Dies ist der zweite Teil meiner
Kubernetes in der Enterprise-Postserie . Wie ich in meinem letzten Beitrag erwähnt habe, ist es beim Übergang zu
„Design and Implementation Guides“ sehr wichtig,
dass alle Menschen Kubernetes (K8s) auf dem gleichen Verständnisniveau haben.
Ich möchte hier nicht den traditionellen Ansatz verfolgen, um die Architektur und Technologien von Kubernetes zu erläutern, aber ich werde alles durch einen Vergleich mit der vSphere-Plattform erklären, mit der Sie als VMware-Benutzer vertraut sind. Auf diese Weise können Sie die offensichtliche Verwirrung und Schwere des Verständnisses von Kubernetes überwinden. Ich habe diesen Ansatz in VMware verwendet, um Kubernetes einem unterschiedlichen Hörerpublikum vorzustellen. Es hat bewiesen, dass es hervorragend funktioniert und Menschen dabei hilft, Schlüsselkonzepte schnell zu beherrschen.
Wichtiger Hinweis bevor wir beginnen. Ich verwende diesen Vergleich nicht, um Ähnlichkeiten oder Unterschiede zwischen vSphere und Kubernetes nachzuweisen. Sowohl das als auch ein anderes sind im Wesentlichen verteilte Systeme und sollten daher Ähnlichkeiten mit jedem anderen ähnlichen System aufweisen. Daher versuche ich am Ende, einer so breiten Community von Benutzern eine so wunderbare Technologie wie Kubernetes vorzustellen.

Ein bisschen Geschichte
Um diesen Beitrag zu lesen, müssen Sie die Container kennenlernen. Ich werde die Grundkonzepte von Containern nicht beschreiben, da es viele Ressourcen gibt, die darüber sprechen. Wenn ich sehr oft mit Kunden spreche, sehe ich, dass sie nicht verstehen können, warum Container unsere Branche eroberten und in Rekordzeit sehr beliebt wurden. Um diese Frage zu beantworten, werde ich über meine praktischen Erfahrungen beim Verständnis der Veränderungen in unserer Branche sprechen.
Bevor ich die Welt der Telekommunikation erkundete, war ich Webentwickler (2003).
Dies war mein zweiter bezahlter Job, nachdem ich als Netzwerktechniker / Administrator gearbeitet hatte (ich weiß, dass ich ein Alleskönner war). Ich habe in PHP entwickelt. Ich habe alle Arten von Anwendungen entwickelt, angefangen bei kleinen Anwendungen, die mein Arbeitgeber verwendet hat, bis hin zu einer professionellen Abstimmungsanwendung für Fernsehprogramme und sogar Telekommunikationsanwendungen, die mit VSAT-Hubs und Satellitensystemen interagieren. Das Leben war großartig, mit Ausnahme einer großen Hürde, die jeder Entwickler kennt, nämlich der Sucht.
Zuerst entwickelte ich die Anwendung auf meinem Laptop unter Verwendung des LAMP-Stacks. Als sie auf meinem Laptop gut funktionierte, lud ich den Quellcode auf die Hostserver (jeder erinnert sich an RackShack?) Oder auf die privaten Server des Kunden herunter. Sie können sich vorstellen, dass die Anwendung sofort abgestürzt ist und auf diesen Servern nicht funktioniert hat. Der Grund dafür ist Sucht. Die Server hatten andere Versionen der Software (Apache, PHP, MySQL usw.) als die von mir auf dem Laptop verwendeten. Ich musste also einen Weg finden, um die Softwareversionen auf den Remote-Servern zu aktualisieren (schlechte Idee) oder den Code auf meinem Laptop neu zu schreiben, damit er mit den Versionen auf den Remote-Servern übereinstimmt (schlechteste Idee). Es war ein Albtraum, manchmal hasste ich mich selbst und fragte mich, warum ich so meinen Lebensunterhalt verdiene.
10 Jahre sind vergangen, die Firma Docker erschien. Als VMware-Berater bei Professional Services (2013) hörte ich von Docker und ließ mich sagen, dass ich diese Technologie damals nicht verstehen konnte. Ich fuhr fort zu sagen: Warum Container verwenden, wenn es virtuelle Maschinen gibt. Warum sollten Sie wichtige Technologien wie vSphere HA, DRS oder vMotion wegen so seltsamer Vorteile wie dem sofortigen Start von Containern oder der Beseitigung des Hypervisor-Overheads aufgeben? Schließlich arbeitet jeder mit virtuellen Maschinen und funktioniert perfekt. Kurz gesagt, ich habe es in Bezug auf die Infrastruktur betrachtet.
