Viele Projekte stehen vor dem Problem von Flockentests, und dieses Thema wurde bei Habré mehr als einmal angesprochen. Tests, die sich nicht für ihren Zustand entschieden haben, benötigen nicht nur ständig Maschinenzeit, sondern auch die Zeit von Entwicklern und Testern. Und wenn Sie in einem kommerziellen Unternehmen eine bestimmte Ressource zuweisen können, um dieses Problem zu lösen und verantwortliche Personen zu ernennen, ist dies in der OpenSource-Community nicht so einfach. Besonders bei großen Projekten - zum Beispiel bei Apache Ignite, wo es fast 60.000 verschiedene Tests gibt.

In diesem Beitrag erfahren Sie, wie Sie dieses Problem in Apache Ignite lösen können. Wir sind Dmitry Pavlov, leitender Software-Ingenieur / Community-Manager bei GridGain, und Nikolai Kulagin, IT-Ingenieur bei Sberbank Technologies.
Alles, was unten geschrieben steht, repräsentiert nicht die Position eines Unternehmens, einschließlich der Sberbank. Diese Geschichte stammt ausschließlich von Mitgliedern der Apache Ignite-Community.Apache Ignite und Tests
Die Geschichte von Apache Ignite beginnt 2014, als GridGain die erste Version des internen Produkts an die Apache Software Foundation spendete. Seitdem sind mehr als 4 Jahre vergangen, und in dieser Zeit näherte sich die Anzahl der Tests der Marke von 60.000.
Wir verwenden JetBrains TeamCity als Continuous Integration Server - danke an die Jungs von JetBrains für die Unterstützung der Open Source-Bewegung. Alle unsere Tests sind auf die Suiten verteilt, deren Anzahl für den Hauptzweig nahe bei 140 liegt. In den Suiten sind die Tests nach bestimmten Kriterien gruppiert. Dies kann nur die Funktionalität des maschinellen Lernens [RunMl], nur den Cache [RunCache] oder das gesamte [RunAll] testen. In Zukunft wird der Testlauf genau [RunAll] bedeuten - eine vollständige Überprüfung. Es dauert ungefähr 55 Stunden Maschinenzeit.
Junit wird als Hauptbibliothek verwendet, es gibt jedoch nur wenige Komponententests. Bei allen unseren Tests handelt es sich größtenteils um Integrationstests, da sie den Start eines oder mehrerer Knoten enthalten (und dies dauert einige Sekunden). Integrationstests sind natürlich praktisch, da ein solcher Test viele Aspekte und Wechselwirkungen abdeckt, was mit einem einzelnen Einheitentest nur schwer zu erreichen ist. Es gibt aber auch Nachteile: In unserem Fall ist dies eine ziemlich lange Vorlaufzeit sowie die Schwierigkeit, ein Problem zu finden.
Probleme mit schuppigen
Ein Teil dieser Tests ist schuppig. Gemäß der TeamCity-Klassifizierung werden jetzt ungefähr 1.700 Tests als schuppig markiert, dh mit einer Statusänderung, ohne den Code oder die Konfiguration zu ändern. Solche Tests können nicht ignoriert werden, da die Gefahr eines Fehlers in der Produktion besteht. Daher müssen sie doppelt überprüft und manchmal mehrmals neu gestartet werden, um die Ergebnisse der Stürze zu analysieren - und dies kostet wertvolle Zeit und Mühe. Und wenn bestehende Mitglieder der Community diese Aufgabe bewältigen, kann dies für neue Mitwirkende zu einem echten Hindernis werden. Sie müssen zugeben, dass Sie bei Änderungen am Java Doc keinen Absturz erwarten, sondern nicht einen, sondern mehrere Dutzend.

Wer ist schuld?
Die Hälfte der Probleme mit Flockentests ergibt sich aus der Konfiguration der Ausrüstung aufgrund der Größe der Installation. Und die zweite Hälfte steht in direktem Zusammenhang mit Menschen, die ihren Fehler verpasst und nicht behoben haben.
Herkömmlicherweise können alle Community-Mitglieder in zwei Gruppen unterteilt werden:
- Enthusiasten, die freiwillig in die Gemeinschaft eintreten und zu ihrer Freizeit beitragen.
- Vollzeitmitarbeiter, die für Unternehmen arbeiten, die dieses Open-Source-Produkt verwenden oder damit in Verbindung stehen.
