
Die Hauptaufgabe von kommerziellen (und auch nichtkommerziellen) Diensten besteht darin, dem Benutzer immer zur Verfügung zu stehen. Obwohl alle abstürzen, stellt sich die Frage, was das IT-Team unternimmt, um sie zu minimieren. Wir haben einen Artikel von Ben Treynor, Mike Dahlin, Vivek Rau und Betsy Beyer „Berechnung der Servicezuverlässigkeit“ übersetzt, in dem beispielsweise Google erklärt, warum 100% ein falscher Bezugspunkt für den Zuverlässigkeitsindikator ist, was die „Regel der vier Neunen“ ist und Wie kann in der Praxis die Machbarkeit großer und kleiner Ausfälle des Dienstes und / oder seiner kritischen Komponenten mathematisch vorhergesagt werden - die erwartete Ausfallzeit, die Zeit, die zum Erkennen eines Fehlers benötigt wird, und die Zeit zum Wiederherstellen des Dienstes.
Berechnung der Servicezuverlässigkeit
Ihr System ist so zuverlässig wie seine Komponenten
Ben Trainor, Mike Dalin, Vivec Rau und Betsy Beyer
Wie im Buch „ Site Reliability Engineering: Zuverlässigkeit und Zuverlässigkeit wie bei Google “ (im Folgenden als SRE-Buch bezeichnet) beschrieben, kann durch die Entwicklung von Google-Produkten und -Diensten eine hohe Geschwindigkeit der Freigabe neuer Funktionen erreicht werden, während aggressive SLO (Service-Level-Ziele, Service-Level-Ziele) beibehalten werden. ) um eine hohe Zuverlässigkeit und schnelle Reaktion zu gewährleisten. SLOs erfordern, dass der Service fast immer in gutem Zustand und fast immer schnell ist. Darüber hinaus geben SLOs auch die genauen Werte dieses „fast immer“ für einen bestimmten Dienst an. SLOs basieren auf folgenden Beobachtungen:
Im allgemeinen Fall ist für jeden Softwaredienst oder jedes System 100% der falsche Bezugspunkt für den Zuverlässigkeitsindikator, da kein Benutzer den Unterschied zwischen 100% und 99.999% Verfügbarkeit feststellen kann. Zwischen dem Benutzer und dem Dienst gibt es viele andere Systeme (sein Laptop, WLAN zu Hause, Anbieter, Netzteil ...), und alle diese Systeme sind in 99,999% der Fälle nicht verfügbar, aber viel seltener. Daher geht die Differenz zwischen 99,999% und 100% aufgrund zufälliger Faktoren verloren, die durch die Unzugänglichkeit anderer Systeme verursacht werden, und der Benutzer profitiert nicht davon, dass wir uns viel Mühe gegeben haben, um diesen letzten Bruchteil des Prozentsatzes der Systemverfügbarkeit zu erreichen. Schwerwiegende Ausnahmen von dieser Regel sind Antiblockiersysteme und Herzschrittmacher!
Eine ausführliche Beschreibung der Beziehung zwischen SLOs und SLIs (Service Level Indicators) und SLAs (Service Level Agreements) finden Sie im Kapitel SRE Target Level of Service. In diesem Kapitel wird auch ausführlich beschrieben, wie Metriken ausgewählt werden, die für einen bestimmten Dienst oder ein bestimmtes System relevant sind. Dies bestimmt wiederum die Auswahl des geeigneten SLO für diesen Dienst oder dieses System.
Dieser Artikel erweitert das SLO-Thema, um sich auf Servicekomponenten zu konzentrieren. Insbesondere werden wir untersuchen, wie sich die Zuverlässigkeit kritischer Komponenten auf die Zuverlässigkeit eines Dienstes auswirkt und wie Systeme entworfen werden, um die Auswirkungen zu verringern oder die Anzahl kritischer Komponenten zu verringern.
