Etwas mehr als ein Jahr lang fand unter meiner Teilnahme der folgende "Dialog" statt:
.Net App : Hey Entity Framework, gib mir bitte viele Daten!
Entity Framework : Entschuldigung, ich habe Sie nicht verstanden. Was meinst du?
.Net App : Ja, ich habe gerade eine Sammlung von 100.000 Transaktionen erhalten. Und jetzt müssen wir schnell die Richtigkeit der dort angegebenen Wertpapierpreise überprüfen.
Entity Framework : Ahh, nun, lass es uns versuchen ...
.Net App : Hier ist der Code:
var query = from p in context.Prices join t in transactions on new { p.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; query.ToList();
Entity Framework :

Klassisch Ich denke, viele Leute sind mit dieser Situation vertraut: Wenn ich wirklich „schön“ und schnell eine Suche in der Datenbank mit dem JOIN der lokalen Sammlung und DbSet durchführen möchte . Normalerweise ist diese Erfahrung enttäuschend.
In diesem Artikel (der eine kostenlose Übersetzung meines anderen Artikels ist ) werde ich eine Reihe von Experimenten durchführen und verschiedene Wege ausprobieren, um diese Einschränkung zu umgehen. Es wird einen Code (unkompliziert), Gedanken und so etwas wie ein Happy End geben.
Einführung
Jeder kennt das Entity Framework , viele verwenden es jeden Tag und es gibt viele gute Artikel darüber, wie man es richtig kocht (verwenden Sie einfachere Abfragen, verwenden Sie die Parameter in Skip and Take, verwenden Sie VIEW, fordern Sie nur die erforderlichen Felder an, überwachen Sie das Zwischenspeichern von Abfragen und Sonstiges) ist das JOIN- Thema der lokalen Sammlung und von DbSet jedoch immer noch eine Schwachstelle.
Herausforderung
Angenommen, es gibt eine Datenbank mit Preisen und eine Sammlung von Transaktionen, für die Sie die Richtigkeit der Preise überprüfen müssen. Angenommen, wir haben den folgenden Code.
var localData = GetDataFromApiOrUser(); var query = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId join t in localData on new { s.Ticker, p.TradedOn, p.PriceSourceId } equals new { t.Ticker, t.TradedOn, t.PriceSourceId } select p; var result = query.ToList();
Dieser Code funktioniert in Entity Framework 6 überhaupt nicht. Im Entity Framework Core funktioniert dies, aber alles wird auf der Clientseite ausgeführt, und wenn sich Millionen von Datensätzen in der Datenbank befinden, ist dies keine Option.
Wie gesagt, ich werde verschiedene Wege versuchen, um dies zu umgehen. Von einfach bis komplex. Für meine Experimente verwende ich den Code aus dem folgenden Repository . Der Code wird geschrieben mit: C # , .Net Core , EF Core und PostgreSQL .
Ich habe auch einige Metriken aufgenommen: Zeitaufwand und Speicherverbrauch. Haftungsausschluss: Wenn der Test länger als 10 Minuten durchgeführt wurde, habe ich ihn unterbrochen (die Einschränkung ist von oben). Testmaschine Intel Core i5, 8 GB RAM, SSD.
DB-Schema
Nur 3 Tabellen: Preise , Wertpapiere und Preisquellen . Preise - enthält 10 Millionen Einträge.