Ein Mitwirkender aus der ersten Gruppe kann durchaus eine einzige Bearbeitung vornehmen und die Community verlassen. Und es ist fast unmöglich, es zu erreichen, wenn ein Fehler entdeckt wird. Es ist einfacher, mit Personen aus der zweiten Gruppe zu interagieren. Sie reagieren eher auf einen Test, den sie brechen. Es kommt jedoch vor, dass ein Unternehmen, das zuvor an einem Produkt interessiert war, es nicht mehr benötigt. Sie verlässt die Community und ihre Mitarbeiter sind bei ihr. Oder es ist möglich, dass der Mitwirkende das Unternehmen und damit die Community verlässt. Natürlich nehmen einige nach solchen Änderungen weiterhin an der Community teil. Aber nicht alle.
Wer wird reparieren?
Wenn wir über Leute sprechen, die die Community verlassen haben, gehen ihre Fehler natürlich zu den aktuellen Mitwirkenden. Es ist erwähnenswert, dass für die Revision, die zu dem Fehler geführt hat, auch der Reviewer verantwortlich ist, aber er kann auch ein Enthusiast sein - das heißt, er wird nicht immer verfügbar sein.
Es kommt vor, dass es sich herausstellt, eine Person zu erreichen, ihm zu sagen: Das ist das Problem. Aber er sagt: Nein, dies ist nicht mein Fix, der einen Fehler verursacht hat. Da ein vollständiger Lauf des Hauptzweigs automatisch mit einer relativ freien Warteschlange ausgeführt wird, geschieht dies meistens nachts. Zuvor können mehrere Commits für den ganzen Tag in die Filiale gegossen werden.
In TeamCity wird jede Codeänderung als Änderungsprotokoll angesehen. Wenn wir nach drei Wechslern einen neuen Sturz haben, werden drei Leute sagen, dass dies nicht an ihrem Engagement liegt. Wenn es fünf Wechsler gibt, werden wir es von fünf Personen hören.
Ein weiteres Problem: Den Mitwirkenden darüber zu informieren, dass die Tests vor jeder Überprüfung ausgeführt werden müssen. Einige wissen nicht, wo, was und wie sie laufen sollen. Oder die Tests wurden ausgeführt, aber der Mitwirkende hat nicht im Ticket darüber geschrieben. Auch in dieser Phase gibt es Probleme.
Mach weiter. Angenommen, die Tests werden ausgeführt, und im Ticket befindet sich ein Link zu den Ergebnissen. Wie sich herausstellte, gibt dies jedoch keine Garantie für die Analyse der Durchlauftests. Der Mitwirkende kann sich seinen Lauf ansehen, dort einige Tropfen sehen, aber "TeamCity sieht gut aus" schreiben. Der Prüfer - insbesondere wenn er mit dem Mitwirkenden vertraut ist oder ihn bereits erfolgreich geprüft hat - sieht das Ergebnis möglicherweise nicht wirklich. Und wir bekommen diese "TeamCity sieht gut aus":
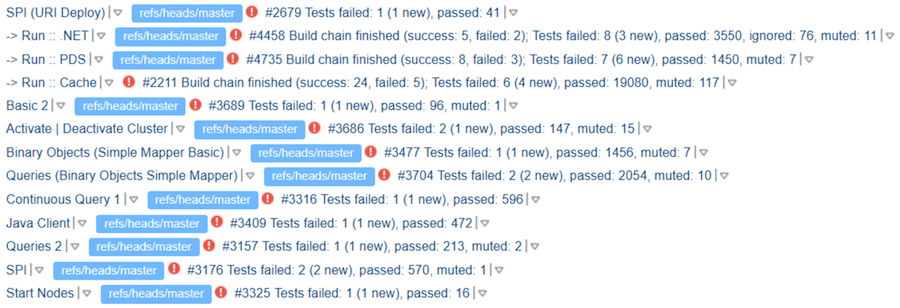
Wo "gut" hier ist, ist nicht klar. Aber anscheinend wissen die Autoren zumindest, dass Tests durchgeführt werden müssen.