Die meisten von Google angebotenen Dienste zielen darauf ab, Nutzern eine Zugänglichkeit von 99,99 Prozent (manchmal als "vier Neunen" bezeichnet) zu bieten. Für einige Dienste ist in der Benutzervereinbarung eine niedrigere Anzahl angegeben, das Ziel von 99,99% ist jedoch im Unternehmen gespeichert. Diese höhere Leiste bietet einen Vorteil in Situationen, in denen sich Benutzer lange vor dem Verstoß gegen die Vertragsbedingungen über die Leistung des Dienstes beschweren, da das Ziel Nummer 1 des SRE-Teams darin besteht, Benutzer mit den Diensten zufrieden zu stellen. Für viele Dienste stellt ein internes Ziel von 99,99% den Mittelweg dar, der Kosten, Komplexität und Zuverlässigkeit in Einklang bringt. Für einige andere, insbesondere globale Cloud-Dienste, liegt das interne Ziel bei 99,999%.
Zuverlässigkeit 99,99%: Beobachtungen und Schlussfolgerungen
Schauen wir uns einige wichtige Beobachtungen und Schlussfolgerungen zum Design und Betrieb des Dienstes mit einer Zuverlässigkeit von 99,99% an und fahren wir dann mit der Praxis fort.
Beobachtung Nr. 1: Fehlerursachen
Fehler treten aus zwei Hauptgründen auf: Probleme mit dem Dienst selbst und Probleme mit kritischen Komponenten des Dienstes. Eine kritische Komponente ist eine Komponente, die im Falle eines Fehlers einen entsprechenden Fehler im Betrieb des gesamten Dienstes verursacht.
Beobachtung Nr. 2: Mathematik der Zuverlässigkeit
Die Zuverlässigkeit hängt von der Häufigkeit und Dauer der Ausfallzeiten ab. Es wird gemessen durch:
- Leerlauffrequenz oder umgekehrt: MTTF (mittlere Zeit bis zum Ausfall).
- Ausfallzeit, MTTR (mittlere Reparaturzeit). Die Ausfallzeit wird durch die Zeit des Benutzers bestimmt: vom Beginn der Fehlfunktion bis zur Wiederaufnahme des normalen Betriebs des Dienstes.
Somit wird Zuverlässigkeit mathematisch als MTTF / (MTTF + MTTR) unter Verwendung der entsprechenden Einheiten definiert.
Schlussfolgerung Nr. 1: Regel der zusätzlichen Neunen
Ein Service kann nicht zuverlässiger sein als alle seine kritischen Komponenten zusammen. Wenn Ihr Service eine Verfügbarkeit von 99,99% sicherstellen möchte, sollten alle kritischen Komponenten in deutlich mehr als 99,99% der Fälle verfügbar sein.
In Google verwenden wir die folgende Faustregel: Kritische Komponenten müssen im Vergleich zur deklarierten Zuverlässigkeit Ihres Dienstes zusätzliche Neunen bereitstellen - im obigen Beispiel 99,999 Prozent Verfügbarkeit -, da jeder Dienst mehrere kritische Komponenten sowie seine eigenen spezifischen Probleme aufweist. Dies wird als "Regel der zusätzlichen Neunen" bezeichnet.
Wenn Sie eine kritische Komponente haben, die nicht genügend Neunen liefert (ein relativ häufiges Problem!), Sollten Sie die negativen Folgen minimieren.
Schlussfolgerung Nr. 2: Mathematik der Frequenz, Erkennungszeit und Erholungszeit
Ein Service kann nicht zuverlässiger sein als das Produkt aus der Häufigkeit von Vorfällen und dem Zeitpunkt der Erkennung und Wiederherstellung. Beispielsweise führen drei Abschaltungen pro Jahr von jeweils 20 Minuten zu einer Ausfallzeit von insgesamt 60 Minuten. Selbst wenn der Service den Rest des Jahres einwandfrei funktioniert hätte, wäre eine Zuverlässigkeit von 99,99 Prozent (nicht mehr als 53 Minuten Ausfallzeit pro Jahr) unmöglich.
Dies ist eine einfache mathematische Beobachtung, die jedoch häufig übersehen wird.