Aber dann fing ich an genau hinzuschauen und es dämmerte mir. Alles, was mit Docker zu tun hat, bezieht sich auf Entwickler. Als ich gerade anfing, als Entwickler zu denken, wurde mir sofort klar, dass ich mit dieser Technologie im Jahr 2003 alle meine Abhängigkeiten packen könnte. Meine Webanwendungen können unabhängig vom verwendeten Server funktionieren. Darüber hinaus wäre es nicht erforderlich, den Quellcode herunterzuladen oder etwas zu konfigurieren. Sie können meine Anwendung einfach in ein Bild „packen“ und Kunden bitten, dieses Bild herunterzuladen und auszuführen. Dies ist der Traum eines jeden Webentwicklers!
Das alles ist großartig. Docker hat das große Interaktions- und Verpackungsproblem gelöst, aber wie geht es weiter? Kann ich als Unternehmenskunde diese Anwendungen während der Skalierung verwalten? Ich möchte weiterhin HA, DRS, vMotion und DR verwenden. Docker hat die Probleme meiner Entwickler gelöst und eine ganze Reihe von Problemen für meine Administratoren (DevOps-Team) verursacht. Sie benötigen eine Plattform zum Starten von Containern, genau wie die zum Starten von virtuellen Maschinen. Und wir kehrten wieder zum Anfang zurück.
Aber dann erschien Google und erzählte der Welt über die Verwendung von Containern seit vielen Jahren (tatsächlich wurden Container von Google erfunden: cgroups) und die richtige Methode, sie über eine Plattform zu verwenden, die sie Kubernetes nannten. Dann öffneten sie den Quellcode für Kubernetes. Präsentiert der Kubernetes Community. Und das hat alles wieder verändert.
Grundlegendes zu Kubernetes im Vergleich zu vSphere
Was ist Kubernetes? Einfach ausgedrückt ist Kubernetes für Container dasselbe wie vSphere für virtuelle Maschinen in einem modernen Rechenzentrum. Wenn Sie VMware Workstation in den frühen 2000er Jahren verwendet haben, wissen Sie, dass diese Lösung ernsthaft als Lösung für Rechenzentren angesehen wurde. Als VI / vSphere mit vCenter- und ESXi-Hosts erschien, änderte sich die Welt der virtuellen Maschinen dramatisch. Kubernetes macht heute dasselbe mit der Welt der Container und bietet die Möglichkeit, Container in der Produktion zu starten und zu verwalten. Aus diesem Grund werden wir vSphere Seite an Seite mit Kubernetes vergleichen, um die Details dieses verteilten Systems zu erläutern und seine Funktionen und Technologien zu verstehen.

Systemübersicht
Wie in vSphere gibt es im Konzept von Kubernetes vCenter- und ESXi-Hosts, es gibt Master- und Node-Hosts. In diesem Zusammenhang entspricht Master in K8s vCenter in dem Sinne, dass es sich um die Verwaltungsebene eines verteilten Systems handelt. Es ist auch der Einstiegspunkt für die API, mit der Sie bei der Verwaltung Ihrer Workload interagieren. Auf die gleiche Weise fungieren K8s-Knoten ähnlich wie ESXi-Hosts als Computerressourcen. Auf ihnen führen Sie Workloads aus (im Fall von K8s nennen wir sie Pods). Knoten können virtuelle Maschinen oder physische Server sein. Bei vSphere ESXi müssen Hosts natürlich immer physisch sein.

Sie können sehen, dass K8s einen Schlüsselwertspeicher namens "etcd" hat. Dieser Speicher ähnelt der vCenter-Datenbank, in der Sie die gewünschte Clusterkonfiguration speichern, die Sie einhalten möchten.
Was die Unterschiede betrifft: Auf Master K8s können Sie auch Workloads ausführen, auf vCenter jedoch nicht. vCenter ist eine virtuelle Appliance, die ausschließlich der Verwaltung gewidmet ist. Im Fall von K8s wird Master als Computerressource betrachtet, aber das Ausführen von Enterprise-Anwendungen darauf ist keine gute Idee.
Wie wird es in der Realität aussehen? Sie werden hauptsächlich die CLI verwenden, um mit Kubernetes zu interagieren (aber die GUI ist immer noch eine sehr praktikable Option). Der folgende Screenshot zeigt, dass ich einen Windows-Computer verwende, um über die Befehlszeile eine Verbindung zu meinem Kubernetes-Cluster herzustellen (ich verwende cmder, wenn Sie interessiert sind). Im Screenshot habe ich einen Master-Knoten und 4 Knoten. Sie arbeiten unter der Kontrolle von K8s v1.6.5 und das Betriebssystem Ubuntu 16.04 ist auf den Knoten installiert. Zum Zeitpunkt des Schreibens dieses Beitrags leben wir hauptsächlich in der Linux-Welt, in der Master und Node immer eine Linux-Distribution ausführen.
