Die meisten auf dem Markt erhältlichen Speichersysteme unterscheiden sich kaum voneinander, da viele Anbieter Geräte von fast denselben ODM-Herstellern bestellen. Wir haben fast alles für uns, vom Gehäuse bis zu den Controllern, Technologien wie RAID 2.0+ und Software.

Unter dem Schnitt gibt es einige Details darüber, was in jedem der Knoten des Datenspeichersystems ungewöhnlich sein kann.
Was ist auf Modulebene interessant?
Strukturell sehen alle modernen Speichersysteme aller Hersteller gleich aus: Die Steuerungen sind vorne im Stahlkastengehäuse und die Schnittstellenmodule hinten installiert. Es gibt auch Netzteile und Belüftung. Es scheint, dass alles vertraut und Standard ist. Tatsächlich haben wir viele interessante Dinge in dieses Paradigma eingeführt.
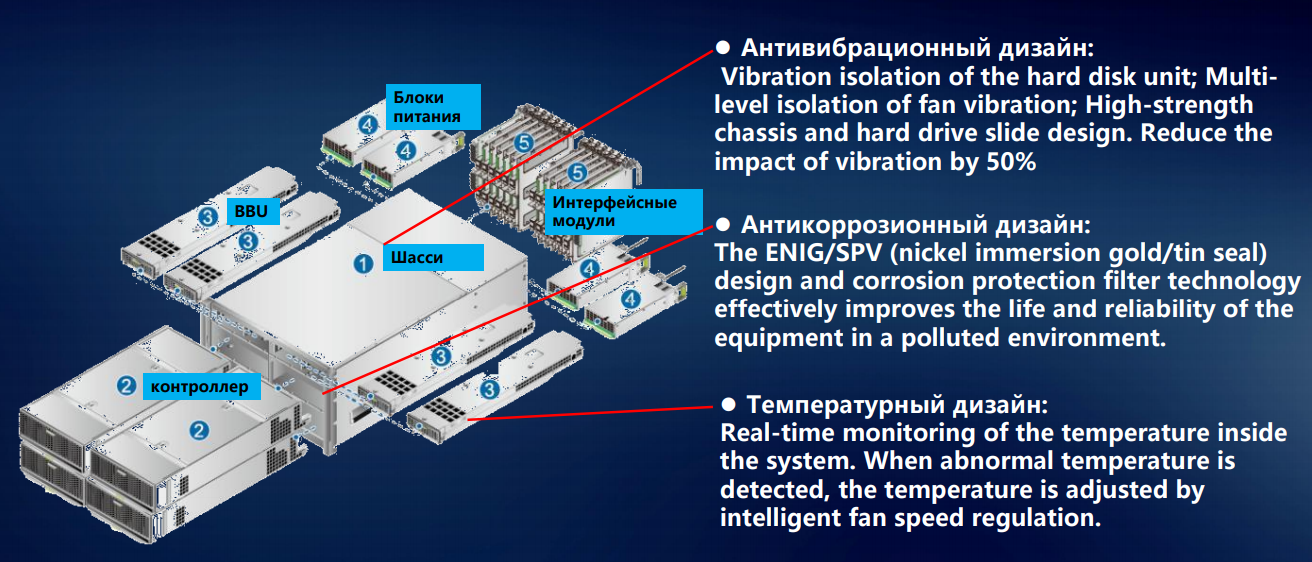
Beginnen wir mit der Montage der Speichersystemelemente im Gehäuse. Das Speichersystem enthält weniger magnetische 3,5-Zoll-Laufwerke, Hybridsysteme und All-Flash-Laufwerke beginnen zu dominieren. Aber auch mehrere Festplatten mit einer Spindeldrehzahl von bis zu 15.000 Umdrehungen pro Minute erzeugen eine Vibration, die nicht ignoriert werden kann. Wir haben eine ganze Reihe von Empfehlungen für diesen Fall entwickelt - wie Magnetlaufwerke mit verschiedenen Parametern auf Plattenregale verteilt werden.
Selbst bei einem Bruchteil eines Prozent, beeinträchtigt dies jedoch die Zuverlässigkeit. In der Größe eines großen Rechenzentrums werden Prozentsätze pro Laufwerk zu konkreten Indikatoren für Ausfälle und Fehlfunktionen. Um sicherzustellen, dass die Vibration einzelner Scheiben weniger durch die starre Chassisstruktur übertragen wird, statten wir die Scheiben unter den Scheiben mit Gummi- oder Metalldämpfern aus. Um eine andere Vibrationsquelle im Speichersystem zu neutralisieren - Lüftungsmodule - setzen wir bidirektionale Lüfter ein und isolieren alle rotierenden Elemente vom Chassis.
Bei Spindelantrieben ist ein minimales Schütteln bereits ein Problem: Die Köpfe verirren sich, die Leistung sinkt erheblich. SSDs sind eine andere Sache, sie haben keine Angst vor Vibrationen. Die sichere Befestigung von Komponenten ist jedoch weiterhin wichtig. Nehmen Sie den Lieferprozess: Die Box kann fallen gelassen oder beiläufig geworfen, seitlich oder verkehrt herum abgelegt werden. Daher haben wir alle Komponenten des Speichersystems streng dreidimensional fixiert. Dies verhindert die Möglichkeit einer Verschiebung während des Transports und schützt die Steckverbinder vor einem Herausspringen aus den Steckdosen bei versehentlichem Aufprall.

