Freunde, Ende Januar werden wir einen neuen Kurs namens "MS SQL Server Developer " starten. Im Vorgriff auf den Start haben wir die Kurslehrerin Kristina Kucherova gebeten , einen Artikel des Autors vorzubereiten. Dieser Artikel ist nützlich, wenn Sie eine sehr beliebte Tabelle auf Prod mit 24/7-Zugriff haben und plötzlich feststellen, dass Sie dringend einen Index hinzufügen müssen, um dabei nichts zu beschädigen.Was tun? Die traditionelle Methode CREATE INDEX WITH (ONLINE = ON) ist für Sie nicht geeignet, da sie beispielsweise einen Systemabsturz und einen Herzinfarkt Ihres DBA verursacht. Alle Spitzen überwachen die Reaktionszeit Ihres Systems genau und kommen, wenn sie zunimmt, zu Ihnen und Ihrem DBA, um zu sprechen in Bezug auf die überschätzten Zahlen Ihrer Arbeitsentschädigung.
Skripte und beschriebene Techniken wurden auf einem System mit einer Last von 400.000 Anforderungen pro Minute verwendet, Versionen von SQL Server 2012 und 2016 (Enterprise).
Es gibt zwei sehr unterschiedliche Ansätze zum Erstellen eines Index, die je nach Größe der Tabelle verwendet werden.
Fall Nr. 1. Ein kleiner, aber sehr beliebter Tisch
Eine Tabelle mit 50.000 Datensätzen (klein), aber sehr beliebt (mehrere tausend Treffer pro Minute). Sie benötigen einen neuen Index und minimale Ausfallzeiten und Sperren für die Tabelle.
In der Anwendung erfolgt der gesamte Zugriff auf die Datenbank nur über Prozeduren.
Wenn ein Fehler auftritt, versucht die Anwendung erneut, auf die Tabelle zuzugreifen.

Was ist das Problem bei der einfachen Anwendung dieses Index? Mit dem Satz WITH ONLINE = ON (ja, wir hatten Glück und dieser war Enterprise).
Tatsache ist, dass es bei einem solchen aktiven Zugriff einige Zeit dauert, bis eine Sperre vorliegt (selbst die minimale, die mit der Option mit Online = EIN benötigt wird). Während des Wartens werden neue Anforderungen in die Warteschlange gestellt, die Warteschlange sammelt sich, die CPU wächst, der DBA schwitzt und blinzelt nervös auf die Entwickler zu, während in den Anwendungsüberwachungsdiagrammen Ihre Antwortzeit reibungslos, aber unvermeidlich zunimmt. Ihr Vice President of Engeneering ist sehr daran interessiert, ob es aufgrund dieser Verlängerung der Reaktionszeit zu Systemausfällen kommen wird, bei denen die Verfügbarkeit der Anwendung zum Jahresende nicht auf 5 Neunen (99.999), sondern auf weniger geschätzt wird. Und dann hat das Unternehmen Verträge, Verpflichtungen und hohe Geldstrafen bei reduzierter Verfügbarkeit, und natürlich werden wir Reputationsverluste nicht vergessen.
Was haben wir getan, um diese unglückliche Situation zu vermeiden?
Das System benötigt noch einen Index.
Sie haben die Rechte von allen außer der aktuellen Sitzung auf diesem Tisch übernommen.
Wenden Sie den Index an.
Ja, die Lösung hat ein Minus: Jeder, der sich in diesen Sekunden an den Tisch gewandt hat, erhält Zugriff verweigert. Wenn Ihre Anwendung normalerweise mit einer solchen Situation umgeht und die Abfrage an die Datenbank wiederholt, sollten Sie sich diese Option genauer ansehen. Bei unserem Projekt hat diese Methode gut funktioniert. Auch hier können Sie ONLINE = ON sicher entfernen, da wir wissen, dass nur die Sitzung während der Indexerstellung Zugriff auf die Tabelle hat.
Code zum Anwenden des Index:
REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User1] REVOKE EXECUTE ON [dbo].[spUserLogin] TO [User2] REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User1] REVOKE EXECUTE ON [dbo].[spUserCreate] TO [User2] CREATE NONCLUSTERED INDEX IX_Users_Email_Status ON [dbo].[Users] ([Email],[Status]); GRANT EXECUTE ON [dbo].[spUserCreate] TO [User1] GRANT EXECUTE ON [dbo].[spUserCreate] TO [User2] GRANT EXECUTE ON [dbo].[spUserLogin] TO [User1] GRANT EXECUTE ON [dbo].[spUserLogin] TO [User2]
Zeitplan für die Antwortzeit und den Prozentsatz der Fehler beim Testen unter Last.