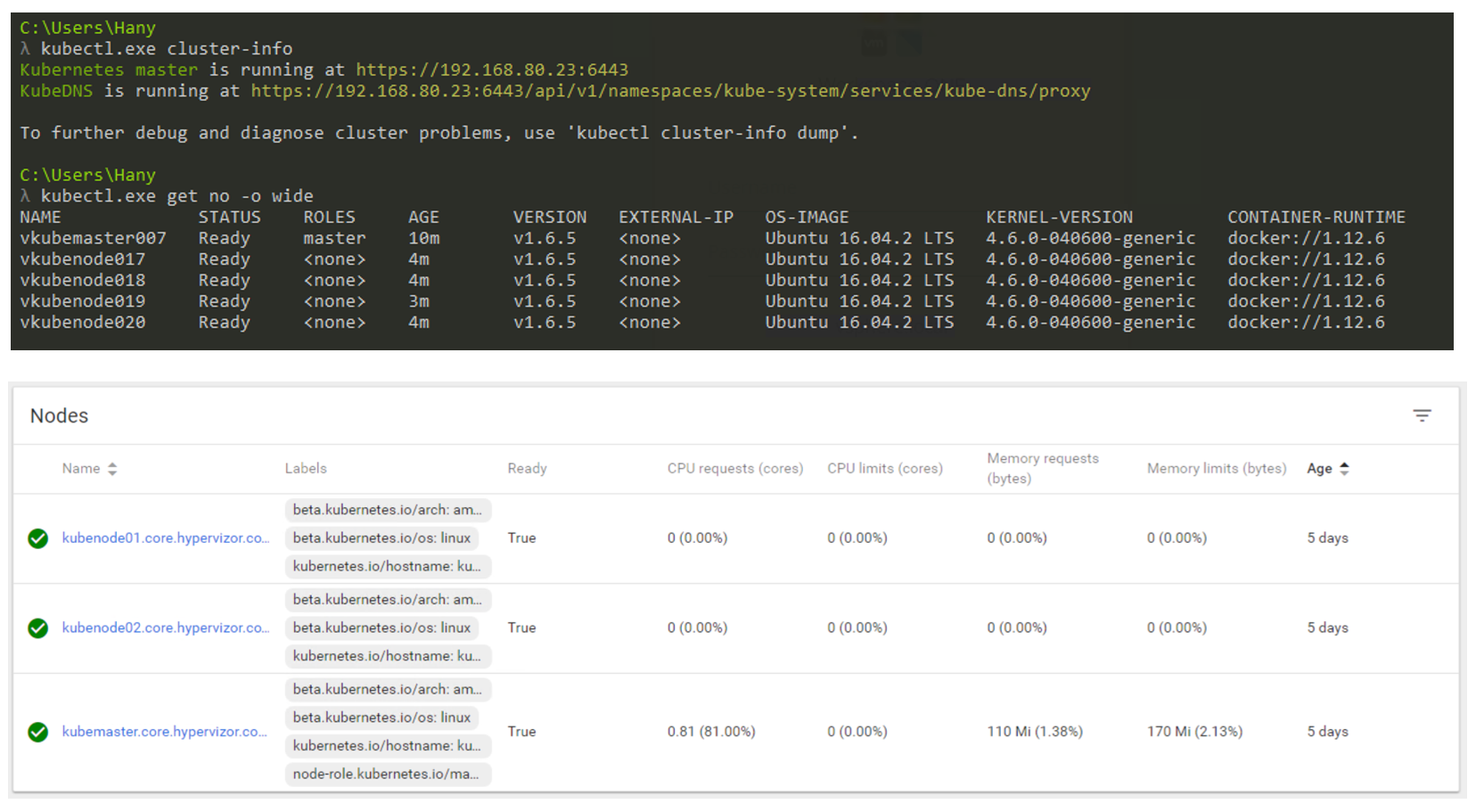 K8s Cluster-Management über CLI und GUI.
K8s Cluster-Management über CLI und GUI.Workload-Formfaktor
In vSphere ist die virtuelle Maschine die logische Grenze des Betriebssystems. In Kubernetes sind Pods wie der ESXi-Host Containergrenzen, auf denen mehrere virtuelle Maschinen gleichzeitig ausgeführt werden können. Jeder Knoten kann mehrere Pods ausführen. Jeder Pod erhält wie virtuelle Maschinen eine routingfähige IP-Adresse, über die Pods miteinander kommunizieren können.
