
 Anton Chaynikov, Entwickler von Data Science, Redmadrobot
Anton Chaynikov, Entwickler von Data Science, Redmadrobot
Hallo Habr! Heute werde ich über die Schwierigkeiten auf dem Weg zum Chatbot sprechen, die die Arbeit der Chat-Betreiber der Versicherungsgesellschaft erleichtern. Genauer gesagt, wie wir dem Bot beigebracht haben, Anforderungen durch maschinelles Lernen voneinander zu unterscheiden. Mit welchen Modellen wurde experimentiert und mit welchen wurden die Ergebnisse erzielt? Wie haben vier Ansätze zur Bereinigung und Anreicherung von Daten von anständiger Qualität und fünf Versuche zur Bereinigung von Daten von Qualität "unanständig".
Herausforderung
Der Chat der Versicherungsgesellschaft erhält täglich +100500 Kundenanrufe. Die meisten Fragen sind einfach und wiederholen sich, aber die Bediener sind nicht einfacher, und die Kunden müssen noch fünf bis zehn Minuten warten. Wie kann die Servicequalität verbessert und die Arbeitskosten optimiert werden, damit die Bediener weniger Routine haben und die Benutzer ein angenehmeres Gefühl haben, wenn sie ihre Probleme schnell lösen?
Und wir machen einen Chatbot. Lassen Sie ihn Benutzernachrichten lesen, Anweisungen für einfache Fälle geben und Standardfragen für komplexe Fälle stellen, um die Informationen zu erhalten, die der Bediener benötigt. Ein Live-Operator verfügt über einen Skriptbaum - ein Skript (oder Flussdiagramm), das angibt, welche Fragen Benutzer möglicherweise stellen und wie sie darauf antworten sollen. Wir würden dieses Schema in einen Chatbot einfügen, aber es ist schlecht - der Chatbot versteht es nicht menschlich und weiß nicht, wie er die Frage des Benutzers mit dem Skriptzweig in Beziehung setzen soll.
Also werden wir ihn mit Hilfe des guten alten maschinellen Lernens unterrichten. Sie können jedoch nicht nur ein von Benutzern generiertes Datenelement verwenden, um ihm ein anständiges Qualitätsmodell beizubringen. Dazu müssen Sie mit der Architektur des Modells und den Daten experimentieren, um sie zu bereinigen und manchmal erneut zu sammeln.
Wie man einen Bot unterrichtet:
- Berücksichtigen Sie die Modelloptionen: Wie werden die Größe des Datensatzes, die Details der Vektorisierung der Texte, die Verringerung der Dimension, der Klassifikator und die endgültige Genauigkeit kombiniert?
- Lassen Sie uns anständige Daten bereinigen: Wir werden Klassen finden, die sicher weggeworfen werden können; Wir werden herausfinden, warum die letzten sechs Monate des Aufschlags besser sind als die vorherigen drei. bestimmen, wo das Modell liegt und wo das Markup; Finden Sie heraus, wie Tippfehler nützlich sein können.
- Wir werden die "unanständigen" Daten bereinigen: Wir werden herausfinden, in welchen Fällen Clustering nützlich und nutzlos ist, da Benutzer und Bediener sprechen, wenn es Zeit ist, das Leiden zu beenden und Markups zu sammeln.
Textur
Wir hatten zwei Kunden - Versicherungsunternehmen mit Online-Chats - und Chatbot-Schulungsprojekte (wir werden sie nicht nennen, das ist nicht wichtig) mit stark unterschiedlicher Datenqualität. Nun, wenn die Hälfte der Probleme des zweiten Projekts durch Manipulationen des ersten gelöst werden könnte. Details sind unten.
Aus technischer Sicht besteht unsere Aufgabe darin, Texte zu klassifizieren. Dies erfolgt in zwei Schritten: Zuerst werden die Texte vektorisiert (unter Verwendung von tf-idf, doc2vec usw.), dann wird das Klassifizierungsmodell anhand der erhaltenen Vektoren (und Klassen) trainiert - Zufallswald, SVM, neuronales Netzwerk usw. und so weiter.