Methode 1. Naiv
Beginnen wir einfach und verwenden den folgenden Code:
Code für Methode 1 var result = new List<Price>(); using (var context = CreateContext()) { foreach (var testElement in TestData) { result.AddRange(context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId)); } }
Die Idee ist einfach: In einer Schleife lesen wir nacheinander Datensätze aus der Datenbank und fügen sie der resultierenden Sammlung hinzu. Dieser Code hat nur einen Vorteil - Einfachheit. Ein Nachteil ist die geringe Geschwindigkeit: Selbst wenn sich ein Index in der Datenbank befindet, wird die meiste Zeit die Kommunikation mit dem Datenbankserver benötigt. Die Metriken sind wie folgt:
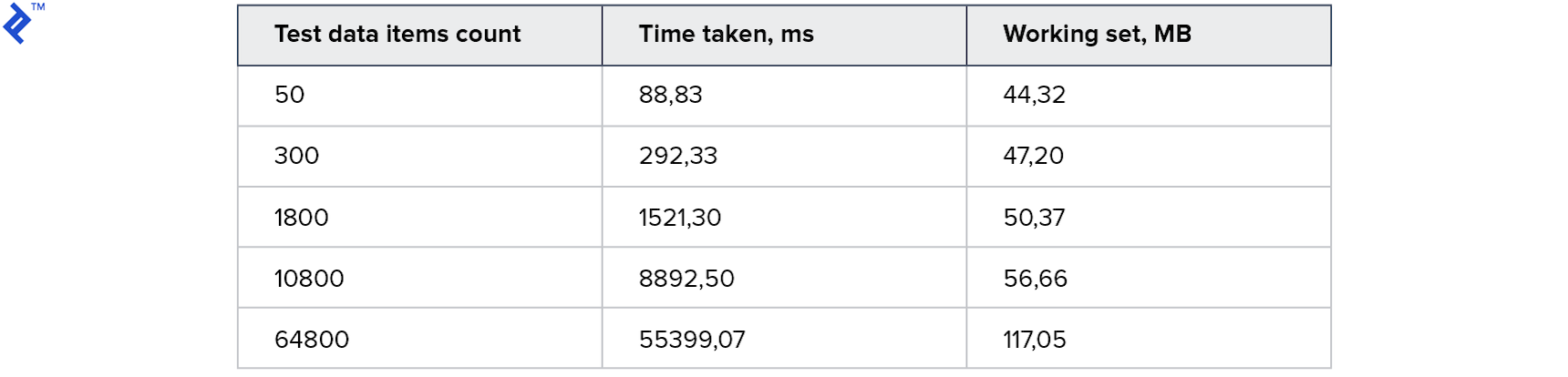
Der Speicherverbrauch ist gering. Eine große Sammlung dauert 1 Minute. Für den Anfang nicht schlecht, aber ich will es schneller.
Methode 2: Naive Parallele
Versuchen wir, Parallelität hinzuzufügen. Die Idee ist, von mehreren Threads auf die Datenbank zuzugreifen.
Code für Methode 2 var result = new ConcurrentBag<Price>(); var partitioner = Partitioner.Create(0, TestData.Count); Parallel.ForEach(partitioner, range => { var subList = TestData.Skip(range.Item1) .Take(range.Item2 - range.Item1) .ToList(); using (var context = CreateContext()) { foreach (var testElement in subList) { var query = context.Prices.Where( x => x.Security.Ticker == testElement.Ticker && x.TradedOn == testElement.TradedOn && x.PriceSourceId == testElement.PriceSourceId); foreach (var el in query) { result.Add(el); } } } });
Ergebnis:
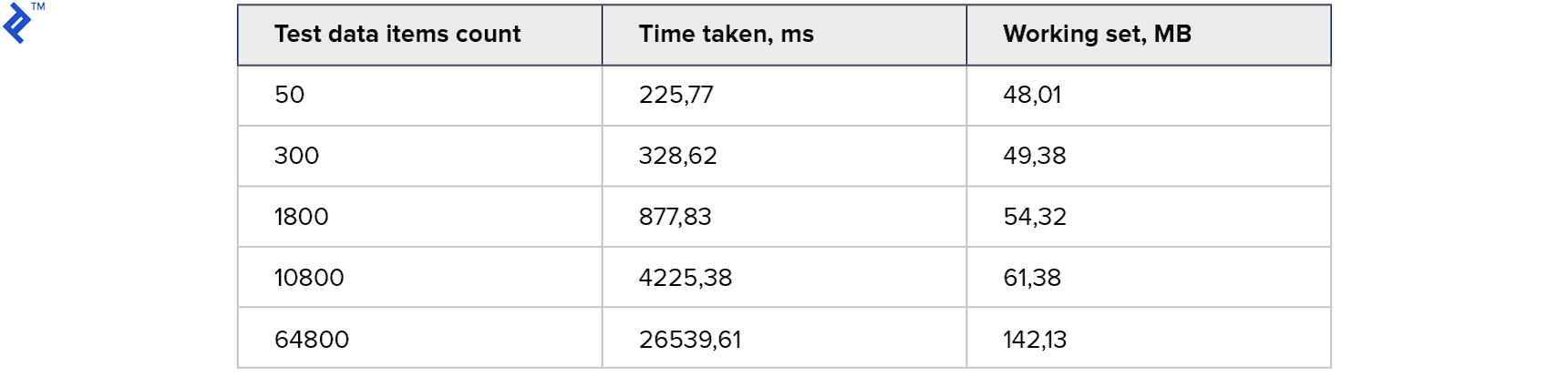
Bei kleinen Sammlungen ist dieser Ansatz sogar langsamer als die erste Methode. Und für die Größten - 2 mal schneller. Interessanterweise wurden auf meinem Computer 4 Threads generiert, was jedoch nicht zu einer 4-fachen Beschleunigung führte. Dies deutet darauf hin, dass der Overhead bei dieser Methode erheblich ist: sowohl auf der Clientseite als auch auf der Serverseite. Der Speicherverbrauch hat zugenommen, aber nicht wesentlich.
