
Wahrscheinlich gibt es auf Habr nicht so viele Benutzer, die noch nie von dem
„Internetarchiv“ gehört haben , einem Dienst, der die für die gesamte Menschheit wichtigen digitalen Daten sucht und speichert, sei es die Internetseiten, Bücher, Videos oder andere Arten von Informationen.
Wer verwaltet das Internetarchiv, wann es erschienen ist und was ist seine Mission? Lesen Sie darüber in der heutigen "Anfrage".
Warum brauchen wir überhaupt ein "Archiv"?
Dies ist alles andere als nur Unterhaltung. Die Mission der Organisation ist es, den universellen Zugang zu allen Informationen zu ermöglichen. Das „Internetarchiv“ soll das Monopol der Bereitstellung von Informationen sowohl durch Telekommunikationsunternehmen (Google, Facebook usw.) als auch durch Regierungen bekämpfen.
Gleichzeitig ist das "Archiv" eine gesetzestreue Organisation. Wenn nach US-amerikanischem Recht einige Informationen entfernt werden müssen, tut die Organisation dies.
Das „Internetarchiv“ dient auch als Werkzeug für Wissenschaftler, Sicherheitsbehörden, Historiker (z. B. Archäologen) und Vertreter vieler anderer Bereiche, ganz zu schweigen von einzelnen Benutzern.
Wann erschien das "Internetarchiv"?
Der Schöpfer des „Archivs“ ist Brewster Cale aus den USA, der die Firma Alexa Internet gegründet hat. Beide Dienste sind sehr beliebt geworden, beide sind immer noch erfolgreich.
Das „Internetarchiv“ hat 1996 damit begonnen, die Informationen von den Websites zu archivieren und die Kopien der Webseiten aufzubewahren. Der Hauptsitz dieser gemeinnützigen Organisation befindet sich in San Francisco, USA.
Fünf Jahre lang waren die Daten jedoch nicht für den öffentlichen Zugriff verfügbar - die Daten wurden auf den Servern des "Archivs" gespeichert, und das ist alles, nur die Verwaltung des Dienstes konnte die alten Kopien der Websites anzeigen. Seit 2001 hat die Serviceverwaltung beschlossen, allen Zugriff auf die gespeicherten Daten zu gewähren.
Am Anfang war das „Internetarchiv“ nur ein Webarchiv, aber dann begann die Organisation, Bücher, Audiodateien, bewegte Bilder und Software zu speichern. Jetzt fungiert das „Internetarchiv“ als Aufbewahrungsort für Fotos und andere Bilder der NASA, offene Bibliothekstexte usw.
Wie existiert die Organisation?
Das "Archiv" besteht aus freiwilligen Spenden - sowohl von Organisationen als auch von Einzelpersonen. Sie können Bitcoins unterstützen. Die Brieftaschennummer lautet 1Archive1n2C579dMsAu3iC6tWzuQJz8dN. Diese Brieftasche hat im Übrigen während ihres Bestehens 357,47245492 BTC erhalten, was derzeit etwa 2,25 Millionen US-Dollar entspricht.
Wie funktioniert "Archiv"?
Die meisten Mitarbeiter sind in den Buchscanzentren beschäftigt und erledigen routinemäßige, aber zeitaufwändige Arbeiten. Die Organisation verfügt über drei Rechenzentren in Kalifornien, USA. Eine in San Francisco, eine in der Stadt Redwood, eine in Richmond. Um das Risiko eines Datenverlusts im Falle einer Naturkatastrophe oder anderer Katastrophen zu vermeiden, verfügt das "Archiv" über Kapazitätsreserven in Ägypten und Amsterdam.
„Millionen von Menschen haben viel Zeit und Mühe aufgewendet, um mit anderen zu teilen, was wir in Form des Internets wissen. Wir möchten eine Bibliothek für diese neue Veröffentlichungsplattform erstellen “, sagte Brewster Kahle, der Gründer des Internetarchivs.
Wie groß ist das "Archiv" jetzt?