Wie wir das bekämpft haben
Methode 1. Separate Tests
Wir haben die Tests in zwei Gruppen unterteilt. Im ersten "sauberen" - stabilen Test. Im zweiten - instabil. Der Ansatz ist ziemlich offensichtlich, hat aber selbst bei zwei Versuchen nicht geklappt. Warum? Weil eine Suite mit instabilen Tests zu einem Ghetto wird, in dem etwas notwendigerweise eine Zeitüberschreitung, Abstürze usw. beginnt. Infolgedessen beginnt jeder, diese immer problematischen Tests einfach zu ignorieren. Im Allgemeinen macht es keinen Sinn, Tests nach Noten zu unterteilen.
Methode 2. Trennung und Benachrichtigung
Die zweite Option ähnelt der ersten - um stabilere Tests zuzuweisen und die verbleibenden PR-Tests nachts auszuführen. Wenn in einer stabilen Gruppe etwas kaputt geht, wird eine Nachricht mit Standard-TeamCity-Tools an den Mitwirkenden gesendet, die besagt, dass etwas repariert werden muss.
... 0 Personen haben auf diese Nachrichten reagiert. Alle ignorierten sie.
Methode 3. Tägliche Überwachung
Wir haben die Suiten in mehrere "Beobachter" aufgeteilt, die verantwortungsvollsten Mitglieder der Community, und sie für Warnungen über Stürze unterschrieben. Infolgedessen wurde in der Praxis bestätigt, dass die Begeisterung tendenziell endet. Mitwirkende geben dieses Unternehmen auf und hören auf, es regelmäßig zu überprüfen. Dann habe ich es verpasst, dort hingeschaut - und wieder ist etwas in den Meister gekrochen.
Methode 4. Automatisierung
Nach einer weiteren erfolglosen Methode erinnerten sich die Jungs von GridGain an ein zuvor entwickeltes Dienstprogramm, das die zu diesem Zeitpunkt fehlenden Funktionen in TeamCity hinzufügte. Die Möglichkeit, allgemeine Statistiken über die Anzahl der Stürze anzuzeigen: Wie viel und was ist gefallen, hat das Ergebnis am nächsten Tag verschlechtert oder verbessert. Dieses Dienstprogramm wurde schrittweise entwickelt, Berichte wurden hinzugefügt und umbenannt. Dann fügten sie Benachrichtigungen hinzu, die erneut umbenannt wurden. So stellte sich heraus, TeamCity Bot. Jetzt hat es fast 500 Commits und 7 Mitwirkende und befindet sich im zusätzlichen Apache-Repository.
Was macht der Bot? Seine Fähigkeiten können in zwei Gruppen kombiniert werden:
- Projektüberwachung - visuelle Überwachung durch Anzeigen der Ergebnisse von Läufen sowie automatische Benachrichtigung in Instant Messenger (z. B. Slack)
- Branch Check - Analyse von PR-Tests sowie Ausstellung eines Visums in einem Ticket.
TeamCity Bot Workflow
Vor Apache Ignite Teamcity Bot war der Prozess des "Beitrags" zur Community wie folgt:
- In JIRA wird eines der Tickets ausgewählt und festgelegt.
- Eine Pull-Anfrage wird erstellt.
- Führt Tests aus, die von den vorgenommenen Änderungen betroffen sein können.
- Wenn die Tests bestanden sind, kann die Pull-Anforderung vom Committer in der Vorschau angezeigt und temperiert werden.
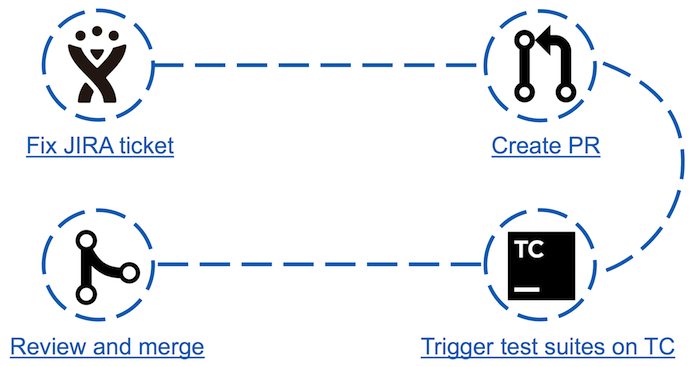
Es sieht einfach aus, aber tatsächlich kann der dritte Punkt für einige Mitwirkende ein Hindernis sein. Zum Beispiel: Ein Neuling in der Community beschließt, seinen ersten Beitrag zu leisten, indem er das einfachste Ticket auswählt. Dies kann das Bearbeiten eines Java-Dokuments oder das Aktualisieren von Maven-Abhängigkeitsversionen sein. Als er die Ergebnisse des Laufs in seinem kleinen Fix analysiert, stellt er plötzlich fest, dass etwa 30 Tests gefallen sind. Woher kommt die Anzahl der fehlgeschlagenen Tests und wie man sie analysiert - er weiß es nicht. Es ist zu erwarten, dass der Mitwirkende nie wieder hierher zurückkehren wird.