Es war einmal eine Zeit, in der wir mit der Entwicklung der Computertechnologie für die Telekommunikationsindustrie begonnen haben, in der die Standards für die Funktionsfähigkeit bei Temperatur und Luftfeuchtigkeit traditionell hoch sind. Und wir haben sie in andere Richtungen verschoben: Metallteile von Speichersystemen oxidieren auch bei hoher Luftfeuchtigkeit nicht - aufgrund der Verwendung von Vernickeln und Verzinken.
Das thermische Design unserer Speichersysteme wurde mit dem Schwerpunkt auf der gleichmäßigen Temperaturverteilung über das Gehäuse entwickelt, um eine Überhitzung oder zu starke Abkühlung einer Ecke des Plattenregals zu vermeiden. Andernfalls kann eine physikalische Verformung nicht vermieden werden - auch wenn sie unbedeutend ist, aber dennoch die Geometrie verletzt und die Lebensdauer der Geräte verkürzen kann. Somit werden einige Bruchteile von einem Prozent gewonnen, dies wirkt sich jedoch immer noch auf die allgemeine Zuverlässigkeit des Systems aus.
Halbleiter-Feinheiten
Wir duplizieren wichtige Komponenten von Speichersystemen: Wenn etwas ausfällt, gibt es immer ein Sicherheitsnetz. Zum Beispiel arbeiten Leistungsmodule für jüngere Modelle nach dem 1 + 1-Schema, für solidere - 2 + 1 und sogar 3 + 1.

Controller, von denen mindestens zwei im Speichersystem vorhanden sind (wir liefern keine Single-Controller-Systeme), sind ebenfalls reserviert. Im Speichersystem der 6800. und älteren Serie wird die Redundanz gemäß dem 3 + 1-Schema durchgeführt, bei den jüngeren Modellen - 1 + 1.
Sogar eine Verwaltungsplatine ist reserviert, was sich nicht direkt auf den Betrieb des Systems auswirkt, sondern nur für Konfigurationsänderungen und Überwachung benötigt wird. Darüber hinaus werden alle Schnittstellenerweiterungskarten für Speichersysteme nur paarweise verkauft, sodass der Client über eine Reserve verfügt.
Alle Komponenten - Netzteile, Lüfter, Controller, Verwaltungsmodule usw. - ausgestattet mit Mikrocontrollern, die auf bestimmte Situationen reagieren können. Wenn der Lüfter beispielsweise von selbst langsamer wird, wird ein Alarm an das Steuermodul gesendet. Dadurch hat der Kunde ein vollständiges Bild des Zustands des Speichersystems - und kann bei Bedarf einige Komponenten selbst austauschen, ohne auf die Ankunft unseres Servicetechnikers warten zu müssen. Wenn die Sicherheitsrichtlinie des Kunden dies zulässt, konfigurieren wir die Steuerungen so, dass sie Informationen über den Zustand des Bügeleisens an unseren technischen Support senden.
Die Chips sind besser und verständlicher.
Wir sind das einzige Unternehmen, das eigene Prozessoren, Chips und Solid-State-Drive-Controller für seine Speichersysteme entwickelt.