Woher kommen die Daten:
- SQL-Upload-Chat-Verlauf. Relevante Upload-Felder: Nachrichtentext; Autor (Kunde oder Betreiber); Gruppieren von Nachrichten in Dialoge; Zeitstempel; Kundenkontaktkategorie (Fragen zur obligatorischen Kfz-Haftpflichtversicherung, zur Rumpfversicherung, zur freiwilligen Krankenversicherung; Fragen zur Website; Fragen zu Treueprogrammen; Fragen zu sich ändernden Versicherungsbedingungen usw.).
- Ein Baum von Skripten oder Sequenzen von Fragen und Antworten von Betreibern an Kunden mit unterschiedlichen Anforderungen.
Ohne Validierung natürlich nirgendwo. Alle Modelle wurden auf 70% der Daten trainiert und gemäß den Ergebnissen auf den restlichen 30% bewertet.
Qualitätsmetriken für die von uns verwendeten Modelle:
- Im Training: Logloss für Differenzierbarkeit;
- Beim Schreiben von Berichten: Klassifizierungsgenauigkeit an einem Testmuster zur Vereinfachung und Klarheit (auch für den Kunden);
- Bei der Wahl der Richtung für weitere Aktionen: die Intuition eines Datenwissenschaftlers, der die Ergebnisse aufmerksam betrachtet.
Modellexperimente
Es ist selten, wenn die Aufgabe sofort klar macht, welches Modell die besten Ergebnisse liefert. Also hier: ohne Experimente nirgendwo.
Wir werden Vektorisierungsoptionen ausprobieren:
- tf-idf in einzelnen Worten;
- tf-idf auf Dreifachzeichen (im Folgenden: 3 Gramm);
- tf-idf auf 2-, 3-, 4-, 5-Gramm getrennt;
- tf-idf auf 2-, 3-, 4-, 5-Gramm zusammengenommen;
- Alle oben genannten + Reduzierung der Wörter im Quelltext auf ein Wörterbuchformular;
- Alle oben genannten + Verringerung der Dimension durch die abgeschnittene SVD-Methode;
- Mit der Anzahl der Messungen: 10, 30, 100, 300;
- doc2vec, geschult auf den Textkörper der Aufgabe.
Die Klassifizierungsoptionen vor diesem Hintergrund sehen eher schlecht aus: SVM, XGBoost, LSTM, zufällige Wälder, naive Bayes, zufällige Wälder zusätzlich zu SVM- und XGB-Vorhersagen.
Und obwohl wir die Reproduzierbarkeit der Ergebnisse an drei unabhängig zusammengestellten Datensätzen und deren Fragmenten überprüft haben, können wir nur für die breite Anwendbarkeit bürgen.
Die Ergebnisse der Experimente:
- In der Kette "Vorverarbeitung-Vektorisierung-Senkung der Dimensionsklassifizierung" ist der Effekt der Auswahl bei jedem Schritt nahezu unabhängig von den anderen Schritten. Was sehr praktisch ist, Sie können nicht mit jeder neuen Idee ein Dutzend Optionen durchgehen und bei jedem Schritt die bekannteste Option verwenden.
- tf-idf in Worten verliert auf 3 Gramm (Genauigkeit 0,72 vs 0,78). 2-, 4-, 5-Gramm verlieren gegen 3-Gramm (0,75–0,76 gegenüber 0,78). {2; 5} -Gramme übertreffen insgesamt 3-Gramm deutlich. Angesichts des starken Anstiegs des erforderlichen Speichers haben wir beschlossen, das Training mit einer Genauigkeit von 0,4% zu vernachlässigen.
- Im Vergleich zu tf-idf aller Sorten war doc2vec hilflos (Genauigkeit 0,4 und darunter). Es würde sich lohnen, ihn nicht im Korps von der Aufgabe aus zu trainieren (~ 250.000 Texte), sondern in einem viel größeren (2,5–25 Millionen Texte), aber bisher haben Ihre Hände leider nicht erreicht.
- Abgeschnittene SVD hat nicht geholfen. Die Genauigkeit nimmt mit zunehmender Messung monoton zu und erreicht ohne TSVD problemlos eine Genauigkeit.
- Unter den Klassifikatoren gewinnt XGBoost spürbar (+ 5–10%). Die engsten Konkurrenten sind SVM und zufällige Wälder. Naive Bayes ist nicht einmal ein Konkurrent zu zufälligen Wäldern.
- Der Erfolg von LSTM hängt stark von der Größe des Datensatzes ab: Bei einer Stichprobe von 100.000 Objekten kann es mit XGB konkurrieren. Auf einer Stichprobe von 6000 - in der Verzögerung zusammen mit Bayes.
