
Das Thema des Artikels ist eher eng gefasst, kann sich jedoch für diejenigen als nützlich erweisen, die ihre eigenen Data Warehouses entwickeln und über die Integration in das Spring Framework nachdenken.
Hintergrund
Entwickler ändern ihre Gewohnheiten normalerweise nicht gern (häufig sind auch Frameworks in der Liste der Gewohnheiten enthalten). Als ich anfing, mit CUBA zu arbeiten , musste ich nicht zu viele neue Dinge lernen, es war möglich, mich fast sofort aktiv an der Arbeit an dem Projekt zu beteiligen. Aber es gab eine Sache, auf der ich länger sitzen musste - es war die Arbeit mit Daten.
Spring verfügt über mehrere Bibliotheken, die für die Arbeit mit der Datenbank verwendet werden können. Eine der beliebtesten ist spring-data-jpa , mit der in den meisten Fällen kein SQL oder JPQL geschrieben werden kann. Sie müssen nur eine spezielle Schnittstelle mit Methoden erstellen, die auf spezielle Weise benannt sind, und Spring generiert und erledigt den Rest der Arbeit für Sie, um Daten aus der Datenbank abzurufen und Instanzen von Entitätsobjekten zu erstellen.
Unten finden Sie die Benutzeroberfläche mit einer Methode zum Zählen von Kunden mit einem bestimmten Nachnamen.
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Diese Schnittstelle kann direkt in Spring Services verwendet werden, ohne dass eine Implementierung erstellt wird, was die Arbeit erheblich beschleunigt.
CUBA verfügt über eine API für die Arbeit mit Daten, die verschiedene Funktionen wie teilweise geladene Entitäten oder ein kniffliges Sicherheitssystem mit Zugriffssteuerung auf Entitätsattribute und Zeilen in Datenbanktabellen umfasst. Diese API unterscheidet sich jedoch geringfügig von dem, was Entwickler in Spring Data oder JPA / Hibernate gewohnt sind.
Warum gibt es in CUBA keine JPA-Repositorys und kann ich sie hinzufügen?
Arbeiten mit Daten in CUBA
In CUBA gibt es drei Hauptklassen, die für die Arbeit mit Daten verantwortlich sind: DataStore, EntityManager und DataManager.
DataStore ist eine allgemeine Abstraktion für jeden Datenspeicher: Datenbank, Dateisystem oder Cloud-Speicher. Mit dieser API können Sie grundlegende Vorgänge für Daten ausführen. In den meisten Fällen müssen Entwickler nicht direkt mit dem DataStore arbeiten, es sei denn, sie entwickeln ihren eigenen Speicher oder es ist ein ganz besonderer Zugriff auf die Daten im Speicher erforderlich.
EntityManager ist eine Kopie des bekannten JPA EntityManager. Im Gegensatz zur Standardimplementierung verfügt es über spezielle Methoden zum Arbeiten mit CUBA-Ansichten , zum "weichen" (logischen) Löschen von Daten sowie zum Arbeiten mit Abfragen in CUBA . Wie im Fall des DataStore muss sich ein normaler Entwickler in 90% der Projekte nicht mit EntityManager befassen, es sei denn, einige Anforderungen müssen unter Umgehung des Datenzugriffsbeschränkungssystems erfüllt werden.
DataManager ist die Hauptklasse für die Arbeit mit Daten in CUBA. Bietet eine API für die Datenmanipulation und unterstützt die Datenzugriffskontrolle, einschließlich des Zugriffs auf Attribute und Einschränkungen auf Zeilenebene. Der DataManager ändert implizit alle Abfragen, die in CUBA ausgeführt werden. Beispielsweise können Tabellenfelder, auf die der aktuelle Benutzer keinen Zugriff hat, von der select Anweisung ausgeschlossen und Bedingungen hinzugefügt werden, um Tabellenzeilen von der Auswahl auszuschließen. Dies erleichtert Entwicklern das Leben, da Sie nicht überlegen müssen, wie Abfragen unter Berücksichtigung der Zugriffsrechte korrekt geschrieben werden sollen. CUBA führt dies automatisch basierend auf Daten aus Datenbankdiensttabellen durch.
Unten sehen Sie ein Diagramm der Interaktion der CUBA-Komponenten, die beim Abrufen von Daten über den DataManager beteiligt sind.