In vSphere werden Anwendungen innerhalb des Betriebssystems ausgeführt, und in Kubernetes werden Anwendungen in Containern ausgeführt. Eine virtuelle Maschine kann jeweils nur mit einem Betriebssystem arbeiten, und ein Pod kann mehrere Container ausführen.
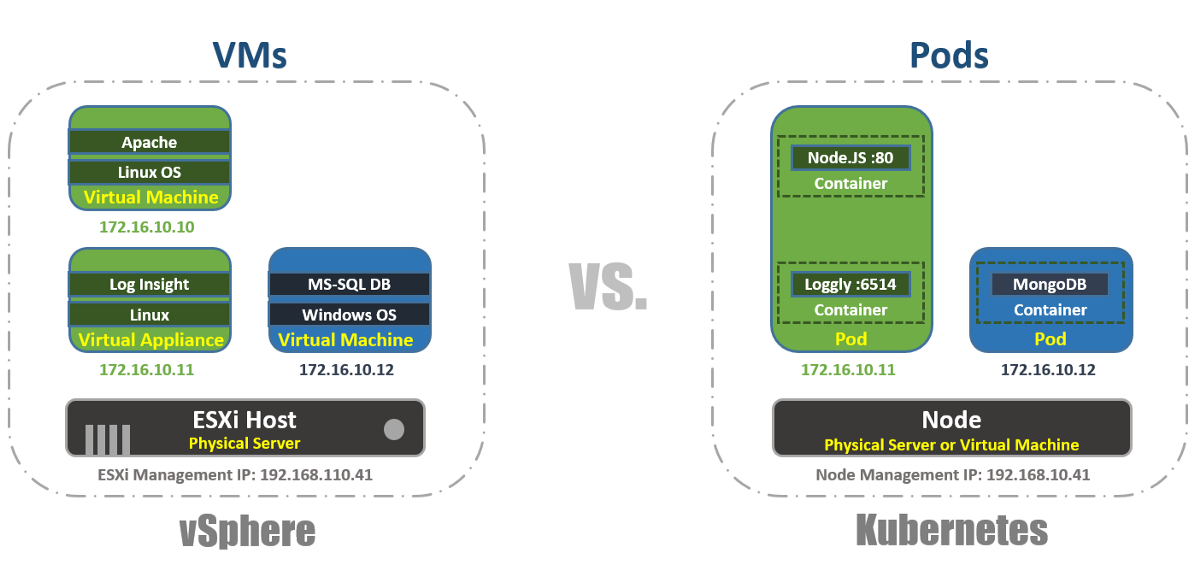
Auf diese Weise können Sie die Pods im K8s-Cluster mithilfe des kubectl-Tools über die CLI auflisten und die Funktionalität der Pods, ihr Alter, ihre IP-Adresse und die Knoten überprüfen, an denen sie gerade arbeiten.

Management
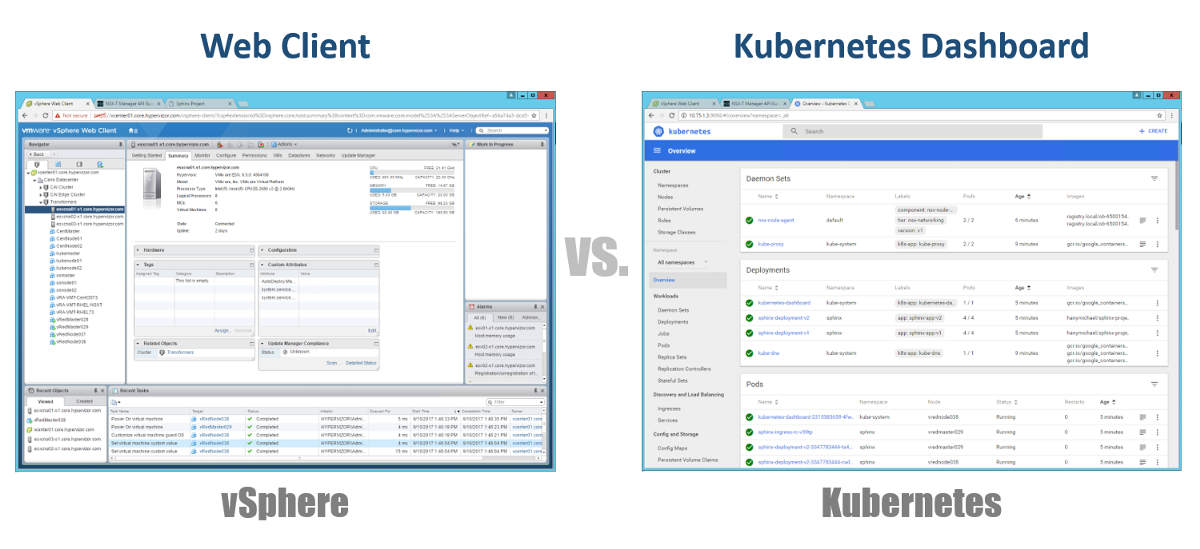
Wie verwalten wir unsere Master, Knoten und Pods? Bei vSphere verwenden wir den Webclient, um die meisten (wenn nicht alle) Komponenten unserer virtuellen Infrastruktur zu verwalten. Für Kubernetes ebenfalls Dashboard. Dies ist ein gutes GUI-basiertes Webportal, auf das Sie über Ihren Browser genauso zugreifen können wie mit dem vSphere Web Client. In den vorherigen Abschnitten können Sie sehen, dass Sie Ihren K8s-Cluster mit dem Befehl kubeclt über die CLI verwalten können. Es ist immer umstritten, wo Sie die meiste Zeit in der CLI oder im grafischen