- Eine zufällige Gesamtstruktur über SVM und XGB stimmt entweder immer mit XGB überein oder irrt sich mehr. Das ist sehr traurig, wir hofften, dass SVM in den Daten zumindest einige Muster findet, die XGB nicht zur Verfügung stehen, aber leider.
- XGBoost ist mit Stabilität kompliziert. Zum Beispiel reduzierte das Upgrade von Version 0.72 auf 0.80 unerklärlicherweise die Genauigkeit trainierter Modelle um 5–10%. Und noch etwas: XGBoost unterstützt das Ändern von Trainingsparametern während des Trainings und die Kompatibilität mit der Standard-Scikit-Learn-API, jedoch streng separat. Sie können nicht beides zusammen machen. Musste es reparieren.
- Wenn Sie Wörter in ein Wörterbuchformular einfügen, verbessert dies die Qualität ein wenig in Kombination mit tf-idf in Wörtern, ist jedoch in allen anderen Fällen nutzlos. Am Ende haben wir es ausgeschaltet, um Zeit zu sparen.
Erfahrung 1. Datenbereinigung oder was mit Markup zu tun ist
Chat-Betreiber sind nur Menschen. Bei der Definition der Kategorien von Benutzerabfragen sind diese häufig falsch und interpretieren die Grenzen zwischen den Kategorien unterschiedlich. Daher müssen die Quelldaten rücksichtslos und intensiv bereinigt werden.
Unsere Daten zum Modelltraining zum ersten Projekt:
- Eine Geschichte von Online-Chat-Nachrichten über mehrere Jahre. Dies sind 250.000 Beiträge in 60.000 Gesprächen. Am Ende des Dialogs wählte der Bediener die Kategorie aus, zu der der Anruf des Benutzers gehört. Es gibt ungefähr 50 Kategorien in diesem Datensatz.
- Skriptbaum. In unserem Fall hatten die Operatoren keine Arbeitsskripte.
Was genau die Daten schlecht sind, haben wir als Hypothesen formuliert, dann überprüft und wenn möglich korrigiert. Folgendes ist passiert:
Der erste Ansatz. Von der gesamten riesigen Liste der Klassen können Sie sicher 5-10 verlassen.
Wir verwerfen kleine Klassen (<1% der Stichprobe): wenig Daten + geringe Auswirkung. Wir vereinen schwer zu unterscheidende Klassen, auf die Operatoren immer noch genauso reagieren. Zum Beispiel:
'dms' + 'wie man einen Termin mit einem Arzt vereinbart' + 'Frage zum Ausfüllen des Programms'
'Stornierung' + 'Stornierungsstatus' + 'Stornierung der bezahlten Police'
"Erneuerungsfrage" + "Wie kann die Richtlinie erneuert werden?"
Als nächstes werfen wir Klassen wie "andere", "andere" und dergleichen aus: Für einen Chatbot sind sie nutzlos (ohnehin an den Operator weitergeleitet) und beeinträchtigen gleichzeitig die Genauigkeit erheblich, da 20% der Anforderungen (30, 50, 90) von Operatoren klassifiziert werden und hier. Jetzt werfen wir die Klasse aus, mit der der Chatbot (noch) nicht arbeiten kann.
Ergebnis: in einem Fall Wachstum von einer Genauigkeit von 0,40 auf 0,69, in einem anderen Fall von 0,66 auf 0,77.
Der zweite Ansatz. Zu Beginn des Chats verstehen die Bediener selbst nur schlecht, wie eine Klasse für den Benutzer ausgewählt werden soll, sodass die Daten viel „Rauschen“ und Fehler enthalten.
Experiment: Wir nehmen nur die letzten zwei (drei, sechs, ...) Monate der Dialoge und trainieren das Modell weiter
sie.
Ergebnis: In einem bemerkenswerten Fall stieg die Genauigkeit von 0,40 auf 0,60, in einem anderen von 0,69 auf 0,78.
Der dritte Ansatz. Manchmal bedeutet eine Genauigkeit von 0,70 nicht, dass das Modell in 30% der Fälle falsch ist, sondern dass in 30% der Fälle das Markup lügt und das Modell es sehr vernünftig korrigiert.
