 Die Textklassifizierung
Die Textklassifizierung ist eine der häufigsten Aufgaben in der
NLP- und Lehrerausbildung, wenn der Datensatz Textdokumente enthält und Beschriftungen zum Trainieren des Textklassifizierers verwendet werden.
Aus NLP-Sicht wird die Aufgabe des Klassifizierens von Text erfüllt, indem die Darstellung auf Wortebene unter Verwendung der Worteinbettung trainiert und dann die Darstellung auf Textebene als Funktion für die Klassifizierung trainiert wird.
Die Art der codierungsbasierten Methoden ignoriert kleine Details und Schlüssel für die Klassifizierung (da die allgemeine Darstellung auf Textebene durch Komprimieren der Darstellungen auf Wortebene untersucht wird).
 Codierungsbasierte Methoden zum Klassifizieren von Text mit Übereinstimmung auf Textebene
Codierungsbasierte Methoden zum Klassifizieren von Text mit Übereinstimmung auf TextebeneEXAM - Neue Textklassifizierungsmethode
Forscher der Shandong University und der National University of Singapore haben
ein neues Textklassifizierungsmodell vorgeschlagen , das Übereinstimmungssignale auf Wortebene in die Textklassifizierungsaufgabe einbezieht. Ihre Methode verwendet einen Interaktionsmechanismus, um detaillierte Hinweise auf Wortebene in den Klassifizierungsprozess einzuführen.
Um das Problem der Einbeziehung genauerer
Übereinstimmungssignale auf Wortebene zu lösen, schlugen die Forscher vor
, die Korrespondenzschätzungen zwischen Wörtern und Klassen explizit zu berechnen .
Die Hauptidee besteht darin, die Interaktionsmatrix aus einer Darstellung auf Wortebene zu berechnen, die die entsprechenden Schlüssel auf Wortebene enthält. Jeder Eintrag in dieser Matrix ist eine Bewertung der Entsprechung zwischen einem Wort und einer bestimmten Klasse.
Die vorgeschlagene Textklassifizierungsstruktur mit dem Namen EXAM - EXplicit InterAction Model (
GitHub ) enthält drei Hauptkomponenten:
- Encoder auf Wortebene,
- Interaktionsschicht und
- Aggregationsschicht.
Mit dieser dreistufigen Architektur können Sie Text sowohl mit kleinen als auch mit verallgemeinerten Signalen und Hinweisen codieren und klassifizieren. Die gesamte Architektur ist im Bild unten dargestellt.
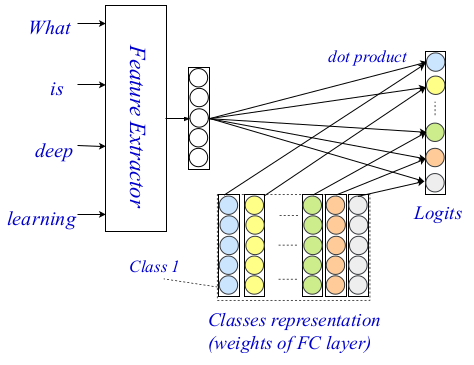
 PRÜFUNG Architektur
PRÜFUNG ArchitekturIn der Vergangenheit wurden Encoder auf Wortebene in der NLP-Community eingehend untersucht, und es sind sehr leistungsfähige Encoder erschienen. Die Autoren verwenden die Sovermenny-Methode als Encoder auf der Ebene der Wörter und beschreiben in ihrer Arbeit zwei weitere Komponenten ihrer Architektur im Detail: die Ebene der Interaktion und Aggregation.
Die Interaktionsschicht, der Hauptbeitrag und die Neuheit des vorgeschlagenen Verfahrens basieren auf dem bekannten Interaktionsmechanismus. Die Forscher verwenden eine
trainierte Präsentationsmatrix, um jede der Klassen zu codieren, damit sie später die Interaktionsschätzungen zwischen den Klassen berechnen können. Die endgültigen Ergebnisse werden unter Verwendung eines Punktprodukts als Funktion der Interaktion zwischen dem Zielwort und jeder Klasse angebracht. Komplexere Funktionen wurden aufgrund der erhöhten Komplexität der Berechnungen nicht berücksichtigt.
