TL; DR: GitHub: // PastorGL / AQLSelectEx .
Einmal, nicht in der kalten Jahreszeit, sondern bereits in der Wintersaison und speziell vor ein paar Monaten, brauchte ich für ein Projekt, an dem ich arbeitete (etwas Geospatial basierend auf Big Data), einen schnellen NoSQL / Key-Value-Speicher.
Wir kauen mit Hilfe von Apache Spark Terabyte an Quellcodes, aber das Endergebnis von Berechnungen, die auf eine lächerliche Menge (nur Millionen von Datensätzen) reduziert wurden, muss irgendwo gespeichert werden. Und es ist sehr wünschenswert, es so zu speichern, dass es schnell gefunden und mithilfe von Metadaten gesendet werden kann, die jeder Zeile des Ergebnisses zugeordnet sind (dies ist eine Ziffer) (aber es gibt ziemlich viele davon).
Die Formate des Khadupov-Stacks in diesem Sinne sind von geringem Nutzen, und relationale Datenbanken für Millionen von Datensätzen werden langsamer, und der Satz von Metadaten ist nicht so fest, dass er gut in das starre Schema eines regulären RDBMS - in unserem Fall PostgreSQL - passt. Nein, normalerweise wird JSON unterstützt, aber es gibt immer noch Probleme mit Indizes für Millionen von Datensätzen. Indizes schwellen an, es wird notwendig, die Tabelle zu partitionieren, und ein solcher Aufwand bei der Verwaltung beginnt, dass nafig-nafig.
In der Vergangenheit wurde MongoDB als NoSQL für das Projekt verwendet, aber im Laufe der Zeit zeigt sich die Monga immer schlechter (insbesondere in Bezug auf die Stabilität), sodass sie schrittweise außer Betrieb genommen wurde. Eine schnelle Suche nach einer moderneren, schnelleren, weniger fehlerhaften und allgemein besseren Alternative führte zu Aerospike . Viele großköpfige Leute haben es dafür, und ich habe mich entschlossen, es zu überprüfen.
Tests haben gezeigt, dass Daten tatsächlich direkt aus dem Spark-Job mit einem Pfiff in der Story gespeichert werden und die Suche in vielen Millionen Datensätzen viel schneller ist als in der Mong. Und sie isst weniger Gedächtnis. Aber es stellte sich heraus, ein "aber". Die Client-API des Aero-Lots ist rein funktional und nicht deklarativ.
Für die Aufzeichnung in der Story ist dies nicht wichtig, da dennoch alle Arten von Feldern jedes resultierenden Datensatzes lokal im Job selbst bestimmt werden müssen - und der Kontext nicht verloren geht. Der funktionale Stil ist hier vorhanden, zumal das Schreiben eines Codes auf andere Weise nicht funktioniert. In der Web-Mündung, die das Ergebnis nach außen hochladen soll und eine gewöhnliche Spring-Webanwendung ist, wäre es jedoch viel logischer, ein Standard-SQL-SELECT aus einem Benutzerformular zu erstellen, in dem es voller AND- und OR- Prädikate wäre , - in der WHERE-Klausel.
Ich werde den Unterschied mit einem solchen synthetischen Beispiel erklären:
SELECT foo, bar, baz, qux, quux FROM namespace.set WITH (baz!='a') WHERE (foo>2 AND (bar<=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)
- Es ist sowohl lesbar als auch relativ klar, welche Aufzeichnungen der Kunde erhalten wollte. Wenn Sie eine solche Anforderung direkt in das Protokoll einfügen, können Sie sie später zum manuellen Debuggen abrufen. Das ist sehr praktisch, wenn Sie alle möglichen seltsamen Situationen analysieren.
Betrachten wir nun den Aufruf der Prädikat-API in einem funktionalen Stil:
Statement reference = new Statement(); reference.setSetName("set"); reference.setNamespace("namespace"); reference.setBinNames("foo", "bar", "baz", "qux", "quux"); reference.setFillter(Filter.stringNotEqual("baz", "a")); reference.setPredExp(
Hier ist die Codewand und sogar in umgekehrter polnischer Notation . Nein, ich verstehe, dass die Stack-Maschine aus Sicht des Programmierers der Engine selbst einfach und bequem zu implementieren ist, aber um Prädikate in RPN aus der Client-Anwendung zu rätseln und zu schreiben ... Ich persönlich möchte nicht an den Anbieter denken, ich möchte mich als Verbraucher dieser API Es war praktisch. Prädikate sind selbst mit einer Hersteller-Client-Erweiterung (konzeptionell ähnlich der Java Persistence Criteria API) unpraktisch zu schreiben. Und dennoch gibt es kein lesbares SELECT im Abfrageprotokoll.