Durch Metriken wie Genauigkeit oder Protokollverlust kann diese Hypothese nicht überprüft werden. Für die Zwecke des Experiments haben wir uns auf den Blick eines Datenwissenschaftlers beschränkt. Im Idealfall müssen Sie den Datensatz jedoch qualitativ neu anordnen, ohne die Kreuzvalidierung zu vergessen.
Um mit solchen Proben zu arbeiten, haben wir den Prozess der "iterativen Anreicherung" entwickelt:
- Teilen Sie den Datensatz in 3-4 Fragmente auf.
- Trainiere das Modell auf dem ersten Fragment.
- Sagen Sie die Klassen der Sekunde anhand des trainierten Modells voraus.
- Schauen Sie sich die vorhergesagten Klassen und den Vertrauensgrad des Modells genau an und wählen Sie den Grenzwert des Vertrauens.
- Entfernen Sie Texte (Objekte), die mit Sicherheit unterhalb der Grenze vorhergesagt wurden, aus dem zweiten Fragment und trainieren Sie das Modell darauf.
- Wiederholen, bis die Fragmente müde werden oder ausgehen.
Einerseits sind die Ergebnisse ausgezeichnet: Das erste Iterationsmodell hat eine Genauigkeit von 70%, das zweite - 95%, das dritte - 99 +%. Ein genauer Blick auf die Ergebnisse von Vorhersagen bestätigt diese Genauigkeit vollständig.
Wie kann man andererseits systematisch überprüfen, ob nachfolgende Modelle die Fehler früherer Modelle nicht lernen? Es besteht die Idee, den Prozess an einem manuell „verrauschten“ Datensatz mit qualitativ hochwertigem Anfangsmarkup wie MNIST zu testen. Aber leider gab es nicht genug Zeit dafür. Und ohne Überprüfung haben wir es nicht gewagt, eine iterative Anreicherung und die daraus resultierenden Modelle in der Produktion einzuführen.
Der vierte Ansatz. Der Datensatz kann erweitert werden - und dadurch die Genauigkeit erhöhen und die Umschulung reduzieren, wodurch vorhandene Texte um viele Tippfehler erweitert werden.
Tippfehler sind Tippfehler - Verdoppeln eines Buchstabens, Überspringen eines Buchstabens, Anordnen benachbarter Buchstaben an bestimmten Stellen, Ersetzen eines Buchstabens durch einen benachbarten Buchstaben auf der Tastatur.
Experiment: Der Anteil der p Buchstaben, in denen ein Tippfehler auftritt: 2%, 4%, 6%, 8%, 10%, 12%. Datensatzerhöhung: In der Regel bis zu 60.000 Replikate. Abhängig von der Anfangsgröße (nach Filtern) bedeutete dies eine 3- bis 30-fache Erhöhung.
Ergebnis: hängt vom Datensatz ab. Bei einem kleinen Datensatz (~ 300 Replikate) ergeben 4–6% der Tippfehler eine stabile und signifikante Erhöhung der Genauigkeit (0,40 → 0,60). Bei großen Datenmengen ist alles schlechter. Bei einem Anteil von Tippfehlern von 8% oder mehr werden die Texte zu Unsinn und die Genauigkeit nimmt ab. Bei einer Fehlerrate von 2 bis 8% schwankt die Genauigkeit im Bereich von wenigen Prozent, überschreitet die Genauigkeit ohne Tippfehler sehr selten, und es scheint, dass die Trainingszeit nicht mehrmals verlängert werden muss.
Als Ergebnis erhalten wir ein Modell, das 5 Anrufklassen mit einer Genauigkeit von 0,86 unterscheidet. Wir koordinieren mit dem Kunden die Texte der Fragen und Antworten für jede der fünf Gabeln, befestigen die Texte am Chatbot und senden sie an die Qualitätssicherung.
Erfahrung 2. Knietief in den Daten oder was ohne Markup zu tun ist
Nachdem wir beim ersten Projekt gute Ergebnisse erzielt hatten, näherten wir uns dem zweiten mit Zuversicht. Aber zum Glück haben wir nicht vergessen, wie man überrascht wird.
Was wir getroffen haben:
- Ein Skriptbaum mit fünf Zweigen, der vor etwa einem Jahr mit dem Kunden vereinbart wurde.
- Eine getaggte Stichprobe von 500 Nachrichten und 11 Klassen unbekannter Herkunft.