Schlussfolgerung aus den Schlussfolgerungen Nr. 1 und Nr. 2
Wenn das Maß an Zuverlässigkeit, auf das sich Ihr Service stützt, nicht erreicht werden kann, müssen Anstrengungen unternommen werden, um die Situation zu korrigieren - entweder durch Erhöhen der Verfügbarkeit des Service oder durch Minimieren der oben beschriebenen negativen Folgen. Das Verringern der Erwartungen (d. H. Der deklarierten Zuverlässigkeit) ist ebenfalls eine Option und häufig die zutreffendste: Machen Sie dem von Ihnen abhängigen Dienst klar, dass er entweder sein System neu erstellen muss, um den Fehler in der Zuverlässigkeit Ihres Dienstes zu kompensieren, oder seine eigenen Service-Level-Ziele zu reduzieren . Wenn Sie die Diskrepanz nicht selbst beseitigen, erfordert ein ausreichend langer Ausfall des Systems zwangsläufig Anpassungen.
Praktische Anwendung
Schauen wir uns ein Beispiel für einen Service mit einer Zielzuverlässigkeit von 99,99% an und erarbeiten die Anforderungen für seine Komponenten und arbeiten mit seinen Fehlern.
Zahlen
Angenommen, Ihr 99,99-Prozent-Service ist mit den folgenden Merkmalen verfügbar:
- Ein größerer Ausfall und drei kleinere Ausfälle pro Jahr. Das klingt beängstigend, aber beachten Sie, dass ein Vertrauensniveau von 99,99% eine große Ausfallzeit von 20 bis 30 Minuten und einige kurze teilweise Abschaltungen pro Jahr impliziert. (Aus der Mathematik geht Folgendes hervor: a) Der Ausfall eines Segments wird aus Sicht von SLO nicht als Ausfall des gesamten Systems angesehen, und b) die Gesamtzuverlässigkeit wird aus der Summe der Zuverlässigkeit der Segmente berechnet.)
- Fünf kritische Komponenten in Form anderer unabhängiger Dienste mit einer Zuverlässigkeit von 99,999%.
- Fünf unabhängige Segmente, die nicht nacheinander ausfallen können.
- Alle Änderungen werden schrittweise segmentweise durchgeführt.
Die mathematische Berechnung der Zuverlässigkeit lautet wie folgt:
Komponentenanforderungen
- Die Gesamtfehlergrenze für das Jahr beträgt 0,01 Prozent von 525.600 Minuten pro Jahr oder 53 Minuten (basierend auf dem 365-Tage-Jahr im schlimmsten Fall).
- Die für das Herunterfahren kritischer Komponenten zugewiesene Grenze beträgt fünf unabhängige kritische Komponenten mit einer Grenze von jeweils 0,001% = 0,005%; 0,005% von 525.600 Minuten pro Jahr oder 26 Minuten.
- Die verbleibende Fehlergrenze Ihres Dienstes beträgt 53-26 = 27 Minuten.
Antwortanforderungen für das Herunterfahren
- Erwartete Ausfallzeit: 4 (1 vollständige Abschaltung und 3 Abschaltungen, die nur ein Segment betreffen)
- Der kumulative Effekt der erwarteten Ausfälle: (1 × 100%) + (3 × 20%) = 1,6
- Fehlererkennung und -behebung danach: 27 / 1,6 = 17 Minuten
- Zeit für die Überwachung, um einen Fehler zu erkennen und darüber zu informieren: 2 Minuten
- Zeit, die dem diensthabenden Spezialisten zur Analyse des Alarms eingeräumt wird: 5 Minuten. (Das Überwachungssystem sollte SLO-Verstöße verfolgen und bei jedem Systemausfall ein Signal an den diensthabenden Pager senden. Viele Google-Dienste werden von diensthabenden Schicht-SR-Ingenieuren unterstützt, die auf dringende Fragen antworten.)
- Verbleibende Zeit zur wirksamen Minimierung von Nebenwirkungen: 10 Minuten
Fazit: Hebelwirkung zur Erhöhung der Servicezuverlässigkeit
Es lohnt sich, die vorgestellten Zahlen sorgfältig zu betrachten, da sie den grundlegenden Punkt betonen: Es gibt drei Haupthebel zur Erhöhung der Zuverlässigkeit des Dienstes.