Im Allgemeinen wurde SQL erfunden, um kriterienbasierte Abfragen in einer Vogelsprache zu schreiben, die nahezu natürlich ist. Man fragt sich also, was zur Hölle?
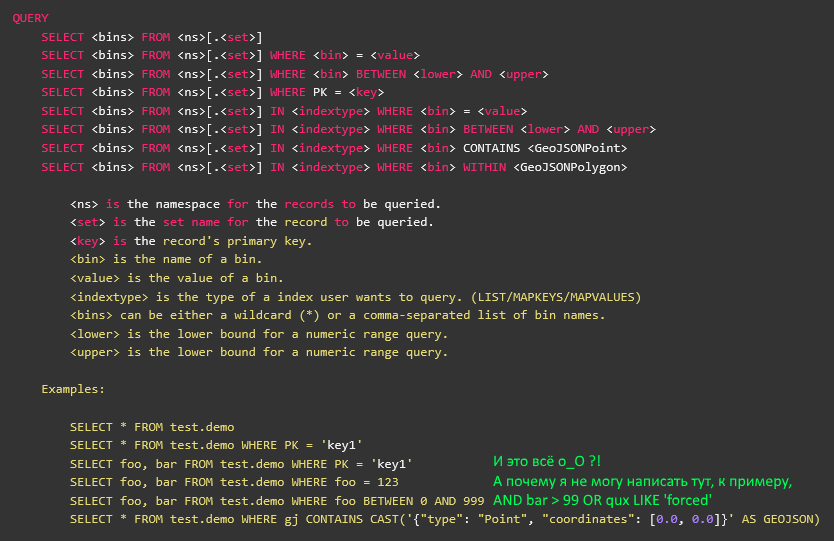
Warten Sie, etwas stimmt nicht ... Gibt es auf dem KDPV einen Screenshot aus der offiziellen Dokumentation des Aerosolders, auf dem SELECT vollständig beschrieben ist?
Ja, beschrieben. Das ist nur AQL - dies ist ein Dienstprogramm eines Drittanbieters, das in einer dunklen Nacht vom linken Hinterfuß geschrieben und vor drei Jahren während der vorherigen Version des Aerosoldering vom Anbieter aufgegeben wurde. Es hat nichts mit der Client-Bibliothek zu tun, obwohl es auf einer Kröte geschrieben ist - einschließlich.
Die Version von vor drei Jahren hatte keine Prädikat-API, und daher gibt es in AQL keine Unterstützung für Prädikate, und all das nach WHERE ist tatsächlich ein Aufruf des Index (sekundär oder primär). Nun, das heißt, näher an der SQL-Erweiterung wie USE oder WITH. Das heißt, Sie können AQL-Quellen nicht einfach in Ersatzteile zerlegen und in Ihrer Anwendung für Prädikataufrufe verwenden.
Außerdem wurde es, wie gesagt, in der dunklen Nacht mit dem linken Hinterfuß geschrieben, und es ist unmöglich, die ANTLR4- Grammatik zu betrachten , nach der AQL die Abfrage ohne Tränen analysiert. Nun, für meinen Geschmack. Aus irgendeinem Grund liebe ich es, wenn die deklarative Definition von Grammatik nicht mit Krötencode gemischt wird und dort sehr coole Nudeln gebraut werden.
Zum Glück scheine ich auch zu wissen, wie man ANTLR macht. Es stimmt, ich habe lange Zeit keinen Checker mitgenommen und das letzte Mal unter der dritten Version geschrieben. Viertens - es ist viel schöner, denn wer eine manuelle AST-Tour schreiben möchte, wenn alles vor uns geschrieben wurde und es einen normalen Besucher gibt, also fangen wir an.