Methode 3: Mehrere enthält
Zeit, etwas anderes auszuprobieren und die Aufgabe auf eine Abfrage zu reduzieren. Dies kann wie folgt erfolgen:
- Bereiten Sie 3 einzigartige Sammlungen von Ticker , PriceSourceId und Date vor
- Führen Sie die Anforderung aus und verwenden Sie 3 Enthält
- Überprüfen Sie die Ergebnisse lokal erneut
Code für Methode 3 var result = new List<Price>(); using (var context = CreateContext()) {
Das Problem hierbei ist, dass die Ausführungszeit und die Menge der zurückgegebenen Daten stark von den Daten selbst abhängen (sowohl in der Abfrage als auch in der Datenbank). Das heißt, es kann nur ein Satz der erforderlichen Daten zurückgegeben werden, und es können zusätzliche Datensätze zurückgegeben werden (sogar 100-mal mehr).
Dies kann anhand des folgenden Beispiels erklärt werden. Angenommen, es gibt die folgende Tabelle mit Daten:

Angenommen, ich benötige Preise für Ticker1 mit TradedOn = 2018-01-01 und für Ticker2 mit TradedOn = 2018-01-02 .
Dann eindeutige Werte für Ticker = ( Ticker1 , Ticker2 )
Und eindeutige Werte für TradedOn = ( 2018-01-01 , 2018-01-02 )
Als Ergebnis werden jedoch 4 Datensätze zurückgegeben, da sie diesen Kombinationen wirklich entsprechen. Das Schlimme ist, dass je mehr Felder verwendet werden, desto größer ist die Chance, zusätzliche Datensätze zu erhalten.
Aus diesem Grund müssen mit dieser Methode erhaltene Daten zusätzlich clientseitig gefiltert werden. Und das ist der größte Nachteil.
Die Metriken sind wie folgt:
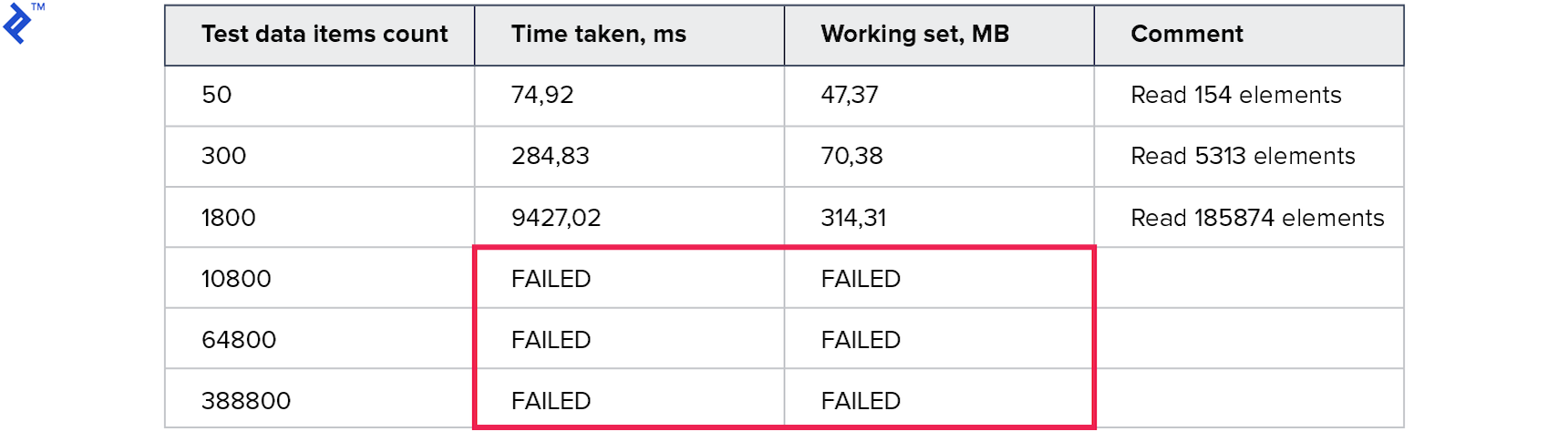
Der Speicherverbrauch ist schlechter als bei allen vorherigen Methoden. Die Anzahl der gelesenen Zeilen ist um ein Vielfaches größer als die angeforderte Anzahl. Tests für große Sammlungen wurden unterbrochen, da sie länger als 10 Minuten liefen. Diese Methode ist nicht gut.