Das "Internetarchiv" hat mehrere Abteilungen, und diejenige, die Informationen von den Websites sammelt, hat ihren eigenen Namen - Wayback Machine. Zum Zeitpunkt der Erstellung der "Anfrage" enthielt das Archiv 339 Milliarden gespeicherte Webseiten. Im Jahr 2017 wurden im „Archiv“ 30 Petabyte an Informationen
gespeichert, dh etwa 300 Milliarden Webseiten, 12 Millionen Bücher, 4 Millionen Audioaufnahmen, 3,3 Millionen Videos, 1,5 Millionen Fotos und 170.000 verschiedene Softwareverteilungen. In nur einem Jahr hat der Service deutlich "an Gewicht zugenommen". Jetzt speichert das "Archiv" 339 Milliarden Webseiten, 19 Millionen Bücher, 4,5 Millionen Videodateien, 4,7 Millionen Audiodateien, 3,2 Millionen Bilder verschiedener Art und 381.000 Softwareverteilungen.
Wie ist die Datenspeicherung organisiert?
Die Informationen werden auf Festplatten in den sogenannten "Datenknoten" gespeichert. Dies sind die Server. Jede von ihnen enthält 36 Festplatten (plus zwei Betriebssystemlaufwerke). Datenknoten sind in Arrays von 10 Computern gruppiert und repräsentieren einen Clusterspeicher. Im Jahr 2016 verwendete das „Archiv“ eine 8-Terabyte-Festplatte, jetzt ist die Situation ungefähr gleich. Es stellt sich heraus, dass ein Knoten ungefähr 288 Terabyte Daten speichert. Im Allgemeinen werden auch Festplatten anderer Größen verwendet: 2,3 und 4 TB.
Im Jahr 2016 gab es rund 20.000 Festplatten. Die Rechenzentren des "Archivs" sind mit Klimaanlagen zur Klimatisierung mit konstanten Eigenschaften ausgestattet. Ein Cluster-Speicher mit 10 Knoten verbraucht etwa 5 Kilowatt Energie.
Die Struktur des Internetarchivs ist eine virtuelle "Bibliothek", die in Abschnitte wie Bücher, Filme, Musik usw. unterteilt ist. Für jedes Element gibt es eine Beschreibung im Katalog - normalerweise den Namen, den Namen des Autors und zusätzliche Informationen. Aus technischer Sicht sind die Elemente strukturiert und befinden sich in Linux-Verzeichnissen.
Die Gesamtmenge der vom "Archiv" gespeicherten Daten beträgt 22 PB, und jetzt ist Platz für weitere 22 PB. "Weil wir paranoid sind" - geben die Vertreter des Dienstes an.

Schauen Sie sich den Screenshot des Verzeichnisinhalts an - es gibt eine Datei mit dem Namen, der mit "_files.xml" endet. Dies ist ein Verzeichnis mit Informationen zu allen Dateien im Verzeichnis.
Was passiert mit den Daten, wenn ein oder mehrere Server ausfallen?
Nichts schlechtes - die Daten werden dupliziert. Sobald ein neues Element in der "Archiv" -Bibliothek angezeigt wird, wird es
sofort repliziert und auf verschiedenen Festplatten auf verschiedenen Servern abgelegt. Der Prozess der Inhaltsspiegelung hilft bei der Bewältigung von Problemen wie Stromausfällen und Dateisystemausfällen.
Wenn die Festplatte ausfällt, wird sie durch eine neue ersetzt. Dank der gespiegelten und reduzierten Datenstruktur werden diese sofort mit Daten gefüllt, die auf der alten Festplatte ausgefallen sind.
Das "Archiv" verfügt über ein spezielles System, das den Status der Festplatte überwacht. Während eines Tages müssen Sie 6 bis 7 der ausgefallenen Laufwerke ersetzen.
Was ist eine Wayback-Maschine?
Dies ist nur einer der "Internetarchiv" -Dienste, die sich auf das Speichern von Webseiten spezialisiert haben. Der Dienst verfügt über eine eigene "Spinne", die regelmäßig alle im Netzwerk verfügbaren Sites überprüft und auf spezialisierten Servern speichert. Je beliebter eine Website ist, desto häufiger kopiert der Roboter ihren Inhalt. Wenn der Ressourcenadministrator nicht möchte, dass die Site-Informationen vom Bot kopiert werden, reicht es aus, ein Verbot in der Datei robots.txt zu registrieren.