Wir nehmen die SQLite-Syntax als Basis und versuchen, alles Unnötige wegzuwerfen. Wir brauchen nur SELECT und nichts weiter.
grammar SQLite; simple_select_stmt : ( K_WITH K_RECURSIVE? common_table_expression ( ',' common_table_expression )* )? select_core ( K_ORDER K_BY ordering_term ( ',' ordering_term )* )? ( K_LIMIT expr ( ( K_OFFSET | ',' ) expr )? )? ; select_core : K_SELECT ( K_DISTINCT | K_ALL )? result_column ( ',' result_column )* ( K_FROM ( table_or_subquery ( ',' table_or_subquery )* | join_clause ) )? ( K_WHERE expr )? ( K_GROUP K_BY expr ( ',' expr )* ( K_HAVING expr )? )? | K_VALUES '(' expr ( ',' expr )* ')' ( ',' '(' expr ( ',' expr )* ')' )* ; expr : literal_value | BIND_PARAMETER | ( ( database_name '.' )? table_name '.' )? column_name | unary_operator expr | expr '||' expr | expr ( '*' | '/' | '%' ) expr | expr ( '+' | '-' ) expr | expr ( '<<' | '>>' | '&' | '|' ) expr | expr ( '<' | '<=' | '>' | '>=' ) expr | expr ( '=' | '==' | '!=' | '<>' | K_IS | K_IS K_NOT | K_IN | K_LIKE | K_GLOB | K_MATCH | K_REGEXP ) expr | expr K_AND expr | expr K_OR expr | function_name '(' ( K_DISTINCT? expr ( ',' expr )* | '*' )? ')' | '(' expr ')' | K_CAST '(' expr K_AS type_name ')' | expr K_COLLATE collation_name | expr K_NOT? ( K_LIKE | K_GLOB | K_REGEXP | K_MATCH ) expr ( K_ESCAPE expr )? | expr ( K_ISNULL | K_NOTNULL | K_NOT K_NULL ) | expr K_IS K_NOT? expr | expr K_NOT? K_BETWEEN expr K_AND expr | expr K_NOT? K_IN ( '(' ( select_stmt | expr ( ',' expr )* )? ')' | ( database_name '.' )? table_name ) | ( ( K_NOT )? K_EXISTS )? '(' select_stmt ')' | K_CASE expr? ( K_WHEN expr K_THEN expr )+ ( K_ELSE expr )? K_END | raise_function ;
Hmm ... Soviel zu SELECT zu viel. Und wenn es ziemlich einfach ist, überschüssiges Material loszuwerden, gibt es noch eine weitere schlechte Sache in Bezug auf die Struktur der resultierenden Problemumgehung.
Das ultimative Ziel ist die Übersetzung in die Prädikat-API mit RPN und impliziter Stack-Maschine. Und hier trägt der atomare Ausdruck in keiner Weise zu einer solchen Transformation bei, da er eine normale Analyse von links nach rechts impliziert. Ja und rekursiv definiert.
Das heißt, wir können unser synthetisches Beispiel erhalten, aber es wird genau so gelesen, wie es geschrieben ist, von links nach rechts:
(foo>2 (bar<=3 foo>5) quux _ '%force%') (qux _('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}')
Es gibt Klammern, die die Priorität des Parsens bestimmen (was bedeutet, dass Sie auf dem Stapel hin und her baumeln müssen), und einige Operatoren verhalten sich wie Funktionsaufrufe.
Und wir brauchen diese Sequenz:
foo 2 > bar 3 <= foo 5 > quux ".*force.*" _ qux "{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}" _
Brr, Zinn, schlechtes Gehirn zum Lesen. Ohne Klammern gibt es jedoch keine Rollbacks und Missverständnisse bei der Reihenfolge des Anrufs. Und wie übersetzen wir einander?
Und dann passiert in einem armen Gehirn ein Schoko! - Hallo, dies ist ein klassischer Rangierbahnhof von vielen. prof. Dijkstra! Normalerweise benötigen okolobigdatovskimi-Schamanen wie ich keine Algorithmen, weil wir einfach die Prototypen, die bereits von Datensatanisten geschrieben wurden, von Python auf die Kröte übertragen und dann eine lange und langwierige Leistung der Lösung erbringen, die durch rein technische (== schamanistische) und nicht wissenschaftliche Methoden erhalten wurde .
Aber dann wurde es plötzlich notwendig, den Algorithmus zu kennen. Oder zumindest eine Idee davon. Glücklicherweise wurden in den letzten Jahren nicht alle Universitätskurse vergessen, und da ich mich an gestapelte Maschinen erinnere, kann ich auch noch etwas anderes über die zugehörigen Algorithmen herausfinden.