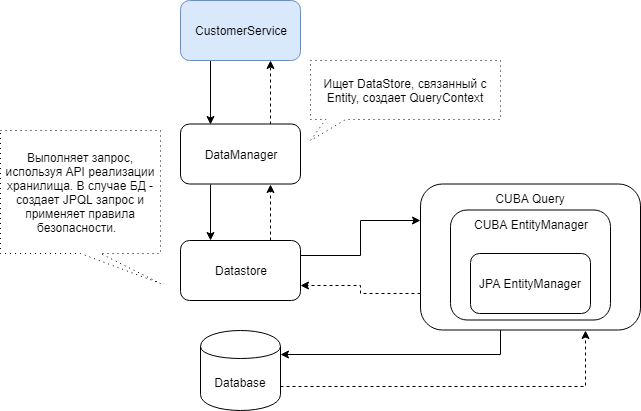
Mit dem DataManager können Sie Entitäten und ganze Hierarchien von Entitäten mithilfe von CUBA-Ansichten relativ einfach laden. In der einfachsten Form sieht die Abfrage folgendermaßen aus:
dataManager.load(Customer.class).list();
Wie bereits erwähnt, filtert DataManager "logisch gelöschte" Datensätze heraus, entfernt verbotene Attribute aus der Anforderung und öffnet und schließt die Transaktion automatisch.
Wenn es jedoch um kompliziertere Abfragen geht, müssen Sie JPQL in CUBA schreiben.
Wenn Sie beispielsweise Kunden mit einem bestimmten Nachnamen zählen müssen, wie im Beispiel aus dem vorherigen Abschnitt, müssen Sie Folgendes schreiben:
public Long countByLastName(String lastName) { return dataManager .loadValue("select count(c) from sample$Customer c where c.lastName = :lastName", Long.class) .parameter("lastName", lastName) .one(); }
oder so:
public Long countByLastName(String lastName) { LoadContext<Customer> loadContext = LoadContext.create(Customer.class); loadContext .setQueryString("select c from sample$Customer c where c.lastName = :lastName") .setParameter("lastName", lastName); return dataManager.getCount(loadContext); }
In der CUBA-API müssen Sie einen JPQL-Ausdruck als Zeichenfolge übergeben (die Kriterien-API wird noch nicht unterstützt). Dies ist eine lesbare und verständliche Methode zum Erstellen von Abfragen. Das Debuggen solcher Abfragen kann jedoch viele unterhaltsame Minuten bringen. Darüber hinaus werden JPQL-Zeichenfolgen während der Containerinitialisierung weder vom Compiler noch vom Spring Framework überprüft, was nur in Runtime zu Fehlern führt.
Vergleichen Sie dies mit Spring JPA:
interface CustomerRepository extends CrudRepository<Customer, Long> { long countByLastName(String lastName); }
Der Code ist dreimal kürzer und enthält keine Zeilen. Außerdem wird der Methodenname countByLastName bei der Initialisierung des Spring-Containers überprüft. Wenn ein Tippfehler countByLastNsme und Sie countByLastNsme , countByLastNsme die Anwendung während der Bereitstellung mit einem Fehler ab:
Caused by: org.springframework.data.mapping.PropertyReferenceException: No property LastNsme found for type Customer!
CUBA basiert auf dem Spring Framework, sodass Sie die spring-data-jpa-Bibliothek in einer mit CUBA geschriebenen Anwendung verwenden können. Es gibt jedoch ein kleines Problem: die Zugriffssteuerung. Die Implementierung von Spring CrudRepository verwendet den EntityManager. Somit werden alle Abfragen unter Umgehung des DataManager ausgeführt. Um JPA-Repositorys in CUBA zu verwenden, müssen Sie daher alle EntityManager-Aufrufe durch DataManager-Aufrufe ersetzen und Unterstützung für CUBA-Ansichten hinzufügen.
Jemand könnte sagen, dass spring-data-jpa eine so unkontrollierte Black Box ist und es immer vorzuziehen ist, reines JPQL oder sogar SQL zu schreiben. Dies ist das ewige Problem des Gleichgewichts zwischen Zweckmäßigkeit und Abstraktionsebene. Jeder wählt die Methode, die er bevorzugt, aber eine zusätzliche Möglichkeit, mit Daten im Arsenal zu arbeiten, wird niemals schaden. Und für diejenigen, die mehr Kontrolle benötigen, hat Spring die Möglichkeit, ihre eigene Anforderung für JPA-Repository-Methoden zu definieren .