Daher verwenden wir in einigen Modellen als Hauptprozessor des Speichersystems (Storage Controller Chip) nicht den klassischen Intel x86, sondern den ARM-Prozessor HiSilicon, unsere Tochtergesellschaft. Tatsache ist, dass sich die ARM-Architektur im Speicher - zur Berechnung des gleichen RAID und der gleichen Deduplizierung - besser zeigt als die Standard-x86-Architektur.
Unser besonderer Stolz sind Chips für SSD-Controller. Und wenn unsere Server mit Halbleiterlaufwerken von Drittanbietern (Intel, Samsung, Toshiba usw.) ausgestattet werden können, installieren wir in den Datenspeichersystemen nur SSDs unseres eigenen Designs.

Der Mikrocontroller des Input-Output-Moduls (Smart I / O-Chip) in Speichersystemen ist ebenfalls eine HiSilicon-Entwicklung sowie der Smart Management Chip für das Remote Storage Management. Die Verwendung unserer eigenen Mikrochips hilft uns, besser zu verstehen, was zu jedem Zeitpunkt mit jeder Speicherzelle passiert. Auf diese Weise konnten wir Verzögerungen beim Zugriff auf Daten in denselben Dorado-Speichersystemen minimieren.

Bei Magnetplatten ist eine kontinuierliche Überwachung im Hinblick auf die Zuverlässigkeit äußerst wichtig. Unsere Speichersysteme unterstützen DHA (Disk Health Analyzer): Die Festplatte selbst zeichnet kontinuierlich auf, was mit ihr passiert und wie gut sie sich anfühlt. Dank der Anhäufung von Statistiken und der Erstellung intelligenter Vorhersagemodelle ist es möglich, den Übergang des Laufwerks in einen kritischen Zustand in 2-3 Monaten und nicht in 5-10 Tagen vorherzusagen. Die Festplatte ist noch "live", die Daten darauf sind absolut sicher - aber der Kunde ist bereit, sie beim ersten Anzeichen eines möglichen Fehlers auszutauschen.
RAID 2.0+
Ausfallsicheres Design in Speichersystemen, das wir auf Systemebene durchdacht haben. Unsere Smart Matrix-Technologie ist ein Add-On zu PCIe - dieser Bus, auf dessen Grundlage Intercontroller-Verbindungen implementiert werden, eignet sich besonders für SSDs.
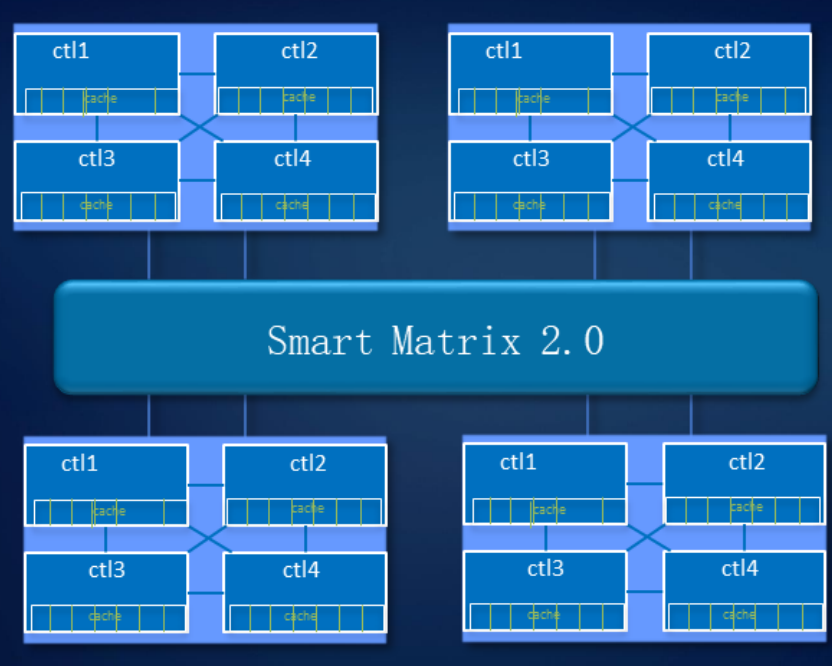
Smart Matrix bietet insbesondere das 4-Controller-Vollnetz in unserem Ocean Store 6800 v5-Speicher. Damit jeder Controller auf alle Festplatten im System zugreifen kann, haben wir ein spezielles SAS-Backend entwickelt. Der Cache wird natürlich zwischen allen derzeit aktiven Controllern gespiegelt.