- Getaggt von Chat-Betreibern aus 220.000 Nachrichten, 21.000 Konversationen und 50 anderen Klassen.
- Das an der ersten Stichprobe trainierte SVM-Modell mit einer Genauigkeit von 0,69, das vom vorherigen Team von Datenwissenschaftlern geerbt wurde. Warum SVM, die Geschichte schweigt.
Zunächst betrachten wir die Klassen: im Skriptbaum, im Beispiel des SVM-Modells, im Hauptbeispiel. Und hier ist was wir sehen:
- Klassen des SVM-Modells entsprechen in etwa den Zweigen von Skripten, aber in keiner Weise Klassen aus einer großen Stichprobe.
- Der Skriptbaum wurde vor einem Jahr über Geschäftsprozesse geschrieben und ist fast veraltet. Das SVM-Modell ist damit veraltet.
- Die beiden größten Klassen in der großen Stichprobe sind Umsatz (50%) und Sonstige (45%).
- Von den fünf nächstgrößeren Klassen sind drei so allgemein wie der Vertrieb.
- Die verbleibenden 45 Klassen enthalten jeweils weniger als 30 Dialoge. Das heißt, Wir haben keinen Skriptbaum, es gibt keine Klassenliste und kein Markup.
Was ist in solchen Fällen zu tun? Wir krempelten die Ärmel hoch und gingen alleine, um Klassen und Markups aus den Daten zu erhalten.
Der erste Versuch. Versuchen wir, Benutzerfragen zu gruppieren, d. H. Die ersten Nachrichten im Dialog, außer Grüße.
Wir prüfen. Wir vektorisieren Repliken, indem wir 3 Gramm zählen. Wir reduzieren die Dimension auf die ersten zehn TSVD-Messungen. Wir clustern durch agglomeratives Clustering mit dem euklidischen Abstand und der Ziel-Ward-Funktion. Verringern Sie die Abmessung erneut mit t-SNE (bis zu zwei Messungen, damit Sie die Ergebnisse mit Ihren Augen betrachten können). Wir zeichnen Replikationspunkte auf der Ebene und malen in den Farben der Cluster.
Ergebnis: Angst und Entsetzen. Bei gesunden Clustern können wir davon ausgehen, dass es keine gibt:
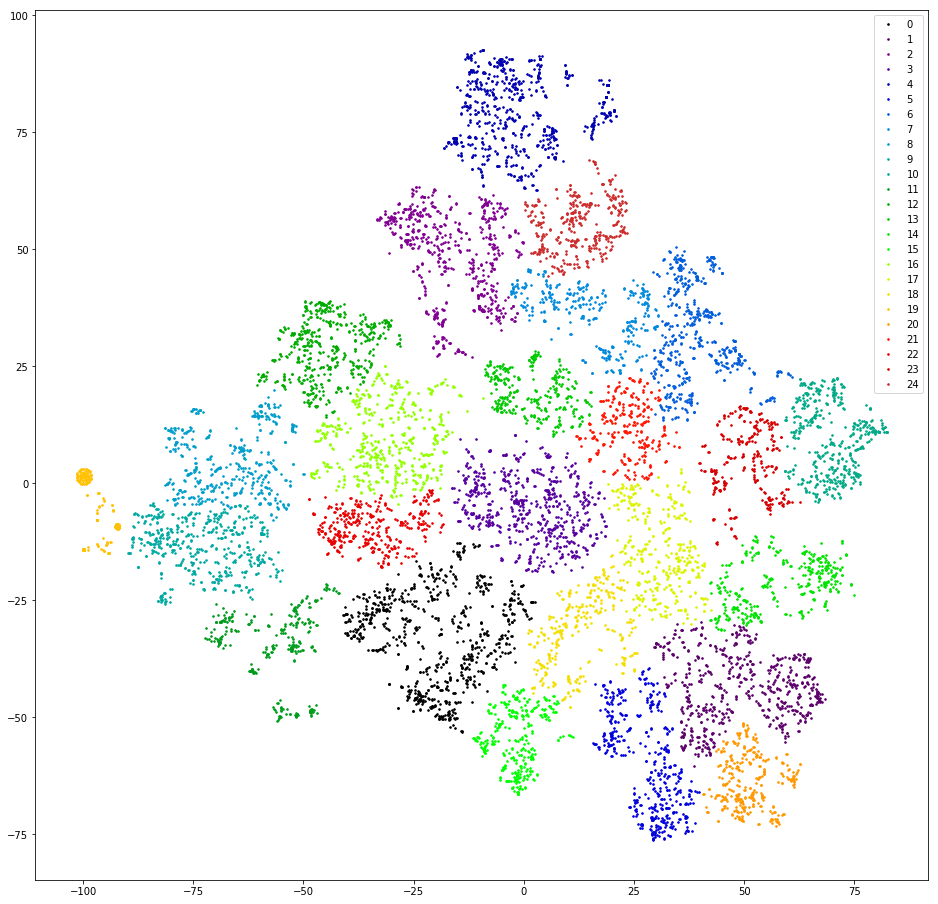
