Wikibook-Beispiel (Illustration aus einem wissenschaftlichen Artikel )Jeder weiß, dass Wikipedia eine wertvolle Informationsquelle ist. Sie können Stunden damit verbringen, ein Thema zu studieren und von einem Link zum anderen zu wechseln, um den Kontext zu einem Thema von Interesse zu erhalten. Es ist jedoch nicht immer offensichtlich, wie alle Inhalte zu einem gemeinsamen Thema gesammelt werden sollen. Wie kann man zum Beispiel alle Artikel zur anorganischen Chemie oder zur Geschichte des Mittelalters kombinieren und die wichtigsten zusammenfassen? Darüber haben Shahar Admati und seine Kollegen von Ben-Gurion im Negev (Israel), die Entwickler des
Wikibook-Bot- Programms für maschinelles Lernen, versucht, dies zu tun.
Wikipedia und das Lehrbuch sind zwei verschiedene Dinge. Aus diesem Grund wurde das
Wikibooks- Projekt erstellt, in dem gemeinsam versucht wird, das Wichtigste zu einem Thema zusammenzufassen. Beispielsweise finden Sie ein Lehrbuch zum maschinellen Lernen mit mehr als 6.000 Seiten mit aktualisierten Abschnitten zu neuronalen Netzen, genetischen Algorithmen und Bildverarbeitung.
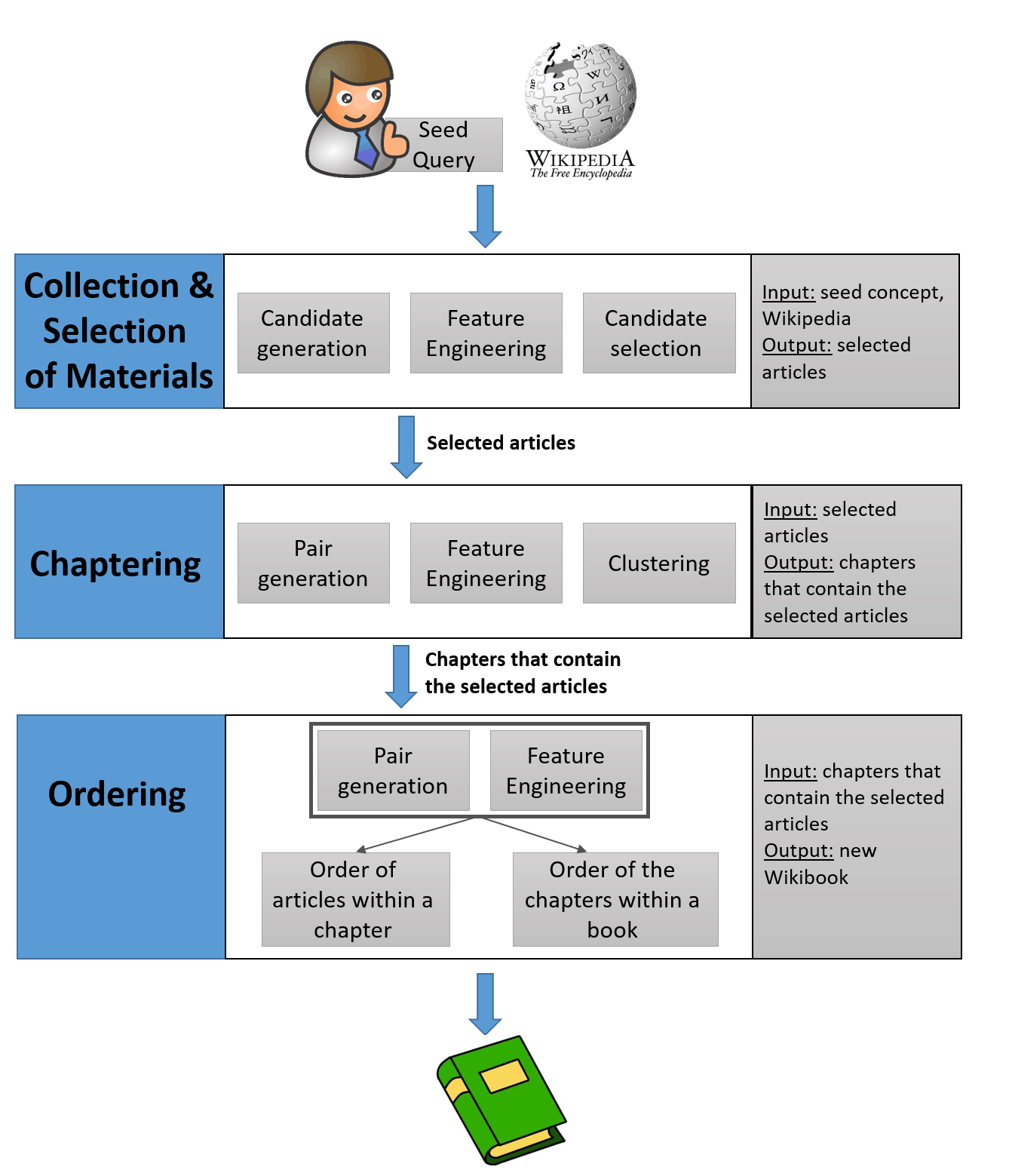
Wikibook-Bot löst mehrere maschinelle Lernaufgaben. Erstens ist dies eine
Klassifizierungsaufgabe, dh Sie müssen feststellen, ob der Artikel zu einem bestimmten Wikibook gehört. Zweitens müssen Sie die ausgewählten Artikel in Kapitel unterteilen - dies ist die Aufgabe des
Clustering . Es wurde durch bekannte Algorithmen gelöst. Schließlich die
Systematisierungsaufgabe , die zwei Unteraufgaben enthält: die Reihenfolge der Artikel in jedem Kapitel und die Reihenfolge der Kapitel selbst.
