die Verwendung von Async. Wir können sicherstellen, dass sie wirklich viel schneller sind.
Bei 1200 RPS gibt Tornado trotz der neuen Schulkoroutinen bereits auf, und Tornado mit den alten Schulkoroutinen ist völlig weggeblasen. Wenn wir 50 ms schlafen und der Microservice für 80 ms verantwortlich ist, geht dies überhaupt nicht in ein Gate.
Tornados neue Schule mit 1.500 RPS hat vollständig aufgegeben, während Aiohttp noch weit von der Grenze von 3.000 RPS entfernt ist. Das interessanteste kommt noch.
Pyflame, Profilierung eines funktionierenden Microservices
Mal sehen, was gerade mit dem Prozessor passiert.

Als wir herausfanden, wie asynchrone Python-Mikrodienste in der Produktion funktionieren, versuchten wir zu verstehen, worauf es ankam. In den meisten Fällen lag das Problem bei der CPU oder den Deskriptoren. In Uber wurde ein großartiges Profiling-Tool erstellt, der
Pyflame- Profiler, der auf dem Systemaufruf ptrace basiert.
Wir starten einen Dienst im Container und werfen eine Kampfladung darauf. Oft ist dies keine sehr triviale Aufgabe - eine solche Last zu erstellen, die sich im Kampf befindet, da es häufig vorkommt, dass Sie synthetische Tests für Lasttests durchführen, aussehen und alles gut funktioniert. Sie schieben die Kampflast auf ihn, und hier beginnt der Mikrodienst zu stumpfen.
Während des Betriebs erstellt dieser Profiler für uns Snapshots des Aufrufstapels. Sie können den Dienst überhaupt nicht ändern, sondern nur pyflame in der Nähe ausführen. Es wird einmal in einem bestimmten Zeitraum eine Stapelverfolgung sammeln und dann eine coole Visualisierung durchführen. Dieser Profiler verursacht sehr wenig Overhead, insbesondere im Vergleich zu cProfile. Pyflame unterstützt auch Multithread-Programme. Wir haben dieses Ding direkt in das Produkt eingeführt, und die Leistung hat sich nicht wesentlich verschlechtert.
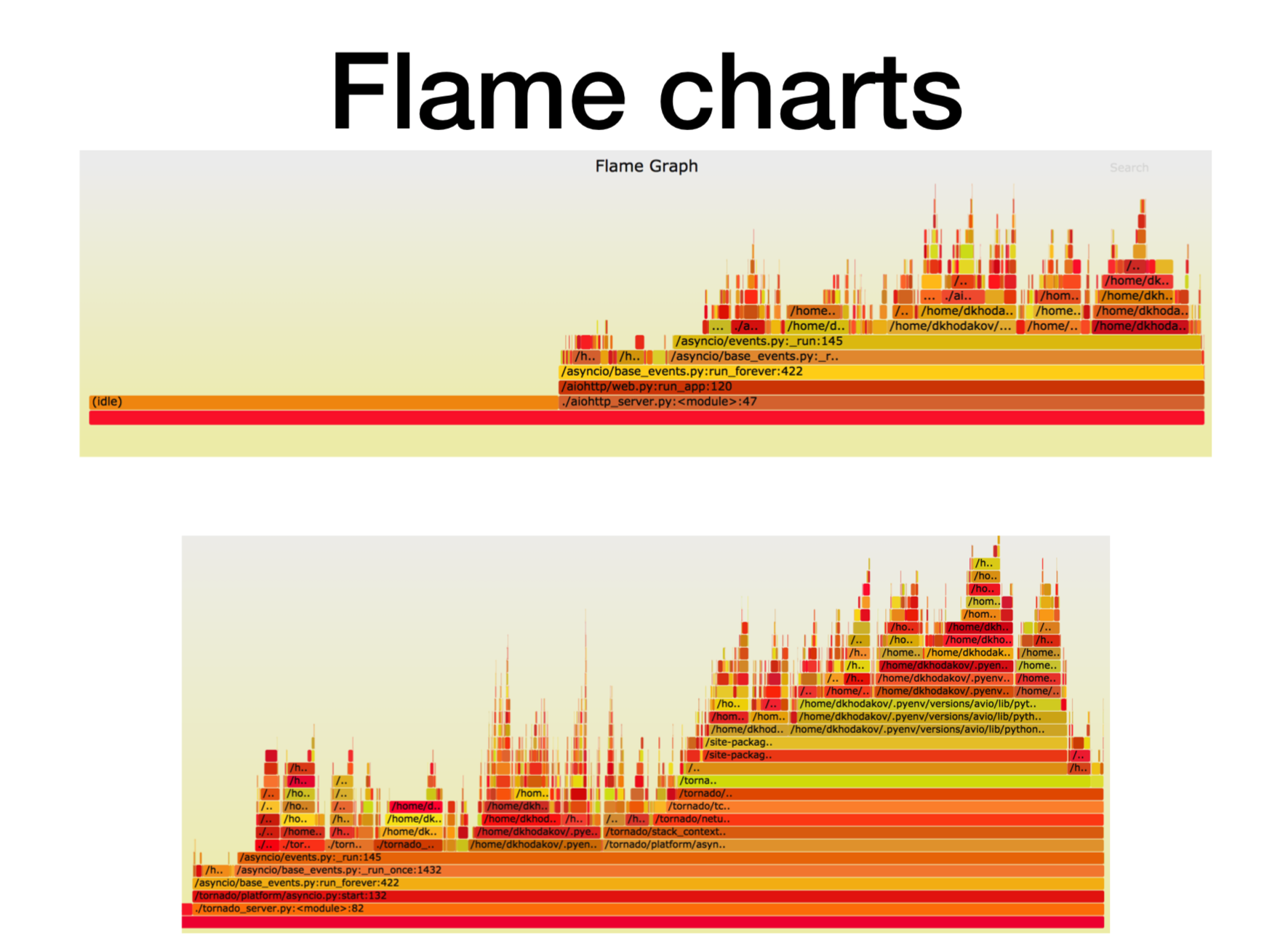
Hier ist die X-Achse die Zeitdauer, die Anzahl der Aufrufe, als der Stapelrahmen auf der Liste aller Python-Stapelrahmen stand. Dies ist die ungefähre Prozessorzeit, die wir in diesem bestimmten Frame des Stapels verbracht haben.