- Reduzieren Sie die Häufigkeit von Ausfällen - durch Freigaberichtlinien, Tests, regelmäßige Bewertungen der Projektstruktur usw.
- Reduzieren Sie Ihre durchschnittliche Ausfallzeit durch Segmentierung, geografische Isolation, allmähliche Verschlechterung oder Kundenisolation.
- Reduzieren Sie die Wiederherstellungszeit - durch Überwachung, Ein-Knopf-Rettungsvorgänge (z. B. Zurücksetzen auf einen früheren Status oder Hinzufügen von Standby-Strom), Betriebsbereitschaftspraktiken usw.
Sie können zwischen diesen drei Methoden abwägen, um die Implementierung der Fehlertoleranz zu vereinfachen. Wenn es beispielsweise schwierig ist, eine 17-minütige MTTR zu erreichen, konzentrieren Sie sich auf die Reduzierung der durchschnittlichen Ausfallzeiten. Strategien zur Minimierung nachteiliger Auswirkungen und zur Abschwächung der Auswirkungen kritischer Komponenten werden später in diesem Artikel ausführlicher erläutert.
Erläuterung „Regeln für zusätzliche Neunen“ für verschachtelte Komponenten
Ein zufälliger Leser kann daraus schließen, dass jedes zusätzliche Glied in der Abhängigkeitskette zusätzliche neun erfordert, so dass zwei zusätzliche neun für Abhängigkeiten zweiter Ordnung, drei zusätzliche neun für Abhängigkeiten dritter Ordnung usw. erforderlich sind.
Dies ist die falsche Schlussfolgerung. Es basiert auf einem naiven Modell einer Hierarchie von Komponenten in Form eines Baumes mit einer konstanten Verzweigung auf jeder Ebene. In einem solchen Modell, wie in Abb. In 1 gibt es 10 eindeutige Komponenten erster Ordnung, 100 eindeutige Komponenten zweiter Ordnung, 1.000 eindeutige Komponenten dritter Ordnung usw., was zu insgesamt 1.111 eindeutigen Diensten führt, selbst wenn die Architektur auf vier Schichten beschränkt ist. Ein Ökosystem hochzuverlässiger Dienste mit so vielen unabhängigen kritischen Komponenten ist eindeutig unrealistisch.
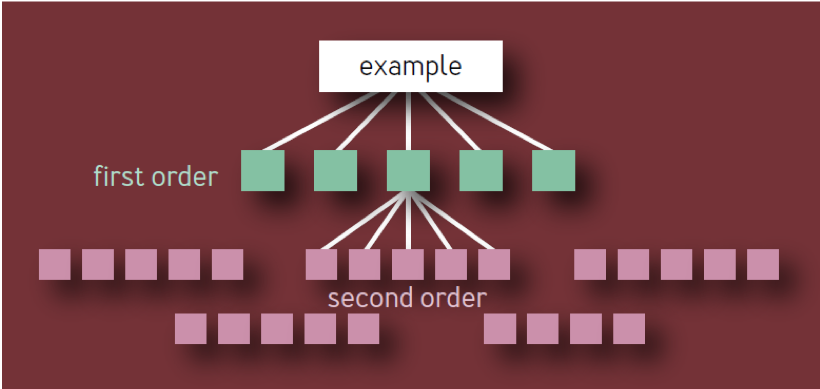
Abb. 1 - Komponentenhierarchie: Ungültiges Modell
Eine kritische Komponente an sich kann den Ausfall des gesamten Dienstes (oder Dienstsegments) verursachen, unabhängig davon, wo sie sich im Abhängigkeitsbaum befindet. Wenn eine bestimmte Komponente von X als Abhängigkeit von mehreren Komponenten erster Ordnung angezeigt wird, sollte X daher nur einmal gezählt werden, da ihr Ausfall letztendlich zu einem Dienstausfall führt, unabhängig davon, wie viele Zwischendienste ebenfalls betroffen sind.
