In einem früheren Artikel der HSE in St. Petersburg haben wir gezeigt, wie maschinelles Lernen nach Fehlern im Programmcode suchen kann. In diesem Beitrag werden wir darüber sprechen, wie wir zusammen mit JetBrains Research versuchen, einen der interessantesten, modernsten und am schnellsten wachsenden Bereiche des maschinellen Lernens - das verstärkte Lernen - sowohl in realen praktischen Problemen als auch in Modellbeispielen zu verwenden.

Über mich
Ich heiße Nikita Sazanovich. Bis Juni 2018 habe ich drei Jahre an der SPbAU studiert und bin dann zusammen mit meinen anderen Klassenkameraden an die HSE St. Petersburg gewechselt, wo ich jetzt mein Grundstudium beende. Vor kurzem arbeite ich auch als Forscher bei JetBrains Research. Bevor ich an die Universität kam, liebte ich Sportprogramme und spielte für die belarussische Nationalmannschaft.
Verstärkungstraining
Reinforcement Learning ist ein Zweig des maschinellen Lernens, bei dem der Agent im Umgang mit der Umgebung eine Verstärkung (daher der Name) in Form einer positiven oder negativen Belohnung erhält. Abhängig von diesen Eingabeaufforderungen ändert der Agent sein Verhalten. Das ultimative Ziel dieses Prozesses ist es, die größtmögliche Belohnung zu erhalten oder auf andere Weise die vom Agenten festgelegten Aktionen zu erreichen.
Agenten arbeiten unter Bedingungen und wählen Aktionen aus. Beim Problem des Verlassens des Labyrinths sind unsere Zustände beispielsweise die x- und y-Koordinaten, und die Aktionen sind oben / unten / links / rechts. Das allgemeine Schema sieht folgendermaßen aus:
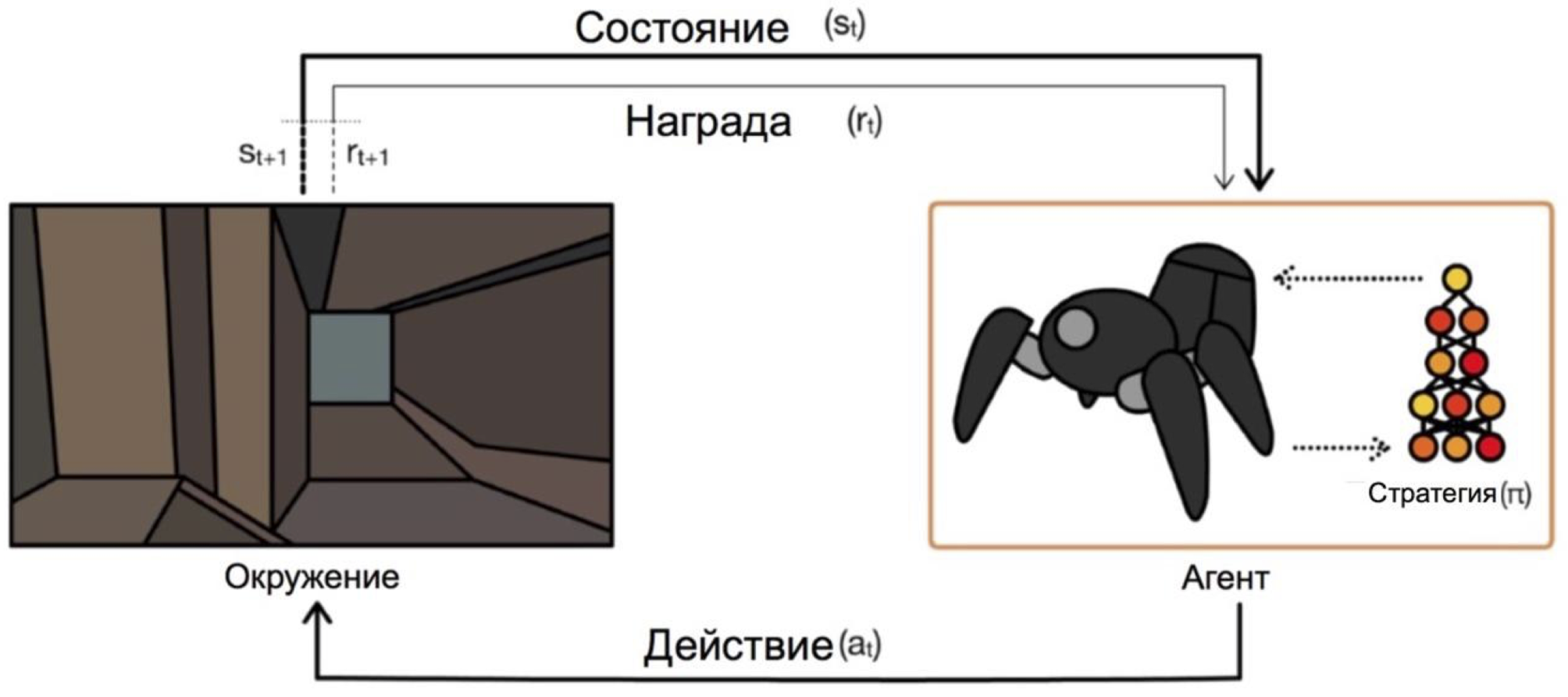