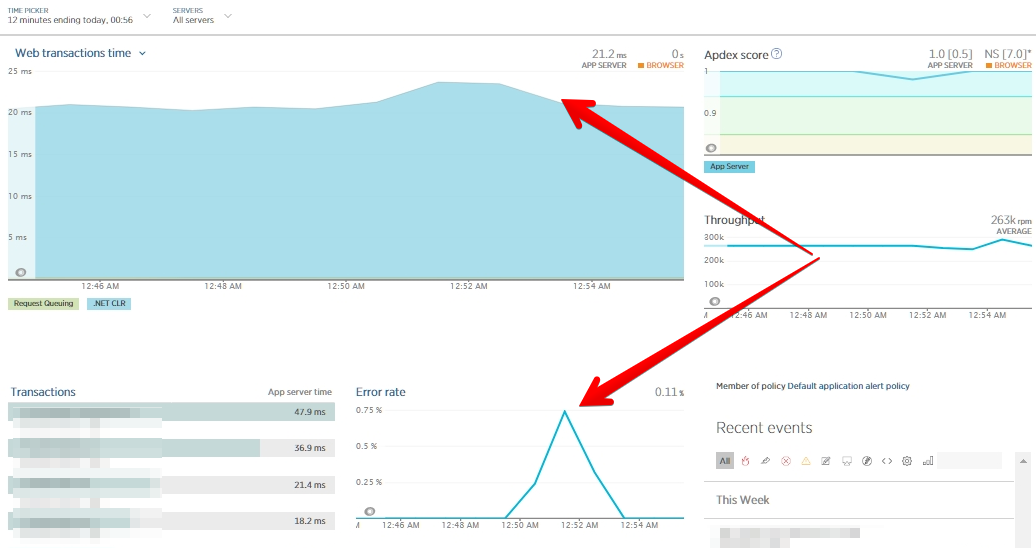
Die Methode kann angewendet werden, wenn Sie wie im beschriebenen Fall eine kleine Tabelle haben und wissen, dass der Index ohne Laden in Sekunden (oder in einer für Sie akzeptablen Zeit) erstellt wird. Gleichzeitig erhöht sich, wie Sie in der obigen Grafik sehen können, die Antwortzeit der Anwendung nicht, obwohl ersichtlich ist, dass die Fehlerrate in Sekunden ohne Zugriff auf die Tabelle höher war.
Fall Nr. 2. Großer Tisch
Wenn Sie eine große Tabelle haben und die Indizes ändern müssen, ist es oft am einfachsten, eine Tabelle mit dem richtigen Index daneben zu erstellen und die Daten schrittweise in eine neue Tabelle zu übertragen.
Es gibt zwei Möglichkeiten:
- Wenn Sie eine spezielle Prozedur zum Ändern einer Tabelle haben, ändern Sie einfach den Prozedurcode so, dass neue Daten nur in die neue Tabelle eingefügt werden, das Löschen von beiden erfolgt, die Aktualisierung auch auf beide angewendet wurde und die Auswahl aus zwei Tabellen mit UNION ALL getroffen wurde.
- Wenn Sie viele verschiedene Teile des Codes haben, in denen Sie die Daten in der Tabelle ändern können, gibt es zwei beliebte Tricks: Anzeigen mit Triggern oder Umschreiben aller Teile des Codes, um Daten in eine neue Tabelle einzufügen, Löschen aus beiden und Aktualisieren beider Tabellen. Eine Ansicht mit Triggern ist eine Option, wenn Sie eine Ansicht mit zwei Tabellen erstellen und umbenennen, Ihre aktuelle Tabelle in TableOld umbenennen und in Tabelle anzeigen. Dann erhalten Sie automatisch den gesamten Tabellenzugriff auf die Ansicht. Hier kann beim Umbenennen ebenfalls ein Problem auftreten, da SchemaLock benötigt wird, das Umbenennen jedoch sehr schnell erfolgt.