Eine korrekte Lesart der Regel lautet wie folgt:
- Wenn ein Dienst N eindeutige kritische Komponenten enthält, trägt jede von ihnen 1 / N zur Unzuverlässigkeit des gesamten durch diese Komponente verursachten Dienstes bei, unabhängig davon, wie niedrig sie in der Hierarchie der Komponenten ist.
- Jede Komponente sollte nur einmal gezählt werden, auch wenn sie mehrmals in der Komponentenhierarchie vorkommt (mit anderen Worten, es werden nur eindeutige Komponenten gezählt). Zum Beispiel bei der Berechnung der Komponenten von Service A in Abb. 2, Service B sollte nur einmal berücksichtigt werden.
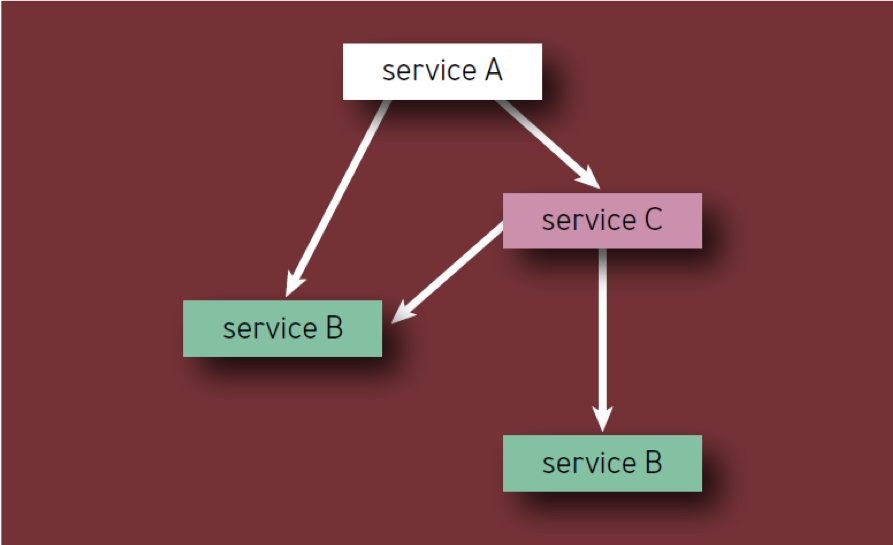
Abb. 2 - Komponenten in der Hierarchie
Betrachten Sie beispielsweise einen hypothetischen Dienst A mit einer Fehlergrenze von 0,01 Prozent. Servicebesitzer sind bereit, die Hälfte dieses Limits für ihre eigenen Fehler und Verluste und die Hälfte für kritische Komponenten auszugeben. Wenn der Dienst N solche Komponenten hat, erhält jede von ihnen 1 / N der verbleibenden Fehlergrenze. Typische Dienste haben häufig 5 bis 10 kritische Komponenten, und daher kann jeder von ihnen nur einen zehnten oder einen zwanzigsten Grad der Fehlergrenze von Dienst A ablehnen. Daher sollten kritische Teile des Dienstes in der Regel eine zusätzliche Zuverlässigkeit von neun aufweisen.
Fehlergrenzen
Das Konzept der Fehlergrenzen wird im Buch SRE ausführlich behandelt, hier sollte es jedoch erwähnt werden. Google SR-Ingenieure verwenden Fehlergrenzen, um die Zuverlässigkeit und das Tempo von Updates auszugleichen. Diese Grenze bestimmt den akzeptablen Ausfallgrad für den Dienst für einen bestimmten Zeitraum (normalerweise einen Monat). Das Fehlerlimit beträgt nur 1 abzüglich des SLO des Dienstes, sodass der zuvor diskutierte 99,99-prozentige verfügbare Dienst ein 0,01-prozentiges „Limit“ für die Unzuverlässigkeit aufweist. Bis der Dienst sein Fehlerlimit innerhalb eines Monats aufgebraucht hat, kann das Entwicklungsteam (innerhalb eines angemessenen Rahmens) neue Funktionen, Updates usw. starten.