Dashboard verbringen werden. Da letzteres von Tag zu Tag immer leistungsfähiger wird (Sie können dieses Video sicher sehen). Persönlich denke ich, dass das Dashboard sehr praktisch ist, um den Status schnell zu überwachen oder die Details verschiedener K8-Komponenten anzuzeigen, sodass keine langen Befehle in die CLI eingegeben werden müssen. Sie werden auf natürliche Weise ein Gleichgewicht zwischen ihnen finden.
Konfigurationen
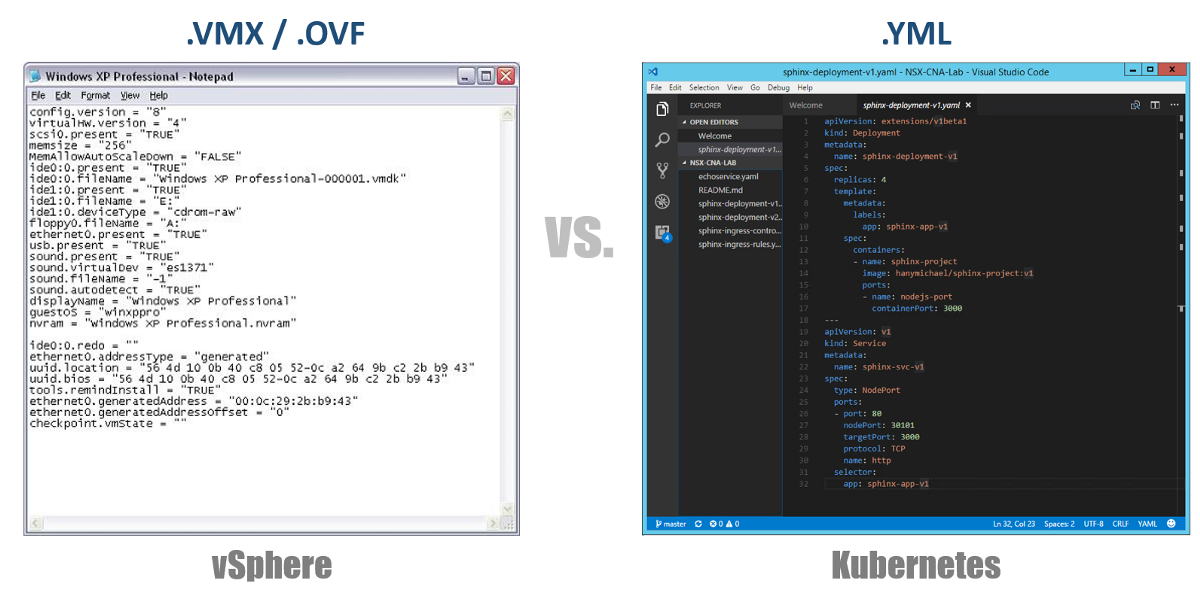
Eines der sehr wichtigen Konzepte in Kubernetes ist der gewünschte Status der Konfigurationen. Sie erklären, dass Sie für fast jede Kubernetes-Komponente über eine YAML-Datei möchten, und erstellen dies alles mit kubectl (oder über ein grafisches Dashboard) als gewünschten Status. Von nun an ist Kubernetes stets bemüht, Ihre Umgebung in einem bestimmten Betriebszustand zu halten. Wenn Sie beispielsweise 4 Replikate eines Pods haben möchten, überwachen K8s diese Pods weiterhin. Wenn einer von ihnen gestorben ist oder der Knoten, an dem er gearbeitet hat, Probleme hatte, werden K8s sich selbst wiederherstellen und diese automatisch erstellen Pod woanders.