Erfahrene Mitglieder der Community leiden ebenfalls unter Schuppenbildung - sie verbringen Zeit damit, zufällige Tests zu analysieren und damit die Produktentwicklung zu behindern.
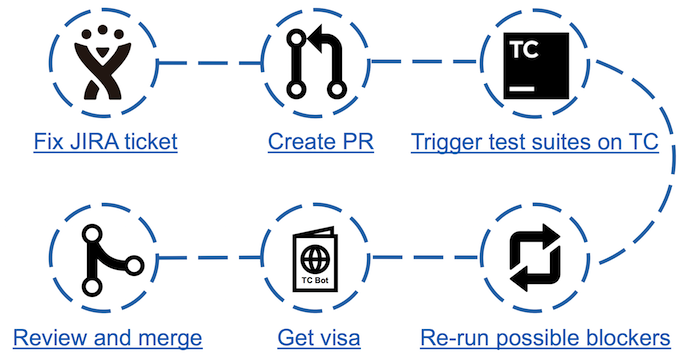 Beitragsschema mit TeamCity Bot
Beitragsschema mit TeamCity BotMit dem Aufkommen des Bots nahmen die Schritte im Gegenspiel zu, aber die Zeit, die für die Analyse der gefallenen Tests aufgewendet wurde, nahm erheblich ab. Jetzt reicht es aus, den Test auszuführen und nach dem Bestehen die entsprechende Bot-Seite aufzurufen. Wenn es mögliche Blocker gibt (abgelegte Tests, die nicht als schuppig gelten), reicht es aus, eine doppelte Überprüfung durchzuführen. Anschließend können Sie in JIRA ein Visum in Form eines Kommentars mit den Testergebnissen erhalten.
Funktionsübersicht
 Beitrag überprüfen - Eine Liste aller nicht geschlossenen PRs mit einer Zusammenfassung aller Informationen: Datum der letzten Aktualisierung, PR-Nummer, Name, Autor und Ticket in JIRA
Beitrag überprüfen - Eine Liste aller nicht geschlossenen PRs mit einer Zusammenfassung aller Informationen: Datum der letzten Aktualisierung, PR-Nummer, Name, Autor und Ticket in JIRA .
 Für jede Pull-Anfrage steht eine Registerkarte mit detaillierteren Informationen zur Verfügung: der richtige PR-Name, ohne den der Bot das gewünschte Ticket in JIRA nicht finden kann; ob Tests durchgeführt wurden; ob das Testergebnis fertig ist; hat einen Kommentar in JIRA hinterlassen.
Für jede Pull-Anfrage steht eine Registerkarte mit detaillierteren Informationen zur Verfügung: der richtige PR-Name, ohne den der Bot das gewünschte Ticket in JIRA nicht finden kann; ob Tests durchgeführt wurden; ob das Testergebnis fertig ist; hat einen Kommentar in JIRA hinterlassen.Analyse der Testergebnisse:


Hier sind zwei Berichte zum Testen derselben PR. Der erste ist vom Bot. Der zweite ist ein Standardbericht über Teamcity. Der Unterschied in der Informationsmenge ist offensichtlich, und dies berücksichtigt nicht die Tatsache, dass zum Anzeigen des Verlaufs der TC-Testläufe auch mehrere Übergänge zu benachbarten Seiten erforderlich sind.