Wenn das Fehlerlimit aufgebraucht ist, werden Änderungen am Dienst ausgesetzt (mit Ausnahme dringender Sicherheitskorrekturen und Änderungen, die den Verstoß überhaupt verursachen sollen), bis der Dienst die Reserve im Fehlerlimit wieder auffüllt oder bis sich der Monat ändert. Viele Dienste bei Google verwenden eine Schiebefenstermethode für SLO, damit die Fehlergrenze schrittweise wiederhergestellt wird. Bei seriösen Diensten mit einem SLO von mehr als 99,99% ist es ratsam, das Limit vierteljährlich und nicht monatlich auf Null zu setzen, da die Anzahl der zulässigen Ausfallzeiten gering ist.
Fehlergrenzen beseitigen Spannungen zwischen Abteilungen, die andernfalls zwischen SR-Ingenieuren und Produktentwicklern auftreten könnten, und bieten ihnen ein gemeinsames, datenbasiertes Tool zur Risikobewertung für die Produkteinführung. Sie geben den SR-Ingenieuren und Entwicklungsteams auch das gemeinsame Ziel, Methoden und Technologien zu entwickeln, mit denen sie schneller innovieren und Produkte ohne „aufgeblähtes Budget“ auf den Markt bringen können.
Strategien zur Reduzierung und Reduzierung kritischer Komponenten
An dieser Stelle haben wir in diesem Artikel die sogenannte "Goldene Regel für die Zuverlässigkeit von Komponenten" festgelegt. Dies bedeutet, dass die Zuverlässigkeit einer kritischen Komponente zehnmal höher sein sollte als die angestrebte Zuverlässigkeitsstufe des gesamten Systems, damit ihr Beitrag zur Unzuverlässigkeit des Systems auf der Fehlerstufe bleibt. Daraus folgt, dass es im Idealfall die Aufgabe ist, möglichst viele Komponenten unkritisch zu machen. Dies bedeutet, dass Komponenten ein geringeres Maß an Zuverlässigkeit aufweisen können, sodass Entwickler die Möglichkeit haben, Innovationen vorzunehmen und Risiken einzugehen.
Die einfachste und naheliegendste Strategie zur Reduzierung kritischer Abhängigkeiten besteht darin, einzelne Fehlerquellen nach Möglichkeit zu beseitigen. Ein größeres System sollte in der Lage sein, ohne eine bestimmte Komponente, die keine kritische Abhängigkeit oder SPOF darstellt, akzeptabel zu arbeiten.
Tatsächlich können Sie höchstwahrscheinlich nicht alle kritischen Abhängigkeiten beseitigen. Sie können jedoch einige Richtlinien für das Systemdesign befolgen, um die Zuverlässigkeit zu optimieren. Obwohl dies nicht immer möglich ist, ist es einfacher und effizienter, eine hohe Systemzuverlässigkeit zu erreichen, wenn Sie die Zuverlässigkeit in der Entwurfs- und Planungsphase festlegen und nicht, nachdem das System funktioniert und die tatsächlichen Benutzer betrifft.
Bewertung der Projektstruktur
Bei der Planung eines neuen Systems oder Dienstes oder bei der Neugestaltung oder Verbesserung eines vorhandenen Systems oder Dienstes kann eine Überprüfung der Architektur oder des Projekts eine gemeinsame Infrastruktur sowie interne und externe Abhängigkeiten aufzeigen.
Gemeinsame Infrastruktur
Wenn Ihr Dienst eine gemeinsam genutzte Infrastruktur verwendet (z. B. den Hauptdatenbankdienst, der von mehreren Produkten verwendet wird, die Benutzern zur Verfügung stehen), prüfen Sie, ob diese Infrastruktur ordnungsgemäß verwendet wird. Identifizieren Sie die Eigentümer der gemeinsam genutzten Infrastruktur eindeutig als zusätzliche Projektteilnehmer. Achten Sie auch auf Komponentenüberlastungen. Koordinieren Sie dazu den Startvorgang sorgfältig mit den Eigentümern dieser Komponenten.