Fast nicht - es gibt eine, links orange, weil alle darin enthaltenen Nachrichten das 3-Gramm-Zeichen „@“ enthalten. Diese 3 Gramm sind ein Vorverarbeitungsartefakt. Irgendwo beim Filtern von Satzzeichen wurde „@“ nicht nur nicht herausgefiltert, sondern auch mit Leerzeichen überwachsen. Aber das Artefakt ist nützlich. Dieser Cluster umfasst Benutzer, die zuerst ihre E-Mail schreiben. Leider ist nur durch die Verfügbarkeit von E-Mails völlig unklar, was die Anfrage des Benutzers ist. Wir gehen weiter.
Der zweite Versuch. Was ist, wenn Betreiber häufig mit mehr oder weniger Standardlinks antworten?
Wir prüfen. Wir extrahieren linkartige Teilzeichenfolgen aus Operator-Nachrichten, bearbeiten die Links leicht, unterscheiden sich in der Schreibweise, haben aber die gleiche Bedeutung (http / https, / search? City =% city%) und berücksichtigen Linkhäufigkeiten.
Ergebnis: vielversprechend. Erstens antworten Betreiber nur auf einen kleinen Teil der Anfragen (<10%) mit Links. Zweitens gibt es selbst nach einmaliger manueller Reinigung und Filterung von Links mehr als dreißig. Drittens gibt es im Verhalten von Benutzern, die den Dialog mit einem Link beenden, keine besondere Ähnlichkeit.
Der dritte Versuch. Lassen Sie uns nach den Standardantworten der Operatoren suchen - was ist, wenn sie Indikatoren für eine Klassifizierung von Nachrichten sind?
Wir prüfen. In jedem Dialog nehmen wir die letzte Replik des Operators (abgesehen von den Abschiedsfeiern: „Ich kann etwas anderem helfen“ usw.) und berücksichtigen die Häufigkeit der eindeutigen Replikate.
Ergebnis: vielversprechend, aber unpraktisch. 50% der Antworten des Bedieners sind eindeutig, weitere 10–20% werden zweimal gefunden, die restlichen 30–40% werden von einer relativ kleinen Anzahl beliebter Vorlagen abgedeckt. Relativ klein - ungefähr dreihundert. Ein genauer Blick auf diese Vorlagen zeigt, dass viele von ihnen in Bezug auf die Bedeutung Varianten derselben Antwort sind - sie unterscheiden sich durch einen Buchstaben, wo durch ein Wort, wo durch einen Absatz. Ich möchte diese bedeutungsnahen Antworten gruppieren.