Eine etwas detailliertere Version zum Umschreiben von Aufrufen einer neuen Tabelle:
- Sie haben die Orders-Tabelle, erstellen eine neue OrdersNew-Tabelle mit demselben Schema, aber mit dem gewünschten Index. Wenn Sie Indentity verwenden, müssen Sie gleichzeitig den ersten Identitätswert in der neuen Tabelle so einstellen, dass er dem Maximalwert in der alten Tabelle + dem Änderungsschritt oder der Lücke entspricht, die Sie sich leisten können, um vom Maximalwert in Bestellungen abzuweichen.
- Erstellen Sie eine OrdersView, in der eine Auswahl aus Orders UNION ALL OrdersNew
- Ändern Sie alle Prozeduren / Aufrufe, um Daten aus der Ansicht auszuwählen, fügen Sie sie in OrdersNew ein, löschen und ändern Sie beide Tabellen.
- Migrieren Sie beispielsweise Daten von der alten Tabelle in die neue:
DECLARE @rowcount INT, @batchsize INT = 4999; SET IDENTITY_INSERT dbo.OrdersNew ON; SET @rowcount = @batchsize; WHILE @rowcount = @batchsize BEGIN BEGIN TRY DELETE TOP (@batchsize) FROM dbo.Orders OUTPUT deleted.Id ,deleted.Column1 ,deleted.Column2 ,deleted.Column3 INTO dbo.OrdersNew (Id ,Column1 ,Column2 ,Column3); SET @rowcount = @@ROWCOUNT; END TRY BEGIN CATCH SELECT ERROR_NUMBER() AS ErrorNumber, ERROR_MESSAGE() AS ErrorMessage; THROW; END CATCH; END; SET IDENTITY_INSERT dbo.OrdersNew OFF;
- Setzen Sie alle Prozeduren vor der Migration auf die Version zurück - mit einer Tabelle. Dies kann durch Ändern oder durch Löschen und Erstellen von Prozeduren erfolgen (vergessen Sie dann nicht die Rechte), und Sie können die neue Tabelle in Bestellungen umbenennen, die leere Tabelle löschen und anzeigen.
In Schritt 2 war es möglich, die Haupttabelle Orders -> OrdersOld und OrdersView -> Orders - und die Ansicht selbst in OrdersOld UNION ALL OrdersNew umzubenennen, wenn das Laden dies zulässt. Dann müssen Sie nicht alle Stellen ändern, an denen eine Auswahl aus der Tabelle vorhanden ist.
Beim Verschieben von Blöcken von einer Tabelle in eine andere werden die Daten fragmentiert.
Wenn die zu ändernde Tabelle aktiv zum Lesen verwendet wird, sich die darin enthaltenen Daten jedoch selten ändern, können Sie erneut Trigger verwenden - eine Kopie aller Änderungen in die 3. Tabelle schreiben - Daten aus der Tabelle über bcp out und bcp in (oder Bulk Insert) in eine neue Tabelle übertragen Erstellen Sie nach der Datenübertragung Indizes und wenden Sie dann die Änderungen aus der Tabelle mit dem Änderungsprotokoll an - und wechseln Sie eine Tabelle in eine andere - die aktuelle, benennen Sie sie in TableOld um und die neue von TableNew in Table.
Die Fehlerwahrscheinlichkeit ist in dieser Situation etwas höher. Testen Sie daher in diesem Fall die Anwendung von Änderungen und verschiedenen Schaltfällen.
Die beschriebenen Optionen sind nicht die einzigen. Sie wurden von mir in einer stark ausgelasteten SQL Server-Datenbank verwendet und verursachten während der Anwendung keine Probleme, was unserem DBA-Team gefiel. Ein solches Aufprallen ist normalerweise nicht für Basen mit einem ruhigeren Lademodus erforderlich, wenn Sie Änderungen in den Stunden mit der geringsten Aktivität sicher anwenden können. Benutzer des Projekts, die die beschriebenen Ansätze verwendet haben, befinden sich in den USA und in Europa und verwenden die Anwendung an Wochentagen und Wochenenden aktiv. Die Tabellen, auf die die Änderungen angewendet wurden, werden ständig in der Arbeit verwendet. Weitere "leisere" Objekte wurden normalerweise durch automatische Skripte geändert, die über das Redgate Toolkit generiert wurden, nachdem die Skripte vom Entwickler und einem der Datenbankadministratoren überprüft wurden.
Gut zu allen! Teilen Sie in den Kommentaren mit, ob Sie eine dieser Methoden verwendet oder Ihre Methode beschrieben haben! Wir laden Sie auch zu einer offenen Lektion und einem Tag der offenen Tür unseres neuen Kurses "MS SQL Server Developer" ein.