Methode 4. Prädikaten-Builder
Versuchen wir es auf der anderen Seite: dem guten alten Ausdruck . Mit ihnen können Sie 1 große Abfrage in der folgenden Form erstellen:
… (.. AND .. AND ..) OR (.. AND .. AND ..) OR (.. AND .. AND ..) …
Dies gibt Hoffnung, dass es möglich sein wird, eine Anfrage zu erstellen und nur die erforderlichen Daten für einen Anruf zu erhalten. Code:
Code für Methode 4 var result = new List<Price>(); using (var context = CreateContext()) { var baseQuery = from p in context.Prices join s in context.Securities on p.SecurityId equals s.SecurityId select new TestData() { Ticker = s.Ticker, TradedOn = p.TradedOn, PriceSourceId = p.PriceSourceId, PriceObject = p }; var tradedOnProperty = typeof(TestData).GetProperty("TradedOn"); var priceSourceIdProperty = typeof(TestData).GetProperty("PriceSourceId"); var tickerProperty = typeof(TestData).GetProperty("Ticker"); var paramExpression = Expression.Parameter(typeof(TestData)); Expression wholeClause = null; foreach (var td in TestData) { var elementClause = Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, tradedOnProperty), Expression.Constant(td.TradedOn) ), Expression.AndAlso( Expression.Equal( Expression.MakeMemberAccess( paramExpression, priceSourceIdProperty), Expression.Constant(td.PriceSourceId) ), Expression.Equal( Expression.MakeMemberAccess( paramExpression, tickerProperty), Expression.Constant(td.Ticker)) )); if (wholeClause == null) wholeClause = elementClause; else wholeClause = Expression.OrElse(wholeClause, elementClause); } var query = baseQuery.Where( (Expression<Func<TestData, bool>>)Expression.Lambda( wholeClause, paramExpression)).Select(x => x.PriceObject); result.AddRange(query); }
Der Code erwies sich als komplizierter als bei den vorherigen Methoden. Das manuelle Erstellen von Expression ist nicht die einfachste und schnellste Operation.
Metriken:
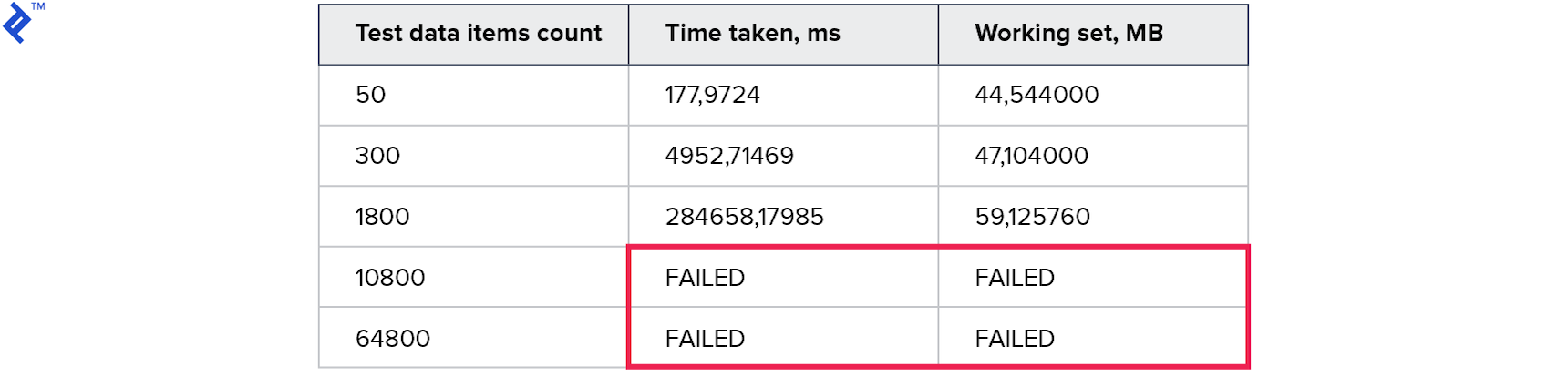
Temporäre Ergebnisse waren noch schlechter als bei der vorherigen Methode. Es scheint, dass der Aufwand während des Baus und beim Gehen durch den Baum viel mehr war als der Gewinn aus der Verwendung einer Anfrage.
Methode 5: Gemeinsame Abfragedatentabelle
Versuchen wir eine andere Option:
Ich habe eine neue Tabelle in der Datenbank erstellt, in die ich die Daten schreiben werde, die zum Abschließen der Anforderung erforderlich sind (implizit benötige ich ein neues DbSet im Kontext).
Um das Ergebnis zu erhalten, das Sie benötigen:
- Transaktion starten
- Laden Sie Abfragedaten in eine neue Tabelle hoch
- Führen Sie die Abfrage selbst aus (unter Verwendung der neuen Tabelle).