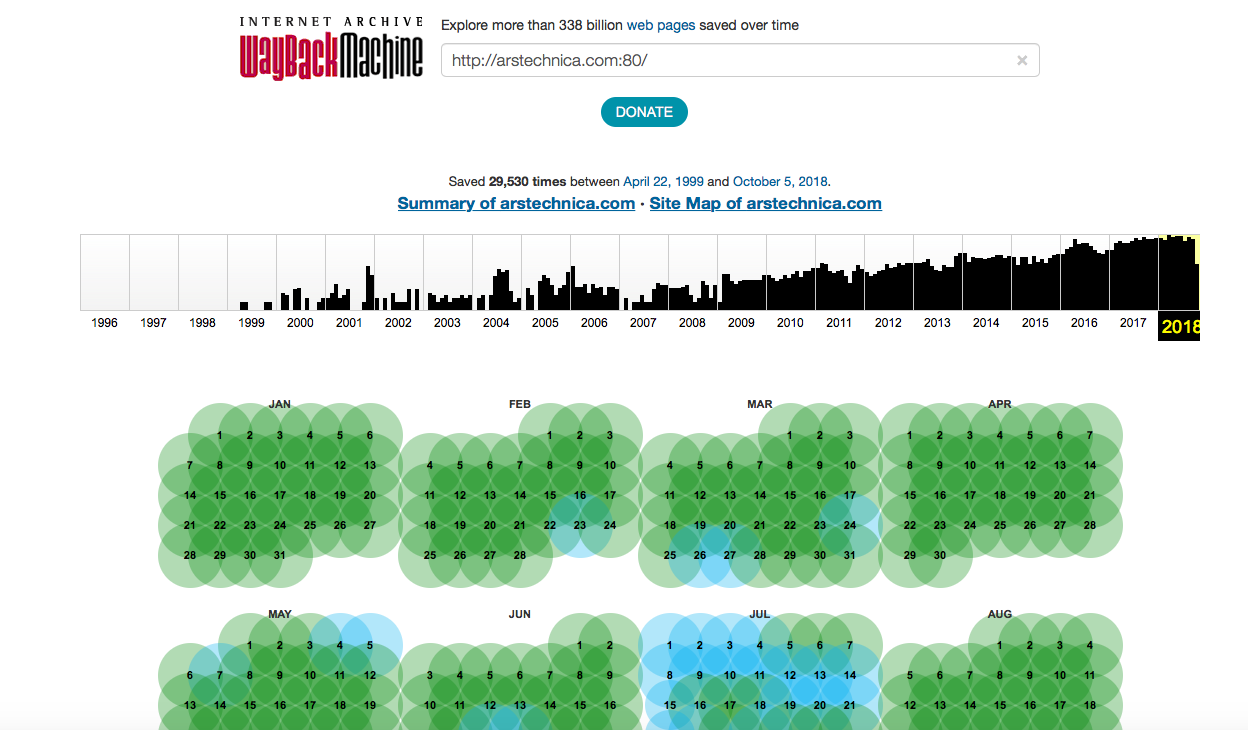 Beliebte Ressourcen werden häufig kopiert - fast täglich. Wayback Machine indiziert sogar die sozialen Netzwerke, einschließlich Twitter, Facebook
Beliebte Ressourcen werden häufig kopiert - fast täglich. Wayback Machine indiziert sogar die sozialen Netzwerke, einschließlich Twitter, Facebook
Im Jahr 2017 startete das „Archiv“ die aktualisierte Wayback-Maschine, die einen bequemeren Zugriff auf die gespeicherten Webseiten verspricht. Der Service wurde stark überarbeitet, wenn nicht von Grund auf neu codiert. Jetzt unterstützt es eine Reihe von Dateiformaten, die zuvor einfach nicht gespeichert werden konnten. Im selben Jahr 2017 gab die Organisation bekannt, dass ihre Server jede Woche etwa 1 Milliarde Webseiten einsparen.