Das Hauptproblem beim Übergang von fiktiven / einfachen Aufgaben (wie dem gleichen Labyrinth) zu realen / praktischen Aufgaben ist folgendes: Belohnungen bei solchen Problemen sind normalerweise sehr selten. Wenn wir zum Beispiel möchten, dass ein Agent Pizza auf einem Stadtplan liefert, wird er verstehen, dass er etwas gut gemacht hat, nur indem er die Bestellung an die Tür geliefert hat, und dies geschieht nur, wenn Sie eine lange und korrekte Abfolge von Aktionen ausführen.
Dieses Problem kann gelöst werden, indem dem Agenten zu Beginn Beispiele für das "Spielen" gegeben werden - die sogenannten Expertendemonstrationen.
Aufgabe zum Lernen
Das Modellproblem, das in diesem Artikel behandelt wird, ist Dota 2.
Dota 2 ist ein beliebtes MOBA-Spiel, in dem ein Team von fünf Helden ein gegnerisches Team besiegen muss, indem es seine "Festung" zerstört. Dota 2 gilt als ziemlich kompliziertes Spiel, es hat Esports mit Preisen im Hauptturnier bei $ 25000000 .
Man konnte von den jüngsten Erfolgen von OpenAI in Dota 2 hören. Zuerst haben sie einen Eins-zu-Eins-Bot erstellt und professionelle Spieler besiegt , dann sind sie zu einem 5x5-Spiel gewechselt und haben diesen Sommer beeindruckende Ergebnisse gezeigt , obwohl sie gegen professionelle Teams verloren haben.

Das einzige Problem ist, dass sie den Agenten für ein Eins-zu-Eins-Spiel auf 60.000 CPUs und 256 K80-GPUs in der Azure-Cloud geschult haben. Sie haben natürlich die Möglichkeit, so viel Macht zu bestellen. Aber wenn Sie weniger Kraft haben, müssen Sie Tricks anwenden. Einer dieser Tricks ist die Verwendung von Spielen, die bereits von Menschen gespielt werden.
Demos im Spiel
In den meisten Fällen werden Demonstrationen künstlich aufgezeichnet: Sie erledigen einfach eine Aufgabe / spielen ein Spiel und sammeln irgendwie die Aktionen, die Sie ausgeführt haben. Sie sammeln also einige Daten, die auf verschiedene Weise in das Training eingebettet werden können. Bisher habe ich das getan, aber wie genau - es wird nach dem Teil über das Schema der Interaktion mit dem Spielclient klar sein.