Wenn Sie zu unseren YAML-Konfigurationsdateien zurückkehren, können Sie diese als VMX-Datei für eine virtuelle Maschine oder als OVF-Deskriptor für eine virtuelle Appliance betrachten, die Sie in vSphere bereitstellen möchten. Diese Dateien definieren die Konfiguration der Workload / Komponente, die Sie ausführen möchten. Im Gegensatz zu VMX / OVF-Dateien, die ausschließlich für virtuelle VMs / Appliances verfügbar sind, werden YAML-Konfigurationsdateien zum Definieren von K8s-Komponenten wie ReplicaSets, Services, Deployments usw. verwendet. Beachten Sie dies in den folgenden Abschnitten.
Virtuelle Cluster
In vSphere haben wir physische ESXi-Hosts, die logisch in Clustern gruppiert sind. Diese Cluster können in andere virtuelle Cluster unterteilt werden, die als "Ressourcenpools" bezeichnet werden. Diese „Pools“ werden hauptsächlich zur Begrenzung von Ressourcen verwendet. Bei Kubernetes haben wir etwas sehr Ähnliches. Wir nennen sie "Namespaces". Sie können auch verwendet werden, um Ressourcenlimits bereitzustellen, die im nächsten Abschnitt erläutert werden. In den meisten Fällen werden „Namespaces“ jedoch als mandantenfähiges Tool für Anwendungen (oder Benutzer, wenn Sie gängige K8-Cluster verwenden) verwendet. Dies ist auch eine der Optionen, mit denen Sie die Netzwerksegmentierung mit NSX-T durchführen können. Berücksichtigen Sie dies in den folgenden Veröffentlichungen.
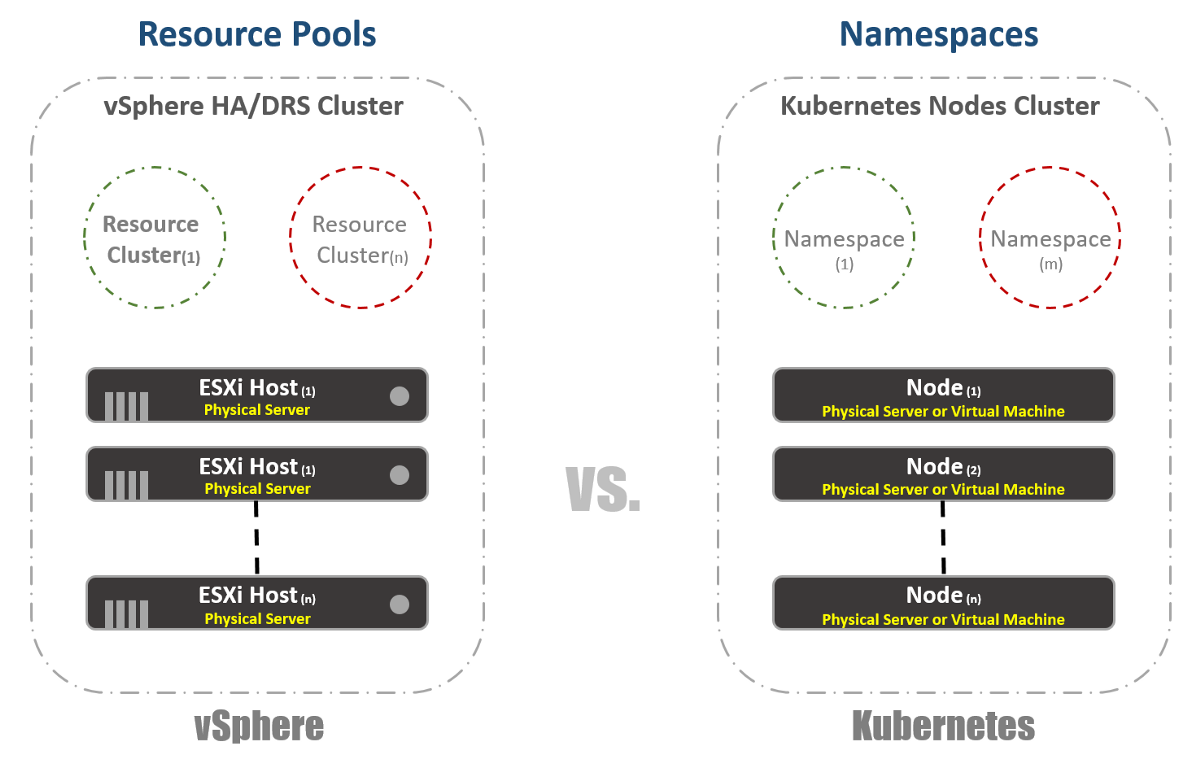
Ressourcenmanagement
Wie bereits im vorherigen Abschnitt erwähnt, werden Namespaces in Kubernetes häufig als Mittel zur Segmentierung verwendet. Eine andere Verwendung von Namespaces ist die Ressourcenzuweisung. Diese Option wird als "Ressourcenkontingente" bezeichnet. Wie aus den vorherigen Abschnitten hervorgeht, erfolgt die Definition in den Konfigurations-YAML-Dateien, in denen der gewünschte Status deklariert ist. In vSphere bestimmen wir dies, wie im folgenden Screenshot zu sehen, anhand der Einstellungen für Ressourcenpools.