Wie Sie sehen können, geht hier die meiste Zeit in aiohttp in den Leerlauf. Gut: Dies ist das, was wir von einem asynchronen Dienst erwarten, damit er die meiste Zeit mit Netzwerkanrufen umgehen kann. Die Tiefe des Stapels beträgt in diesem Fall etwa 15 Frames.
In Tornado (zweites Bild) mit der gleichen Last wird viel weniger Zeit für den Leerlauf aufgewendet, und die Stapeltiefe beträgt in diesem Fall etwa 30 Frames.
Hier ist ein
Link zu svg , du kannst dich verdrehen.
Komplexerer asynchroner Benchmark
async def work():
Erwarten Sie eine Laufzeit von 125 ms.

Tornado mit Uvloop hält besser. Aber Aiohttp uvloop hilft noch viel mehr. Aiohttp verhält sich bei 2300-2400 RPS schlecht und erweitert mit uvloop den Lastbereich erheblich. Eine Importlinie, und jetzt haben Sie einen viel produktiveren Service.
Zusammenfassung
Ich werde zusammenfassen, was ich Ihnen heute vermitteln wollte.
- Erstens habe ich einen bestimmten künstlichen Benchmark gestartet, bei dem es eine anständige Menge an langer Coroutine gab. In unserem Test schnitt Aiohttp 2,5-mal besser ab als Tornado.
- Die zweite Tatsache. Uvloop hilft sehr gut dabei, die Leistung von Aiohttp zu verbessern (besser als Tornado).
- Ich habe Ihnen von Pyflame erzählt, mit dem wir die Anwendung häufig direkt in der Produktion profilieren.
- Und wir sprachen auch über den Ertrag von (warten) gegen den Ertrag.
Aufgrund dieser Benchmarks ist unser Empfehlungsteam (und einige andere) mit Tornado für Microservices in Python in der Produktion fast vollständig zu Aiohttp gewechselt.
- Bei Kampfdiensten sank der CPU-Verbrauch um mehr als das Zweifache.
- Wir haben angefangen, Zeitüberschreitungen für http-Anfragen zu respektieren.
- Die Latenzdienste gingen zwei- bis fünfmal zurück.
Hier ist ein
Link zum Benchmark . Bei Interesse können Sie es wiederholen. Vielen Dank für Ihre Aufmerksamkeit. Stellen Sie Fragen, ich werde versuchen, sie zu beantworten.