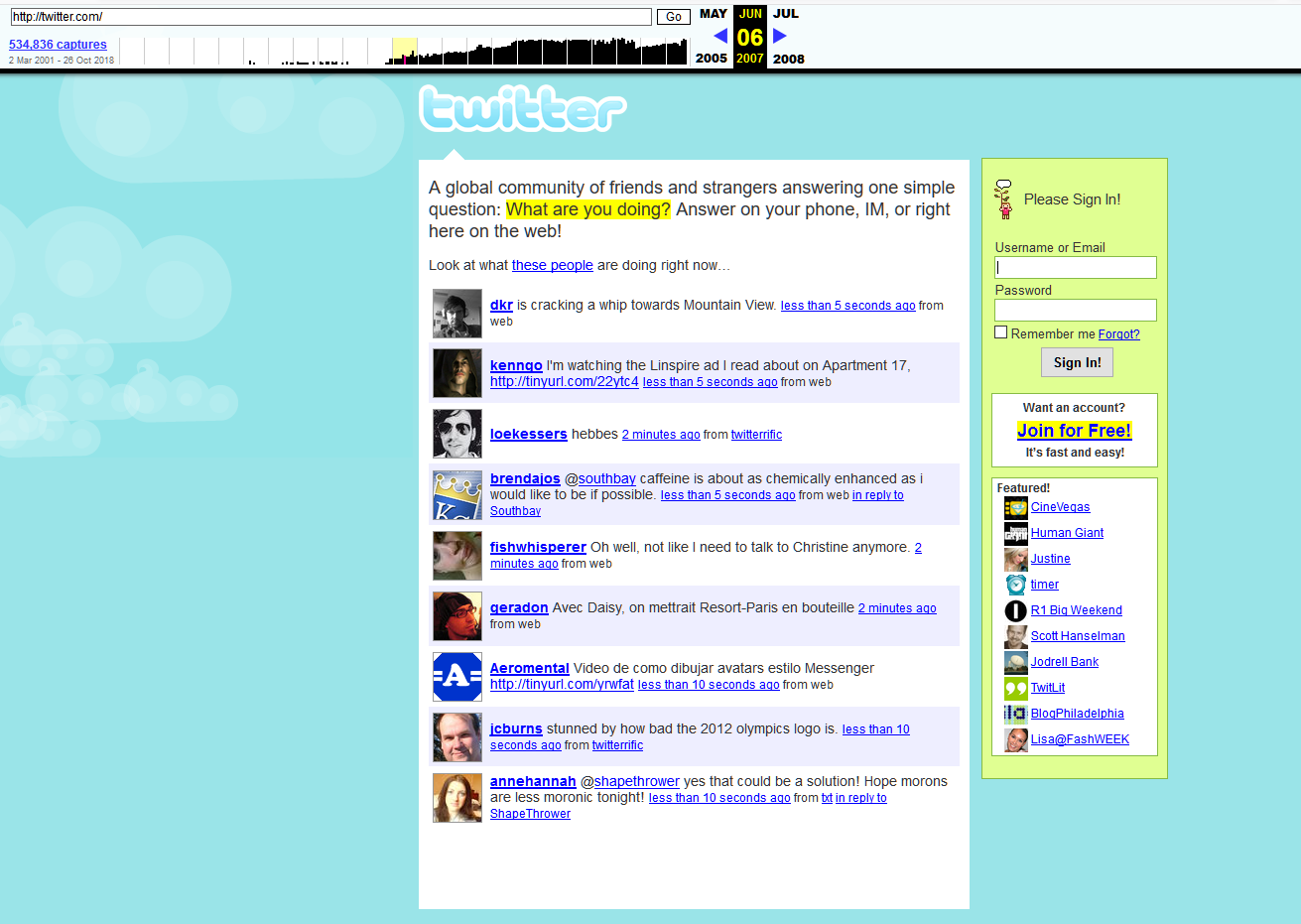 So sah Twitter 2007 aus
So sah Twitter 2007 ausWas kann man sonst noch in der Datenbank "Internetarchiv" finden?