Wenn der Controller abstürzt, wechseln die Dienste von ihm schnell zum Spiegelcontroller, und die verbleibenden Controller stellen die Beziehung wieder her, um sich gegenseitig zu spiegeln. Gleichzeitig verfügen die im Cache aufgezeichneten Daten über eine Spiegelreserve, um die Systemzuverlässigkeit sicherzustellen.

Das System kann drei Steuerungen standhalten. Wie in der Abbildung gezeigt, wählen die Cache-Daten von Controller B Controller C oder D aus, um den Cache zu spiegeln, wenn Steuerung A ausfällt. Wenn Controller D ausfällt, spiegeln die Controller B und C den Cache.

Das RAID 2.0-Datenverteilungssystem ist der Standard für unsere Speichersysteme: Die Virtualisierung auf Festplattenebene hat das kunstlose blockweise Kopieren von Inhalten von einem Medium auf ein anderes lange ersetzt. Alle Festplatten sind in Blöcken zusammengefasst, sie sind zu größeren Konglomeraten einer zweistufigen Struktur zusammengefasst, und bereits über der oberen Ebene befinden sich die logischen Volumes, aus denen RAID-Arrays bestehen.

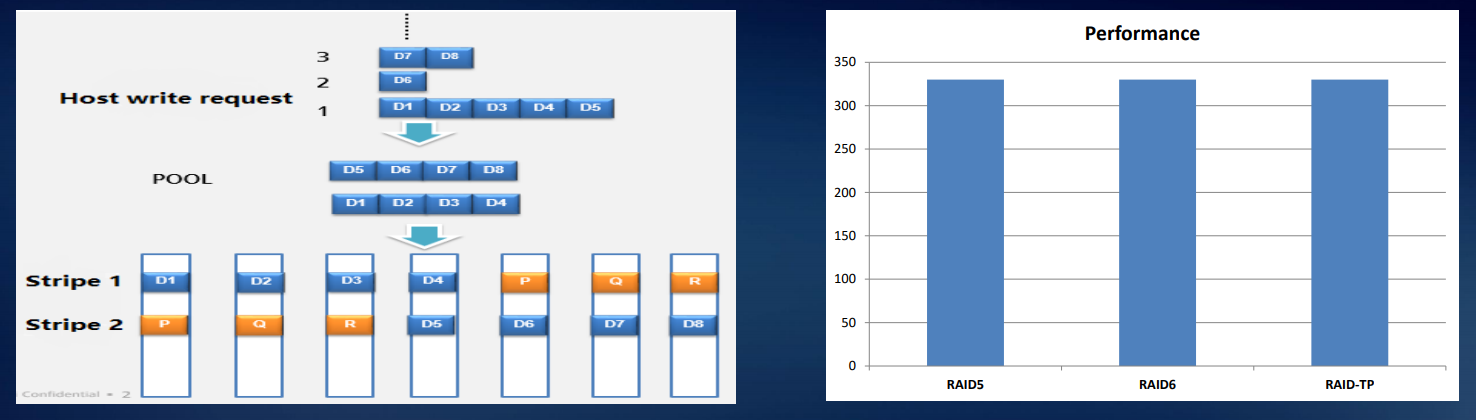
Der Hauptvorteil dieses Ansatzes ist die reduzierte Wiederherstellungszeit des Arrays. Darüber hinaus wird im Falle eines Festplattenfehlers die Neuerstellung nicht auf der Hot-Spare-Festplatte durchgeführt, die die ganze Zeit gestanden hat, sondern auf freiem Speicherplatz auf allen verwendeten Festplatten. Die folgende Abbildung zeigt als Beispiel neun RAID5-Festplatten. Wenn Festplatte 1 abstürzt, sind die Daten CKG0 und CKG1 beschädigt. Das System wählt CK für die zufällige Rekonstruktion aus.