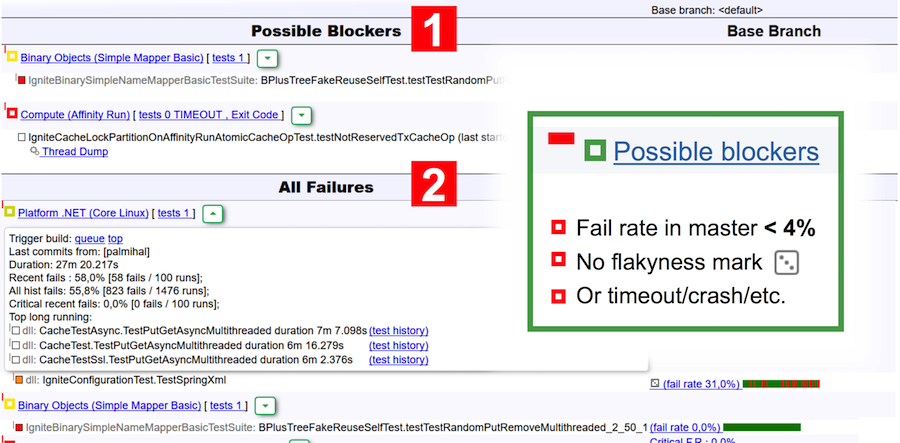
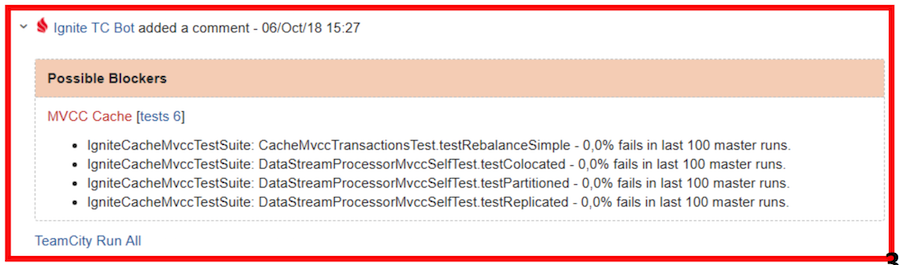
Kommen wir zurück zum Bot-Bericht. Dieser Bericht ist visuell in zwei Tabellen unterteilt: mögliche Blocker und alle Abstürze. Blocker umfassen Tests, die:
- eine Fehlerrate im Master von weniger als 4% haben (weniger als 4 Starts von 100 waren erfolglos);
- sind gemäß der Klassifizierung von TeamCity nicht schuppig;
- fiel aufgrund einer Zeitüberschreitung, zu wenig Speicher, Exit-Code, JVM-Fehler.
Im obigen Screenshot sind beispielsweise zwei Suiten als mögliche Blocker angegeben - in der ersten fiel der Test und in der zweiten fand eine Zeitüberschreitung statt.
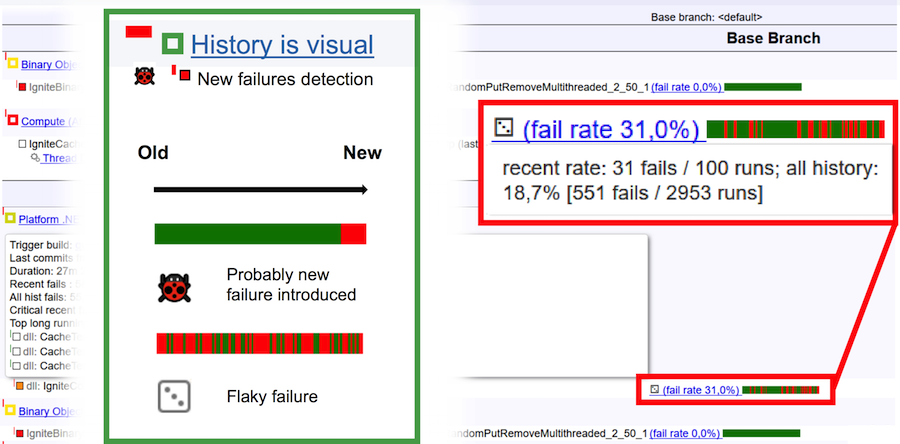
Um endlich zu verstehen, was ein schuppiger Test und was ein Fehler ist, betrachten Sie das obige Bild. Die horizontale Leiste ist 100 Läufe. Vertikaler grüner Balken - Test erfolgreich bestanden, roter Tropfen. Im Falle eines Fehlers sieht der Laufverlauf natürlich aus: Ein einfacher grüner Balken am Ende ändert die Farbe in Rot. Dies bedeutet, dass an dieser Stelle ein Fehler auftrat und der Test ständig abfiel. Wenn wir einen schuppigen Test vor uns haben, dann ist seine Laufhistorie ein kontinuierlicher Wechsel von grünen und roten Farben.