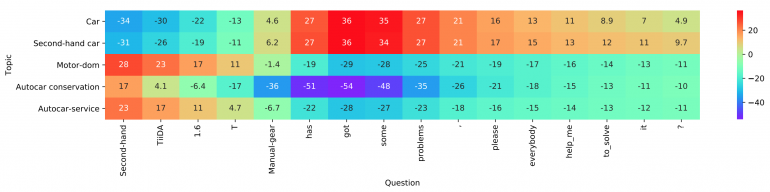 Ebenenvisualisierung
EbenenvisualisierungSchließlich verwenden sie einen einfachen, vollständig verbundenen zweischichtigen MLP als Aggregationsschicht. Sie erwähnen auch, dass hier eine komplexere Aggregationsebene, einschließlich CNN oder LSTM, verwendet werden kann. MLP wird verwendet, um die endgültigen Klassifizierungsprotokolle unter Verwendung der Interaktionsmatrix und der Codierungen auf Wortebene zu berechnen. Die Kreuzentropie wird als Funktion des Verlusts zur Optimierung verwendet.
Noten
Um den vorgeschlagenen Rahmen für die Textklassifizierung zu bewerten, führten die Forscher umfangreiche Experimente sowohl unter Bedingungen mit mehreren Klassen als auch unter Bedingungen mit mehreren Tags durch. Sie zeigen, dass ihre Methode modernen relevanten modernen Methoden weit überlegen ist.
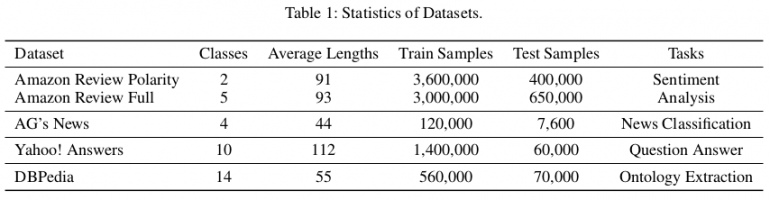 Statistik der verwendeten Datensätze zur Auswertung
Statistik der verwendeten Datensätze zur AuswertungZur Bewertung legen sie drei verschiedene Grundtypen von Modellen fest:
- Modelle basierend auf der Entwicklung von Attributen;
- Tiefe charakterbasierte Modelle
- Tiefe wortbasierte Modelle.
Die Autoren verwendeten öffentlich verfügbare Referenzdatensätze (Zhang, Zhao und LeCun 2015), um die vorgeschlagene Methode zu bewerten. Insgesamt gibt es sechs Sätze von Klassifizierungstextdaten, die den Aufgaben der Analyse von Stimmungen, der Klassifizierung von Nachrichten, Fragen und Antworten bzw. der Extraktion von Ontologien entsprechen. In dem Artikel zeigen sie, dass EXAM die beste Leistung unter drei Datensätzen erzielt: AG, Yah. A. und DBP. Die Bewertung und der Vergleich mit anderen Methoden sind in den folgenden Tabellen aufgeführt.
![Testen Sie die Satzgenauigkeit [%] für Aufgaben zur Klassifizierung von Dokumenten mehrerer Klassen und vergleichen Sie sie mit anderen Methoden](https://habrastorage.org/getpro/habr/post_images/de7/8d8/b60/de78d8b6017c9624c347b0fb645ae0ae.png)

Schlussfolgerungen
Diese Arbeit ist ein wichtiger Beitrag auf dem Gebiet der Verarbeitung natürlicher Sprache (NLP). Dies ist die erste Arbeit, die genauere Hinweise zur Übereinstimmung auf Wortebene in die Textklassifizierung in tiefen neuronalen Netzwerkmodellen einführt. Das vorgeschlagene Modell bietet Indikatoren auf dem neuesten Stand der Technik für mehrere Datensätze.
Übersetzung - Stanislav Litvinov