- Rollback einer Transaktion (um die Datentabelle für Abfragen zu löschen)
Der Code sieht folgendermaßen aus:
Code für Methode 5 var result = new List<Price>(); using (var context = CreateContext()) { context.Database.BeginTransaction(); var reducedData = TestData.Select(x => new SharedQueryModel() { PriceSourceId = x.PriceSourceId, Ticker = x.Ticker, TradedOn = x.TradedOn }).ToList();
Erste Metriken:
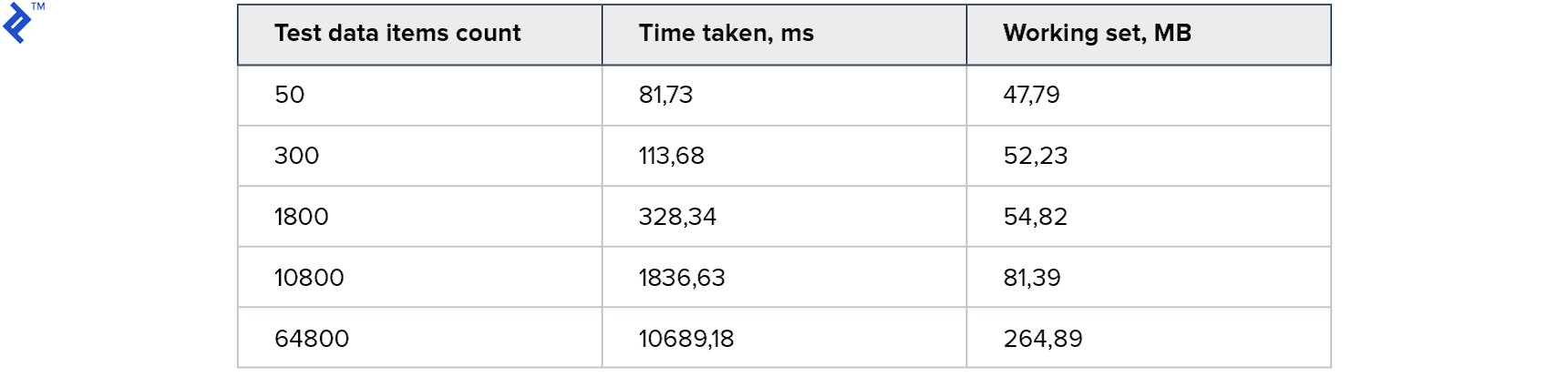
Alle Tests haben funktioniert und schnell funktioniert! Der Speicherverbrauch ist ebenfalls akzeptabel.
Somit kann diese Tabelle durch die Verwendung einer Transaktion von mehreren Prozessen gleichzeitig verwendet werden. Und da es sich um eine real vorhandene Tabelle handelt, stehen uns alle Funktionen des Entity Framework zur Verfügung: Sie müssen nur die Daten in die Tabelle laden, eine Abfrage mit JOIN erstellen und ausführen. Auf den ersten Blick ist dies das, was Sie brauchen, aber es gibt erhebliche Nachteile:
- Sie müssen eine Tabelle für einen bestimmten Abfragetyp erstellen
- Es ist notwendig, Transaktionen zu verwenden (und DBMS-Ressourcen darauf zu verschwenden).
- Und die bloße Idee, dass Sie etwas SCHREIBEN müssen, wenn Sie LESEN müssen, sieht seltsam aus. Und bei Read Replica funktioniert es einfach nicht.
Und der Rest ist eine mehr oder weniger funktionierende Lösung, die bereits verwendet werden kann.
Methode 6. MemoryJoin-Erweiterung
Jetzt können Sie versuchen, den vorherigen Ansatz zu verbessern. Die Gedanken sind:
- Anstatt eine Tabelle zu verwenden, die für einen Abfragetyp spezifisch ist, können Sie eine verallgemeinerte Option verwenden. Erstellen Sie nämlich eine Tabelle mit einem Namen wie shared_query_data und fügen Sie mehrere Guid- Felder, mehrere Long- , mehrere String- usw. hinzu. Es können einfache Namen verwendet werden: Guid1 , Guid2 , String1 , Long1 , Date2 usw. Dann kann diese Tabelle für 95% der Abfragetypen verwendet werden. Eigenschaftsnamen können später mithilfe der Auswahlperspektive „angepasst“ werden.
- Als nächstes müssen Sie ein DbSet für shared_query_data hinzufügen .
- Was aber, wenn anstelle des Schreibens von Daten in die Datenbank Werte mit dem Konstrukt VALUES übergeben werden? Das heißt, es ist erforderlich, dass in der endgültigen SQL-Abfrage anstelle des Zugriffs auf shared_query_data ein Aufruf an VALUES erfolgt . Wie kann man das machen?