Interne und externe Abhängigkeiten
Manchmal hängt ein Produkt oder eine Dienstleistung von Faktoren ab, die außerhalb der Kontrolle Ihres Unternehmens liegen - beispielsweise von Softwarebibliotheken oder Diensten und Daten von Dritten. Die Identifizierung dieser Faktoren minimiert die unvorhersehbaren Folgen ihrer Verwendung.
Planen und entwerfen Sie Systeme sorgfältig
Beachten Sie beim Entwurf Ihres Systems die folgenden Grundsätze:
Redundanz und Isolation
Sie können versuchen, die Auswirkungen der kritischen Komponente zu verringern, indem Sie mehrere unabhängige Instanzen davon erstellen. Wenn das Speichern von Daten in einer Instanz beispielsweise eine Verfügbarkeit dieser Daten von 99,9 Prozent sicherstellt, ergibt das Speichern von drei Kopien in drei weit verbreiteten Kopien theoretisch eine Verfügbarkeitsstufe von 1 bis 0,013 oder neun Neunen, wenn der Ausfall der Instanz bei einer Korrelation von Null unabhängig ist.
In der realen Welt ist die Korrelation niemals Null (berücksichtigen Sie die Ausfälle des Backbone-Netzwerks, die viele Zellen gleichzeitig betreffen), sodass die tatsächliche Zuverlässigkeit niemals nahe an neun Neunen heranreicht, sondern drei Neunen bei weitem überschreitet.
In ähnlicher Weise kann das Senden eines RPC (Remote Procedure Call) an einen Serverpool im selben Cluster eine 99-prozentige Verfügbarkeit der Ergebnisse gewährleisten, während das gleichzeitige Senden von drei RPCs an drei verschiedene Serverpools und das Akzeptieren der ersten Antwort zum Erreichen der Verfügbarkeitsstufe beitragen höher als drei Neunen (siehe oben). Diese Strategie kann auch die Verzögerung der Antwortzeit verkürzen, wenn die Serverpools gleich weit vom RPC-Absender entfernt sind. (Da die Kosten für das gleichzeitige Senden von drei RPCs hoch sind, teilt Google die Zeit für diese Anrufe häufig strategisch zu: Die meisten unserer Systeme erwarten einen Teil der zugewiesenen Zeit vor dem Senden des zweiten RPC und etwas mehr Zeit vor dem Senden des dritten RPC.)
Reserve und ihre Anwendung
Richten Sie den Start und die Portierung der Software so ein, dass die Systeme weiterhin funktionieren, wenn einzelne Teile ausfallen (ausfallsicher) und sich bei Problemen isolieren. Das Grundprinzip hierbei ist, dass Sie wahrscheinlich Ihre Fehlergrenze überschreiten, wenn Sie die Person zum Einschalten der Reserve verbinden.
Asynchronität
Entwerfen Sie Komponenten nach Möglichkeit asynchron, um zu verhindern, dass sie kritisch werden. Wenn ein Dienst eine RPC-Antwort von einem seiner unkritischen Teile erwartet, die eine starke Verlangsamung der Antwortzeit anzeigt, wird durch diese Verlangsamung die Leistung des übergeordneten Dienstes unnötig beeinträchtigt. Wenn Sie den RPC für eine nicht kritische Komponente auf den asynchronen Modus einstellen, wird die Antwortzeit des übergeordneten Dienstes nicht an die Leistung dieser Komponente gebunden. Und obwohl Asynchronität den Code und die Infrastruktur des Dienstes komplizieren kann, lohnt sich dieser Kompromiss dennoch.
Ressourcenplanung
Stellen Sie sicher, dass alle Komponenten mit allem ausgestattet sind, was Sie benötigen. , — .
, \ .
, . . . , .
SLO. , , . , , , MTTR .
, . :
, , , . :
, : , , . — , . , , , .
, . , Google , 10 .
Fazit
, , , , . , . Google , , (. SRE, B: ).