Der vierte Versuch. Clustering der neuesten Replikate von Anweisungen. Diese sind viel besser gruppiert:
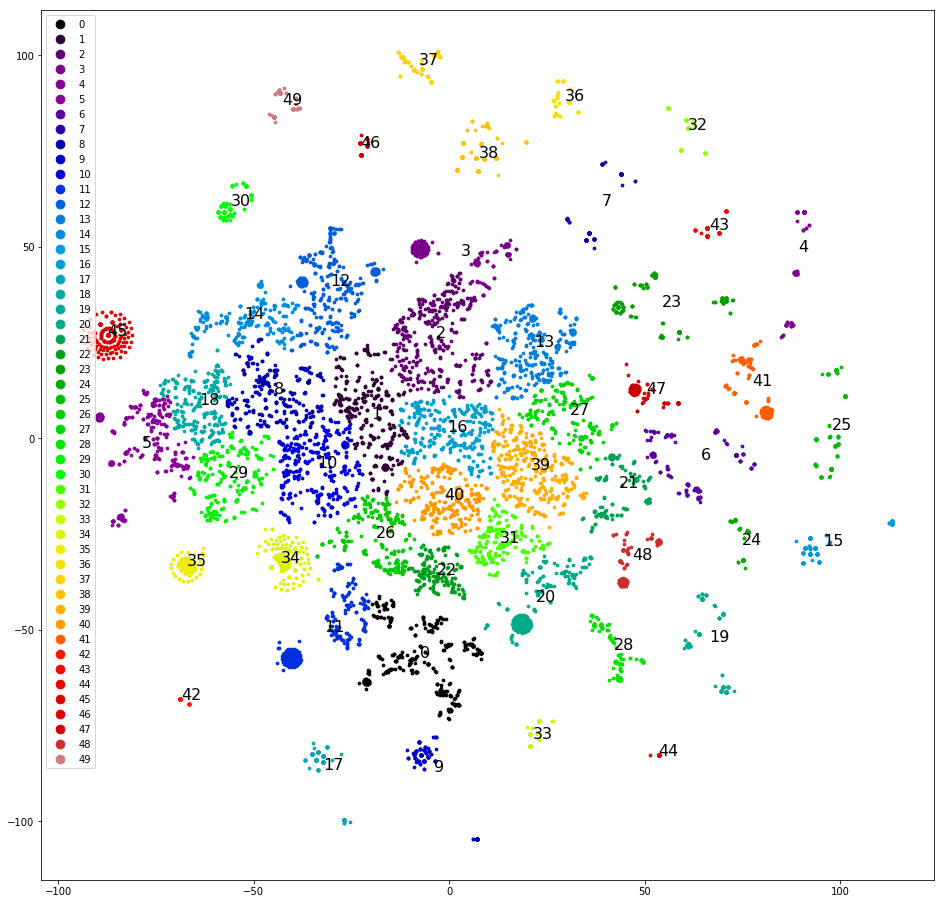
Damit können Sie bereits arbeiten.
Wir gruppieren und zeichnen Replikate in der Ebene, wie im ersten Versuch, bestimmen die am klarsten getrennten Cluster manuell, entfernen sie aus dem Datensatz und gruppieren sie erneut. Nachdem Sie etwa die Hälfte des Datensatzes getrennt haben, enden klare Cluster, und wir beginnen zu überlegen, welche Klassen ihnen zugewiesen werden sollen. Wir streuen Cluster nach den ursprünglichen fünf Klassen - die Stichprobe ist „verzerrt“, und drei der fünf ursprünglichen Klassen erhalten keinen einzigen Cluster. Schade. Wir verteilen Cluster in fünf Klassen, die wir zufällig bestimmen: "Anrufen", "Kommen", "Warten Sie einen Tag auf eine Antwort", "Probleme mit Captcha", "Andere". Der Versatz ist geringer, aber die Genauigkeit beträgt nur 0,4–0,5. Wieder schlecht. Weisen Sie jedem der über 30 Cluster eine eigene Klasse zu. Die Stichprobe ist erneut verzerrt und die Genauigkeit beträgt erneut 0,5, obwohl etwa fünf ausgewählte Klassen eine anständige Genauigkeit und Vollständigkeit aufweisen (0,8 und höher). Das Ergebnis ist aber immer noch nicht beeindruckend.
Der fünfte Versuch. Wir brauchen alle Vor- und Nachteile des Clustering. Wir rufen das vollständige Cluster-Dendrogramm anstelle der oberen dreißig Cluster ab. Wir speichern es in einem Format, das für Kundenanalysten zugänglich ist, und helfen ihnen beim Markup - wir skizzieren die Liste der Klassen.
Für jede Nachricht berechnen wir eine Kette von Clustern, die jede Nachricht enthält, beginnend mit der Wurzel. Wir erstellen eine Tabelle mit Spalten: Text, ID des ersten Clusters in der Kette, ID des zweiten Clusters in der Kette, ..., ID des Clusters, der dem Text entspricht. Wir speichern die Tabelle in csv / xls. .
. ~10000 . , , . — 4000 10000 , -. 6000 :
- Baseline: — 0.66.
- , . 0.73.
- «» — 0.79.
, . , , . , . , . .
, :
- (, , .) .
- XGBoost - , - , .
- — , .
- — , .
- . .
To be concluded.