- In Entity Framework Core - nur mit FromSql .
- In Entity Framework 6 - Sie müssen DbInterception verwenden - ändern Sie die generierte SQL, indem Sie das VALUES- Konstrukt unmittelbar vor der Ausführung hinzufügen. Dies führt zu einer Einschränkung: In einer einzelnen Anforderung darf nicht mehr als ein VALUES- Konstrukt vorhanden sein. Aber es wird funktionieren!
- Da wir nicht in die Datenbank schreiben, wird die Tabelle shared_query_data im ersten Schritt erstellt. Wird sie überhaupt nicht benötigt? Antwort: Ja, es wird nicht benötigt, aber DbSet wird weiterhin benötigt, da das Entity Framework das Datenschema kennen muss, um Abfragen zu erstellen. Es stellt sich heraus, dass wir ein DbSet für ein verallgemeinertes Modell benötigen, das nicht in der Datenbank vorhanden ist und nur dazu verwendet wird, das Entity Framework zu inspirieren, dass es weiß, was es tut.
Konvertieren Sie IEnumerable in IQueryable Example- Die Eingabe erhielt eine Sammlung von Objekten des folgenden Typs:
class SomeQueryData { public string Ticker {get; set;} public DateTimeTradedOn {get; set;} public int PriceSourceId {get; set;} }
- Wir verfügen über DbSet mit den Feldern String1 , String2 , Date1 , Long1 usw.
- Lassen Sie Ticker in String1 , TradedOn in Date1 und PriceSourceId in Long1 gespeichert ( int mapps in long , um Felder für int und long nicht getrennt zu machen).
- Dann sieht FromSql + VALUES folgendermaßen aus:
var query = context.QuerySharedData.FromSql( "SELECT * FROM ( VALUES (1, 'Ticker1', @date1, @id1), (2, 'Ticker2', @date2, @id2) ) AS __gen_query_data__ (id, string1, date1, long1)")
- Jetzt können Sie eine Projektion erstellen und eine bequeme IQueryable mit demselben Typ zurückgeben, der am Eingang war:
return query.Select(x => new SomeQueryData() { Ticker = x.String1, TradedOn = x.Date1, PriceSourceId = (int)x.Long1 });
Ich habe es geschafft, diesen Ansatz zu implementieren und ihn sogar als NuGet-Paket EntityFrameworkCore.MemoryJoin zu entwerfen (der Code ist ebenfalls verfügbar). Trotz der Tatsache, dass der Name das Wort Core enthält, wird auch Entity Framework 6 unterstützt. Ich habe es MemoryJoin genannt , aber tatsächlich sendet es lokale Daten an das DBMS im VALUES- Konstrukt und die ganze Arbeit wird daran erledigt.
Der Code lautet wie folgt:
Code für Methode 6 var result = new List<Price>(); using (var context = CreateContext()) {
Metriken:
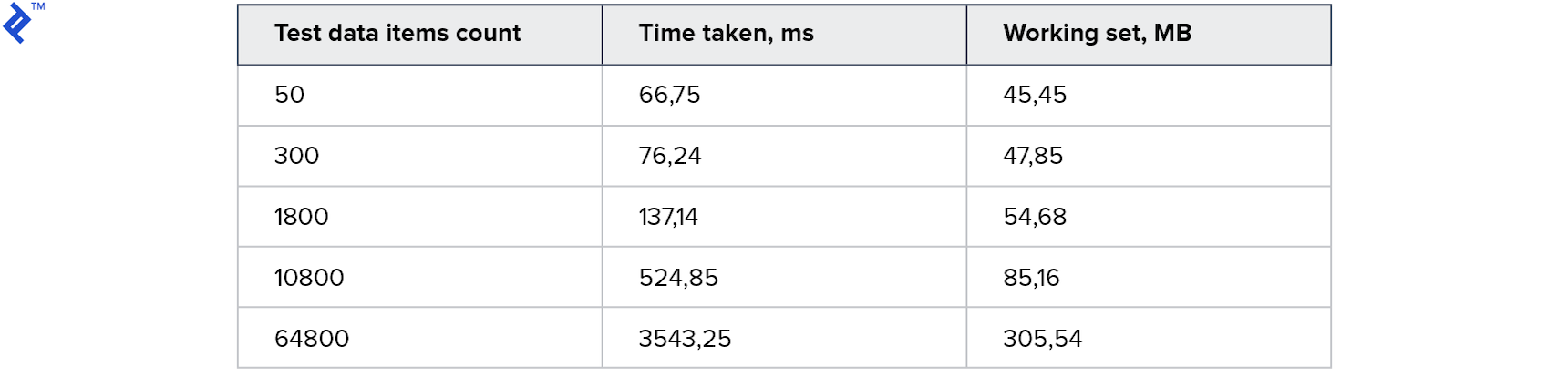
Dies ist das beste Ergebnis, das ich je versucht habe. Der Code war sehr einfach und unkompliziert und funktionierte gleichzeitig für Read Replica.