Analyse der Testergebnisse
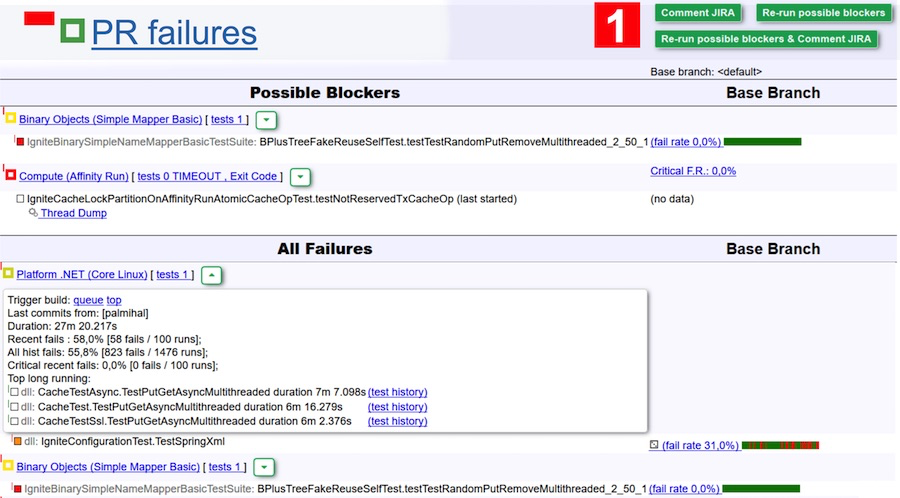
Zum Beispiel analysieren wir die Ergebnisse des Bestehens der Tests im obigen Screenshot. Laut der Bot-Version kann es aufgrund eines Fehlers zu zwei Abstürzen kommen - sie sind in der Tabelle "Mögliche Blocker" aufgeführt. Es kann sich jedoch durchaus um schuppige Tests mit einer geringen Ausfallrate handeln. Um diese Option auszuschließen, klicken Sie einfach auf die Schaltfläche Mögliche Blocker erneut ausführen. Diese beiden Suiten werden dann noch einmal überprüft. Um die Aufgabe noch einfacher zu machen, können Sie auf Mögliche Blocker erneut ausführen und JIRA kommentieren und nach Abschluss der Prüfung einen Kommentar (und damit eine Benachrichtigung per E-Mail) vom Bot erhalten. Dann gehen Sie hinein und sehen Sie, ob es ein Problem gibt oder nicht.
Für Rezensenten ist dies sehr cool. Sie können Änderungen vergessen, die keine Prüfungen bestanden haben. Klicken Sie einfach auf eine Reihe von Änderungen, klicken Sie auf die große grüne Schaltfläche "Ausführen" und warten Sie auf den Buchstaben.
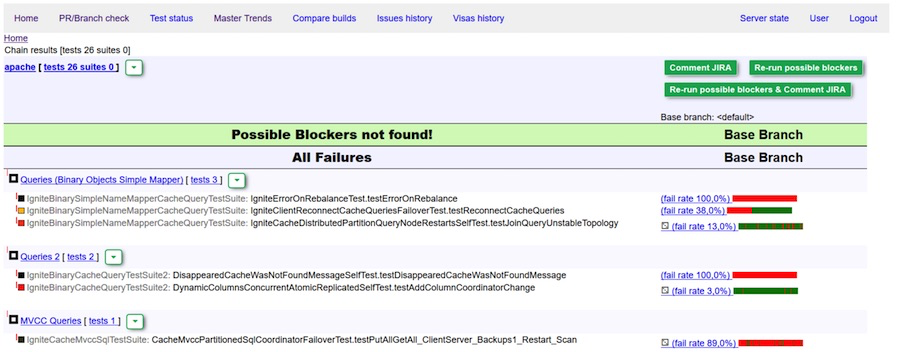 Perfekter Bericht: Keine Blocker erkannt
Perfekter Bericht: Keine Blocker erkannt

Grünes Visum (Kommentar) des Bots. Keine Blocker gefunden.