Bücher Die Sammlung der Organisation ist riesig und umfasst digitalisierte Bücher, sowohl gängige als auch sehr seltene Ausgaben. Die Bücher werden nicht nur in Englisch, sondern auch in vielen anderen Sprachen gespeichert. Das "Archiv" verfügt über spezialisierte Zentren zum Scannen von Büchern, insgesamt 33 solcher Zentren. Sie befinden sich in fünf Ländern auf der ganzen Welt.
Die Mitarbeiter des Zentrums scannen täglich etwa 1.000 Bücher. Die Datenbank des Dienstes enthält Millionen von Veröffentlichungen. Die Arbeit an ihrer Digitalisierung wird sowohl von einfachen Leuten als auch von verschiedenen Organisationen, einschließlich Bibliotheken und Stiftungen, finanziert.
Seit 2007 speichert das „Internetarchiv“ öffentliche Bücher aus der Google Buchsuche in seiner Datenbank. Nach dem Start ist die Buchdatenbank schnell gewachsen - 2013 wurden mehr als 900.000 Bücher vom Google-Dienst gespeichert.
Einer der Dienste des "Archivs" bietet auch Zugang zu den Büchern, die vollständig geöffnet sind. Es gibt bereits mehr als eine Million von ihnen. Dieser Dienst heißt Open Library.
Video Der Dienst speichert 4,5 Millionen Videos. Sie sind in Themen unterteilt und haben einen ganz anderen Fokus. Auf den "Archiv" -Servern werden Filme, Dokumentationen, Sportveranstaltungen, Fernsehsendungen und viele andere Materialien gespeichert.
Im Jahr 2015 entstand aus dem „Archiv“ ein
Großprojekt - die Digitalisierung der Videokassetten. Anfangs waren es etwa 40.000 Kassetten aus dem Archiv von Marion Stokes, einer Frau, die die Nachrichten seit Jahrzehnten auf Band aufzeichnet. Dann summierten sich andere Videobänder. Sie wurden von den Fans der Idee, für die Menschheit wichtige Daten zu digitalisieren, ins "Archiv" geschickt.
Audiodateien. Ähnlich wie bei den Videos speichert das "Archiv" Audiodateien, die ebenfalls nach Themen unterteilt sind. Im vergangenen Jahr begann das „Archiv“ mit der Umsetzung seines neuen Projekts - der Dekodierung von Schellackaufzeichnungen, dem ältesten Format von Audioaufnahmen. Der Klang blieb auf den Schellackplatten erhalten - einem Naturharz, das von den weiblichen Schuppeninsekten isoliert wird. Insgesamt enthält das Archiv
Great 78 Project mehrere hunderttausend Datensätze .
Software Natürlich ist es einfach unmöglich, die gesamte von der Menschheit erstellte Software zu speichern, selbst für das "Archiv". Die Server speichern Vintage - zum Beispiel die Programme für Macintosh, Software für DOS und andere Software. Im Jahr 2016 haben die Mitarbeiter von „Archive“
über 1500 Programme für Windows 3.1 veröffentlicht. Sie können direkt im Browser arbeiten. 2017 hat das Internetarchiv das
Softwarearchiv für den ersten Macintosh veröffentlicht .
Spiele Ja, das "Archiv" bietet Zugriff auf eine Vielzahl von Spielen. Einige von ihnen können in der Browser-Emulator-Umgebung abgespielt werden. Eine Vielzahl von Spielen wird gespeichert, einschließlich des für die
tragbaren Analog-Digital-Konsolen . Es gibt
Spiele für MS-DOS und Konsolenspiele
für Atari und ColecoVision .

Zum ersten Mal wurde das Archiv alter Spiele 2013 von der Organisation
hochgeladen . Wir sprechen über die Titel von vor 30-40 Jahren, die direkt im Browser abgespielt werden konnten. Dies sind die Spiele für Atari 2600 (1977), Atari 7800 (1986), ColecoVision (1982), Philips Videopac G7000 (1978) und Astrocade (1983). Das Interessanteste ist, dass das Internetarchiv dafür gesorgt hat, dass Sie legal spielen können. Jetzt hat die Sammlung
mehr als 3400 Spiele und wächst weiter.