Ein Beispiel für eine generierte Anforderung zum Empfangen von 3 Elementen SELECT "p"."PriceId", "p"."ClosePrice", "p"."OpenPrice", "p"."PriceSourceId", "p"."SecurityId", "p"."TradedOn", "t"."Ticker", "t"."TradedOn", "t"."PriceSourceId" FROM "Price" AS "p" INNER JOIN "Security" AS "s" ON "p"."SecurityId" = "s"."SecurityId" INNER JOIN ( SELECT "x"."string1" AS "Ticker", "x"."date1" AS "TradedOn", CAST("x"."long1" AS int4) AS "PriceSourceId" FROM ( SELECT * FROM ( VALUES (1, @__gen_q_p0, @__gen_q_p1, @__gen_q_p2), (2, @__gen_q_p3, @__gen_q_p4, @__gen_q_p5), (3, @__gen_q_p6, @__gen_q_p7, @__gen_q_p8) ) AS __gen_query_data__ (id, string1, date1, long1) ) AS "x" ) AS "t" ON (("s"."Ticker" = "t"."Ticker") AND ("p"."PriceSourceId" = "t"."PriceSourceId")
Hier können Sie auch sehen, wie das verallgemeinerte Modell (mit den Feldern String1 , Date1 , Long1 ) mit Select in das im Code verwendete Modell (mit den Feldern Ticker , TradedOn , PriceSourceId ) umgewandelt wird.
Alle Arbeiten werden in einer Abfrage auf dem SQL Server ausgeführt. Und das ist ein kleines Happy End, über das ich am Anfang gesprochen habe. Die Verwendung dieser Methode erfordert jedoch Verständnis und die folgenden Schritte:
- Sie müssen Ihrem Kontext ein zusätzliches DbSet hinzufügen (obwohl die Tabelle selbst weggelassen werden kann ).
- In dem standardisierten Modell, das standardmäßig verwendet wird, werden 3 Felder der Typen Guid , String , Double , Long , Date usw. deklariert. Das sollte für 95% der Anfragetypen ausreichen. Wenn Sie eine Sammlung von Objekten mit 20 Feldern an FromLocalList übergeben , wird eine Ausnahme ausgelöst, die besagt, dass das Objekt zu komplex ist. Dies ist eine weiche Einschränkung und kann umgangen werden. Sie können Ihren Typ deklarieren und dort mindestens 100 Felder hinzufügen. Mehr Felder arbeiten jedoch langsamer.
- Weitere technische Details sind in meinem Artikel beschrieben .
Fazit
In diesem Artikel habe ich meine Gedanken zum Thema JOIN local collection und DbSet vorgestellt. Es schien mir, dass meine Entwicklung mit VALUES für die Community von Interesse sein könnte. Zumindest bin ich einem solchen Ansatz nicht begegnet, als ich dieses Problem selbst gelöst habe. Persönlich hat mir diese Methode geholfen, eine Reihe von Leistungsproblemen in meinen aktuellen Projekten zu überwinden. Vielleicht hilft sie Ihnen auch.
Jemand wird sagen, dass die Verwendung von MemoryJoin zu "abstrus" ist und weiterentwickelt werden muss, und bis dahin müssen Sie es nicht verwenden. Dies ist genau der Grund, warum ich sehr zweifelhaft war und fast ein Jahr lang diesen Artikel nicht geschrieben habe. Ich stimme zu, dass ich möchte, dass es einfacher funktioniert (ich hoffe, dass es eines Tages so sein wird), aber ich sage auch, dass die Optimierung nie die Aufgabe der Junioren war. Die Optimierung erfordert immer ein Verständnis der Funktionsweise des Tools. Und wenn es die Möglichkeit gibt, das 8-fache zu beschleunigen ( Naive Parallel vs MemoryJoin ), würde ich 2 Punkte und Dokumentation beherrschen.