Tatsächlich funktioniert das Programm relativ einfach. Das Prinzip ist jedem klar, der auf das Lernen neuronaler Netze gestoßen ist. Der erste Schritt besteht darin, einen Trainingsdatensatz zu erstellen. Aus den rund 6.700 vorhandenen Wikibooks in englischer Sprache wurden Bücher mit mehr als 1.000 Ansichten und mit 10 oder mehr Artikeln ausgewählt.

Da diese Wikibooks sowohl für Schulungen als auch für Tests eine Art Goldstandard darstellen, haben die Entwickler dies als Qualitätsstandard angesehen. Nach dem Training des neuronalen Netzwerks wurde die weitere Arbeit in mehrere oben aufgeführte Schritte unterteilt: Klassifizierung, Clustering und Systematisierung. Die Arbeit beginnt mit einem vom Menschen erzeugten Lehrbuchtitel. Der Name beschreibt ein beliebiges Konzept. Zum Beispiel Maschinelles Lernen: Eine vollständige Anleitung.
Die erste Aufgabe besteht darin, den gesamten Satz von Artikeln zu sortieren und festzustellen, welche relevant genug sind, um in dieses Thema aufgenommen zu werden. "Diese Aufgabe ist aufgrund des großen Artikelvolumens auf Wikipedia und der Notwendigkeit, die relevantesten Artikel aus den verfügbaren Millionen auszuwählen, schwierig", schreiben die Autoren in einem wissenschaftlichen Artikel. Um dies zu lösen, verwendeten sie die Wikipedia-Netzwerkstruktur, da einige Artikel häufig auf andere verweisen. Es ist davon auszugehen, dass der zugehörige Artikel auch zum Thema gehört.
Die Arbeit beginnt also mit einem kleinen Kern von Artikeln, in deren Titel ein bestimmter Titel erwähnt wird. Dann werden alle Artikel bestimmt, die sich in einem Abstand von bis zu drei Übergängen vom Kern befinden. Aber wie viele der gefundenen Artikel sind im Lehrbuch enthalten? Die Antwort auf diese Frage geben Wikibooks, die von Menschen erstellt wurden. Durch eine automatische Analyse ihres Inhalts können Sie feststellen, wie viel Inhalt von Wikipedia in von Menschen erstellten Büchern im Lehrbuch enthalten ist.
Jedes von Menschen erstellte Wikibook verfügt über eine Netzwerkstruktur, die durch die Anzahl der Links, die auf andere Artikel verweisen, eine bestimmte Anzahl von Links, die auf Seiten verweisen, die Rangfolge der enthaltenen Artikel usw. definiert ist. Der entwickelte Algorithmus analysiert jeden automatisch ausgewählten Artikel für ein bestimmtes Thema und beantwortet die Frage: Wenn Sie ihn in ein Wikibook aufnehmen, ähnelt seine Netzwerkstruktur eher Büchern, die von einer Person erstellt wurden oder nicht. Wenn nicht, wird der Artikel weggelassen.
Basierend auf den Trainingsdaten und den vorhandenen Methoden des maschinellen Lernens werden auch andere Aufgaben gelöst. Auf diese Weise konnte das Team automatisch Wikibooks generieren, die bereits von Personen erstellt wurden. Die Wirksamkeit der vorgeschlagenen Methode wurde bewertet, indem automatisch generierte Bücher mit 407 echten Wikibooks verglichen wurden. Es wird gesagt, dass es für alle Aufgaben möglich war, beim Vergleich hohe und statistisch signifikante Ergebnisse zu erzielen. Die wahre Wirksamkeit des Algorithmus kann jedoch geschätzt werden, nachdem Wikibooks zu anderen Themen erstellt wurden, und nicht nur zu denen, zu denen er studiert hat.
Die Beschreibung des Bots wurde als wissenschaftlicher Artikel
"Wikibook-Bot - Automatische Generierung von Wikipedia-Büchern" auf der Preprint-Site von arXiv.org veröffentlicht.