Ein größeres und abenteuerlicheres Ziel ist es, mehr Daten von Open Access zu erhalten. Einer der Gründe für die Wahl von Dota 2, um das Lernen zu beschleunigen, war eine Ressource wie Dotabuff . Es werden verschiedene Statistiken zum Spiel gesammelt, aber was noch wichtiger ist, es gibt vollständige Wiederholungen der Spiele. Und sie können nach Bewertung sortiert werden.
Bisher habe ich nicht versucht, wie Gigabyte solcher Daten im Vergleich zu mehreren Episoden sehr hilfreich sein werden. Die Datenerfassung war ganz einfach: Sie erhalten Links zu Dotabuff-Spielen, laden Spiele herunter und verwenden den Dota 2 - Spieleparser .
Bündeln Sie mit dem Kunden des Spiels für das Training
Wir haben ein Dota 2-Spiel, dessen Client unter den Plattformen Windows, Linux und MacOS existiert. Aber normalerweise findet das Training in einer Art Python-Skript statt, und darin erstellen Sie eine Umgebung, sei es ein Labyrinth, eine Maschine, die einen Hügel hinaufklettert oder so etwas. Für Dota 2 gibt es jedoch keine Umgebung. Deshalb musste ich selbst diesen Wrapper erstellen, der technisch sehr interessant war. Es stellte sich heraus, dass es so war:
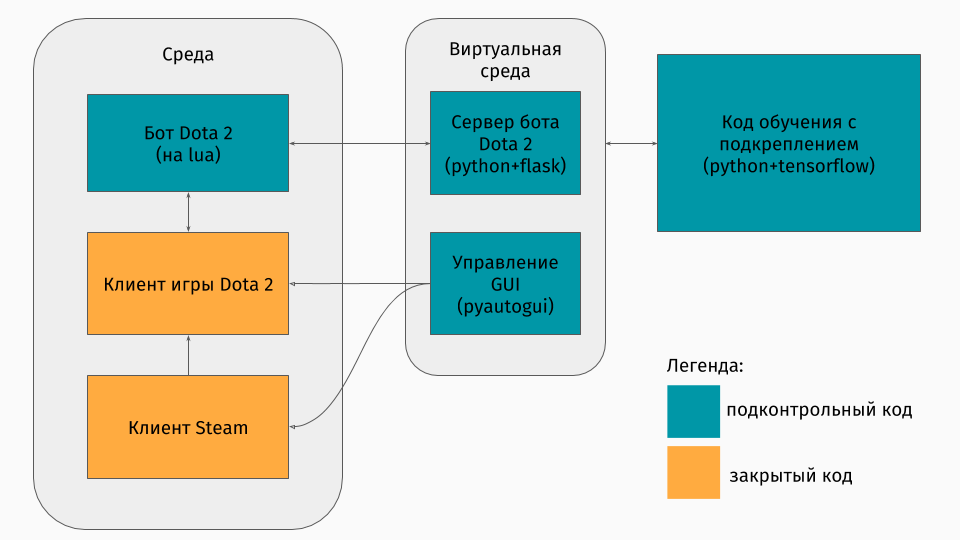
Der erste Teil ist ein Skript für die Kommunikation mit dem Spielclient. Glücklicherweise gibt es für Dota 2 eine offizielle API zum Erstellen von Bots: Dota Bot Scripting . Es ist als Inserts in der Lua-Sprache implementiert, die, wie sich herausstellte, in der Spieleentwicklung beliebt ist. Das Bot-Skript, das mit dem Spielclient interagiert, ruft zum richtigen Zeitpunkt Informationen ab, an denen wir interessiert sind (z. B. Koordinaten auf der Karte, Positionen der Gegner), und sendet damit JSON an den Server.