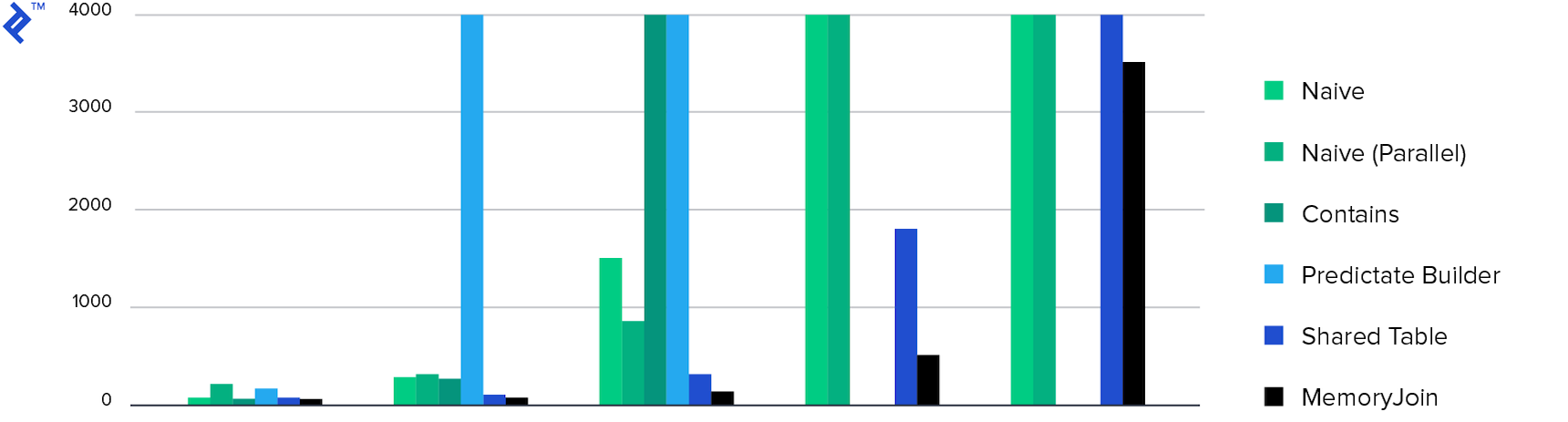
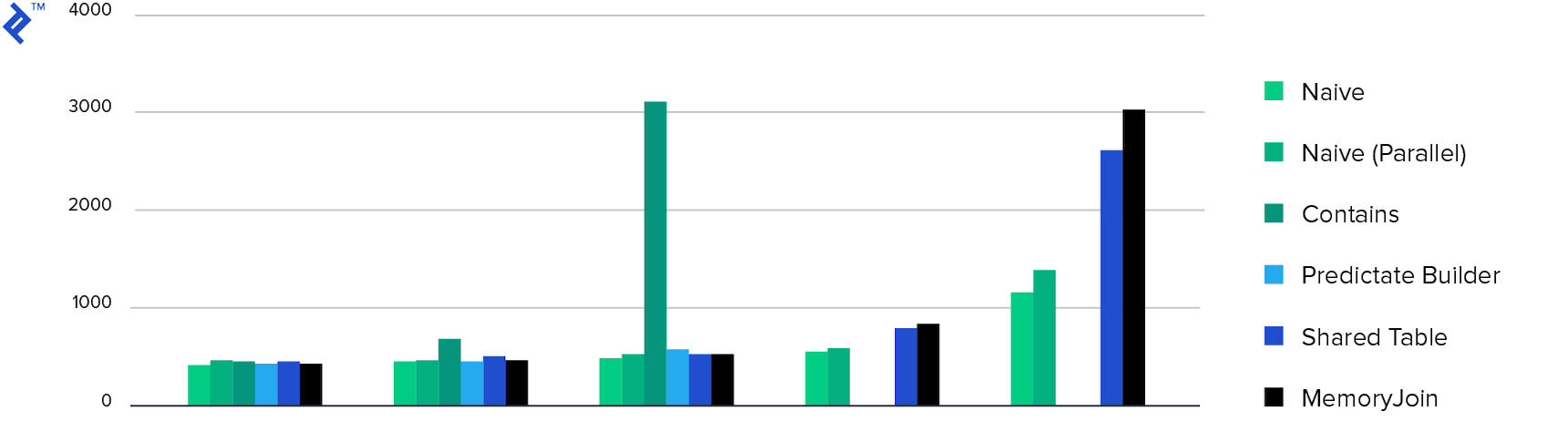
Und schließlich die Diagramme:
Zeit verbracht. Nur 4 Methoden haben die Aufgabe in weniger als 10 Minuten erledigt , und MemoryJoin ist die einzige Möglichkeit, die Aufgabe in weniger als 10 Sekunden zu erledigen.
Speicherverbrauch. Alle Methoden mit Ausnahme von Multiple Contains zeigten ungefähr den gleichen Speicherverbrauch. Dies liegt an der Menge der zurückgegebenen Daten.
Danke fürs Lesen!