Identifizierung der Arbeitslast
Dies ist ziemlich einfach und für vSphere und Kubernetes fast gleich. Im ersten Fall verwenden wir die Konzepte von Tags, um ähnliche Workloads zu definieren (oder zu gruppieren), und im zweiten Fall verwenden wir den Begriff „Labels“. Bei Kubernetes ist die Identifizierung der Arbeitslast obligatorisch.

Reservierung
Nun zum richtigen Spaß. Wenn Sie wie ich ein großer Fan von vSphere FT waren oder sind, werden Sie diese Funktion in Kubernetes trotz einiger Unterschiede zwischen den beiden Technologien lieben. In vSphere handelt es sich um eine virtuelle Maschine mit einer laufenden Schatteninstanz, die auf einem anderen Host ausgeführt wird. Wir zeichnen Anweisungen auf der virtuellen Hauptmaschine auf und spielen sie auf der virtuellen Schattenmaschine wieder. Wenn die Hauptmaschine nicht mehr funktioniert, wird die virtuelle Schattenmaschine sofort eingeschaltet. Anschließend versucht vSphere, einen anderen ESXi-Host zu finden, um eine neue Schatteninstanz der virtuellen Maschine zu erstellen und die gleiche Redundanz beizubehalten. Bei Kubernetes haben wir etwas sehr Ähnliches. ReplicaSets ist der Betrag, den Sie angeben, um mehrere Instanzen von Pods auszuführen. Wenn ein Pod ausfällt, stehen andere Instanzen zur Verfügung, um den Datenverkehr zu bedienen. Gleichzeitig versucht K8s, auf jedem verfügbaren Knoten einen neuen Pod zu starten, um den gewünschten Konfigurationsstatus beizubehalten. Der Hauptunterschied besteht, wie Sie vielleicht bereits bemerkt haben, darin, dass Pods bei K8 immer funktionieren und den Verkehr bedienen. Sie sind keine Schatten-Workloads.

Lastausgleich
Obwohl dies möglicherweise keine in vSphere integrierte Funktion ist, ist es sehr, sehr häufig erforderlich, Load Balancer auf der Plattform auszuführen. In der vSphere-Welt gibt es virtuelle oder physische Load Balancer zum Verteilen des Netzwerkverkehrs auf mehrere virtuelle Maschinen. Es kann viele verschiedene Konfigurationsmodi geben, aber nehmen wir an, wir meinen einarmige Konfiguration. In diesem Fall gleichen Sie die Last des Ost-West-Verkehrs auf Ihren virtuellen Maschinen aus.
Ebenso hat Kubernetes das Konzept der "Dienste". Der Dienst in K8s kann auch in verschiedenen Konfigurationsmodi verwendet werden. Wählen wir die ClusterIP-Konfiguration, um sie mit dem One-Armed Load Balancer zu vergleichen. In diesem Fall verfügt der Dienst in K8 über eine virtuelle IP-Adresse (VIP), die immer statisch ist und sich nicht ändert. Dieser VIP verteilt den Datenverkehr auf mehrere Pods. Dies ist besonders wichtig in der Kubernetes-Welt, in der Pods von Natur aus vergänglich sind und Sie die IP-Adresse des Pods verlieren, sobald dieser stirbt oder gelöscht wird. Daher sollten Sie immer einen statischen VIP angeben.
Wie bereits erwähnt, verfügt Service über viele andere Konfigurationen, z. B. "NodePort", bei denen Sie einen Port auf Knotenebene zuweisen und anschließend die Übersetzung von Portadressen für Pods durchführen. Es gibt auch einen „LoadBalancer“, in dem Sie eine Load Balancer-Instanz von einem Drittanbieter oder Cloud-Anbieter ausführen.