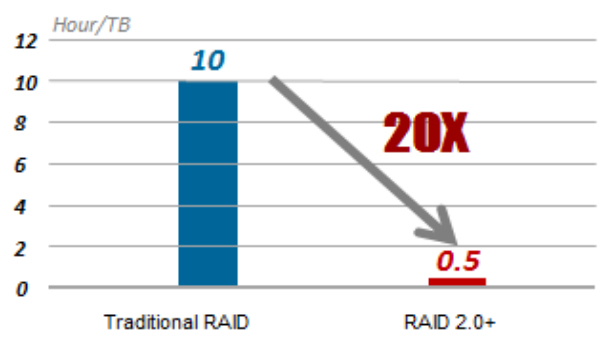
Die normale RAID-Wiederherstellungsgeschwindigkeit beträgt 30 MB / s, sodass die Wiederherstellung von 1 TB Daten 10 Stunden dauert. RAID 2.0+ reduziert diese Zeit auf 30 Minuten.
Unseren Entwicklern gelang es, eine gleichmäßige Lastverteilung zwischen allen Spindelantrieben und SSDs im System zu erreichen. Auf diese Weise können Sie das Potenzial von Hybridspeichersystemen viel besser nutzen als bei der üblichen Verwendung von Solid-State-Laufwerken als Cache.

In Systemen der Dorado-Klasse haben wir das sogenannte RAID-TP implementiert, ein Array mit dreifacher Parität. Ein solches System funktioniert weiterhin, solange drei Laufwerke ausfallen. Dies erhöht die Zuverlässigkeit im Vergleich zu RAID 6 um zwei Dezimalstellen, bei RAID 5 um drei.
Wir empfehlen RAID-TP für besonders kritische Daten, insbesondere da dies aufgrund von RAID 2.0 und Hochgeschwindigkeits-Flash-Laufwerken keinen wesentlichen Einfluss auf die Leistung hat. Sie brauchen nur mehr freien Platz, um zu reservieren.