Implementierung
JPA-Repositorys werden als CUBA-Modul unter Verwendung der Spring-Data-Commons- Bibliothek implementiert. Wir haben die Idee der Änderung von spring-data-jpa aufgegeben, da der Arbeitsaufwand im Vergleich zum Schreiben unseres eigenen Abfragegenerators viel höher wäre. Zumal Spring-Data-Commons den größten Teil der Arbeit erledigt. Das Parsen eines Methodennamens und das Zuordnen eines Namens zu Klassen und Eigenschaften erfolgt beispielsweise vollständig in dieser Bibliothek. Spring-data-commons enthält alle erforderlichen Basisklassen für die Implementierung Ihrer eigenen Repositorys, und die Implementierung erfordert keinen großen Aufwand. Diese Bibliothek wird beispielsweise in spring-data-mongodb verwendet .
Am schwierigsten war es, die JPQL-Generierung basierend auf einer Hierarchie von Objekten genau zu implementieren - das Ergebnis der Analyse des Methodennamens. Glücklicherweise wurde eine ähnliche Aufgabe bereits in Apache Ignite implementiert, sodass der Code von dort übernommen und ein wenig angepasst wurde, um JPQL anstelle von SQL zu generieren und den delete .
Spring-data-commons verwendet Proxy, um Schnittstellenimplementierungen dynamisch zu erstellen. Wenn der CUBA-Anwendungskontext initialisiert wird, werden alle Links zu Schnittstellen durch Links zu im Kontext veröffentlichten Proxy-Bins ersetzt. Wenn die Schnittstellenmethode aufgerufen wird, wird sie vom entsprechenden Proxy-Objekt abgefangen. Anschließend generiert dieses Objekt eine JPQL-Abfrage mit dem Namen der Methode, ersetzt die Parameter und sendet die Abfrage mit Parametern zur Ausführung an den DataManager. Das folgende Diagramm zeigt einen vereinfachten Prozess der Interaktion zwischen Schlüsselkomponenten des Moduls.

Verwenden von Repositorys in CUBA
Um Repositorys in CUBA zu verwenden, müssen Sie nur das Modul in der Projekterstellungsdatei verbinden:
appComponent("com.haulmont.addons.cuba.jpa.repositories:cuba-jpa-repositories-global:0.1-SNAPSHOT")
Sie können die XML-Konfiguration verwenden, um Repositorys zu aktivieren:
<?xml version="1.0" encoding="UTF-8"?> <beans:beans xmlns:beans="http://www.springframework.org/schema/beans" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns:context="http://www.springframework.org/schema/context" xmlns:repositories="http://www.cuba-platform.org/schema/data/jpa" xsi:schemaLocation=" http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context-4.3.xsd http://www.cuba-platform.org/schema/data/jpa http://www.cuba-platform.org/schema/data/jpa/cuba-repositories.xsd"> <context:component-scan base-package="com.company.sample"/> <repositories:repositories base-package="com.company.sample.core.repositories"/> </beans:beans>
Und Sie können die Anmerkungen verwenden:
@Configuration @EnableCubaRepositories public class AppConfig {
Nachdem die Unterstützung von Repositorys aktiviert wurde, können Sie diese in der üblichen Form erstellen, zum Beispiel:
public interface CustomerRepository extends CubaJpaRepository<Customer, UUID> { long countByLastName(String lastName); List<Customer> findByNameIsIn(List<String> names); @CubaView("_minimal") @JpqlQuery("select c from sample$Customer c where c.name like concat(:name, '%')") List<Customer> findByNameStartingWith(String name); }
Für jede Methode können Sie Anmerkungen verwenden:
@CubaView - Zum @CubaView der CUBA-Ansicht, die im DataManager verwendet werden soll@JpqlQuery - um die JPQL-Abfrage anzugeben, die unabhängig vom Methodennamen ausgeführt wird.
Dieses Modul wird im global Modul des CUBA-Frameworks verwendet. Daher können Repositorys sowohl im Kernmodul als auch im web . Sie müssen sich nur daran erinnern, Repositorys in den Konfigurationsdateien beider Module zu aktivieren.
Ein Beispiel für die Verwendung des Repositorys im CUBA-Dienst:
@Service(CustomerService.NAME) public class CustomerServiceBean implements PersonService { @Inject private CustomerRepository customerRepository; @Override public List<Date> getCustomersBirthDatesByLastName(String name) { return customerRepository.findByNameStartingWith(name) .stream().map(Customer::getBirthDate).collect(Collectors.toList()); } }
Fazit
CUBA ist ein flexibles Framework. Wenn Sie etwas hinzufügen möchten, müssen Sie den Kernel nicht selbst reparieren oder auf eine neue Version warten. Ich hoffe, dass dieses Modul die CUBA-Entwicklung effizienter und schneller macht. Die erste Version des Moduls ist auf GitHub verfügbar und wurde in CUBA Version 6.10 getestet