Rotes Visum - Überprüfung und / oder Bearbeitung von Fehlern erforderlichEs kommt vor, dass immer noch einige Fehler in den „Master“ gelangen. Wie gesagt, bevor dies durch persönliche Benachrichtigungen bekämpft wurde. Oder jemand hat dafür gesorgt, dass nichts fiel. Jetzt verwenden wir eine einfachere Lösung:

Wenn ein neuer Fehler erkannt wird, wird eine Nachricht an die Entwicklerliste gesendet, die die Mitwirkenden und ihre Wechsler angibt, die möglicherweise die Fehlerursache sind. So wird die ganze Community herausfinden, wer alles verursacht hat.
Auf diese Weise konnten wir die Anzahl der Hotfixes erhöhen und die Zeit zur Behebung des Problems erheblich verkürzen.
Status des Überwachungsassistenten
Eine weitere Funktion des Bots ist die Überwachung des Status des Assistenten mit den Statistiken zu den letzten Starts.

Meistertrends

Auf der Seite "Mastertrends" werden zwei "Master" -Auswahlen für bestimmte Zeiträume verglichen. Für jedes Element in der Tabelle werden der Maximal-, Minimalwert und der Median angezeigt.

Zusätzlich zu den allgemeinen Ergebnissen für die gesamte Stichprobe enthält die Tabelle Diagramme für jeden Indikator mit der Anzeige der Werte jedes Builds. Durch Klicken auf einen Punkt können Sie zu den Ergebnissen des Laufs in TeamCity gelangen. Außerdem ist es möglich, das Ergebnis aus der Statistik zu entfernen. Dies ist nützlich, wenn abnormale Werte aufgrund schwerwiegender Ausfälle auftreten, an denen der Mitwirkende wahrscheinlich nicht schuld ist. Solche Ergebnisse sollten ausgeschlossen werden, damit sie bei der Berechnung derselben Flockentests nicht berücksichtigt werden. Darüber hinaus kann der Build auch unterschieden werden, um die Ergebnisse für jeden Indikator zu verfolgen.
Apache Ignite Teamcity Bot hat jetzt über 65 registrierte Mitglieder. Während des gesamten Zeitraums der Nutzung des Bots erhielten Visa mehr als 400 Pull-Anfragen, und durchschnittlich werden fünf Visa pro Tag ausgestellt.
TeamCity Bot Struktur
Der Bot wird auf einem separaten Server gehostet, geht zu ignite.apache.org, um Daten zu erhalten, benachrichtigt öffentlich alle auf der Entwicklerliste - dies ist unsere Hauptplattform für Ignite-Entwickler - und schreibt Visa über die JIRA-API auf Tickets.
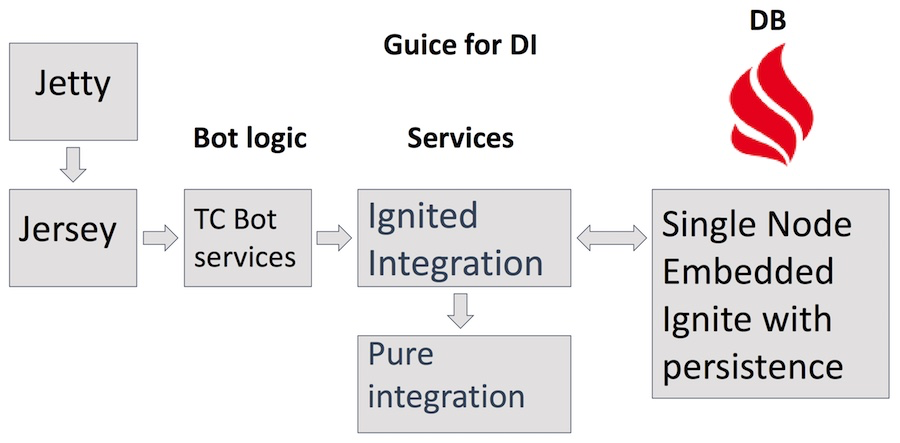
Es verwendet den Jetty-Server, Jersey-Servlets, eine Reihe von Diensten mit komplexer Geschäftslogik des Bots selbst, einschließlich Teamcity-, JIRA- und GitHub-Dienste, die auf den Ignited Integration-Dienst zugreifen. Darüber hinaus Pure Integration für http-Anfragen. Als Speicher - Apache Ignites eigenes Produkt im eingebetteten Einzelknotenkonfigurationsmodus mit aktiver Persistenz. Zusätzlich zu den offensichtlichen Vorteilen der Verwendung von Ignite als Datenbank hilft es uns, verschiedene Anwendungsbereiche von Ignite zu finden und zu verstehen, was praktisch ist und was nicht.