Kuberentes verfügt über einen weiteren sehr wichtigen Lastausgleichsmechanismus, den „Ingress Controller“. Sie können es als Inline-Load-Balancer für Anwendungen betrachten. Die Hauptidee ist, dass der Ingress Controller (in Form eines Pods) mit einer von außen sichtbaren IP-Adresse gestartet wird. Diese IP-Adresse enthält möglicherweise Platzhalter-DNS-Einträge. Wenn der Datenverkehr über eine externe IP-Adresse beim Ingress Controller eintrifft, überprüft er die Header und ermittelt anhand der zuvor festgelegten Regeln, zu welchem Pod dieser Name gehört. Beispiel: sphinx-v1.esxcloud.net wird an den Dienst sphinx-svc-1 und sphinx-v2.esxcloud.net an den Dienst sphinx-svc2 usw. weitergeleitet.

Speicher und Netzwerk
Speicher und Vernetzung sind sehr, sehr breite Themen, wenn es um Kubernetes geht. Es ist fast unmöglich, in einem Einführungsbeitrag kurz auf diese beiden Themen einzugehen, aber ich werde bald ausführlich auf die verschiedenen Konzepte und Optionen für jedes dieser Themen eingehen. Schauen wir uns in der Zwischenzeit kurz an, wie der Netzwerkstapel in Kubernetes funktioniert, wie wir ihn im nächsten Abschnitt benötigen werden.
Kubernetes verfügt über verschiedene Netzwerk-Plugins, mit denen Sie das Netzwerk Ihrer Knoten und Pods konfigurieren können. Ein gängiges Plugin ist "kubenet", das derzeit in Mega-Clouds wie GCP und AWS verwendet wird. Hier werde ich kurz auf die Implementierung von GCP eingehen und dann ein praktisches Beispiel für die Implementierung in GKE zeigen.

Auf den ersten Blick mag dies zu kompliziert erscheinen, aber ich hoffe, Sie können dies alles am Ende dieses Beitrags verstehen. Erstens sehen wir, dass wir zwei Kubernetes-Knoten haben: Knoten 1 und Knoten (m). Jeder Knoten verfügt wie jeder Linux-Computer über eine eth0-Schnittstelle. Diese Schnittstelle hat eine IP-Adresse für die Außenwelt, in unserem Fall im Subnetz 10.140.0.0/24. Das Upstream L3-Gerät fungiert als Standard-Gateway für die Weiterleitung unseres Datenverkehrs. Es kann sich um einen L3-Switch in Ihrem Rechenzentrum oder einen VPC-Router in der Cloud wie GCP handeln, wie wir später sehen werden. Geht alles gut?
Weiter sehen wir, dass wir die Bridge-Schnittstelle cbr0 innerhalb des Knotens haben. Diese Schnittstelle ist das Standard-Gateway für das IP-Subnetz 10.40.1.0/24 im Fall von Knoten 1. Dieses Subnetz wird von Kubernetes jedem Knoten zugewiesen. Knoten erhalten normalerweise ein / 24-Subnetz, aber Sie können dies mit NSX-T ändern (wir werden dies in den folgenden Beiträgen behandeln). Im Moment ist dieses Subnetz dasjenige, von dem aus wir IP-Adressen für Pods vergeben werden. Auf diese Weise erhält jeder Pod in Knoten 1 eine IP-Adresse von diesem Subnetz. In unserem Fall hat Pod 1 eine IP-Adresse von 10.40.1.10. Sie stellen jedoch fest, dass sich in diesem Pod zwei verschachtelte Container befinden. Wir haben bereits gesagt, dass innerhalb eines Pods ein oder mehrere Container gestartet werden können, die hinsichtlich ihrer Funktionalität eng miteinander verbunden sind. Das sehen wir in der Abbildung. Container 1 überwacht Port 80 und Container 2 Port 90. Beide Container haben dieselbe IP-Adresse 10.40.1.10, besitzen jedoch keinen Netzwerk-Namespace. OK, wem gehört dann dieser Netzwerkstapel? Tatsächlich gibt es einen speziellen Container namens "Pause Container". , IP- IP- Pod' . , Pause Container , IP- 10.40.1.10, , , 1 80, 2 90.
, ? Linux IP Forwarding cbr0 eth0. , , L3 , ? . - L3 . 10.40.1.0/24 IP- Node 1 (10.140.0.11) 10.40.2.0/24 next hope — Node (m) IP- 10.140.0.12.
, . . - , CNI (Container Network Interface) Kuberentes, . NSX-T — , .
, kubenet, CNI. kubenet — , Google Container Engine (GKE), , , , . , GCP. .
Was weiter?
Kuberentes. ,
.
Der zweite Teil.. .
.