Der zweite Teil ist der Wrapper selbst. Dies ist als Server konzipiert, der die gesamte Logik zum Starten von Steam, Dota und zum Empfangen von JSON von einem Skript im Spiel verarbeitet. Die Verwaltung des Startens von Spielen und Clients erfolgt über Pyautogui , und die Kommunikation mit dem Lua-Insert im Spiel erfolgt über den Flask-Server.
Der dritte Teil besteht aus dem Lernalgorithmus selbst. Dieser Algorithmus wählt Aktionen aus, empfängt die folgenden Zustände und Belohnungen vom Server, hinter denen die gesamte Kommunikation mit dem Spiel verborgen ist, und verbessert dessen Verhalten.
Von Experten lernen
Der Algorithmus selbst ist in diesem Artikel nicht besonders wichtig, da diese Techniken mit jedem Algorithmus verwendet werden können. Wir haben DQN verwendet (über das Sie auf dem Hub lesen können). Im Wesentlichen ist dies ein tiefes neuronales Netzwerk + Q-Learning- Algorithmus. Ja, dies ist genau der DQN, den DeepMind zum Spielen von Atari-Spielen erstellt hat.
Interessanter ist es auch, über die Verwendung früherer Spiele zu sprechen. Ich habe zwei Ansätze ausprobiert: Potenzialbasierte Belohnungsgestaltung und Handlungsberatung.
Die allgemeine Idee der Ansätze ist, dass der Agent nicht nur für die Ziele der Aufgabe (zum Beispiel am Ende des Labyrinths oder für das Besteigen des Berges), sondern auch während des Trainings bei jedem Schritt eine Belohnung erhält. Diese zusätzliche Belohnung zeigt, wie gut der Agent arbeitet, um das endgültige Ziel zu erreichen. Natürlich möchte ich sie automatisch fragen und nicht die Regeln / Bedingungen auswählen. Die folgenden Ansätze helfen dabei.
Die Essenz einer potenziell basierten Belohnungsformung besteht darin, dass einige Zustände uns zunächst vielversprechender erscheinen als andere, und basierend darauf modifizieren wir die tatsächlichen Belohnungen, die der Algorithmus erhält. Wir machen es so: wo - modifizierte Auszeichnung, - Die Belohnung ist echt, - Abzinsungsfaktor aus dem Lernalgorithmus (für uns nicht sehr wichtig), aber und es gibt unser Potenzial für den Zustand, den wir während besucht haben . Ein einfaches Beispiel ist die Überwindung eines Labyrinths.
Angenommen, es gibt ein Labyrinth, in dem wir von der Zelle (0,0) in die Zelle (5,5) kommen wollen. Dann kann unser Potential für den Zustand (x, y) minus der euklidischen Entfernung von (x, y) zu unserem Ziel (5.5) sein: . Das heißt, je näher wir der Ziellinie kommen, desto größer ist das Potenzial des Staates (zum Beispiel , , ) Deshalb motivieren wir den Agenten mit allen Mitteln, sich dem Ziel zu nähern.
Für Dota 2 ist die Idee dieselbe, aber die Potenziale sind etwas komplizierter:

Stellen Sie sich vor, wir wollen nur die gleichen Zustände wie der Demonstrator durchlaufen. Je mehr Zustände wir passieren, desto höher ist das Potenzial. Wir setzen das Potenzial des Staates durch den Prozentsatz des Abschlusses der Wiederholung, wenn es eine Bedingung gibt, die unserer nahe kommt. Dies hat bei verschiedenen Aufgaben unterschiedliche Bedeutungen. In Dota 2 bedeutet dies jedoch, dass der Bot zunächst das Zentrum erreichen soll (schließlich gibt es zu Beginn der Demonstrationen nur Stufen zum Zentrum) und dann den Zustand des menschlichen Spielers beibehalten hat (gute Gesundheit, sicherer Abstand zu Gegnern usw.). )
Die zweite Methode, Handlungsratschläge, wurde diesem Artikel entnommen. Das Wesentliche ist, dass wir dem Agenten jetzt nicht die Nützlichkeit von Zuständen, sondern die Nützlichkeit von Handlungen empfehlen. Zum Beispiel kann es in unserem Dota 2-Spiel solche Ratschläge geben: Wenn sich ein feindlicher Diener in Ihrer Nähe befindet, greifen Sie ihn an; Wenn Sie das Zentrum nicht erreicht haben, gehen Sie in seine Richtung. Wenn Sie die Gesundheit verlieren, ziehen Sie sich in Ihren Turm zurück. Und dieser Artikel beschreibt eine Methode zum Spezifizieren solcher Tipps, ohne dass der Programmierer selbst darüber nachdenkt - automatisch.