Die erste Version der Bot-Implementierung wurde von einem Artikel zum REST-Caching inspiriert und bestand aus einem REST-Cache sowie GitHub- und Teamcity-Diensten. Teamcity xml und json, die vom Server zurückgegeben wurden, wurden von Pure Java Objects analysiert, die dann zwischengespeichert wurden. Zuerst hat es funktioniert und das ziemlich schnell. Mit zunehmender Datenmenge begannen sich die Ergebnisse jedoch zu verschlechtern.
Es ist erwähnenswert, dass TeamCity eine Geschichte löscht, die älter als ~ 2 Wochen ist, der Bot jedoch nicht. Letztendlich erschienen mit diesem Ansatz Tonnen von Daten, die sehr schwer zu verwalten sind.
TeamCity Bot Entwicklung
Der neue Ansatz implementiert eine kompakte Datenspeicheroption und entscheidet sich für eine kleine Anzahl von Cache-Partitionen. Eine große Anzahl von Partitionen auf einem Knoten wirkt sich negativ auf die Geschwindigkeit der Datensynchronisation mit der Festplatte aus und erhöht die Startzeit des Clusters.
Alle wichtigen Datenaktualisierungen werden asynchron durchgeführt, da wir sonst aufgrund der langsamen Rückgabe von TeamCity-Daten Gefahr laufen, eine schlechte UX zu erhalten.
Für Zeichenfolgen, deren Werte selten geändert werden (z. B. die Namen von Tests), erfolgt eine einfache Zuordnung in id, die von Atomic Sequence generiert wird. Hier ist ein Beispiel für einen solchen Eintrag:

Der lange Testname entspricht der int-Nummer, die in allen Builds gespeichert ist. Dies spart eine enorme Menge an Ressourcen. Zu den Methoden, die diese Zeile zurückgeben, gehört der In-Memory-Cache-Interceptor von Guava. Dank der Cache-Annotation wählen wir selbst im Heap keine Zeilen aus, indem wir sie von Ignite by id lesen. Und mit id bekommen wir immer die gleiche Linie, was gut für die Leistung ist.
Für "unvorhersehbare" Zeilen, z. B. Stapelverfolgungsprotokolle, werden verschiedene Arten der Komprimierung verwendet - gzip-Komprimierung, schnelle Komprimierung oder unkomprimierte, je nachdem, welche besser ist. Alle diese Methoden helfen dabei, maximale Daten in den Arbeitsspeicher zu integrieren und dem Client schnell eine Antwort zu geben.
Warum TeamCity Bot besser ist
Dies bedeutet nicht, dass TeamCity nicht über die oben aufgeführten Funktionen verfügt. Sie sind, aber auf einem Haufen von verschiedenen Orten verstreut. Im Bot wird alles auf einer Seite gesammelt und Sie können schnell verstehen, wo das Problem liegt.
Eine nette Ergänzung ist der Brief, den der Bot auf dem Entwicklungsblatt sendet, wenn er ein Problem erkennt. Unmittelbar in der Community gibt es Gelegenheit, eine Diskussion zu beginnen: „Lassen Sie uns vielleicht jetzt umkehren?“. Dies erhöht das Vertrauen der Prüfer.
Mit dem Bot ist es für neue Mitwirkende viel einfacher, sich dem Entwicklungsprozess anzuschließen. Wenn Sie Ihre erste Korrektur vornehmen, wissen Sie nicht immer, was die vorgenommenen Änderungen bedeuten können. Wenn Sie direkt in die Analyse der Testergebnisse in TeamCity eintauchen, können Sie leicht Ihre Begeisterung für die weitere Entwicklung verlieren. Apache Ignite TeamCity Bot hilft Ihnen, schnell zu verstehen, ob es ein Problem gibt, und die Begeisterung aufrechtzuerhalten.
Wir hoffen, dass der Bot das Leben der derzeitigen Mitwirkenden vereinfacht und neue Leute für die Community gewinnt. Schließlich raten wir natürlich, das Auftreten einer großen Anzahl von Flockentests zu verhindern, da es schwierig ist, mit ihnen umzugehen. Und vertraue Robotern - sie haben keine Vorlieben und sie nehmen nicht das Wort der Leute dafür.