All-Flash-Systeme werden in der Regel für DBMS mit kleinen Datenblöcken und hohem IOPS verwendet. Letzteres ist für SSDs nicht sehr gut: NAND-Speicherzellen haben schnell keinen Strom mehr. In unserer Implementierung sammelt das System zuerst einen relativ großen Datenblock im Cache des Laufwerks und schreibt ihn dann vollständig in die Zellen. Auf diese Weise können Sie die Belastung der Festplatten verringern sowie in einem sparsameren Modus die "Speicherbereinigung" durchführen und Speicherplatz auf der SSD freigeben.
Sechs Neunen
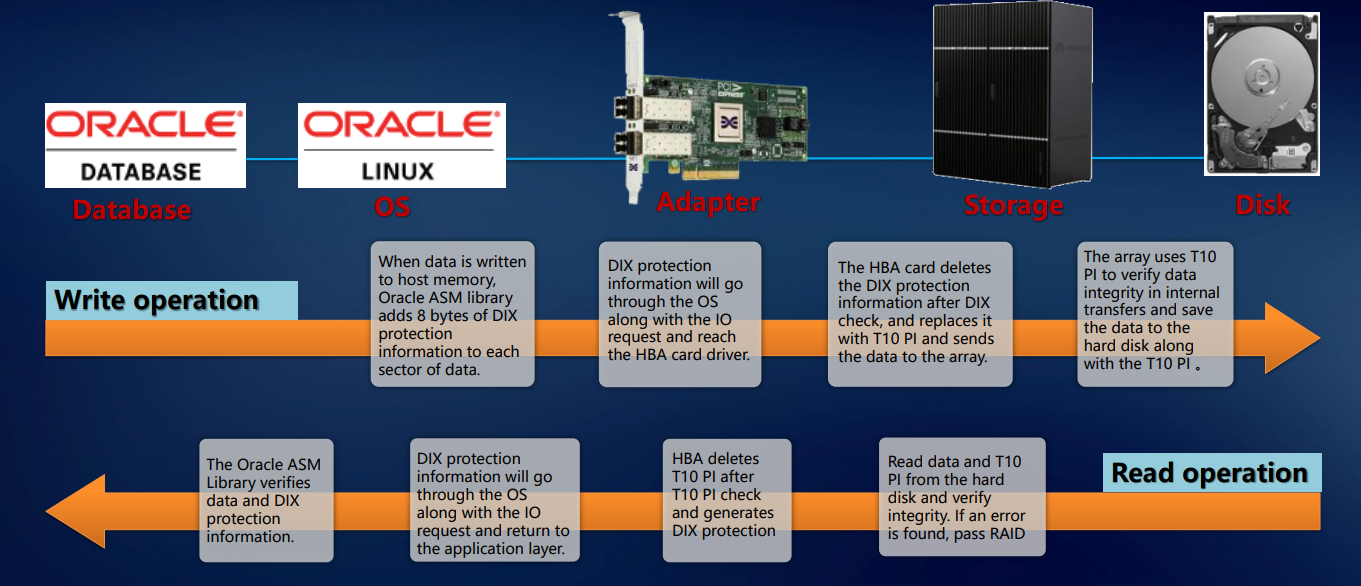
Das Obige ermöglicht es uns, über die Fehlertoleranz unserer Systeme auf der Ebene der gesamten Lösung zu sprechen. Die Validierung wird auf Anwendungsebene (z. B. Oracle DBMS), Betriebssystem, Adapter, Speicher usw. bis zur Festplatte implementiert. Dieser Ansatz stellt sicher, dass genau der Datenblock, der an die externen Ports gelangt ist, ohne Beschädigung oder Verlust auf die internen Festplatten des Systems geschrieben wird. Dies impliziert eine Unternehmensebene.
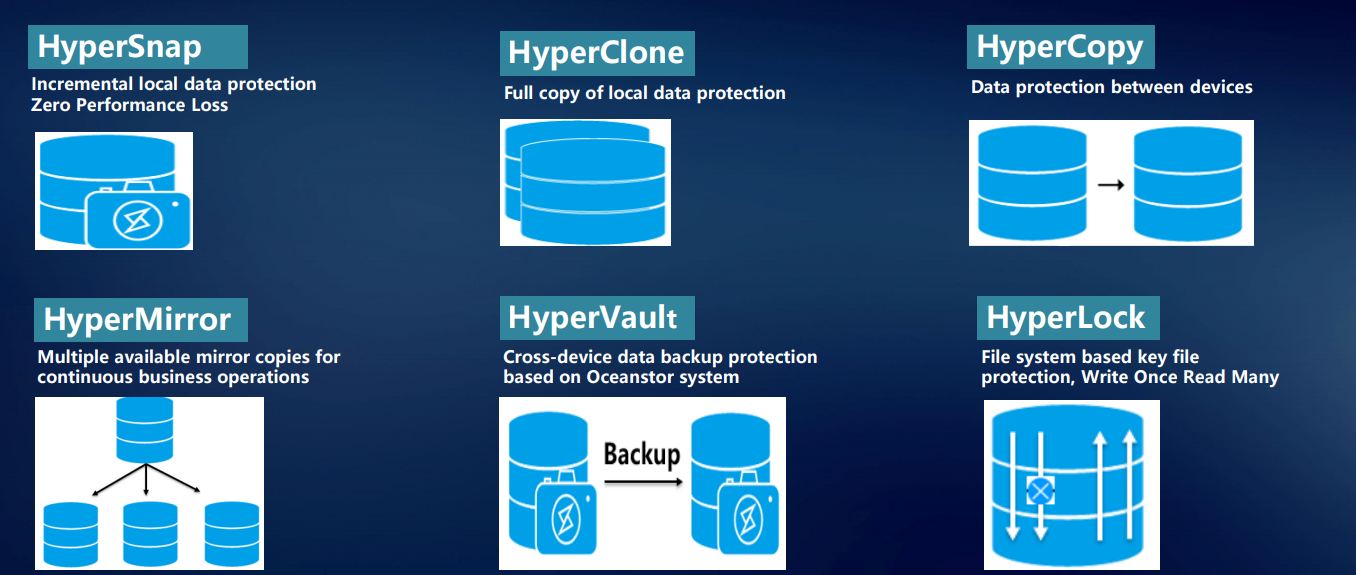
Für zuverlässige Speicherung, Schutz und Wiederherstellung von Daten sowie schnellen Zugriff darauf haben wir eine Reihe proprietärer Technologien entwickelt.