Potentiale werden nach diesem Prinzip erzeugt: Aktionspotential in der Lage
erhöht sich bei Vorhandensein verwandter Bedingungen mit dem gleichen
Aktion in den Demonstrationen. Weitere Belohnung für Maßnahmen im obigen Diagramm
variiert als .
Es ist erwähnenswert, dass wir bereits Potenziale für Maßnahmen in Staaten setzen.
Ergebnisse
Zunächst stelle ich fest, dass das Ziel des Spiels leicht vereinfacht wurde, weil ich alles auf meinem Laptop unterrichtet habe. Das Ziel des Agenten war es, so viele Angriffe wie möglich auszuführen, was in gewisser Weise ein echtes Ziel zu sein scheint. Dazu musst du zuerst in die Mitte der Karte gelangen und dann Gegner angreifen, um nicht zu sterben. Um das Lernen zu beschleunigen, habe ich nur wenige (1 bis 3) zweiminütige Demonstrationen aufgezeichnet.
Das Training eines Agenten mit einem der Ansätze dauert auf einem PC nur 20 Stunden (die meiste Zeit dauert das Rendern eines Dota 2-Spiels), und nach den OpenAI-Diagrammen dauert das Training auf seinen Servern mehrere Wochen.
Kurze Darstellung des Spiels bei Verwendung des potenziell basierten Belohnungsformungsansatzes:
Und für den Aktionsberatungsansatz:
Diese Notizen wurden mit einer Trainingsgeschwindigkeit von x10 gemacht. Ungenauigkeiten im Verhalten des Agenten beim Umzug in die Mitte sind immer noch sichtbar, aber der Kampf in der Mitte zeigt immer noch die erlernten Manöver. Zum Beispiel Rückzug bei schlechter Gesundheit.
Sie können auch die Unterschiede in den Ansätzen erkennen: Bei einer potenziell basierten Belohnungsformung bewegt sich der Agent reibungslos, weil "Geht durch Potenzial"; Mit Handlungsratschlägen spielt der Bot in der Mitte aggressiver, da er Hinweise auf den Angriff erhält.
Zusammenfassung
Ich stelle sofort fest, dass einige Punkte absichtlich weggelassen wurden: Welcher Algorithmus war genau, wie wurde der Zustand dargestellt und ob es möglich ist, einen Agenten für das Spielen mit echten Spielern auszubilden usw.
Zunächst wollte ich in diesem Artikel zeigen, dass Sie bei verstärktem Training nicht immer zwischen einer sehr einfachen Umgebung (Flucht aus dem Labyrinth) oder sehr hohen Schulungskosten wählen müssen (nach meinen flüchtigen Berechnungen hat OpenAI diese Server für das Training in Azure 4715 US-Dollar gekostet pro Stunde). Es gibt Techniken, die das Lernen beschleunigen können, und ich habe nur über eine davon gesprochen - die Verwendung von Demonstrationen. Es ist wichtig zu beachten, dass Sie auf diese Weise den Demonstrator nicht nur wiederholen, sondern nur von ihm „abstoßen“. Es ist wichtig, dass der Agent durch Weiterbildung die Möglichkeit hat, Experten zu übertreffen.
Wenn Sie an den Details interessiert sind, finden Sie den Code für den Trainingsprozess auf GitHub .