Okay In einer von Shunting Yard geschärften Grammatik würde ein SELECT auf der obersten Ebene folgendermaßen aussehen:
select_stmt : K_SELECT ( STAR | column_name ( COMMA column_name )* ) ( K_FROM from_set )? ( (K_USE | K_WITH) index_expr )? ( K_WHERE where_expr )? ; where_expr : ( atomic_expr | OPEN_PAR | CLOSE_PAR | logic_op )+ ; logic_op : K_NOT | K_AND | K_OR ; atomic_expr : column_name ( equality_op | regex_op ) STRING_LITERAL | ( column_name | meta_name ) ( equality_op | comparison_op ) NUMERIC_LITERAL | column_name map_op iter_expr | column_name list_op iter_expr | column_name geo_op cast_expr ;
Das heißt, die den Klammern entsprechenden Token sind signifikant, und es sollte kein rekursiver Ausdruck vorhanden sein. Stattdessen wird es eine Menge aller private_expr geben, und alle sind endlich.
In dem Code auf der Kröte, den der Besucher für diesen Baum implementiert, machen die Dinge etwas mehr süchtig - in strikter Übereinstimmung mit dem Algorithmus, der selbst die hängende Logik verarbeitet und die Klammern ausgleicht. Ich werde keinen Auszug geben ( schauen Sie sich den GC selbst an), aber ich werde die folgende Überlegung machen.
Es wird deutlich, warum sich die Autoren des Aero-Spikes nicht um die Unterstützung von Prädikaten in AQL gekümmert haben und diese vor drei Jahren aufgegeben haben. Weil es streng typisiert ist und der Aero-Spike selbst als schemalose Geschichte dargestellt wird. Daher ist es unmöglich, eine Abfrage von Bare SQL ohne ein vorbestimmtes Schema zu übernehmen und auszuweiden. Ups
Aber wir sind verbrannt und vor allem arrogant. Wir brauchen ein Schema mit Feldtypen, also wird es ein Schema mit Feldtypen geben. Darüber hinaus verfügt die Client-Bibliothek bereits über alle erforderlichen Definitionen, sie müssen nur noch abgeholt werden. Obwohl ich für jeden Typ viel Code schreiben musste (siehe den gleichen Link aus Zeile 56).
Jetzt initialisieren ...
final HashMap FOO_BAR_BAZ = new HashMap() {{ put("namespace.set0", new HashMap() {{ put("foo", ParticleType.INTEGER); put("bar", ParticleType.DOUBLE); put("baz", ParticleType.STRING); put("qux", ParticleType.GEOJSON); put("quux", ParticleType.STRING); put("quuux", ParticleType.LIST); put("corge", ParticleType.MAP); put("corge.uier", ParticleType.INTEGER); }}); put("namespace.set1", new HashMap() {{ put("grault", ParticleType.INTEGER); put("garply", ParticleType.STRING); }}); }}; AQLSelectEx selectEx = AQLSelectEx.forSchema(FOO_BAR_BAZ);
... und voila, jetzt ruckelt unsere synthetische Abfrage einfach und deutlich vom Aerosoldering:
Statement statement = selectEx.fromString("SELECT foo,bar,baz,qux,quux FROM namespace.set WITH (baz='a') WHERE (foo>2 AND (bar <=3 OR foo>5) AND quux LIKE '%force%') OR NOT (qux WITHIN CAST('{\"type\": \"Polygon\", \"coordinates\": [0.0, 0.0],[1.0, 0.0],[1.0, 1.0],[0.0, 1.0],[0.0, 0.0]}' AS GEOJSON)");
Und um das Formular von der Web-Mündung in die Anfrage selbst zu konvertieren, greifen wir auf eine Menge Code zu, der vor langer Zeit in die Web-Mündung geschrieben wurde ... wenn das Unternehmen das Projekt endlich erreicht, hat der Kunde es vorerst ins Regal gestellt. Es ist eine Schande, verdammt, ich habe fast eine Woche Zeit verbracht.
Ich hoffe, ich habe es mit Vorteil ausgegeben, und die AQLSelectEx-Bibliothek wird für jemanden nützlich sein, und der Ansatz selbst wird ein wenig realistischeres Tutorial sein als andere Artikel aus dem Hub, die sich mit ANTLR befassen.