HyperMetro ist wahrscheinlich die interessanteste Entwicklung der letzten anderthalb Jahre. Auf Controller-Ebene wird eine schlüsselfertige Lösung implementiert, die auf unseren Speichersystemen zum Aufbau eines ausfallsicheren U-Bahn-Clusters basiert und keine zusätzlichen Gateways oder Server außer dem Arbiter benötigt. Es wird einfach durch eine Lizenz implementiert: zwei Huawei-Speichersysteme plus eine Lizenz - und es funktioniert.

Die HyperSnap-Technologie bietet kontinuierlichen Datenschutz ohne Leistungseinbußen. Das System unterstützt RoW. Um Datenverluste bei der Speicherung zu einem bestimmten Zeitpunkt zu vermeiden, werden viele Technologien verwendet: verschiedene Snapshots, Klone, Kopien.
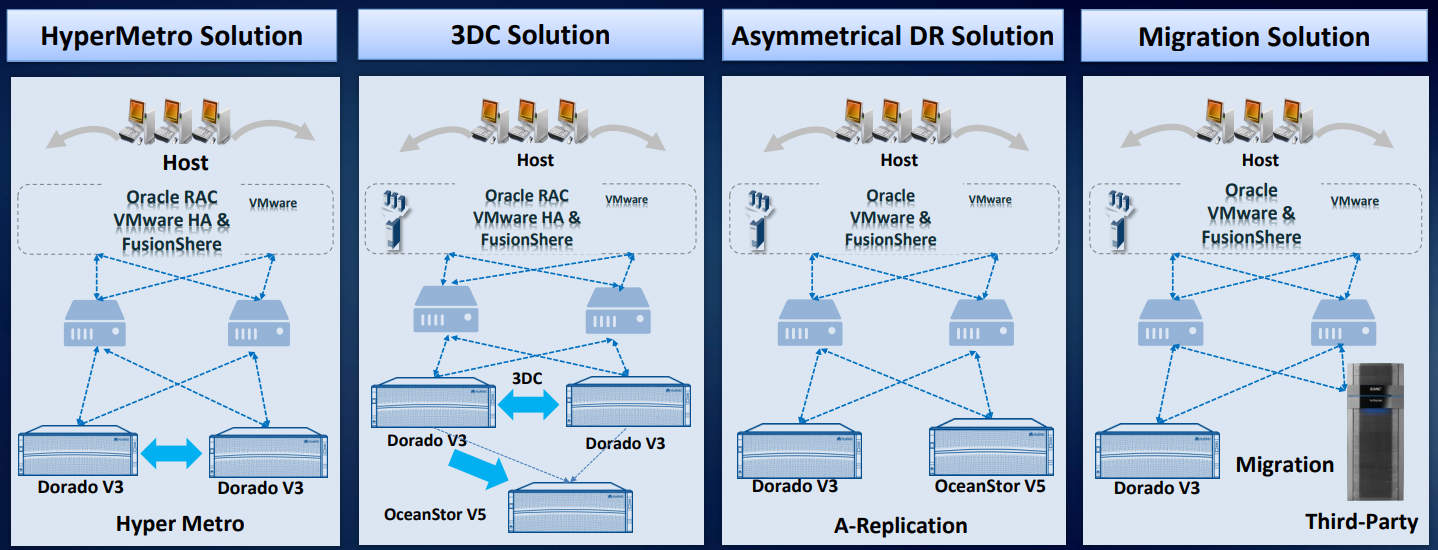
Basierend auf unseren Speichersystemen wurden mindestens vier Disaster Recovery-Lösungen entwickelt und in der Praxis getestet.
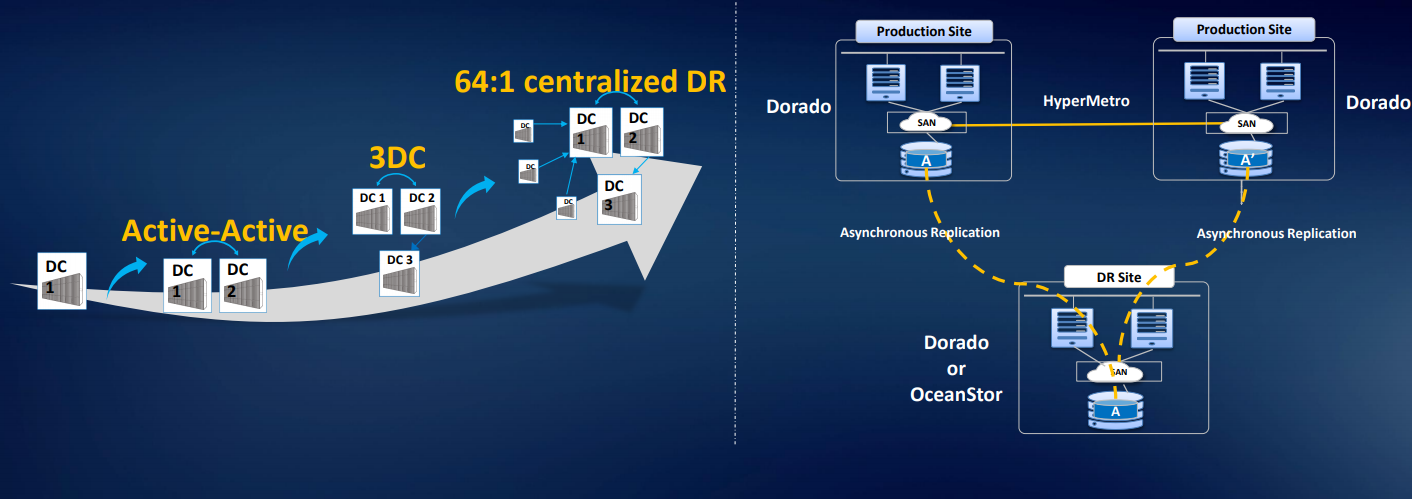
Wir haben auch eine Lösung für drei Rechenzentren der 3DC Ring DR-Lösung: zwei Rechenzentren im Cluster, und das dritte wird repliziert. Wir können die asynchrone Replikation oder Migration von Arrays von Drittanbietern organisieren. Es gibt eine Smart Virtualization-Lizenz, sodass Sie Volumes von den meisten Standard-Arrays mit FC-Zugriff verwenden können: Hitachi, DELL EMC, HPE usw. Die Lösung ist wirklich ausgearbeitet, es gibt Analoga auf dem Markt, aber sie kosten mehr. Es gibt Anwendungsbeispiele in Russland.
Infolgedessen können Sie auf der Ebene der gesamten Lösung die Zuverlässigkeit von sechs Neunen und auf der Ebene des lokalen Speichers von fünf Neunen erhalten. Im Allgemeinen haben wir es versucht.
Gepostet von Vladimir Svinarenko, Senior IT Solutions Manager bei Huawei Enterprise in Russland